NLP_Transformer架构
文章目录
- Transformer架构剖析
- 编码器-解码器架构
- 各种注意力的应用
- Transformer中的自注意力
- Transformer中的多头自注意力
- Transformer中的编码器-解码器注意力
- Transformer中的注意力掩码和因果注意力
- 编码器的输入和位置编码
- 编码器的内部结构
- 编码器的输出和编码器-解码器的连接
- 解码器的输入和位置编码
- 解码器的内部结构
- 解码器的输出和Transformer的输出头
- Transformer代码实现
- 组件1_多头注意力(包含残差连接和层归一化)
- 组件2_逐位置前馈网络(包含残差连接和层归一化)
- 组件3_正弦位置编码表
- 组件4_填充掩码
- 组件5_编码器层
- 组件6_编码器
- 组件7_后续掩码
- 组件8_解码器层
- 组件9_解码器
- 组件10_Transformer类
- 完成翻译任务
- 数据准备
- 训练Transformer模型
- 测试Transformer模型
- 小结
Transformer架构剖析
在此之前,RNN和LSTM是自然语言处理领域的主流技术。然而,这些网络结构存在计算效率低、难以捕捉长距离依赖、信息传递时的梯度消失和梯度爆炸等问题。这些问题在序列类型的神经网络系统中长期存在着,让学者们很头疼。因此,NLP的应用也不能像CV应用一样直接落地。为了解决这些问题,瓦斯瓦尼等人提出了一个全新的架构——Transformer。
Transformer 的核心是自注意力机制,它能够为输入序列中的每个元素分配不同的权重,从而更好地捕捉序列内部的依赖关系。与此同时,Transformer 摒弃了 RNN和 LSTM中的循环结构,采用了全新的编码器-解码器架构。这种设计使得模型可以并行处理输入数据,进一步加速训练过程,提高计算效率。
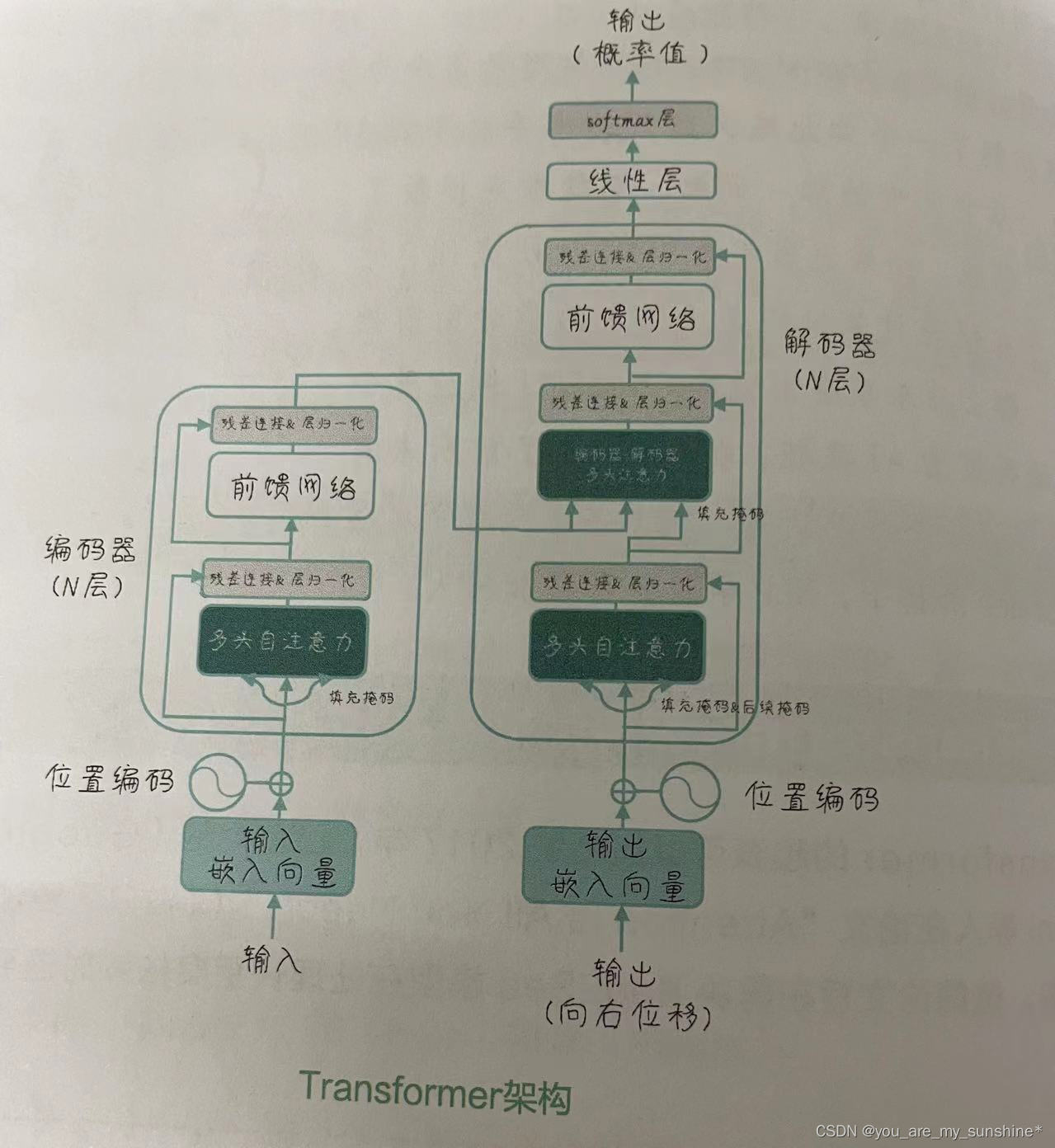
编码器-解码器架构
原始的 Transformer分为两部分:编码器和解码器。编码器负责将输入序列转换为一种表示,解码器则根据这种表示生成输出序列。
各种注意力的应用
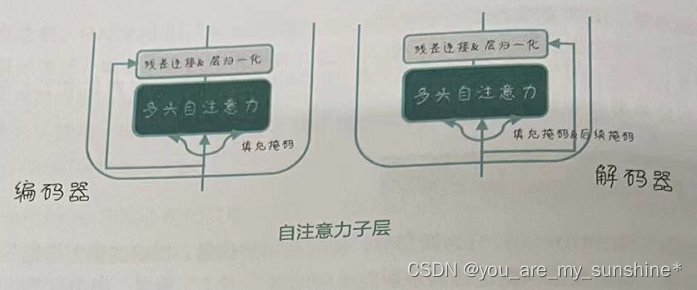
在 Transformer 的编码器和解码器内部,大量地使用了自注意力、多头自注意力和编码器-解码器注意力。
Transformer中的自注意力
自注意力是 Transformer的核心组件,它允许模型为输入序列中的每个元素分配不同的权重,从而捕捉序列内部的依赖关系。在编码器和解码器的每一层中,都包含了一个自注意力子层。
自注意力的计算过程。
- (1)将输入序列的每个元素分别投影到三个不同的向量空间,得到2、K和V向量。
- (2)计算Q和K的点积,然后除以一个缩放因子(通常是K向量的维度的平方根),得到注意力分数。
- (3)用softmax函数对注意力分数进行归一化,得到注意力权重。
- (4)将注意力权重与对应的V向量相乘,并求和,得到自注意力的输出。
提出 Transformer的谷歌学者们认为,在自注意力机制的帮助下,我们完全可以摒弃传统的RNN或LSTM等方法,不再需要一个接一个地处理序列元素。这使 Transformer能够更好地利用现代计算设备的并行计算能力,从而大幅提升了训练和推理速度,也使得模型具有强大的表达能力。这就是为什么Transformer在处理长距离依赖时比传统的 RNN 和 LSTM等方法更加高效。
在 Transformer 中,自注意力是通过多头自注意力来实现的。
Transformer中的多头自注意力
多头自注意力是Transformer中一个非常重要的概念,是对自注意力机制的一种扩展,旨在让模型能够同时关注输入序列中的多个不同的表示子空间,从而捕捉更丰富的信息。
多头自注意力的灵感来自多任务学习。你可以把它想象成一个小团队,每个成员都在关注输入序列的不同方面。通过将注意力分为多个头,可以将自注意力机制复制多次(通常设定为8次或更多)。每个头使用不同的权重参数进行自注意力计算。由此,模型可以学会从不同的角度关注输入序列,从而捕捉更丰富的信息。多头自注意力的输出会被拼接起来,然后通过一个线性层进行整合,得到多头自注意力的最终输出(如图所示)。
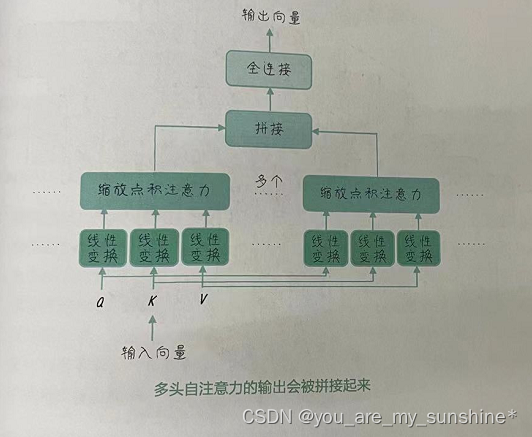
多头自注意力的计算过程如下:
- (1)对于每个头,将输入序列的每个元素分别投影到三个不同的向量空间,得到Q、 K和V向量。
- (2)使用Q、K和 V向量计算自注意力输出。
- (3)将所有头的输出沿着最后一个维度拼接起来。
- (4)通过一个线性层,将拼接后的结果映射到最终的输出空间。
多头自注意力既可以用于编码器和解码器的自注意力子层,也可以用于解码器的编码器-解码器注意力子层。通过这种设计,Transformer能够更好地捕捉输入序列中的局部和全局依赖关系,从而进一步提升模型的表达能力。
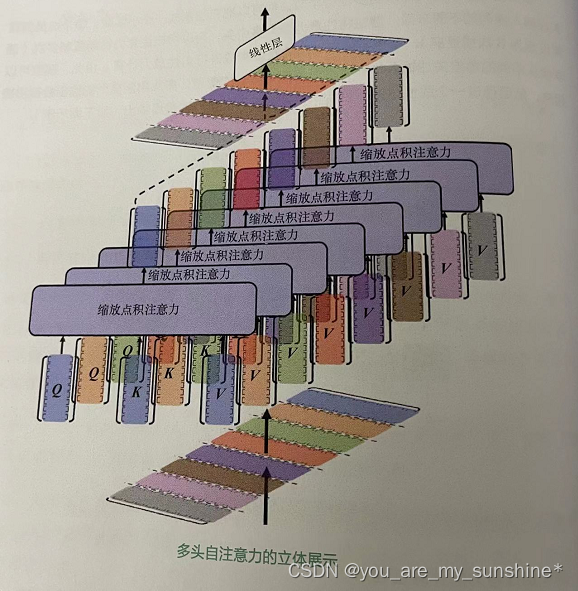
下面这张图片为Transformer中的多头自注意力进行了立体可视化,很好地体现了它的实现过程。
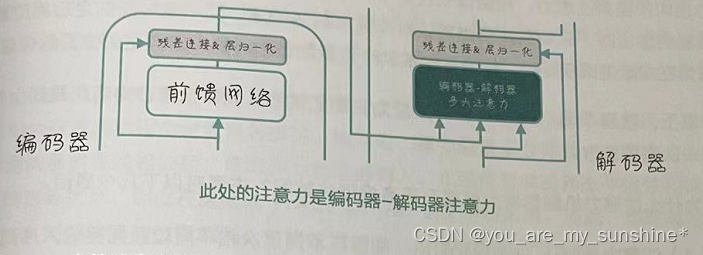
Transformer中的编码器-解码器注意力
Transformer 中还有一个额外的“编码器——解码器注意力”层(如下图所示)。这个编码器——解码器注意力主要用于解码器中,使得解码器能够关注到编码器输出的相关信息,从而更好地生成目标序列。它的计算过程与自注意力类似,但是这里的Q向量来自解码器的上一层输出,而K和V向量则来自编码器的输出。
Transformer中的注意力掩码和因果注意力
在注意力机制中,我们希望告诉模型,哪些信息是当前位置最需要关注的;同时也希望告诉模型,某些特定信息是不需要被关注的,这就是注意力掩码的作用。
Transformer 中的注意力掩码主要用于以下两种情况。
-
填充注意力掩码(Padding Attention Mask):当处理变长序列时,通常需要对较短的序列进行填充,使所有序列具有相同的长度,以便进行批量处理。填充的部分对实际任务没有实际意义,因此我们需要使用填充注意力掩码来避免模型将这些填充位置考虑进来。填充注意力掩码用于将填充部分的注意力权重设为极小值,在应用softmax时,这些位置的权重将接近于零,从而避免填充部分对模型输出产生影响。在Transformer的编码器中,我们只需要使用填充注意力掩码。
-
后续注意力掩码(Subsequent Attention Mask),又称前瞻注意力掩码(Look-ahead Attention Mask):在自回归任务中,例如文本生成,模型需要逐步生成输出序列。在这种情况下,为了避免模型在生成当前位置的输出时,提前获取未来位置的信息,需要使用前瞻注意力掩码。前瞻注意力掩码将当前位置之后的所有位置的注意力权重设为极小值,这样在计算当前位置的输出时,模型只能访问到当前位置之前的信息,从而确保输出的自回归性质。在 Transformer的解码器中,不仅需要使用填充注意力掩码,还需要使用后续注意力掩码。
为什么注意力机制能够大幅提升语言模型性能呢?主要有以下几个原因。
- (1)注意力机制让Transformer能够在不同层次和不同位置捕捉输入序列中的依赖关系。
- (2)注意力机制使得模型具有强大的表达能力,能够有效处理各种序列到序列任务。
- (3)由于注意力机制的计算可以高度并行化,Transformer的训练速度也得到了显著提升。
Transformer 的这几个优势,终于克服了传统NLP 模型(如TextCNN、RNN和LSTM)处理长文本序列问题时的局限,它的出现可谓NLP 领域的雪耻时刻。
编码器的输入和位置编码
首先,我们会把需要处理的文本序列转换为一个输入 位置编码 词嵌入向量(Word Embedding),它负责将输入的词转换成词向量。然后,我们会为这些词向量添加位置编码 输入词 嵌入向量 (Positional Encoding),从而为模型提供位置信息,如右图所示。

