MongoDB聚合:$geoNear
$geoNear根据指定的点按照距离以由近到远的顺序输出文档。
从4.2版本开始,MongoDB移除了limit和num选项以及100个文档的限制,如果要限制结果文档的数量可以使用$limit阶段。
语法
{ $geoNear: { <geoNear options> } }
$geoNear操作接受一个包含了下面选项字段的文档。使用与已处理文档坐标系相同的单位指定所有距离:
|字段|类型|描述|
|-|-|
|distanceField|string|包含计算距离的输出字段,要指定内嵌文档字段可以使用点号.|
|distanceMultiplier|number|可选,查询返回的所有距离的乘数。例如,使用distanceMultiplier将球面查询返回的弧度乘以地球半径转换为公里|
|includeLocs|string|可选,指定识别位置的输出字段,用于计算距离。当位置字段包含多个位置时,该选项非常有用。要指定嵌入文档中的字段,可使用点符号.|
|key||可选,指定用于计算距离的地理空间索引字段。如果集合有多个2d或(且)2dsphere索引,就必须要使用key选项来指定要使用的索引字段路径。如果集合有超过一个的2d索引或2dsphere索引,而且没有指定一个给key,MongoDB将返回错误。如果没有指定key,而且集合只有一个2d索引或(且)2dsphere索引,MongoDB会找到第一个2d索引来使用,如果2d索引不存在,则会去找2dsphere索引来使用|
|maxDistance|number|可选,文档与中心点的最大距离。MongoDB 会将结果限制在与中心点的距离在指定范围内的文档。如果指定点是GeoJSON,则以米为单位指定距离;如果指定点是legacy坐标对,则以弧度为单位指定距离|
|near|GeoJSON点或legacy坐标对|查找最接近文件的点。如果使用2dsphere索引,可以使用GeoJSON点或legacy坐标对来指定点。如果使用2d索引,则要使用legacy坐标对来指定|
|query|document|可选,将结果限制为与查询匹配的文档。查询语法为常规MongoDB读操作查询语法。不能在$geoNear阶段的查询字段中指定$near谓词|
|spherical|boolean|可选,缺省为fasle,决定MongoDB如何计算两点间的距离。当为true是,MongoDB使用$nearSphere语义并且使用球形几何体计算距离。当为false时MongoDB 使用$near语义:球形几何用于2dsphere索引,平面几何用于2d索引|
使用
当使用$geoNear时需要考虑下面的情况:
$geoNear只能用于管道的第一个阶段。- 必须包含
distanceField选项,distanceField选项指定了包含距离计算的字段。 $geoNear需要一个地理空间索引。如果集合上有多个地理空间索引,需要使用keys参数指定一下计算时要使用的索引,如果只有一个地理空间索引,可以不指定keys参数,$geoNear会隐式使用索引字段进行计算。$geoNear阶段不可以在query字段中使用$near。- 从版本4.2开始,
$geoNear默认情况下不再限制100个文档。 - 从版本4.1开始,
near参数支持let选项和绑定let选项。 - 从版本5.3开始,可以在时间序列集合的任何字段上使用
$geoNear管道运算符。 - 从版本6.0开始,可以在时间序列集合的任何字段上创建partial和2dsphere索引。
举例
给places插入下面的数据:
db.places.insertMany( [{name: "Central Park",location: { type: "Point", coordinates: [ -73.97, 40.77 ] },category: "Parks"},{name: "Sara D. Roosevelt Park",location: { type: "Point", coordinates: [ -73.9928, 40.7193 ] },category: "Parks"},{name: "Polo Grounds",location: { type: "Point", coordinates: [ -73.9375, 40.8303 ] },category: "Stadiums"}
] )
下面的操作为location字段创建一个2dsphere索引:
db.places.createIndex( { location: "2dsphere" } )
最大距离
上面的places集合有一个2dsphere索引,下面的聚合使用$geoNear查找位置距离中心点[ -73.99279 , 40.719296 ]最多2米距离且category等于Parks的文档。
db.places.aggregate([{$geoNear: {near: { type: "Point", coordinates: [ -73.99279 , 40.719296 ] },distanceField: "dist.calculated",maxDistance: 2,query: { category: "Parks" },includeLocs: "dist.location",spherical: true}}
])
聚合返回下面的结果:
{"_id" : 8,"name" : "Sara D. Roosevelt Park","category" : "Parks","location" : {"type" : "Point","coordinates" : [ -73.9928, 40.7193 ]},"dist" : {"calculated" : 0.9539931676365992,"location" : {"type" : "Point","coordinates" : [ -73.9928, 40.7193 ]}}
}
匹配的文档包含两个新字段:
dist.calculated字段,包含了计算后的距离dist.location字段,包含了用于计算的位置
最小距离
下面的示例使用minDistance选项来指定文档与中心点的最小距离。下面的聚合查找所有位置距离中心点[ -73.99279 , 40.719296 ]至少2米距离且category等于Parks的文档。
db.places.aggregate([{$geoNear: {near: { type: "Point", coordinates: [ -73.99279 , 40.719296 ] },distanceField: "dist.calculated",minDistance: 2,query: { category: "Parks" },includeLocs: "dist.location",spherical: true}}
