使用 Chainlit, Langchain 及 Elasticsearch 轻松实现对 PDF 文件的查询

在我之前的文章 “Elasticsearch:与多个 PDF 聊天 | LangChain Python 应用教程(免费 LLMs 和嵌入)” 里,我详述如何使用 Streamlit,Langchain, Elasticsearch 及 OpenAI 来针对 PDF 进行聊天。在今天的文章中,我将使用 Chainlit 来展示如使用 Langchain 及 Elasticsearch 针对 PDF 文件进行查询。
为方便大家学习,我的代码在地址 GitHub - liu-xiao-guo/langchain-openai-chainlit: Chat with your documents (pdf, csv, text) using Openai model, LangChain and Chainlit 进行下载。
安装
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请选择 Elastic Stack 8.x 进行安装。在安装的时候,我们可以看到如下的安装信息:

拷贝 Elasticsearch 证书
我们把 Elasticsearch 的证书拷贝到当前的目录下:
$ pwd
/Users/liuxg/python/elser
$ cp ~/elastic/elasticsearch-8.12.0/config/certs/http_ca.crt .
$ ls http_ca.crt
http_ca.crt安装 Python 依赖包
我们在当前的目录下打入如下的命令:
python3 -m venv .venv
source .venv/bin/activate然后,我们再打入如下的命令:
$ pwd
/Users/liuxg/python/langchain-openai-chainlit
$ source .venv/bin/activate
(.venv) $ pip3 install -r requirements.txt运行应用
有关 Chainlit 的更多知识请参考 Overview - Chainlit。这里就不再赘述。有关 pdf_qa.py 的代码如下:
pdf_qa.py
# Import necessary modules and define env variables# from langchain.embeddings.openai import OpenAIEmbeddings
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQAWithSourcesChain
from langchain_openai import ChatOpenAI
from langchain.prompts.chat import (ChatPromptTemplate,SystemMessagePromptTemplate,HumanMessagePromptTemplate,
)
import os
import io
import chainlit as cl
import PyPDF2
from io import BytesIOfrom pprint import pprint
import inspect
# from langchain.vectorstores import ElasticsearchStore
from langchain_community.vectorstores import ElasticsearchStore
from elasticsearch import Elasticsearchfrom dotenv import load_dotenv# Load environment variables from .env file
load_dotenv()OPENAI_API_KEY= os.getenv("OPENAI_API_KEY")
ES_USER = os.getenv("ES_USER")
ES_PASSWORD = os.getenv("ES_PASSWORD")
elastic_index_name='pdf_docs'# text_splitter and system templatetext_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)system_template = """Use the following pieces of context to answer the users question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
ALWAYS return a "SOURCES" part in your answer.
The "SOURCES" part should be a reference to the source of the document from which you got your answer.Example of your response should be:```
The answer is foo
SOURCES: xyz
```Begin!