图中的类似于太极图的那个符号其实是“正弦”符号。正弦位置编码使用不同频率的正弦和余弦函数对每个位置进行编码。编码后,每个位置都会得到一个固定的位置编码,与词向量拼接或相加后,可以作为模型的输入。正弦位置编码具有平滑性和保留相对位置信息等优点,因此在原始的Transformer 论文中被采用。当然,也有其他位置编码方法,如可学习的位置编码,它将位置信息作为模型参数进行学习。
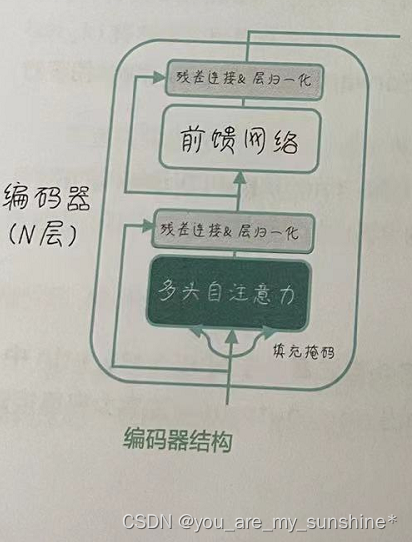
编码器的内部结构
编码器由多个相同结构的层堆叠而成,每个层包含两个主要部分:多头自注意力和前馈神经网络。让我们一步一步地剖析这两个部分。
首先,刚才说了,当输入序列经过词嵌入处理后,会得到一组词向量。为了将位置信息融入这些词向量中,我们还需要为它们添加位置编码。这一步的目的是让模型能够区分输入序列中不同位置的词。
接下来,词向量和位置编码将结合起来进入编码器的第一层。在这一层中,会先进行多头自注意力计算。多头自注意力允许模型从不同的角度关注输入序列,捕捉更丰富的信息。每个头都有自己的注意力权重,这些权重将被用来对输入序列的不同部分进行加权求和。
多头自注意力的输出会与原始输入相加,也就是残差连接(Residual Connection),然后经过层归一化(Layer Normalization)处理,如右图所示。层归一化有助于稳定模型的训练过程,提高模型的收敛速度。“残差连接&层归一化”这个模块,在Transformer相关英文论文中被简称为“Add & Norm”层。

之后,我们将进入前馈神经网络(Feed-Forward Neural Network,FFNN)部分。FFNN 是一个包含两个线性层和一个激活函数(如ReLU)的简单网络。这个网络将对上一步得到的输出进行非线性变换。
最后,前馈神经网络的输出会与多头自注意力的结果再次相加,残差连接及层归一化并进行层归一化,如图所示。这样,我们就完成了编码器中一个前馈网络层的处理过程。
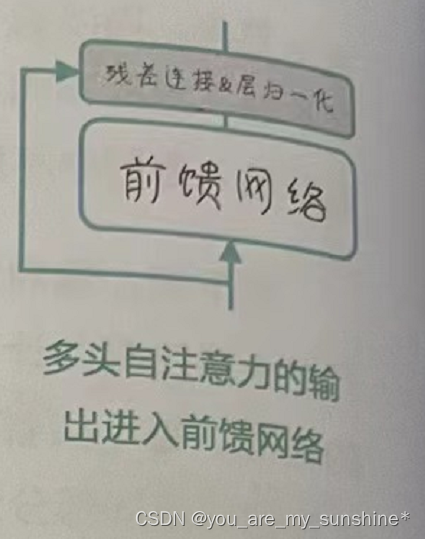
这个过程会在编码器的所有层中重复进行,最后一层的输出将被传递给解码器。解码器通过这种方式,可以对输入序列的信息进行深度提取和表示,为解码器生成目标序列提供了有力的支持。
编码器的输出和编码器-解码器的连接
编码器的输出向量会被传递给解码器的编码器一解码器注意力计算单元。
这种设计使得解码器能够在生成目标序列时,充分利用输入序列的信息,从而提高生成结果的准确性。同时,通过自注意力和编码器一解码器注意力机制的结合,解码器可以捕捉目标序列内部和输入序列与目标序列之间的依赖关系,进一步增强模型的表达能力。
解码器的输入和位置编码
现在让我们来谈谈解码器的输入部分。解码器的主要任务基于编码器输出的上下文向量生成目标序列。不过,解码器并不仅接收编码器的输出序列,而是需要首先接收自己的输入序列,这个输入通常是目标序列的一个部分,英文中通常叫作“输出”(Output),如图所示。

