WSL下如何使用Ubuntu本地部署Vits2.3-Extra-v2:中文特化修复版(新手从0开始部署教程)
环境:
硬:
台式电脑
1.cpu:I5 11代以上
2.内存16G以上
3.硬盘固态500G以上
4.显卡N卡8G显存以上
20系2070以上
本案例英伟达4070 12G
5.网络可连github
软:
Win10 专业版 19045以上
WSL2 -Ubuntu22.04
1.bert-Vits2.3
Extra-v2:中文特化修复版
Extra-Fix分支
底模:Bert-VITS2_中文特化修复底模_0.0.1
2.python 3.11以上
3.git
4.cuda11.8
5.pytorch2.1
问题描述:
WSL下如何使用Ubuntu本地部署Vits2.3-Extra-v2:中文特化修复版

解决方案:
Bert-VITS2简介
bert-vits2可预测感情文本转语音技术的工作原理是,首先对大量的文本数据进行情感分析,以了解不同情感表达的语法和词汇使用情况。然后,利用这些信息,人工智能模型可以预测给定文本的情感倾向,并调整语音输出的音调和语速等参数,以匹配这种情感倾向。
流程包括文本预处理、声学模型处理训练和后处理三个步骤。首先,文本预处理会对标注的文本分析和处理,例如分词、词性标注和语法分析等。然后,声学模型训练会将文本转化为声学特征,这个过程通常需要大量的语音数据来训练。最后,后处理会对生成的语音波形进行优化和调整,以使其更符合直播带货的需求
Bert-VITS2部署
一、部署底层环境
Win10 安装WSL
WSL,全称Windows Subsystem for Linux,是Windows操作系统中的一个功能,它允许在Windows上运行Linux子系统。通过WSL,用户可以在Windows环境下使用Linux的命令行工具、脚本和应用程序,而无需进行双系统切换或虚拟机配置。WSL提供了与Linux内核的兼容性,使得在Windows上进行开发和运行Linux应用变得更加方便。用户可以在Microsoft Store中下载WSL,安装后即可使用。
1.启用 WSL 相关功能:
打开cmd终端(管理员权限)
运行以下命令以启用虚拟机平台功能:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
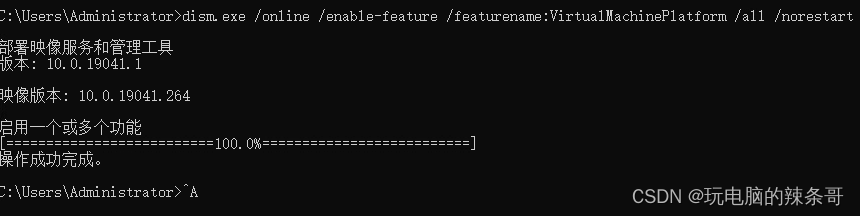
重新启动计算机
2.安装 WSL 2 Linux 内核更新包:
下载适用于你的系统的 WSL 2 Linux 内核更新包:
x64 系统:https://aka.ms/wsl2kernel

ARM64 系统:https://aka.ms/wsl2kernelarm64
安装下载的。
3.设置 WSL 2 为默认版本:
打开 cmd终端,运行以下命令以将 WSL 2 设置为默认版本:
shell wsl --set-default-version 2
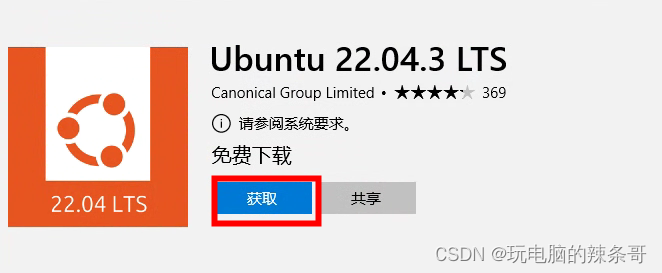
4.安装 Ubuntu 22.04 分发版:
打开 Microsoft Store 应用商店
在搜索栏中搜索 “Ubuntu 22.04”
选择 “Ubuntu 20.04 LTS” 并点击 “获取”
安装完成后,点击 “启动”
5.配置 Ubuntu 22.04:
在 Ubuntu 20.04 的安装界面中,为新的 Linux 用户设置用户名和密码
安装显卡驱动
1.Win10安装cuda-wsl驱动
https://developer.nvidia.com/cuda/wsl
确定要安装的版本
从物理设备开始一直到上层应用,CUDA有一条复杂的软件版本依赖链。我们通常从自己电脑的物理GPU型号开始,确定每个环节的软件版本:
GPU物理设备的型号 ——决定——> GPU驱动的版本号 对应关系
GPU驱动的版本号 ——决定——> CUDA的版本号 对应关系
CUDA的版本号 ——决定——> cuDNN的版本号 对应关系
CUDA的版本号,同上 ——决定——> PyTorch等深度学习框架的版本号 对应关系
nvcc -V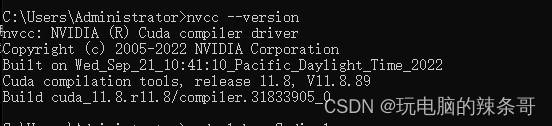
cmd下以root权限进入WSL
wsl -u root
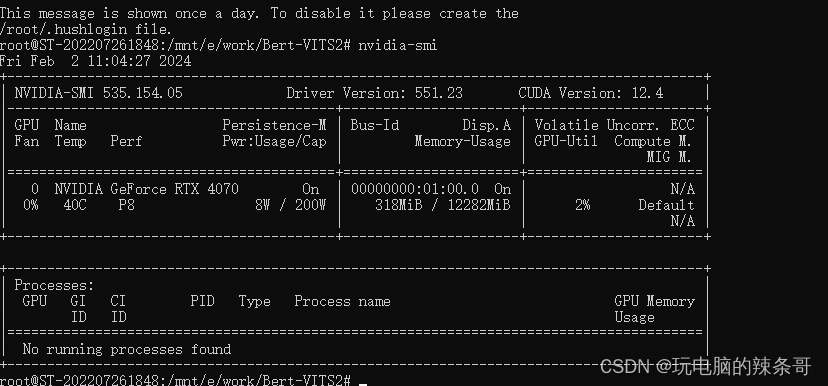
查看显卡配置
nvidia-smi
2.ubuntu安装cuda(如果WIN10下驱动正常,这步不需要再安装)
https://developer.nvidia.com/cuda-toolkit-archive
安装cuda11.8
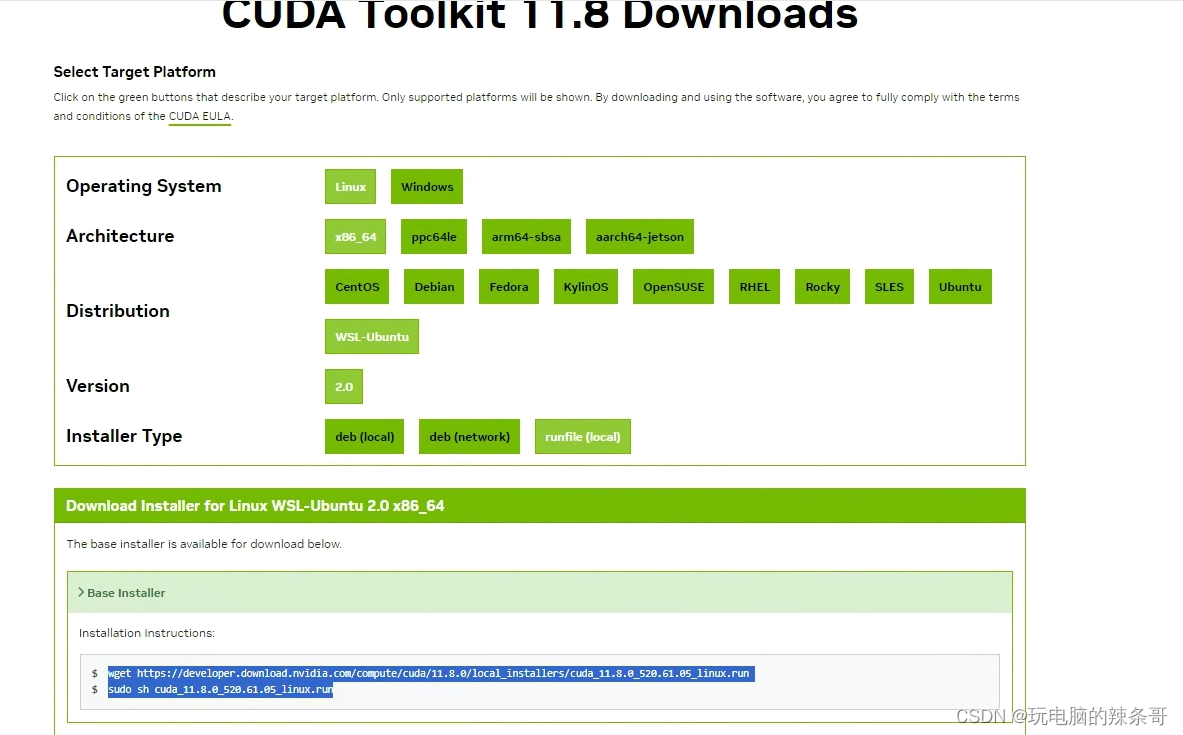
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
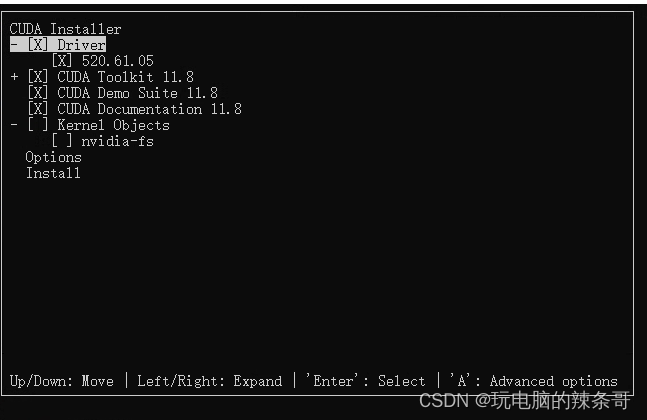
sudo sh cuda_11.8.0_520.61.05_linux.run
选install