----------------
{summaries}"""messages = [SystemMessagePromptTemplate.from_template(system_template),HumanMessagePromptTemplate.from_template("{question}"),
]
prompt = ChatPromptTemplate.from_messages(messages)
chain_type_kwargs = {"prompt": prompt}@cl.on_chat_start
async def on_chat_start():# Sending an image with the local file pathelements = [cl.Image(name="image1", display="inline", path="./robot.jpeg")]await cl.Message(content="Hello there, Welcome to AskAnyQuery related to Data!", elements=elements).send()files = None# Wait for the user to upload a PDF filewhile files is None:files = await cl.AskFileMessage(content="Please upload a PDF file to begin!",accept=["application/pdf"],max_size_mb=20,timeout=180,).send()file = files[0]# print("type: ", type(file))# print("file: ", file)# pprint(vars(file))# print(file.content)msg = cl.Message(content=f"Processing `{file.name}`...")await msg.send()# Read the PDF file# pdf_stream = BytesIO(file.content)with open(file.path, 'rb') as f:pdf_content = f.read()pdf_stream = BytesIO(pdf_content)pdf = PyPDF2.PdfReader(pdf_stream)pdf_text = ""for page in pdf.pages:pdf_text += page.extract_text()# Split the text into chunkstexts = text_splitter.split_text(pdf_text)# Create metadata for each chunkmetadatas = [{"source": f"{i}-pl"} for i in range(len(texts))]# Create a Chroma vector storeembeddings = OpenAIEmbeddings()url = f"https://{ES_USER}:{ES_PASSWORD}@localhost:9200"connection = Elasticsearch(hosts=[url], ca_certs = "./http_ca.crt", verify_certs = True)docsearch = Noneif not connection.indices.exists(index=elastic_index_name):print("The index does not exist, going to generate embeddings") docsearch = await cl.make_async(ElasticsearchStore.from_texts)( texts,embedding = embeddings, es_url = url, es_connection = connection,index_name = elastic_index_name, es_user = ES_USER,es_password = ES_PASSWORD,metadatas=metadatas)else: print("The index already existed")docsearch = ElasticsearchStore(es_connection=connection,embedding=embeddings,es_url = url, index_name = elastic_index_name, es_user = ES_USER,es_password = ES_PASSWORD )# Create a chain that uses the Chroma vector storechain = RetrievalQAWithSourcesChain.from_chain_type(ChatOpenAI(temperature=0),chain_type="stuff",retriever=docsearch.as_retriever(search_kwargs={"k": 4}),)# Save the metadata and texts in the user sessioncl.user_session.set("metadatas", metadatas)cl.user_session.set("texts", texts)# Let the user know that the system is readymsg.content = f"Processing `{file.name}` done. You can now ask questions!"await msg.update()cl.user_session.set("chain", chain)@cl.on_message
async def main(message:str):chain = cl.user_session.get("chain") # type: RetrievalQAWithSourcesChainprint("chain type: ", type(chain))cb = cl.AsyncLangchainCallbackHandler(stream_final_answer=True, answer_prefix_tokens=["FINAL", "ANSWER"])cb.answer_reached = Trueprint("message: ", message)pprint(vars(message))print(message.content)res = await chain.acall(message.content, callbacks=[cb])answer = res["answer"]sources = res["sources"].strip()source_elements = []# Get the metadata and texts from the user sessionmetadatas = cl.user_session.get("metadatas")all_sources = [m["source"] for m in metadatas]texts = cl.user_session.get("texts")print("texts: ", texts)if sources:found_sources = []# Add the sources to the messagefor source in sources.split(","):source_name = source.strip().replace(".", "")# Get the index of the sourcetry:index = all_sources.index(source_name)except ValueError:continuetext = texts[index]found_sources.append(source_name)# Create the text element referenced in the messagesource_elements.append(cl.Text(content=text, name=source_name))if found_sources:answer += f"\nSources: {', '.join(found_sources)}"else:answer += "\nNo sources found"if cb.has_streamed_final_answer:cb.final_stream.elements = source_elementsawait cb.final_stream.update()else:await cl.Message(content=answer, elements=source_elements).send()我们可以使用如下的命令来运行:
export ES_USER="elastic"
export ES_PASSWORD="xnLj56lTrH98Lf_6n76y"
export OPENAI_API_KEY="YourOpenAiKey"chainlit run pdf_qa.py -w(.venv) $ chainlit run pdf_qa.py -w
2024-02-14 10:58:30 - Loaded .env file
2024-02-14 10:58:33 - Your app is available at http://localhost:8000
2024-02-14 10:58:34 - Translation file for en not found. Using default translation en-US.
2024-02-14 10:58:35 - 2 changes detected我们先选择项目自带的 pdf 文件:
Is sample PDF download critical to an organization?