具体来说:
- 在训练阶段中,我们通常会使用目标序列的真值作为解码器的输入,这种方法称为“教师强制”训练。在之前当我们进行Seq2Seq模型的搭建时,已经使用过教师强制,把目标序列输送给解码器以帮助训练了。为了便于理解,当时,我把这个传递给解码器的序列命名为“decoder_input”,而在有些Seq2Seq 模型教学程序中,它会被直接命名为“Output”,而解码器的预测值当然也会被称为“Output”,也就是“Prediction”。这就有点令人费解了吧,解码器的输入序列和输出序列都叫“输出”( Output)。
- 在推理阶段中,解码器的输入则是模型自己已经生成的目标序列(所以这个序列叫“Output”也没错,它既是解码器现在的输入,也是解码器之前的输出)。这个训练阶段和推理阶段的区别非常重要。
输出序列后面所标注的“向右位移”该如何理解?
在第一个位置上填充一个特殊的起始符号(例如《sos》或《start》),作为当前时刻的输入,如果有教师强制,则解码器输入后续的位置就会自然地向右位移一位;如果没有教师强制,那么每个时刻生成的输出也会向右位移一位,与真值相比,左边多了一个起始符。
“今天天气真好,我们去”
我们可以这样准备训练数据。
源序列(输入):“《sos》 今天天气真好,我们去”
目标序列(输出):“今天天气真好,我们去《eos》”
在这个例子中,我们在源序列的开头添加了一个特殊的起始符号(《sos》),用于表示序列的开始。我们还在目标序列的结尾添加了一个特殊的结束符号(《eos》),表示序列的结束。
所谓向右位移一位,其实就是"今"在输入序列中是第一个token,现在加了 《sos》 再输入解码器就变成了输入序列的第二个token。
在Transformer中,虽然每个位置的词都是并行处理的,但是通过序列的“右移一位”操作及后续的掩码操作,确保了在预测某个位置的词时,模型只能使用该位置前面的词作为上下文信息,不能使用未来的信息。这就使得Transformer能够像 RNN那样,从左到右逐词生成序列,但同时又避免了RNN的顺序计算的限制,提高了计算效率。
下面接着谈解码器的输入序列处理流程,这部分和编码器一样。首先,输入序列会经过词嵌入处理,得到一组词向量。与编码器类似,我们还需要对这些词向量进行位置编码,以便模型能够区分输入序列中不同位置的词。接下来,解码器的输入序列的词向量和位置编码的结合将进入解码器的第一层的第一个单元,计算解码器向量的多头自注意力。
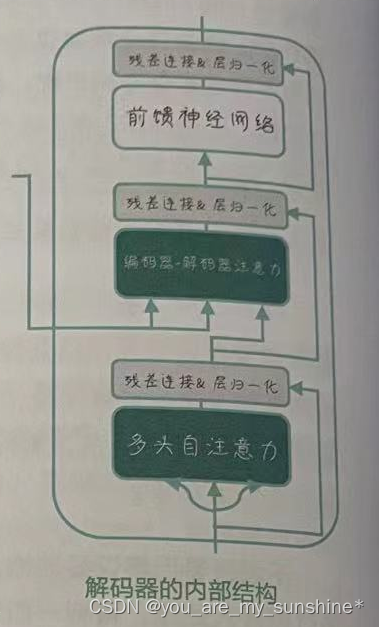
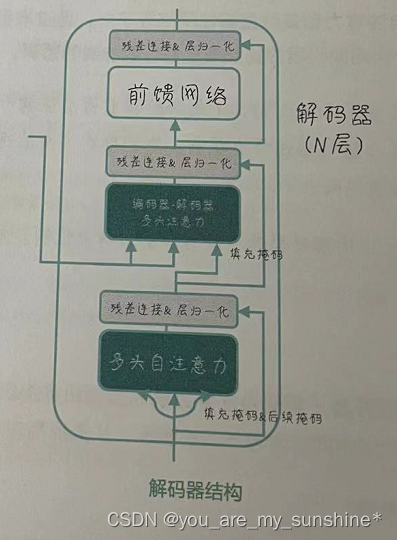
解码器的内部结构
和编码器一样,解码器也由多个相同结构的层堆叠而成,每个层包含多头自注意力机制、编码器-解码器注意力机制、前馈神经网络三个主要单元(如图所示)。
首先,解码器会进行多头自注意力计算。这个过程类似于编码器中的多头自注意力计算,但解码器的自注意力机制在处理时要遵循一个重要的原则:只能关注已经生成的输出序列中的位置,避免在生成新词时“看到未来”。
在解码器的多头自注意力之后,我们在第二个处理单元进行编码器——解码器注意力计算。这个过程中解码器需要同时关注来自编码器的源序列信息和解码器自身输入的自注意力信息,以生成目标序列。此时,编码器的输出将作为这个注意力机制的Key向量和Value向量,而解码器自身的自注意力输出将作为Query向量。
接下来的步骤与编码器类似,我们将进行残差连接和层归一化、前馈神经网络计算,以及再次进行残差连接和层归一化。这个过程在解码器的所有层中重复进行,最后一层的输出将用于预测目标序列。
这就是解码器如何接收属于自己的输入(右移后的目标序列)并结合编码器输出(上下文向量)来生成目标序列预测值的过程。
解码器的输出和Transformer的输出头
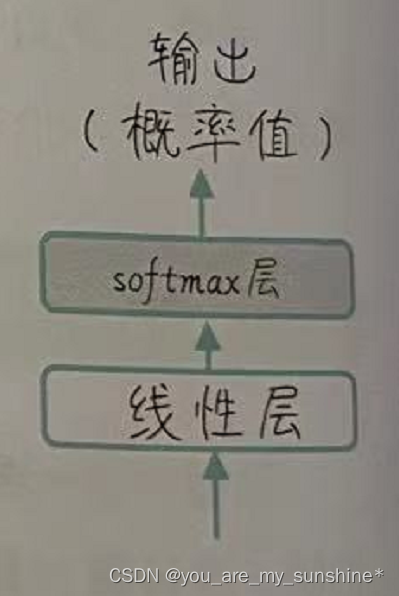
首先,线性层负责将解码器输出的向量映射到词汇表大小的空间。这意味着,对于每个位置,线性层的输出将包含一个与词汇表中每个线性层 词对应的分数。这个分数可以理解为当前位置生成该词的概率。
紧接着,我们将对这些分数应用softmax函数,从而将它们转换为概率分布,确保所有概率之和为 1,这样我们就可以更方便地比较这些分数,并选择最有可能是结果的词。
至此,Transformer已经输出了目标序列的概率分布。具体的下游任务将根据这个概率分布来解决问题。例如,在机器翻译任务中,通常会选择概率最高的词作为预测的翻译结果;而在文本摘要或问答任务中,可能会根据这个概率分布来生成摘要或回答。
- 机器翻译:在机器翻译任务中,Transformer的输出头是一个词汇表大小的概率分布。可以使用贪婪解码(Greedy Decode)、集束搜索(Beam Search)等解码方法来生成翻译结果。损失函数通常为交叉熵损失,用于衡量模型预测与实际目标序列之间的差距。
- 文本摘要:文本摘要任务与机器翻译类似,都需要生成一个目标序列,因此,输出头也是一个词汇表大小的概率分布。但在解码阶段,可以采用不同的策略来生成摘要,如集束搜索或者采样。损失函数通常也是交叉熵损失。
- 文本分类:文本分类任务需要根据输入序列预测类别标签。可以将 Transformer 的输出头替换为一个全连接层,将词汇表大小的输出概率分布转换为类别标签的概率分布。损失函数可以选择交叉熵损失或其他适用于分类问题的损失函数。
- 问答任务:问答任务通常需要预测答案在输入序列中的起始和结束位置。可以将Transformer的输出头替换为两个全连接层,分别预测答案的起始位置的概率分布和结束位置的概率分布。损失函数可以设置为两个交叉熵损失,分别衡量起始位置和结束位置预测结果的准确性。
- 命名实体识别:命名实体识别任务需要为输入序列中的每个词分配一个标签。可以将Transformer的输出头替换为一个全连接层,输出每个位置的标签概率分布。损失函数可以选择逐位置交叉熵损失。
这些示例展示了如何针对不同任务调整Transformer 模型的输出头和损失函数。通过这些调整,可以将基本的Transformer 应用于各种自然语言处理任务。
Transformer代码实现
让我们回到Transformer架构图,逐个组件地去实现它(如图所示)。这个逐步拆解的过程是从中心到两边、从左到右进行的。也就是从中心组件到外围延展,从编码器到解码器延展,然后把它们组合成Transformer 类。
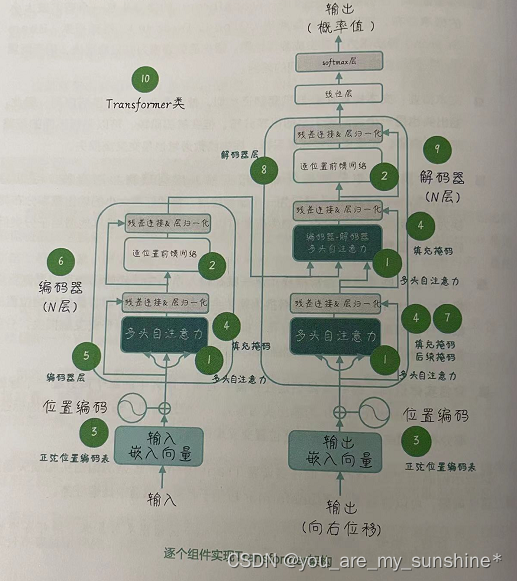
以下是代码的关键组件。
- (1)多头自注意力:通过 ScaledDotProductAttention类实现缩放点积注意力机制,然后通过MultiHeadAttention类实现多头自注意力机制。
- (2)逐位置前馈网络:通过PoswiseFeedForwardNet类实现逐位置前馈网络。
- (3)正弦位置编码表:通过get_sin_code_table函数生成正弦位置编码表。
- (4)填充掩码:通过get_attn_pad_mask函数为填充令牌《pad》生成注意力掩码,避免注意力机制关注无用的信息。
- (5)编码器层:通过EncoderLayer类定义编码器的单层。
- (6)编码器:通过Encoder 类定义Transformer完整的编码器部分。
- (7)后续掩码:通过get_attn_subsequent_mask函数为后续令牌(当前位置后面的信息)生成注意力掩码,避免解码器中的注意力机制“偷窥”未来的目标数据。
- (8)解码器层:通过 DecoderLayer 类定义解码器的单层。
- (9)解码器:通过 Decoder 类定义 Transformer 完整的解码器部分。
- (10) Transformer类:此类将编码器和解码器整合为完整的 Transformer 模型。
组件1_多头注意力(包含残差连接和层归一化)

