杂谈--spconv导出中onnx的扩展阅读
Onnx 使用
Onnx 介绍

Onnx (Open Neural Network Exchange) 的本质是一种 Protobuf 格式文件,通常看到的 .onnx 文件其实就是通过 Protobuf 序列化储存的文件。onnx-ml.proto 通过 protoc (Protobuf 提供的编译程序) 编译得到 onnx-ml.pb.h 和 onnx-ml.pb.cc 或 onnx_ml_pb2.py,然后用 onnx_ml.pb.cc 和代码来操作 onnx 模型文件,实现增删改操作。onnx-ml.proto 则是描述 onnx 文件如何组成和结构,用于作为操控 onnx 的参照。但是这个.proto 文件(里面用的是 protobuf 语法)只是一个中间表示文件,不具备任何能力,即并不面向存储和传输(序列化,反序列化,读写)。所以需要用 protoc 编译 .proto 文件,是将 .proto 文件编译成不同语言的实现,得到 .cc 和 .py 文件这两个接口文件,这样不同语言中的数据就可以和自定义的结构化数据格式的数据进行交互。
onnx-ml.proto
查看 onnx-ml.proto 文件可以看到每个 proto 的不同的数据结构,message 就是结构化数据的关键字,用于描述数据的字段、类型和层次结构。之后加载了 onnx 模型后,就可以按照这个文件内部记录的数据结构来访问模型中的数据。

