【AutoML】AutoKeras 进行 RNN 循环神经网络训练
由于最近这些天都在人工审查之前的哪些问答数据,所以迟迟都没有更新 AutoKeras 的训练结果。现在那部分数据都已经整理好了,20w+ 的数据最后能够使用的高质量数据只剩下 2k+。这 2k+ 的数据已经经过数据校验并且对部分问题的提问方式和答案内容进行了不改变原意的重构,相信用这部分数据进行训练将会得到满意的效果。
在正式讲解之前,还是先将一些概念性的内容讲一下。
为什么选 AutoKeras?
首先作为一名人工智能的初学者是会存在选择困难症的(毕竟人工智能种类五花八门,各有各特色。学习和实施门槛也各不相同,挺难选择的),去生啃论文又看得云里雾里。再加上小公司要快速产出,上级一直输出压力,整个人会越来越焦躁,也越来越学不下去。就在这时我遇到了 AutoML 的 AutoKeras,它简直就是初学者的救星。
AutoKeras 基于 Keras,而 Keras 又基于 Tensorflow。Tensorflow 发展了这么久了社区非常庞大且活跃,小白不明白的地方要找查证资料也比较简单。除此之外,AutoKeras 通过结合使用神经网络搜索算法和贝叶斯优化来搜索给定数据集的最佳模型架构和超参数,因此它的参数几乎都是可选的。它的具体实现是先创建一组具有不同架构和超参数的模型,然后在数据集上对其进行评估。最后根据模型的性能对模型进行排名,并选择最佳模型(这对于初学者来说真的非常友好!!)。AutoKeras 还提供了易于使用的 API,供开发人员快速开始深度学习。简单来说,只要你会 Python,会调用 API,再准备好你的数据,就能快速构建和部署模型。公司领导是“面向结果”管理的,对于他来说你能够快速产出比什么都重要。
什么是 AutoML 模型?
AutoML(Automated Machine Learning)是指利用自动化技术来简化机器学习模型的构建和训练过程的方法。个人觉得 AutoML 的最大优势在于降低了使用机器学习的门槛,即使像我这种初学者也能够轻松使用。
什么是 CNN?什么是 RNN?
先说 CNN,CNN 是卷积神经网络(Convolutional Neural Network)的简写,它主要由卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully Connected Layer)组成。简单来说,这三层的分工就是卷积层负责学习图像中的特征,池化层用于降低卷积层输出的空间维度,同时保留关键信息,而全连接层则用于将卷积和池化层的输出映射到最终的输出类别。基于这种特征,CNN 多用于处理和分析视觉数据,像图像识别、检测、生成等处理非常出色。
循环神经网络(Recurrent Neural Network,RNN)是一类用于处理序列数据的神经网络。它在处理序列数据时具有记忆性,可以保持对先前输入的记忆,并在处理新输入时使用这些记忆。RNN 的基本结构是通过将网络的输出反馈到输入中,以实现对序列数据的处理。而我们的目标是训练一个问答机器人,这种自然语言处理的人工智能非常适合使用 RNN 进行训练。
(那些太过高深的原理等等我也不太会,以上都是我看完了之后的一些总结,如有纰漏的地方请各位指正,谢谢)
开始训练
好了,上面基础概念的想说的都说了,下面就开始说说我是怎样做训练的吧。
更新第一篇文章中搭建的训练环境插件,如下图:
# 更新 pip
python3 -m pip install --upgrade pip
# 安装 pymysql 插件(因为数据需要从 mysql 中提取)
pip install pymysql
接着我就按照 AutoKeras 官网提供的例子进行了训练,但训练其实遇到了很多的问题。
第一次训练时我直接调用 TextClassifier 这个高级 API,然而在训练到第三循环时就报错了,如下图:
Search: Running Trial #3Value |Best Value So Far |Hyperparameter
bert |transformer |text_block_1/block_type
0 |0 |classification_head_1/dropout
adam_weight_decay |adam |optimizer
2e-05 |0.001 |learning_rate
512 |None |text_block_1/bert_block_1/max_sequence_lengthDownloading data from https://storage.googleapis.com/keras-nlp/models/bert_base_en_uncased/v1/vocab.txt
Traceback (most recent call last):File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/urllib/request.py", line 1350, in do_openh.request(req.get_method(), req.selector, req.data, headers,
...
ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1124)....raise Exception(error_msg.format(origin, e.errno, e.reason))
Exception: URL fetch failure on https://storage.googleapis.com/keras-nlp/models/bert_base_en_uncased/v1/vocab.txt: None -- [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1124)Trial 3 Complete [00h 00m 00s]
上面的报错说 block_type 在使用 bert 类型的时候就出现了错误,疑似是需要通过网络下载某些东西之后才能继续。既然就在原代码中加入以下两行代码来规避掉 https 的验证,如下图:
# 引入 ssl 模块
import ssl
# 设置 ssl 验证
ssl._create_default_https_context = ssl._create_unverified_context
加入以上代码后又可以继续训练了,接着又出现了以下报错,如下图:
Traceback (most recent call last):File "/Users/yuanzhenhui/Documents/code_space/git/processing/python/autokeras-env/phw2-industry-bot/model_train.py", line 130, in <module>main()
...raise e.with_traceback(filtered_tb) from NoneFile "/Users/yuanzhenhui/Documents/code_space/git/processing/python/autokeras-env/lib/python3.8/site-packages/tensorflow/python/eager/execute.py", line 53, in quick_executetensors = pywrap_tfe.TFE_Py_Execute(ctx._handle, device_name, op_name,
tensorflow.python.framework.errors_impl.InvalidArgumentError: Graph execution error:indices[18] = -1 is not in [0, 50)[[{{node embedding_lookup}}]][[IteratorGetNext]] [Op:__inference_test_function_7479]
Segmentation fault: 11
经过网上的搜索发现,这个问题是测试数据跟训练数据出现较大差异时造成的。
这是因为我的训练数据、测试数据和验证数据都是独立构造出来的,虽然都是存放在同一张表中,但由于数据量较为庞大,因此难以保证所有数据向量都一致的情况这仍然是数据质量的问题。由于并不知道具体那条数据存在问题,于是只能缩减取数的范围后进入下一轮训练,如下图:
Search: Running Trial #4Value |Best Value So Far |Hyperparameter
vanilla |vanilla |text_block_1/block_type
none |none |text_block_1/embedding_1/pretraining
64 |64 |text_block_1/embedding_1/embedding_dim
