《动手学深度学习(PyTorch版)》笔记8.5
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过,同时对于书上部分章节也做了整合。
Chapter8 Recurrent Neural Networks
8.5 Implementation of RNN from Scratch
8.5.1 Model Defining
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
import matplotlib.pyplot as pltbatch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)#每个词元都表示为一个数字索引,但将这些索引直接输入神经网络可能会使学习变得困难。
#最简单的表示称为独热编码(one-hot encoding),即将每个索引映射为相互不同的单位向量:
#假设词表中不同词元的数目为N(即len(vocab)),词元索引的范围为0到N-1。
#如果词元的索引是整数i,那么我们将创建一个长度为N的全0向量,并将第i处的元素设置为1。
F.one_hot(torch.tensor([0, 2]), len(vocab))#索引为0和2的独热向量X = torch.arange(10).reshape((2, 5))
print(F.one_hot(X.T, 28).shape)#形状为(时间步数,批量大小,词表大小)def get_params(vocab_size, num_hiddens, device):num_inputs = num_outputs = vocab_sizedef normal(shape):return torch.randn(size=shape, device=device) * 0.01# 隐藏层参数W_xh = normal((num_inputs, num_hiddens))W_hh = normal((num_hiddens, num_hiddens))b_h = torch.zeros(num_hiddens, device=device)# 输出层参数W_hq = normal((num_hiddens, num_outputs))b_q = torch.zeros(num_outputs, device=device)# 附加梯度params = [W_xh, W_hh, b_h, W_hq, b_q]for param in params:param.requires_grad_(True)return paramsdef init_rnn_state(batch_size, num_hiddens, device):return (torch.zeros((batch_size, num_hiddens), device=device), )def rnn(inputs, state, params):# inputs的形状:(时间步数量,批量大小,词表大小)W_xh, W_hh, b_h, W_hq, b_q = paramsH, = stateoutputs = []# X的形状:(批量大小,词表大小)for X in inputs:H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)Y = torch.mm(H, W_hq) + b_qoutputs.append(Y)return torch.cat(outputs, dim=0), (H,)class RNNModelScratch: #@save"""从零开始实现的循环神经网络模型"""def __init__(self, vocab_size, num_hiddens, device,get_params, init_state, forward_fn):self.vocab_size, self.num_hiddens = vocab_size, num_hiddensself.params = get_params(vocab_size, num_hiddens, device)self.init_state, self.forward_fn = init_state, forward_fndef __call__(self, X, state):X = F.one_hot(X.T, self.vocab_size).type(torch.float32)return self.forward_fn(X, state, self.params)def begin_state(self, batch_size, device):return self.init_state(batch_size, self.num_hiddens, device)num_hiddens = 512
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
state = net.begin_state(X.shape[0], d2l.try_gpu())