3.安装cuda-toolkit
apt install nvidia-cuda-toolkit
完成查看
nvcc -V
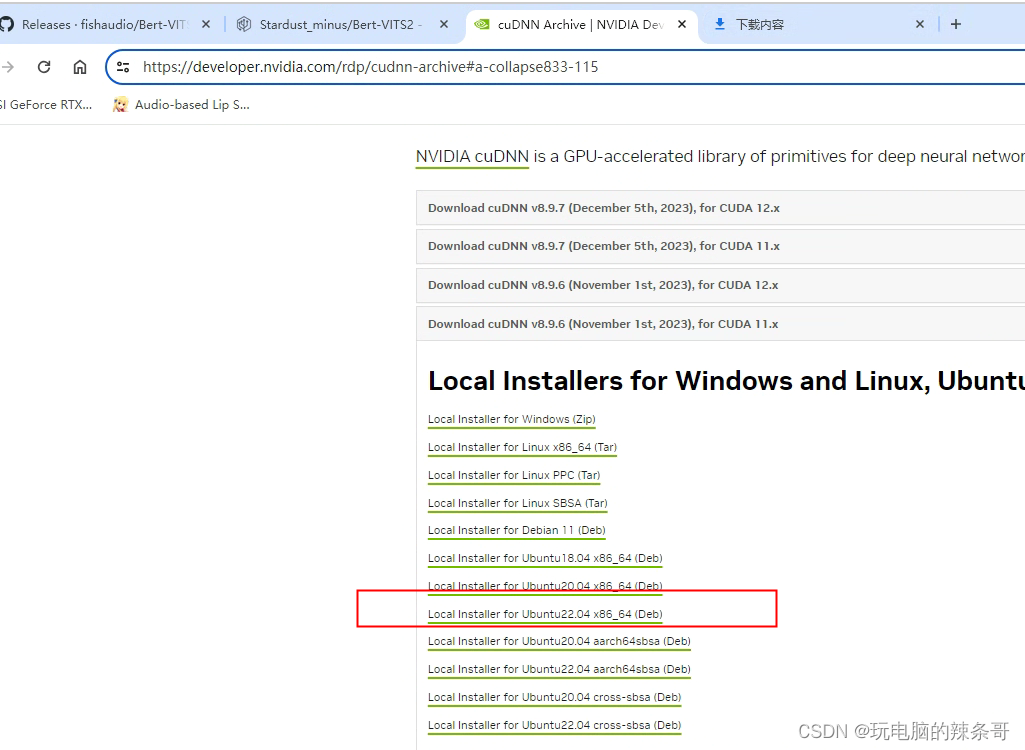
4.安装cuDNN
https://developer.nvidia.com/rdp/cudnn-archive#a-collapse833-115
拉取Vits2.3项目
拉取Extra-Fix分支
1.在e盘新建work文件夹
2.进入文件夹cd /mnt/e/work
git clone https://github.com/fishaudio/Bert-VITS2.git
还可以下载下来解压到work目录
3.安装python3.11
编辑软件源配置文件:
sudo nano /etc/apt/sources.list
在打开的文件中,将现有的软件源地址替换为清华大学的镜像源地址。
将清华源地址粘贴到文件中
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-security main restricted universe multiverse保存更改,并关闭编辑器(按下 Ctrl + X,然后按下 Y 确认保存,最后按下 Enter 关闭编辑器)。
更新软件包列表:
sudo apt update
安装python3.11
sudo apt install python3.11
apt install python3-pip
4.安装pytorch
PyTorch是一个开源的机器学习框架,用于构建深度学习模型。它提供了丰富的工具和库,使得开发者可以轻松地创建和训练各种类型的神经网络模型
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu118
警告:以“root”用户身份运行pip可能会导致权限中断以及与系统包管理器发生冲突。建议改用虚拟环境:https://pip.pypa.io/warnings/venv
5.设置虚拟环境
安装venv包,请先安装:
sudo apt install python3-venv
创建新的虚拟环境:
python3 -m venv vitsenv
将vitsenv替换为您想要为虚拟环境的名称
激活虚拟环境:
source vitsenv/bin/activate

现在您的提示符应该已更改,表示您正在虚拟环境中工作。现在,您可以使用pip而无需使用sudo命令
完成工作后,请记得停用虚拟环境:
deactivatepip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu118
查看是否成功
python -c "import numpy; print(numpy.__version__)"
python -c "import torch; print(torch.__version__)"

6.安装需求依赖库
安装项目里的需求依赖库:
pip install -r requirements.txt
requirements.txt 里面内容
librosa==0.9.2:用于音频和音乐信号处理的Python库。
matplotlib:用于创建可视化图表和绘图的Python库。
numpy:用于进行数值计算和数组操作的Python库。
numba:用于提供即时编译(JIT)功能,加速Python代码的执行。
phonemizer:用于将文本转换为音素序列的Python库。
scipy:用于科学计算和数值分析的Python库。
tensorboard:用于可视化和监控深度学习模型训练过程的工具。
Unidecode:用于将Unicode文本转换为ASCII文本的Python库。
amfm_decompy:用于分解调频调幅信号的Python库。
jieba_fast:用于中文分词的快速版本。
jieba:用于中文分词的Python库。
transformers:用于自然语言处理(NLP)任务的预训练模型和工具的库。
pypinyin:用于将汉字转换为拼音的Python库。
cn2an:用于将中文数字转换为阿拉伯数字的Python库。
gradio==3.50.2:用于构建交互式界面的Python库。
av:用于音频和视频处理的Python库。
mecab-python3:Python的日本语形态分析器MeCab的绑定。
loguru:用于更简单和更美观的日志记录的Python库。
unidic-lite:日本语形态分析字典Unidic的轻量级版本。
cmudict:包含美国英语发音的字典。
fugashi:Python的日本语形态分析器。
num2words:将数字转换为对应的文字表达的Python库。
PyYAML:用于解析和生成YAML文件的Python库。
requests:用于发送HTTP请求的Python库。
pyopenjtalk-prebuilt:日本语文本到语音合成的库。
jaconv:用于日本语文本转换的Python库。
psutil:用于获取系统信息和进程管理的Python库。
GPUtil:用于获取GPU(显卡)信息的Python库。
vector_quantize_pytorch:用于向量量化的PyTorch实现。
g2p_en:用于将英文单词转换为音素序列的Python库。
sentencepiece:用于分词和文本处理的Python库。
pykakasi:用于日语文本转化为罗马字拼音的Python库。
langid:用于自然语言文本语言检测的Python库。
onnxruntime-gpu:用于在GPU上运行ONNX模型的库。
opencc==1.1.7:用于简繁体中文转换的库。
WeTextProcessing>=0.1.10:用于中文文本处理的库

