OpenAI 生成视频模型 Sora 论文翻译
系列文章目录
前言
视频生成模型作为世界模拟器
本技术报告的重点是 (1) 将所有类型的视觉数据转换为统一表示,以便对生成模型进行大规模训练的方法,以及 (2) 对索拉的能力和局限性的定性评估。 该报告不包括模型和实现细节。
许多先前的工作使用各种方法研究了视频数据的生成建模,包括循环网络,[1][2][3] 生成对抗网络,[4][5][6][7] 自回归变压器,[8][9] 和扩散模型。[10][11][12] 这些工作通常侧重于视觉数据的一个狭窄类别、较短的视频或固定尺寸的视频。Sora 是一种通用的视觉数据模型——它可以生成时长、纵横比和分辨率各异的视频和图像,最长达一分钟的高清视频。
将视觉数据转化为补丁
我们从通过在互联网规模的数据上训练获得泛用能力的大语言模型中汲取灵感。[ ^ 13][ ^ 14] 大型语言模型范式成功的一部分原因是,它使用了巧妙地统一了文本、代码、数学和各种自然语言等不同模态的标记。在这项工作中,我们将探讨视觉数据生成模型如何能够继承这些好处。虽然大型语言模型有文本标记,但索拉有视觉补丁。以前已经证明,补丁对于视觉数据模型是一种有效的表示方法。[ ^ 15][ ^ 16][ ^ 17][ ^ 18] 我们发现,补丁是训练用于不同类型视频和图像的生成模型的高度可扩展且有效的方法。
在高层次上,我们首先通过压缩视频到低维潜空间中[^19],然后分解表示为时空块来将视频转换为块。
视频压缩网络
我们训练了一个网络来降低视觉数据的维度。 [20X20] 这个网络接受原始视频作为输入,并输出一个压缩了时间和空间的潜在表示。 Soray 被训练在压缩潜在空间中生成视频。 我们还训练了一个相应的解码器模型,该模型将生成的潜在值映射回像素空间。
时空潜伏图块
给定一个压缩输入视频,我们提取一系列时空图块作为变压器标记。由于图像只是单帧视频,所以此方案也适用于图像。我们的基于图块的表示使索拉能够针对具有不同分辨率、持续时间和宽高比的视频和图像进行训练。在推理时,我们可以根据大小适当的网格来排列随机初始化的图块以控制生成视频的尺寸。
视频生成中的可扩展转换器
Sora 是一个扩散模型;给定输入噪声块(以及诸如文本提示之类的条件信息),它被训练为预测原始“干净”的块。重要的是,Sora 是一个扩散变压器。变压器在各种领域展示了显著的扩展性,包括语言建模、计算机视觉和图像生成。
在这项工作中,我们发现扩散转换器在 视频模型中也有效地进行缩放。 下面,我们将固定种子和输入的视频样本与训练进度进行比较。 随着计算量的增加,样本质量明显提高。
可变时长、分辨率、宽高比
过去的方法通常是将图像和视频调整大小、裁剪或修剪为标准尺寸——例如,分辨率设置为 256x256 的 4 秒长的视频。我们发现训练原始尺寸的数据有几个好处。
抽样灵活性
Sora 可以对宽屏 1920x1080p 视频、纵向 1080x1920 视频以及介于两者之间的任何视频进行取样。 这使得 Sora 能够在不同设备上直接生成原生宽高比的内容。 它还让我们能够在全分辨率渲染之前,使用相同的模型快速原型化低分辨率的内容。
改进了框架和构图
我们发现,在原始宽高比下训练视频可以提高构图和框架。 我们将索拉模型与一个版本进行比较,该版本会将所有用于训练的视频裁剪为正方形,这是在训练生成模型时常见的做法。 在正方形裁剪(左)上训练的模型有时会生成只有部分主体可见的视频。相比之下,来自索拉的视频(右)具有更好的框架。
语言理解
训练文本到视频生成系统需要大量带有相应文本字幕的视频。我们在视频上应用了 DALL-E 3 中介绍的重新打标签技术。我们首先训练了一个高度描述性的标题模型,然后使用它为训练集中的所有视频生成文本标题。我们发现,在高度描述性的视频标题上进行训练可以提高文本保真度以及视频的整体质量。
与 DALL-E 3 类似,我们还使用 GPT 将短用户提示转换为更长、更详细的字幕,然后发送给视频模型。 这使得索拉能够生成高质量的视频,准确地遵循用户的提示。
在愉快地散步中度过时光
用图片和视频提示
上面所有结果和我们的登录页面都展示了 文本到视频 的示例。 但是,Sora 还可以接受其他输入,比如现有图像或视频。 这种能力使 Sora 能够执行各种图像和视频编辑任务——制作循环视频、让静态图片动起来、延长视频时间等。
动画DALL-E图像
Sora 可以通过输入图像和提示来生成视频。下面我们将展示基于 DALL-E 2 [^31] 和 DALL-E 3 [^30] 图像生成的示例视频。
一只戴着贝雷帽和黑色高领毛衣的柴犬。
怪物插图。 以扁平设计风格描绘了多种多样的怪物家庭。 这个群体包括一只毛茸茸的棕色怪兽、一只光滑的黑色怪兽,带有天线、一只长满斑点的绿色怪兽和一只微小的斑点怪兽,它们都生活在充满趣味性的环境中。
一张写有“SORA”的现实风格云彩的照片。
在一个华丽的历史大厅里,一股巨大的海浪峰峦叠嶂地冲向岸边。两位冲浪者抓住时机,在巨浪上熟练地驾驭着。
生成视频的延长
Sora 还可以向前或向后扩展视频。以下是四个从生成的视频片段开始,时间都向后推移的视频。因此,这四段视频中的每一部都有不同的开头,但最终都会走向相同的结局。
我们可以用这种方法在前、后两个方向上扩展视频,以产生一个无缝的无限循环。
视频到视频编辑
扩散模型使我们能够使用文本提示编辑图像和视频的方法变得丰富。在下面,我们将其中一种方法应用于 Soras ,即 SDEdit [ ^ 32 ] 。 这种技术使 Soras 能够零样本转换输入视频的风格和环境。
连接视频
我们还可以使用索拉 在两个输入视频之间进行渐进插值,创建完全不同的主题和场景构成之间的视频无缝过渡。在下面的例子中,居中的视频 插值于左侧和右侧的对应视频。
图像生成能力
Sora 还可以生成图像。我们通过在时域上具有一个帧长的空间网格中排列高斯噪声来实现这一点。该模型可以生成不同分辨率大小的图像——高达 2048x2048 分辨率。