这里我们有两个子组件:ScaledDotProductAttention(缩放点积注意力)类和 MultiHeadAttention(多头自注意力)类。它们在Transformer架构中负责实现自注意力机制。其中,ScaledDotProductAttention类是构成MultiHeadAttention类的组件元素,也就是说,在多头自注意力中的每一个头,都使用缩放点积注意力来实现。
import numpy as np # 导入 numpy 库
import torch # 导入 torch 库
import torch.nn as nn # 导入 torch.nn 库
d_k = 64 # K(=Q) 维度
d_v = 64 # V 维度
# 定义缩放点积注意力类
class ScaledDotProductAttention(nn.Module):def __init__(self):super(ScaledDotProductAttention, self).__init__() def forward(self, Q, K, V, attn_mask):#------------------------- 维度信息 -------------------------------- # Q K V [batch_size, n_heads, len_q/k/v, dim_q=k/v] (dim_q=dim_k)# attn_mask [batch_size, n_heads, len_q, len_k]#----------------------------------------------------------------# 计算注意力分数(原始权重)[batch_size,n_heads,len_q,len_k]scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) #------------------------- 维度信息 -------------------------------- # scores [batch_size, n_heads, len_q, len_k]#----------------------------------------------------------------- # 使用注意力掩码,将 attn_mask 中值为 1 的位置的权重替换为极小值#------------------------- 维度信息 -------------------------------- # attn_mask [batch_size, n_heads, len_q, len_k], 形状和 scores 相同#----------------------------------------------------------------- scores.masked_fill_(attn_mask, -1e9) # 对注意力分数进行 softmax 归一化weights = nn.Softmax(dim=-1)(scores) #------------------------- 维度信息 -------------------------------- # weights [batch_size, n_heads, len_q, len_k], 形状和 scores 相同#----------------------------------------------------------------- # 计算上下文向量(也就是注意力的输出), 是上下文信息的紧凑表示context = torch.matmul(weights, V) #------------------------- 维度信息 -------------------------------- # context [batch_size, n_heads, len_q, dim_v]#----------------------------------------------------------------- return context, weights # 返回上下文向量和注意力分数
这段代码中先定义 Q、K和V的维度,为了实现点积,K和Q的维度必须相等。
此处的 ScaledDotProductAttention类负责计算缩放点积注意力,将输入张量作为输入,并为每个位置计算一个权重向量。我们首先使用三个不同的线性变换Q、K和V将输入张量投影到不同的向量空间,并将这些投影向量分成多个头。然后,通过缩放点积注意力,计算每个位置与其他位置的相关性得分(也就是我们之前讲的从原始权重 raw_weights 缩放后的权重scaled_weights)。之后,使用softmax函数对这些得分进行归一化以产生最终权重向量weights。它计算Q、K和V之间的关系,并根据注意力掩码 attn_mask调整注意力分数。最后,根据注意力权重计算出上下文向量,这也就是前面多次提到的attn_output。
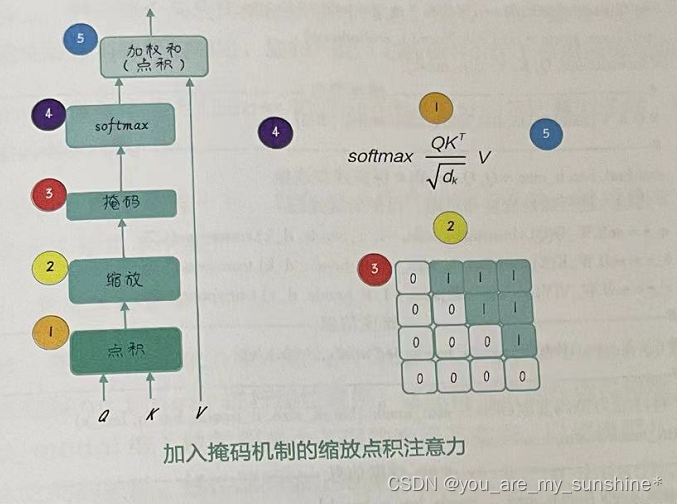
在 ScaledDotProductAttention类的 forward 方法中,会接收掩码张量attn_mask 这个参数,这个张量是在编码器/解码器的输入部分创建的,用于表示哪些位置的注意力分数应该被忽略。它与scores 张量具有相同的维度,使得两者可以逐元素地进行操作。
代码中的 scores.masked_fill_(attn_mask,-1e9)是一个就地(in-place)操作,它将scores 张量中对应attn_mask 值为1的位置替换为一个极小值(-1e9)。这么做的目的是在接下来应用softmax函数时,使这些位置的权重接近于零。这样,在计算上下文向量时,被掩码的位置对应的值对结果的贡献就会非常小,几乎可以忽略。
在实际应用中,注意力掩码可以用于遮蔽填充部分,或者在解码过程中避免看到未来的信息。这些掩码可以帮助模型聚焦于真实的输入数据,并确保在自回归任务中,解码器不会提前访问未来的信息。
下面定义多头自注意力另一个子组件,多头自注意力类(这里同时包含残差连接和层归一化操作)。
# 定义多头自注意力类
d_embedding = 512 # Embedding 的维度
n_heads = 8 # Multi-Head Attention 中头的个数
batch_size = 3 # 每一批的数据大小
class MultiHeadAttention(nn.Module):def __init__(self):super(MultiHeadAttention, self).__init__()self.W_Q = nn.Linear(d_embedding, d_k * n_heads) # Q的线性变换层self.W_K = nn.Linear(d_embedding, d_k * n_heads) # K的线性变换层self.W_V = nn.Linear(d_embedding, d_v * n_heads) # V的线性变换层self.linear = nn.Linear(n_heads * d_v, d_embedding)self.layer_norm = nn.LayerNorm(d_embedding)def forward(self, Q, K, V, attn_mask): #------------------------- 维度信息 -------------------------------- # Q K V [batch_size, len_q/k/v, embedding_dim] #----------------------------------------------------------------- residual, batch_size = Q, Q.size(0) # 保留残差连接# 将输入进行线性变换和重塑,以便后续处理q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2)v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2)#------------------------- 维度信息 -------------------------------- # q_s k_s v_s: [batch_size, n_heads, len_q/k/v, d_q=k/v]#----------------------------------------------------------------- # 将注意力掩码复制到多头 attn_mask: [batch_size, n_heads, len_q, len_k]attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)#------------------------- 维度信息 -------------------------------- # attn_mask [batch_size, n_heads, len_q, len_k]#----------------------------------------------------------------- # 使用缩放点积注意力计算上下文和注意力权重context, weights = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)#------------------------- 维度信息 -------------------------------- # context [batch_size, n_heads, len_q, dim_v]# weights [batch_size, n_heads, len_q, len_k]#----------------------------------------------------------------- # 通过调整维度将多个头的上下文向量连接在一起context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) #------------------------- 维度信息 -------------------------------- # context [batch_size, len_q, n_heads * dim_v]#----------------------------------------------------------------- # 用一个线性层把连接后的多头自注意力结果转换,原始地嵌入维度output = self.linear(context) #------------------------- 维度信息 -------------------------------- # output [batch_size, len_q, embedding_dim]#----------------------------------------------------------------- # 与输入 (Q) 进行残差链接,并进行层归一化后输出output = self.layer_norm(output + residual)#------------------------- 维度信息 -------------------------------- # output [batch_size, len_q, embedding_dim]#----------------------------------------------------------------- return output, weights # 返回层归一化的输出和注意力权重
这段代码首先用全局变量设置了嵌入向量的维度大小d_embedding 和注意力头 n_heads 的数量。同时定义批次大小batch_size。
MultiHeadAttention 类实现了多头自注意力机制。首先,它将输入序列Q、K和V分别映射到多个头上,并对每个头应用缩放点积注意力。然后,它将这些头的结果拼接起来,并通过一个线性层得到最终的输出。层归一化(LayerNorm)被用来稳定训练过程。
在Transformer架构中的Encoder和 Decoder 部分的自注意力子层,将会实例化MultiHeadAttention类。
-
线性变换:在多头自注意力中,输入的Query、Key和Value分别通过三个不同的线性层nn.Linear进行线性变换。这些线性层的作用是将输入的每个词向量(d_model维)映射到多个不同的表示子空间,以便模型从不同的角度捕获输入之间的关系。线性层的输出维度分别为d_kn_heads、d_kn_ heads 和 d_v* n_heads,其中n_heads表示注意力头的数量,d_k表示每个头中的 Key 和Query(d_q=d_k)向量的维度,d_v表示每个头中的 Value 向量的维度。
-
重塑和置换:线性变换后,我们需要将输出张量重新整形,以便将不同的注意力头分开。这里的view和transpose操作用于实现这一目标。首先,通过view函数,我们将每个输入的(d_k/d_v * n_heads )维度变为[n_heads ,d_k](对于Query 和 Key) 或[n_heads,d_v](对于 Value)。然后,使用 transpose 函数将 seq_len 维和 n_heads维互换,最终得到形状为[batch_ size, n_heads, seq_len,d_k](对于 Query和Key)或[batch_size, n_heads, seq_len, d_v](对于 Value)的张量。这样,我们就可以将每个头的 Query、Key 和 Value 分开处理,实现多头自注意力。
经过这些处理,我们可以在不同表示子空间中并行计算注意力。这有助于模型更好地捕捉输入之间的不同方面的信息和关系,从而提高模型的性能,这个过程如图所示。
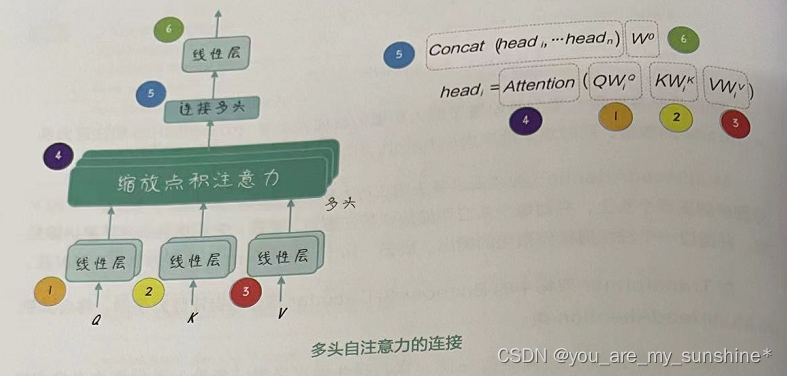
下面就图中的公式所对应的代码步骤做一个说明。 -
(1) 1、2、3对应代码中的:
q_s = self.W_Q(Q).view(batch_size,-1,n_heads, d_k).transpose(1,2)
k_s = self.W_K(K).view(batch_size,-1, n_heads, d_k).transpose(1,2)
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2)
其中,Q、K、V分别乘以权重矩阵W_Q、W_K、W_V,并通过view 和 transpose 方法改变形状以便后续处理。
- (2)Attention()对应代码中的:
context, weights =ScaledDotProductAttention((q_s,k_s,v_s, attn_mask)
缩放点积注意力是注意力机制的核心部分。
- (3) Concat(headi,… headn)对应代码中的:
context = context.transpose(1, 2).contiguous(.view(batch_size, -1, n_heads * d_v)
其中,context的维度变换实现了不同头输出的连接。
(4)W°对应代码中的:
output = self.linear(context)
其中,self.linear是一个线性层,其参数是权重矩阵,也就是公式中的 W°。
同时,在多头自注意力中,我们也需要将注意力掩码应用到每个注意力头上。为此,我们需要将原始的注意力掩码沿着注意力头的维度进行重复,以确保每个头都有一个相同的掩码来遮蔽注意力分数。
在代码中我们首先用unsqueeze(1)函数在批量维度(batch dimension)和头维度( head dimension)之间插入一个新维度。这样,attn_mask张量的形状大小变为 batch_size x1 xlen_q x len_k。接下来,使用repeat函数沿着新插入的头维度重复掩码。我们在头维度上重复n_heads次,这样,每个注意力头都有一个相同的掩码。重复后,attn_mask张量的形状大小变为batch_size x n_heads xlen_q x len_k。
现在,我们已经为每个注意力头准备好了注意力掩码,可以将它应用到每个头的注意力分数上。这样,无论是填充掩码还是后续掩码,我们都可以确保每个头都遵循相同的规则来计算注意力。
组件2_逐位置前馈网络(包含残差连接和层归一化)
在Transformer编码器和解码器的每一层注意力层之后,都衔接有一个 PoswiseFeedForwardNet类,起到进一步提取特征和表示的作用。
无论是多头自注意力组件,还是前馈神经网络组件,都严格地保证“队形”,不打乱、不整合、不循环,而这种对序列位置信息的完整保持和并行处理,正是Transformer 的核心思路。
# 定义逐位置前馈网络类
class PoswiseFeedForwardNet(nn.Module):def __init__(self, d_ff=2048):super(PoswiseFeedForwardNet, self).__init__()# 定义一维卷积层 1,用于将输入映射到更高维度self.conv1 = nn.Conv1d(in_channels=d_embedding, out_channels=d_ff, kernel_size=1)# 定义一维卷积层 2,用于将输入映射回原始维度self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_embedding, kernel_size=1)# 定义层归一化self.layer_norm = nn.LayerNorm(d_embedding)def forward(self, inputs): #------------------------- 维度信息 -------------------------------- # inputs [batch_size, len_q, embedding_dim]#---------------------------------------------------------------- residual = inputs # 保留残差连接 # 在卷积层 1 后使用 ReLU 激活函数 output = nn.ReLU()(self.conv1(inputs.transpose(1, 2))) #------------------------- 维度信息 -------------------------------- # output [batch_size, d_ff, len_q]#----------------------------------------------------------------# 使用卷积层 2 进行降维 output = self.conv2(output).transpose(1, 2) #------------------------- 维度信息 -------------------------------- # output [batch_size, len_q, embedding_dim]#----------------------------------------------------------------# 与输入进行残差链接,并进行层归一化output = self.layer_norm(output + residual) #------------------------- 维度信息 -------------------------------- # output [batch_size, len_q, embedding_dim]#----------------------------------------------------------------return output # 返回加入残差连接后层归一化的结果
PoswiseFeedForwardNet类实现了逐位置前馈网络,用于处理Transformer中自注意力机制的输出。其中包含两个一维卷积层,它们一个负责将输入映射到更高维度,一个再把它映射回原始维度。在两个卷积层之间,使用了ReLU函数。
在PoswiseFeedForwardNet类中,首先通过使用conv1的多个卷积核将输入序列映射到更高的维度(程序后的序列降维到原始维度。这个过程在输入 中是2048维,这是一个可调节的超参数), 并应用 ReLU 函数。接着,conv2将映射序列的每个位置上都是独立完成的,因为一维卷积层会在每个位置进行逐点操作。所以,逐位置前馈神经网络能够在每个位置上分别应用相同的运算,从而捕捉输入序列中各个位置的信息。
多头自注意力层和逐位置前馈神经网络层是编码器层结构中的两个主要组件,不过,在开始构建编码器层之前,还要再定义两个辅助性的组件。第一个是位置编码表,第二个是生成填充注意力掩码的函数。
组件3_正弦位置编码表
Transformer模型的并行结构导致它不是按位置顺序来处理序列的,但是在处理序列尤其是注意力计算的过程中,仍需要位置信息来帮助捕捉序列中的顺序关系。为了解决这个问题,需要向输入序列中添加位置编码。
Transformer的原始论文中使用的是正弦位置编码。它的计算公式如下:
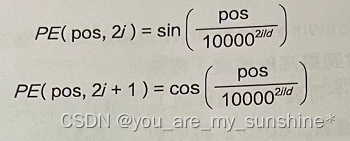
这种位置编码方式具有周期性和连续性的特点,可以让模型学会捕捉位置之间的相对关系和全局关系。这个公式可以用于计算位置嵌入向量中每个维度的角度值。
- pos:单词/标记在句子中的位置,从0到seq_len-1。
- d:单词/标记嵌入向量的维度embedding_dim。
- i:嵌入向量中的每个维度,从0到(d/2)-1。
公式中d 是固定的,但 pos 和i是变化的。如果 d=1024,则i∈ [0,512],因为 2i和 2i+1 分别代表嵌入向量的偶数和奇数位置。
# 生成正弦位置编码表的函数,用于在 Transformer 中引入位置信息
def get_sin_enc_table(n_position, embedding_dim):#------------------------- 维度信息 --------------------------------# n_position: 输入序列的最大长度# embedding_dim: 词嵌入向量的维度#----------------------------------------------------------------- # 根据位置和维度信息,初始化正弦位置编码表sinusoid_table = np.zeros((n_position, embedding_dim)) # 遍历所有位置和维度,计算角度值for pos_i in range(n_position):for hid_j in range(embedding_dim):angle = pos_i / np.power(10000, 2 * (hid_j // 2) / embedding_dim)sinusoid_table[pos_i, hid_j] = angle # 计算正弦和余弦值sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i 偶数维sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1 奇数维 #------------------------- 维度信息 --------------------------------# sinusoid_table 的维度是 [n_position, embedding_dim]#---------------------------------------------------------------- return torch.FloatTensor(sinusoid_table) # 返回正弦位置编码表
在后续编码器(及解码器)组件中,我们将调用这个函数生成位置嵌入向量,为编码器和解码器输入序列中的每个位置添加一个位置编码,如图所示。