安装需要一段时间。。。
可以把源设置为清华的
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
 7.安装转写包
7.安装转写包
pip install funasr modelscope -i https://pypi.douban.com/simple/
二、模型下载
1.首先是bert模型下载
bert模型链接
https://openi.pcl.ac.cn/Stardust_minus/Bert-VITS2/modelmanage/show_model
2.按各自需要下载英日中的bert模型,将下载得到的pytorch_model.bin文件放入对应文件夹
deberta-v2-large-japanese-char-wwm(必下)
点进去下载
chinese-roberta-wwm-ext-large (必下)
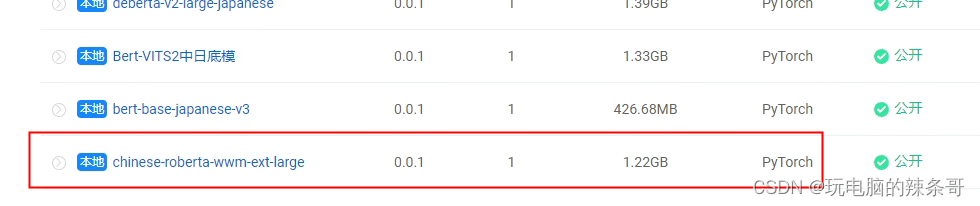 点进去下载
点进去下载
3.放进chinese-roberta-wwm-ext-large 下
将clap模型放入
Bert-VITS2\emotional\clap-htsat-fused

4.然后我们需要下载训练所需要的预训练模型
先输入
pip install openi
5.安装启智ai
然后进入以下链接: https://openi.pcl.ac.cn/user/settings/applications
先注册该平台账号,然后生成token(令牌)
 保存该令牌,然后回到vits界面,输入openi login
保存该令牌,然后回到vits界面,输入openi login
右键粘贴你刚才保存的token
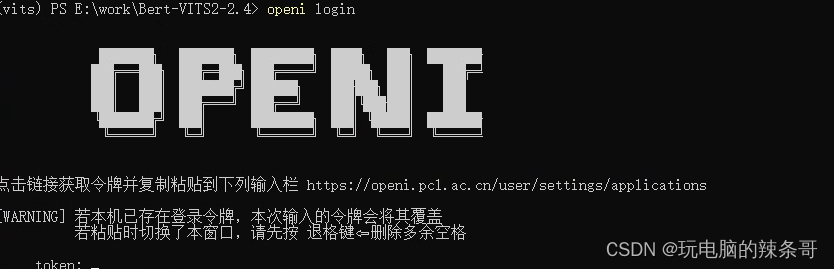

6.在线下载
openi model download -r Stardust_minus/Bert-VITS2 -m Bert-VITS2_中文特化修复底模 -p ./pretrained_model
还可以手工一个一个下载
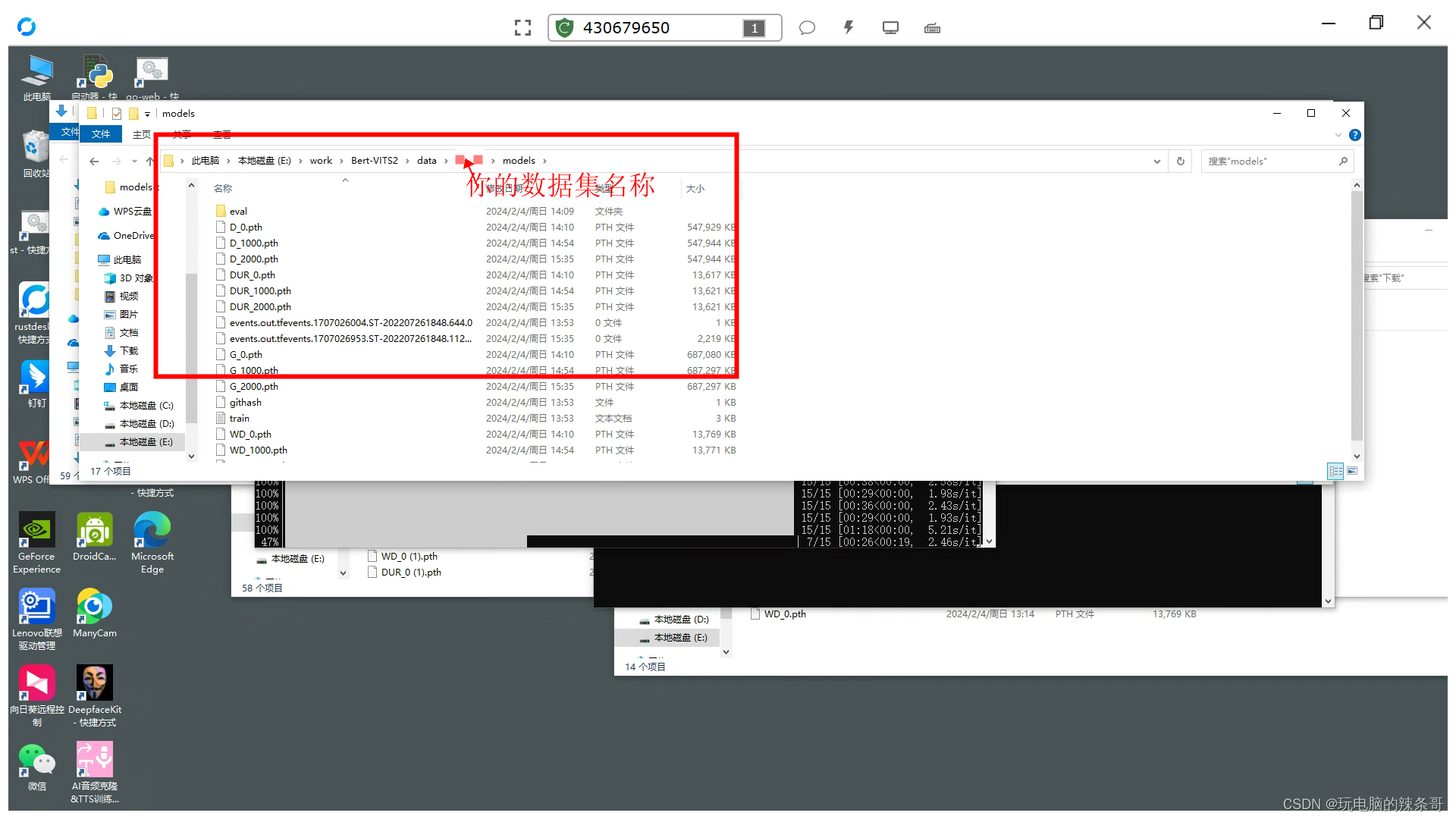
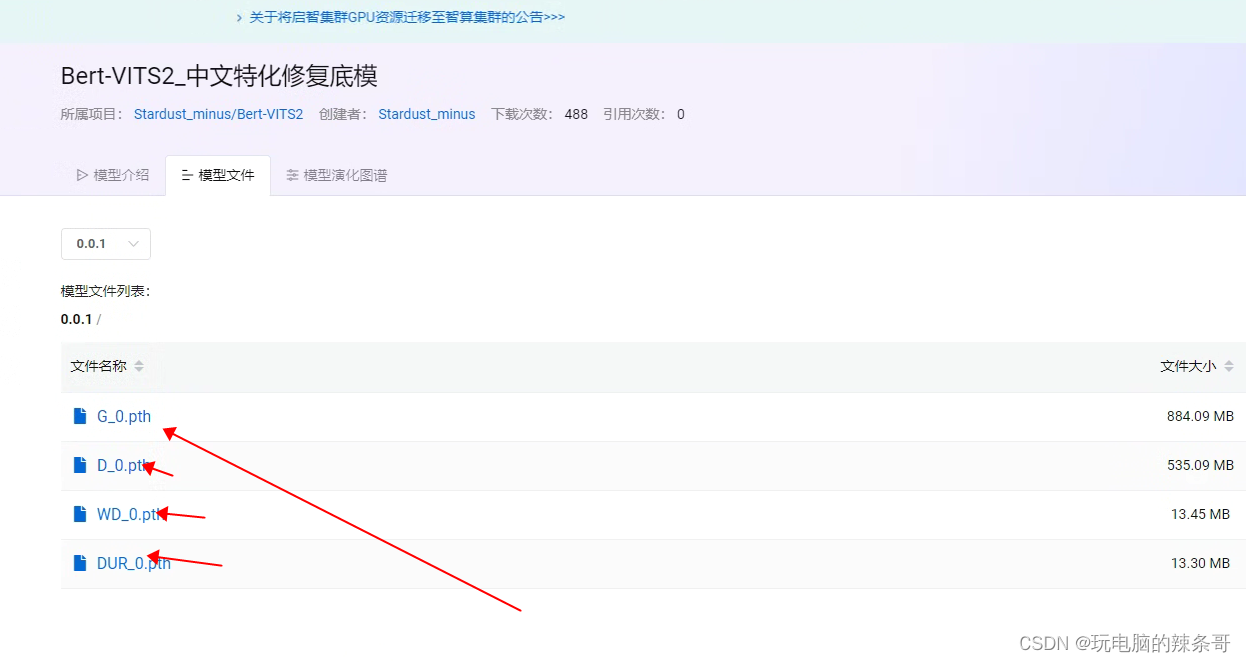 放置在,你设定的数据集名称文件夹 模型文件夹里,和下面自定义模型文件夹路径一样
放置在,你设定的数据集名称文件夹 模型文件夹里,和下面自定义模型文件夹路径一样
三、生成和修改配置文件
1.首次使用该项目先输入 python resample.py,生成配置文件