Does comprehensive PDF testing have various advantages?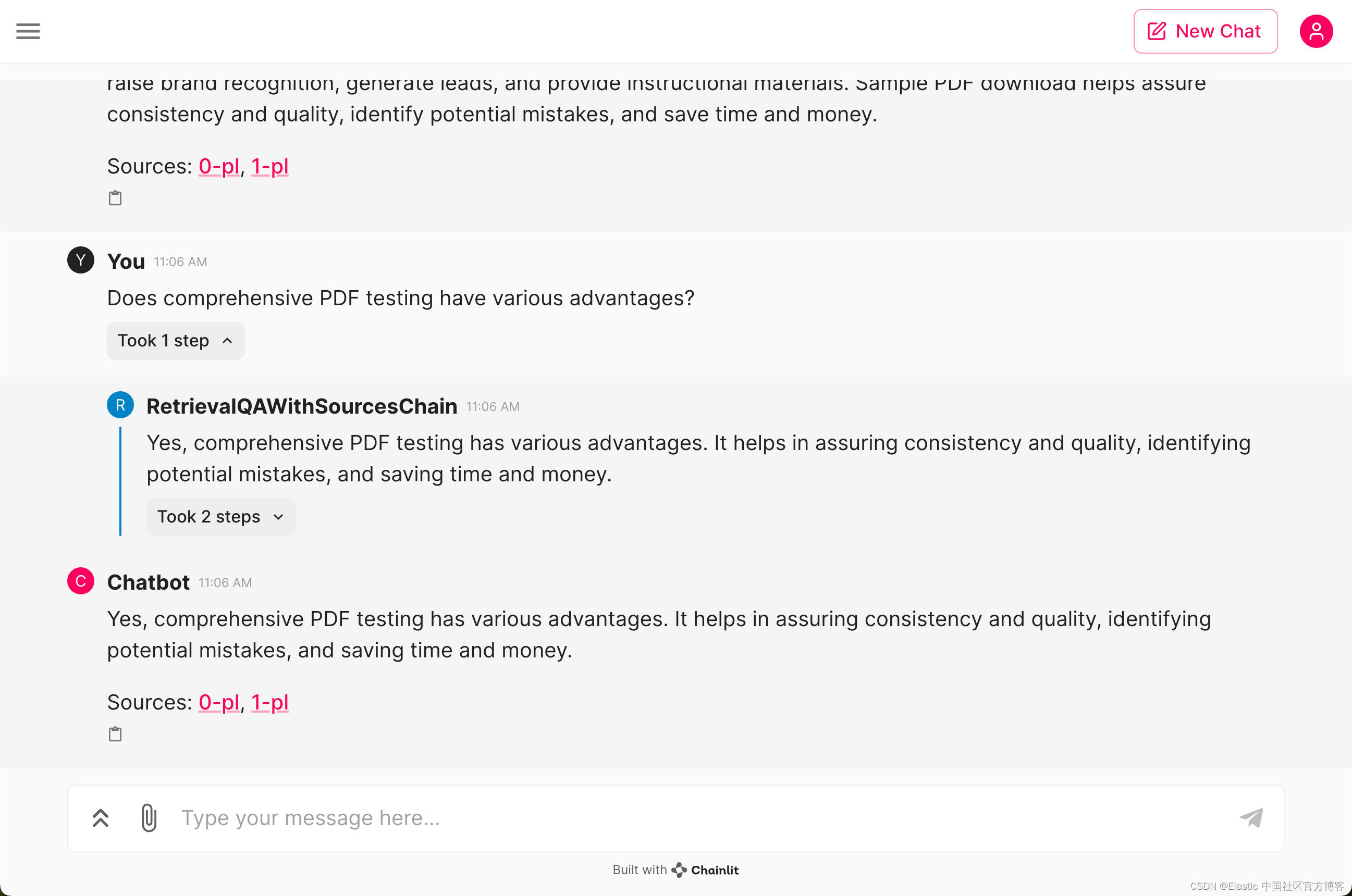
相关文章:
使用 Chainlit, Langchain 及 Elasticsearch 轻松实现对 PDF 文件的查询
在我之前的文章 “Elasticsearch:与多个 PDF 聊天 | LangChain Python 应用教程(免费 LLMs 和嵌入)” 里,我详述如何使用 Streamlit,Langchain, Elasticsearch 及 OpenAI 来针对 PDF 进行聊天。在今天的文章中…...