])
使用let选项
在下面的例子中:
let选项用于将数组[-73.99279,40.719296]的值设置给变量$pt。pt被指定为near参数的let选项。
db.places.aggregate(
[{"$geoNear":{"near":"$$pt","distanceField":"distance","maxDistance":2,"query":{"category":"Parks"},"includeLocs":"dist.location","spherical":true}}
],
{"let":{ "pt": [ -73.99279, 40.719296 ] }
}
)
聚合返回符合下面条件的所有文档:
- 距离
let变量指定的点至少2米距离 category等于Parks
{_id: ObjectId("61715cf9b0c1d171bb498fd7"),name: 'Sara D. Roosevelt Park',location: { type: 'Point', coordinates: [ -73.9928, 40.7193 ] },category: 'Parks',distance: 1.4957325341976439e-7,dist: { location: { type: 'Point', coordinates: [ -73.9928, 40.7193 ] } }
},
{_id: ObjectId("61715cf9b0c1d171bb498fd6"),name: 'Central Park',location: { type: 'Point', coordinates: [ -73.97, 40.77 ] },category: 'Parks',distance: 0.0009348548688841822,dist: { location: { type: 'Point', coordinates: [ -73.97, 40.77 ] } }
}
使用绑定let选项
let选项可以绑定一个变量用于$geoNear查询。
在下面的例子中,$lookup:
- 使用
let定义$pt。 - 在
pipeline使用$geoNear阶段。 - 在
$geoNear阶段用pt定义near。
db.places.aggregate( [{$lookup: {from: "places",let: { pt: "$location" },pipeline: [{$geoNear: {near: "$$pt",distanceField: "distance"}}],as: "joinedField"}},{$match: { name: "Sara D. Roosevelt Park" }}
] );
聚合返回的结果中:
Sara D. Roosevelt Park文档作为主文档。- 将地点集合中的每个文档作为子文档,使用
$pt变量计算距离。
{_id: ObjectId("61715cf9b0c1d171bb498fd7"),name: 'Sara D. Roosevelt Park',location: { type: 'Point', coordinates: [ -73.9928, 40.7193 ] },category: 'Parks',joinedField: [{_id: ObjectId("61715cf9b0c1d171bb498fd7"),name: 'Sara D. Roosevelt Park',location: { type: 'Point', coordinates: [ -73.9928, 40.7193 ] },category: 'Parks',distance: 0},{_id: ObjectId("61715cf9b0c1d171bb498fd6"),name: 'Central Park',location: { type: 'Point', coordinates: [ -73.97, 40.77 ] },category: 'Parks',distance: 5962.448255234964},{_id: ObjectId("61715cfab0c1d171bb498fd8"),name: 'Polo Grounds',location: { type: 'Point', coordinates: [ -73.9375, 40.8303 ] },category: 'Stadiums',distance: 13206.535424939102}]
}
指定地理空间索引
假定有一个places集合,该集合的location字段上有一个2dsphere索引,legacy字段上有一个2d索引。
places集合中的文档类似这个:
{"_id" : 3,"name" : "Polo Grounds","location": {"type" : "Point","coordinates" : [ -73.9375, 40.8303 ]},"legacy" : [ -73.9375, 40.8303 ],"category" : "Stadiums"
}
下面的例子使用key选项,为$geoNear聚合操作指定使用location字段的值而不是使用legacy字段的值。聚合管道同事使用$limit返回最多5个文档。
db.places.aggregate([{$geoNear: {near: { type: "Point", coordinates: [ -73.98142 , 40.71782 ] },key: "location",distanceField: "dist.calculated",query: { "category": "Parks" }}},{ $limit: 5 }
])
聚合返回下面的结果:
{"_id" : 8,"name" : "Sara D. Roosevelt Park","location" : {"type" : "Point","coordinates" : [-73.9928,40.7193]},"category" : "Parks","dist" : {"calculated" : 974.175764916902}
}
{"_id" : 1,"name" : "Central Park","location" : {"type" : "Point","coordinates" : [-73.97,40.77]},"legacy" : [-73.97,40.77],"category" : "Parks","dist" : {"calculated" : 5887.92792958097}
}
相关文章:

MongoDB聚合:$geoNear
$geoNear根据指定的点按照距离以由近到远的顺序输出文档。 从4.2版本开始,MongoDB移除了limit和num选项以及100个文档的限制,如果要限制结果文档的数量可以使用$limit阶段。 语法 { $geoNear: { <geoNear options> } }$geoNear操作接受一个包含…...

Docker-CE 国内源国内镜像
Docker-CE 就是 Docker Community Edition 的意思 docker-ce由docker官方维护 , docker.io由Debian维护 Docker官文 – Install Docker Engine on CentOS Docker官文 – Install Docker Engine on Fedora Docker官文 – Install Docker Engine on Debian Docker官文 – In…...
【Tauri】(3):使用Tauri1.5版本,进行桌面应用开发,在windows上搭建环境,安装node,rust环境,可以打包成功,使用vite创建应用
1,视频地址: https://www.bilibili.com/video/BV1Ny421a7nA/ 【Tauri】(3):使用Tauri1.5版本,进行桌面应用开发,在windows上搭建环境,安装node,rust环境,可以…...

C++ 堆排序
C 堆排序 堆排序是一种基于二叉堆数据结构的排序算法,其原理如下: 构建最大堆:将待排序的数组看作一个完全二叉树,并通过调整节点的位置构建一个最大堆。最大堆满足每个父节点的值都大于或等于其子节点的值。构建最大堆的过程可以…...
U3D记录之FBX纹理丢失问题
今天费老大劲从blender建了个模型,然后导出进去unity 发现贴图丢失 上网查了一下 首先blender导出要改设置 这个path mode要copy 然后unity加载纹理也要改设置 这里这个模型的纹理load要改成external那个模式 然后就有了,另外这个导出还有好多选项可…...

监测Nginx访问日志502情况后并做相应动作
今天带大家写一个比较实用的脚本哈 原理: 假设服务器环境为lnmp,近期访问经常出现502现象,且502错误在重启php-fpm服务后消失,因此需要编写监控脚本,一旦出现502,则自动重启php-fpm服务 场景: 1…...

【数据分享】1929-2023年全球站点的逐年平均风速(Shp\Excel\免费获取)
气象数据是在各项研究中都经常使用的数据,气象指标包括气温、风速、降水、能见度等指标,说到气象数据,最详细的气象数据是具体到气象监测站点的数据! 有关气象指标的监测站点数据,之前我们分享过1929-2023年全球气象站…...