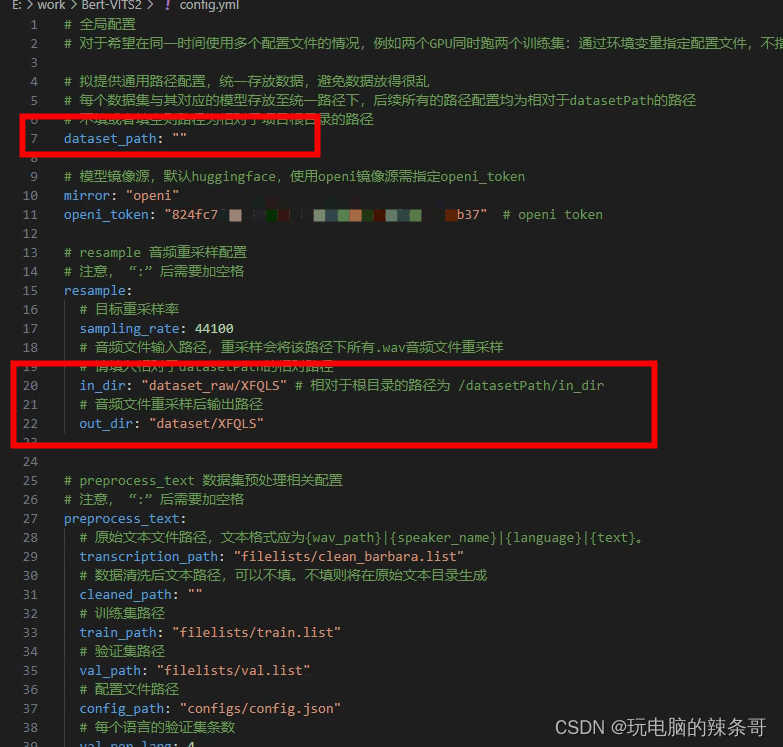
2.然后修改config.yml,根据自己实际情况进行修改
如果你不知道应该怎么修改,可以给我的参考一下
dataset_raw是你放置未处理的音频的文件夹,dataset处理后的数据集文件夹
这两个文件夹都需要手动创建
mirror将它的值从改为"openi"
3.将标注文本文件全部同意命名为clean_barbara.list,标注文本位于filelist文件夹内(后期用别的软件标注,标注文件在这替换)
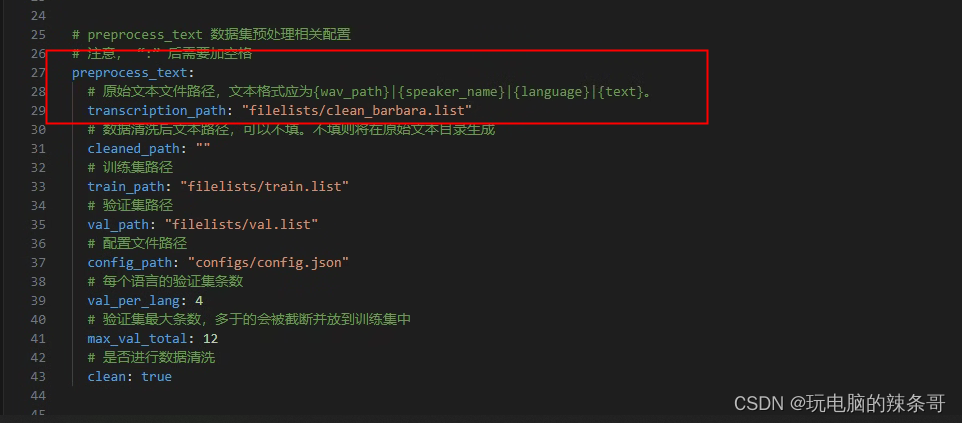
4.自动保存的模型数量,根据需要和自己的硬盘空间进行修改