0.25 |0.25 |text_block_1/embedding_1/dropout
5 |5 |text_block_1/conv_block_1/kernel_size
False |False |text_block_1/conv_block_1/separable
False |False |text_block_1/conv_block_1/max_pooling
1 |1 |text_block_1/conv_block_1/num_blocks
1 |1 |text_block_1/conv_block_1/num_layers
256 |256 |text_block_1/conv_block_1/filters_0_0
512 |512 |text_block_1/conv_block_1/filters_0_1
0 |0 |text_block_1/conv_block_1/dropout
64 |64 |text_block_1/conv_block_1/filters_1_0
256 |256 |text_block_1/conv_block_1/filters_1_1
0 |0 |classification_head_1/dropout
adam |adam |optimizer
0.001 |0.001 |learning_rateTraceback (most recent call last):File "/Users/yuanzhenhui/Documents/code_space/git/processing/python/autokeras-env/lib/python3.8/site-packages/keras_tuner/src/engine/base_tuner.py", line 273, in _try_run_and_update_trialself._run_and_update_trial(trial, *fit_args, **fit_kwargs)
...max_tokens = self.max_tokens or hp.Choice(File "/Users/yuanzhenhui/Documents/code_space/git/processing/python/autokeras-env/lib/python3.8/site-packages/keras_tuner/src/engine/hyperparameters/hyperparameters.py", line 300, in Choicereturn self._retrieve(hp)File "/Users/yuanzhenhui/Documents/code_space/git/processing/python/autokeras-env/lib/python3.8/site-packages/keras_tuner/src/engine/hyperparameters/hyperparameters.py", line 208, in _retrievereturn self.values[hp.name]
KeyError: 'text_block_1/max_tokens'Trial 4 Complete [00h 00m 04s]Best val_loss So Far: 4.101563930511475
Total elapsed time: 00h 24m 03s
又来了一个新问题,“实际 tokens 长度大于最大 tokens 长度”导致无法继续训练下去。其实这个问题才是 AutoML 较为致命的。因为 AutoML 会自动调整参数,这也许会将部分参数调整过大,导致最终超出了硬件可支持的阈值。而且这事儿出现概率还挺高的,因此你最好提前设定最大值让 AutoML 不要自动给你调这个参数了,或者你提供足够的资源其实也行。毕竟谁都不想训练好几天最终因为超出阈值终止训练。不过还好在 AutoKeras 中是提供参数选择是否对训练好的内容进行覆盖的,如果不覆盖那么原来训练好的数据还是会保留。
言归正传,上面这个报错只需要将 max_tokens 参数调大就可以了(下面将提供完成代码)。
最后我想说的是,做这个训练还是要用 GPU 来做吧,虽然 AutoKeras 也继承了 Tensorflow 可以使用 CPU 来进行训练,但是速度太慢了。因此还是建议各位在做训练的时候先找一台 Windows 的机器,里面装好 Nvidia 显卡配置好 CUDA 和 cuDNN。我自己亲测,快的不是一丁半点。
好了,上关键代码如下图:
...
def ak_qa_train_main(page, page_size):...if tr_data.shape[0] != 0:# 自定义训练模型整理text_input = ak.TextInput()# 直接使用 textblock 来对数据进行训练text_output = text_block_model(text_input)model = ak.AutoModel(inputs=text_input, outputs=text_output, project_name=auto_model_path, overwrite=True)# 训练模型model_fit = model.fit(tr_data[:, 0], tr_data[:, 1], batch_size=32, validation_split=0.15)print('history dict:', model_fit.history)# 将训练好的模型导出model.export_model().save(export_model_path, save_format="tf")...def text_block_model(input_node):output_cnn_block = ak.TextBlock(max_tokens=200000)(input_node)output_rnn_block = ak.TextToIntSequence(output_sequence_length=32, max_tokens=200000)(input_node)output_rnn_block = ak.Embedding()(output_rnn_block)output_rnn_block = ak.Normalization()(output_rnn_block)output_rnn_block = ak.RNNBlock(layer_type="lstm", return_sequences=True)(output_rnn_block)output_rnn_block = ak.DenseBlock()(output_rnn_block)output_block = ak.Merge()([output_cnn_block, output_rnn_block])return ak.ClassificationHead()(output_block)
...
以上代码中 ak_qa_train_main 内代码为第一处关键代码,这里我并没有用到 AutoKeras 的高级 API 进行训练(经过反复的试验发现高级 API 存在大量使用约束)而采用了自定义模型(AutoModel)的方式进行训练,因此我必须在训练前先定义好训练模型。
训练模型需要一个数据输入,而由于我们是文本的训练数据,因此需要实例化一个 TextInput 作为训练数据输入。
而 text_block_model 方法则作为训练流程被使用(此处为第二处关键代码,下面会详细说明),它的返回将会作为训练结果进行输出。这样我们就有了输入和输出了,之后就可以将其指定到 AutoModel 的对应参数中。
AutoModel 执行之后将会得到一个 model 对象,有了 model 对象就能够进行真实的训练了,这时你只需要调用 fit API 就能执行训练。其中 fit 的第一个参数应该传入“问题”数据集,第二个参数传入“答案”数据集,第三个参数 batch_size 就是一次性提取训练数据的批次大小。
之后我们需要通过 model_fit.history 查看一下模型的损失(loss)和准确度(accuracy),用于判断模型是否适用。最后我们会通过 model.export_model().save() 来保存模型,然后通过 loss 和 accuracy 判断究竟保留哪个模型,删除掉那个模型。
这样我们就已经将训练的基础配置和调用代码写好了,是不是非常简单。
那么接下来我们就来说说第二处关键代码 text_block_model ,如下图:
