(17)Hive ——MR任务的map与reduce个数由什么决定?
一、MapTask的数量由什么决定?
MapTask的数量由以下参数决定
- 文件个数
- 文件大小
- blocksize
一般而言,对于每一个输入的文件会有一个map split,每一个分片会开启一个map任务,很容易导致小文件问题(如果不进行小文件合并,极可能导致Hadoop集群资源雪崩)
hive中小文件产生的原因及解决方案见文章:
(14)Hive调优——合并小文件-CSDN博客文章浏览阅读779次,点赞10次,收藏17次。Hive的小文件问题https://blog.csdn.net/SHWAITME/article/details/136108785
maxSize的默认值为256M,minSize的默认值是1byte,切片大小splitSize的计算公式:
splitSize=Min(maxSize,Max(minSize,blockSize)) = Min(256M,Max(1 byte ,128M)) = 128M =blockSize所以默认splitSize就等于blockSize块大小

# minSize的默认值是1byte
set mapred.min.split.size=1#maxSize的默认值为256M
set mapred.max.split.size=256000000#hive.input.format是用来指定输入格式的参数。决定了Hive读取数据时使用的输入格式,
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
二、如何调整MapTask的数量
假设blockSize一直是128M,且splitSize = blockSize = 128M。在不改变blockSize块大小的情况下,如何增加/减少mapTask数量
2.1 增加map的数量
增加map:需要调小maxSize,且要小于blockSize才有效,例如maxSize调成100byte
splitSize=Min(maxSize,Max(minSize,blockSize)) = Min(100,Max(1,128*1000*1000)) =100 byte = maxSize
调整前的map数 = 输入文件的大小/ splitSize = 输入文件的大小/ 128M
调整后的map数 = 输入文件的大小/ splitSize = 输入文件的大小/ 100byte
2.2 减少map的数量
减少map:需要调大minSize ,且要大于blockSize才有效,例如minSize 调成200M
splitSize=Min(maxSize,Max(minSize,blockSize)) = Min(256m, Max(200M,128M)) = 200M=minSize
调整前的map数 = 输入文件的大小/ splitSize = 输入文件的大小/ 128M
调整后的map数 = 输入文件的大小/ splitSize = 输入文件的大小/ 200M
三、ReduceTask的数量决定
reduce的个数决定hdfs上落地文件的个数(即: reduce个数决定文件的输出个数)。 ReduceTask的数量,由参数mapreduce.job.reduces 控制,默认值为 -1 时,代表ReduceTask的数量是根据hive的数据量动态计算的。