5.server内的模型留空[],进入Hiyori UI后再加载模型


6.webui块的模型路径根据你自己的模型位置进行修改
ctrl+将所有的config.json路径都替换为configs/config.json
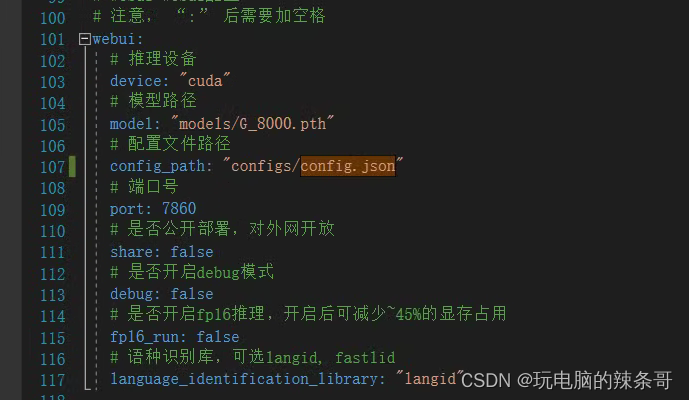
全部配置文件内容如下
# 全局配置
# 对于希望在同一时间使用多个配置文件的情况,例如两个GPU同时跑两个训练集:通过环境变量指定配置文件,不指定则默认为./config.yml# 拟提供通用路径配置,统一存放数据,避免数据放得很乱
# 每个数据集与其对应的模型存放至统一路径下,后续所有的路径配置均为相对于datasetPath的路径
# 不填或者填空则路径为相对于项目根目录的路径
dataset_path: ""# 模型镜像源,默认huggingface,使用openi镜像源需指定openi_token
mirror: "openi"
openi_token: "824fc7f0a921968883b708ea1ad64fe015894b37" # openi token# resample 音频重采样配置
# 注意, “:” 后需要加空格
resample:# 目标重采样率sampling_rate: 44100# 音频文件输入路径,重采样会将该路径下所有.wav音频文件重采样# 请填入相对于datasetPath的相对路径in_dir: "dataset_raw/XFQLS" # 相对于根目录的路径为 /datasetPath/in_dir# 音频文件重采样后输出路径out_dir: "dataset/XFQLS"# preprocess_text 数据集预处理相关配置
# 注意, “:” 后需要加空格
preprocess_text:# 原始文本文件路径,文本格式应为{wav_path}|{speaker_name}|{language}|{text}。transcription_path: "filelists/clean_barbara.list"# 数据清洗后文本路径,可以不填。不填则将在原始文本目录生成cleaned_path: ""# 训练集路径train_path: "filelists/train.list"# 验证集路径val_path: "filelists/val.list"# 配置文件路径config_path: "configs/config.json"# 每个语言的验证集条数val_per_lang: 4# 验证集最大条数,多于的会被截断并放到训练集中max_val_total: 12# 是否进行数据清洗clean: true# bert_gen 相关配置
# 注意, “:” 后需要加空格
bert_gen:# 训练数据集配置文件路径config_path: "configs/config.json"# 并行数num_processes: 4# 使用设备:可选项 "cuda" 显卡推理,"cpu" cpu推理# 该选项同时决定了get_bert_feature的默认设备device: "cuda"# 使用多卡推理use_multi_device: false# emo_gen 相关配置
# 注意, “:” 后需要加空格
emo_gen:# 训练数据集配置文件路径config_path: "configs/config.json"# 并行数num_processes: 4# 使用设备:可选项 "cuda" 显卡推理,"cpu" cpu推理device: "cuda"# 使用多卡推理use_multi_device: false# train 训练配置
# 注意, “:” 后需要加空格
train_ms:env:MASTER_ADDR: "localhost"MASTER_PORT: 10086WORLD_SIZE: 1LOCAL_RANK: 0RANK: 0# 可以填写任意名的环境变量# THE_ENV_VAR_YOU_NEED_TO_USE: "1234567"# 底模设置base:use_base_model: falserepo_id: "Stardust_minus/Bert-VITS2"model_image: "Bert-VITS2_2.3底模" # openi网页的模型名# 训练模型存储目录:与旧版本的区别,原先数据集是存放在logs/model_name下的,现在改为统一存放在Data/你的数据集/models下model: "data/XFQLS/models"# 配置文件路径config_path: "configs/config.json"# 训练使用的worker,不建议超过CPU核心数num_workers: 5# 关闭此项可以节约接近70%的磁盘空间,但是可能导致实际训练速度变慢和更高的CPU使用率。spec_cache: False# 保存的检查点数量,多于此数目的权重会被删除来节省空间。keep_ckpts: 15# webui webui配置
# 注意, “:” 后需要加空格
webui:# 推理设备device: "cuda"# 模型路径model: "models/G_8000.pth"# 配置文件路径config_path: "configs/config.json"# 端口号port: 7860# 是否公开部署,对外网开放share: false# 是否开启debug模式debug: false# 语种识别库,可选langid, fastlidlanguage_identification_library: "langid"# server-fastapi配置
# 注意, “:” 后需要加空格
# 注意,本配置下的所有配置均为相对于根目录的路径
server:# 端口号port: 5000# 模型默认使用设备:但是当前并没有实现这个配置。device: "cuda"# 需要加载的所有模型的配置,可以填多个模型,也可以不填模型,等网页成功后手动加载模型# 不加载模型的配置格式:删除默认给的两个模型配置,给models赋值 [ ],也就是空列表。参考模型2的speakers 即 models: [ ]# 注意,所有模型都必须正确配置model与config的路径,空路径会导致加载错误。# 也可以不填模型,等网页加载成功后手动填写models。models:- # 模型的路径model: ""# 模型configs/config.json的路径config: ""# 模型使用设备,若填写则会覆盖默认配置device: "cuda"# 模型默认使用的语言language: "ZH"# 模型人物默认参数# 不必填写所有人物,不填的使用默认值# 暂时不用填写,当前尚未实现按人区分配置speakers:- speaker: "科比"sdp_ratio: 0.2noise_scale: 0.6noise_scale_w: 0.8length_scale: 1- speaker: "五条悟"sdp_ratio: 0.3noise_scale: 0.7noise_scale_w: 0.8length_scale: 0.5- speaker: "安倍晋三"sdp_ratio: 0.2noise_scale: 0.6noise_scale_w: 0.8length_scale: 1.2- # 模型的路径model: ""# 模型configs/config.json的路径config: ""# 模型使用设备,若填写则会覆盖默认配置device: "cpu"# 模型默认使用的语言language: "JP"# 模型人物默认参数# 不必填写所有人物,不填的使用默认值speakers: [ ] # 也可以不填# 百度翻译开放平台 api配置
# api接入文档 https://api.fanyi.baidu.com/doc/21
# 请不要在github等网站公开分享你的app id 与 key
translate:# 你的APPID"app_key": ""# 你的密钥"secret_key": ""相关文章:
WSL下如何使用Ubuntu本地部署Vits2.3-Extra-v2:中文特化修复版(新手从0开始部署教程)
环境: 硬: 台式电脑 1.cpu:I5 11代以上 2.内存16G以上 3.硬盘固态500G以上 4.显卡N卡8G显存以上 20系2070以上 本案例英伟达4070 12G 5.网络可连github 软: Win10 专业版 19045以上 WSL2 -Ubuntu22.04 1.bert-Vits2.3 Extra-v2:…...

Go语言的100个错误使用场景(40-47)|字符串函数方法
前言 大家好,这里是白泽。 《Go语言的100个错误以及如何避免》 是最近朋友推荐我阅读的书籍,我初步浏览之后,大为惊喜。就像这书中第一章的标题说到的:“Go: Simple to learn but hard to master”,整本书通过分析100…...
Fluke ADPT 连接器新增对福禄克万用 Fluke 15B Max 的支持
所需设备: 1、Fluke ADPT连接器; 2、Fluke 15B Max; Fluke 15B Max拆机图: 显示界面如下图: 并且可以将波形导出到EXCEL: 福禄克万用表需要自己动手改造!!!...

前端工程化面试题 | 10.精选前端工程化高频面试题
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...
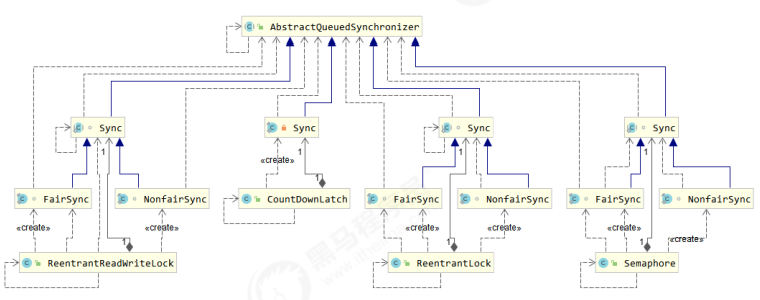
【并发编程】AQS原理
📝个人主页:五敷有你 🔥系列专栏:并发编程 ⛺️稳中求进,晒太阳 1. 概述 全称是 AbstractQueuedSynchronizer,是阻塞式锁和相关的同步器工具的框架 特点: 用 state 属性来表示资源的状…...
AI:130-基于深度学习的室内导航与定位
🚀点击这里跳转到本专栏,可查阅专栏顶置最新的指南宝典~ 🎉🎊🎉 你的技术旅程将在这里启航! 从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。 ✨✨✨ 每一个案例都附带有在本地跑过的关键代码,详细讲解供…...

