【python】网络爬虫与信息提取--Beautiful Soup库
Beautiful Soup网站:https://www.crummy.com/software/BeautifulSoup/
作用:它能够对HTML.xml格式进行解析,并且提取其中的相关信息。它可以对我们提供的任何格式进行相关的爬取,并且可以进行树形解析。
使用原理:它能够把任何我们给它的文档当作一锅汤,任何给我们煲制这锅汤。
一、安装
目前最常用的版本是Beautiful Soup 4,也就是 bs4 ,所以在导入时 import bs4就是在导入Beautiful Soup
1.使用管理员权限打开command命令台
2.运行pip install beautifulsoup4
二、Beautiful Soup的安装小测
以下链接为测试链接:This is a python demo page (python123.io)
1.打开该链接查看页面

2.浏览器打开页面后,右击打开“查看页面源代码”(edge,其他浏览器也可),任何将源代码拷贝下来放在我们的程序当中,或者使用上一博文所说的requests库。r.text就是html代码相关的内容。

3.为了简化,我们可以定义一个变量叫做demo,表示这个页面的所有代码的内容
![]()
4.导入beautiful soup库:from bs4 import BeautifulSoup
5.除了给出html,还要给出解析demo的解释器:soup= BeautifulSoup(demo,"html.parser")
6.看看安装是否正确:print(soup.prettify())

三、Beautiful Soup库的基本元素
Beautiful Soup库也叫beautifulsoupb4或bs4。bs4库是解析、遍历、维护“标签树”的功能库,只要我们提供的文件是标签类型,那么bs库都能给它做很好的解析。

这个属性是用来定义标签的特点的。
bs库的引用:from bs4 import BeautifulSoup。这说明我们从bs库引入了一个BeautifulSoup模型。如果我们需要bs库里面的一些基本变量进行判断的时候,我们可以直接引用bs库:import bs4.
理解bs:bs本身解析的是html和xml文档,那么这个文档和标签树是一一对应的,那么经过了bs类的处理(把标签树理解为一个字符串,bs就可以把它转化为一个bs类,bs类是一个能代表标签树的类型。)事实上,我们认为html文档,标签树和bs类这三者是等价的,bs对应一个html/xml文档的全部内容。

实际上,每一种解析器它都是可以有效解析html和xml文档的,这里面我们主要使用的是html解析器。




这时候,soup表示我们解析后的demo页面。title标签就是我们页面在浏览器左上方显示位置信息的地方。事实上,所有html语法上的标签都可以使用soup.tag方式访问获得。

当html文档中存在多个相同的tag标签时,我们用soup.tag只能返回其中的第一个。比如刚刚访问的a标签,页面中有两个a标签,却只返回第一个。
获取标签名字的方法:

a.parent表示包裹a的上一级标签。

标签的属性是在标签中标明标签特点的相关区域,它以字典的形式来组织。因为它是字典,我们可以对属性做信息的提取,如下图。

查看标签属性的类型:type(tag.attrs)

需注意,tag标签可以有零个或者多个属性,那么如果没有属性存在的时候,我们使用attrs获得的字典是个空字典,但是无论有属性还是没有属性,我们总能获得一个字典。
获得标签之间的内容:

注释:

我们分别对p和b标签分别用.string的时候,我们都能产生一段文本,但是当这个文本是注释形式的时候,它并没有标明它是注释,所以我们分析文档的时候,我们需要对其中的注释部分做相关的判断,而判断的依据就是它的类型,这种情况在我们分析文本中并不常用,所以做一个基本了解即可。
四、基于bs库的html内容遍历方法
遍历方式:上行遍历、下行遍历、平行遍历
1.下行遍历


对于一个标签的儿子节点并不仅仅包括标签节点,也包括字符串节点,比如像是\n的回车,它也是一个body标签的儿子节点类型,我们可以用len函数获得儿子节点的数量,或者给定数组下标获得对应数据。


2.上行遍历


soup的父亲是空的。
上行遍历代码如下:

3.平行遍历
使用条件:平行遍历发生在同一个付节点的各节点间,不是同一个父节点下的标签之间不构成平行遍历关系。


需注意,在标签树中,尽管数形结构采用的是标签的形式来组织,但是标签之间的navigableString也构成了标签树的节点,也就是说任何一个节点它的平行标签,它的父亲标签,它的儿子标签是可能存在navigableString类型的。
平行遍历代码如下:

总结:

五、基于bs库的html格式化和编码
1.格式化
目的:让html内容更加友好的显示
方案:利用BS库的prettify()方法
prettify()作用:能够为html文本的标签以及内容增加换行符,它也可以对每一个标签来做相关的处理


