【极数系列】Flink集成KafkaSink 实时输出数据(11)
文章目录
- 01 引言
- 02 连接器依赖
- 2.1 kafka连接器依赖
- 2.2 base基础依赖
- 03 使用方法
- 04 序列化器
- 05 指标监控
- 06 项目源码实战
- 6.1 包结构
- 6.2 pom.xml依赖
- 6.3 配置文件
- 6.4 创建sink作业
01 引言
KafkaSink 可将数据流写入一个或多个 Kafka topic
实战源码地址,一键下载可用:https://gitee.com/shawsongyue/aurora.git
模块:aurora_flink_connector_kafka
主类:KafkaSinkStreamingJob
02 连接器依赖
2.1 kafka连接器依赖
<!--kafka依赖 start--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>3.0.2-1.18</version></dependency><!--kafka依赖 end-->
2.2 base基础依赖
若是不引入该依赖,项目启动直接报错:Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/flink/connector/base/source/reader/RecordEmitter
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-base</artifactId><version>1.18.0</version></dependency>
03 使用方法
Kafka sink 提供了构建类来创建 KafkaSink 的实例
DataStream<String> stream = ...;KafkaSink<String> sink = KafkaSink.<String>builder().setBootstrapServers(brokers).setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic("topic-name").setValueSerializationSchema(new SimpleStringSchema()).build()).setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).build();stream.sinkTo(sink);以下属性在构建 KafkaSink 时是必须指定的:
Bootstrap servers, setBootstrapServers(String)
消息序列化器(Serializer), setRecordSerializer(KafkaRecordSerializationSchema)
如果使用DeliveryGuarantee.EXACTLY_ONCE 的语义保证,则需要使用 setTransactionalIdPrefix(String)
04 序列化器
-
构建时需要提供
KafkaRecordSerializationSchema来将输入数据转换为 Kafka 的ProducerRecord。Flink 提供了 schema 构建器 以提供一些通用的组件,例如消息键(key)/消息体(value)序列化、topic 选择、消息分区,同样也可以通过实现对应的接口来进行更丰富的控制。 -
其中消息体(value)序列化方法和 topic 的选择方法是必须指定的,此外也可以通过
setKafkaKeySerializer(Serializer)或setKafkaValueSerializer(Serializer)来使用 Kafka 提供而非 Flink 提供的序列化器
KafkaRecordSerializationSchema.builder().setTopicSelector((element) -> {<your-topic-selection-logic>}).setValueSerializationSchema(new SimpleStringSchema()).setKeySerializationSchema(new SimpleStringSchema()).setPartitioner(new FlinkFixedPartitioner()).build();
05 容错恢复
`KafkaSink` 总共支持三种不同的语义保证(`DeliveryGuarantee`)。对于 `DeliveryGuarantee.AT_LEAST_ONCE` 和 `DeliveryGuarantee.EXACTLY_ONCE`,Flink checkpoint 必须启用。默认情况下 `KafkaSink` 使用 `DeliveryGuarantee.NONE`。 以下是对不同语义保证的解释:
DeliveryGuarantee.NONE不提供任何保证:消息有可能会因 Kafka broker 的原因发生丢失或因 Flink 的故障发生重复。DeliveryGuarantee.AT_LEAST_ONCE: sink 在 checkpoint 时会等待 Kafka 缓冲区中的数据全部被 Kafka producer 确认。消息不会因 Kafka broker 端发生的事件而丢失,但可能会在 Flink 重启时重复,因为 Flink 会重新处理旧数据。DeliveryGuarantee.EXACTLY_ONCE: 该模式下,Kafka sink 会将所有数据通过在 checkpoint 时提交的事务写入。因此,如果 consumer 只读取已提交的数据(参见 Kafka consumer 配置isolation.level),在 Flink 发生重启时不会发生数据重复。然而这会使数据在 checkpoint 完成时才会可见,因此请按需调整 checkpoint 的间隔。请确认事务 ID 的前缀(transactionIdPrefix)对不同的应用是唯一的,以保证不同作业的事务 不会互相影响!此外,强烈建议将 Kafka 的事务超时时间调整至远大于 checkpoint 最大间隔 + 最大重启时间,否则 Kafka 对未提交事务的过期处理会导致数据丢失。
05 指标监控
Kafka sink 会在不同的范围(Scope)中汇报下列指标。
| 范围 | 指标 | 用户变量 | 描述 | 类型 |
|---|---|---|---|---|
| 算子 | currentSendTime | n/a | 发送最近一条数据的耗时。该指标反映最后一条数据的瞬时值。 | Gauge |
06 项目源码实战
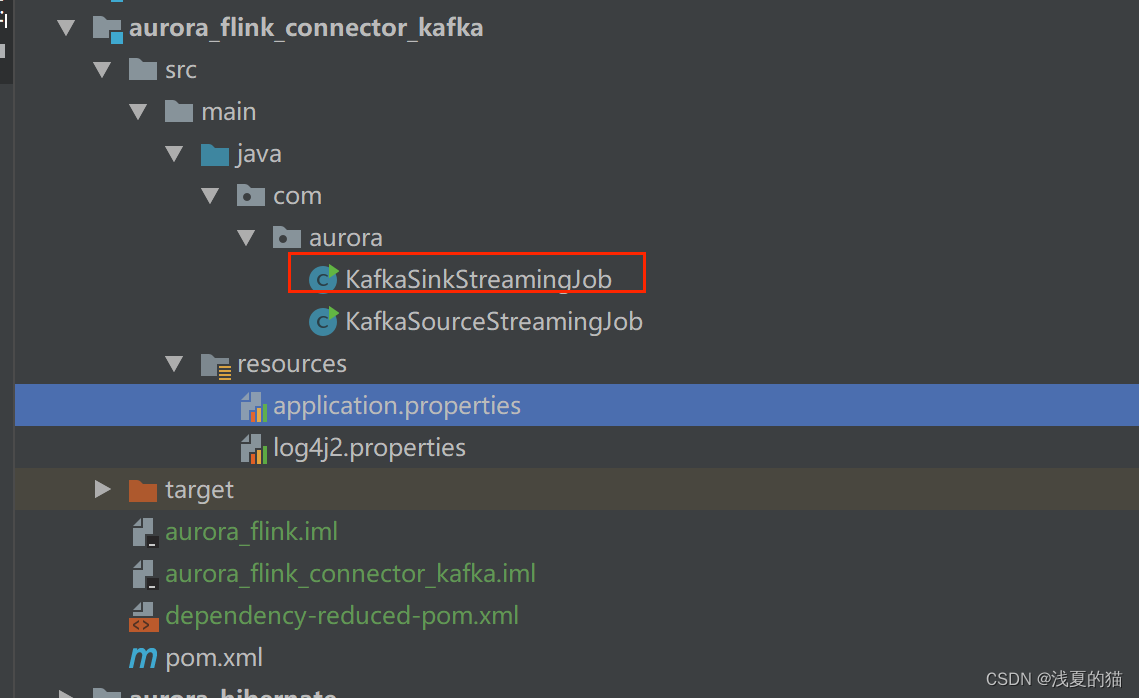
6.1 包结构