def text_block_model(input_node):output_cnn_block = ak.TextBlock(max_tokens=200000)(input_node)output_rnn_block = ak.TextToIntSequence(output_sequence_length=32, max_tokens=200000)(input_node)output_rnn_block = ak.Embedding()(output_rnn_block)output_rnn_block = ak.Normalization()(output_rnn_block)output_rnn_block = ak.RNNBlock(layer_type="lstm", return_sequences=True)(output_rnn_block)output_rnn_block = ak.DenseBlock()(output_rnn_block)output_block = ak.Merge()([output_cnn_block, output_rnn_block])return ak.ClassificationHead()(output_block)
这段代码主要是描述整个模型的训练结构的。
首先在接收到输入数据后,数据将会传入 TextBlock 进行 CNN 数据特征提取。这里的 TextBlock 是 AutoKeras 的高级 API ,它会在训练过程中自动调整。同时,TextBlock 也提供了 max_tokens 参数,通过查看源码得知默认 max_tokens 只有 5000,如下图:
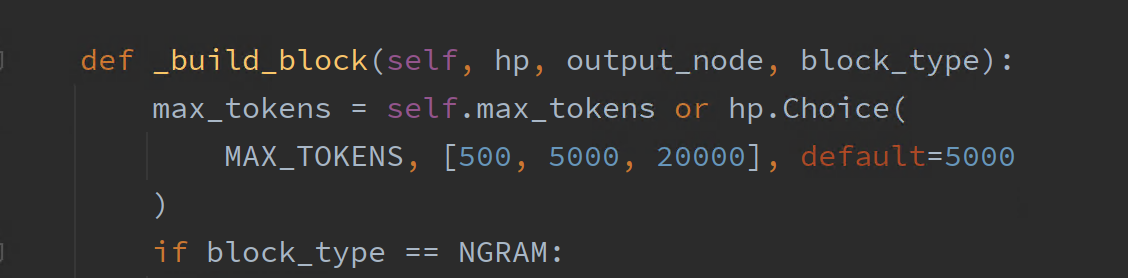
这样索性调整到 200000 应该够用。
注意!!!
这个是重点,使用 TextBlock 是需要它对问答数据进行数据特征提取,这使得 TextBlock 的存在非常重要的。而且 TextBlock 能自动调整参数,在不清楚那种参数能够更好的提取到特征的情况下,TextBlock 能够自动帮助我找到所需的模型参数,这非常方便。
ok,除了 TextBlock 外我还写了一个 RNN 训练分支。首先数据会先通过 TextToIntSequence 将文本转换为数字序列,这里将句子的最大长度(output_sequence_length)设置为 32,避免自动调参时这个参数设置过高的情况。此外,TextToIntSequence 也有提供 max_tokens 参数的,顺手将这个参数也设置为 200000 吧。
然后通过 Embedding 将数字序列转换为稠密向量,之后经过 Normalization 对稠密向量进行归一化处理,之后就可以送去给 RNNBlock 进行 RNN 训练了,这里指定了使用 lstm 类型进行训练,就不需要 AutoKeras 自动选择 gru 了。训练之后的数据将会经过 DenseBlock 使用全连接层生成下一个词,最后将 TextBlock 输出和 RNN 训练输出通过 Merge 方法进行合并,最后通过 ClassificationHead 进行汇聚输出。
由于没有设置训练回数,因此不可能将默认训练的 100 次输出都展示出来,这里就只截取其中一个比较有代表性的结果,如下图:
Search: Running Trial #9Value |Best Value So Far |Hyperparameter
transformer |transformer |text_block_1/block_type
none |none |embedding_1/pretraining
128 |128 |embedding_1/embedding_dim
0.25 |0.25 |embedding_1/dropout
True |True |rnn_block_1/bidirectional
2 |2 |rnn_block_1/num_layers
False |False |dense_block_1/use_batchnorm
2 |2 |dense_block_1/num_layers
32 |32 |dense_block_1/units_0
0 |0 |dense_block_1/dropout
32 |32 |dense_block_1/units_1
add |add |merge_1/merge_type
0.25 |0.25 |classification_head_1/dropout
adam |adam |optimizer
0.001 |0.001 |learning_rate
none |none |text_block_1/transformer_1/pretraining
128 |128 |text_block_1/transformer_1/embedding_dim
8 |8 |text_block_1/transformer_1/num_heads
2048 |2048 |text_block_1/transformer_1/dense_dim
0 |0 |text_block_1/transformer_1/dropout
1024 |None |text_block_1/dense_block_1/units_2
256 |128 |text_block_1/text_to_int_sequence_1/output_sequence_length
flatten |global_avg |text_block_1/spatial_reduction_1/reduction_type
True |False |text_block_1/dense_block_1/use_batchnorm
1 |1 |text_block_1/dense_block_1/num_layers
1024 |512 |text_block_1/dense_block_1/units_0
0.5 |0 |text_block_1/dense_block_1/dropout
64 |256 |text_block_1/dense_block_1/units_1Epoch 1/1000
75/75 [==============================] - 12s 115ms/step - loss: 8.0654 - accuracy: 0.0000e+00 - val_loss: 467.1426 - val_accuracy: 0.0000e+00
Epoch 2/1000
75/75 [==============================] - 8s 103ms/step - loss: 6.8244 - accuracy: 0.0967 - val_loss: 272.3265 - val_accuracy: 0.0000e+00
Epoch 3/1000
75/75 [==============================] - 6s 86ms/step - loss: 2.3318 - accuracy: 0.5792 - val_loss: 353.9221 - val_accuracy: 0.0000e+00
Epoch 4/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.5466 - accuracy: 0.9150 - val_loss: 392.8975 - val_accuracy: 0.0000e+00
Epoch 5/1000
75/75 [==============================] - 8s 104ms/step - loss: 0.2716 - accuracy: 0.9563 - val_loss: 268.3076 - val_accuracy: 0.0000e+00
Epoch 6/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.1708 - accuracy: 0.9708 - val_loss: 304.3133 - val_accuracy: 0.0000e+00
Epoch 7/1000
75/75 [==============================] - 6s 87ms/step - loss: 0.1353 - accuracy: 0.9742 - val_loss: 352.0239 - val_accuracy: 0.0000e+00
Epoch 8/1000
75/75 [==============================] - 6s 87ms/step - loss: 0.0840 - accuracy: 0.9850 - val_loss: 313.1510 - val_accuracy: 0.0000e+00
Epoch 9/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0726 - accuracy: 0.9858 - val_loss: 315.7093 - val_accuracy: 0.0000e+00