Android性能调优 - 应用安全问题
Android应用安全 1.组件暴露: 像比如ContentProvider,BroadcastReceiver,Activity等组件有android:exported属性; 如果是私有组件 android:exported “false”; 如果是公有组件 android:exported “true” 且进行权限控制&…...
等常见的方法)
C#的Char 结构的像IsLetterOrDigit(Char)等常见的方法
目录 一、Char 结构的方法 二、Char.IsLetterOrDigit 方法 1.Char.IsLetterOrDigit(Char)用法 2.IsLetterOrDigit(String, Int32)方法 三、Char.IsLetter 方法 1.IsLetter(Char) 2.IsLetter(String, Int32) 四、Char.IsDigit 方法 1. IsDigit(String, Int32) 2.IsDig…...
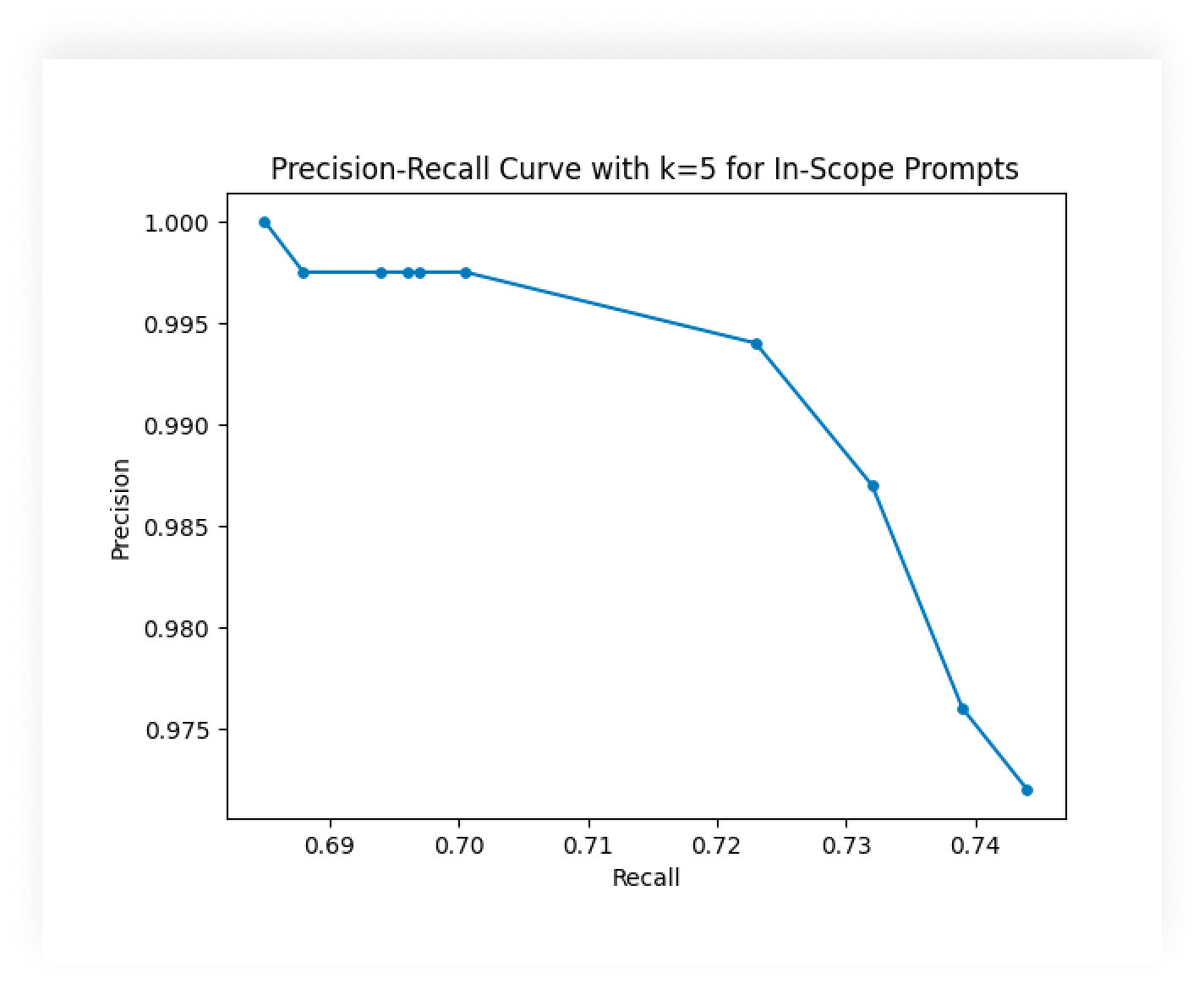
部分意图分类【LLM+RAG】
在生成人工智能领域工作最有价值的事情之一就是发现新兴技术如何融入新的解决方案。 举个例子:在为北美顶级金融服务公司之一设计对话式人工智能助手时,WillowTree 的数据和人工智能研究团队 (DART) 发现,将意图分类与大型语言模型 (LLM) 结合…...

1277. 统计全为 1 的正方形子矩阵
1277. 统计全为 1 的正方形子矩阵 题目链接:1277. 统计全为 1 的正方形子矩阵 代码如下: class Solution { public:int countSquares(vector<vector<int>>& matrix) {if(matrix.size()0||matrix[0].size()0) return 0;//dp[i][j]代表…...