特写镜头中一位女性在秋天,极端细节,浅景深
充满生机的珊瑚礁,五彩斑斓的鱼儿和海洋生物
以苹果树下的年轻老虎为主题的数字艺术,采用油画风格呈现,并包含华丽的细节。
一个有舒适小屋和北极光展示的雪景村庄,高清细节,逼真的DSLR相机,50毫米f / 1.2。
新兴模拟能力
我们发现,当 视频模型 在大范围内进行训练时,它们会表现出许多有趣的涌现性能力。 这些能力使索拉能够模拟物理世界中的人、动物和环境的一些方面。这些属性没有明确的 三维、物体 等归纳偏见——它们纯粹是规模现象。
三维一致。索拉可以生成具有动态相机运动的视频。随着相机的移动和旋转,人物和场景元素在三维空间中保持一致地移动。
长程连贯性和物体永存性。 生成视频系统面临的一个重大挑战是在采样长视频时保持时间一致性。 我们发现,Sora 往往能够有效地捕获短期和长期依赖关系——尽管并非总是如此。 例如,即使人物、动物或物体被遮挡或离开画面,我们的模型也能持久地跟踪它们。 同样,它可以在单个样本中为同一角色生成多个镜头,并在视频中保持其外观。
与世界互动。索拉有时可以简单地模拟影响世界状态的动作。例如,画家可以在画布上留下新的笔触,这些笔触会随着时间的推移而保留下来,或者一个人可以吃汉堡并留下咬痕。
模拟数字世界。索拉还可以模拟人工过程——例如,电子游戏。索拉可以同时根据基本策略控制我的世界中的玩家,同时以高保真度渲染世界及其动态。这些能力可以通过提示索拉“我的世界”标题来零样本诱导。
这些能力表明,视频模型的持续扩展是开发高度模拟物理世界、数字世界及其内部生物体、动物和人类等对象的有希望的方法。
讨论
Sora 目前作为模拟器存在许多局限性。例如,它无法准确模拟许多基本交互的物理,比如玻璃破碎。其他交互,如吃食物,并不总是导致正确的对象状态更改。我们在主页上列举了模型的其他常见故障模式——例如长时间样本中出现的不连贯或物体自发出现——在我们的着陆页中。
我们相信索拉今天所展示的能力,证明了对视频模型的持续扩展是走向能够模拟物理世界和数字世界的潜在途径。以及生活在其中的物体、动物和人类。
参考文献
-
Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhudinov. "Unsupervised learning of video representations using lstms." International conference on machine learning. PMLR, 2015.↩︎
-
Chiappa, Silvia, et al. "Recurrent environment simulators." arXiv preprint arXiv:1704.02254 (2017).↩︎
-
Ha, David, and Jürgen Schmidhuber. "World models." arXiv preprint arXiv:1803.10122 (2018).↩︎
-
Vondrick, Carl, Hamed Pirsiavash, and Antonio Torralba. "Generating videos with scene dynamics." Advances in neural information processing systems 29 (2016).↩︎
-
Tulyakov, Sergey, et al. "Mocogan: Decomposing motion and content for video generation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.↩︎
-
Clark, Aidan, Jeff Donahue, and Karen Simonyan. "Adversarial video generation on complex datasets." arXiv preprint arXiv:1907.06571 (2019).↩︎
-
Brooks, Tim, et al. "Generating long videos of dynamic scenes." Advances in Neural Information Processing Systems 35 (2022): 31769-31781.↩︎
-
Yan, Wilson, et al. "Videogpt: Video generation using vq-vae and transformers." arXiv preprint arXiv:2104.10157 (2021).↩︎
-
Wu, Chenfei, et al. "Nüwa: Visual synthesis pre-training for neural visual world creation." European conference on computer vision. Cham: Springer Nature Switzerland, 2022.↩︎
-
Ho, Jonathan, et al. "Imagen video: High definition video generation with diffusion models." arXiv preprint arXiv:2210.02303 (2022).↩︎
-
Blattmann, Andreas, et al. "Align your latents: High-resolution video synthesis with latent diffusion models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.↩︎
-
Gupta, Agrim, et al. "Photorealistic video generation with diffusion models." arXiv preprint arXiv:2312.06662 (2023).↩︎