Leetcode1423.可获得的最大点数
文章目录 题目原题链接思路(逆向思维) 题目 原题链接 Leetcode1423.可获得的最大点数 思路(逆向思维) 由题目可知,从两侧选k张,总数为n张,即从中间选n - k张 nums总和固定,要选k张最…...
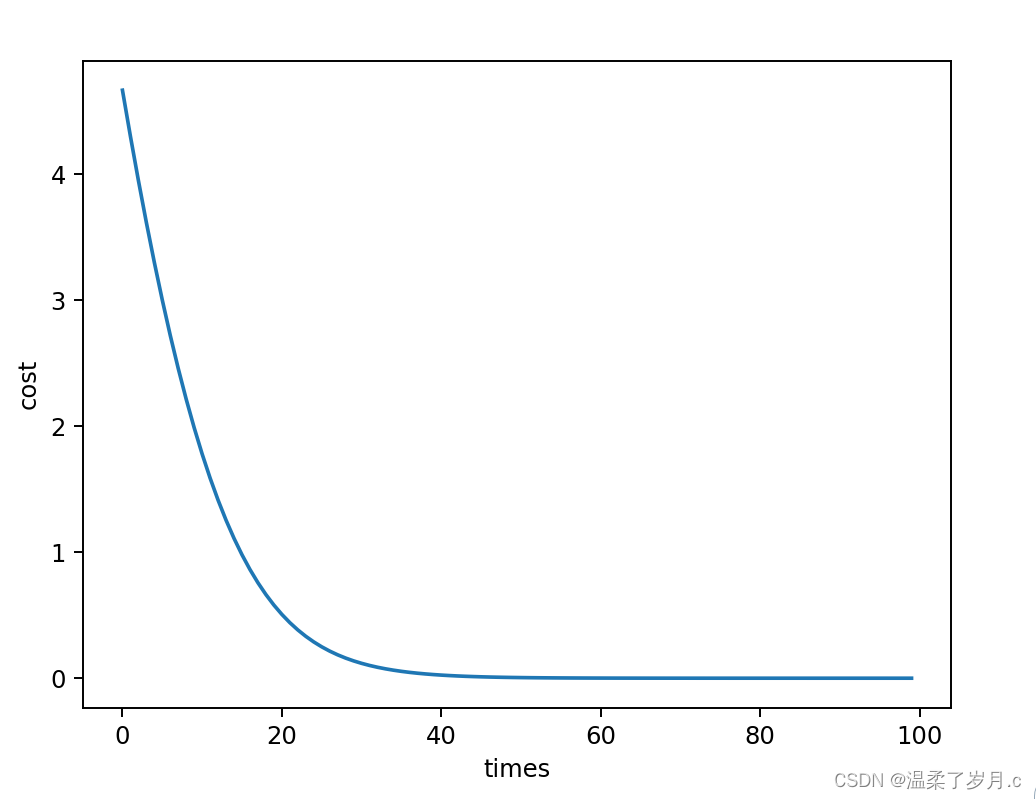
深度学习之梯度下降算法
梯度下降算法 梯度下降算法数学公式结果 梯度下降算法存在的问题随机梯度下降算法 梯度下降算法 数学公式 这里案例是用梯度下降算法,来计算 y w * x 先计算出梯度,再进行梯度的更新 import numpy as np import matplotlib.pyplot as pltx_data [1.0,…...
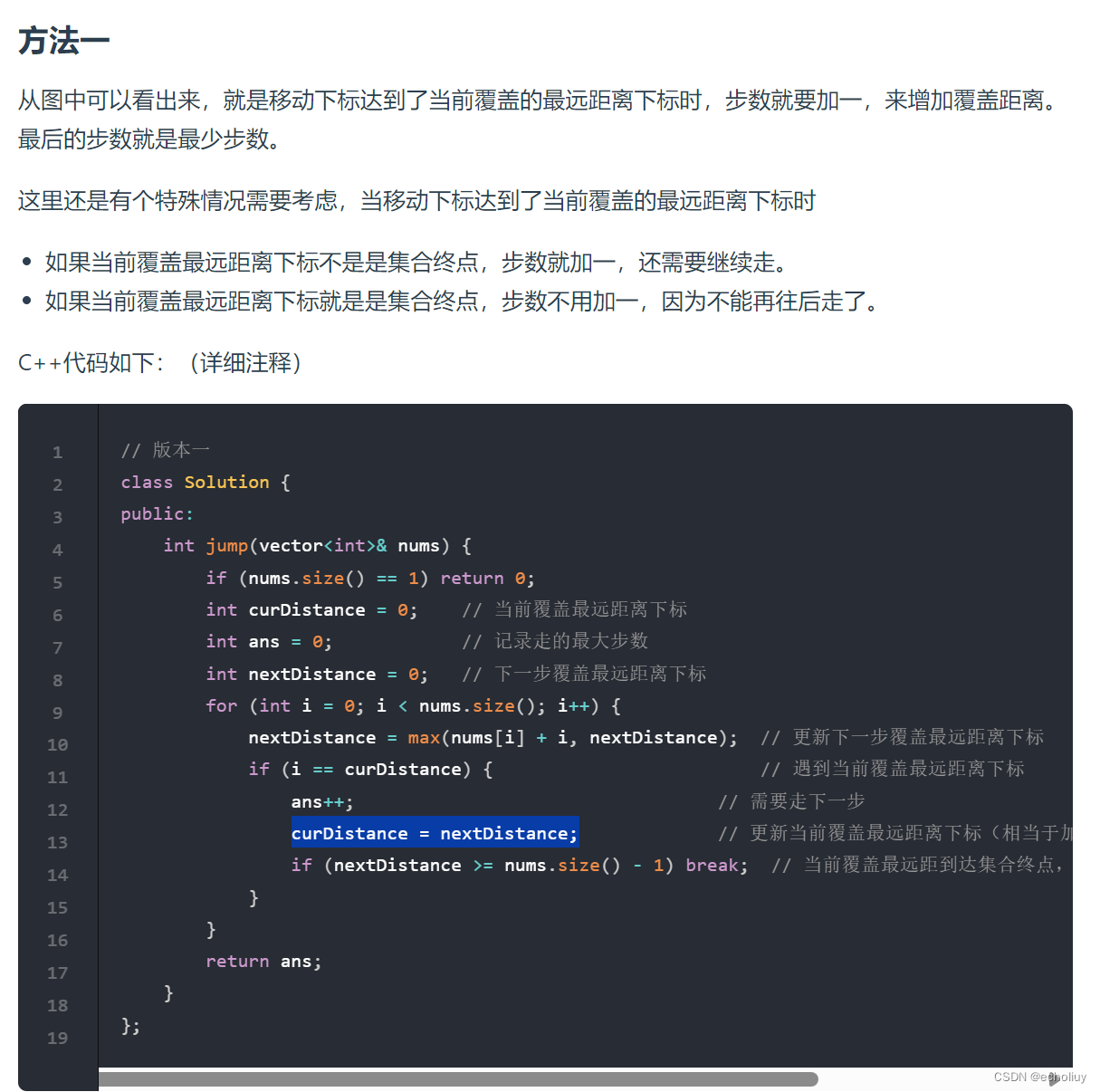
代码随想录第32天|● 122.买卖股票的最佳时机II ● 55. 跳跃游戏 ● 45.跳跃游戏II
文章目录 买卖股票思路一:贪心代码: 思路:动态规划代码: 跳跃游戏思路:贪心找最大范围代码: 跳跃游戏②思路:代码: 方法二:处理方法一的特殊情况 买卖股票 思路一&#x…...
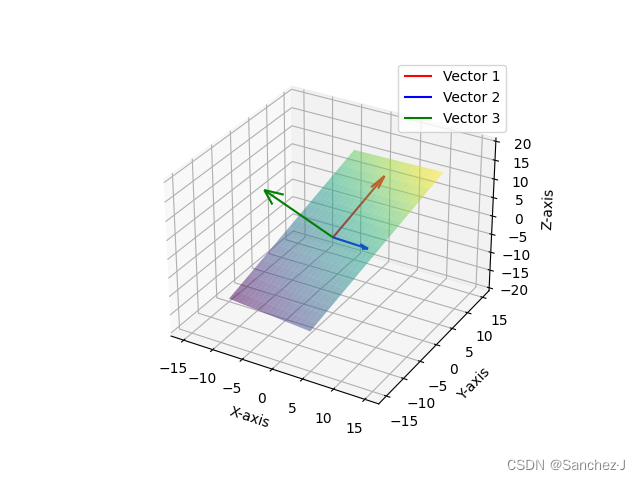
线性代数的本质 2 线性组合、张成的空间、基
基于3Blue1Brown视频的笔记 一种新的看待方式 对于一个向量,比如说,如何看待其中的3和-2? 一开始,我们往往将其看作长度(从向量的首走到尾部,分别在x和y上走的长度)。 在有了数乘后࿰…...