2.编码
注意,bs4库将任何读入的html文件或者字符串都转换成utf-8编码
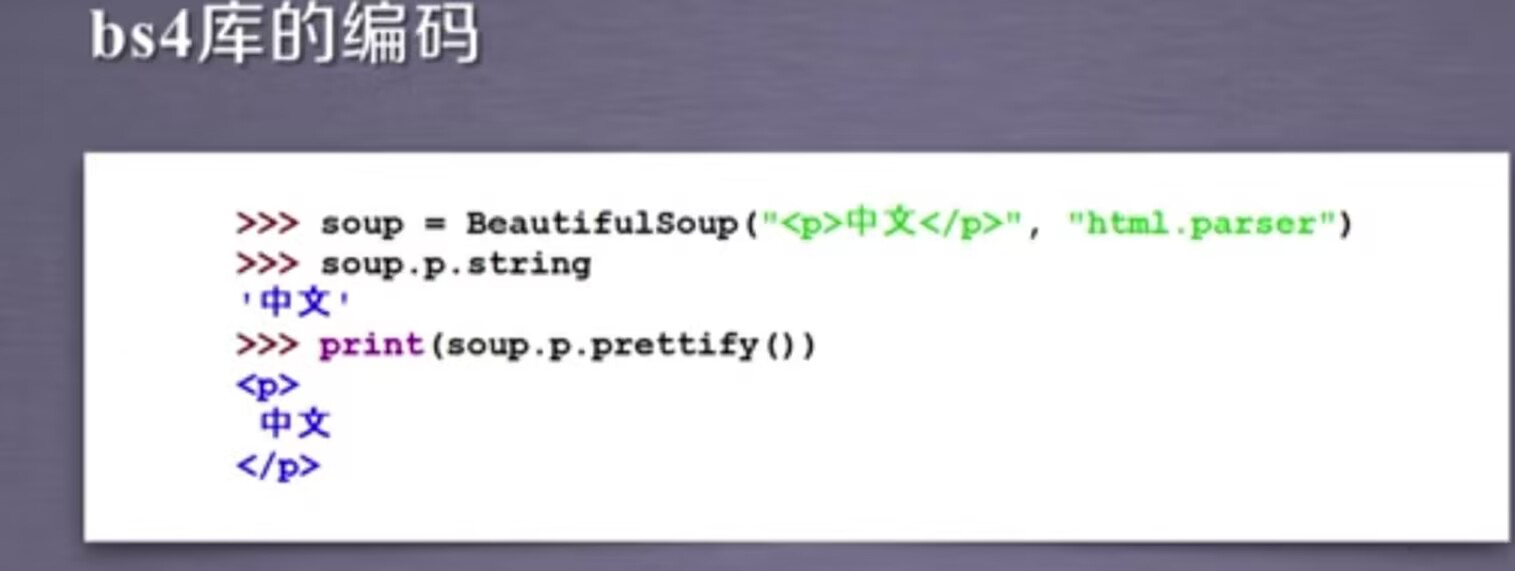
可以看见,当我们输入中文的时候,它的结果可以很好的显示出来。
六、信息标记的三种形式
作用:1.标记后的信息可形成信息组织结构,增加信息维度 2.标记后的信息可用于通讯、存储和展示 3.标记的结构与信息用于具有价值 4.标记后的信息更有利于程序理解和运用
HTML的信息标记:HTML是WWW的信息组织方式,可以把声音图像视频等超文本的信息嵌入到文本当中。HTML通过预定义的<>...</>标签形式组织不同类型的信息
现在国际公认的三种信息标记种类:xml、ison、yaml
1.xml
xml,拓展标记语言,与html很接近的标记语言,它采用了以标签为主来构建信息和表达信息。


2.json
json,有类型的键值对 key:value。当一个键值有多个值时,采用[]和逗号隔开。
好处:对于javascript等编程语言来说,可以直接将json格式作为程序的一部分,简化编程。


3.yaml
yaml,无类型的键值对 key:value。通过缩进表示包含关系。



七、三种信息标记形式的比较
表示形式



实例



xml:有效信息占比不高,大多数信息被标签占用
比较


八、信息的提取的一般方法

方法一: 我们需要什么信息,去解析标签树就可以了。好处是你需要什么信息,就能找到这部分的位置。缺点是需要对整个文件的信息组织形式有清楚的认识和理解

方法二:就好像我们使用word一样,根本不需要关心整个word文档具有什么样的标题形式和格式,只需要我们对信息的文本利用函数去查找就可以。

实例:提取HTML中所有URL链接
思路:1.搜索到所有<a>标签 2.解析<a>标签格式,提取href后的链接内容。

九、基于bs4库的html内容查找方法


如果我们给出的标签名是true的话,将显示当前soup的所有标签信息。
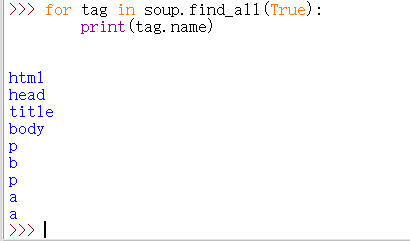
当我们需要查询b开头的b和body标签,这需要我们引入正则表达式库(import re)。

soup.find_all(id='link1')表示包含的元素就是属性中id域等于link1的标签元素,当查找的内容html不包含时,则返回空数组。

也就是当进行属性查找的时候,我们必须准确地赋值这个信息,如果我们想查找属性的部分信息,可以考虑引入正则表达式,否则就需要准确查找,不多也不能少。

soup.find_all('a',recursive=False)返回空值,表示它的儿子节点层面上是没有a标签的

查找更多信息 :

