如何开发一个属于自己的人工智能语言大模型?
要开发一个属于自己的人工智能语言模型,你需要遵循以下步骤:
-
数据收集:首先你需要大量的文本数据来训练你的模型。这些数据可以来自于各种来源,例如书籍、网站、新闻文章等。你需要确保这些数据足够多样化,以便模型能学习到各种语言模式。
-
数据预处理:在训练模型之前,你需要对数据进行预处理。这可能包括清理文本、去除停用词、进行词干提取、分词等。
-
选择模型结构:你需要选择一个适合处理文本数据的模型结构。一种常见的选择是 Transformer 结构,这是 GPT 和 BERT 等模型使用的结构。
-
训练模型:使用你的数据和选择的模型结构,你可以开始训练你的模型。这通常需要大量的计算资源和时间。
-
评估模型:训练完成后,你需要评估模型的性能。这通常涉及到在一些测试数据上运行模型,并使用一些度量标准(如准确率、召回率、F1 分数等)来评估其性能。
-
优化和调整:根据模型的评估结果,你可能需要对模型进行优化和调整。这可能包括改变模型结构、调整学习率、增加训练数据等。
-
部署模型:模型训练和优化完成后,你可以将其部署到一个服务器,以便在应用程序中使用。
这只是一个基本的概述,开发一个人工智能语言模型实际上是一个非常复杂的过程,需要深厚的机器学习知识和大量的计算资源。如果你刚开始接触这个领域,我建议你先从一些简单的项目开始,例如使用现有的模型和工具库进行文本分类或情感分析。
数据收集是什么样类型的数据都可以吗?
在训练一个人工智能语言模型时,你需要的数据类型主要是文本数据。这些数据可以从各种来源获取,包括书籍、新闻文章、网站、论坛帖子、社交媒体帖子等。
重要的是,这些文本数据需要尽可能地多样化和全面,以便模型能够学习到语言的各种模式和用法。例如,如果你只使用新闻文章来训练你的模型,那么模型可能会很擅长生成类似新闻的文本,但可能不擅长处理更口语化或非正式的文本。
此外,你需要确保你有权使用你的数据源进行训练,这意味着你需要注意版权和隐私问题。在某些情况下,你可能需要去标识化你的数据,以保护用户的隐私。
最后,你的数据需要经过适当的预处理,以便模型可以更有效地学习。这可能包括清理文本(例如,删除特殊字符或纠正拼写错误)、分词、去除停用词等。
假如我现在已经有数据了,那么如何使用Transformer 结构开发我的大模型?
如果你已经有了数据,那么你可以开始使用 Transformer 结构来训练你的模型。以下是一个基本的步骤概述:
-
预处理数据:首先,你需要对你的数据进行预处理。这可能包括分词(将文本分解为单词或其他更小的单位)、构建词汇表(一个包含你的数据中所有独特单词的列表)和编码(将你的文本转换为模型可以处理的数字)。
-
选择模型架构:然后,你需要选择你的模型架构。对于 Transformer,你需要设置一些参数,如隐藏层的大小、注意力头的数量、编码器和解码器层的数量等。
-
训练模型:现在你可以开始训练你的模型。你需要选择一个适当的损失函数(例如,对于语言建模任务,常用的损失函数是交叉熵损失)和一个优化器。然后,你可以使用你的数据和这些设置来训练你的模型。这通常需要大量的计算资源和时间。
-
评估和优化模型:训练完成后,你需要评估你的模型的性能。这可能包括在一个验证集上运行你的模型,并计算一些度量(例如,准确率或困惑度)。然后,你可以根据这些结果来优化你的模型。
这只是一个基本的概述,实际的过程可能会更复杂。你可能需要进行更多的数据预处理步骤,例如处理不平衡的类或去除停用词。你也可能需要尝试不同的模型参数或优化器设置,以找到最佳的配置。