- 工程实践 - 《QPS百万级的有状态服务实践》01 - 存储选型实践
本文属于专栏《构建工业级QPS百万级服务》 《QPS百万级的无状态服务实践》已经完成。截止目前为止,支持需求“给系统传入两个日期,计算间隔有多少天”的QPS百万级服务架构已经完成。如图1: 图1 可是这个架构不能满足需求“给系统传入两个日期…...
SECS/GEM的HSMS通讯?金南瓜方案
High Speed SECS Message Service (HSMS) 是一种基于 TCP/IP 的协议,它使得 SECS 消息通信更加快速。这通常用作设备间通信的接口。 HSMS 状态逻辑变化(序列): 1.Not Connected:准备初始化 TCP/IP 连接,但尚…...

wayland(xdg_wm_base) + egl + opengles——dma_buf 作为纹理数据源(五)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、EGL dma_buf import 相关的数据结构和函数1. EGLImageKHR2. eglCreateImageKHR()3. glEGLImageTargetTexture2DOES()二、egl 中 import dma_buf 作为纹理的代码实例1. egl_wayland_dmabuf_…...

【VTKExamples::PolyData】第二十八期 LinearExtrusion
很高兴在雪易的CSDN遇见你 VTK技术爱好者 QQ:870202403 前言 本文分享VTK样例LinearExtrusion,并解析接口vtkLinearExtrusionFilter,希望对各位小伙伴有所帮助! 感谢各位小伙伴的点赞+关注,小易会继续努力分享,一起进步! 你的点赞就是我的动力(^U^)ノ~YO 目录…...
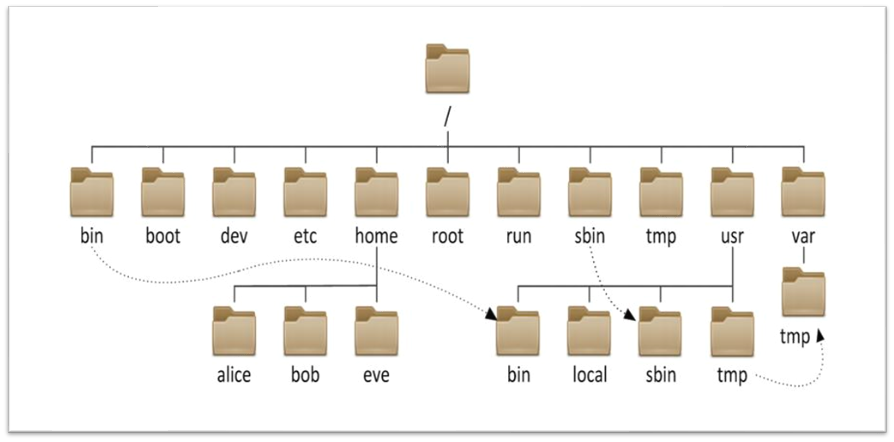
Linux操作系统基础(五):Linux的目录结构
文章目录 Linux的目录结构 一、Linux目录与Windows目录区别 二、常见目录介绍(记住重点) Linux的目录结构 一、Linux目录与Windows目录区别 Linux的目录结构是一个树型结构 Windows 系统 可以拥有多个盘符, 如 C盘、D盘、E盘 Linux 没有盘符 这个概…...

SolidWorks如何在一个零件的基础上绘制另一个零件
经过测试,新建零件,然后插入零件a,在a的基础上绘制b,这种做法无法断开a与b的联系。虽然可以通过切除命令,切除b,但不是正途。 在装配体中可以实现: (1)建立装配体 (2&…...
)
gin(结)
gin day1 今天的目标就是学懂,看懂每一步代码。 gin框架 gin框架就是go语言的web框架。框架你也可以理解成一个库。里面有一堆封装好的工具,帮你实现各种各样的功能,这样使得你可以关注业务本身,而在写代码上少费力。 快速入门&…...

JavaScript 设计模式之桥接模式
桥接模式 通过桥接模式,我们可以将业务逻辑与元素的事件解耦,也可以更灵活的创建一些对象 倘若我们有如下代码 const dom document.getElementById(#test)// 鼠标移入移出事件 // 鼠标移入时改变背景色和字体颜色 dom.onmouseenter function() { th…...