简写方式:
<tag>(..) 等价于 <tag>.find_all(..)
soup(..) 等价于 soup.find_all(..)
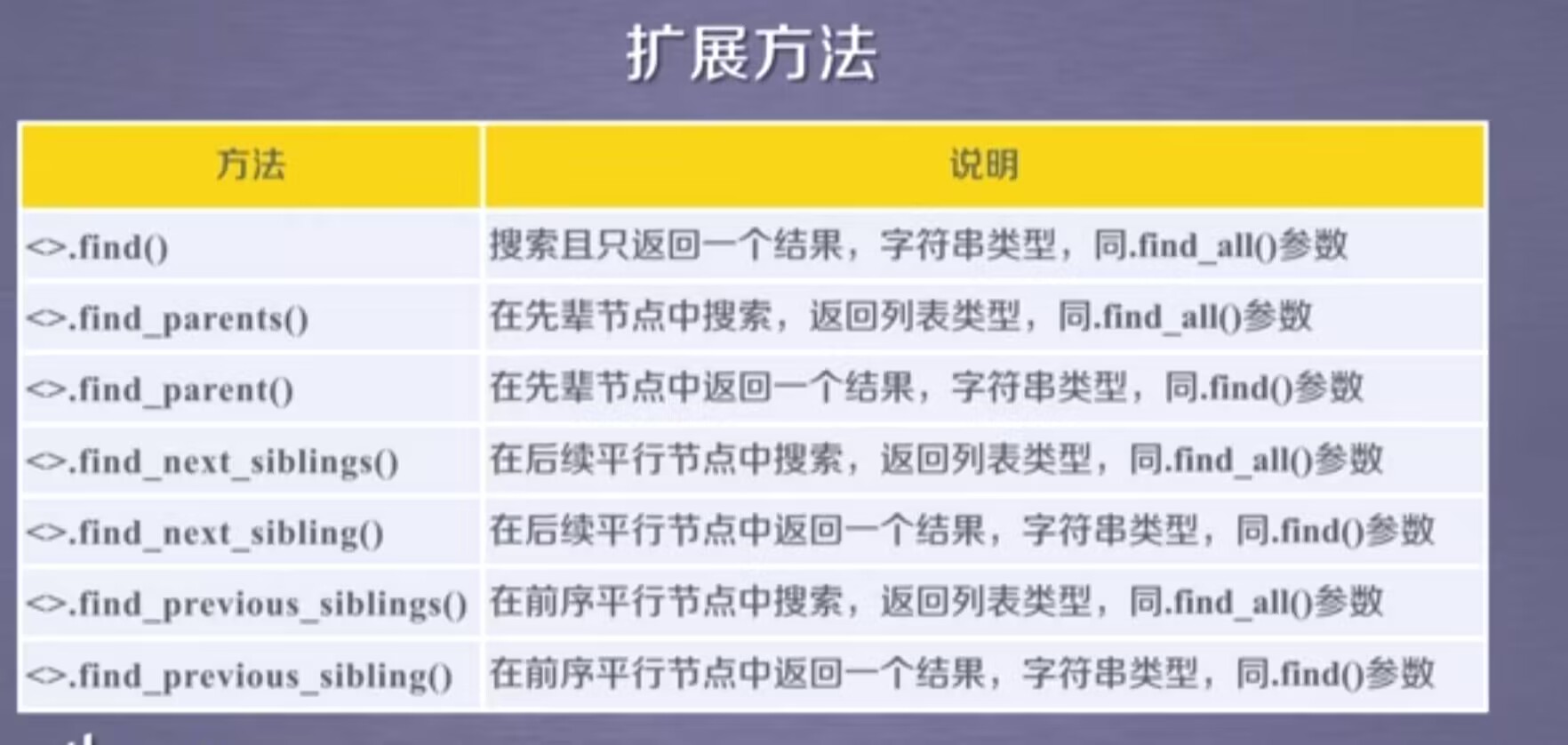
扩展方法:
十、实例:中国大学排名定向爬虫
基本情况:我们将采取由上海交通大学设计研发的最好大学排名。
【软科排名】2023年最新软科中国大学排名|中国最好大学排名 (shanghairanking.cn)
功能描述:
输入:大虚的排名URL链接
输出:排名、名称、总分
技术路线:requests-bs4
定向爬虫:仅对输入url进行爬取,不拓展爬取其他url。
注意:如果有些数据是通过javascript等脚本语言生成的,也就是说当你访问一个网页的时候,它的信息是动态提取和生成的,在这种情况下,用requests和bs4是无法获取它的信息的。
程序的结构设计与(步骤):1.从网络上获取大学排名网页内容(可以定义一个getHTMLText()函数) 2.提取网页内容中信息到合适的数据结构(定义fillUnivList()) 3.利用数据结构展示并输出结果(定义printUnivList())
实现:
(关于在IDLE中怎么换行继续敲写代码而不执行语句 :按ctrl+n弹出新窗口,在新窗口里面写。)
先写主函数,由于实现了网络请求,我们要import requests库和bs4库![]()
刚才我们定义了三个函数分别对应三个步骤,我们将这三个函数写进来,但由于此时我们还没有对每个函数的内部功能进行设计和实现,所以我们只要写出函数的定义就可以。pass语句表示不做任何操作。