此外,开发一个大型的语言模型可能需要专业的机器学习知识和大量的计算资源。如果你刚开始接触这个领域,我建议你从一些更简单的任务开始,例如使用现有的 Transformer 模型(如 BERT 或 GPT-2)进行微调,以解决具体的问题。
这些都是深度学习和 Transformer 模型的关键概念。让我一个个解释给你:
-
隐藏层的大小:在神经网络中,隐藏层的大小是指每个隐藏层中神经元的数量。在 Transformer 模型中,这通常指的是在自注意力机制中用于表示每个单词或词元的向量的维度。
-
注意力头的数量:在 Transformer 模型中,注意力机制是一个核心的组成部分,它允许模型关注输入序列中的不同部分。一个注意力头就是一个独立的注意力机制。增加注意力头的数量可以帮助模型学习到更复杂的模式,但也会增加模型的复杂性和计算需求。
-
编码器和解码器层的数量:在 Transformer 模型中,编码器和解码器都是由多个相同的层堆叠而成的。每个层都包括一个自注意力机制和一个前馈神经网络。增加层数可以帮助模型学习到更复杂的模式,但也会增加模型的复杂性和计算需求。
-
损失函数:损失函数是用于评估模型预测与实际值之间差距的度量。在训练过程中,我们的目标是最小化损失函数。对于分类问题,常见的损失函数是交叉熵损失。
-
优化器:优化器是用来更新模型参数以最小化损失函数的算法。常见的优化器包括梯度下降(及其变体,如随机梯度下降)、Adam、RMSprop 等。
使用huggenface能否部署我自己开发的大模型?
是的,Hugging Face 是一个非常流行的开源库,它提供了一种方便的方式来训练、使用和部署基于 Transformer 的模型。
如果你已经训练了一个模型,你可以使用 Hugging Face 的 Model Hub 来共享和部署你的模型。你只需要将你的模型和相关的配置文件上传到 Model Hub,然后你就可以通过一个 URL 在任何地方使用你的模型了。
此外,Hugging Face 还提供了一些工具来帮助你在各种环境中部署你的模型,包括在服务器、在云、在浏览器和在移动设备上。
请注意,部署大型模型可能会有一些挑战,包括计算资源的需求和延迟的问题。你可能需要使用一些优化技术,如模型剪枝和量化,来减少模型的大小和提高运行速度。
相关文章:

如何开发一个属于自己的人工智能语言大模型?
要开发一个属于自己的人工智能语言模型,你需要遵循以下步骤: 数据收集:首先你需要大量的文本数据来训练你的模型。这些数据可以来自于各种来源,例如书籍、网站、新闻文章等。你需要确保这些数据足够多样化,以便模型能学…...

【HTTP】localhost和127.0.0.1的区别是什么?
目录 localhost是什么呢? 从域名到程序 localhost和127.0.0.1的区别是什么? 域名的等级划分 多网站共用一个IP和端口 私有IP地址 IPv6 今天在网上逛的时候看到一个问题,没想到大家讨论的很热烈,就是标题中这个: …...

Edge浏览器-常用快捷键
按键组合作用Ctrl Shift I开发人员工具Ctrl E定位到 空地址栏Ctrl L定位到 地址栏Ctrl Shift B显示或隐藏 收藏夹栏Ctrl Shift O打开收藏夹(搜索)Ctrl T打开一个新标签页Ctrl W关闭当前标签页Ctrl Shift T重新打开刚才关闭的标签页Ctrl Tab切换到下一个标签页Ctrl…...

C++:Vector动态数组的copy深入理解
动态数组分配的大小默认为2的n次方1,2,4,8... 在main中创建的vertices,push需要放到Vertex中(copy),下一次copy是因为要调整vertices的大小 vertices.push_back(Vertex(1,2,3));//拷贝 第一次&a…...