B3651 [语言月赛202208] 数组调整
题目描述 给出一个长度为 n 的数组,第 i 个数为ai。 为了调整这个数组,需要将第 k 个数改变为 −ak。 请你求出调整后的数组中所有数的和。 输入格式 输入共两行。 输入的第一行为两个整数 n,k。 输入的第二行为 n 个整数,第 i 个…...
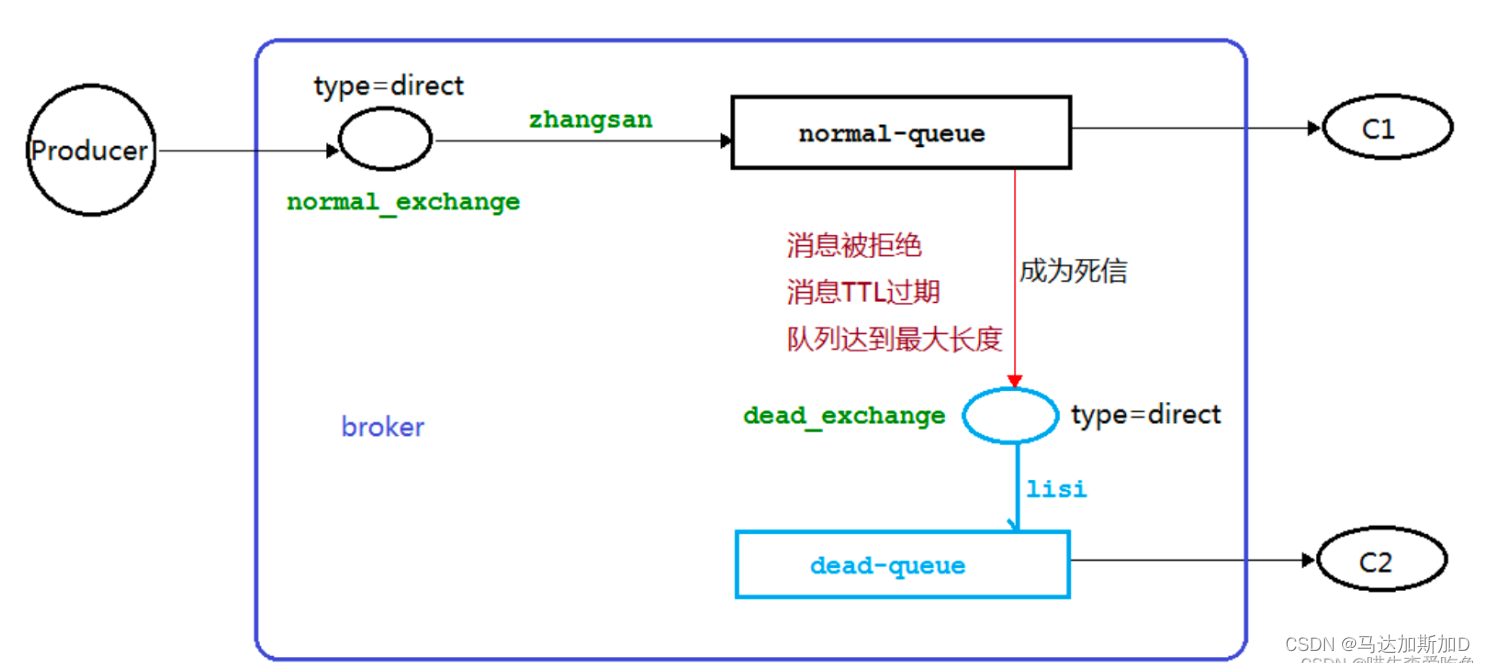
MessageQueue --- RabbitMQ
MessageQueue --- RabbitMQ RabbitMQ IntroRabbitMQ 核心概念RabbitMQ 分发类型Dead letter (死信)保证消息的可靠传递 RabbitMQ Intro 2007年发布,是一个在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统,…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...
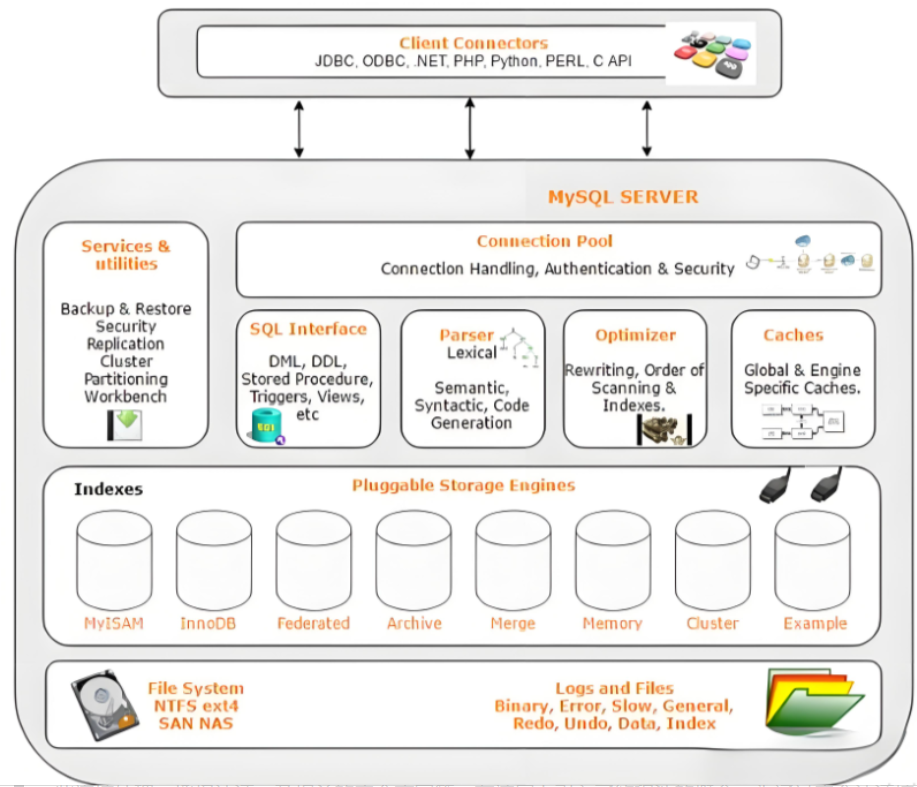
Mysql故障排插与环境优化
前置知识点 最上层是一些客户端和连接服务,包含本 sock 通信和大多数jiyukehuduan/服务端工具实现的TCP/IP通信。主要完成一些简介处理、授权认证、及相关的安全方案等。在该层上引入了线程池的概念,为通过安全认证接入的客户端提供线程。同样在该层上可…...
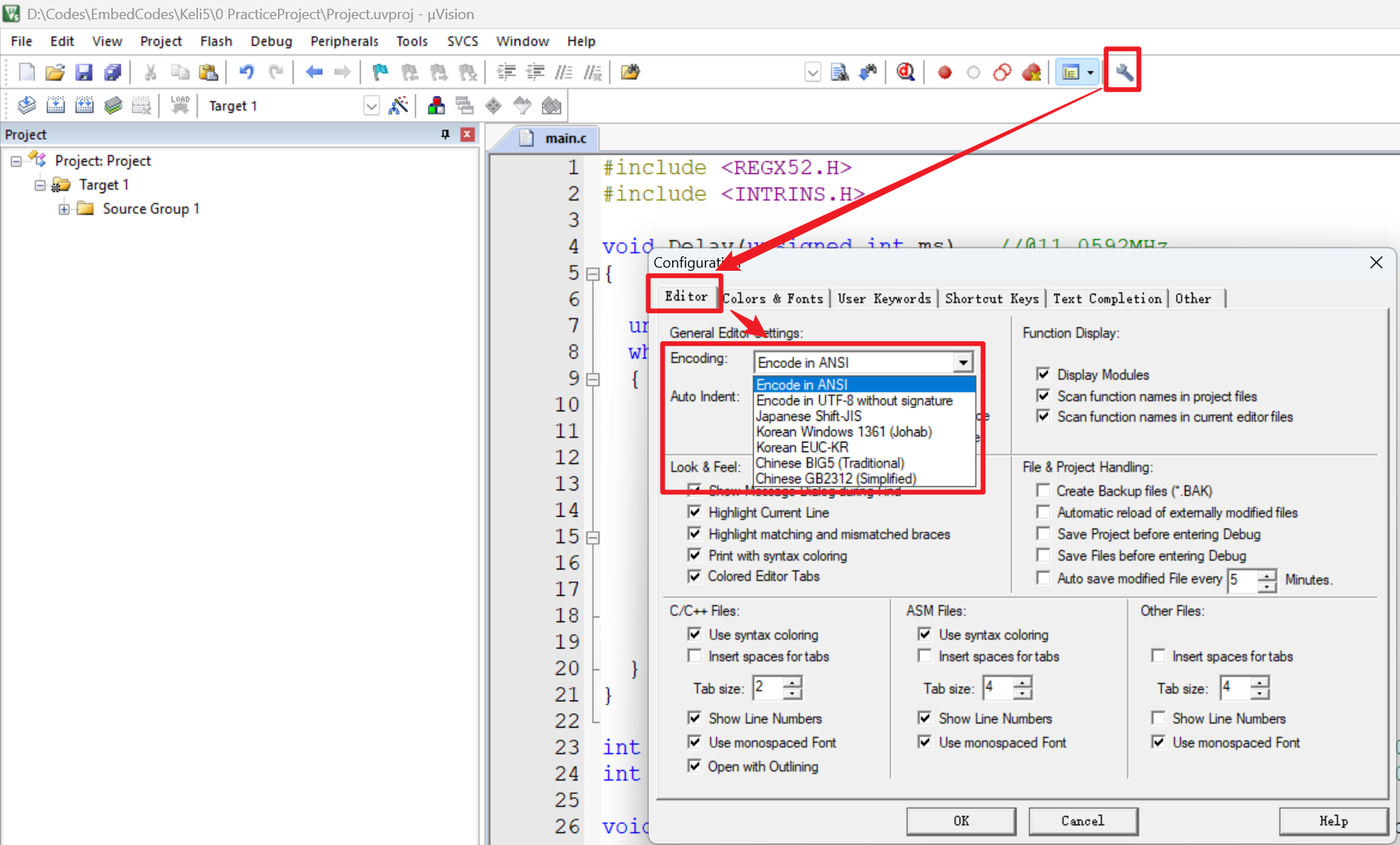
【51单片机】4. 模块化编程与LCD1602Debug
1. 什么是模块化编程 传统编程会将所有函数放在main.c中,如果使用的模块多,一个文件内会有很多代码,不利于组织和管理 模块化编程则是将各个模块的代码放在不同的.c文件里,在.h文件里提供外部可调用函数声明,其他.c文…...

【深尚想】TPS54618CQRTERQ1汽车级同步降压转换器电源芯片全面解析
1. 元器件定义与技术特点 TPS54618CQRTERQ1 是德州仪器(TI)推出的一款 汽车级同步降压转换器(DC-DC开关稳压器),属于高性能电源管理芯片。核心特性包括: 输入电压范围:2.95V–6V,输…...

GeoServer发布PostgreSQL图层后WFS查询无主键字段
在使用 GeoServer(版本 2.22.2) 发布 PostgreSQL(PostGIS)中的表为地图服务时,常常会遇到一个小问题: WFS 查询中,主键字段(如 id)莫名其妙地消失了! 即使你在…...
)
stm32进入Infinite_Loop原因(因为有系统中断函数未自定义实现)
这是系统中断服务程序的默认处理汇编函数,如果我们没有定义实现某个中断函数,那么当stm32产生了该中断时,就会默认跑这里来了,所以我们打开了什么中断,一定要记得实现对应的系统中断函数,否则会进来一直循环…...