我们将大学信息放在unifo中,给出刚刚页面的链接https://www.shanghairanking.cn/rankings/bcur/202311
然后调用刚刚的三个函数,先将url转换成html,然后信息提取后将html放在unifo中
接着填充第一个函数:设置timeout时间是30秒,然后用raise_for_status来产生异常信息,接着修改编码,然后把网页内容返回给程序的其他部分。

接着填充第二个函数:通过BeautifulSoup库解析网页,将需要的信息加入到一个列表中。if isinstance(tr, bs4.element.Tag): 判断tr标签是不是bs4定义的tag标签,过滤掉不是bs4定义的tag标签,为了使这个代码能够运行,我们需引入一个叫bs4的库
所有代码如下:
import requests
import bs4
from bs4 import BeautifulSoup
def getHTMLText(url):try:r = requests.get(url,timeout=30)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:return ""def fillUnivList(ulist,html):soup = BeautifulSoup(html, "html.parser")for tr in soup.find("tbody").children:if isinstance(tr, bs4.element.Tag): tds = tr('td') n = tds[1].find("a").string # 因为大学名字在td标签的子标签a中,所以需要单独提取ulist.append([tds[0].string, n, tds[4].string])def printUnivList(ulist,num):tplt = "{0:^10}{1:{3}^10}{2:^10}"print(tplt.format("序号", "学校名称", "总分", chr(12288))) for i in range(num):u = ulist[i]a = u[0].strip() # 去掉字符串类两边的空格b = u[1].strip()c = u[2].strip()print(tplt.format(a, b, c, chr(12288)))def main():unifo=[]url='https://www.shanghairanking.cn/rankings/bcur/202311'html=getHTMLText(url)fillUnivList(unifo,html)printUnivList(unifo,20)main()
美化:采用中文字符的空格进行填充--chr(12288)
相关文章:
【python】网络爬虫与信息提取--Beautiful Soup库
Beautiful Soup网站:https://www.crummy.com/software/BeautifulSoup/ 作用:它能够对HTML.xml格式进行解析,并且提取其中的相关信息。它可以对我们提供的任何格式进行相关的爬取,并且可以进行树形解析。 使用原理:它能…...

谷歌浏览器,如何将常用打开的网站创建快捷方式到电脑桌面?
打开谷歌浏览器,打开想要创建的快捷方式的网页 点击浏览器右上角的三个点: 点击选择【更多工具】 选择【创建快捷方式】 然后,在浏览器上方会弹出一个框,让命名此创建的快捷方式的名称 命名好之后,再点击【创…...

产品经理面试题解析:业务架构是通往成功的关键吗?
大家好,我是小米!今天我要和大家聊的是产品经理面试中的一个热门话题:“业务架构”!相信不少小伙伴在准备面试的时候都会遇到这个问题,究竟什么是业务架构?它又与产品经理的工作有着怎样的关系呢࿱…...