切片操作)
【PyTorch】PyTorch中张量(Tensor)切片操作
PyTorch深度学习总结 第三章 PyTorch中张量(Tensor)切片操作 文章目录 PyTorch深度学习总结一、前言二、获取张量中的元素1、切片(行、列数)方法2、torch.where()函数3、使元素置零的操作 一、前言 上文介绍了PyTorch中改变张量(Tensor)形状的操作&…...
GeoServer 2.11.1升级解决Eclipse Jetty 的一系列安全漏洞问题
Eclipse Jetty 资源管理错误漏洞(CVE-2021-28165) Eclipse Jetty HTTP请求走私漏洞(CVE-2017-7656) Eclipse Jetty HTTP请求走私漏洞(CVE-2017-7657) Eclipse Jetty HTTP请求走私漏洞(CVE-2017-7658) Jetty 信息泄露漏洞(CVE-2017-9735) Eclipse Jetty 安全漏洞(CVE-2022-20…...

【蓝桥杯选拔赛真题34】C++最大值 第十三届蓝桥杯青少年创意编程大赛C++编程选拔赛真题解析
目录 C/C++最大值 一、题目要求 1、编程实现 2、输入输出...
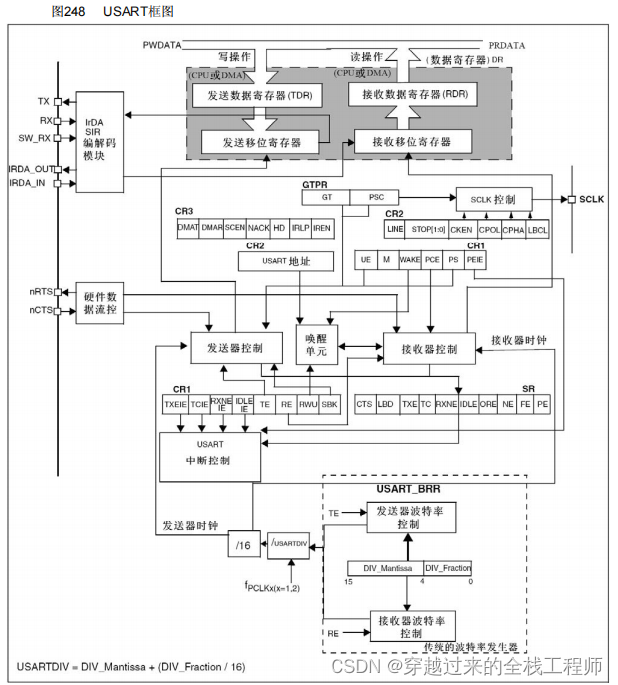
STM32之USART
概述 串口通信,通用异步收发传输器(Universal Asynchronous Receiver/Transmitter ),简称UART;而USART(Universal Synchronous/Asynchronous Receiver/Transmitter)通用同步收发传输器。 USAR…...
unity 点击事件
目录 点击按钮,显示图片功能教程 第1步添加ui button,添加ui RawImage 第2步 添加脚本: 第3步,把脚本拖拽到button,点击button,设置脚本的变量, GameObject添加 Component组件 点击按钮&am…...