组件4_填充掩码
在NLP任务中,输入序列的长度通常是不固定的。为了能够同时处理多个序列,我们需要将这些序列填充到相同的长度,将不等长的序列补充到等长,这样才能将它们整合成同一个批次进行训练。通常使用一个特殊的标记(如《pad》,编码后《pad》这个 token 的值通常是0)来表示填充部分。
然而,这些填充符号并没有实际的含义,所以我们希望模型在计算注意力时忽略它们。因此,在编码器的输入部分,我们使用了填充位的注意力掩码机制(如图所示)。这个掩码机制的作用是在注意力计算的时候把无用的信息屏蔽,防止模型在计算注意力权重时关注到填充位。
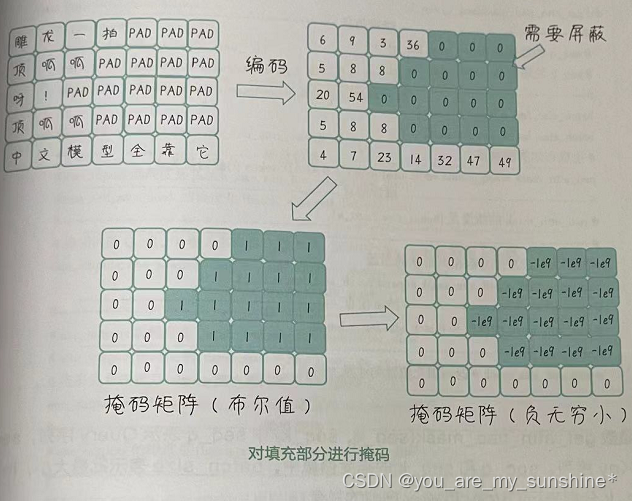
屏蔽流程如下:
- (1)根据输入文本序列创建一个与其形状相同的二维矩阵。对于原始文本中的每个单词,矩阵中对应位置填充0;对于填充的 符号,矩阵中对应位置填充1。
- (2)需要将填充掩码矩阵应用到注意力分数矩阵上。注意力分数矩阵是通过查询、键和值矩阵计算出的。为了将填充部分的权重降至接近负无穷,我们可以先将填充掩码矩阵中的1替换为一个非常大的负数(例如-1e9),再将处理后的填充掩码矩阵与注意力分数矩阵进行元素相加。这样,有意义的token 加了0,值保持不变,而填充部分加了无穷小值,在注意力分数矩阵中的权重就会变得非常小。
- (3)对注意力分数矩阵应用softmax函数进行归一化。由于填充部分的权重接近负无穷,softmax函数会使其归一化后的权重接近于0。这样,模型在计算注意力时就能够忽略填充部分的信息,专注于序列中实际包含的有效内容。
# 定义填充注意力掩码函数
def get_attn_pad_mask(seq_q, seq_k):#------------------------- 维度信息 --------------------------------# seq_q 的维度是 [batch_size, len_q]# seq_k 的维度是 [batch_size, len_k]#-----------------------------------------------------------------batch_size, len_q = seq_q.size()batch_size, len_k = seq_k.size()# 生成布尔类型张量pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # <PAD>token 的编码值为 0#------------------------- 维度信息 --------------------------------# pad_attn_mask 的维度是 [batch_size,1,len_k]#-----------------------------------------------------------------# 变形为与注意力分数相同形状的张量 pad_attn_mask = pad_attn_mask.expand(batch_size, len_q, len_k)#------------------------- 维度信息 --------------------------------# pad_attn_mask 的维度是 [batch_size,len_q,len_k]#-----------------------------------------------------------------return pad_attn_mask
在多头自注意力计算中计算注意力权重时,会将这个函数生成的填充注意力掩码与原始权重相加,使得填充部分的权重变得非常小(接近负无穷),从而在使用softmax函数归一化后接近于0,实现忽略填充部分的效果。
组件5_编码器层
有了多头自注意力和逐位置前馈网络这两个主要组件,以及正弦位置编码表和填充掩码这两个辅助函数后,现在我们终于可以搭建编码器层这个核心组件了。
# 定义编码器层类
class EncoderLayer(nn.Module):def __init__(self):super(EncoderLayer, self).__init__() self.enc_self_attn = MultiHeadAttention() # 多头自注意力层 self.pos_ffn = PoswiseFeedForwardNet() # 位置前馈神经网络层def forward(self, enc_inputs, enc_self_attn_mask):#------------------------- 维度信息 --------------------------------# enc_inputs 的维度是 [batch_size, seq_len, embedding_dim]# enc_self_attn_mask 的维度是 [batch_size, seq_len, seq_len]#-----------------------------------------------------------------# 将相同的 Q,K,V 输入多头自注意力层 , 返回的 attn_weights 增加了头数 enc_outputs, attn_weights = self.enc_self_attn(enc_inputs, enc_inputs,enc_inputs, enc_self_attn_mask)#------------------------- 维度信息 --------------------------------# enc_outputs 的维度是 [batch_size, seq_len, embedding_dim] # attn_weights 的维度是 [batch_size, n_heads, seq_len, seq_len] # 将多头自注意力 outputs 输入位置前馈神经网络层enc_outputs = self.pos_ffn(enc_outputs) # 维度与 enc_inputs 相同#------------------------- 维度信息 --------------------------------# enc_outputs 的维度是 [batch_size, seq_len, embedding_dim] #-----------------------------------------------------------------return enc_outputs, attn_weights # 返回编码器输出和每层编码器注意力权重
编码器层EncoderLayer类的__init__方法中,定义内容如下。
-
(1)定义了多头自注意力层MultiHeadAttention 实例enc_self_attn,用于实现序列内部的自注意力计算。
-
(2)定义了逐位置前馈网络层PoswiseFeedForwardNet 实例pos_ffn,用于对自注意力层处理后的序列进行进一步特征提取。
EncoderLayer类的forward方法接收两个参数:enc_inputs 表示输入的序列, enc_self_attn_mask 表示自注意力计算时使用的掩码(如填充掩码)。
forward 方法内部流程如下。
- (1)将enc_inputs 作为 Q、K、V输入到多头自注意力层enc_self_attn中,并将enc_self_attn_mask作为掩码。得到输出enc_outputs,注意力权重矩阵 attn_weights。
- (2)将enc_outputs 输入逐位置前馈网络层pos_ffn,并更新enc_outputs。
- (3)最后返回enc_outputs和attn_weights.enc_outputs表示编码器层的输出, attn_weights 表示自注意力权重矩阵,可以用于分析和可视化。
在多头自注意力层MultiHeadAttention 的输出中,enc_outputs的维度是[batch_size,seq_len,embedding_dim]。原因是在多头自注意力层 MultiHeadAttention 内部,首先将输入的enc_inputs 映射为2、K、v,这些映射后的张量的维度为[batch_size,n_heads, seq_len,d_k]。然后,通过对这些张量进行自注意力计算,得到的注意力输出的维度也为[batch_size,n_heads, seq_len,d_ k]。最后,我们需要将这些头合并回原来的维度,这通过将最后两个维度进行拼接实现,也就是n_heads * d_k等于embedding_dim,所以最终的enc_outputs的维度就是[batch_size, seq_len, embedding_dim]。
而对于 attn_weights,在多头自注意力层MultiHeadAttention 内部,首先将输入的 enc_inputs 映射为Q、K、v,这些映射后的张量的维度为[batch_size,n_ heads, seq_len,d_k]。然后,通过计算Q和K的点积得到注意力分数,通过 softmax 进行归一化,得到的注意力权重的维度是[batch_size,n_heads, seq_len, seq_len]。这个维度的含义是,对于每个批次中的每个头,每个输入序列中的每个元素,都有一个长度为seq_len的权重向量,对应该元素与输入序列中的其他元素之间的关系强度。注意,在MultiHeadAttention 计算结束后,我们并不会像处理enc_ outputs 一样合并头的结果,所以attn_weights 的维度会保持为[batch_size,n_ heads, seq_len, seq_len]。
如图所示,这个编码器层类实现了 Transformer编码器中的一层计算,包括多头自注意力和逐位置前馈网络两个子层。在实际的Transformer 编码器中,通常会堆叠多个这样的层来构建一个深度模型,以捕捉更丰富的序列
编码器特征。
组件6_编码器
# 定义编码器类
n_layers = 6 # 设置 Encoder 的层数
class Encoder(nn.Module):def __init__(self, corpus):super(Encoder, self).__init__() self.src_emb = nn.Embedding(len(corpus.src_vocab), d_embedding) # 词嵌入层self.pos_emb = nn.Embedding.from_pretrained( \get_sin_enc_table(corpus.src_len+1, d_embedding), freeze=True) # 位置嵌入层self.layers = nn.ModuleList(EncoderLayer() for _ in range(n_layers))# 编码器层数def forward(self, enc_inputs): #------------------------- 维度信息 --------------------------------# enc_inputs 的维度是 [batch_size, source_len]#-----------------------------------------------------------------# 创建一个从 1 到 source_len 的位置索引序列pos_indices = torch.arange(1, enc_inputs.size(1) + 1).unsqueeze(0).to(enc_inputs)#------------------------- 维度信息 --------------------------------# pos_indices 的维度是 [1, source_len]#----------------------------------------------------------------- # 对输入进行词嵌入和位置嵌入相加 [batch_size, source_len,embedding_dim]enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(pos_indices)#------------------------- 维度信息 --------------------------------# enc_outputs 的维度是 [batch_size, seq_len, embedding_dim]#-----------------------------------------------------------------# 生成自注意力掩码enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) #------------------------- 维度信息 --------------------------------# enc_self_attn_mask 的维度是 [batch_size, len_q, len_k] #----------------------------------------------------------------- enc_self_attn_weights = [] # 初始化 enc_self_attn_weights# 通过编码器层 [batch_size, seq_len, embedding_dim]for layer in self.layers: enc_outputs, enc_self_attn_weight = layer(enc_outputs, enc_self_attn_mask)enc_self_attn_weights.append(enc_self_attn_weight)#------------------------- 维度信息 --------------------------------# enc_outputs 的维度是 [batch_size, seq_len, embedding_dim] 维度与 enc_inputs 相同# enc_self_attn_weights 是一个列表,每个元素的维度是 [batch_size, n_heads, seq_len, seq_len] #-----------------------------------------------------------------return enc_outputs, enc_self_attn_weights # 返回编码器输出和编码器注意力权重
编码器 Encoder类的__init__方法中初始化的内容如下。
- (1)词嵌入层nn.Embedding 实例src_emb。该层将输入序列中的单词转换为词嵌入向量。len(corpus.src_vocab)表示词汇表的大小,d_embedding 表示词嵌入向量的维度。输入的编码应该通过nn.Embedding进行词向量的表示学习,用以捕捉上下文关系。这个我们已经比较了解了,因此这个组件无须过多说明。
- (2)位置嵌入层实例pos_emb。使用nn.Embedding.from_pretrained()方法从预先计算的正弦位置编码表(由get_sinusoid_encoding_table()函数生成)创建位置嵌入层,并通过freeze=True 参数保持其权重不变。
- (3)编码器层数self.layers。使用nn.ModuleList()创建一个模块列表,包含n_ layers 个 EncoderLayer 实例。这些层将顺序堆叠在编码器中。
Encoder 类的 forward方法中接收一个参数enc_inputs,表示输入的序列,其形状为 [batch_size, source_len]。
forward 方法内部流程如下。
- (1)将enc_inputs 输入词嵌入层src_emb和位置嵌入层pos_emb中,然后将得到的词嵌入向量和位置嵌入向量相加,得到enc_outputs。
- (2)调用get_attn_pad_mask()函数,为输入序列生成自注意力掩码(如填充掩码),命名为 enc_self_attn_mask。在多头自注意力计算中,这个掩码可以让模型忽略填充部分。
- (3)定义一个空列表enc_self_attn_weights,用于收集每个编码器层的自注意力权重矩阵。
- (4)遍历编码器层数self.layers 中的每个EncoderLayer实例。将enc_ outputs 和 enc_self_attn_mask输入编码器层,更新enc_outputs 并将得到的自注意力权重矩阵 enc_self_attn_weight 添加到列表 enc_self_attn_weights 中。
- (5)最后返回 enc_outputs 和 enc_self_attn_weights.enc_outputs 表示编码器的输出,enc_self_attn_weights 表示每个编码器层的自注意力权重矩阵,可以用于分析和可视化。
这个编码器类实现了Transformer模型中的编码器部分,包括词嵌入、位置嵌入和多个编码器层。通过这个编码器,可以处理输入序列,并从中提取深层次的特征表示。这些特征表示可以直接应用于后续的任务,如序列到序列的生成任务(如机器翻译)或者分类任务(如情感分析)等。
组件7_后续掩码
后续注意力掩码引入解码器,而编码器中不需要。这和解码器训练过程中通常会使用到的教师强制有关。教师强制在训练过程中将真实的输出作为下一个时间步的输入。为了确保模型在预测当前位置时不会关注到未来的信息,我们就需要在解码器中应用后续注意力掩码。因为,在序列生成任务(如机器翻译或文本摘要等)中,模型需要逐个生成目标序列的元素,而不能提前获取未来的信息。
在自然语言处理中,尤其是Seq2Seq任务中,我们需要为解码器提供正确的输入,对于已经生成的部分,我们要让解码器看到序列是否正确,然后用正确的信息(Ground Truth)来预测下一个词。但是与此同时,为了确保模型不会提前获取未来的信息,我们又需要在注意力计算中遮住当前位置后面的信息(Subsequent Positions )。这真是既矛盾,又没有办法的事情。
所以,对序列中的第一个位置,我们需要遮住后面所有的词;而对后面的词,需要遮住的词会逐渐减少(如图所示)。比如把“咖哥喜欢小冰”这句话输入解码器当对“咖哥”计算注意力时,解码器不可以看到“喜欢”“小冰”这两个词。当对“喜欢”计算注意力时,解码器可以看到“咖哥”,不能看到“小冰”,因为它正是需要根据“咖哥”和“喜欢”这个上下文,来猜测咖哥喜欢谁。当对最后一个词"小冰"计算注意力的时候,前两个词就不是秘密了。
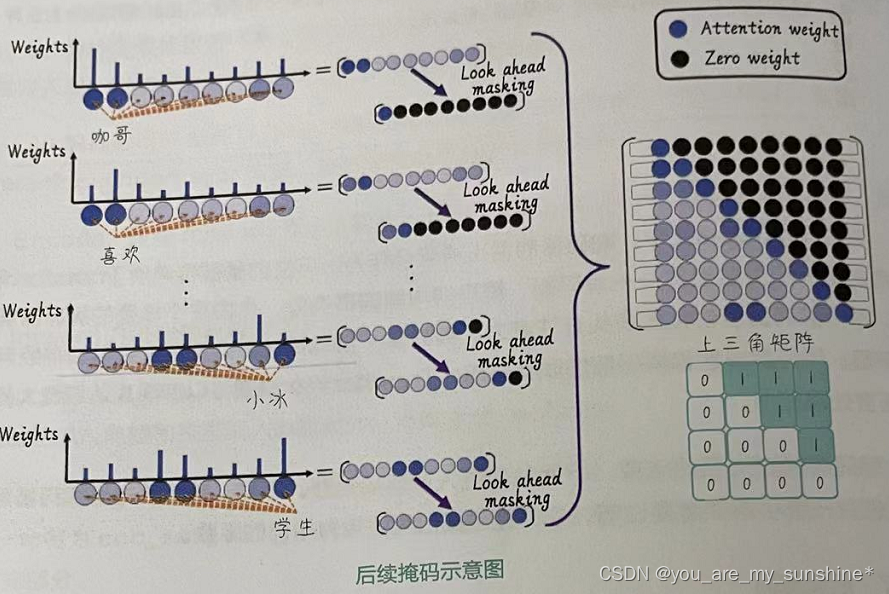
为了实现上面的目标,需要构建一个上三角矩阵,也就是一个注意力掩码矩阵。其中对角线及以下的元素为0,对角线以上的元素为1。在计算多头自注意力时,我们将该矩阵与后续注意力掩码相加,使得未来信息对应的权重变得非常小(接近负无穷)。然后,通过应用softmax函数,未来信息对应的权重将接近于0,从而实现忽略未来信息的目的。
下面定义一个后续注意力掩码函数get_attn_subsequent_mask,它只有一个参数,用于接收解码器的输入序列形状信息,以生成掩码矩阵。
# 生成后续注意力掩码的函数,用于在多头自注意力计算中忽略未来信息
def get_attn_subsequent_mask(seq):#------------------------- 维度信息 --------------------------------# seq 的维度是 [batch_size, seq_len(Q)=seq_len(K)]#-----------------------------------------------------------------# 获取输入序列的形状attn_shape = [seq.size(0), seq.size(1), seq.size(1)] #------------------------- 维度信息 --------------------------------# attn_shape 是一个一维张量 [batch_size, seq_len(Q), seq_len(K)]#-----------------------------------------------------------------# 使用 numpy 创建一个上三角矩阵(triu = triangle upper)subsequent_mask = np.triu(np.ones(attn_shape), k=1)#------------------------- 维度信息 --------------------------------# subsequent_mask 的维度是 [batch_size, seq_len(Q), seq_len(K)]#-----------------------------------------------------------------# 将 numpy 数组转换为 PyTorch 张量,并将数据类型设置为 byte(布尔值)subsequent_mask = torch.from_numpy(subsequent_mask).byte()#------------------------- 维度信息 --------------------------------# 返回的 subsequent_mask 的维度是 [batch_size, seq_len(Q), seq_len(K)]#-----------------------------------------------------------------return subsequent_mask # 返回后续位置的注意力掩码
代码中的 attn_shape是一个包含三个元素的列表,分别代表seq的批量大小、序列长度和序列长度。这个形状与多头自注意力中的注意力权重矩阵相匹配。
然后,使用np.triu()函数创建一个与注意力权重矩阵相同的上三角矩阵,也就是一个注意力掩码矩阵。将矩阵中的对角线及其下方元素设置为0,对角线上方元素设置为1。对于矩阵中的每个元素(i,j),如果i<= j,则填充 0;如果i>j,则填充 1。这样会使矩阵的下三角(包括对角线)填充为0,表示当前位置可以关注到之前的位置(包括自身),上三角填充为1,所以当前位置不能关注到之后的位置。
这样,注意力矩阵的每一行表示一个时间步,每个元素表示该时间步对其他时间步的注意力权重。对于序列中的每个位置,这个矩阵的每一行都表示该位置能关注到的其他位置。0表示当前位置可以关注到该位置,而1表示不能关注到该位置。
最后,将上三角矩阵转换为PyTorch 张量,并将数据类型转换为byte,得到 subsequent_mask张量,它表示后续注意力掩码。
这样,我们就创建了一个后续注意力掩码矩阵,其形状与注意力权重矩阵相同。掩码矩阵中,填充位对应的元素为1,非填充位对应的元素为0。这个后续注意力掩码矩阵,将只应用于解码器层的输入序列,也就是我们前文中多次解释的向右位移后的输出序列。
组件8_解码器层
# 定义解码器层类
class DecoderLayer(nn.Module):def __init__(self):super(DecoderLayer, self).__init__() self.dec_self_attn = MultiHeadAttention() # 多头自注意力层 self.dec_enc_attn = MultiHeadAttention() # 多头自注意力层,连接编码器和解码器 self.pos_ffn = PoswiseFeedForwardNet() # 位置前馈神经网络层def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):#------------------------- 维度信息 --------------------------------# dec_inputs 的维度是 [batch_size, target_len, embedding_dim]# enc_outputs 的维度是 [batch_size, source_len, embedding_dim]# dec_self_attn_mask 的维度是 [batch_size, target_len, target_len]# dec_enc_attn_mask 的维度是 [batch_size, target_len, source_len]#----------------------------------------------------------------- # 将相同的 Q,K,V 输入多头自注意力层dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)#------------------------- 维度信息 --------------------------------# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]# dec_self_attn 的维度是 [batch_size, n_heads, target_len, target_len]#----------------------------------------------------------------- # 将解码器输出和编码器输出输入多头自注意力层dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)#------------------------- 维度信息 --------------------------------# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]# dec_enc_attn 的维度是 [batch_size, n_heads, target_len, source_len]#----------------------------------------------------------------- # 输入位置前馈神经网络层dec_outputs = self.pos_ffn(dec_outputs)#------------------------- 维度信息 --------------------------------# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]# dec_self_attn 的维度是 [batch_size, n_heads, target_len, target_len]# dec_enc_attn 的维度是 [batch_size, n_heads, target_len, source_len] #-----------------------------------------------------------------# 返回解码器层输出,每层的自注意力和解 - 编码器注意力权重return dec_outputs, dec_self_attn, dec_enc_attn