【蓝桥杯】灭鼠先锋
一.题目描述 二.解题思路 博弈论: 只能转移到必胜态的,均为必败态。 可以转移到必败态的,均为必胜肽。 最优的策略是,下一步一定是必败态。 #include<iostream> #include<map> using namespace std;map<string,bo…...
)
2024年华为OD机试真题-求字符串中所有整数的最小和-Python-OD统一考试(C卷)
题目描述: 输入字符串s,输出s中包含所有整数的最小和 说明 1. 字符串s,只包含 a-z A-Z +- ; 2. 合法的整数包括 1) 正整数 一个或者多个0-9组成,如 0 2 3 002 102 2)负整数 负号 - 开头,数字部分由一个或者多个0-9组成,如 -0 -012 -23 -00023 输入描述: 包含…...
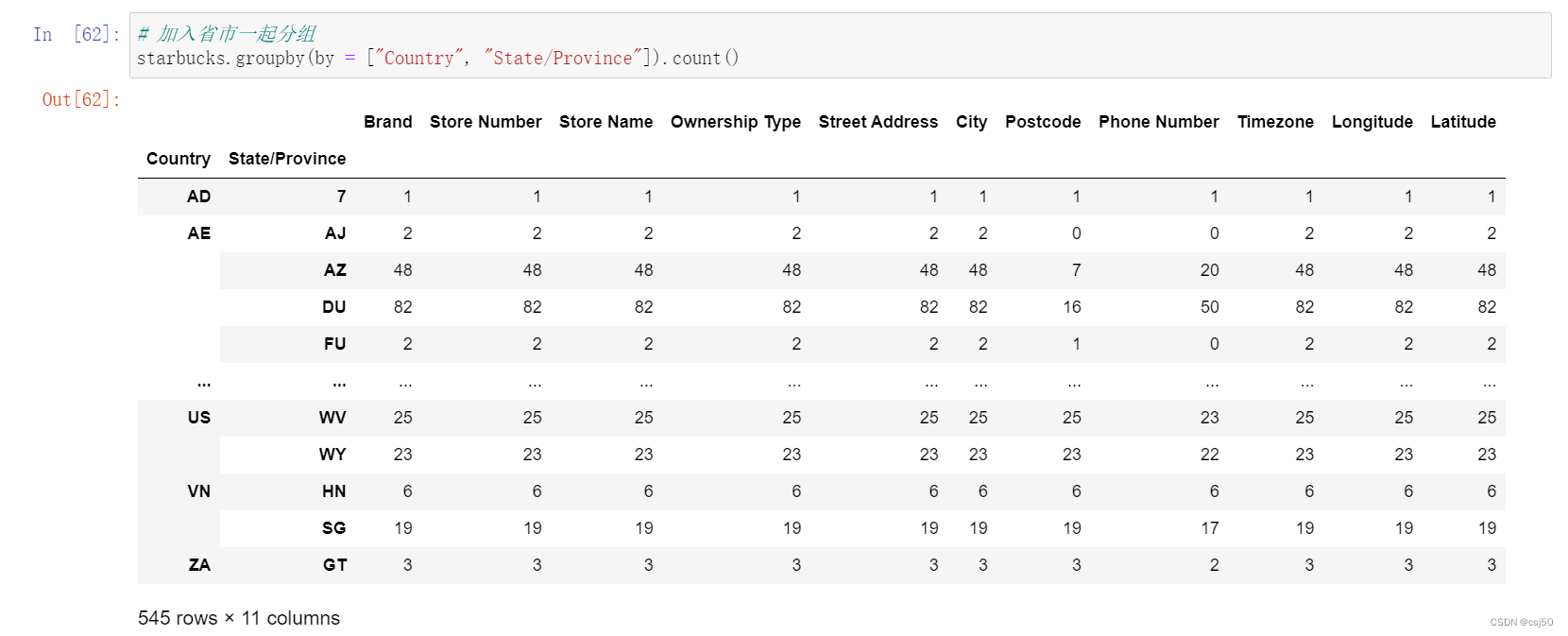
数据分析基础之《pandas(7)—高级处理2》
四、合并 如果数据由多张表组成,那么有时候需要将不同的内容合并在一起分析 1、先回忆下numpy中如何合并 水平拼接 np.hstack() 竖直拼接 np.vstack() 两个都能实现 np.concatenate((a, b), axis) 2、pd.concat([data1, data2], axis1) 按照行或者列…...

fluent脱硝SCR相对标准偏差、氨氮比、截面速度计算
# -*- coding: utf-8 -*- """ Created on Wed Sep 20 20:40:30 2023 联系QQ:3123575367,专业SCR脱硝仿真。 该程序用来处理fluent通过export-solution-ASCII-Space导出的数据,可计算标准偏差SD、相对标准偏差RSD,适用于求解平面的相对均匀…...
(A~E))
Codeforces Round 925 (Div. 3)(A~E)
题目暂时是AC,现在是Hack阶段,代码仅供参考。 A. Recovering a Small String 题目给出的n都可以由字母来组成,比如4可以是aab,字母里面排第一个和第二个,即1124。但是会歧义,比如aba为1214,也是…...