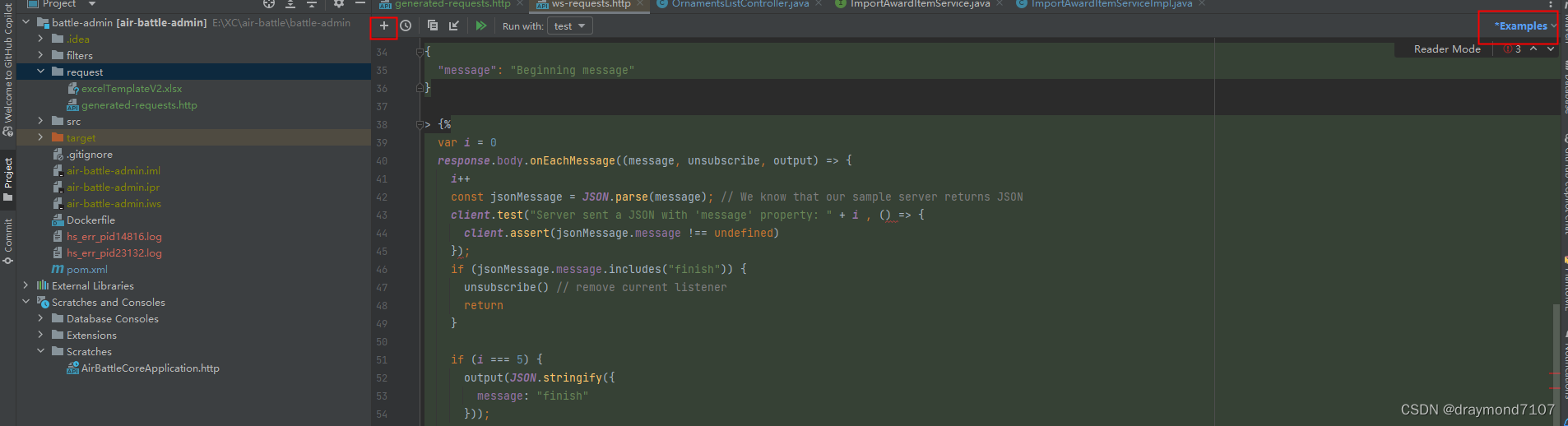
idea自带的HttpClient使用
1. 全局变量配置 {"local":{"baseUrl": "http://localhost:9001/"},"test": {"baseUrl": "http://localhost:9002/"} }2. 登录并将结果设置到全局变量 PostMapping("/login")public JSONObject login(H…...
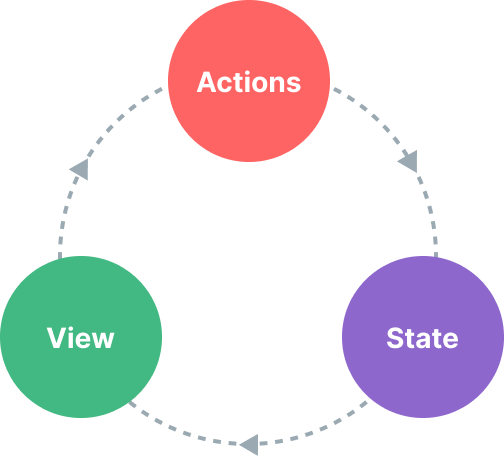
vue3-应用规模化-路由和状态
客户端 vs. 服务端路由 服务端路由指的是服务器根据用户访问的 URL 路径返回不同的响应结果。当我们在一个传统的服务端渲染的 web 应用中点击一个链接时,浏览器会从服务端获得全新的 HTML,然后重新加载整个页面。 然而,在单页面应用中&…...