-
Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).↩︎↩︎
-
Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.↩︎↩︎
-
Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).↩︎↩︎
-
Arnab, Anurag, et al. "Vivit: A video vision transformer." Proceedings of the IEEE/CVF international conference on computer vision. 2021.↩︎↩︎
-
He, Kaiming, et al. "Masked autoencoders are scalable vision learners." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.↩︎↩︎
-
Dehghani, Mostafa, et al. "Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution." arXiv preprint arXiv:2307.06304 (2023).↩︎↩︎
-
Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.↩︎
-
Kingma, Diederik P., and Max Welling. "Auto-encoding variational bayes." arXiv preprint arXiv:1312.6114 (2013).↩︎
-
Sohl-Dickstein, Jascha, et al. "Deep unsupervised learning using nonequilibrium thermodynamics." International conference on machine learning. PMLR, 2015.↩︎
-
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in neural information processing systems 33 (2020): 6840-6851.↩︎
-
Nichol, Alexander Quinn, and Prafulla Dhariwal. "Improved denoising diffusion probabilistic models." International Conference on Machine Learning. PMLR, 2021.↩︎
-
Dhariwal, Prafulla, and Alexander Quinn Nichol. "Diffusion Models Beat GANs on Image Synthesis." Advances in Neural Information Processing Systems. 2021.↩︎
-
Karras, Tero, et al. "Elucidating the design space of diffusion-based generative models." Advances in Neural Information Processing Systems 35 (2022): 26565-26577.↩︎
-
Peebles, William, and Saining Xie. "Scalable diffusion models with transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.↩︎
-
Chen, Mark, et al. "Generative pretraining from pixels." International conference on machine learning. PMLR, 2020.↩︎
-
Ramesh, Aditya, et al. "Zero-shot text-to-image generation." International Conference on Machine Learning. PMLR, 2021.↩︎
-
Yu, Jiahui, et al. "Scaling autoregressive models for content-rich text-to-image generation." arXiv preprint arXiv:2206.10789 2.3 (2022): 5.↩︎
-
Betker, James, et al. "Improving image generation with better captions." Computer Science. https://cdn.openai.com/papers/dall-e-3. pdf 2.3 (2023): 8↩︎↩︎
-
Ramesh, Aditya, et al. "Hierarchical text-conditional image generation with clip latents." arXiv preprint arXiv:2204.06125 1.2 (2022): 3.↩︎
-
Meng, Chenlin, et al. "Sdedit: Guided image synthesis and editing with stochastic differential equations." arXiv preprint arXiv:2108.01073 (2021).↩︎
相关文章:

OpenAI 生成视频模型 Sora 论文翻译
系列文章目录 前言 视频生成模型作为世界模拟器 本技术报告的重点是 (1) 将所有类型的视觉数据转换为统一表示,以便对生成模型进行大规模训练的方法,以及 (2) 对索拉的能力和局限性的定性评估。 该报告不包括模型和实现细节。 许多先前的工作使用各种方…...

2.13日学习打卡----初学RocketMQ(四)
2.13日学习打卡 目录: 2.13日学习打卡一.RocketMQ之Java ClassDefaultMQProducer类DefaultMQPushConsumer类Message类MessageExt类 二.RocketMQ 消费幂消费过程幂等消费速度慢的处理方式 三.RocketMQ 集群服务集群特点单master模式多master模式多master多Slave模式-…...
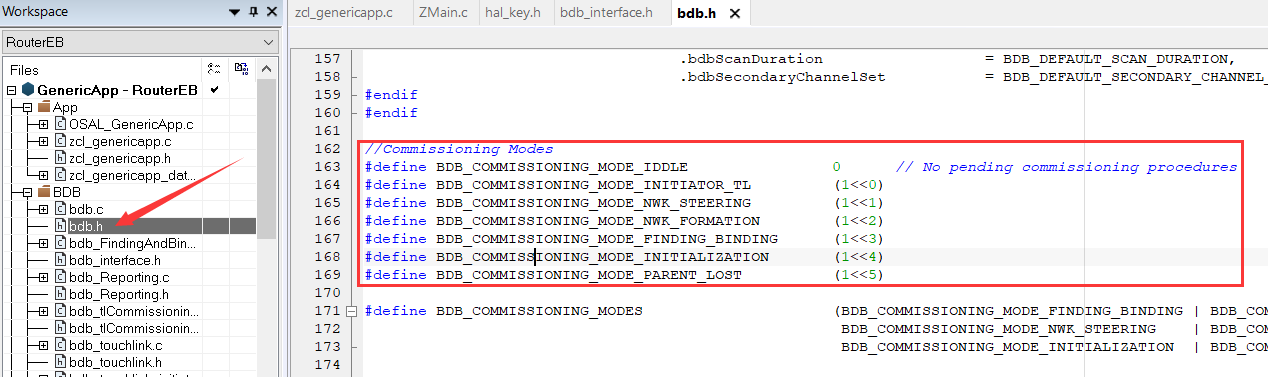
ZigBee学习——BDB
✨本博客参考了善学坊的教程,并总结了在实现过程中遇到的问题。 善学坊官网 文章目录 一、BDB简介二、BDB Commissioning Modes2.1 Network Steering2.2 Network Formation2.3 Finding and Binding(F & B)2.4 Touchlink 三、BDB Commissi…...
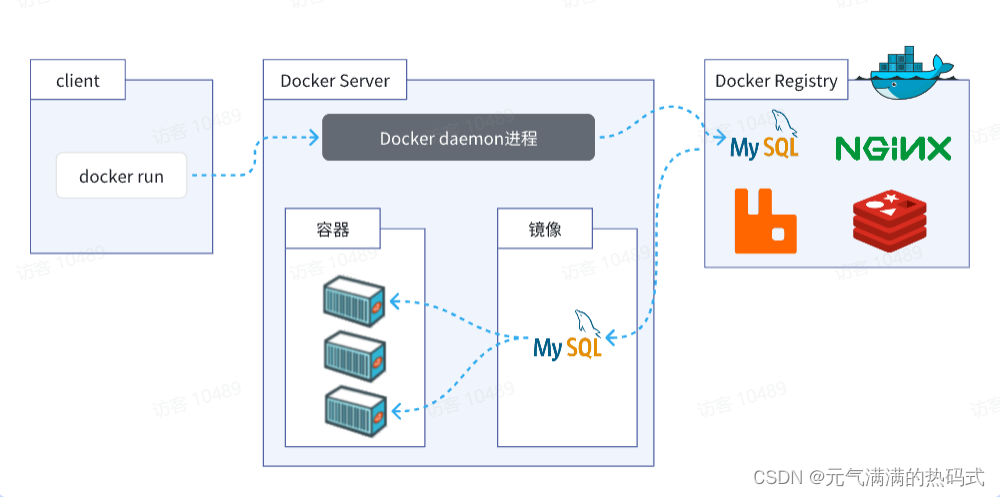
使用Docker快速部署MySQL
部署MySQL 使用Docker安装,仅仅需要一步即可,在命令行输入下面的命令 docker run -d \--name mysql \-p 3306:3306 \-e TZAsia/Shanghai \-e MYSQL_ROOT_PASSWORD123456 \mysql MySQL安装完毕!通过任意客户端工具即可连接到MySQL. 当我们执…...