@RequestBody、@RequestParam、@RequestPart使用方式和使用场景
RequestBody和RequestParam和RequestPart使用方式和使用场景 1.RequestBody2.RequestParam3.RequestPart 1.RequestBody 使用此注解接收参数时,适用于请求体格式为 application/json,只能用对象接收 2.RequestParam 接收的参数是来自HTTP 请求体 或 请…...
LeetCode、1143. 最长公共子序列【中等,二维DP】
文章目录 前言LeetCode、1143. 最长公共子序列【中等,二维DP】题目链接与分类思路2022年暑假学习思路及题解二维DP解决 资料获取 前言 博主介绍:✌目前全网粉丝2W,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者…...
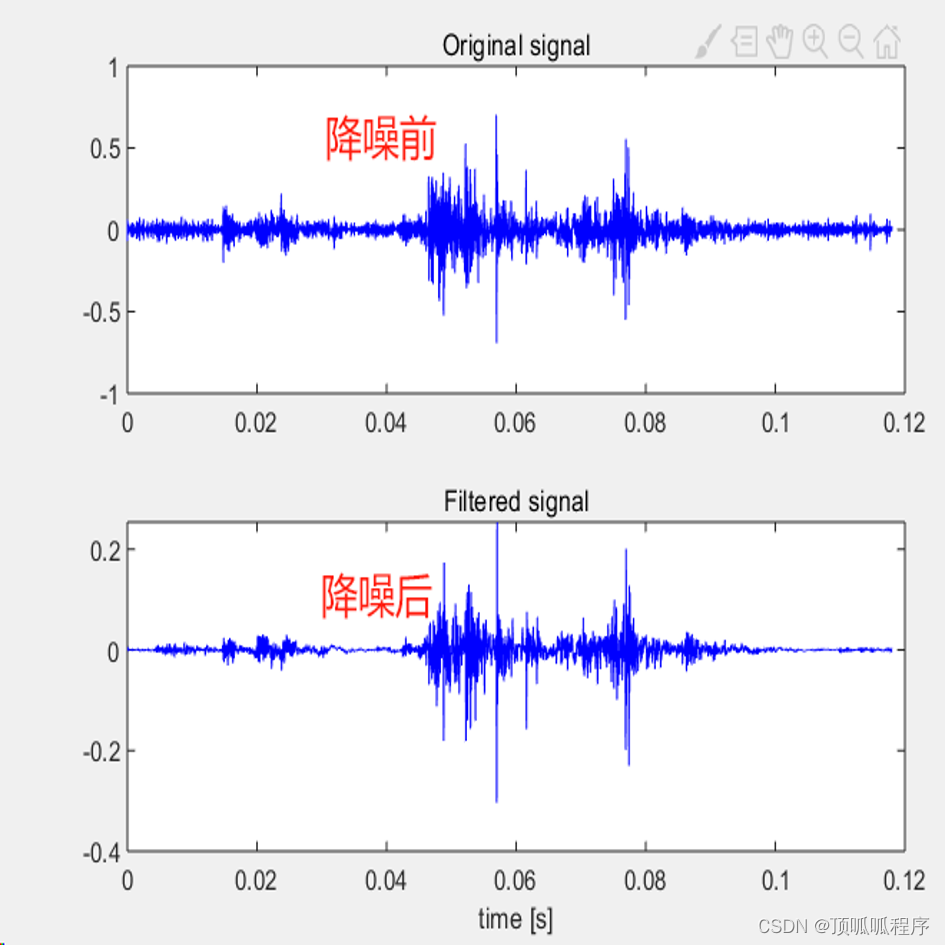
162基于matlab的多尺度和谱峭度算法对振动信号进行降噪处理
基于matlab的多尺度和谱峭度算法对振动信号进行降噪处理,选择信号峭度最大的频段进行滤波,输出多尺度谱峭度及降噪结果。程序已调通,可直接运行。 162 matlab 信号处理 多尺度谱峭度 (xiaohongshu.com)...

Android Studio六大基本布局的概览和每个布局的关键特性以及实例分析
1. 线性布局 (LinearLayout) 描述: 线性布局是一种按指定方向(水平或垂直)排列其子视图的布局容器。通过android:orientation属性可设置为horizontal或vertical。 关键属性: android:orientation: 指定布局方向。android:layout_weight: 子视图权重,用于分配剩余空间。示…...

【go语言】一个简单HTTP服务的例子
一、Go语言安装 Go语言(又称Golang)的安装过程相对简单,下面是在不同操作系统上安装Go语言的步骤: 在Windows上安装Go语言: 访问Go语言的官方网站(golang.org)或者使用国内镜像站点࿰…...