Epoch 10/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0571 - accuracy: 0.9896 - val_loss: 328.4327 - val_accuracy: 0.0000e+00
Epoch 11/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0457 - accuracy: 0.9921 - val_loss: 278.0609 - val_accuracy: 0.0000e+00
Epoch 12/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0606 - accuracy: 0.9896 - val_loss: 463.8227 - val_accuracy: 0.0000e+00
Epoch 13/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0290 - accuracy: 0.9942 - val_loss: 336.2177 - val_accuracy: 0.0000e+00
Epoch 14/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0212 - accuracy: 0.9962 - val_loss: 320.1093 - val_accuracy: 0.0000e+00
Epoch 15/1000
75/75 [==============================] - 8s 103ms/step - loss: 0.0166 - accuracy: 0.9962 - val_loss: 257.0939 - val_accuracy: 0.0000e+00
Epoch 16/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0179 - accuracy: 0.9954 - val_loss: 371.0593 - val_accuracy: 0.0000e+00
Epoch 17/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0153 - accuracy: 0.9967 - val_loss: 347.0213 - val_accuracy: 0.0000e+00
Epoch 18/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0158 - accuracy: 0.9975 - val_loss: 348.9128 - val_accuracy: 0.0000e+00
Epoch 19/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0222 - accuracy: 0.9942 - val_loss: 387.7633 - val_accuracy: 0.0000e+00
Epoch 20/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0113 - accuracy: 0.9987 - val_loss: 371.1013 - val_accuracy: 0.0000e+00
Epoch 21/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0067 - accuracy: 0.9996 - val_loss: 271.1282 - val_accuracy: 0.0000e+00
Epoch 22/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0147 - accuracy: 0.9975 - val_loss: 355.8381 - val_accuracy: 0.0000e+00
Epoch 23/1000
75/75 [==============================] - 8s 103ms/step - loss: 0.0046 - accuracy: 1.0000 - val_loss: 204.0495 - val_accuracy: 0.0000e+00
Epoch 24/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0083 - accuracy: 0.9992 - val_loss: 272.5107 - val_accuracy: 0.0000e+00
Epoch 25/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0062 - accuracy: 0.9992 - val_loss: 314.7820 - val_accuracy: 0.0000e+00
Epoch 26/1000
75/75 [==============================] - 6s 87ms/step - loss: 0.0186 - accuracy: 0.9975 - val_loss: 384.4933 - val_accuracy: 0.0000e+00
Epoch 27/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0121 - accuracy: 0.9987 - val_loss: 426.2129 - val_accuracy: 0.0000e+00
Epoch 28/1000
75/75 [==============================] - 6s 87ms/step - loss: 0.0061 - accuracy: 0.9996 - val_loss: 496.2940 - val_accuracy: 0.0000e+00
Epoch 29/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0148 - accuracy: 0.9975 - val_loss: 494.6873 - val_accuracy: 0.0000e+00
Epoch 30/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0141 - accuracy: 0.9975 - val_loss: 678.3535 - val_accuracy: 0.0000e+00
Epoch 31/1000
75/75 [==============================] - 6s 87ms/step - loss: 0.0123 - accuracy: 0.9975 - val_loss: 675.3771 - val_accuracy: 0.0000e+00
Epoch 32/1000
75/75 [==============================] - 6s 86ms/step - loss: 0.0124 - accuracy: 0.9979 - val_loss: 683.1956 - val_accuracy: 0.0000e+00
Epoch 33/1000
75/75 [==============================] - 6s 87ms/step - loss: 0.0090 - accuracy: 0.9992 - val_loss: 617.5909 - val_accuracy: 0.0000e+00Trial 9 Complete [00h 03m 46s]
val_loss: 204.0495147705078Best val_loss So Far: 7.96969747543335
Total elapsed time: 00h 13m 37s
这个是第 9 次训练的输出,其他输出都跟这个差不多就不截取出来了。可以看到训练损失率低,准确度高,但是验证的损失率高,准确率低。这可不是什么好事儿,这个结果证明目前的模型存在过拟合的情况(估计是因为训练的数据太少所致的)。过拟合会导致模型过度依赖于训练数据的特定特征和噪声,而未能泛化到其他数据。
话虽这样,但至少证明方向是对的,如果继续走这条路的话后面就加大泛化数据训练就好。但这个并非最终目标,后面我会用 transformer 对中药材数据进行重新训练,届时将会再增加训练数据量级,等有具体结果我会再更新人工智能系列的文章,我们 transformer 再见。
相关文章:
【AutoML】AutoKeras 进行 RNN 循环神经网络训练
由于最近这些天都在人工审查之前的哪些问答数据,所以迟迟都没有更新 AutoKeras 的训练结果。现在那部分数据都已经整理好了,20w 的数据最后能够使用的高质量数据只剩下 2k。这 2k 的数据已经经过数据校验并且对部分问题的提问方式和答案内容进行了不改变…...