力扣热题100_滑动窗口_3_无重复字符的最长子串
文章目录 题目链接解题思路解题代码 题目链接 3. 无重复字符的最长子串 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: s “abcabcbb” 输出: 3 解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。 示…...
RM电控工程讲义
HAL_CAN_RxFifo0MsgPendingCallback(CAN_HandleTypeDef *hcan) 是一个回调函数,通常在STM32的HAL库中用于处理CAN(Controller Area Network)接收FIFO 0中的消息。当CAN接口在FIFO 0中有待处理的消息时,这个函数会被调用。 HAL库C…...
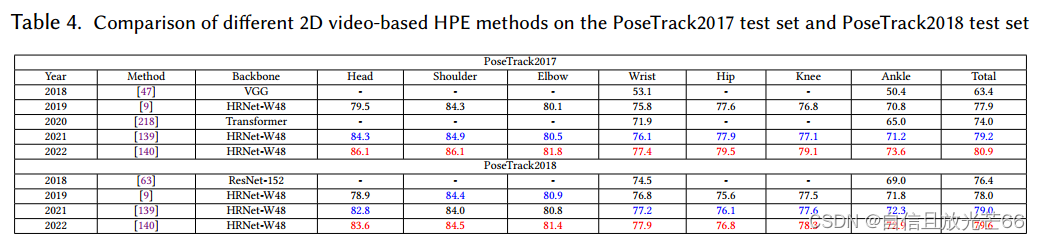
论文阅读:《Deep Learning-Based Human Pose Estimation: A Survey》——Part 1:2D HPE
目录 人体姿态识别概述 论文框架 HPE分类 人体建模模型 二维单人姿态估计 回归方法 目前发展 优化 基于热图的方法 基于CNN的几个网络 利用身体结构信息提供构建HPE网络 视频序列中的人体姿态估计 2D多人姿态识别 方法 自上而下 自下而上 2D HPE 总结 数据集…...

