突破编程_C++_高级教程(多线程编程实例)
1 生产者-消费者模型
生产者-消费者模型是一种多线程协作的设计模式,它主要用于处理生产数据和消费数据的过程。在这个模型中,存在两类线程:生产者线程和消费者线程。生产者线程负责生产数据,并将其放入一个共享的数据缓冲区(通常是一个队列)。消费者线程则从该数据缓冲区中取出数据进行处理。这种模型的核心在于确保生产者和消费者之间的同步和互斥,以防止数据丢失或重复处理。
生产者-消费者模型的适用场景:
生产者-消费者模型广泛适用于需要处理并发数据流的场景,其中数据的生成和处理速度可能不同。以下是几个具体的应用场景:
线程池
在实现线程池的技术点中,任务队列就是一个典型的生产者-消费者模型的应用。当线程池繁忙时,新提交的任务会被放入任务队列(相当于数据缓冲区)等待处理。一旦有线程空闲出来,它会从队列中取出任务进行处理。
网络编程
在生产者-消费者模型中,生产者可以代表网络数据的接收方,将接收到的数据放入缓冲区;而消费者可以代表数据的处理方,从缓冲区中取出数据进行处理。这种模型可以有效地处理网络延迟和数据流的不稳定性。
数据库操作
在数据库操作中,生产者可以代表数据的写入操作,将数据写入数据库;消费者可以代表数据的读取操作,从数据库中读取数据进行处理。生产者-消费者模型可以有效地处理数据库的读写并发问题。
文件操作
在处理大文件或数据流时,生产者可以代表数据的读取操作,将读取的数据放入缓冲区;消费者可以代表数据的处理操作,从缓冲区中取出数据进行处理。这种模型可以有效地提高文件处理的效率。
在 C++11 中,可以使用 <thread>, <mutex>, <condition_variable> 和 <queue> 等库来实现生产者-消费者模型。如下为样例代码:
#include <iostream>
#include <thread>
#include <vector>
#include <queue>
#include <mutex>
#include <condition_variable> std::queue<int> g_datas; // 全局生产产品
int g_dataIndex = 0; // 全局生产产品的编号std::mutex g_mutex;
std::condition_variable g_cv;const int MAX_NUM = 3; // 一次生产产品的数量void producer(int id)
{for (int i = 0; i < MAX_NUM; ++i){std::unique_lock<std::mutex> lock(g_mutex);g_datas.push(g_dataIndex);printf("producer %d produced item : %d\n", id, g_dataIndex);g_dataIndex++;g_cv.notify_one();lock.unlock();std::this_thread::yield(); // 计算机核数较多,并且性能较好的情况下,该语句可以不用加,这样生产者-消费者的整体效率更高。}// 通知生产结束 g_cv.notify_all();
}void consumer()
{while (true) {std::unique_lock<std::mutex> lock(g_mutex);g_cv.wait(lock, [] { return !g_datas.empty(); });int data = g_datas.front();g_datas.pop();printf("consumer consumed item : %d\n", data);}
}int main()
{std::vector<std::thread> producers;std::thread consumerThread(consumer);// 创建生产者线程 for (int i = 0; i < 3; i++){producers.emplace_back(producer, i);}// 等待生产结束for (auto& t : producers){t.join();}consumerThread.join();return 0;
}
上面代码的输出为:
producer 0 produced item : 0
consumer consumed item : 0
producer 0 produced item : 1
producer 0 produced item : 2
consumer consumed item : 1
consumer consumed item : 2
producer 2 produced item : 3
producer 2 produced item : 4
consumer consumed item : 3
consumer consumed item : 4
producer 1 produced item : 5
producer 2 produced item : 6
consumer consumed item : 5
consumer consumed item : 6
producer 1 produced item : 7
consumer consumed item : 7
producer 1 produced item : 8
consumer consumed item : 8
在上面代码中,创建了多个生产者线程和一个消费者线程。每个生产者线程都按照产品序列号进行产品生产,并将其推送到共享队列 g_datas 中。消费者线程则等待队列中有元素可用时,从中取出元素并处理。当所有生产者线程完成生产后,它们通过 g_cv.notify_all(); 通知消费者线程来结束生产。
注意以下几点:
使用 std::mutex 来保护共享队列 g_datas 的访问,确保同一时间只有一个线程可以修改它。
使用 std::condition_variable 来在队列为空时阻塞消费者线程,直到有生产者线程向队列中添加新元素。
std::unique_lock 与 std::lock_guard 类似,但提供了更多的灵活性,如手动解锁和条件等待。
std::this_thread::yield() 用于让出CPU时间片,使其他线程有机会运行。但是在计算机核数较多,并且性能较好的情况下,该语句可以不用加,这样生产者-消费者的整体效率更高。