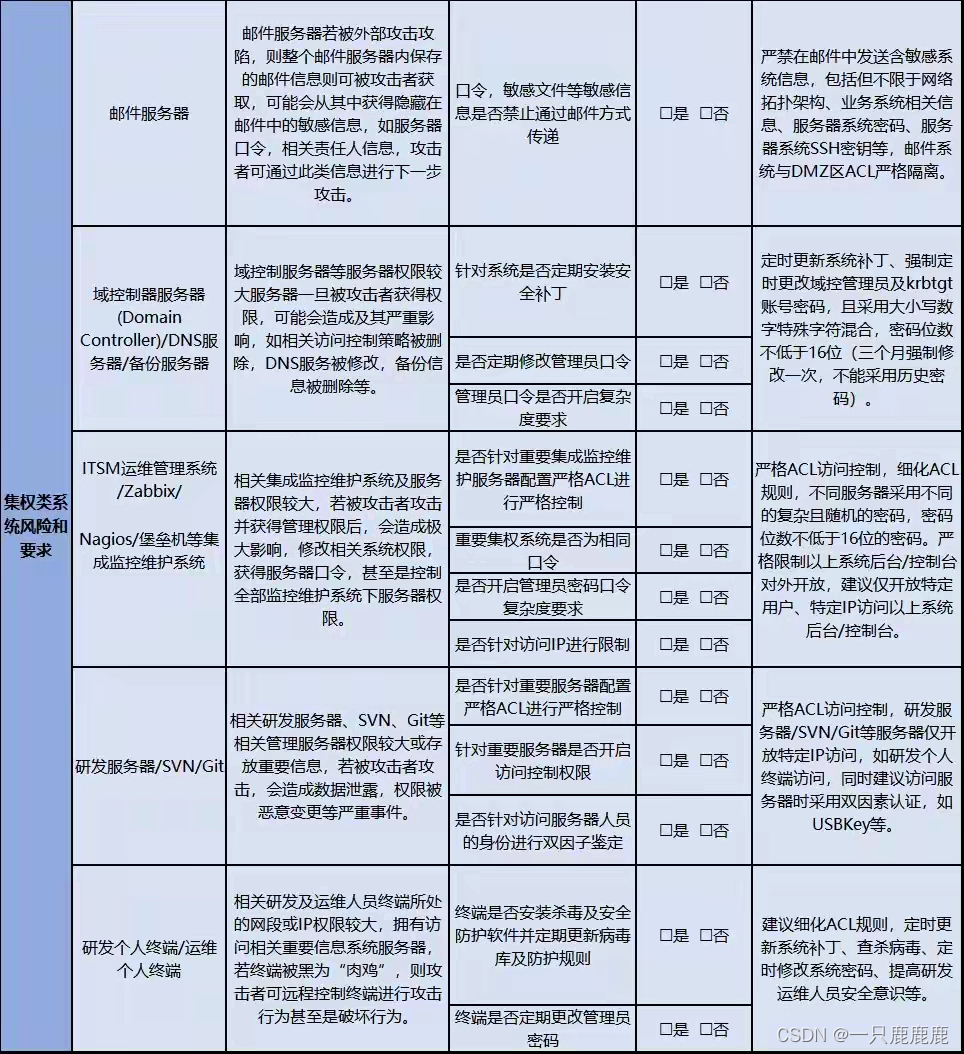
网络安全检查表
《网络攻击检查表》 1.应用安全漏洞 2.弱口令,默认口令 3.服务器互联网暴露 4.操作系统,中间件安全漏洞 5.研发服务器,邮件服务器等安全检查...
)
SSM框架,Maven的学习(下)
依赖传递和依赖冲突 依赖传递指的是当一个模块或库 A 依赖于另一个模块或库 B,而 B 又依赖于模块或库 C,那么 A 会间接依赖于 C。这种依赖传递结构可以形成一个依赖树。当我们引入一个库或框架时,构建工具(如 Maven、Gradle&…...

Vivado开发FPGA使用流程、教程 verilog(建立工程、编译文件到最终烧录的全流程)
目录 一、概述 二、工程创建 三、添加设计文件并编译 四、线上仿真 五、布局布线 六、生成比特流文件 七、烧录 一、概述 vivado开发FPGA流程分为创建工程、添加设计文件、编译、线上仿真、布局布线(添加约束文件)、生成比特流文件、烧录等步骤&a…...