Y, new_state = net(X.to(d2l.try_gpu()), state)
print(Y.shape, len(new_state), new_state[0].shape)#隐状态形状不变,仍为(批量大小,隐藏单元数)def predict_ch8(prefix, num_preds, net, vocab, device): #@save"""在prefix后面生成新字符"""state = net.begin_state(batch_size=1, device=device)outputs = [vocab[prefix[0]]]get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))#get_input()将outputs列表中的最后一个字符的整数标识输入网络for y in prefix[1:]: # 预热期_, state = net(get_input(), state)outputs.append(vocab[y])for _ in range(num_preds): # 预测num_preds步y, state = net(get_input(), state)outputs.append(int(y.argmax(dim=1).reshape(1)))return ''.join([vocab.idx_to_token[i] for i in outputs])predict_ch8('time traveller ', 10, net, vocab, d2l.try_gpu())#由于还没有训练网络,会生成荒谬的预测结果
8.5.2 Gradient Clipping
对于长度为 T T T的序列,在迭代中计算这 T T T个时间步上的梯度,将会在反向传播过程中产生长度为 O ( T ) \mathcal{O}(T) O(T)的矩阵乘法链。当 T T T较大时,它可能导致数值不稳定,例如可能导致梯度爆炸或梯度消失。假定在向量形式的 x \mathbf{x} x中,或者在小批量数据的负梯度 g \mathbf{g} g方向上,使用 η > 0 \eta > 0 η>0作为学习率时,在一次迭代中,我们将 x \mathbf{x} x更新为 x − η g \mathbf{x} - \eta \mathbf{g} x−ηg。如果我们进一步假设目标函数 f f f表现良好,即函数 f f f在常数 L L L下利普希茨连续(Lipschitz continuous),也就是说,对于任意 x \mathbf{x} x和 y \mathbf{y} y我们有:
∣ f ( x ) − f ( y ) ∣ ≤ L ∥ x − y ∥ . |f(\mathbf{x}) - f(\mathbf{y})| \leq L \|\mathbf{x} - \mathbf{y}\|. ∣f(x)−f(y)∣≤L∥x−y∥.
在这种情况下,我们可以安全地假设:如果我们通过 η g \eta \mathbf{g} ηg更新参数向量,则
∣ f ( x ) − f ( x − η g ) ∣ ≤ L η ∥ g ∥ , |f(\mathbf{x}) - f(\mathbf{x} - \eta\mathbf{g})| \leq L \eta\|\mathbf{g}\|, ∣f(x)−f(x−ηg)∣≤Lη∥g∥,
这意味着变化不会超过 L η ∥ g ∥ L \eta \|\mathbf{g}\| Lη∥g∥的,坏的方面是限制了取得进展的速度;好的方面是限制了事情变糟的程度。有时梯度可能很大,使得优化算法可能无法收敛,我们可以通过降低 η \eta η的学习率来解决这个问题。但是如果很少得到大的梯度,一个替代方案是通过将梯度 g \mathbf{g} g投影回给定半径(例如 θ \theta θ)的球来截断梯度 g \mathbf{g} g,如下式:
g ← min ( 1 , θ ∥ g ∥ ) g . \mathbf{g} \leftarrow \min\left(1, \frac{\theta}{\|\mathbf{g}\|}\right) \mathbf{g}. g←min(1,∥g∥θ)g.
上式使得梯度范数永远不会超过 θ \theta θ,并且更新后的梯度完全与 g \mathbf{g} g的原始方向对齐。它还有一个作用,即限制任何给定的小批量数据(以及其中任何给定的样本)对参数向量的影响,这赋予了模型一定程度的稳定性。
def grad_clipping(net, theta): #@save"""截断梯度"""if isinstance(net, nn.Module):params = [p for p in net.parameters() if p.requires_grad]else:params = net.paramsnorm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))if norm > theta:for param in params:param.grad[:] *= theta / norm