这个模型可以扩展为多个消费者线程,只需创建更多的消费者线程实例即可。在实际应用中,可能还需要考虑其他因素,如队列的大小限制、线程的同步问题、以及优雅地处理线程的启动和停止等。
2 线程池
线程池是一种在并发编程中常用的技术,它用于管理和重用线程。线程池的基本思想是在应用程序启动时创建一定数量的线程,并将它们保存在一个线程池中。当需要执行任务时,从线程池中获取一个空闲的线程来执行该任务。当任务执行完毕后,线程将返回到线程池,以供其他任务复用。线程池的设计目标是避免频繁地创建和销毁线程所带来的开销,以及控制并发执行的线程数量,从而提高系统的性能和资源利用率。
线程池通常包含以下几个关键组成部分:
线程池管理器
负责创建、管理和控制线程池。它负责线程的创建、销毁和管理,以及线程池的状态监控和调度任务。
工作队列
用于存储待执行的任务。当线程池中的线程都在执行任务时,新的任务会被放入工作队列中等待执行。
线程池线程
实际执行任务的线程。线程池中会维护一组线程,这些线程可以被重复使用,从而避免了频繁创建和销毁线程的开销。
线程池的运行机制如下:当任务到达时,线程池管理器会检查线程池中是否有空闲的线程。如果有,则将任务分配给空闲线程执行;如果没有,则根据线程池的配置来决定是创建一个新线程还是将任务放入工作队列中等待执行。当线程池中的线程执行完任务后,会从工作队列中获取下一个任务并执行。
线程池适用于以下场景:
任务量巨大且单个任务执行时间较短
当有大量任务需要执行,且每个任务的执行时间相对较短时,使用线程池可以显著提高程序的执行效率。线程池可以避免频繁地创建和销毁线程,减少资源消耗。
需要控制并发度
线程池可以限制并发执行的线程数量,防止系统过载。通过调整线程池的大小,可以控制并发度,避免资源消耗过大。
提供线程管理和监控
线程池提供了一些管理和监控机制,例如线程池的创建、销毁、线程状态的监控等,方便开发人员进行线程的管理和调试。
总体而言,线程池是一种高效、灵活的并发编程技术,适用于多种场景。通过合理地配置线程池的大小和任务队列的容量,可以充分利用系统资源,提高程序的性能和响应速度。
在 C++11 中,可以使用 <thread>, <mutex>, <condition_variable> 和 <queue> 等库来实现线程池。如下为样例代码:
#include <iostream>
#include <vector>
#include <queue>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <functional>
#include <future> class ThreadPool
{
public:ThreadPool(size_t);template<class F, class... Args>auto enqueue(F&& f, Args&&... args)->std::future<typename std::result_of<F(Args...)>::type>;~ThreadPool();
private:// 需要保持线程活动的标记 std::vector< std::thread > workers;// 任务队列 std::queue< std::function<void()> > tasks;// 同步 std::mutex queueMutex;std::condition_variable condition;bool stop;
};// 构造函数
inline ThreadPool::ThreadPool(size_t num): stop(false)
{for (size_t i = 0; i < num; i++){workers.emplace_back([this] {while (true){std::function<void()> task;{std::unique_lock<std::mutex> lock(this->queueMutex);this->condition.wait(lock,[this] { return this->stop || !this->tasks.empty(); });if (this->stop && this->tasks.empty()){return;}task = std::move(this->tasks.front());this->tasks.pop();}task();}});}
}// 添加新工作项到线程池
template<class F, class... Args>
auto ThreadPool::enqueue(F&& f, Args&&... args)
-> std::future<typename std::result_of<F(Args...)>::type>
{using return_type = typename std::result_of<F(Args...)>::type;auto task = std::make_shared< std::packaged_task<return_type()> >(std::bind(std::forward<F>(f), std::forward<Args>(args)...));std::future<return_type> res = task->get_future();{std::unique_lock<std::mutex> lock(queueMutex);// 不允许在停止后添加任务 if (stop) {throw std::runtime_error("enqueue on stopped ThreadPool");}tasks.emplace([task]() { (*task)(); });}condition.notify_one();return res;
}// 析构函数
inline ThreadPool::~ThreadPool()
{{std::unique_lock<std::mutex> lock(queueMutex);stop = true;}condition.notify_all();for (std::thread &worker : workers) {worker.join();}
}// 使用线程池的例子
void doSomething(int n)