在DecoderLayer类的__init__方法中:
- (1)定义了多头自注意力层实例dec_self_attn。这个层用于处理解码器的输入序列。
- (2)定义了另一个多头自注意力层实例dec_enc_attn。这个层用于建立解码器和编码器之间的联系,将编码器的输出信息融合到解码器的输出中。
- (3)定义了逐位置前馈网络层实例pos_ffn。这个层用于处理多头自注意力层的输出,进一步提取特征。
forward 方法接收4个参数:dec_inputs表示解码器的输入,enc_outputs表示编码器的输出,dec_self_attn_mask表示解码器自注意力掩码,dec_enc_attn_ mask 表示编码器-解码器注意力掩码。在forward方法内部:
-
(1)将dec_inputs 作为0、K、V输入多头自注意力层dec_self_attn 中,并传入 dec_self_attn_mask。得到输出dec_outputs和自注意力权重矩阵dec_self_attn。
-
(2)将dec_outputs 作为Q,enc_outputs 作为K、V输入多头自注意力层 dec_enc_attn 中,并传入dec_enc_attn_mask。得到更新后的输出dec_outputs和编码器-解码器注意力权重矩阵dec_enc_attn。
-
(3)将dec_outputs输入逐位置前馈网络层pos_ffn 中,得到最终的dec_outputs。
-
(4)返回 dec_outputs、dec_self_attn 和 dec_enc_attn.dec_outputs 表示解码器层的输出,dec_self_attn表示解码器自注意力权重矩阵,dec_enc_attn 表示编码器-解码器注意力权重矩阵。
这个解码器层类实现了Transformer模型中的解码器层部分,包括多头自注意力、编码器-解码器多头自注意力和逐位置前馈网络等子层。通过堆叠多个解码器层,模型可以生成目标序列,并利用编码器的输出信息进行更准确的预测。
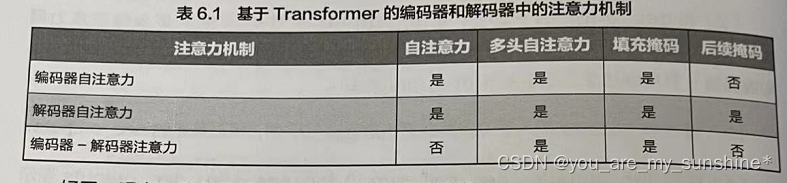
Transformer的解码器有两层注意力机制,包括一个自注意力机制和一个编码器一解码器注意力机制,它们都是多头的吗?它们是否都有填充掩码?它们是否都有后续掩码?
是的有多头。自注意力和编码器一解码器注意力机制都采用多头自注意力策略。多头自注意力能让模型在多个子空间中同时学习不同的表示,从而提高表现。
是的有填充掩码。填充掩码用于忽略输入序列中的填充部分,防止注意力机制关注这些无意义的区域。在自注意力和编码器-解码器注意力中都用到填充掩码。
不是都有后续掩码。后续掩码用于防止解码器关注输入序列中未来的信息,从而确保每个解码器层只能关注当前位置和之前的位置。在解码器的自注意力机制中,会使用后续掩码。然而,在编码器-解码器注意力中,通常不使用后续掩码,因为这个注意力机制是为了让解码器关注整个编码器的输出序列,而不需要限制注意力范围。
组件9_解码器
解释器类的实现代码如下:
# 定义解码器类
n_layers = 6 # 设置 Decoder 的层数
class Decoder(nn.Module):def __init__(self, corpus):super(Decoder, self).__init__()self.tgt_emb = nn.Embedding(len(corpus.tgt_vocab), d_embedding) # 词嵌入层self.pos_emb = nn.Embedding.from_pretrained( \get_sin_enc_table(corpus.tgt_len+1, d_embedding), freeze=True) # 位置嵌入层 self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) # 叠加多层def forward(self, dec_inputs, enc_inputs, enc_outputs): #------------------------- 维度信息 --------------------------------# dec_inputs 的维度是 [batch_size, target_len]# enc_inputs 的维度是 [batch_size, source_len]# enc_outputs 的维度是 [batch_size, source_len, embedding_dim]#----------------------------------------------------------------- # 创建一个从 1 到 source_len 的位置索引序列pos_indices = torch.arange(1, dec_inputs.size(1) + 1).unsqueeze(0).to(dec_inputs)#------------------------- 维度信息 --------------------------------# pos_indices 的维度是 [1, target_len]#----------------------------------------------------------------- # 对输入进行词嵌入和位置嵌入相加dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(pos_indices)#------------------------- 维度信息 --------------------------------# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]#----------------------------------------------------------------- # 生成解码器自注意力掩码和解码器 - 编码器注意力掩码dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) # 填充位掩码dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs) # 后续位掩码dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask \+ dec_self_attn_subsequent_mask), 0) dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # 解码器 - 编码器掩码#------------------------- 维度信息 -------------------------------- # dec_self_attn_pad_mask 的维度是 [batch_size, target_len, target_len]# dec_self_attn_subsequent_mask 的维度是 [batch_size, target_len, target_len]# dec_self_attn_mask 的维度是 [batch_size, target_len, target_len]# dec_enc_attn_mask 的维度是 [batch_size, target_len, source_len]#----------------------------------------------------------------- dec_self_attns, dec_enc_attns = [], [] # 初始化 dec_self_attns, dec_enc_attns# 通过解码器层 [batch_size, seq_len, embedding_dim]for layer in self.layers:dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)dec_self_attns.append(dec_self_attn)dec_enc_attns.append(dec_enc_attn)#------------------------- 维度信息 --------------------------------# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]# dec_self_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, target_len, target_len]# dec_enc_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, target_len, source_len]#----------------------------------------------------------------- # 返回解码器输出,解码器自注意力和解码器 - 编码器注意力权重 return dec_outputs, dec_self_attns, dec_enc_attns
Decoder类负责生成目标序列,在__init__方法中初始化的内容如下。
- 词嵌入层实例tgt_emb。这个层将目标序列中的单词转换为对应的向量表示。
- 位置嵌入层实例pos_emb。这个层通过预先计算的正弦位置编码表来引入位置信息。
- 一个nn.ModuleList实例,用于存储多个解码器层。这里使用列表解析式创建了n_layers 个解码器层。
Decoder类的forward方法中接收3个参数:dec_inputs 表示解码器的输入, enc_inputs 表示编码器的输入,enc_outputs 表示编码器的输出。
forward 方法内部流程如下。
- 对解码器输入进行词嵌入和位置嵌入相加,得到dec_outputs。
- 生成解码器自注意力掩码dec_self_attn_mask和解码器-编码器注意力掩码 dec_enc_attn_mask。
- 解码器自注意力掩码dec_self_attn_mask是后续注意力掩码dec_self_ attn_subsequent_mask与填充注意力掩码dec_self_attn_pad_mask的结合,通过将两个掩码矩阵相加并使用torch.gt函数生成一个布尔类型矩阵。 gt 表示“greater than”(大于),用于逐元素地比较两个张量,并返回一个与输入形状相同的布尔张量,看对应位置的输入元素是否大于给定的阈值0。这个布尔矩阵将用于遮挡填充位和未来信息。
- 解码器-编码器注意力掩码dec_enc_attn_mask则只包括填充注意力掩码 dec_self_attn_pad_mask,仅仅需要遮挡编码器传递进来的上下文向量中的填充位。
- 初始化两个空列表dec_self_attns 和dec_enc_attns,用于存储每个解码器层的自注意力权重矩阵和编码器-解码器注意力权重矩阵。
- 使用一个 for 循环遍历所有的解码器层,将dec_outputs、enc_outputs、 dec_self_attn_mask和dec_enc_attn_mask 输入解码器层中。得到更新后的 dec_outputs,以及当前解码器层的自注意力权重矩阵dec_self_attn和编码器-解码器注意力权重矩阵dec_enc_attn。将这两个权重矩阵分别添加到列表 dec_self_attns 和 dec_enc_attns 中。
- 返回dec_outputs、dec_self_attns和 dec_enc_attns.dec_outputs表示解码器的输出,dec_self_attns表示解码器各层的自注意力权重矩阵, dec_enc_attns表示解码器各层的编码器-解码器注意力权重矩阵。
这个解码器类实现了Transformer 模型中的解码器部分,包括词嵌入、位置嵌入和多个解码器层。通过堆叠多个解码器层,可以捕获目标序列中的复杂语义和结构信息。解码器的输出将被用来预测目标序列的下一个词。
组件10_Transformer类
在Transformer模型的训练和推理过程中,解码器与编码器一起工作。编码器负责处理源序列并提取其语义信息,解码器则根据编码器的输出和自身的输入(目标序列)生成新的目标序列。在这个过程中,解码器会利用自注意力机制关注目标序列的不同部分,同时通过编码器一解码器注意力机制关注编码器输出的不同部分。当解码器处理完所有的解码器层后,最终输出的dec_outputs 将被送入一个线性层和 softmax 层(softmax层已经整合在损失函数中,不需要具体实现,所以下面的代码我们只定义线性层),生成最终的预测结果。这个预测结果是一个概率分布,表示每个词在目标序列下一个位置的概率。
下面构建 Transformer 模型的类。
# 定义 Transformer 模型
class Transformer(nn.Module):def __init__(self, corpus):super(Transformer, self).__init__() self.encoder = Encoder(corpus) # 初始化编码器实例 self.decoder = Decoder(corpus) # 初始化解码器实例# 定义线性投影层,将解码器输出转换为目标词汇表大小的概率分布self.projection = nn.Linear(d_embedding, len(corpus.tgt_vocab), bias=False)def forward(self, enc_inputs, dec_inputs):#------------------------- 维度信息 --------------------------------# enc_inputs 的维度是 [batch_size, source_seq_len]# dec_inputs 的维度是 [batch_size, target_seq_len]#----------------------------------------------------------------- # 将输入传递给编码器,并获取编码器输出和自注意力权重 enc_outputs, enc_self_attns = self.encoder(enc_inputs)#------------------------- 维度信息 --------------------------------# enc_outputs 的维度是 [batch_size, source_len, embedding_dim]# enc_self_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, src_seq_len, src_seq_len] #----------------------------------------------------------------- # 将编码器输出、解码器输入和编码器输入传递给解码器# 获取解码器输出、解码器自注意力权重和编码器 - 解码器注意力权重 dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)#------------------------- 维度信息 --------------------------------# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]# dec_self_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, tgt_seq_len, src_seq_len]# dec_enc_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, tgt_seq_len, src_seq_len] #----------------------------------------------------------------- # 将解码器输出传递给投影层,生成目标词汇表大小的概率分布dec_logits = self.projection(dec_outputs) #------------------------- 维度信息 --------------------------------# dec_logits 的维度是 [batch_size, tgt_seq_len, tgt_vocab_size]#-----------------------------------------------------------------# 返回逻辑值 ( 原始预测结果 ), 编码器自注意力权重,解码器自注意力权重,解 - 编码器注意力权重return dec_logits, enc_self_attns, dec_self_attns, dec_enc_attns
完成翻译任务
仍然使用Seq2Seq的小型翻译任务数据集。不过,我们这次把数据集整合到一个TranslationCorpus类,这个类会读入语料,自动整理语料库的字典,
提供批量数据。
数据准备
sentences = [['哒哥 喜欢 爬山', 'DaGe likes climb'],['我 爱 学习 人工智能', 'I love studying AI'],['深度学习 改变 世界', ' DL changed the world'],['自然语言处理 很 强大', 'NLP is powerful'],['神经网络 非常 复杂', 'Neural-networks are complex'] ]
from collections import Counter # 导入 Counter 类
# 定义 TranslationCorpus 类
class TranslationCorpus:def __init__(self, sentences):self.sentences = sentences# 计算源语言和目标语言的最大句子长度,并分别加 1 和 2 以容纳填充符和特殊符号self.src_len = max(len(sentence[0].split()) for sentence in sentences) + 1self.tgt_len = max(len(sentence[1].split()) for sentence in sentences) + 2# 创建源语言和目标语言的词汇表self.src_vocab, self.tgt_vocab = self.create_vocabularies()# 创建索引到单词的映射self.src_idx2word = {v: k for k, v in self.src_vocab.items()}self.tgt_idx2word = {v: k for k, v in self.tgt_vocab.items()}# 定义创建词汇表的函数def create_vocabularies(self):# 统计源语言和目标语言的单词频率src_counter = Counter(word for sentence in self.sentences for word in sentence[0].split())tgt_counter = Counter(word for sentence in self.sentences for word in sentence[1].split()) # 创建源语言和目标语言的词汇表,并为每个单词分配一个唯一的索引src_vocab = {'<pad>': 0, **{word: i+1 for i, word in enumerate(src_counter)}}tgt_vocab = {'<pad>': 0, '<sos>': 1, '<eos>': 2, **{word: i+3 for i, word in enumerate(tgt_counter)}} return src_vocab, tgt_vocab# 定义创建批次数据的函数def make_batch(self, batch_size, test_batch=False):input_batch, output_batch, target_batch = [], [], []# 随机选择句子索引sentence_indices = torch.randperm(len(self.sentences))[:batch_size]for index in sentence_indices:src_sentence, tgt_sentence = self.sentences[index]# 将源语言和目标语言的句子转换为索引序列src_seq = [self.src_vocab[word] for word in src_sentence.split()]tgt_seq = [self.tgt_vocab['<sos>']] + [self.tgt_vocab[word] \for word in tgt_sentence.split()] + [self.tgt_vocab['<eos>']] # 对源语言和目标语言的序列进行填充src_seq += [self.src_vocab['<pad>']] * (self.src_len - len(src_seq))tgt_seq += [self.tgt_vocab['<pad>']] * (self.tgt_len - len(tgt_seq)) # 将处理好的序列添加到批次中input_batch.append(src_seq)output_batch.append([self.tgt_vocab['<sos>']] + ([self.tgt_vocab['<pad>']] * \(self.tgt_len - 2)) if test_batch else tgt_seq[:-1])target_batch.append(tgt_seq[1:]) # 将批次转换为 LongTensor 类型input_batch = torch.LongTensor(input_batch)output_batch = torch.LongTensor(output_batch)target_batch = torch.LongTensor(target_batch) return input_batch, output_batch, target_batch
# 创建语料库类实例
corpus = TranslationCorpus(sentences)
训练Transformer模型
import torch # 导入 torch
import torch.optim as optim # 导入优化器
model = Transformer(corpus) # 创建模型实例
criterion = nn.CrossEntropyLoss() # 损失函数
optimizer = optim.Adam(model.parameters(), lr=0.0001) # 优化器
epochs = 5 # 训练轮次
for epoch in range(epochs): # 训练 100 轮optimizer.zero_grad() # 梯度清零enc_inputs, dec_inputs, target_batch = corpus.make_batch(batch_size) # 创建训练数据 outputs, _, _, _ = model(enc_inputs, dec_inputs) # 获取模型输出 loss = criterion(outputs.view(-1, len(corpus.tgt_vocab)), target_batch.view(-1)) # 计算损失if (epoch + 1) % 1 == 0: # 打印损失print(f"Epoch: {epoch + 1:04d} cost = {loss:.6f}")loss.backward()# 反向传播 optimizer.step()# 更新参数