总体而言,ReduceTask的数量决定方式有以下两种:
3.1 方式一:hive动态计算
3.1.1 动态计算公式
ReduceTask数量 = min (参数2,输入的总数据量/ 参数1)
参数1:hive.exec.reducers.bytes.per.reducer
含义:每个reduce任务处理的数据量(默认值:256M)
参数2:hive.exec.reducers.max
含义:每个MR任务能开启的reduce任务数的上限值(默认值:1009个)
ps: 一般参数2的值不会轻易变动,因此在普通集群规模下,hive根据数据量动态计算reduce的个数,计算公式为:输入总数据量/hive.exec.reducers.bytes.per.reducer
3.1.2 源码分析
(1)通过源码分析 hive是如何动态计算reduceTask的个数的?
在org.apache.hadoop.hive.ql.exec.mr包下的 MapRedTask类中//方法类调用逻辑MapRedTask | ----setNumberOfReducers | ---- estimateNumberOfReducers|---- estimateReducers
(2)核心方法setNumberOfReducers(读取 用户手动设置的reduce个数)
/*** Set the number of reducers for the mapred work.*/private void setNumberOfReducers() throws IOException {ReduceWork rWork = work.getReduceWork();// this is a temporary hack to fix things that are not fixed in the compiler// 获取通过外部传参设置reduce数量的值 rWork.getNumReduceTasks() Integer numReducersFromWork = rWork == null ? 0 : rWork.getNumReduceTasks();if (rWork == null) {console.printInfo("Number of reduce tasks is set to 0 since there's no reduce operator");} else {if (numReducersFromWork >= 0) {//如果手动设置了reduce的数量 大于等于0 ,则进来,控制台打印日志console.printInfo("Number of reduce tasks determined at compile time: "+ rWork.getNumReduceTasks());} else if (job.getNumReduceTasks() > 0) {//如果手动设置了reduce的数量,获取配置中的值,并传入到work中int reducers = job.getNumReduceTasks();rWork.setNumReduceTasks(reducers);console.printInfo("Number of reduce tasks not specified. Defaulting to jobconf value of: "+ reducers);} else {//如果没有手动设置reduce的数量,进入方法if (inputSummary == null) {inputSummary = Utilities.getInputSummary(driverContext.getCtx(), work.getMapWork(), null);}// #==========【重中之中】estimateNumberOfReducers int reducers = Utilities.estimateNumberOfReducers(conf, inputSummary, work.getMapWork(),work.isFinalMapRed());rWork.setNumReduceTasks(reducers);console.printInfo("Number of reduce tasks not specified. Estimated from input data size: "+ reducers);}//hive shell中所看到的控制台打印日志就在这里console.printInfo("In order to change the average load for a reducer (in bytes):");console.printInfo(" set " + HiveConf.ConfVars.BYTESPERREDUCER.varname+ "=<number>");console.printInfo("In order to limit the maximum number of reducers:");console.printInfo(" set " + HiveConf.ConfVars.MAXREDUCERS.varname+ "=<number>");console.printInfo("In order to set a constant number of reducers:");console.printInfo(" set " + HiveConf.ConfVars.HADOOPNUMREDUCERS+ "=<number>");}}
(3)如果没有手动设置reduce的个数,hive是如何动态计算reduce个数的?
int reducers = Utilities.estimateNumberOfReducers(conf, inputSummary, work.getMapWork(),work.isFinalMapRed());/*** Estimate the number of reducers needed for this job, based on job input,* and configuration parameters.** The output of this method should only be used if the output of this* MapRedTask is not being used to populate a bucketed table and the user* has not specified the number of reducers to use.** @return the number of reducers.*/public static int estimateNumberOfReducers(HiveConf conf, ContentSummary inputSummary,MapWork work, boolean finalMapRed) throws IOException {// bytesPerReducer 每个reduce处理的数据量,默认值为256M BYTESPERREDUCER("hive.exec.reducers.bytes.per.reducer", 256000000L)long bytesPerReducer = conf.getLongVar(HiveConf.ConfVars.BYTESPERREDUCER);//整个mr任务,可以开启的reduce个数的上限值:maxReducers的默认值1009个MAXREDUCERS("hive.exec.reducers.max", 1009)int maxReducers = conf.getIntVar(HiveConf.ConfVars.MAXREDUCERS);//#===========对totalInputFileSize的计算double samplePercentage = getHighestSamplePercentage(work);long totalInputFileSize = getTotalInputFileSize(inputSummary, work, samplePercentage);// if all inputs are sampled, we should shrink the size of reducers accordingly.if (totalInputFileSize != inputSummary.getLength()) {LOG.info("BytesPerReducer=" + bytesPerReducer + " maxReducers="+ maxReducers + " estimated totalInputFileSize=" + totalInputFileSize);} else {LOG.info("BytesPerReducer=" + bytesPerReducer + " maxReducers="+ maxReducers + " totalInputFileSize=" + totalInputFileSize);}// If this map reduce job writes final data to a table and bucketing is being inferred,// and the user has configured Hive to do this, make sure the number of reducers is a// power of twoboolean powersOfTwo = conf.getBoolVar(HiveConf.ConfVars.HIVE_INFER_BUCKET_SORT_NUM_BUCKETS_POWER_TWO) &&finalMapRed && !work.getBucketedColsByDirectory().isEmpty();//#==============【真正计算reduce个数的方法】看源码的技巧return的方法是重要核心方法return estimateReducers(totalInputFileSize, bytesPerReducer, maxReducers, powersOfTwo);}
(4) 动态计算reduce个数的方法 estimateReducers
public static int estimateReducers(long totalInputFileSize, long bytesPerReducer,int maxReducers, boolean powersOfTwo) {double bytes = Math.max(totalInputFileSize, bytesPerReducer);// 假设totalInputFileSize 1000M// bytes=Math.max(1000M,256M)=1000Mint reducers = (int) Math.ceil(bytes / bytesPerReducer);//reducers=(int)Math.ceil(1000M/256M)=4 此公式说明如果totalInputFileSize 小于256M ,则reducers=1 ;也就是当输入reduce端的数据量特别小,即使手动设置reduce Task数量为5,最终也只会开启1个reduceTaskreducers = Math.max(1, reducers);//Math.max(1, 4)=4 ,reducers的结果还是4reducers = Math.min(maxReducers, reducers);//Math.min(1009,4)=4; reducers的结果还是4int reducersLog = (int)(Math.log(reducers) / Math.log(2)) + 1;int reducersPowerTwo = (int)Math.pow(2, reducersLog);if (powersOfTwo) {// If the original number of reducers was a power of two, use thatif (reducersPowerTwo / 2 == reducers) {// nothing to do} else if (reducersPowerTwo > maxReducers) {// If the next power of two greater than the original number of reducers is greater// than the max number of reducers, use the preceding power of two, which is strictly// less than the original number of reducers and hence the maxreducers = reducersPowerTwo / 2;} else {// Otherwise use the smallest power of two greater than the original number of reducersreducers = reducersPowerTwo;}}return reducers;}
3.2 方式二:用户手动指定
手动调整reduce个数: set mapreduce.job.reduces = 10
需要注意:出现以下几种情况时,手动调整reduce个数不生效。
3.2.1 order by 全局排序
sql中使用了order by全局排序,那只能在一个reduce中完成,无论怎么调整reduce的数量都是无效的。
hive (default)>set mapreduce.job.reduces=5;hive (default)> select * from empt order by length(ename);Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
3.2.2 map端输出的数据量很小
在【3.1.2 源码分析——(4) 】动态计算reduce个数的核心方法 estimateReducers中,有下面这三行代码:
int reducers = (int) Math.ceil(bytes / bytesPerReducer);
reducers = Math.max(1, reducers);
reducers = Math.min(maxReducers, reducers);
如果map端输出的数据量bytes (假如只有1M) 远小于hive.exec.reducers.bytes.per.reducer (每个reduce处理的数据量默认值为256M) 参数值,maxReducers默认为1009个,计算下列值:
int reducers = (int) Math.ceil(1 / 256M)=1;reducers = Math.max(1, 1)=1;reducers = Math.min(1009, 1)=1;
此时即使用户手动 set mapreduce.job.reduces=10,也不生效,reduce个数最后还是只有1个。
参考文章:
Hive mapreduce的map与reduce个数由什么决定?_hive中map任务和reduce任务数量计算原理-CSDN博客
相关文章:
(17)Hive ——MR任务的map与reduce个数由什么决定?
一、MapTask的数量由什么决定? MapTask的数量由以下参数决定 文件个数文件大小blocksize 一般而言,对于每一个输入的文件会有一个map split,每一个分片会开启一个map任务,很容易导致小文件问题(如果不进行小文件合并&…...