{printf("doing something with %d\n",n);std::this_thread::sleep_for(std::chrono::seconds(1));
}int main() {ThreadPool pool(4);// 添加任务到线程池 auto fut1 = pool.enqueue(doSomething, 1);auto fut2 = pool.enqueue(doSomething, 2);auto fut3 = pool.enqueue(doSomething, 3);auto fut4 = pool.enqueue(doSomething, 4);// 等待所有任务完成 fut1.get();fut2.get();fut3.get();fut4.get();return 0;
}
上面代码的输出为:
doing something with 1
doing something with 2
doing something with 3
doing something with 4
上面代码中的 enqueue 函数是是线程池的核心,它接受一个可调用对象(函数、 Lambda 表达式等)和一组参数,并将它们封装到一个 std::packaged_task 对象中。 std::packaged_task 是一个模板类,它接受一个可调用对象,并将其包装成一个任务,这个任务可以异步执行,并且可以在将来某个时间点获取其结果。
一旦任务被封装,它就被添加到线程池的任务队列中。然后,通过调用condition.notify_one()来唤醒一个等待在条件变量上的线程(如果有的话)。这个被唤醒的线程会从队列中取出任务并执行它。
enqueue 函数返回一个 std::future 对象,这个对象代表了异步任务的结果。调用者可以通过这个 std::future 对象来获取任务的结果,或者等待任务完成。
在main函数中,首先创建了一个包含 4 个线程的线程池。然后向线程池添加了 4 个任务,每个任务都调用 doSomething 函数并传入一个不同的参数。每个任务都返回一个 std::future 对象,我们可以通过这些对象来等待任务完成并获取结果。
最后,通过调用 get() 方法来等待每个任务完成并获取其结果。因为 doSomething 函数没有返回任何值,所以 get() 方法在这里实际上没有做任何事情。如果 doSomething 函数返回了一个值,那么get()方法会返回这个值。
3 定时器
定时器是一个可以设定在某一特定时间点触发某个操作或事件的系统工具。它可以基于时间周期来执行任务,或者在某些特定时间间隔后执行某个操作。定时器的主要作用是产生一个时基,即从某一时刻开始,经过一段指定的时间,触发一个中断或超时回调事件,可以在中断或者超时回调函数中处理数据。
定时器的适用场景非常广泛,如下是几种常见的用途:
嵌入式系统
在嵌入式系统中,定时器是一个基础服务,如 RTOS (实时操作系统)就需要依赖定时器提供时钟节拍以实现线程延时、线程时间片轮询调度等。
操作系统
在操作系统中,定时器用于实现各种定时任务,如定时清理缓存、定时检查系统资源使用情况等。
网络编程
在网络编程中,定时器常用于实现超时控制,如TCP连接超时、请求超时等。
任务调度
在任务调度系统中,定时器可以用于按照预设的时间间隔执行某些任务,如每日的数据统计、报告生成等。
在 C++11 中,可以使用 <thread>, <mutex>, <condition_variable> 和 <queue> 等库来实现线程池。如下为样例代码:
#include <iostream>
#include <thread>
#include <chrono>
#include <atomic>
#include <mutex>
#include <condition_variable>
#include <functional> class Timer {
public:Timer() : expired(true), tryToExpire(false) {}void start(uint64_t interval, std::function<void()> task){if (expired == false) {// 上一个定时器还在运行, 设置一个标志让线程尽快结束当前等待并退出 tryToExpire = true;// 等待线程结束 if (thread.joinable()){thread.join();}}expired = false;tryToExpire = false;// 保存任务和间隔时间 this->task = task;this->interval = std::chrono::milliseconds(interval);// 启动定时器线程 thread = std::thread([this]() {while (!expired) {std::unique_lock<std::mutex> lock(this->mtx);// 检查是否需要尽快结束等待 if (tryToExpire){// 通过notify_all唤醒可能在等待的线程,并立即返回 this->cv.notify_all();continue;}// 等待定时器到期或收到退出通知 this->cv.wait_for(lock, this->interval, [this]() { return this->expired || this->tryToExpire; });// 检查定时器是否仍然有效 if (!expired) {// 执行任务 this->task();}}});// 分离线程,这样当线程结束时会自动释放资源 thread.detach();}void stop() {// 设置定时器到期标志 expired = true;tryToExpire = true;// 唤醒可能在等待的线程 cv.notify_all();// 如果线程是可连接的,则等待它结束 if (thread.joinable()) {thread.join();}}~Timer() {stop();}private:std::atomic<bool> expired;std::atomic<bool> tryToExpire;std::thread thread;std::function<void()> task;std::chrono::milliseconds interval;std::mutex mtx;std::condition_variable cv;