使用 repeated 就表示内部的属性是数组,使用 optional 就表示数据可选。NodeProto 中 input 就是一个数组,其中储存着 string,需要使用索引访问,name 就是一个 string。这些参数后面的数值表示每个属性特定的 id,这些 id 是不能冲突的,官方已经指定好了。
Onnx 结构
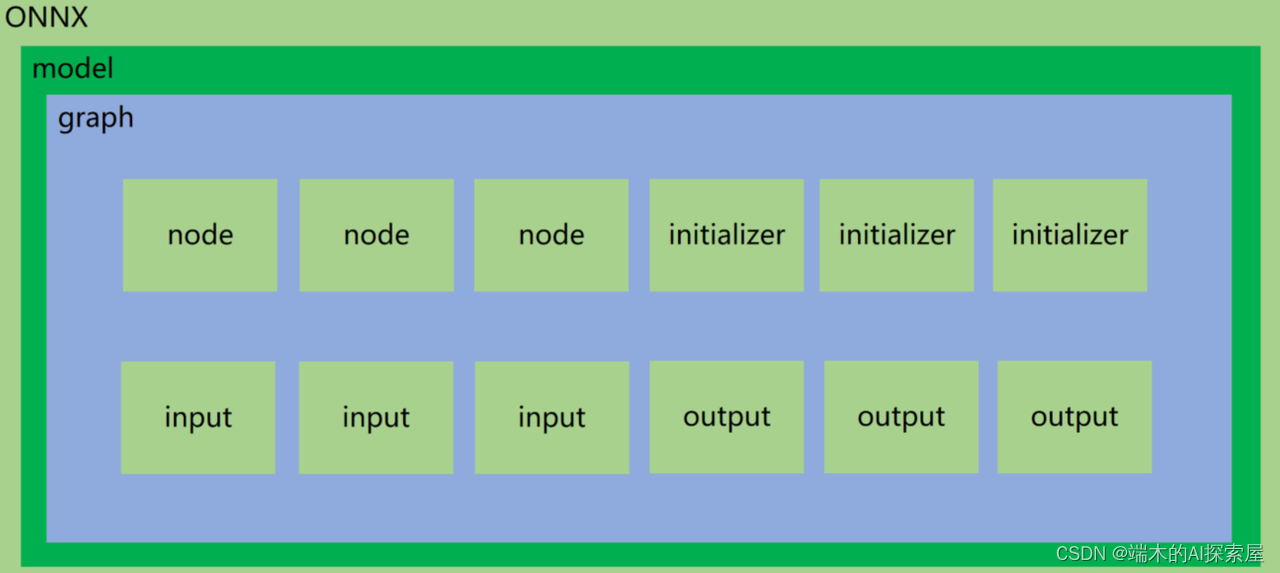
-
onnx.model: 这是一个具体的 ONNX 模型实例,它是一个
ModelProto对象,可以通过onnx.helper.make_model来构建。它包含了模型的所有信息,包括元数据、图(graph)、初始参数等。代码中对应ModelProto,其中opset_import是OperatorSetIdProto数据结构的数组;graph是GraphProto数据结构,一个 model 对应一个 graph。 -
onnx.model.graph: 这是 onnx 模型的计算图,它是一个
GraphProto对象,可以通过onnx.helper.make_graph来构建。计算图是一种描述模型计算过程的图形结构,它由一系列的节点 (node) 组成,这些节点代表了模型中的各种操作 (如卷积、激活函数等)。代码中对应GraphProto,其中node是NodeProto数据结构的数组;initializer是一个TensorProto数据结构的数组;sparse_initializer是一个SparseTensorProto数据结构的数组;input、output和value_info是ValueInfoProto数据结构的数组。 -
onnx.model.graph.node: 这是计算图中的一个节点,它是一个
NodeProto对象,可以通过onnx.helper.make_node。每个节点代表了一个操作,它有一定数量的输入和输出,这些输入和输出都是张量。节点还有一个操作类型 (如"Conv"、"Relu"等) 和一些特定的参数 (如卷积核的大小、步长、填充等)。代码中对应NodeProto,其中input和output是string类型数组;attribute是一个AttributeProto数据结构,用于定义 node 属性,常见用法是将 (key, value) 传入 Proto 中;op_type是一个string,需要对应 onnx 提供的 operators。 -
onnx.model.graph.initializer: 这是模型的初始化参数,它是一个
TensorProto对象,可以通过onnx.helper.make_tensor。每个TensorProto对象都包含了一个张量的所有信息,包括数据类型、形状、数据等。模型的所有权重和偏置都包含在这个列表中。代码中对应TensorProto,其中dims是int64类型数组;raw_data是bytes类型。 -
onnx.model.graph.input/output: 这是模型的输入/输出信息,它是一个
ValueInfoProto对象,可以通过onnx.helper.make_value_info或onnx.helper.make_tensor_value_info。每个ValueInfoProto对象描述了一个输入/输出的信息,包括名称、数据类型、形状等。主要是用于标记哪些节点是输入/输出。代码中对应ValueInfoProto,其中type是一个TypeProto数据结构,内部定义了标准 onnx 数据类型。
ONNX 模型的计算图中的节点可以有多种类型,其中包括 Constant,表示一种特殊的操作,它的作用是在计算过程中提供一个常量张量。这种常量张量的值在模型训练过程中不会改变,因此被视为常量。例如,对于大小为 (bs, N, H, W, 2) 的 anchorgrid 张量(其中,bs 是批处理大小,N 是锚框(anchor box)的种类数量,H 和 W 分别代表特征图的高度和宽度,最后的** 2 **代表每个锚框的宽度和高度),它可以被存储在一个 Constant 类型的节点中。值得注意的是,当使用ONNX图形可视化工具(如Netron)时,Constant 类型的节点可能不会显示出来。这是因为这些节点并不涉及任何计算操作,只是提供了一个常量张量。
另外,还有一种类型为"Identity"的节点。"Identity"节点表示一种标识操作,它的输出和输入完全相同。这种节点通常用于在需要保持计算图结构完整性的情况下,将某些张量传递到计算图的下一层。换句话说,它不会改变传递给它的任何信息,可以被视为一个透明的或者无操作的节点。
Onnx 模型生成
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.onnx
import osclass Model(torch.nn.Module):def __init__(self):super().__init__()self.conv = nn.Conv2d(1, 1, 3, padding=1)self.relu = nn.ReLU()self.conv.weight.data.fill_(1)self.conv.bias.data.fill_(0)def forward(self, x):x = self.conv(x)x = self.relu(x)return x# 这个包对应opset11的导出代码,如果想修改导出的细节,可以在这里修改代码
# import torch.onnx.symbolic_opset11
print("对应opset文件夹代码在这里:", os.path.dirname(torch.onnx.__file__))model = Model()#dummy如果改成torch.zeros(8, 1, 3, 3),对生成的onnx图是没有影响的
dummy = torch.zeros(1, 1, 3, 3)#生成的onnx图的conv算子的bias为1,这是由输出通道数决定的,因为输出通道为1
torch.onnx.export(model, # 这里的args,是指输入给model的参数,需要传递tuple,因此用括号(dummy,), # 储存的文件路径"demo.onnx", # 打印详细信息verbose=True, # 为输入和输出节点指定名称,方便后面查看或者操作input_names=["image"], output_names=["output"], # 这里的opset,指,各类算子以何种方式导出,对应于symbolic_opset11opset_version=11, # 表示他有batch、height、width3个维度是动态的,在onnx中给其赋值为-1# 通常,我们只设置batch为动态,其他的避免动态dynamic_axes={"image": {0: "batch", 2: "height", 3: "width"},"output": {0: "batch", 2: "height", 3: "width"},}
)print("Done.!")
Onnx 模型加载
import onnx
import onnx.helper as helper
import numpy as npmodel = onnx.load("demo.onnx")#打印信息
print("==============node信息")
# print(helper.printable_graph(model.graph))
print(model)conv_weight = model.graph.initializer[0]
conv_bias = model.graph.initializer[1]# initializer里有dims这个属性是可以通过打印model看到的
# dims在onnx-ml.proto文件中是repeated类型的,即数组类型,所以要用索引去取!
print(conv_weight.dims)
# 取node节点的第一个元素
print(f"===================={model.graph.node[1].name}==========================")
print(model.graph.node[1])# 数据是以protobuf的格式存储的,因此当中的数值会以bytes的类型保存,通过np.frombuffer方法还原成类型为float32的ndarray
print(f"===================={conv_weight.name}==========================")
print(conv_weight.name, np.frombuffer(conv_weight.raw_data, dtype=np.float32))print(f"===================={conv_bias.name}==========================")
print(conv_bias.name, np.frombuffer(conv_bias.raw_data, dtype=np.float32))
==============node信息
ir_version: 6
producer_name: "pytorch"
producer_version: "1.13.1"
graph {node {input: "image"input: "conv.weight"input: "conv.bias"output: "/conv/Conv_output_0"name: "/conv/Conv"op_type: "Conv"attribute {name: "dilations"ints: 1ints: 1type: INTS}attribute {name: "group"i: 1type: INT}attribute {name: "kernel_shape"ints: 3ints: 3type: INTS}attribute {name: "pads"ints: 1ints: 1ints: 1ints: 1type: INTS}attribute {name: "strides"ints: 1ints: 1type: INTS}}node {input: "/conv/Conv_output_0"output: "output"name: "/relu/Relu"op_type: "Relu"}name: "torch_jit"initializer {dims: 1dims: 1dims: 3dims: 3data_type: 1name: "conv.weight"raw_data: "\000\000\200?\000\000\200?\000\000\200?\000\000\200?\000\000\200?\000\000\200?\000\000\200?\000\000\200?\000\000\200?"}initializer {dims: 1data_type: 1name: "conv.bias"raw_data: "\000\000\000\000"}input {name: "image"type {tensor_type {elem_type: 1shape {dim {dim_param: "batch"}dim {dim_value: 1}dim {dim_param: "height"}dim {dim_param: "width"}}}}}output {name: "output"type {tensor_type {elem_type: 1shape {dim {dim_param: "batch"}dim {dim_value: 1}dim {dim_param: "height"}dim {dim_param: "width"}}}}}
}
opset_import {version: 11
}[1, 1, 3, 3]
====================/relu/Relu==========================
input: "/conv/Conv_output_0"
output: "output"
name: "/relu/Relu"
op_type: "Relu"====================conv.weight==========================
conv.weight [1. 1. 1. 1. 1. 1. 1. 1. 1.]
====================conv.bias==========================
conv.bias [0.]
这个是 TensorProto 中使用的数据类型,initializer 中的 data_type 为 1 就表示数据类型为 FLOAT。
https://github.com/onnx/onnx/blob/v1.2.1/onnx/onnx-ml.proto#L88
https://onnx.ai/onnx/search.html?q=SparseConvolution&check_keywords=yes&area=default#