6.2 pom.xml依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.xsy</groupId><artifactId>aurora_flink_connector_kafka</artifactId><version>1.0-SNAPSHOT</version><!--属性设置--><properties><!--java_JDK版本--><java.version>11</java.version><!--maven打包插件--><maven.plugin.version>3.8.1</maven.plugin.version><!--编译编码UTF-8--><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><!--输出报告编码UTF-8--><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><!--json数据格式处理工具--><fastjson.version>1.2.75</fastjson.version><!--log4j版本--><log4j.version>2.17.1</log4j.version><!--flink版本--><flink.version>1.18.0</flink.version><!--scala版本--><scala.binary.version>2.11</scala.binary.version></properties><!--通用依赖--><dependencies><!-- json --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>${fastjson.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><!--================================集成外部依赖==========================================--><!--集成日志框架 start--><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>${log4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>${log4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>${log4j.version}</version></dependency><!--集成日志框架 end--><!--kafka依赖 start--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>3.0.2-1.18</version></dependency><!--kafka依赖 end--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-base</artifactId><version>1.18.0</version></dependency></dependencies><!--编译打包--><build><finalName>${project.name}</finalName><!--资源文件打包--><resources><resource><directory>src/main/resources</directory></resource><resource><directory>src/main/java</directory><includes><include>**/*.xml</include></includes></resource></resources><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>org.apache.flink:force-shading</exclude><exclude>org.google.code.flindbugs:jar305</exclude><exclude>org.slf4j:*</exclude><excluder>org.apache.logging.log4j:*</excluder></excludes></artifactSet><filters><filter><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>org.aurora.KafkaStreamingJob</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins><!--插件统一管理--><pluginManagement><plugins><!--maven打包插件--><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>${spring.boot.version}</version><configuration><fork>true</fork><finalName>${project.build.finalName}</finalName></configuration><executions><execution><goals><goal>repackage</goal></goals></execution></executions></plugin><!--编译打包插件--><plugin><artifactId>maven-compiler-plugin</artifactId><version>${maven.plugin.version}</version><configuration><source>${java.version}</source><target>${java.version}</target><encoding>UTF-8</encoding><compilerArgs><arg>-parameters</arg></compilerArgs></configuration></plugin></plugins></pluginManagement></build><!--配置Maven项目中需要使用的远程仓库--><repositories><repository><id>aliyun-repos</id><url>https://maven.aliyun.com/nexus/content/groups/public/</url><snapshots><enabled>false</enabled></snapshots></repository></repositories><!--用来配置maven插件的远程仓库--><pluginRepositories><pluginRepository><id>aliyun-plugin</id><url>https://maven.aliyun.com/nexus/content/groups/public/</url><snapshots><enabled>false</enabled></snapshots></pluginRepository></pluginRepositories></project>
6.3 配置文件
(1)application.properties
#kafka集群地址
kafka.bootstrapServers=localhost:9092
#kafka主题