};// 使用示例
int main() {Timer timer;timer.start(1000, []() {printf("timer task executed!\n");});std::this_thread::sleep_for(std::chrono::milliseconds(4200));printf("main thread waking up...\n");// 停止定时器 timer.stop();return 0;
}
上面代码的输出为:
timer task executed!
timer task executed!
timer task executed!
timer task executed!
main thread waking up...
上面代码中的 Timer 类使用一个内部线程来周期性地执行任务。当调用 start 方法时,它会启动一个线程,该线程将等待指定的时间间隔,然后执行任务。如果定时器正在运行,并且再次调用 start ,则会尝试停止当前线程并启动一个新的线程。调用 stop 方法会设置标志来通知线程退出循环,并结束执行。
注意:这个简单的定时器实现可能不适用于所有场景,特别是需要高精度或复杂调度的场景。对于更复杂的用例,可能需要使用专门的定时器库或考虑使用操作系统提供的定时器服务。
另外,这个实现中使用了 std::thread::detach 来分离线程。这意味着一旦线程完成执行,它会自动释放所有资源。然而,在某些情况下,使用 detach 可能会导致问题,因为它不允许检查线程是否已安全完成执行。在更复杂的应用程序中,使用 std::future 和 std::async 可能是更好的选择,因为它们提供了更好的异常处理和线程同步机制。
4 多线程搜索算法
在 C++ 中,可以使用多线程来加速搜索算法,特别是当处理大量数据或可以并行处理多个搜索任务时。以下是一个简单的例子,展示了如何使用 C++ 的多线程功能来加速一个简单的线性搜索算法。
假设有一个很大的整数数组,并且想要找到某个特定的值。可以将数组分成多个部分,并为每个部分分配一个线程来执行搜索。这样,搜索任务就可以并行执行,从而加速搜索过程。
如下为样例代码:
#include <iostream>
#include <vector>
#include <thread>
#include <atomic> // 搜索函数,用于单个线程
bool searchInRange(const std::vector<int>& data, size_t start, size_t end, int target, std::atomic<bool>& found)
{for (size_t i = start; i < end; i++){if (data[i] == target){found = true;return true;}}return false;
}// 多线程搜索函数
bool parallelSearch(const std::vector<int>& data, int target, size_t threadCount)
{std::atomic<bool> found(false);const size_t rangeSize = data.size() / threadCount;std::vector<std::thread> threads;// 为每个线程分配一个搜索范围 for (size_t i = 0; i < threadCount; i++){size_t start = i * rangeSize;size_t end = (i == threadCount - 1) ? data.size() : start + rangeSize;threads.emplace_back(searchInRange, std::ref(data), start, end, target, std::ref(found));}// 等待所有线程完成 for (auto& thread : threads){thread.join();}// 检查是否找到了目标 return found;
}int main()
{// 示例数据 std::vector<int> data = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };int target = 6;// 使用多线程搜索 const size_t threadCount = std::thread::hardware_concurrency(); // 获取可用的CPU核心数 if (parallelSearch(data, target, threadCount)) {printf("found target %d in parallel search\n", target);}else {printf("target %d not found in parallel search\n", target);}return 0;
}
上面代码的输出为:
found target 6 in parallel search
在上面代码中, parallelSearch 函数负责创建多个线程,并将搜索任务分配给它们。每个线程都会调用 searchInRange 函数,该函数负责在分配给它的数组范围内搜索目标值。 std::atomic 类型的 found 变量用于跨线程同步搜索结果。
注意:这个简单的例子并没有考虑数据划分和线程同步的复杂性。在实际应用中,可能需要更复杂的策略来确保数据被均匀划分,并避免线程间的数据竞争。此外,对于某些类型的数据和搜索算法,多线程搜索可能并不会带来性能提升,甚至可能导致性能下降,因为线程创建和管理本身也需要资源。因此,在决定使用多线程之前,最好先分析数据和算法,看看它们是否适合并行处理。
相关文章:
)
突破编程_C++_高级教程(多线程编程实例)
1 生产者-消费者模型 生产者-消费者模型是一种多线程协作的设计模式,它主要用于处理生产数据和消费数据的过程。在这个模型中,存在两类线程:生产者线程和消费者线程。生产者线程负责生产数据,并将其放入一个共享的数据缓冲区&…...