H12-821_74
74.在某路由器上查看LSP,看到如下结果: A.发送目标地址为3.3.3.3的数据包时,打上标签1026,然后发送。 B.发送目标地址为4.4.4.4的数据包时,不打标签直接发送。 C.当路由器收到标签为1024的数据包,将把标签…...

有趣儿的组件(HTML/CSS)
分享几个炫酷的组件,起飞~~ 评论区留爪,继续分享哦~ 文章目录 1. 按钮2. 输入3. 工具提示4. 单选按钮5. 加载中 1. 按钮 HTML: <button id"btn">Button</button>CSS: button {padding: 10px 20px;text-tr…...
)
1、深度学习环境配置相关下载地址整理(cuda、cudnn、torch、miniconda、pycharm、torchvision等)
一、深度学习环境配置相关: 1、cuda:https://developer.nvidia.com/cuda-toolkit-archive 2、cudnn:https://developer.nvidia.com/rdp/cudnn-archive 4、miniconda:https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/?C…...
Spring Boot3自定义异常及全局异常捕获
⛰️个人主页: 蒾酒 🔥系列专栏:《spring boot实战》 🌊山高路远,行路漫漫,终有归途。 目录 前置条件 目的 主要步骤 定义自定义异常类 创建全局异常处理器 手动抛出自定义异常 前置条件 已经初始化好一个…...
【python】网络爬虫与信息提取--Beautiful Soup库
Beautiful Soup网站:https://www.crummy.com/software/BeautifulSoup/ 作用:它能够对HTML.xml格式进行解析,并且提取其中的相关信息。它可以对我们提供的任何格式进行相关的爬取,并且可以进行树形解析。 使用原理:它能…...