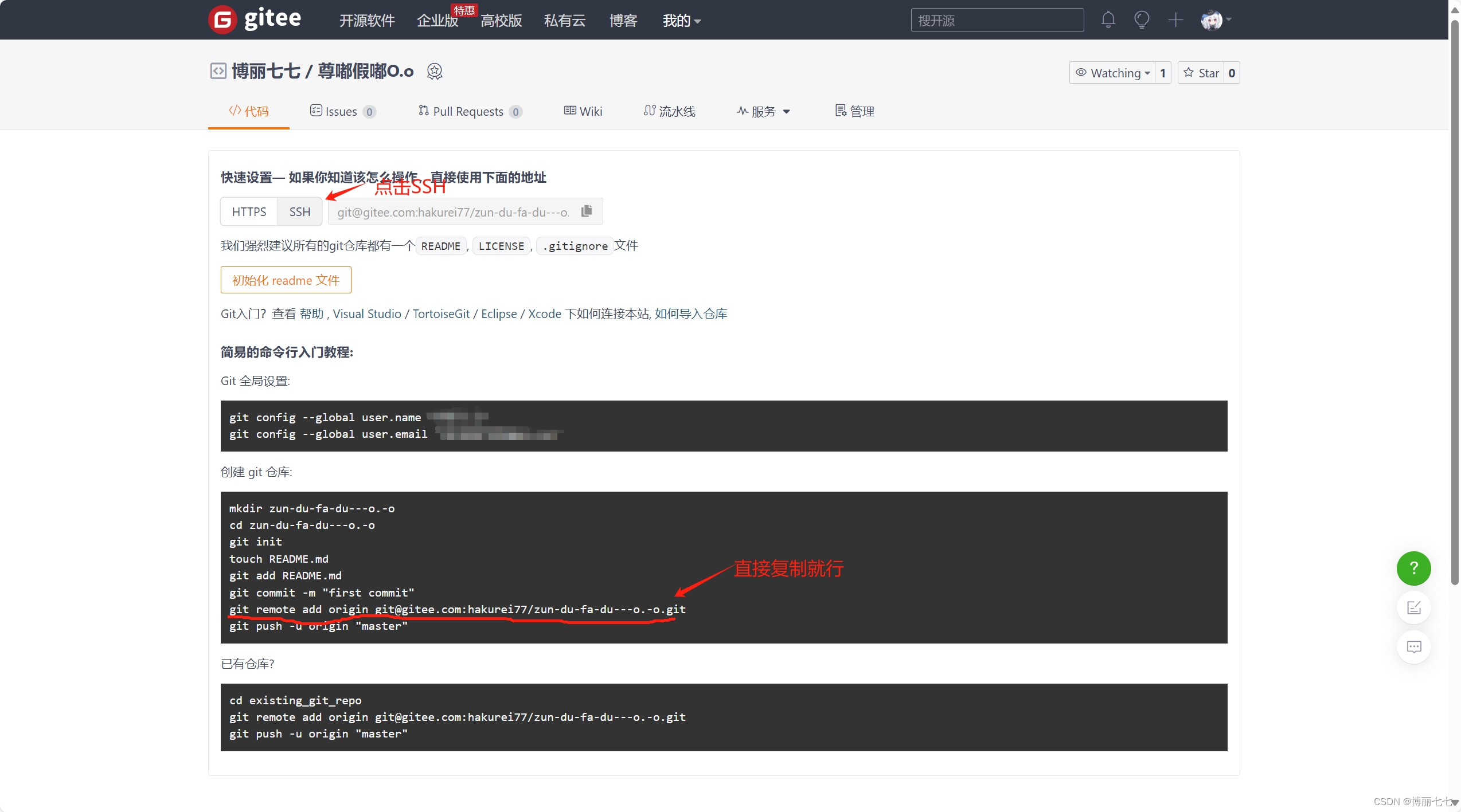
Gitee的使用教程(简单详细)
1.安装git(我的电脑自带git,我没弄这步QAQ) Git (git-scm.com)https://git-scm.com/ 安装好后在桌面点击鼠标右键会出现git GUI 和 git Bash(没有的话点击显示更多选项) 2.去gitee上注册一个账号 工作台 - Gitee.co…...