精读《Function Component 入门》
1. 引言 如果你在使用 React 16,可以尝试 Function Component 风格,享受更大的灵活性。但在尝试之前,最好先阅读本文,对 Function Component 的思维模式有一个初步认识,防止因思维模式不同步造成的困扰。 2. 精读 什…...

类的构造方法
在类中,出成员方法外,还存在一种特殊类型的方法,那就是构造方法。构造方法是一个与类同名的方法,对象的创建就是通过构造方法完成的。每个类实例化一个对象时,类都会自动调用构造方法。 构造方法的特点: 构…...

ChatGPT和LLM
ChatGPT和LLM(大型语言模型)之间存在密切的关系。 首先,LLM是一个更为抽象的概念,它包含了各种自然语言处理任务中使用的各种深度学习模型结构。这些模型通过建立深层神经网络,根据已有的大量文本数据进行文本自动生成…...

「优选算法刷题」:判定字符是否唯一
一、题目 实现一个算法,确定一个字符串 s 的所有字符是否全都不同。 示例 1: 输入: s "leetcode" 输出: false 示例 2: 输入: s "abc" 输出: true限制: 0 < len(s) < 100 s[i]仅包含小写字母 二…...

详解自定义类型:枚举与联合体!
目录 编辑 一、枚举类型 1.枚举类型的声明 2.枚举类型的优点 3.枚举类型的使用 二、联合体类型(共用体) 1.联合体类型的声明 2.联合体的特点 3.相同成员的结构体和联合体的对比 4.联合体大小的计算 5.用联合体判断大小端 三.完结散花 悟已往之不谏&…...