测试Transformer模型
# 创建一个大小为 1 的批次,目标语言序列 dec_inputs 在测试阶段,仅包含句子开始符号 <sos>
enc_inputs, dec_inputs, target_batch = corpus.make_batch(batch_size=1,test_batch=True)
print("编码器输入 :", enc_inputs) # 打印编码器输入
print("解码器输入 :", dec_inputs) # 打印解码器输入
print("目标数据 :", target_batch) # 打印目标数据
predict, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs) # 用模型进行翻译
predict = predict.view(-1, len(corpus.tgt_vocab)) # 将预测结果维度重塑
predict = predict.data.max(1, keepdim=True)[1] # 找到每个位置概率最大的词汇的索引
# 解码预测的输出,将所预测的目标句子中的索引转换为单词
translated_sentence = [corpus.tgt_idx2word[idx.item()] for idx in predict.squeeze()]
# 将输入的源语言句子中的索引转换为单词
input_sentence = ' '.join([corpus.src_idx2word[idx.item()] for idx in enc_inputs[0]])
print(input_sentence, '->', translated_sentence) # 打印原始句子和翻译后的句子

代码从corpus对象中创建一个大小为1的批次,用于测试。输入批次enc inputs 包含源语言序列,输出批次dec_inputs 包含目标语言序列(在测试阶段,仅包含句子开始符号《sos》,后面跟着填充令牌《pad》,这样就不会在测试时传给解码器真值信息),目标批次target_batch 包含目标语言的序列(去除句子开始符号《sos》,最后添加句子结束符号《eos》)。把enc_inputs 和dec_inputs 传入模型进行预测,然后将预测结果重塑为一个形状为(-1,len(corpus.tgt_vocab))的张量,使用max函数沿着维度1(词汇表维度)找到每个位置概率最大的单词的索引。最后将预测的索引转换为单词并打印出翻译后的句子。
这个 Transformer能训练,能用。不过,其输出结果并不理想,模型只成功翻译了一个单词“NLP”,之后就不断重复这个词。
这次训练效果不理想的真正原因和模型的简单或者复杂无关,主要是因为此处我们并没有利用解码器的自回归机制进行逐位置(即逐词、逐令牌、逐元素或逐时间步)的生成式输出。
在 Transformer的训练过程中,我们通过最大化预测正确词的概率来优化模型;而在推理过程中,我们可以将解码器的输出作为下一个时间步的输入,在每一个时间步都选择概率最大的词作为下一个词(如贪心搜索等),或者使用更复杂的搜索策略(如集束搜索等)。
小结
在Transformer架构出现之前,处理NLP任务的“霸榜”技术是RNN。虽然在某些方面具有优势,但它的局限性也不容忽视。在训练过程中,RNN(包括LSTM和 GRU)可能会遇到梯度消失和梯度爆炸的问题,这会导致网络在学习长距离依赖关系时变得困难。
自此,Transformer已经在各种NLP 任务上刷新了记录,例如机器翻译、情感分析、问答系统等。Transformer的成功主要归功于其利用了自注意力机制,这使得模型能够捕捉到输入序列中不同位置之间的依赖关系,提升了模型表达能力,同时保持了计算效率。
学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
动手学深度学习(pytorch)
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
慕课网
海贼宝藏
…
相关文章:
NLP_Transformer架构
文章目录 Transformer架构剖析编码器-解码器架构各种注意力的应用Transformer中的自注意力Transformer中的多头自注意力Transformer中的编码器-解码器注意力Transformer中的注意力掩码和因果注意力 编码器的输入和位置编码编码器的内部结构编码器的输出和编码器-解码器的连接解…...