kafka.topic=topic_a
#kafka消费者组
kafka.group=aurora_group
(2)log4j2.properties
rootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmprootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmp
6.4 创建sink作业
package com.aurora;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.KafkaSourceBuilder;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.runtime.state.StateBackend;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.util.ArrayList;/*** @author 浅夏的猫* @description kafka 连接器使用demo作业* @datetime 22:21 2024/2/1*/
public class KafkaSinkStreamingJob {private static final Logger logger = LoggerFactory.getLogger(KafkaSinkStreamingJob.class);public static void main(String[] args) throws Exception {//===============1.获取参数==============================//定义文件路径String propertiesFilePath = "E:\\project\\aurora_dev\\aurora_flink_connector_kafka\\src\\main\\resources\\application.properties";//方式一:直接使用内置工具类ParameterTool paramsMap = ParameterTool.fromPropertiesFile(propertiesFilePath);//================2.初始化kafka参数==============================String bootstrapServers = paramsMap.get("kafka.bootstrapServers");String topic = paramsMap.get("kafka.topic");KafkaSink<String> sink = KafkaSink.<String>builder()//设置kafka地址.setBootstrapServers(bootstrapServers)//设置消息序列号方式.setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic(topic).setValueSerializationSchema(new SimpleStringSchema()).build())//至少一次.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).build();//=================4.创建Flink运行环境=================StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();ArrayList<String> listData = new ArrayList<>();listData.add("test");listData.add("java");listData.add("c++");DataStreamSource<String> dataStreamSource = env.fromCollection(listData);//=================5.数据简单处理======================SingleOutputStreamOperator<String> flatMap = dataStreamSource.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String record, Collector<String> collector) throws Exception {logger.info("正在处理kafka数据:{}", record);collector.collect(record);}});//数据输出算子flatMap.sinkTo(sink);//=================6.启动服务=========================================//开启flink的checkpoint功能:每隔1000ms启动一个检查点(设置checkpoint的声明周期)env.enableCheckpointing(1000);//checkpoint高级选项设置//设置checkpoint的模式为exactly-once(这也是默认值)env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);//确保检查点之间至少有500ms间隔(即checkpoint的最小间隔)env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);//确保检查必须在1min之内完成,否则就会被丢弃掉(即checkpoint的超时时间)env.getCheckpointConfig().setCheckpointTimeout(60000);//同一时间只允许操作一个检查点env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);//程序即使被cancel后,也会保留checkpoint数据,以便根据实际需要恢复到指定的checkpointenv.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);//设置statebackend,指定state和checkpoint的数据存储位置(checkpoint的数据必须得有一个可以持久化存储的地方)env.getCheckpointConfig().setCheckpointStorage("file:///E:/flink/checkPoint");env.execute();}}相关文章:
【极数系列】Flink集成KafkaSink 实时输出数据(11)
文章目录 01 引言02 连接器依赖2.1 kafka连接器依赖2.2 base基础依赖 03 使用方法04 序列化器05 指标监控06 项目源码实战6.1 包结构6.2 pom.xml依赖6.3 配置文件6.4 创建sink作业 01 引言 KafkaSink 可将数据流写入一个或多个 Kafka topic 实战源码地址,一键下载可用…...