define和typedef
目录 一、define 二、typedef 三、二者之间的区别 一、define 在我们写代码的日常中,经常会用到define去配合数组的定义使用 #define N 10 arr[N]{0}; define不仅仅能做这些 #define是一种宏,我们首先来了解一下宏定义。 宏定义一般作用在C语言的预…...
SpringCloud之Nacos用法笔记
SpringCloud之Nacos注册中心 Nacos注册中心nacos启动服务注册到Nacosnacos服务分级模型NacosRule负载均衡策略根据集群负载均衡加权负载均衡Nacos环境隔离-namespace Nacos与eureka的对比临时实例与非临时实例设置 Nacos配置管理统一配置管理微服务配置拉取配置自动刷新远端配置…...
【c++】拷贝构造函数
1.特征 1.拷贝构造函数是构造函数的一个重载形式。 2.若显示定义了拷贝构造函数,编译器就不会自动生成构造函数了。 3.拷贝构造函数的参数只有一个且必须是类型对象的引用,使用传值方式编译器直接报错,因为会引发无穷递归调用。 4.若未显…...

17.3.1.2 曝光
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 基本算法:先定义一个阈值,通常取得是128 原图像:颜色值color(R,G&#…...

【Win10 触摸板】在插入鼠标时禁用触摸板,并在没有鼠标时自动启用触摸板。取消勾选连接鼠标时让触摸板保持打开状态,但拔掉鼠标后触摸板依旧不能使用
出现这种问题我的第一反应就是触摸板坏了,但是无意间我换了一个账户发现触摸板可以用,因此推断触摸板没有坏,是之前的账户问题,跟系统也没有关系,不需要重装系统。 解决办法:与鼠标虚拟设备有关 然后又从知…...
排序算法---桶排序
原创不易,转载请注明出处。欢迎点赞收藏~ 桶排序(Bucket Sort)是一种排序算法,它将待排序的数据分到几个有序的桶中,每个桶再分别进行排序,最后将各个桶中的数据按照顺序依次取出,即可得到有序序…...

FPGA_工程_基于rom的vga显示
一 框图 二 代码修改 module Display #(parameter H_DISP 1280,parameter V_DISP 1024,parameter H_lcd 12d150,parameter V_lcd 12d150,parameter LCD_SIZE 15d10_000 ) ( input wire clk, input wire rst_n, input wire [11:0] lcd_xpos, //lcd horizontal coo…...