谷歌浏览器,如何将常用打开的网站创建快捷方式到电脑桌面?
打开谷歌浏览器,打开想要创建的快捷方式的网页 点击浏览器右上角的三个点: 点击选择【更多工具】 选择【创建快捷方式】 然后,在浏览器上方会弹出一个框,让命名此创建的快捷方式的名称 命名好之后,再点击【创…...

产品经理面试题解析:业务架构是通往成功的关键吗?
大家好,我是小米!今天我要和大家聊的是产品经理面试中的一个热门话题:“业务架构”!相信不少小伙伴在准备面试的时候都会遇到这个问题,究竟什么是业务架构?它又与产品经理的工作有着怎样的关系呢࿱…...

【蓝桥杯】灭鼠先锋
一.题目描述 二.解题思路 博弈论: 只能转移到必胜态的,均为必败态。 可以转移到必败态的,均为必胜肽。 最优的策略是,下一步一定是必败态。 #include<iostream> #include<map> using namespace std;map<string,bo…...
)
2024年华为OD机试真题-求字符串中所有整数的最小和-Python-OD统一考试(C卷)
题目描述: 输入字符串s,输出s中包含所有整数的最小和 说明 1. 字符串s,只包含 a-z A-Z +- ; 2. 合法的整数包括 1) 正整数 一个或者多个0-9组成,如 0 2 3 002 102 2)负整数 负号 - 开头,数字部分由一个或者多个0-9组成,如 -0 -012 -23 -00023 输入描述: 包含…...
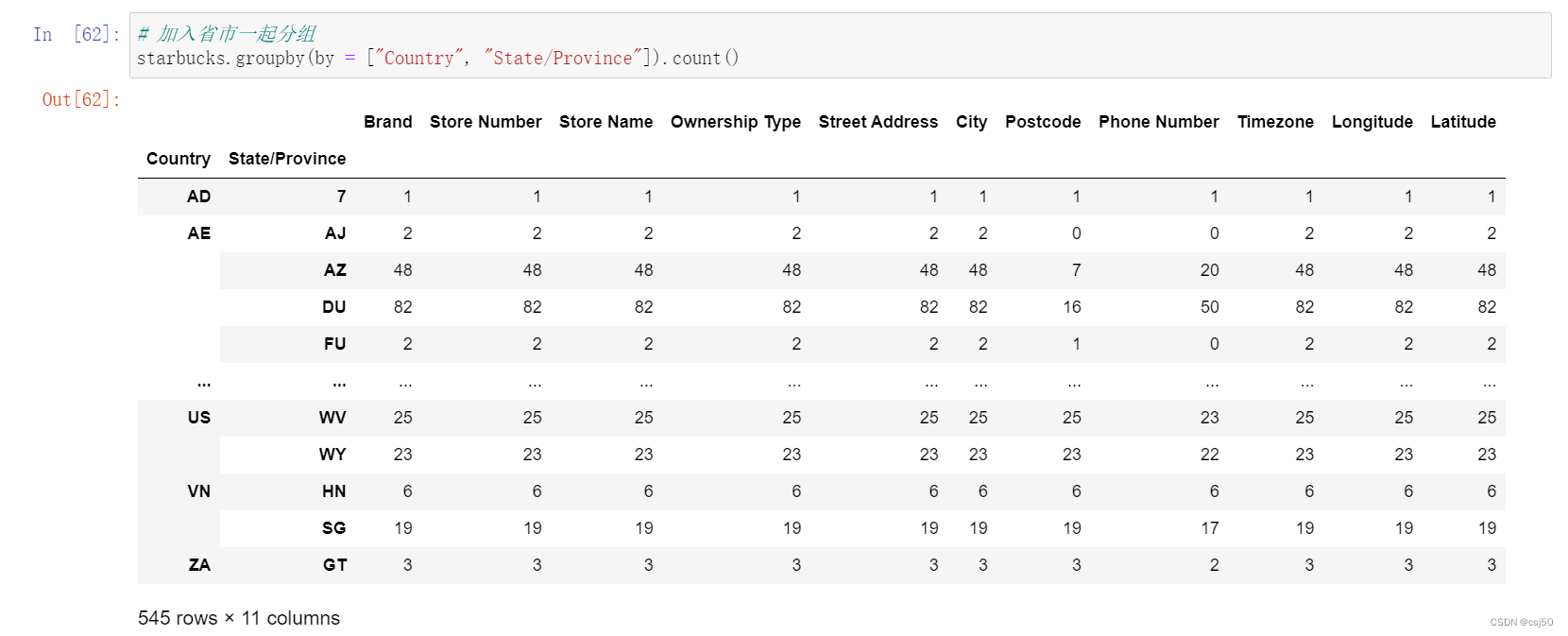
数据分析基础之《pandas(7)—高级处理2》
四、合并 如果数据由多张表组成,那么有时候需要将不同的内容合并在一起分析 1、先回忆下numpy中如何合并 水平拼接 np.hstack() 竖直拼接 np.vstack() 两个都能实现 np.concatenate((a, b), axis) 2、pd.concat([data1, data2], axis1) 按照行或者列…...