我为什么选择Xamarin开发ios app安卓app
临岁之寒简书作者,转载 Xamarin是一项跨平台开发技术,之前是收费的,而且据说收费不菲,所以使用的人数比较少,在国内几乎无人问津。后来Xamarin被微软收购,现已免费开放,相信今后国内的使用人群会大幅地增长…...

安全基础~通用漏洞4
文章目录 知识补充XSS跨站脚本**原理****攻击类型**XSS-后台植入Cookie&表单劫持XSS-Flash钓鱼配合MSF捆绑上线ctfshow XSS靶场练习 知识补充 SQL注入小迪讲解 文件上传小迪讲解 文件上传中间件解析 XSS跨站脚本 xss平台: https://xss.pt/ 原理 恶意攻击者…...

2024/2/12 图的基础知识 2
目录 查找文献 P5318 【深基18.例3】查找文献 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 有向图的拓扑序列 848. 有向图的拓扑序列 - AcWing题库 最大食物链计数 P4017 最大食物链计数 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 查找文献 P5318 【深基18.例3】…...

无人机飞行原理,多旋翼无人机飞行原理详解
多旋翼无人机升空飞行的首要条件是动力,有了动力才能驱动旋粪旋转,才能产生克服重力所必需的升力。使旋翼产生升力,进而推动多旋翼无人机升空飞行的一套设备装置称为动力装置,包括多旋翼无人机的发动机以及保证发动机正常工作所必…...
docker本地目录挂载
小命令 1、查看容器详情 docker inspect 容器名称 还是以nginx为例,上篇文章我们制作了nginx静态目录的数据卷,此时查看nginx容器时会展示出来(docker inspect nginx 展示信息太多,这里只截图数据卷挂载信息)&#…...
使用C++从零开始,自己写一个MiniWeb
第一步:新建项目 1、打开VS点击创建新项目 2、选择空项目并点下一步(切记不能选错项目类型) 3、填写项目名称和路径,点击创建即可 新建好后项目是这样的比较干净 4、右击源文件,点击添加,新建http.cpp文件…...

Android Graphics 图像显示系统 - 开篇
“ 随着学习的不断深入和工作经验的积累,欲将之前在博客中整理的Android Graphics知识做进一步整理,并纠正一些理解上的错误,故开设Graphics主题系列文章 ” 序言 由于工作需要,也源于个人兴趣,终于下决心花时间整理一…...

机器学习在各个行业的应用介绍
随着科技的飞速发展,机器学习已经从实验室走向了现实世界,逐渐成为各行各业不可或缺的工具。从金融领域到医疗健康,从零售市场到制造业,机器学习正在改变着我们的工作方式和生活质量。 本文将深入探讨机器学习在以下几个领域的应用…...

【生产实测有效】Windows命令行查看激活状态脚本
Windows查看激活状态关键代码 通过windows server 自带的PowerShell来执行 Get-WmiObject SoftwareLicensingProduct | Select-Object -Property Description, LicenseStatus | findstr "Operating System"|findstr "1$"Get-WmiObject SoftwareLicensingPr…...

简单的Udp服务器
目录 简单的UDP网络程序1.1 UdpServer.hpp1.2 UdpClient.cc1.3 main.cc1.4 makefile1.5 log.hpp 简单的UDP网络程序 1.1 UdpServer.hpp #pragma once#include <iostream> using namespace std;#include <unistd.h> #include <sys/types.h> #include <sy…...

【Linux进程间通信】用管道实现简单的进程池、命名管道
【Linux进程间通信】用管道实现简单的进程池、命名管道 目录 【Linux进程间通信】用管道实现简单的进程池、命名管道为什么要实现进程池?代码实现命名管道创建一个命名管道 理解命名管道匿名管道与命名管道的区别命名管道的打开规则 作者:爱写代码的刚子…...
Linux操作系统基础(九):Linux用户与权限
文章目录 Linux用户与权限 一、文件权限概述 二、终端命令:组管理 三、终端命令:用户管理 1、创建用户 、 设置密码 、删除用户 2、查看用户信息 3、su切换用户 4、sudo 4.1、给指定用户授予权限 4.2、使用 用户 zhangsan登录, 操作管理员命令…...

蓝桥杯——第 5 场 小白入门赛(c++详解!!!)
文章目录 1 十二生肖基本思路: 2 欢迎参加福建省大学生程序设计竞赛基本思路:代码: 3 匹配二元组的数量基本思路:代码: 4 元素交换基本思路:代码: 5 下棋的贝贝基本思路:代码: 6 方程…...