第13章 网络 Page738~741 13.8.3 TCP/UDP简述
libcurl是C语言写成的网络编程工具库,asio是C写的网络编程的基础类型库 libcurl只用于客户端,asio既可以写客户端,也可以写服务端 libcurl实现了HTTP\FTP等应用层协议,但asio却只实现了传输层TCP/UDP等协议。 在学习http时介绍…...
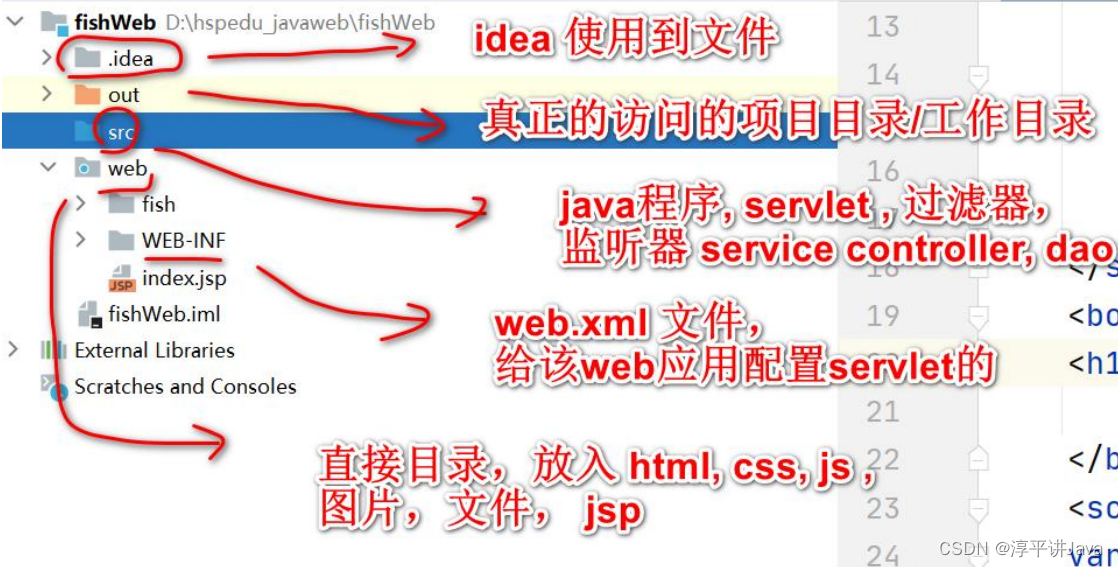
Tomcat要点总结
一、Tomcat 服务中部署 WEB 应用 1.什么是Web应用 (1) WEB 应用是多个 web 资源的集合。简单的说,可以把 web 应用理解为硬盘上的一个目录, 这个目录用于管理多个 web 资源。 (2)Web 应用通常也称之为…...
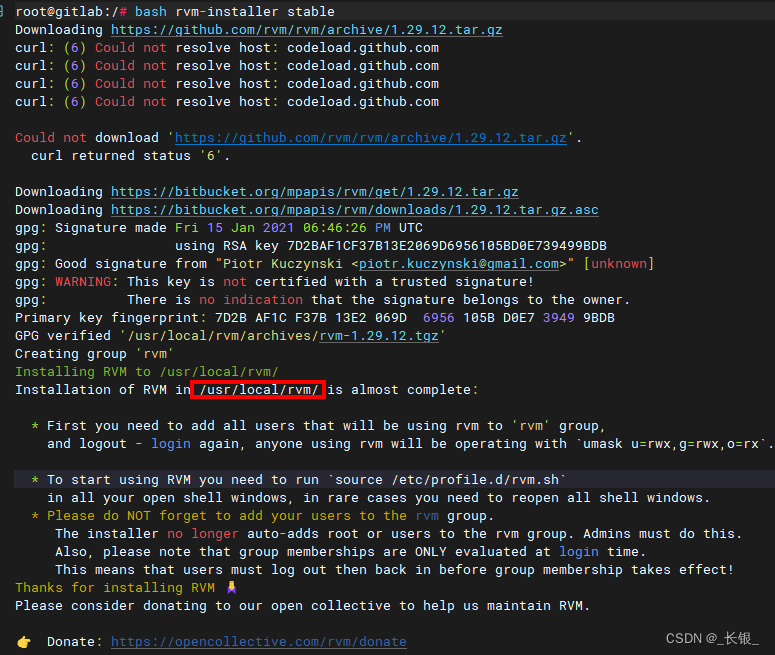
Ubuntu 20.04 安装RVM
RVM是管理Ruby版本的工具,使用RVM可以在单机上方便地管理多个Ruby版本。 下载安装脚本 首先使下载安装脚本 wget https://raw.githubusercontent.com/rvm/rvm/master/binscripts/rvm-installer 如果出现了 Connection refused 的情况, 可以考虑执行以下命令修改dns,再执…...

