XLNet做文本分类
import torch
from transformers import XLNetTokenizer, XLNetForSequenceClassification
from torch.utils.data import DataLoader, TensorDataset
# 示例文本数据
texts = ["This is a positive example.", "This is a negative example.", "Another positive example."]
# 示例标签
labels = [1, 0, 1] # 1表示正例,0表示负例
# 加载XLNet模型和分词器
model_name = "xlnet-base-cased"
tokenizer = XLNetTokenizer.from_pretrained(model_name)
model = XLNetForSequenceClassification.from_pretrained(model_name)
# 分词并编码文本
tokenized_texts = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# 将标签转换为PyTorch张量
labels = torch.tensor(labels)
# 创建数据集
dataset = TensorDataset(tokenized_texts['input_ids'], tokenized_texts['attention_mask'], labels)
# 创建数据加载器
batch_size = 2
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 设置训练设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 定义优化器和损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
criterion = torch.nn.CrossEntropyLoss()
# 训练模型
epochs = 3
for epoch in range(epochs):
for input_ids, attention_mask, labels in dataloader:
input_ids, attention_mask, labels = input_ids.to(device), attention_mask.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
# 测试模型
model.eval()
with torch.no_grad():
test_texts = ["This is a test sentence.", "Another test sentence."]
tokenized_test_texts = tokenizer(test_texts, padding=True, truncation=True, return_tensors='pt')
input_ids = tokenized_test_texts['input_ids'].to(device)
attention_mask = tokenized_test_texts['attention_mask'].to(device)
outputs = model(input_ids, attention_mask=attention_mask)
logits = outputs.logits
predictions = torch.argmax(logits, dim=1)
print("Predictions:", predictions.tolist())
import torch
from transformers import XLNetTokenizer, XLNetForSequenceClassification
from torch.utils.data import DataLoader, TensorDataset# 示例文本数据
texts = ["This is a positive example.", "This is a negative example.", "Another positive example."]# 示例标签
labels = [1, 0, 1] # 1表示正例,0表示负例# 加载XLNet模型和分词器
model_name = "xlnet-base-cased"
tokenizer = XLNetTokenizer.from_pretrained(model_name)
model = XLNetForSequenceClassification.from_pretrained(model_name)# 分词并编码文本
tokenized_texts = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')# 将标签转换为PyTorch张量
labels = torch.tensor(labels)# 创建数据集
dataset = TensorDataset(tokenized_texts['input_ids'], tokenized_texts['attention_mask'], labels)# 创建数据加载器
batch_size = 2
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# 设置训练设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# 定义优化器和损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
criterion = torch.nn.CrossEntropyLoss()# 训练模型
epochs = 3
for epoch in range(epochs):for input_ids, attention_mask, labels in dataloader:input_ids, attention_mask, labels = input_ids.to(device), attention_mask.to(device), labels.to(device)optimizer.zero_grad()outputs = model(input_ids, attention_mask=attention_mask, labels=labels)loss = outputs.lossloss.backward()optimizer.step()# 测试模型
model.eval()
with torch.no_grad():test_texts = ["This is a test sentence.", "Another test sentence."]tokenized_test_texts = tokenizer(test_texts, padding=True, truncation=True, return_tensors='pt')input_ids = tokenized_test_texts['input_ids'].to(device)attention_mask = tokenized_test_texts['attention_mask'].to(device)outputs = model(input_ids, attention_mask=attention_mask)logits = outputs.logitspredictions = torch.argmax(logits, dim=1)print("Predictions:", predictions.tolist())
相关文章:

XLNet做文本分类
import torch from transformers import XLNetTokenizer, XLNetForSequenceClassification from torch.utils.data import DataLoader, TensorDataset # 示例文本数据 texts ["This is a positive example.", "This is a negative example.", "Anot…...

Swift 5.9 新 @Observable 对象在 SwiftUI 使用中的陷阱与解决
概览 在 Swift 5.9 中,苹果为我们带来了全新的可观察框架 Observation,它是观察者开发模式在 Swift 中的一个全新实现。 除了自身本领过硬以外,Observation 框架和 SwiftUI 搭配起来也能相得益彰,事倍功半。不过 Observable 对象…...