Codeforces Round 303 (Div. 2)C. Kefa and Park(DFS、实现)
文章目录 题面链接题意题解代码总结 题面 链接 C. Kefa and Park 题意 求叶节点数量,叶节点满足,从根节点到叶节点的路径上最长连续1的长度小于m 题解 这道题目主要是实现,当不满足条件时直接返回。 到达叶节点后统计答案,用…...

797. 差分
Problem: 797. 差分 文章目录 思路解题方法复杂度Code 思路 这是一个差分数组的问题。差分数组的主要适用场景是频繁对原始数组的某一个区间进行增减操作。这种操作是区间修改操作,在这种操作下,差分数组只需要对区间的两个端点进行操作,时间…...
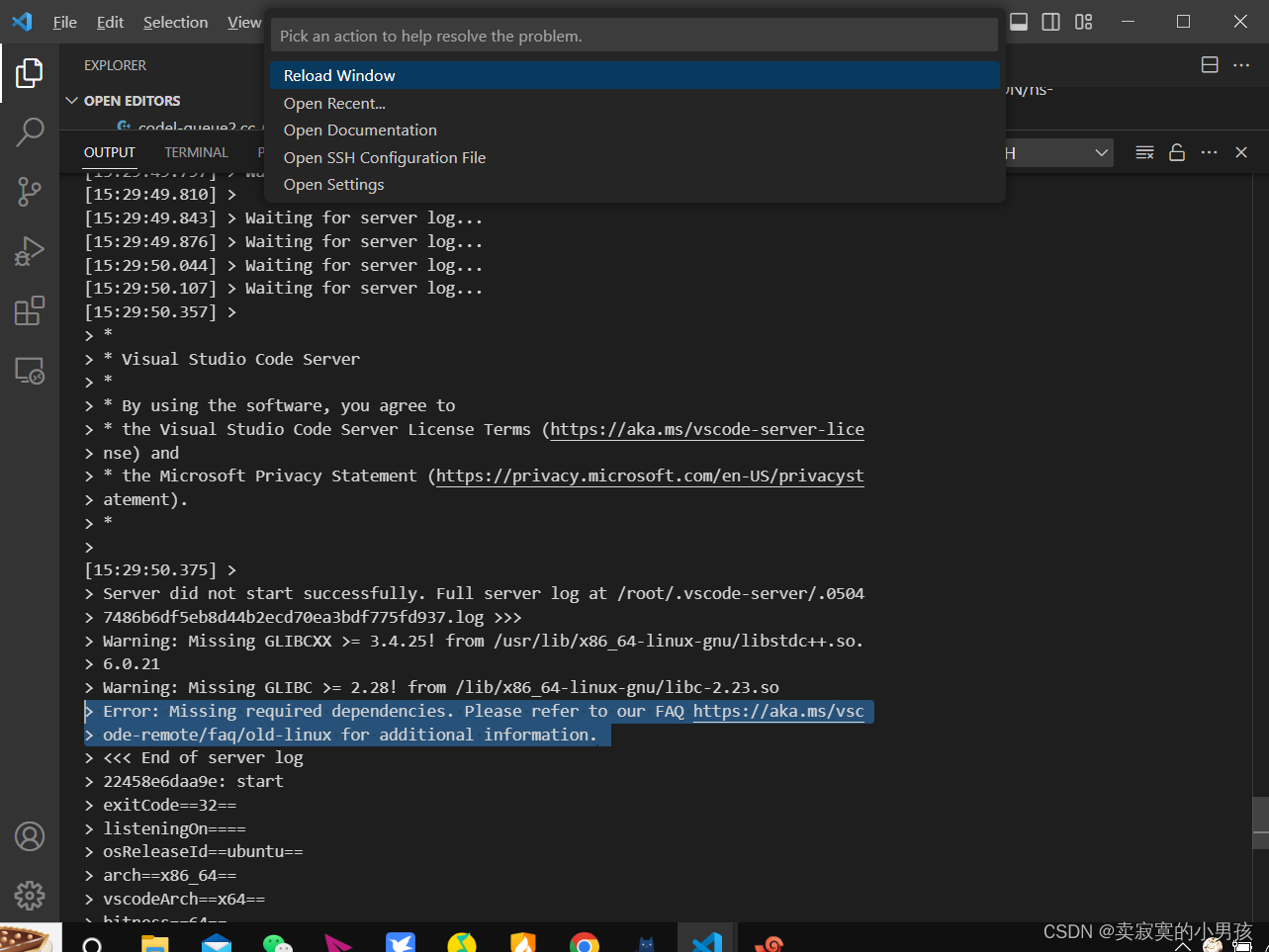
2024.2.5 vscode连不上虚拟机,始终waiting for server log
昨天还好好的,吃着火锅,做着毕设,突然就被vscode给劫了。 起初,哥们跟着网上教程有模有样地删除了安装包缓存,还删除了.vscode-server,发现没卵用,之前都是搜那个弹窗报错。 后来发现原来是vsco…...