fluent脱硝SCR相对标准偏差、氨氮比、截面速度计算
# -*- coding: utf-8 -*- """ Created on Wed Sep 20 20:40:30 2023 联系QQ:3123575367,专业SCR脱硝仿真。 该程序用来处理fluent通过export-solution-ASCII-Space导出的数据,可计算标准偏差SD、相对标准偏差RSD,适用于求解平面的相对均匀…...
(A~E))
Codeforces Round 925 (Div. 3)(A~E)
题目暂时是AC,现在是Hack阶段,代码仅供参考。 A. Recovering a Small String 题目给出的n都可以由字母来组成,比如4可以是aab,字母里面排第一个和第二个,即1124。但是会歧义,比如aba为1214,也是…...

@RequestBody、@RequestParam、@RequestPart使用方式和使用场景
RequestBody和RequestParam和RequestPart使用方式和使用场景 1.RequestBody2.RequestParam3.RequestPart 1.RequestBody 使用此注解接收参数时,适用于请求体格式为 application/json,只能用对象接收 2.RequestParam 接收的参数是来自HTTP 请求体 或 请…...
LeetCode、1143. 最长公共子序列【中等,二维DP】
文章目录 前言LeetCode、1143. 最长公共子序列【中等,二维DP】题目链接与分类思路2022年暑假学习思路及题解二维DP解决 资料获取 前言 博主介绍:✌目前全网粉丝2W,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者…...
162基于matlab的多尺度和谱峭度算法对振动信号进行降噪处理
基于matlab的多尺度和谱峭度算法对振动信号进行降噪处理,选择信号峭度最大的频段进行滤波,输出多尺度谱峭度及降噪结果。程序已调通,可直接运行。 162 matlab 信号处理 多尺度谱峭度 (xiaohongshu.com)...