C语言——oj刷题——杨氏矩阵
目录 1. 理解杨氏矩形的特点 2. 实现杨氏矩形查找算法 3. 编写示例代码 当我们谈到杨氏矩形时,我们指的是一种在二维数组中查找目标元素的高效算法。它是由杨氏(Yan Shi)教授提出的,因此得名为杨氏矩形。 杨氏矩形问题的场景是…...

C++ 50道面试题
1. static关键字 1.全局static变量 存储位置:静态存储区,在程序运行期间一直存在 初始化: 未手动初始化的变量自动初始化为0 作用域: 从定义之处开始,到文件结束,仅能在本文件中使用 2.局部static变量…...

寒假学习记录14:JS字符串
目录 查找字符串中的特定元素 String.indexOf() (返回索引值) 截取字符串的一部分 .substring() (不影响原数组)(不允许负值) 截取字符串的一部分 .slice() (不影响原数…...

【数学建模】【2024年】【第40届】【MCM/ICM】【C题 网球运动中的“动量”】【解题思路】
一、题目 (一) 赛题原文 2024 MCM Problem C: Momentum in Tennis In the 2023 Wimbledon Gentlemen’s final, 20-year-old Spanish rising star Carlos Alcaraz defeated 36-year-old Novak Djokovic. The loss was Djokovic’s first at Wimbledon…...
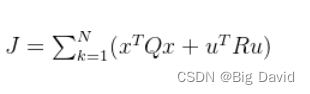
无人驾驶LQR控制算法 c++ 实现
参考博客: (1)LQR的理解与运用 第一期——理解篇 (2)线性二次型调节器(LQR)原理详解 (3)LQR控制基本原理(包括Riccati方程具体推导过程) (4)【基础…...
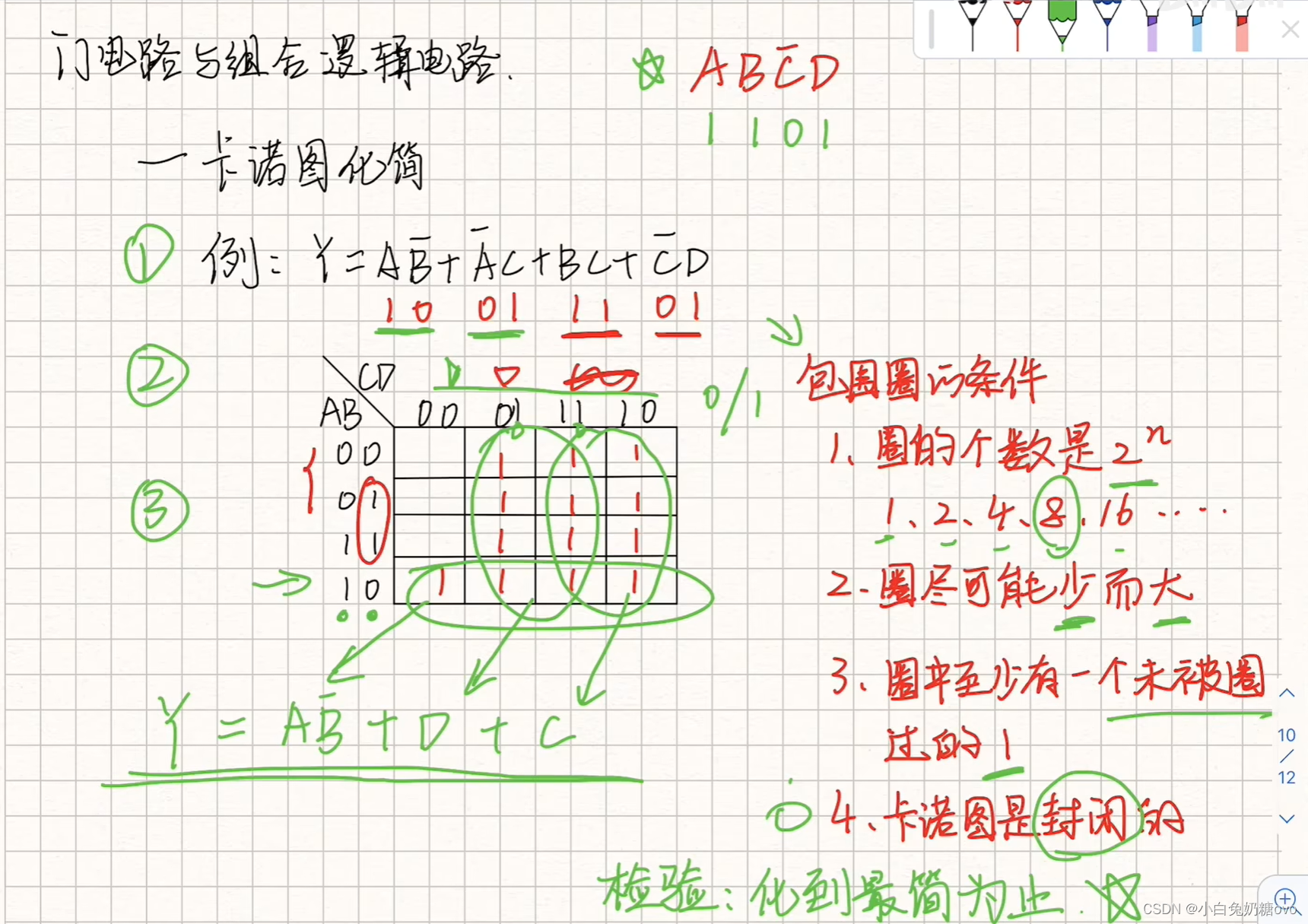
Karnaugh map (卡诺图)
【Leetcode】 289. Game of Life According to Wikipedia’s article: “The Game of Life, also known simply as Life, is a cellular automaton devised by the British mathematician John Horton Conway in 1970.” The board is made up of an m x n grid of cells, wh…...

C# CAD 框选pdf输出
在C#中进行AutoCAD二次开发时,实现框选(窗口选择)实体并输出这些实体到PDF文件通常涉及以下步骤: public ObjectIdCollection GetSelectedEntities() {using (var acTrans HostApplicationServices.WorkingDatabase.Transaction…...