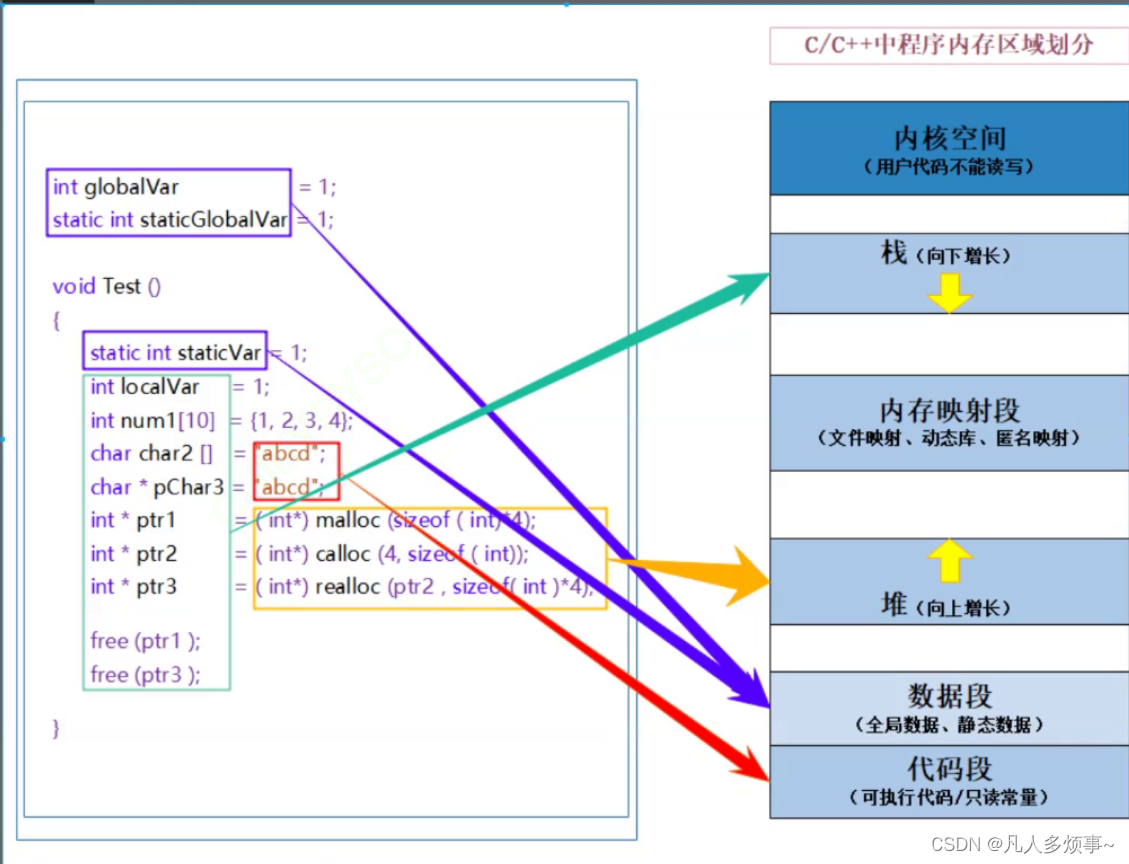
C语言之动态内存管理
目录 1. 为什么要有动态内存分配2. malloc和freemallocfree 3. calloc和realloccallocrealloc 4. 常见的动态内存的错误对NULL直接的解引用操作对动态开辟空间的越界访问对非动态开辟内存使用free释放使用free释放一块动态开辟内存的一部分对同一块动态内存多次释放动态开辟内存…...

【AIGC风格prompt深度指南】掌握绘画风格关键词,实现艺术模仿的革新实践
[小提琴家]ASCII风格,点,爆炸,光,射线,计算机代码 由冰和水制成的和平标志]非常详细,寒冷,冰冻,大气,照片逼真,流动,16K 胡迪尼模拟火和水&#x…...