LeetCode Python - 15.三数之和
目录 题目答案运行结果 题目 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意:答案中不可…...
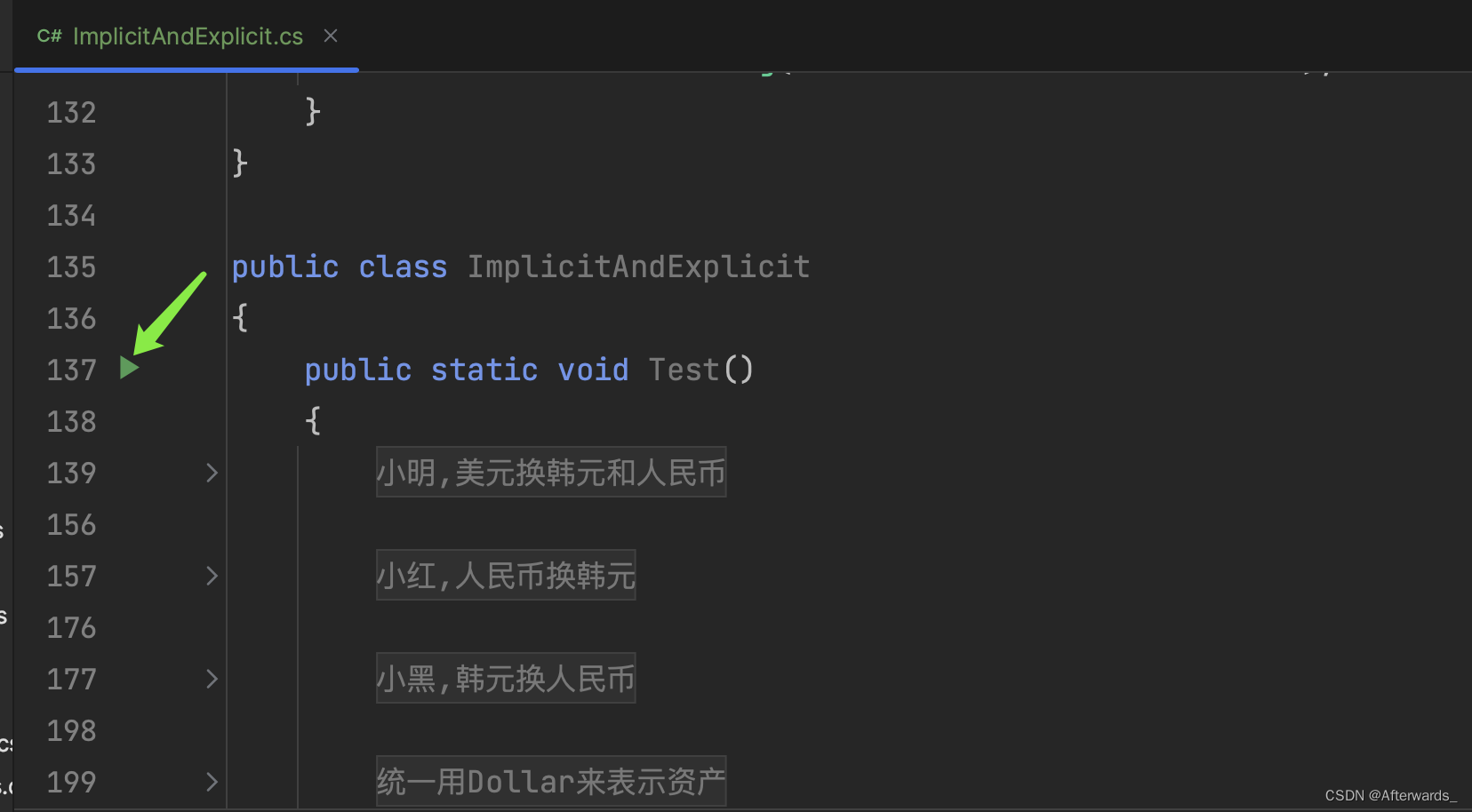
C#中implicit和explicit
理解: 使用等号代替构造函数调用的效果以类似重载操作符的形式定义用于类型转换的函数前者类型转换时候直接写等号赋值语法,后者要额外加目标类型的强制转换stirng str -> object o -> int a 可以 int a (int)(str as object)转换通过编译,但没有转换逻辑所以运行会报错…...

探讨java系统中全局唯一ID实现方案
为什么需要全局唯一ID 我们这里引用美团 Leaf 的场景介绍:在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一…...
微信小程序(四十四)鉴权组件插槽-登入检测
注释很详细,直接上代码 新增内容: 1.鉴权组件插槽的用法 2.登入检测示范 源码: app.json {"usingComponents": {"auth":"/components/auth/auth"} }app.js App({globalData:{//定义全局变量isLoad:false} })…...
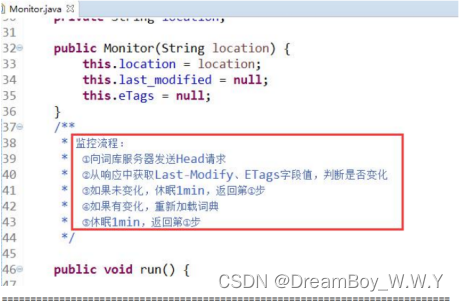
【ES】--ES集成热更新自定义词库(字典)
目录 一、问题描述二、具体实施1、Tomcat实现远程扩展字典2、验证生效3、ES配置远程扩展字典4、为何不重启ES能实现热更新 一、问题描述 问题现象: 前面完成了自定义分词器词库集成到ES中。在实际项目中词库是时刻在变更的,但又不希望重启ES,对此我们应…...