生成树(习题)
模板】最小生成树 生成树有两种方法,但是我只会克鲁斯卡尔算法,所以接下来下面的的题目都是按照这个算法来实现的,首先来见一下生么是这个算法,在之前的我写的一篇博客中有题使叫修复公路,其实这一题就是使用了这个算…...

ARMv8-AArch64 的异常处理模型详解之异常处理概述Handling exceptions
异常处理模型详解之异常处理概述 一,异常处理相关概念二,异常处理概述 一,异常处理相关概念 在介绍异常处理之前,有必要了解一些关于异常处理状态的术语: 当处理器响应一个异常时,我们称该异常被获取了&a…...

Ubuntu 18.04上安装cuDNN 8.9.6.50:一站式指南
Content 一、前言二、准备工作三、安装步骤1. 启用本地仓库2. 导入CUDA GPG密钥3. 更新仓库元数据4. 安装运行时库5. 安装开发者库6. 安装代码示例7. 另外一种安装办法 四、验证安装1. 验证cuDNN版本2. 测试示例代码 五、总结 一、前言 在深度学习领域,高效的计算资…...

Microsoft Word 超链接
Microsoft Word 超链接 1. 取消超链接2. 自动超链接2.1. 选项2.2. 校对 -> 自动更正选项2.3. Internet 及网络路径替换为超链接 References 1. 取消超链接 Ctrl A -> Ctrl Shift F9 2. 自动超链接 2.1. 选项 2.2. 校对 -> 自动更正选项 2.3. Internet…...

SparkJDBC读写数据库实战
默认的操作 代码val df = spark.read.format("jdbc").option("url", "jdbc:postgresql://localhost:5432/testdb").option("user", "username").option("password", "password").option("driver&q…...

代码随想录 -- 数组
文章目录 二分查找题目描述题解 移除元素题目描述题解:暴力解法题解:双指针法 有序数组的平方题目描述题解:暴力解法题解:双指针法 长度最小的子数组题目描述题解:暴力解法题解:滑动窗口(双指针…...

【国产MCU】-CH32V307-基本定时器(BCTM)
基本定时器(BCTM) 文章目录 基本定时器(BCTM)1、基本定时器(BCTM)介绍2、基本定时器驱动API介绍3、基本定时器使用实例CH32V307的基本定时器模块包含一个16 位可自动重装的定时器(TIM6和TIM7),用于计数和在更新新事件产生中断或DMA 请求。 本文将详细介绍如何使用CH32…...

Node.js开发-fs模块
这里写目录标题 fs模块1) 文件写入2) 文件写入3) 文件移动与重命名4) 文件删除5) 文件夹操作6) 查看资源状态7) 相对路径问题8) __dirname fs模块 fs模块可以实现与硬盘的交互,例如文件的创建、删除、重命名、移动等,还有文件内容的写入、读取ÿ…...

探索Nginx:强大的开源Web服务器与反向代理
一、引言 随着互联网的飞速发展,Web服务器在现代技术架构中扮演着至关重要的角色。Nginx(发音为“engine x”)是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP代理服务器。Nginx因其卓越的性能、稳定性和灵活性&…...
相机图像质量研究(4)常见问题总结:光学结构对成像的影响--焦距
系列文章目录 相机图像质量研究(1)Camera成像流程介绍 相机图像质量研究(2)ISP专用平台调优介绍 相机图像质量研究(3)图像质量测试介绍 相机图像质量研究(4)常见问题总结:光学结构对成像的影响--焦距 相机图像质量研究(5)常见问题总结:光学结构对成…...
【从Python基础到深度学习】1. Python PyCharm安装及激活
前言: 为了帮助大家快速入门机器学习-深度学习,从今天起我将用100天的时间将大学本科期间的所学所想分享给大家,和大家共同进步。【从Python基础到深度学习】系列博客中我将从python基础开始通过知识和代码实践结合的方式进行知识的分享和记…...