通过 helper 自定义 Onnx 模型
import onnx # pip install onnx>=1.10.2
import onnx.helper as helper
import numpy as np# https://github.com/onnx/onnx/blob/v1.2.1/onnx/onnx-ml.protonodes = [helper.make_node(name="Conv_0", # 节点名字,不要和op_type搞混了op_type="Conv", # 节点的算子类型, 比如'Conv'、'Relu'、'Add'这类,详细可以参考onnx给出的算子列表inputs=["image", "conv.weight", "conv.bias"], # 各个输入的名字,结点的输入包含:输入和算子的权重。必有输入X和权重W,偏置B可以作为可选。outputs=["3"], pads=[1, 1, 1, 1], # 其他字符串为节点的属性,attributes在官网被明确的给出了,标注了default的属性具备默认值。group=1,dilations=[1, 1],kernel_shape=[3, 3],strides=[1, 1]),helper.make_node(name="ReLU_1",op_type="Relu",inputs=["3"],outputs=["output"])
]initializer = [helper.make_tensor(name="conv.weight",data_type=helper.TensorProto.DataType.FLOAT,dims=[1, 1, 3, 3],vals=np.array([1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0], dtype=np.float32).tobytes(),raw=True),helper.make_tensor(name="conv.bias",data_type=helper.TensorProto.DataType.FLOAT,dims=[1],vals=np.array([0.0], dtype=np.float32).tobytes(),raw=True)
]inputs = [helper.make_value_info(name="image",type_proto=helper.make_tensor_type_proto(elem_type=helper.TensorProto.DataType.FLOAT,shape=["batch", 1, 3, 3]))
]outputs = [helper.make_value_info(name="output",type_proto=helper.make_tensor_type_proto(elem_type=helper.TensorProto.DataType.FLOAT,shape=["batch", 1, 3, 3]))
]graph = helper.make_graph(name="mymodel",inputs=inputs,outputs=outputs,nodes=nodes,initializer=initializer
)# 如果名字不是ai.onnx,netron解析就不是太一样了
opset = [helper.make_operatorsetid("ai.onnx", 11)
]# producer主要是保持和pytorch一致
model = helper.make_model(graph, opset_imports=opset, producer_name="pytorch", producer_version="1.9")
onnx.save_model(model, "my.onnx")print(model)
print("Done.!")
Extra
pytorch_quantization.tensor_quant
该模块是用于对张量量化的,通常会使用 QuantDescriptor、TensorQuantFunction 和 FakeTensorQuantFunction。第一个为张量描述器,后面两个是用于对张量进行量化。TensorQuantFunction 和 FakeTensorQuantFunction 中的前向,即量化 (Quantization) 由_tensor_quant 进行计算,反向就是反量化 (Dequantization)。
TensorQuantFunction 和 FakeTensorQuantFunction 代码介绍:
前向:
- TensorQuantFunction 和 FakeTensorQuantFunction 在前向中的操作基本相同的,TensorQuantFunction 会对输入为 torch.half 精度的张量的 scale 进行截断操作,FakeTensorQuantFunction 中没有这样的操作。
- TensorQuantFunction 的输出是量化后的张量和 scale,FakeTensorQuantFunction 的输出仅仅是量化后的张量。
反向:
- TensorQuantFunction 和 FakeTensorQuantFunction 的反向过程是相同的。
pytorch_quantization.tensor_quant.QuantDescriptor
量化描述器,主要用于描述一个张量如何被量化,内部记录了量化方式、校准方法、缩放因子、零点等信息。
一般用于描述网络中的输入和权重。
QuantMixin 和 QuantInputMixin
QuantMixin 用于表示网络中有输入和权重,在进行量化时,要对这两个部分进行量化。
pytorch_quantization.nn.TensorQuantizer
TensorQuantizer 创建需要 Descriptor 做为入参。TensorQuantizer 通过量化描述器中的量化参数和量化方法来调用相应的量化方法从而实现对张量的量化。