8.5.3 Training
下面训练模型的方式与3.6有三个不同之处:
- 序列数据的不同采样方法(随机采样和顺序分区)将导致隐状态初始化的差异。
使用顺序分区时,只在每个迭代周期的开始位置初始化隐状态,由于下一个小批量数据中的第 i i i个子序列样本与当前第 i i i个子序列样本相邻,因此当前小批量数据最后一个样本的隐状态将用于初始化下一个小批量数据第一个样本的隐状态。这样,存储在隐状态中的序列的历史信息可以在一个迭代周期内流经相邻的子序列,然而在任何一点隐状态的计算,都依赖于同一迭代周期中前面所有的小批量数据,这使得梯度计算变得复杂。为了降低计算量,在处理任何一个小批量数据之前,我们先分离梯度,使得隐状态的梯度计算总是限制在一个小批量数据的时间步内。当使用随机抽样时,需要为每个迭代周期重新初始化隐状态因为每个样本都是在一个随机位置抽样的。 - 在更新模型参数之前截断梯度,目的是使得即使训练过程中某个点上发生了梯度爆炸,也能保证模型收敛。
- 用困惑度来评价模型,确保了不同长度的序列具有可比性。
代码如下:
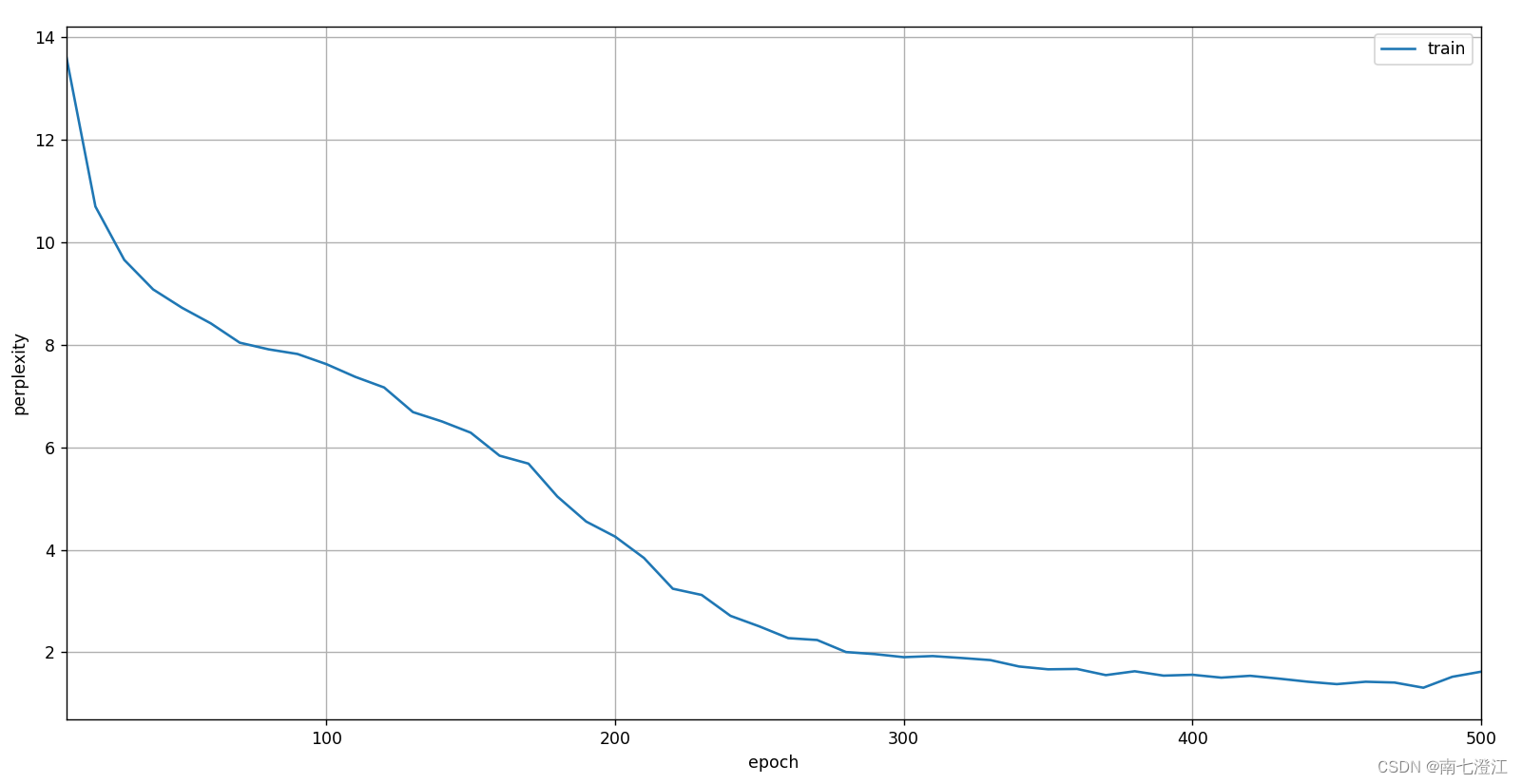
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):#@save"""训练网络一个迭代周期"""state, timer = None, d2l.Timer()metric = d2l.Accumulator(2) # 训练损失之和,词元数量for X, Y in train_iter:if state is None or use_random_iter:# 在第一次迭代或使用随机抽样时初始化statestate = net.begin_state(batch_size=X.shape[0], device=device)else:if isinstance(net, nn.Module) and not isinstance(state, tuple):# state对于nn.GRU是个张量state.detach_()else:# state对于nn.LSTM或对于我们从零开始实现的模型是个张量for s in state:s.detach_()y = Y.T.reshape(-1)X, y = X.to(device), y.to(device)y_hat, state = net(X, state)l = loss(y_hat, y.long()).mean()if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.backward()grad_clipping(net, 1)updater.step()else:l.backward()grad_clipping(net, 1)# 因为已经调用了mean函数updater(batch_size=1)metric.add(l * y.numel(), y.numel())#y.numel()返回y中元素的数量return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()def train_ch8(net, train_iter, vocab, lr, num_epochs, device,use_random_iter=False):#@save"""训练模型"""loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])# 初始化if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(), lr)else:updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)# 训练和预测for epoch in range(num_epochs):ppl, speed = train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter)if (epoch + 1) % 10 == 0:print(predict('time traveller'))animator.add(epoch + 1, [ppl])print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')print(predict('time traveller'))print(predict('traveller'))num_epochs, lr = 500, 1#使用顺序分区
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu())
#使用随机抽样
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu(),use_random_iter=True)
plt.show()
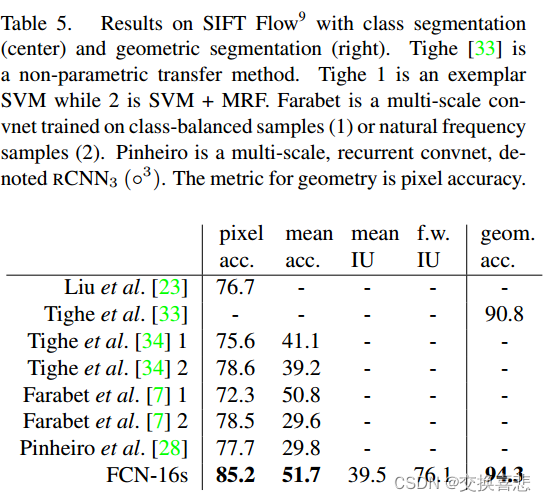
顺序分区训练结果:

随机抽样训练结果:
相关文章:
《动手学深度学习(PyTorch版)》笔记8.5
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过&…...
【蓝桥杯单片机入门记录】LED灯(附多个例程)
目录 一、LED灯概述 1.1 LED发光原理 1.2电路原理图 1.3电路实物图 1.4 开发板LED灯原理图 1.4.1共阳极LED灯操控原理(本开发板) (非实际原理图,便于理解版本)由图可以看出,每个LED灯的左边…...

c语言简单json库
文章目录 写在前面头文件源代码使用示例 写在前面 用c语言实现的一个简单json库,极其轻量 仅1个四百多行源码的源文件,和1个头文件 支持对象、数组、数值、字符串类型 github仓库 头文件 对主要的json API的声明 #ifndef ARCOJSON_ARCOJSON_H #defin…...

Linux操作系统基础(七):Linux常见命令(二)
文章目录 Linux常见命令(二) 一、kill命令 二、ifconfig命令 三、clear命令 四、重启与关机命令 五、which命令 六、hostname命令 七、grep命令 八、|管道 九、useradd命令 十、userdel命令 十一、tar命令 十二、su命令 十三、ps命令 Linu…...

进程状态
广义概念: 从广义上来讲,进程分为新建、运行、阻塞、挂起、退出五个状态,其中新建和退出两个状态可以直接理解字面意思。 运行状态: 这里涉及到运行队列的概念,CPU在读取数据的时候,需要把内存中的进程放入…...
STM32固件库简介与使用指南
1. STM32官方标准固件库简介 STM32官方标准固件库是由STMicroelectronics(ST)提供的一套软件开发工具,旨在简化STM32微控制器的软件开发过程。该固件库提供了丰富的功能和模块,涵盖了STM32微控制器的各种外设,包括但不…...