CSS基础---新手入门级详解
CSS:层叠样式表 CSS(Cascading Style Sheets,层叠样式表),是一种用来为结构化文档添加样式(字体、间距和颜色)的计算机语言,css扩展名为.css。 实例: <!DOCTYPE html><html> <head><…...

Python中Pymysql库的常见用法和代码示例
关注B站可以观看更多实战教学视频:肆十二-的个人空间-肆十二-个人主页-哔哩哔哩视频 (bilibili.com) pymysql是一个用于连接MySQL数据库的Python库,它允许你执行SQL查询并处理返回的结果。以下是pymysql库的一些常见用法和代码示例: 1. 安装…...
使用 WPF + Chrome 内核实现高稳定性的在线客服系统复合应用程序
对于在线客服与营销系统,客服端指的是后台提供服务的客服或营销人员,他们使用客服程序在后台观察网站的被访情况,开展营销活动或提供客户服务。在本篇文章中,我将详细介绍如何通过 WPF Chrome 内核的方式实现复合客服端应用程序。…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

日常一水C
多态 言简意赅:就是一个对象面对同一事件时做出的不同反应 而之前的继承中说过,当子类和父类的函数名相同时,会隐藏父类的同名函数转而调用子类的同名函数,如果要调用父类的同名函数,那么就需要对父类进行引用&#…...

c# 局部函数 定义、功能与示例
C# 局部函数:定义、功能与示例 1. 定义与功能 局部函数(Local Function)是嵌套在另一个方法内部的私有方法,仅在包含它的方法内可见。 • 作用:封装仅用于当前方法的逻辑,避免污染类作用域,提升…...

【FTP】ftp文件传输会丢包吗?批量几百个文件传输,有一些文件没有传输完整,如何解决?
FTP(File Transfer Protocol)本身是一个基于 TCP 的协议,理论上不会丢包。但 FTP 文件传输过程中仍可能出现文件不完整、丢失或损坏的情况,主要原因包括: ✅ 一、FTP传输可能“丢包”或文件不完整的原因 原因描述网络…...
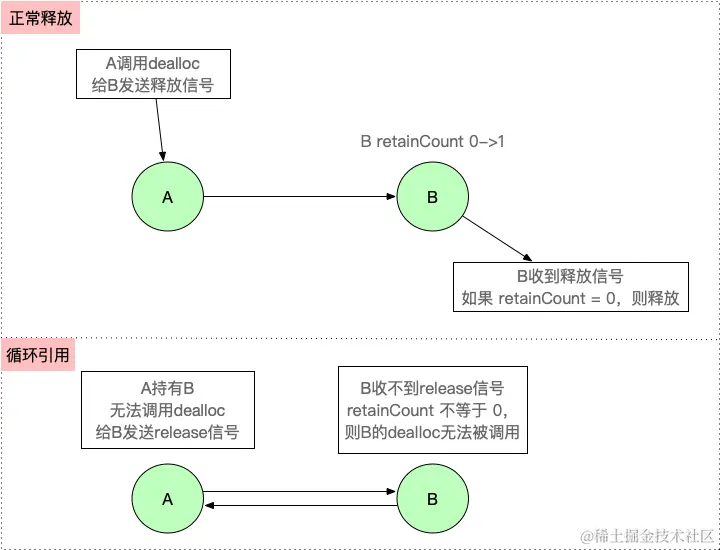
【iOS】 Block再学习
iOS Block再学习 文章目录 iOS Block再学习前言Block的三种类型__ NSGlobalBlock____ NSMallocBlock____ NSStackBlock__小结 Block底层分析Block的结构捕获自由变量捕获全局(静态)变量捕获静态变量__block修饰符forwarding指针 Block的copy时机block作为函数返回值将block赋给…...