Protobuf
Protocol Buffers(简称 Protobuf)是一种轻量级、高效的数据序列化格式,由 Google 开发。它旨在支持跨平台、跨语言的数据交换和存储。
Protobuf 使用一种结构化的数据描述语言来定义数据的结构和格式,这些描述文件被称为 .proto 文件。通过定义 .proto 文件,您可以指定消息的字段和数据类型,并使用 Protobuf 编译器将其转换为特定语言的类或结构体,用于在不同的编程语言中进行数据的序列化和反序列化。
与其他数据序列化格式相比,Protobuf 具有以下优势:
- 高效性:Protobuf 使用二进制编码,因此比文本格式(如 JSON、XML)更紧凑,占用更少的存储空间和网络带宽。
- 快速性:由于 Protobuf 的编解码过程是基于生成的高效代码实现的,因此比通用的解析器更快。
- 可扩展性:您可以在已定义的消息结构中添加新的字段,而不会破坏现有数据的兼容性。接收方可以选择性地忽略他们不理解的字段。
- 跨平台和跨语言支持:通过使用 Protobuf,您可以在不同的编程语言和平台之间进行数据交换,因为 Protobuf 提供了多种语言的支持,包括 C++、Java、Python、Go 等。
Protobuf 在众多领域中被广泛使用,特别是在大规模分布式系统、通信协议、数据存储和数据交换等方面。它提供了一种高效、灵活和可扩展的方式来处理结构化数据。
append_initializer 函数介绍
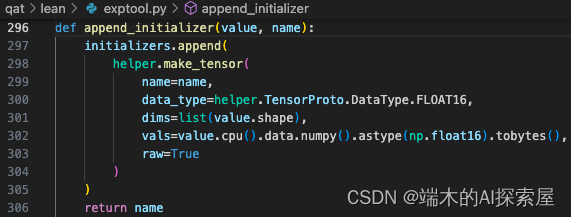
入参:
- value 是模型当前模块的权重,维度经过 permute 之后 KIO 变为 OKI。
- name 用于描述初始化是特定层的权重或偏置。
返回:
- 将 name 作为函数返回值
这里在 initializers 中添加了一个 TensorProto 对象,主要是用于记录权重和偏置的信息,其中记录了数据名称、类型、维度和数值。这里的 name 需要设置为唯一的,不能与其他相同的数据结构的 name 重复。这里的 dims 需要使用 list 来储存,是因为在 TensorProto 数据结构中,是使用 repeated int64 来定义的。raw 设置为了 True,这里的 vals 就需要转换为 bytes 类型,如果是 False,就只需要转换为 np.float16 类型。
make_node 函数介绍
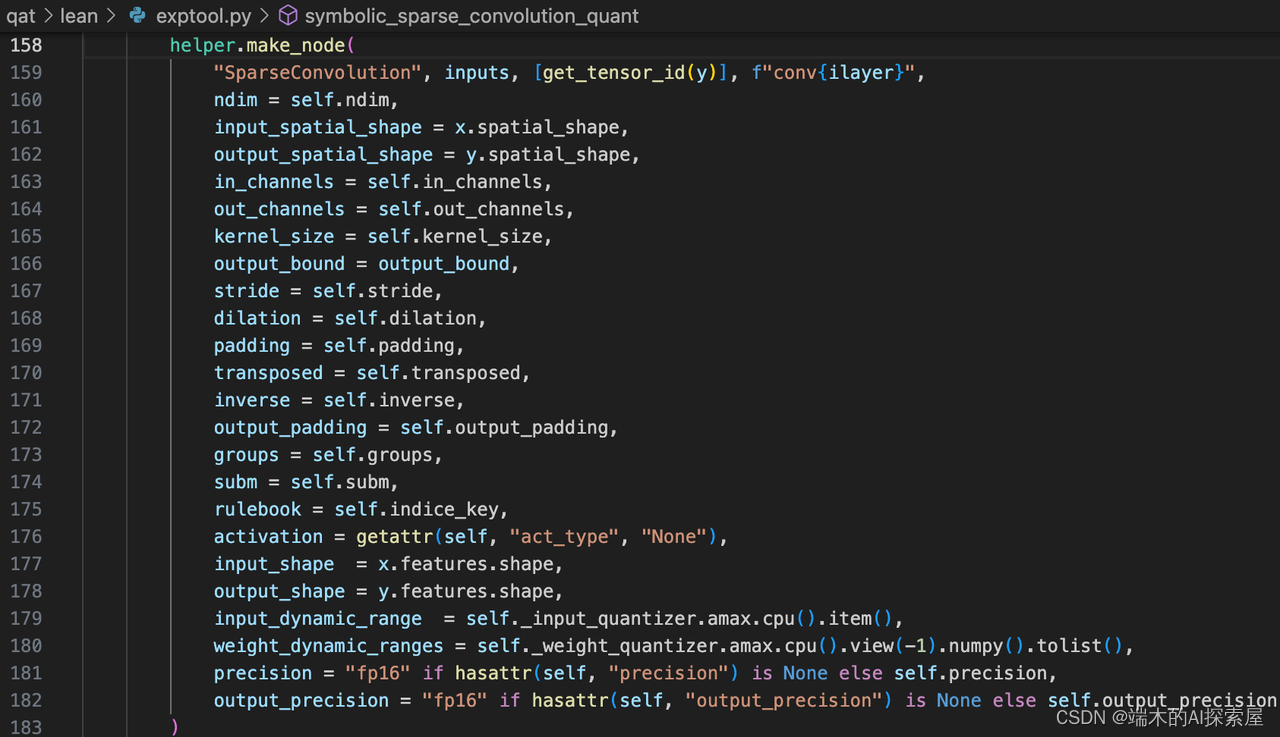
通过 make_node 函数可以创建一个 NodeProto 对象,这个节点会记录了指定的操作,用于之后生成 GraphProto 对象表示计算图。
以上面这段代码为例,先介绍一下参数的含义:
- ops_type:数据类型为 str,该参数需要设置为特定的官方操作类型名称,当前的 ops_type 为 “SparseConvolution”,这里使用了自定义的操作,并不是官方提供的默认操作。
- input/output:数据类型为 list[str],该参数表示节点的输入/输出的名称,当前的 input 为 [‘0’, ‘spconv0.weight’, ‘spconv0.bias’],output 为 [‘1’]。
- name: 数据类型为可选的 str,该参数表示节点的名称,当前的 names 为 conv0。
- doc_string: 数据类型为可选的 str,用于提供节点的文档字符串 (Documentation String),用于描述节点的功能和用途。它对于理解和解释节点的作用非常有用。可以使用该参数为节点添加描述性的文本。这里没有设置该参数。
- domain: 数据类型为可选的 str,指定节点所属的域(Domain)。域是用于标识特定领域或框架的字符串。不同的域可能有不同的操作类型和语义。默认情况下,节点属于 ONNX 的主要域。如果要使用特定域的扩展或自定义操作类型,可以指定相应的域。例如,“com.example.custom” 表示自定义域。域的使用可以帮助在不同框架之间进行模型转换和兼容性。
- **kwargs: 数据类型为 dict,用于描述节点的属性,这里用于储存当前稀疏卷积模块的属性。
相关文章:
杂谈--spconv导出中onnx的扩展阅读
Onnx 使用 Onnx 介绍 Onnx (Open Neural Network Exchange) 的本质是一种 Protobuf 格式文件,通常看到的 .onnx 文件其实就是通过 Protobuf 序列化储存的文件。onnx-ml.proto 通过 protoc (Protobuf 提供的编译程序) 编译得到 onnx-ml.pb.h 和 onnx-ml.pb.cc 或 on…...
-Linux ARM驱动编程第二天-arm ads下的start.S分析(物联技术666))
嵌入式培训机构四个月实训课程笔记(完整版)-Linux ARM驱动编程第二天-arm ads下的start.S分析(物联技术666)
链接:https://pan.baidu.com/s/1E4x2TX_9SYhxM9sWfnehMg?pwd1688 提取码:1688 ; ; NAME: 2440INIT.S ; DESC: C start up codes ; Configure memory, ISR ,stacks ; Initialize C-variables ; 完全注释 ; HISTORY: ; 2002.02.25:kwtark: ver 0.…...
STL之list容器的介绍与模拟实现+适配器
STL之list容器的介绍与模拟实现适配器 1. list的介绍2. list容器的使用2.1 list的定义2.2 list iterator的使用2.3 list capacity2.4 list element access2.5 list modifiers2.6 list的迭代器失效 3. list的模拟实现3.1 架构搭建3.2 迭代器3.2.1 正向迭代器3.2.2反向迭代器适配…...