【Linux】 Linux 小项目—— 进度条
进度条 基础知识1 \r && \n2 行缓冲区3 函数介绍 进度条实现版本 1代码实现运行效果 版本2 Thanks♪(・ω・)ノ谢谢阅读!!!下一篇文章见!!! 基础知识 1 \r &&a…...
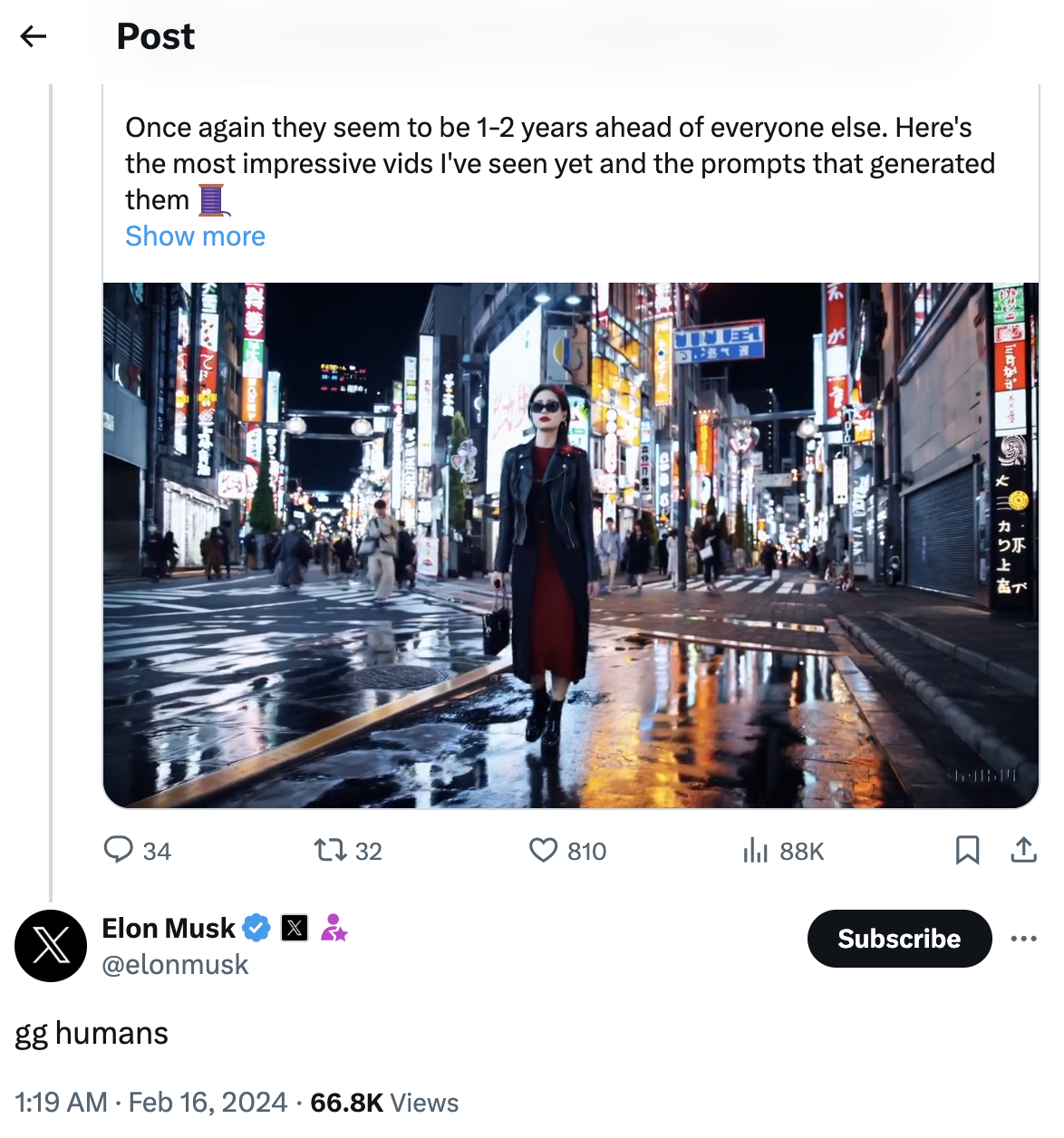
Sora和Pika,RunwayMl,Stable Video对比!网友:Sora真王者,其他都是弟
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识…...

Go内存优化与垃圾收集
Go提供了自动化的内存管理机制,但在某些情况下需要更精细的微调从而避免发生OOM错误。本文介绍了如何通过微调GOGC和GOMEMLIMIT在性能和内存效率之间取得平衡,并尽量避免OOM的产生。原文: Memory Optimization and Garbage Collector Management in Go 本…...