代码随想录算法训练营第31天|● 理论基础 ● 455.分发饼干 ● 376. 摆动序列 ● 53. 最大子序和
文章目录 理论基础分发饼干思路:代码: 摆动序列思路一 贪心算法:代码: 思路二:动态规划(想不清楚)代码: 最大子序和思路:代码: 理论基础 贪心算法其实就是没…...

无人机地面站技术,无人机地面站理论基础详解
地面站作为整个无人机系统的作战指挥中心,其控制内容包括:飞行器的飞行过程,飞行航迹, 有效载荷的任务功能,通讯链路的正常工作,以及 飞行器的发射和回收。 无人机地面站总述 地面站作为整个无人机系统的作战指挥中心…...

2024.2.13
21.C 22.D 23.B 5先出栈表示1,2,3,4已经入栈了,5出后4出,但之后想出1得先让3,2先后出栈,所以 B 不可能 24.10,12,120 25.2,5 26.可能会出现段错误…...

论文阅读:四足机器人对抗运动先验学习稳健和敏捷的行走
论文:Learning Robust and Agile Legged Locomotion Using Adversarial Motion Priors 进一步学习:AMP,baseline方法,TO 摘要: 介绍了一种新颖的系统,通过使用对抗性运动先验 (AMP) 使四足机器人在复杂地…...
.NET Core WebAPI中封装Swagger配置
一、创建相关文件 创建一个Utility/SwaggerExt文件夹,添加一个类 二、在Program中找到Swagger相关配置信息 三、添加方法,在Program中调用 在SwaggerExt类中添加方法,将相关配置添写入 /// <summary> /// swagger配置 /// </sum…...

28. 找出字符串中第一个匹配项的下标
Problem: 28. 找出字符串中第一个匹配项的下标 文章目录 思路解题方法复杂度Code 思路 这个问题可以通过使用KMP(Knuth-Morris-Pratt)算法来解决。KMP算法是一种改进的字符串匹配算法,它的主要思想是当子串与目标字符串不匹配时,能…...

宿舍|学生宿舍管理小程序|基于微信小程序的学生宿舍管理系统设计与实现(源码+数据库+文档)
学生宿舍管理小程序目录 目录 基于微信小程序的学生宿舍管理系统设计与实现 一、前言 二、系统功能设计 三、系统实现 1、管理员模块的实现 (1)学生信息管理 (2)公告信息管理 (3)宿舍信息管理 &am…...
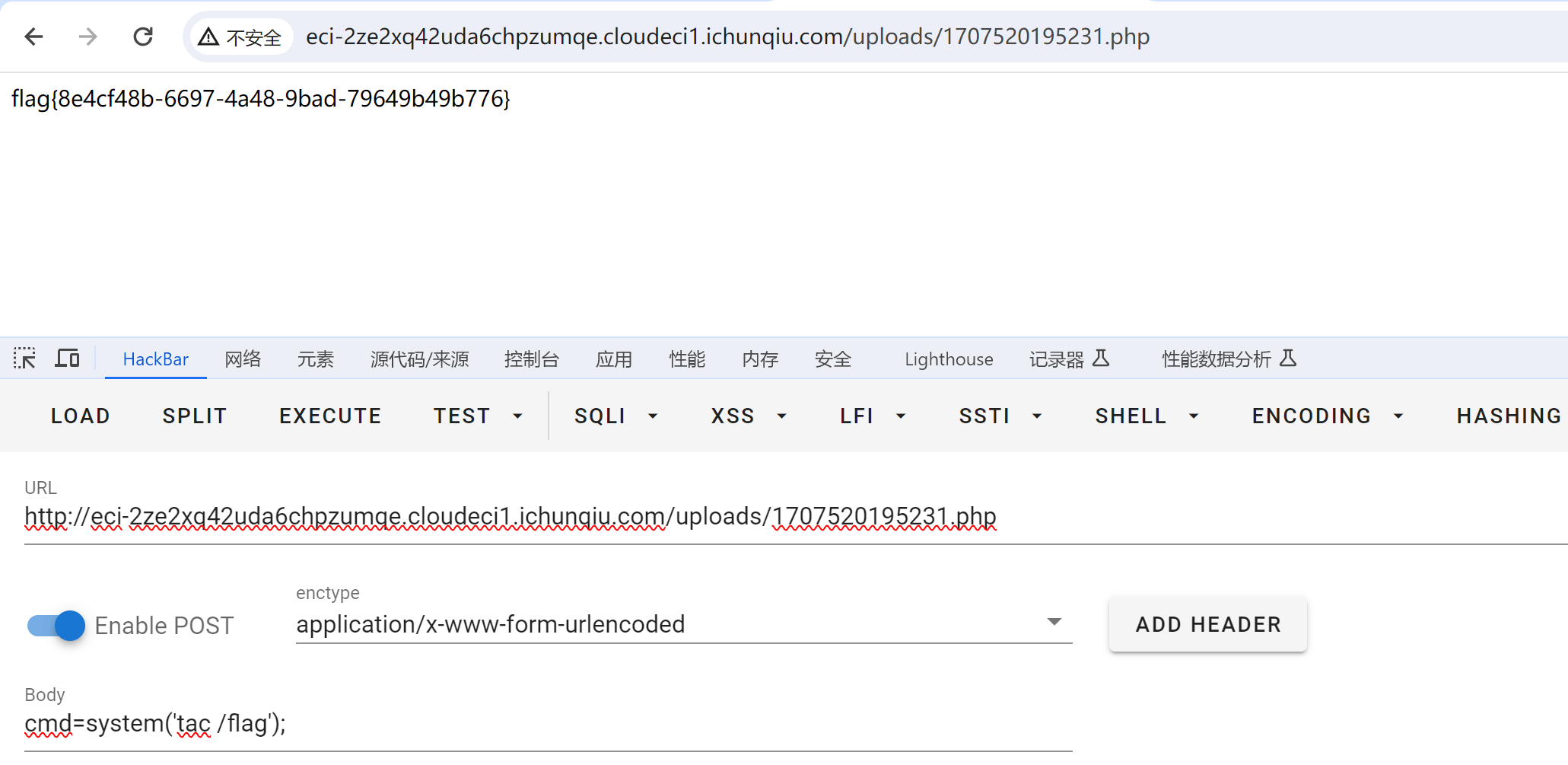
CVE-2022-25487 漏洞复现
漏洞描述:Atom CMS 2.0版本存在远程代码执行漏洞,该漏洞源于/admin/uploads.php 未能正确过滤构造代码段的特殊元素。攻击者可利用该漏洞导致任意代码执行。 其实这就是一个文件上传漏洞罢了。。。。 打开之后,/home路由是个空白 信息搜集&…...