Leetcode With Golang 二叉树 part1
这一部分主要来梳理二叉树题目最简单最基础的部分,包括遍历,一些简单题目。 一、Leecode 144 - 二叉树的前序遍历 https://leetcode.cn/problems/binary-tree-preorder-traversal/description/ 二叉树的遍历是入门。我们需要在程序一开始就创建一个空…...
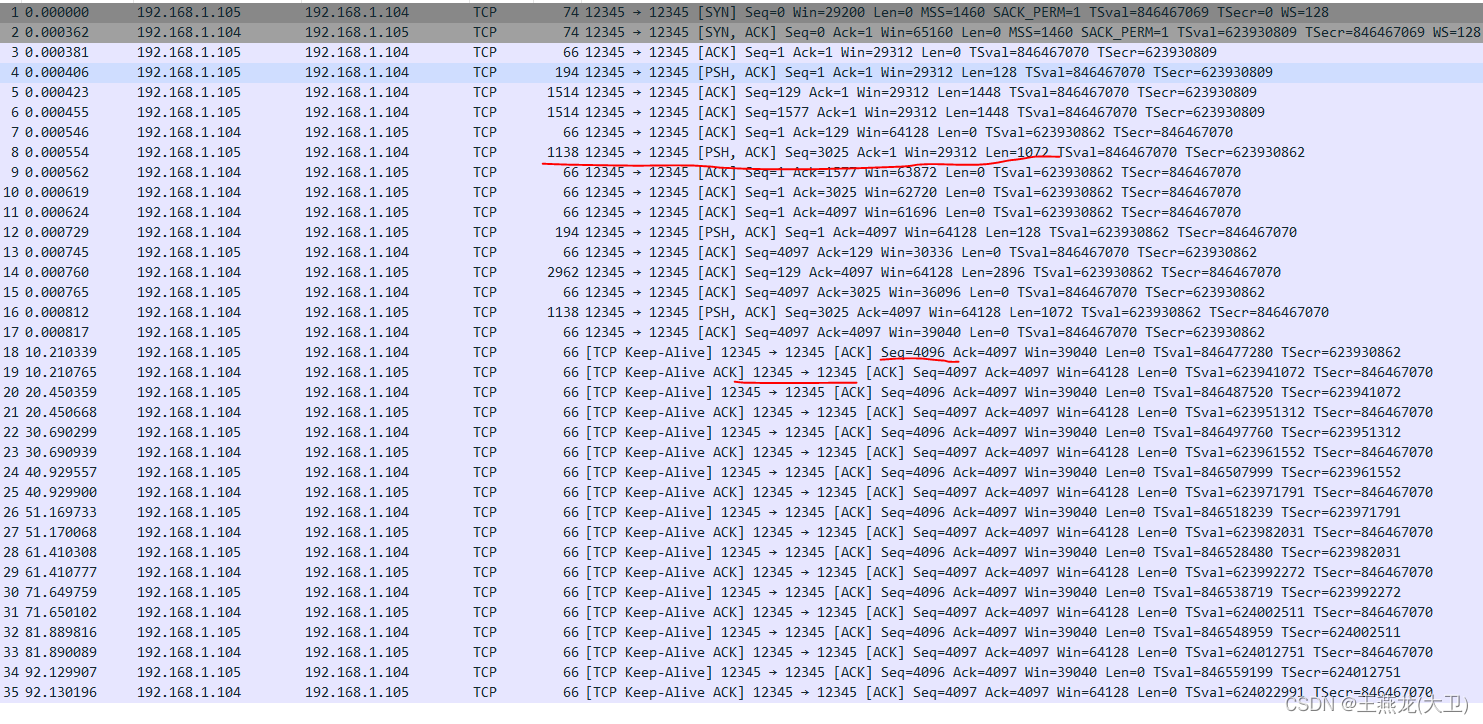
tcp 中使用的定时器
定时器的使用场景主要有两种。 (1)周期性任务 这是定时器最常用的一种场景,比如 tcp 中的 keepalive 定时器,起到 tcp 连接的两端保活的作用,周期性发送数据包,如果对端回复报文,说明对端还活着…...