Ps:污点修复画笔工具
污点修复画笔工具 Spot Healing Brush Tool专门用于快速清除图像中的小瑕疵、污点、尘埃或其他不想要的小元素。 它通过分析被修复区域周围的内容,无需手动取样,自动选择最佳的修复区域来覆盖和融合这些不完美之处,从而实现无痕修复的效果。 …...

JAVA面试题17
什么是Java中的静态内部类?它与非静态内部类有什么区别? 答案:静态内部类是定义在另一个类中的类,并且被声明为静态。与非静态内部类不同,静态内部类不依赖于外部类的实例,可以直接访问外部类的静态成员。 …...

数据备份和恢复
数据备份和恢复 什么情况下会用到数据备份呢 数据丢失的场景 人为误操作造成的某些数据被误操作 软件BUG造成数据部分或者全部丢失 硬件故障造成数据库部分或全部丢失 安全漏洞被入侵数据恶意破坏 非数据丢失场景 基于某个时间点的数据恢复 开发测试环境数据库搭建 相同数据库的…...
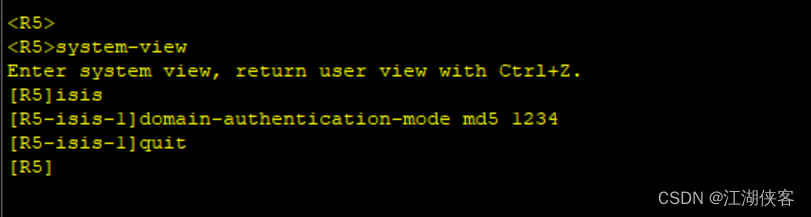
核心篇 - 集成IS-IS配置实战
文章目录 一. 实验专题1.1. 实验1:配置单区域集成IS-IS1.1.1. 实验目的1.1.2. 实验拓扑1.1.3. 实验步骤(1)配置IP地址(2)配置IS-IS 1.1.4. 实验调试(1)查看邻接表(2)查看…...

【OpenAI Sora】开启未来:视频生成模型作为终极世界模拟器的突破之旅
这份技术报告主要关注两个方面:(1)我们的方法将各种类型的视觉数据转化为统一的表示形式,从而实现了大规模生成模型的训练;(2)对Sora的能力和局限性进行了定性评估。报告中不包含模型和实现细节…...
)
MVC 、DDD、中台、Java SPI(Service Provider Interface)
文章目录 引言I 单体架构DDD实现版本1.1 核心概念1.2 DDD四层架构规范1.3 案例1.4 请求转发流程II 领域服务调用2.1 菱形对称架构2.2 中台III Java SPI3.1 概念3.2 实现原理3.3 例子:本地SPI找服务see alsojava -cp</...

C++单例模式的实现
单例模式就是在整个程序运行期都只有一个实例。在代码实现方面,我们要限制new出多于一个对象这种情况的发生。而不是仅仅依靠无保障的约定。 目前大多数的编程语言的做法都是私有化构造函数,对外提供一个获取实例的接口。这样做的目的使实例的创建不能在…...

rust函数 stuct struct方法 关联函数
本文结合2个代码实例主要介绍了rust函数定义方法,struct结构体定义、struct方法及关联函数等相关基础知识。 代码1: main.rc #[derive(Debug)]//定义一个结构体 struct Ellipse {max_semi_axis: u32,min_semi_axis: u32, }fn main() {//椭圆࿰…...

浅谈基于中台模式的大数据生态体系的理解
这篇文章主要浅谈一下我对大数据生态体系建设的理解。 大数据生态系统为高并发,高吞吐,高峰值,高堆积等大规模数据的采集,处理,计算,存储,服务提供了完善的处理体系,致力于打造核心数…...

MySQL的锁机制
一:概述 锁是计算机协调多个进程或线程并发访问某一资源的机制(避免争抢); 在数据库中,除传统的计算资源(如CPU,RAM,I/O等)的争用以外,数据也是一种供许多用…...