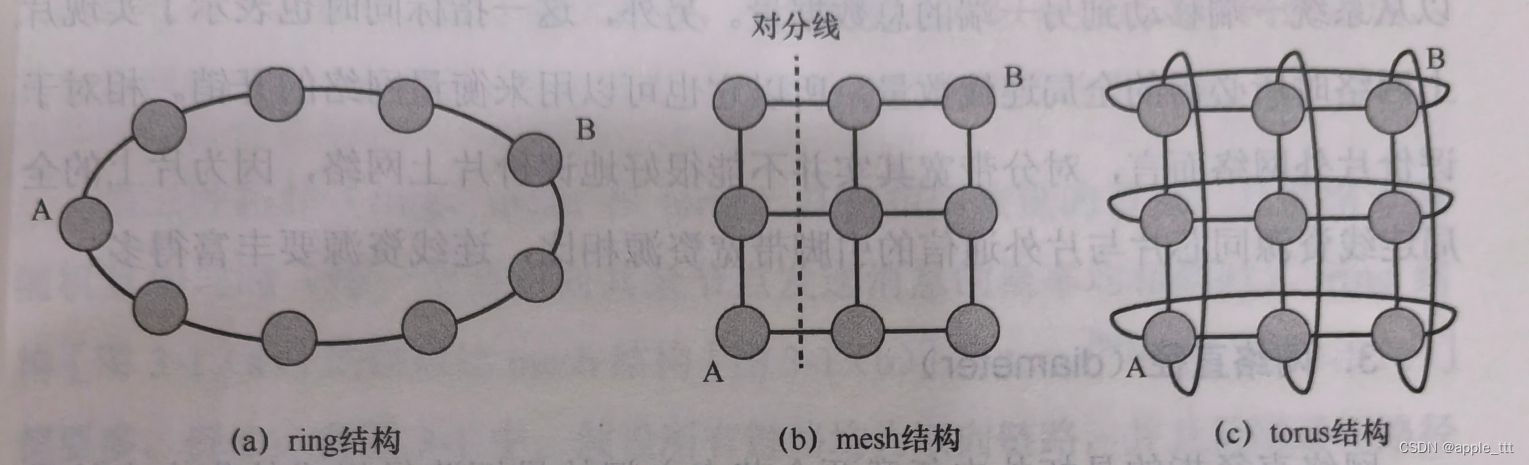
片上网络NoC(3)——拓扑指标
目录 一、概述 二、指标 2.1 与网络流量无关的指标 2.1.1 度(degree) 2.1.2 对分带宽(bisection bandwidth) 2.1.3 网络直径(diameter) 2.2 与网络流量相关的指标 2.2.1 跳数(hop coun…...

二叉树 ---- 所有结点数
普通二叉树的结点数: 递归法: 对二叉树进行前序or后序遍历: typedef struct Tree {int data;Tree* leftChild;Tree* rightChild; }tree,*linklist; //计算普通二叉树的结点数 int nodenums(linklist node) {if(node nullptr) return 0; …...