【Spring】Bean 的生命周期
一、Bean 的生命周期 Spring 其实就是一个管理 Bean 对象的工厂,它负责对象的创建,对象的销毁等 所谓的生命周期就是:对象从创建开始到最终销毁的整个过程 什么时候创建 Bean 对象?创建 Bean 对象的前后会调用什么方法…...
云计算基础-存储基础
存储概念 什么是存储: 存储就是根据不同的应用程序环境,通过采取合理、安全、有效的方式将数据保存到某些介质上,并能保证有效的访问,存储的本质是记录信息的载体。 存储的特性: 数据临时或长期驻留的物理介质需要保…...
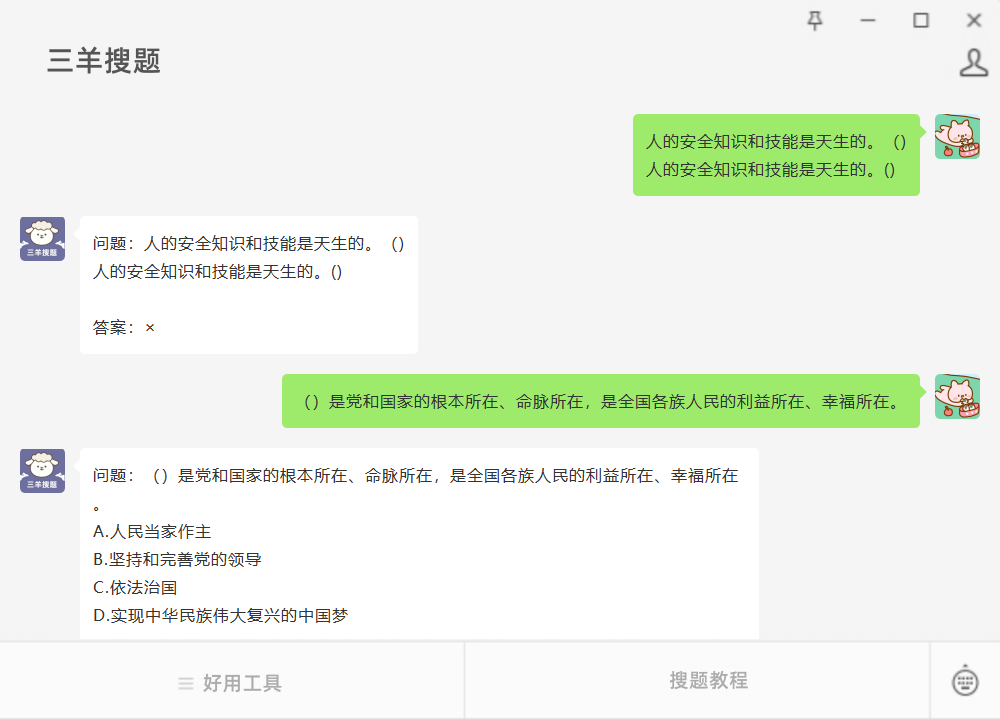
问题:人的安全知识和技能是天生的。() #媒体#知识分享#学习方法
问题:人的安全知识和技能是天生的。() 人的安全知识和技能是天生的。() 参考答案如图所示 问题:()是党和国家的根本所在、命脉所在,是全国各族人民的利益所在、幸福所在。 A.人民当家作主 B.坚持和完善…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

【C++进阶篇】智能指针
C内存管理终极指南:智能指针从入门到源码剖析 一. 智能指针1.1 auto_ptr1.2 unique_ptr1.3 shared_ptr1.4 make_shared 二. 原理三. shared_ptr循环引用问题三. 线程安全问题四. 内存泄漏4.1 什么是内存泄漏4.2 危害4.3 避免内存泄漏 五. 最后 一. 智能指针 智能指…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...

WEB3全栈开发——面试专业技能点P7前端与链上集成
一、Next.js技术栈 ✅ 概念介绍 Next.js 是一个基于 React 的 服务端渲染(SSR)与静态网站生成(SSG) 框架,由 Vercel 开发。它简化了构建生产级 React 应用的过程,并内置了很多特性: ✅ 文件系…...

Vue3中的computer和watch
computed的写法 在页面中 <div>{{ calcNumber }}</div>script中 写法1 常用 import { computed, ref } from vue; let price ref(100);const priceAdd () > { //函数方法 price 1price.value ; }//计算属性 let calcNumber computed(() > {return ${p…...

写一个shell脚本,把局域网内,把能ping通的IP和不能ping通的IP分类,并保存到两个文本文件里
写一个shell脚本,把局域网内,把能ping通的IP和不能ping通的IP分类,并保存到两个文本文件里 脚本1 #!/bin/bash #定义变量 ip10.1.1 #循环去ping主机的IP for ((i1;i<10;i)) doping -c1 $ip.$i &>/dev/null[ $? -eq 0 ] &&am…...
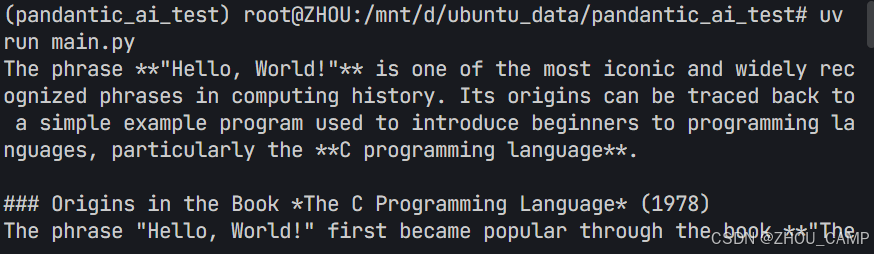
PydanticAI快速入门示例
参考链接:https://ai.pydantic.dev/#why-use-pydanticai 示例代码 from pydantic_ai import Agent from pydantic_ai.models.openai import OpenAIModel from pydantic_ai.providers.openai import OpenAIProvider# 配置使用阿里云通义千问模型 model OpenAIMode…...