已解决ImportError: cannot import name ‘PILLOW_VERSION‘异常的正确解决方法,亲测有效!!!
已解决ImportError: cannot import name PILLOW_VERSION异常的正确解决方法,亲测有效!!! 文章目录 问题分析 报错原因 解决思路 解决方法 总结 在Python项目开发中,依赖管理是保证项目正常运行的关键环节。然而&…...
Unity3D物体缩放避坑指南:为什么你的Transform.localScale总是不生效?
Unity3D物体缩放避坑指南:为什么你的Transform.localScale总是不生效? 在Unity3D开发中,Transform.localScale属性看似简单,却隐藏着许多让开发者头疼的陷阱。不少开发者都遇到过这样的场景:明明代码里设置了localScal…...

从单调到惊艳:手把手教你用PyQt5 QPalette打造动态渐变和图片自适应背景窗口
从单调到惊艳:手把手教你用PyQt5 QPalette打造动态渐变和图片自适应背景窗口 在桌面应用开发中,用户界面的视觉体验往往决定了产品的第一印象。传统的单色背景或简单图片填充已经难以满足现代用户对美感的追求。PyQt5作为Python生态中最强大的GUI框架之一…...

从Kaggle竞赛到真实业务:聊聊那些年我们用错的AI算法和开源库
从Kaggle竞赛到真实业务:聊聊那些年我们用错的AI算法和开源库 在数据科学社区里,Kaggle竞赛排行榜和真实业务需求之间,似乎永远隔着一道看不见的鸿沟。那些在竞赛中斩获高分的神奇模型,一旦放进生产环境,常常表现得像…...

Linux内核链表安全遍历:list_for_each_entry_safe 深度解析
1. 为什么需要安全的链表遍历 在Linux内核开发中,链表是最基础也是最常用的数据结构之一。内核开发者经常需要遍历链表来访问或操作其中的节点。但有一个场景特别棘手:当你需要在遍历过程中删除当前节点时,普通的遍历方法会导致链表断裂甚至系…...

如何快速掌握PDF对比工具:5个实用场景完全指南
如何快速掌握PDF对比工具:5个实用场景完全指南 【免费下载链接】diff-pdf A simple tool for visually comparing two PDF files 项目地址: https://gitcode.com/gh_mirrors/di/diff-pdf PDF对比工具diff-pdf是一款开源的视觉化PDF文件对比神器,它…...

Alexa Skills Kit SDK SMAPI 集成:自动化技能管理和部署的完整流程
Alexa Skills Kit SDK SMAPI 集成:自动化技能管理和部署的完整流程 【免费下载链接】alexa-skills-kit-sdk-for-nodejs The Alexa Skills Kit SDK for Node.js helps you get a skill up and running quickly, letting you focus on skill logic instead of boilerp…...
)
Carsim Tiretester保姆级教程:从零生成轮胎特性曲线(附完整Excel数据导入流程)
Carsim Tiretester保姆级教程:从零生成轮胎特性曲线(附完整Excel数据导入流程) 刚接触车辆动力学仿真的工程师或学生,常常会被轮胎特性曲线的生成过程困扰。轮胎作为车辆与地面唯一的接触点,其力学特性直接影响整车的操…...

用Qwen3-VL-30B做智能助手:上传文档图片,自动提取关键信息
用Qwen3-VL-30B做智能助手:上传文档图片,自动提取关键信息 1. 为什么需要智能文档处理助手 每天我们都会遇到大量需要处理的文档和图片:合同、发票、报告、表格、名片...手动输入这些信息不仅耗时耗力,还容易出错。传统OCR技术虽…...

解决Qt中使用qmqtt连接ONENet MQTT服务端的版本兼容性问题
1. 问题背景:当qmqtt遇上ONENet 最近在做一个物联网项目,需要用Qt开发一个MQTT客户端连接ONENet平台。按照官方文档,我选择了emqx/qmqtt这个第三方库,结果连接时直接报错。代码明明照着示例写的,参数也都检查过&#x…...

GLM-4v-9b行业落地:跨境电商商品图多语言描述生成自动化方案
GLM-4v-9b行业落地:跨境电商商品图多语言描述生成自动化方案 1. 引言:跨境电商卖家的共同痛点 如果你是做跨境电商的,下面这个场景你一定不陌生:仓库里堆满了新品,运营同事催着要上架,但每个商品都需要准…...