黑马Java——IO流
一、IO流的概述 IO流:存储和读取数据的解决方案 IO流和File是息息相关的 1、IO流的分类 1.1、纯文本文件 word、Excel不是纯文本文件 而txt或者md文件是纯文本文件 2、小结 二、IO流的体系结构 三、字节流 1、FileOutputStream(字节输出流ÿ…...

re:从0开始的CSS学习之路 11. 盒子垂直布局
1. 盒子的垂直布局的注意 若两个“相邻”垂直摆放的盒子,上面盒子的下外边距与下面盒子的上外边距会发生重叠,称为外边距合并 若合并后,外边距会选择重叠外边距的较大值 若两个盒子具有父子关系,则两个盒子的上外边距会发生重叠&…...

Kindling-OriginX 如何集成 DeepFlow 的数据增强网络故障的解释力
DeepFlow 是基于 eBPF 的可观测性开源项目,旨在为复杂的云基础设施及云原生应用提供深度可观测性。DeepFlow 基于 eBPF 采集了精细的链路追踪数据和网络、应用性能指标,其在网络路径上的全链路覆盖能力和丰富的 TCP 性能指标能够为专业用户和网络领域专家…...
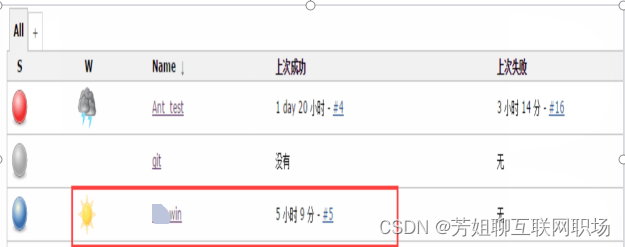
轻松掌握Jenkins执行远程window的Jmeter接口脚本
Windows环境:10.1.2.78 新建与配置节点 【系统管理】—【管理节点】—【新建节点】输入节点名称,勾选“dumb slave”,点击ok 按如上配置: 说明: Name:定义slave的唯一名称标识,可以是任意字…...
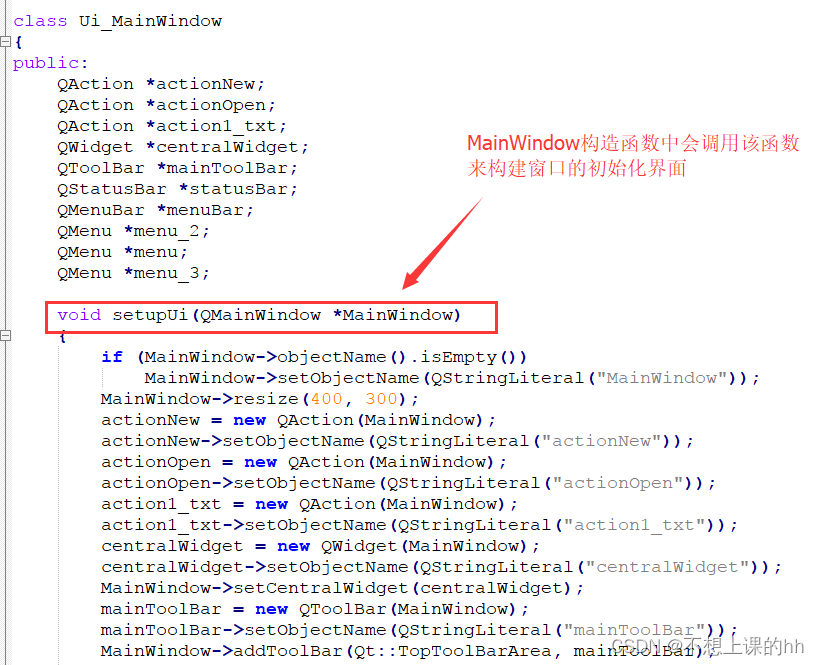
UI文件原理
使用UI文件创建界面很轻松很便捷,他的原理就是每次我们保存UI文件的时候,QtCreator就自动帮我们将UI文件翻译成C的图形界面创建代码。可以通过以下步骤查看代码 到工程编译目录,一般就是工程同级目录下会生成另一个编译目录,会找到…...
OS设备管理
设备管理 操作系统作为系统资源的管理者,其提供的功能有:处理机管理、存储器管理、文件管理、设备管理。其中前三个管理都是在计算机的主机内部管理其相对应的硬件。 I/O设备 I/O即输入/输出。I/O设备即可以将数据输入到计算机,或者可以接收…...

Matlab绘图经典代码大全:条形图、极坐标图、玫瑰图、填充图、饼状图、三维网格云图、等高线图、透视图、消隐图、投影图、三维曲线图、函数图、彗星图
学会 MATLAB 中的绘图命令对初学者来说具有重要意义,主要体现在以下几个方面: 1. 数据可视化。绘图命令是 MATLAB 中最基本也是最重要的功能之一,它可以帮助初学者将数据可视化,更直观地理解数据的分布、变化规律和趋势。通过绘制图表,可以快速了解数据的特征,从而为后续…...

姿态传感器MPU6050模块之陀螺仪、加速度计、磁力计
MEMS技术 微机电系统(MEMS, Micro-Electro-Mechanical System),也叫做微电子机械系统、微系统、微机械等,指尺寸在几毫米乃至更小的高科技装置。微机电系统其内部结构一般在微米甚至纳米量级,是一个独立的智能系统。 微…...
MySQL 基础知识(一)之数据库和 SQL 概述
目录 1 数据库相关概念 2 数据库的结构 3 SQL 概要 4 SQL 的基本书写规则 1 数据库相关概念 数据库是将大量的数据保存起来,通过计算机加工而成的可以进行高效访问的数据集合数据库管理系统(DBMS)是用来管理数据库的计算机系统…...