【开源】SpringBoot框架开发智能教学资源库系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 课程档案模块2.3 课程资源模块2.4 课程作业模块2.5 课程评价模块 三、系统设计3.1 用例设计3.2 数据库设计3.2.1 课程档案表3.2.2 课程资源表3.2.3 课程作业表3.2.4 课程评价表 四、系统展示五、核心代…...

融资项目——获取树形结构的数据
如下图所示,下列数据是一个树形结构数据,行业中包含若干子节点。表的设计如下图,设置了一个id为1的虚拟根节点。(本树形结构带虚拟根节点共三层) 实现逻辑: 延时展示方法,先展现第二层的信息&a…...

Crypto-RSA2
题目:(BUUCTF在线评测 (buuoj.cn)) 已知e,n,dp/(dq),c求明文: 首先有如下公式: dp ≡ d mod (p-1) ,ed ≡ 1 mod φ(n) ,npq ,φ(n)(p-1)(q-1) python代码实现如下: import libnu…...
IEEE Internet of Things Journal投稿经验
期刊名:IEEE Internet of Things Journal 期刊分区:中科院一区 Top 影响因子:10.6 投稿状态 (1)2023.11.3,投稿成功,状态为:under review(大u大r)࿱…...
实例分割论文阅读之:FCN:《Fully Convolutional Networks for Semantica Segmentation》
论文地址:https://openaccess.thecvf.com/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf 代码链接:https://github.com/pytorch/vision 摘要 卷积网络是强大的视觉模型,可以产生特征层次结构。我们证明,…...

apk反编译修改教程系列---简单去除apk登陆 修改vip与一些反编译基础常识【十二】
往期教程: 安卓玩机-----反编译apk 修改apk 去广告 去弹窗等操作中的一些常识apk反编译修改教程系列-----修改apk应用名称 任意修改名称 签名【一】 apk反编译修改教程系列-----任意修改apk版本号 版本名 防止自动更新【二】 apk反编译修改教程系列-----修改apk中…...

网络安全习题集
第一章 绪论 4 ISO / OSI 安全体系结构中的对象认证安全服务使用( C ) 机制来完成。 A .访问控制 B .加密 C .数字签名 D .数据完整性 5 身份鉴别是安全服务中的重要一环,以下关于身份鉴别的叙述不正确的是…...

C++中的volatile:穿越编译器的屏障
C中的volatile:穿越编译器的屏障 在C编程中,我们经常会遇到需要与硬件交互或多线程环境下访问共享数据的情况。为了确保程序的正确性和可预测性,C提供了关键字volatile来修饰变量。本文将深入解析C中的volatile关键字,介绍其作用、…...
(07)Hive——窗口函数详解
一、 窗口函数知识点 1.1 窗户函数的定义 窗口函数可以拆分为【窗口函数】。窗口函数官网指路: LanguageManual WindowingAndAnalytics - Apache Hive - Apache Software Foundationhttps://cwiki.apache.org/confluence/display/Hive/LanguageManual%20Windowing…...
【开源图床】使用Typora+PicGo+Github+CDN搭建个人博客图床
准备工作: 首先电脑得提前完成安装如下: 1. nodejs环境(node ,npm):【安装指南】nodejs下载、安装与配置详细教程 2. Picgo:【安装指南】图床神器之Picgo下载、安装与配置详细教程 3. Typora:【安装指南】markdown神器之Typora下载、安装与无限使用详细教…...

阅读笔记(SOFT COMPUTING 2018)Seam elimination based on Curvelet for image stitching
参考文献: Wang Z, Yang Z. Seam elimination based on Curvelet for image stitching[J]. Soft Computing, 2018: 1-16. 注:SOFT COMPUTING 大类学科小类学科Top期刊综述期刊工程技术 3区 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE 计算机…...