能源管理师——为能源可持续发展护航
能源管理师是在能源管理领域具有专业知识和技能的专业人士,他们的工作对于实现能源的有效利用和可持续发展至关重要。 能源管理师的主要职责是协助企业或组织进行能源管理,包括能源规划、能源审计、节能措施的实施和能源绩效的评估等。他们通过对能源使…...

设计模式理解:单例模式+工厂模式+建设者模式+原型模式
迪米特法则:Law of Demeter, LoD, 最少知识原则LKP 如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。 所以,在运用迪米特…...

除了Omnipeek,你的8812BU网卡还能怎么玩?Win10下的另类WiFi抓包与网络诊断实战
解锁Realtek 8812BU网卡的隐藏潜能:Windows 10下的WiFi抓包与网络诊断全攻略 当你手握一块Realtek 8812BU无线网卡时,可能只把它当作普通的网络连接工具。但实际上,这款硬件在Windows 10环境下可以变身为强大的网络诊断利器。本文将带你探索…...

社交媒体数据采集难题?MediaCrawler让复杂任务变简单
社交媒体数据采集难题?MediaCrawler让复杂任务变简单 【免费下载链接】MediaCrawler-new 项目地址: https://gitcode.com/GitHub_Trending/me/MediaCrawler-new 在信息爆炸的数字时代,企业、研究机构和内容创作者常常需要从各大社交平台获取有价…...

GBase 8c 表空间规划和对象迁移
GBase 8c 表空间规划和对象迁移 我最近看 GBase 8c 资料时,越来越强烈的一个感觉是:很多现场不是不会建表空间,而是把表空间用得太晚、太散、太随意。 真正落到现场时,最常见的现象通常不是“不会执行 CREATE TABLESPACE”&#x…...
)
别再只杀进程了!挖矿病毒XMRig的完整清除与溯源指南(附config.json钱包地址分析)
深度对抗XMRig挖矿病毒:从清除到溯源的实战手册 发现任务管理器里反复出现的xmrig.exe进程?别急着再次点击"结束任务"——这就像用创可贴处理骨折,治标不治本。作为处理过数百起挖矿事件的安全工程师,我总结了一套从内…...
)
保姆级教程:在Ubuntu 20.04上搞定Isaac Gym Preview 4和强化学习环境(含常见libpython报错解决)
保姆级教程:在Ubuntu 20.04上搞定Isaac Gym Preview 4和强化学习环境(含常见libpython报错解决) 刚接触Isaac Gym的机器人/强化学习新手,往往会在环境配置阶段遇到各种依赖问题。本文将提供一个从零开始的详细安装指南,…...

【微信小程序更新机制全解析】原理、实践与最佳实践
前言 微信小程序的更新机制,是连接开发者版本迭代与用户体验的核心桥梁。它设计的核心逻辑是**“自动无感更新为主,手动强制更新为辅”,在保证小程序快速启动、稳定可用**的前提下,尽可能让用户使用最新版本;同时为开…...

从收音机到WiFi:LC并联谐振电路在实际通信系统里是怎么用的?
从矿石收音机到5G基站:LC并联谐振电路的百年进化史 当你拧动老式收音机的调谐旋钮时,金属指针在刻度盘上滑过不同电台的频率标记,耳机里传来忽大忽小的静电噪声,直到某个瞬间——声音突然清晰起来。这个看似简单的动作背后&#x…...

从114G输出文件反推:OpenHarmony编译后,out目录里到底装了啥?如何优化存储空间?
从114G输出文件反推:OpenHarmony编译后,out目录里到底装了啥?如何优化存储空间? 当你第一次完成OpenHarmony的完整编译,看到out目录膨胀到51G甚至更大时,难免会感到震惊。更令人头疼的是,随着开…...

上海计算机学会2026年2月月赛C++丙组T1 乘积的秘密
乘积的秘密 题目描述 给定两个整数 A 与 B,保证 A ≤ B。请求出从 A 一直乘到 B 的符号: 如果乘积大于 0,输出 Positive;如果乘积小于 0,输出 Negative;如果乘积等于 0,输出 Zero。 输入格式 两…...

Ostrakon-VL-8B实战:模拟互联网产品A/B测试中的视觉效果分析
Ostrakon-VL-8B实战:模拟互联网产品A/B测试中的视觉效果分析 每次产品迭代,设计团队和产品经理之间总少不了一场“拉锯战”。新版本的设计稿出来了,A方案简洁现代,B方案信息突出,到底哪个更能吸引用户点击?…...