挑战杯 wifi指纹室内定位系统
简介 今天来介绍一下室内定位相关的原理以及实现方法; WIFI全称WirelessFidelity,在中文里又称作“行动热点”,是Wi-Fi联盟制造商的商标做为产品的品牌认证,是一个创建于IEEE 802.11标准的无线局域网技术。基于两套系统的密切相关ÿ…...

Midjourney提示词风格调试测评
在Midjourney中提示词及风格参数的变化无疑会对最终的作品产生影响,那影响具体有多大?今天我我们将通过一个示例进行探究。 示例提示词: 计算机代码海洋中的黄色折纸船(图像下方)风格参考:金色长发的女人,…...
Codeforces Round 926 (Div. 2)(A~C)
A. Sasha and the Beautiful Array 分析:说实话,打比赛的时候看到这题没多想,过了一下样例发现将数组排序一下就行,交了就过了。刚刚写题解反应过来,a2-a1a3-a2.....an-a(n-1) an - a1,所以最后结果只取决…...

Godot 游戏引擎个人评价和2024年规划(无代码)
文章目录 前言Godot C# .net core 开发简单评价Godot相关网址可行性 Godot(GDScirpt) Vs CocosGodot VS UnityUnity 的裁员Unity的股票Unity的历史遗留问题:Mono和.net core.net core的开发者,微软 个人的独立游戏Steam平台分成说明独立游戏的选题美术风…...
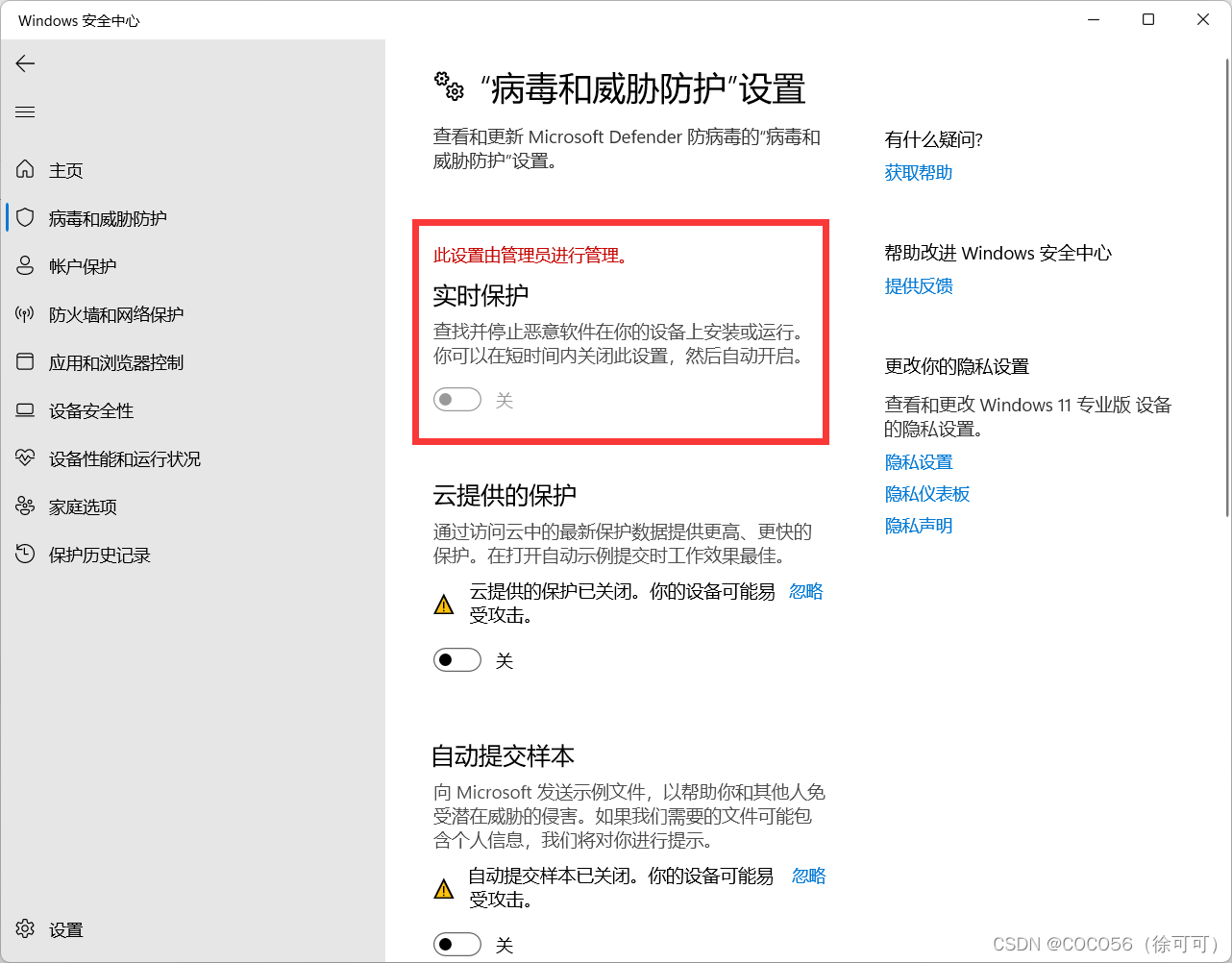
Win11关闭Windows Defender实时保护,暂时关闭和永久关闭方法 | Win10怎么永久关闭Windows Defender实时保护
文章目录 1. 按2. 暂时关闭Windows Defender实时保护3. 永久关闭实时保护 1. 按 开启Windows Defender实时保护有时候会导致系统变得异常卡顿,严重影响系统的流畅度,并且由于会有几率错误拦截和查杀我们的正常操作,所以还会导致我们的程序无…...