Android Studio六大基本布局的概览和每个布局的关键特性以及实例分析
1. 线性布局 (LinearLayout) 描述: 线性布局是一种按指定方向(水平或垂直)排列其子视图的布局容器。通过android:orientation属性可设置为horizontal或vertical。 关键属性: android:orientation: 指定布局方向。android:layout_weight: 子视图权重,用于分配剩余空间。示…...

【go语言】一个简单HTTP服务的例子
一、Go语言安装 Go语言(又称Golang)的安装过程相对简单,下面是在不同操作系统上安装Go语言的步骤: 在Windows上安装Go语言: 访问Go语言的官方网站(golang.org)或者使用国内镜像站点࿰…...

LeetCode Python - 15.三数之和
目录 题目答案运行结果 题目 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意:答案中不可…...
C#中implicit和explicit
理解: 使用等号代替构造函数调用的效果以类似重载操作符的形式定义用于类型转换的函数前者类型转换时候直接写等号赋值语法,后者要额外加目标类型的强制转换stirng str -> object o -> int a 可以 int a (int)(str as object)转换通过编译,但没有转换逻辑所以运行会报错…...

突破抖音直播回放下载限制:5大技术创新与3大实战场景全解密
突破抖音直播回放下载限制:5大技术创新与3大实战场景全解密 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

PDF补丁丁深度解析:高效PDF文档处理与批量优化完整指南
PDF补丁丁深度解析:高效PDF文档处理与批量优化完整指南 【免费下载链接】PDFPatcher PDF补丁丁——PDF工具箱,可以编辑书签、剪裁旋转页面、解除限制、提取或合并文档,探查文档结构,提取图片、转成图片等等 项目地址: https://g…...
)
别光记公式!用Python+OpenCV手把手带你标定相机内参外参(附完整代码)
别光记公式!用PythonOpenCV手把手带你标定相机内参外参(附完整代码) 在计算机视觉项目中,相机标定是构建三维感知系统的第一步。很多开发者能背诵内参矩阵的数学形式,却对如何用代码实际获取这些参数一头雾水。本文将用…...

BongoCat:让你的桌面充满生命力的互动伙伴
BongoCat:让你的桌面充满生命力的互动伙伴 【免费下载链接】BongoCat 🐱 跨平台互动桌宠 BongoCat,为桌面增添乐趣! 项目地址: https://gitcode.com/gh_mirrors/bong/BongoCat 在数字时代的今天,我们与电脑屏幕…...

BigDL-2.x DLlib深度指南:用Spark DataFrames构建分布式深度学习应用
BigDL-2.x DLlib深度指南:用Spark DataFrames构建分布式深度学习应用 【免费下载链接】BigDL-2.x BigDL: Distributed TensorFlow, Keras and PyTorch on Apache Spark/Flink & Ray 项目地址: https://gitcode.com/gh_mirrors/bi/BigDL-2.x BigDL-2.x是一…...

Smithbox终极指南:5个技巧让你轻松掌握魂系列游戏修改艺术
Smithbox终极指南:5个技巧让你轻松掌握魂系列游戏修改艺术 【免费下载链接】Smithbox Smithbox is a modding tool for Elden Ring, Armored Core VI, Sekiro, Dark Souls 3, Dark Souls 2, Dark Souls, Bloodborne and Demons Souls. 项目地址: https://gitcode.…...
Pixel Script Temple 机器学习全流程辅助:从数据清洗到模型部署脚本
Pixel Script Temple 机器学习全流程辅助:从数据清洗到模型部署脚本 1. 机器学习项目中的痛点与解决方案 在机器学习项目的实际开发中,数据科学家常常面临一个共同的困境:大量时间被消耗在重复性的代码编写和调试上,而非核心算法…...

如何用三月七小助手实现星穹铁道全自动化游戏体验
如何用三月七小助手实现星穹铁道全自动化游戏体验 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 在《崩坏:星穹铁道》的广阔宇宙中,每位开拓…...

【案例共创】码道小工匠,儿童跳绳智能计数系统开发实战
最新案例动态,请查阅【案例共创】码道小工匠,儿童跳绳智能计数系统开发实战小伙伴们快来进行实操吧! 本案例由开发者:yd_sun提供,华为开发者空间案例中心优化并收录。 一、概述 1.1 适用对象 个人开发者高校学生企…...

从零构建:麦克纳姆轮底盘的运动学模型与O-长方形布局解析
1. 麦克纳姆轮基础原理与结构解析 第一次接触麦克纳姆轮时,我被它那酷似"风火轮"的外观吸引了。这种特殊设计的轮子由瑞典工程师Bengt Ilon在1973年发明,如今已成为移动机器人领域的明星组件。让我带你从最基础的物理结构开始,逐步…...