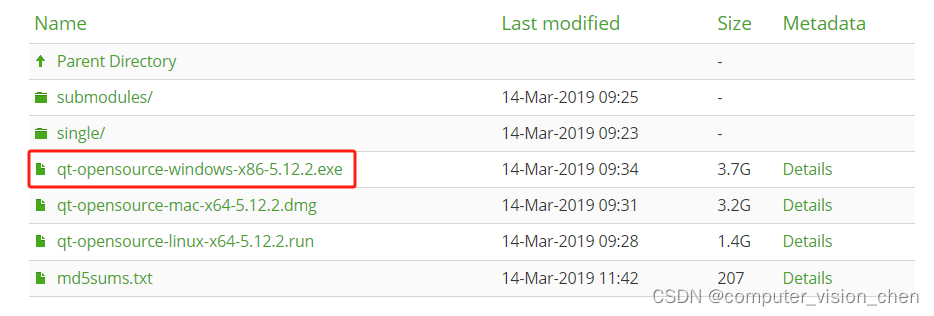
Qt安装配置教程windows版(包括:Qt5.8.0版本,Qt5.12,Qt5.14版本下载安装教程)(亲测可行)
目录 Qt5.8.0版本安装教程Qt5.8.0版本下载安装 Qt5.12.2版本安装教程下载安装 Qt 5.14.2安装教程下载安装和创建项目 参考视频 QT为嵌入式系统提供了大量的库和可重用组件。 WPS Office,咪咕音乐,Linux桌面环境等都是QT开发的。 Qt5.8.0版本安装教程 Q…...
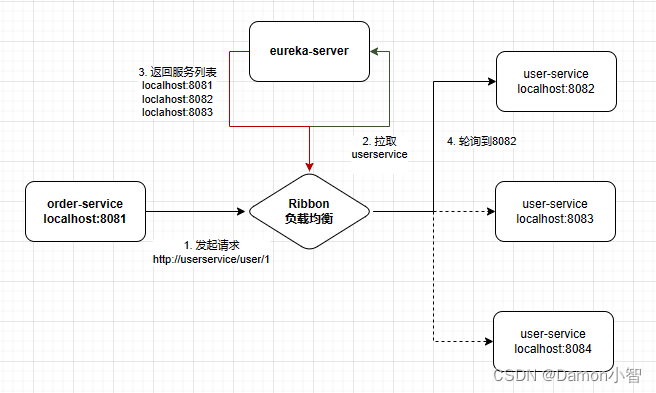
SpringCloud-Ribbon实现负载均衡
在微服务架构中,负载均衡是一项关键的技术,它可以确保各个服务节点间的负载分布均匀,提高整个系统的稳定性和性能。Spring Cloud 中的 Ribbon 就是一种负载均衡的解决方案,本文将深入探讨 Ribbon 的原理和在微服务中的应用。 一、…...
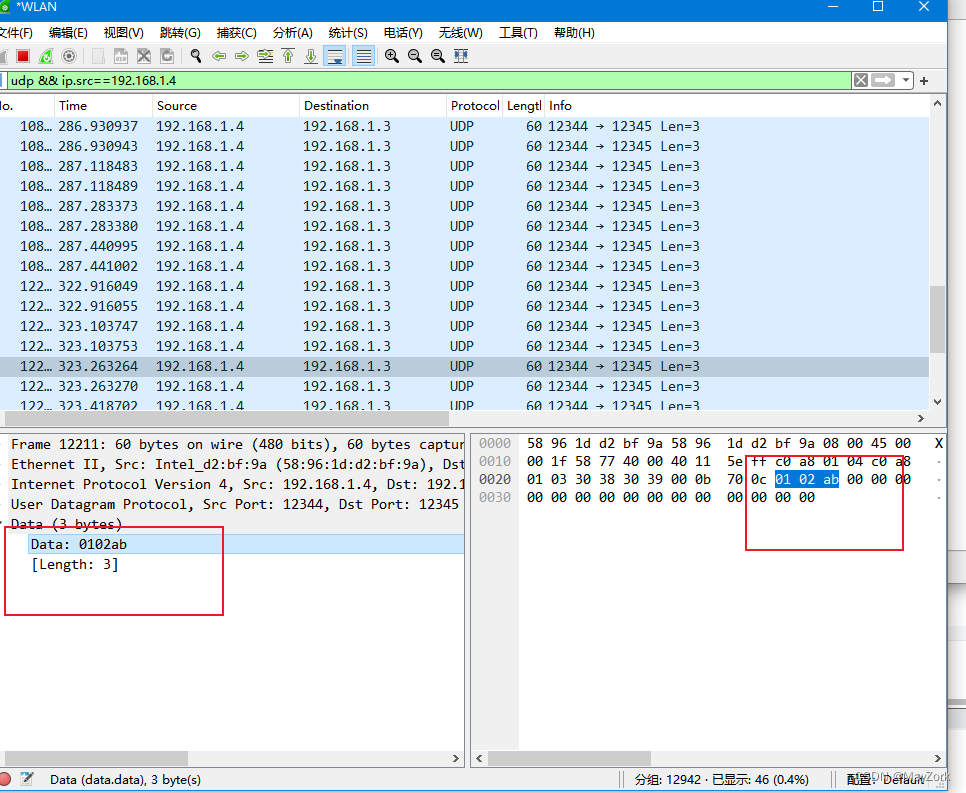
Qt网络编程-TCP与UDP
网络基础 TCP与UDP基础 关于TCP与UDP的基础这里就不过多介绍了,具体可以查看对应百度百科介绍: TCP(传输控制协议)_百度百科 (baidu.com) UDP_百度百科 (baidu.com) 需要知道这两者的区别: 可靠性: TC…...