Python 3 时间序列可视化指南
简介 时间序列分析属于统计学的一个分支,涉及对有序的、通常是时间性的数据进行研究。当适当应用时,时间序列分析可以揭示意想不到的趋势,提取有用的统计数据,甚至预测未来的趋势。因此,它被应用于许多领域࿰…...

[算法前沿]--059-大语言模型Fine-tuning踩坑经验之谈
前言 由于 ChatGPT 和 GPT4 兴起,如何让人人都用上这种大模型,是目前 AI 领域最活跃的事情。当下开源的 LLM(Large language model)非常多,可谓是百模大战。面对诸多开源本地模型,根据自己的需求,选择适合自己的基座模型和参数量很重要。选择完后需要对训练数据进行预处…...

【Docker】01 Docker安装与配置
文章目录 一、Docker二、离线安装Docker三、联网安装Docker3.1 下载YUM软件库文件3.2 安装epel-release3.3 安装yum-utils3.4 设置镜像仓库3.5 查看docker-ce所有版本3.6 安装Docker3.7 启动Docker3.8 查看Docker信息3.9 启动第一个容器 四、一些配置4.1 登录DockerHub4.2 镜像…...

Unity3d Shader篇(六)— BlinnPhong高光反射着色器
文章目录 前言一、BlinnPhong高光反射着色器是什么?1. BlinnPhong高光反射着色器的工作原理2. BlinnPhong高光反射着色器的优缺点优点缺点 3. 公式 二、使用步骤1. Shader 属性定义2. SubShader 设置3. 渲染 Pass4. 定义结构体和顶点着色器函数5. 片元着色器函数 三…...
定时任务的选择调研)
Go-zero微服务个人探究之路(十二)定时任务的选择调研
前言 很多时候后台需要做定时任务的需求,笔者的项目采用go-zero框架微服务框架,需要做定时任务,于是做了如下方法调研,共有大概三种主要选择 方案 难度总体由容易到复杂 go的timer库 通过Go的标准库time中的Ticker和Tick功能…...

Java中,List、Map和Set的区别是什么?
在Java中,List、Map和Set是三种常用的集合类型,它们之间的主要区别如下: 1、List List是有序集合,它可以包含重复元素。 List中的元素是按照插入顺序排列的,可以通过索引访问每个元素。 Java中常见的List实现类有A…...
Google刚刚推出了图神经网络Tensorflow-GNN
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
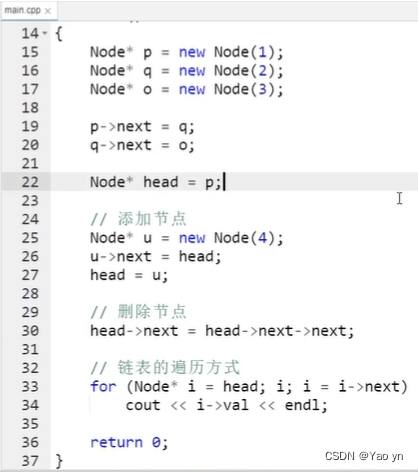
链表基础知识汇总
链表 链表是一种基本的数据结构,是由一系列节点组成的集合。每个节点包含两个部分:值和指向下一个节点的指针。链表中的节点可以动态地添加、删除,其大小可以根据需要进行扩展或缩小。 链表通常用于处理不固定长度的数据结构,具有…...
)
Educational Codeforces Round 2(远古edu计划)
A. 恶心模拟。。 模拟一下分类即可 数字类,数字0,或者都是数字 字母类,字母空的也是字母,有字母就是字母 #include<bits/stdc.h> #define INF 1e9 using namespace std; typedef long long ll; const int N2e59; strin…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

PHP 8.5 即将发布:管道操作符、强力调试
前不久,PHP宣布了即将在 2025 年 11 月 20 日 正式发布的 PHP 8.5!作为 PHP 语言的又一次重要迭代,PHP 8.5 承诺带来一系列旨在提升代码可读性、健壮性以及开发者效率的改进。而更令人兴奋的是,借助强大的本地开发环境 ServBay&am…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...

小木的算法日记-多叉树的递归/层序遍历
🌲 从二叉树到森林:一文彻底搞懂多叉树遍历的艺术 🚀 引言 你好,未来的算法大神! 在数据结构的世界里,“树”无疑是最核心、最迷人的概念之一。我们中的大多数人都是从 二叉树 开始入门的,它…...