C#面:强类型和弱类型
强类型 强类型是指在编程语言中,变量必须明确声明其数据类型,并且在编译时会进行类型检查的特性。它可以提高代码的可读性和可维护性,但有时需要显式地进行类型转换。换句话说,强类型语言要求变量的类型在编译时就要确定…...

nodejs和npm和vite
Nodejs 简单的说 Node.js 就是运行在服务端的 JavaScript。 Node.js 是一个基于 Chrome JavaScript 运行时建立的一个平台。 Node.js 是一个事件驱动 I/O 服务端 JavaScript 环境 用途: Node.js 可以被看作是一个 JavaScript 运行时环境,专门用于在服务…...
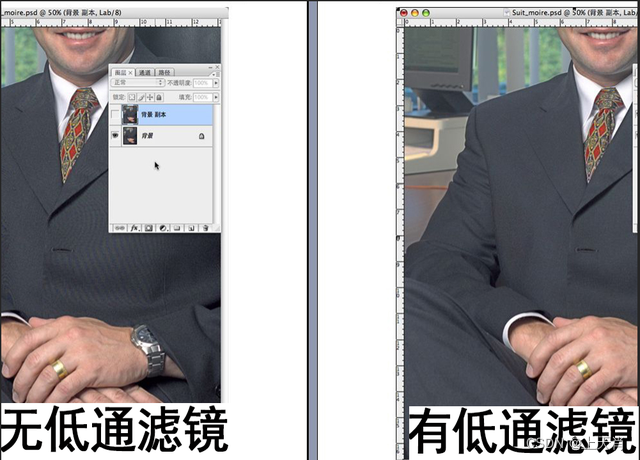
相机图像质量研究(24)常见问题总结:CMOS期间对成像的影响--摩尔纹
系列文章目录 相机图像质量研究(1)Camera成像流程介绍 相机图像质量研究(2)ISP专用平台调优介绍 相机图像质量研究(3)图像质量测试介绍 相机图像质量研究(4)常见问题总结:光学结构对成像的影响--焦距 相机图像质量研究(5)常见问题总结:光学结构对成…...

Redis -- 数据库管理
目录 前言 切换数据库(select) 数据库中key的数量(dbsize) 清除数据库(flushall flushdb) 前言 MySQL有一个很重要的概念,那就是数据库database,一个MySQL里面有很多个database,一个datab…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...