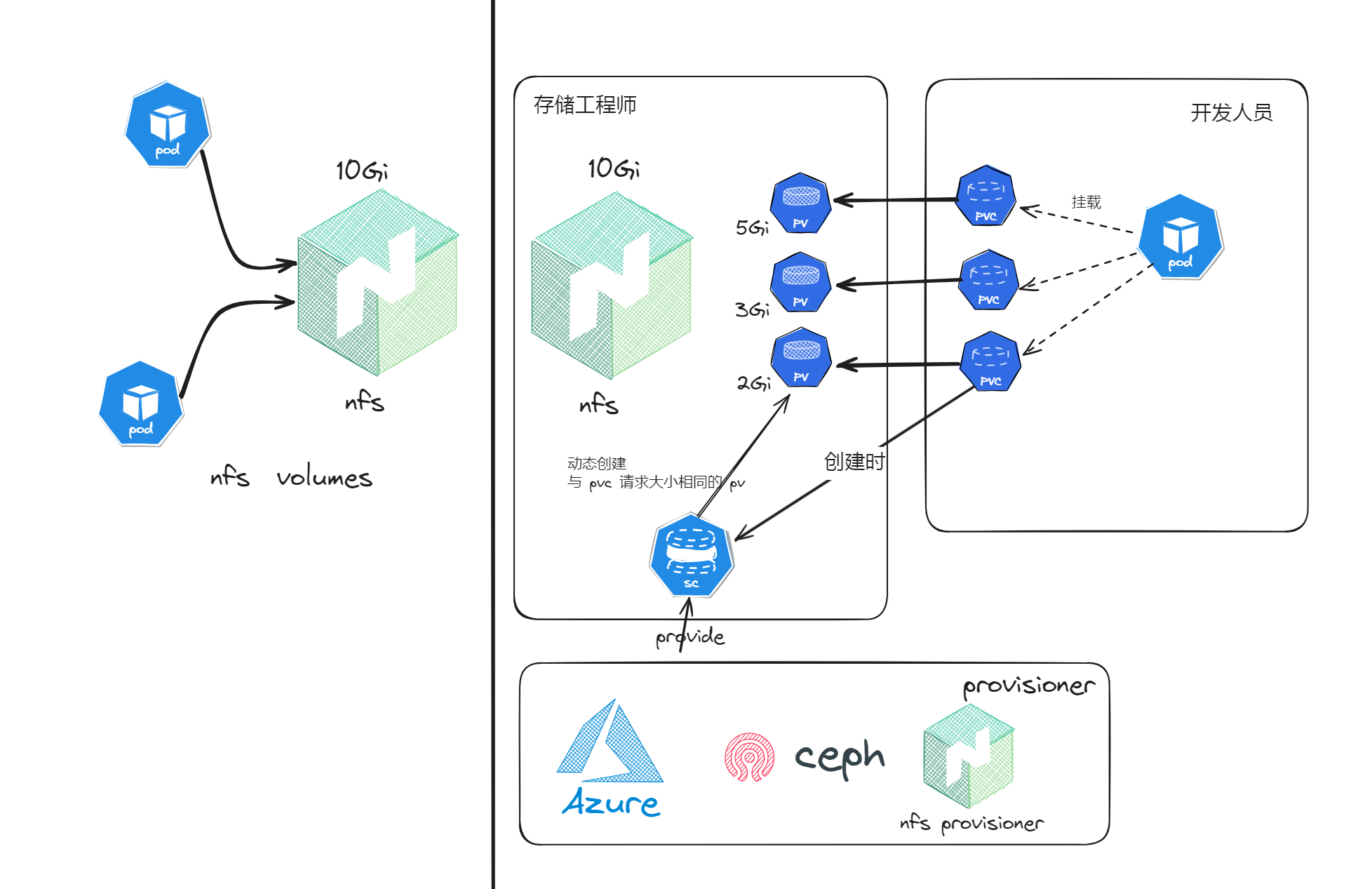
步步深入 k8s 使用 pv pvc sc 在 nfs 基础上共享存储
博客原文 文章目录 前言集群环境nfs 环境搭建pod 挂载 nfs架构图 pvc 方式挂载 nfs架构图 storageclass 方式动态申请 pv架构图 参考 前言 持久化卷(Persistent Volume, PV)允许用户将外部存储映射到集群,而持久化卷申请(Persist…...
Stable Diffusion 模型下载:Disney Pixar Cartoon Type A(迪士尼皮克斯动画片A类)
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里。 文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八案例九案例十...
Modelsim10.4安装
简介(了解,可跳过) modelsim是Mentor公司开发的优秀的HDL语言仿真软件。 它能提供友好的仿真环境,采用单内核支持VHDL和Verilog混合仿真的仿真器。它采用直接优化的编译技术、Tcl/Tk技术和单一内核仿真技术,编译仿真速…...
Java基于微信小程序的医院核酸检测服务系统,附源码
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...
VC++ 绘制折线学习
win32 有三个绘制折线的函数; Polyline,根据给定点数组绘制折线; PolylineTo,除了绘制也更新当前位置; PolyPolyline,绘制多条折线,第一个参数是点数组,第二个参数是一个数组、指…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...