Promise 常见题目
微信搜索“好朋友乐平”关注公众号。 1. Promise 对象池 请你编写一个异步函数 promisePool ,它接收一个异步函数数组 functions 和 池限制 n。它应该返回一个 promise 对象,当所有输入函数都执行完毕后,promise 对象就执行完毕。 池限制 定…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

RSS 2025|从说明书学习复杂机器人操作任务:NUS邵林团队提出全新机器人装配技能学习框架Manual2Skill
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。 尽管 VLMs 取得了显著进展,机器人仍难以胜任复杂的长时程任务(如家具装配),主要受限于人…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...
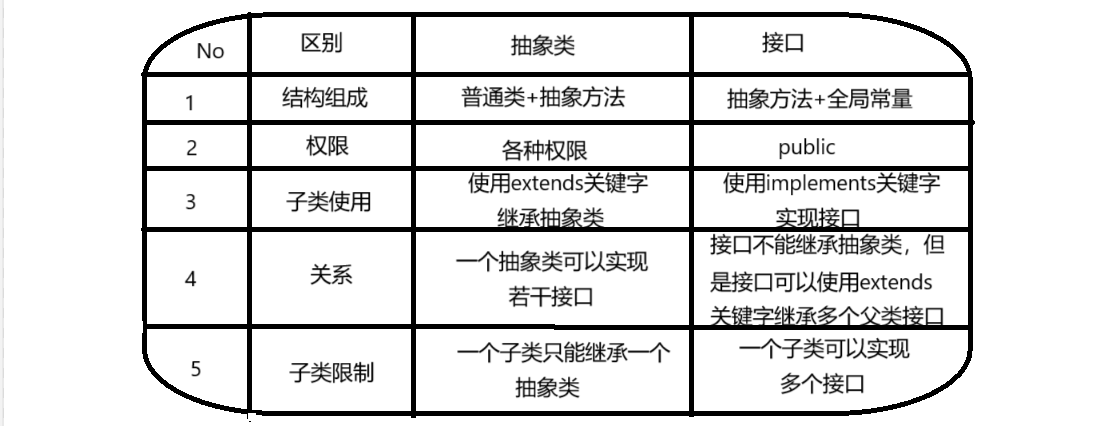
抽象类和接口(全)
一、抽象类 1.概念:如果⼀个类中没有包含⾜够的信息来描绘⼀个具体的对象,这样的类就是抽象类。 像是没有实际⼯作的⽅法,我们可以把它设计成⼀个抽象⽅法,包含抽象⽅法的类我们称为抽象类。 2.语法 在Java中,⼀个类如果被 abs…...