C# CAD2016 宗地生成界址点,界址点编号及排序
1 、界址点起点位置C# CAD2016 多边形顶点按方向重新排序 2、 界址点顺时针逆时针走向 C# CAD2016 判断多边形的方向正时针或逆时针旋转 3、块文件插入 //已知块文件名称 GXGLQTC //块文件需要插入的坐标点 scaledPoint// 插入块到当前图纸中的指定位置ObjectId newBlockId;B…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...
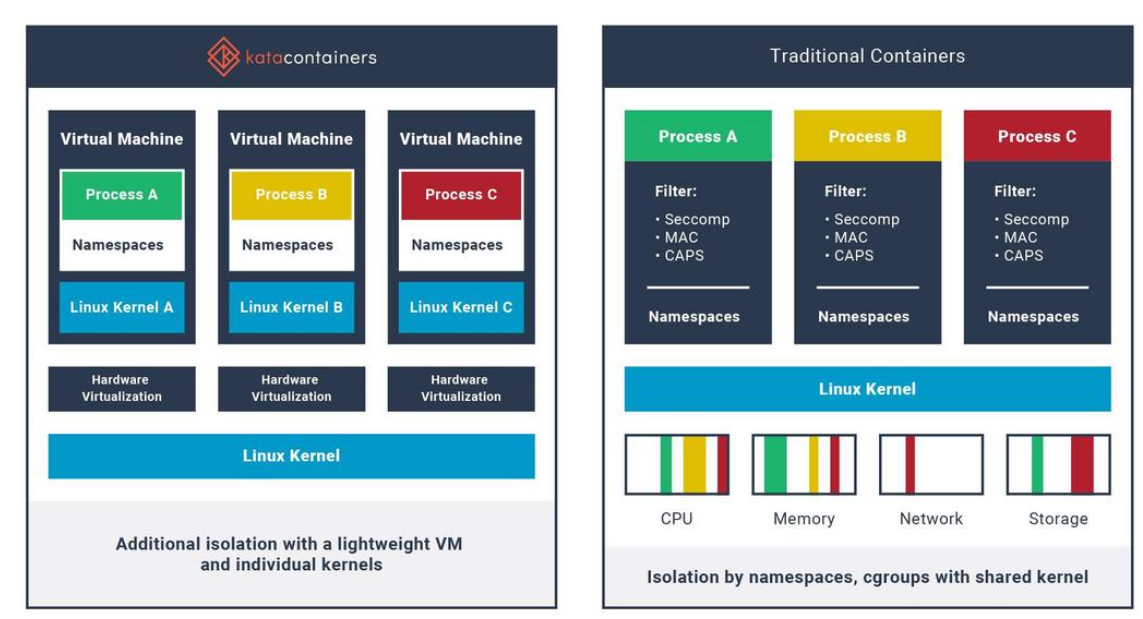
沙箱虚拟化技术虚拟机容器之间的关系详解
问题 沙箱、虚拟化、容器三者分开一一介绍的话我知道他们各自都是什么东西,但是如果把三者放在一起,它们之间到底什么关系?又有什么联系呢?我不是很明白!!! 就比如说: 沙箱&#…...

对象回调初步研究
_OBJECT_TYPE结构分析 在介绍什么是对象回调前,首先要熟悉下结构 以我们上篇线程回调介绍过的导出的PsProcessType 结构为例,用_OBJECT_TYPE这个结构来解析它,0x80处就是今天要介绍的回调链表,但是先不着急,先把目光…...

EEG-fNIRS联合成像在跨频率耦合研究中的创新应用
摘要 神经影像技术对医学科学产生了深远的影响,推动了许多神经系统疾病研究的进展并改善了其诊断方法。在此背景下,基于神经血管耦合现象的多模态神经影像方法,通过融合各自优势来提供有关大脑皮层神经活动的互补信息。在这里,本研…...
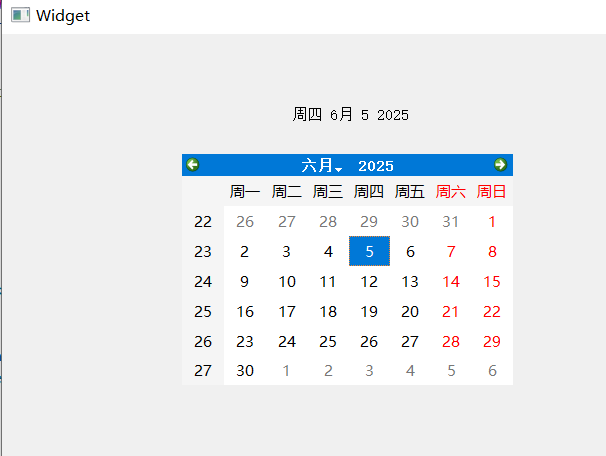
【QT控件】显示类控件
目录 一、Label 二、LCD Number 三、ProgressBar 四、Calendar Widget QT专栏:QT_uyeonashi的博客-CSDN博客 一、Label QLabel 可以用来显示文本和图片. 核心属性如下 代码示例: 显示不同格式的文本 1) 在界面上创建三个 QLabel 尺寸放大一些. objectName 分别…...
新版NANO下载烧录过程
一、序言 搭建 Jetson 系列产品烧录系统的环境需要在电脑主机上安装 Ubuntu 系统。此处使用 18.04 LTS。 二、环境搭建 1、安装库 $ sudo apt-get install qemu-user-static$ sudo apt-get install python 搭建环境的过程需要这个应用库来将某些 NVIDIA 软件组件安装到 Je…...