LinkedList数据结构链表
LinkedList在Java中是一个实现了List和Deque接口的双向链表。它允许我们在列表的两端添加或删除元素,同时也支持在列表中间插入或移除元素。在分析LinkedList之前,需要理解链表这种数据结构: 链表:链表是一种动态数据结构&#x…...
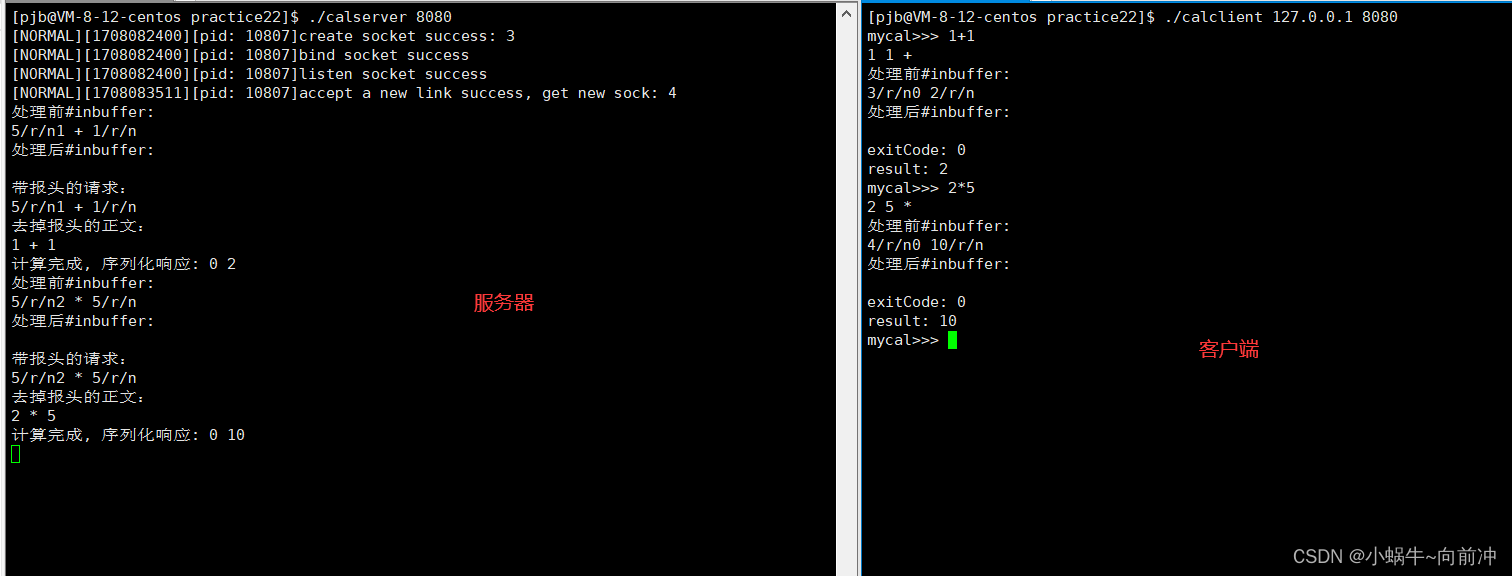
[计算机网络]---序列化和反序列化
前言 作者:小蜗牛向前冲 名言:我可以接受失败,但我不能接受放弃 如果觉的博主的文章还不错的话,还请点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正 目录 一、再谈协议…...

[前端开发] 常见的 HTML CSS JavaScript 事件
代码示例指路 常见的 HTML、CSS、JavaScript 事件代码示例 常见的 HTML CSS JavaScript 事件 事件HTML 事件鼠标事件键盘事件表单事件 JavaScript 事件对象事件代理(事件委托) 事件 在 Web 开发中,事件是用户与网页交互的重要方式之一。通过…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...