CVE-2012-2311 漏洞复现
CVE-2012-2311 这个漏洞被爆出来以后,PHP官方对其进行了修补,发布了新版本5.4.2及5.3.12,但这个修复是不完全的,可以被绕过,进而衍生出CVE-2012-2311漏洞。 PHP的修复方法是对-进行了检查: if(query_str…...

多线程面试题汇总
多线程面试题汇总 一、多线程1、线程的生命周期2、线程的创建(函数创建)3、线程的创建(使用类)4、守护线程 二、全局解释器锁1、使用单线程实现累加到5000000002、使用多线程实现累加到5000000003、总结 三、线程安全1、多线程之数…...
CentOS7.9+Kubernetes1.29.2+Docker25.0.3高可用集群二进制部署
CentOS7.9Kubernetes1.29.2Docker25.0.3高可用集群二进制部署 Kubernetes高可用集群(Kubernetes1.29.2Docker25.0.3)二进制部署二进制软件部署flannel v0.22.3网络,使用的etcd是版本3,与之前使用版本2不同。查看官方文档进行了解…...

STM32——OLED菜单(二级菜单)
文章目录 一.补充二. 二级菜单代码 简介:首先在我的51 I2C里面有OLED详细讲解,本期代码从51OLED基础上移植过来的,可以先看完那篇文章,在看这个,然后按键我是用的定时器扫描不会堵塞程序,可以翻开我的文章有单独的定时…...

配置Vite+React+TS项目
初始化 执行npm create vite并填写项目名、用那个框架。。 配置 路径别名 在vite.config.ts里面配置: import { defineConfig } from vite import react from vitejs/plugin-react import path from pathexport default defineConfig({plugins: [react()],reso…...

2.13:C语言测试题
21.(b) 6 22.(b) cd 23.b) 5 4 1 3 2 栈:先进后出 24. b,c,d:10,12,120 25.2,5 26.越界访问,可能正常输出,可能段错误 27. 0,41 28. a)11 b) 320 29. aab; ba-b; aa-b; 30. p150x801005; p250x810…...

ubuntu22.04 有一台机器说有4T硬盘,但是df的时候看不到,怎么查找
在 Ubuntu 22.04 上,如果你有一块硬盘在使用df命令时未显示,这通常意味着硬盘尚未被挂载或者根本未被分区和格式化。以下是一些步骤来帮助你识别和准备新硬盘: 1. 检查硬盘是否被系统识别 首先,使用lsblk命令来检查系统是否识别…...

【机器学习】数据清洗之识别重复点
🎈个人主页:甜美的江 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步…...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之NavDestination组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之NavDestination组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、NavDestination组件 作为NavRouter组件的子组件,用于显示导…...

tokio tcp通信
引入crate tokio { version "1.35.1", features ["full"] } 服务端 use std::time::Duration; use tokio::{io::{AsyncBufReadExt, AsyncWriteExt},net::{tcp::{OwnedReadHalf, OwnedWriteHalf},TcpListener, TcpStream,},sync::mpsc, };#[tokio::ma…...
LCR 122. 路径加密【简单】
LCR 122. 路径加密 假定一段路径记作字符串 path,其中以 "." 作为分隔符。现需将路径加密,加密方法为将 path 中的分隔符替换为空格 " ",请返回加密后的字符串。 示例 1: 输入:path "a.ae…...

SpringUtils 工具类,方便在非spring管理环境中获取bean
应用场景: 1 可用在工具类中, 2 spring【Controller,service】环境中, 3 其中的一个方法getAopProxy可获得代理对象,需要将 EnableAspectJAutoProxy(exposeProxy true) 允许获取代理对象 import org.springframework.aop.framew…...

JavaWeb之请求
请求 客户端请求由ServletRequest类型的request对象表示,在HTTP请求场景下,容器提供的请求对象的具体类型为HttpServletRequest HTTP的请求消息分为三部分:请求行、请求头、请求正文。 请求行对应方法 // 获取请求行中的协议名和版本public S…...
VsCode中常用的正则表达式操作
在vscode中可以使用正则表达式来进行搜索内容,极大的方便了我们对大量数据中需要查看的信息进行筛选,使用正则搜索时点击 .* 此文章会持续补充常用的正则操作 1.光标选中搜索到的内容 将搜索的内容进行全选,举例:在如下文件中我需…...

ubuntu22.04@laptop OpenCV Get Started: 007_color_spaces
ubuntu22.04laptop OpenCV Get Started: 007_color_spaces 1. 源由2. 颜色空间2.1 RGB颜色空间2.2 LAB颜色空间2.3 YCrCb颜色空间2.4 HSV颜色空间 3 代码工程结构3.1 C应用Demo3.2 Python应用Demo 4. 重点分析4.1 interactive_color_detect4.2 interactive_color_segment4.3 da…...

mysql 查询性能优化关键点总结
MySQL查询性能优化是数据库管理的重要环节,良好的性能优化可以提高查询效率,降低系统负载。以下是一些关键点,用于优化MySQL查询性能: 1. 索引优化 索引是MySQL查询优化的重要手段,合理的索引可以大大…...

React - 分页插件默认是英文怎么办
英文组件的通用解决方案 这里以分页插件为例: 大家可以看到,最后的这个页面跳转提示文字为Go to,不是中文,而官网里面的案例则是: 解决方案: import { ConfigProvider } from antd; import zhCN from an…...

揭开Markdown的秘籍:引用|代码块|超链接
🌈个人主页:聆风吟 🔥系列专栏:Markdown指南、网络奇遇记 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 📋前言一. ⛳️Markdown 引用1.1 🔔引用1.2 🔔嵌套引用1.3 &…...

【C语言】Debian安装并编译内核源码
在Debian 10中安装并编译内核源码的过程如下: 1. 安装依赖包 首先需要确保有足够的权限来安装包。为了编译内核,需要有一些基础的工具和库。 sudo apt update sudo apt upgrade sudo apt install build-essential libncurses-dev bison flex libssl-d…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

大话软工笔记—需求分析概述
需求分析,就是要对需求调研收集到的资料信息逐个地进行拆分、研究,从大量的不确定“需求”中确定出哪些需求最终要转换为确定的“功能需求”。 需求分析的作用非常重要,后续设计的依据主要来自于需求分析的成果,包括: 项目的目的…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...