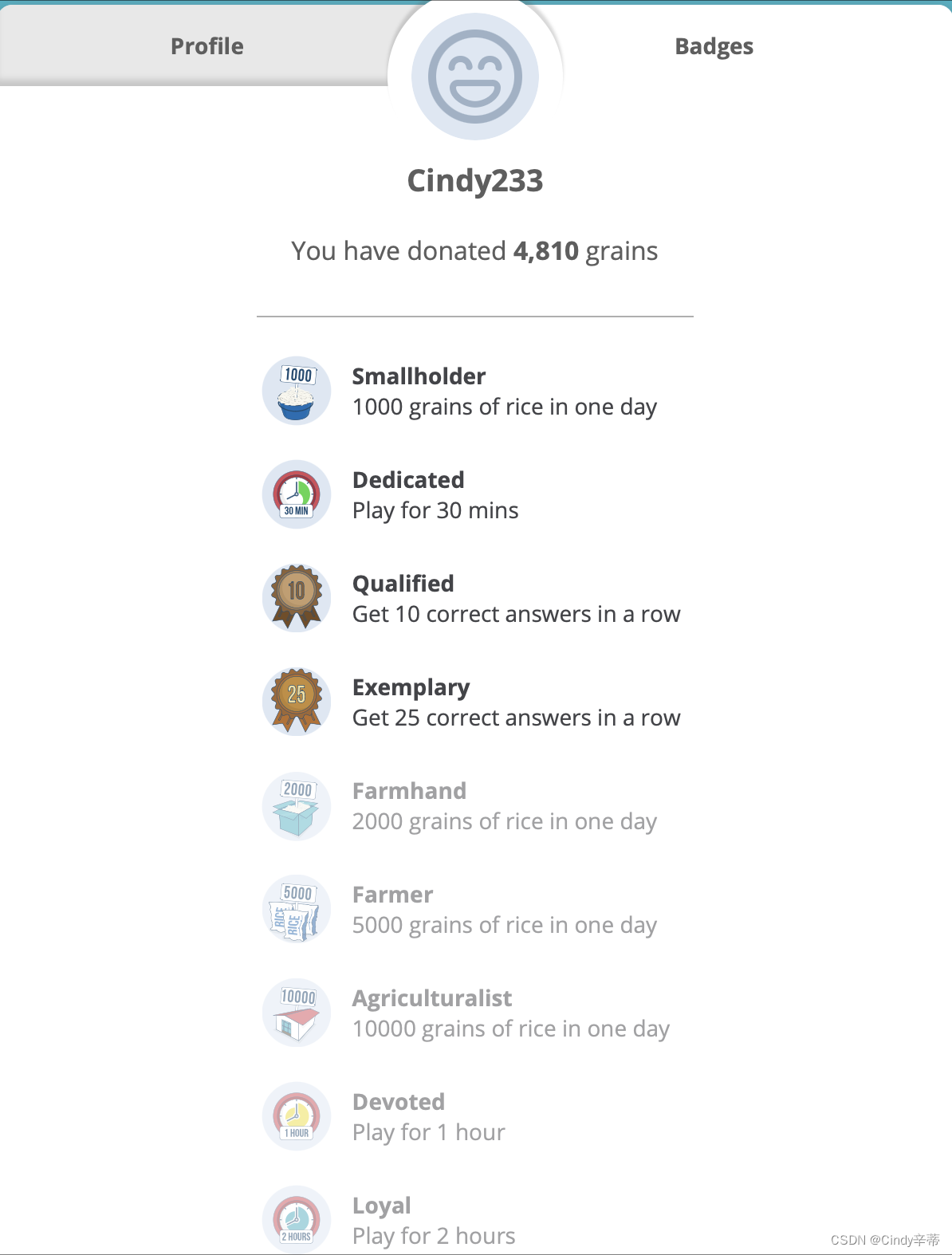
分享一个学英语的网站
名字叫:公益大米网 Freerice 这个网站是以做题的形式来记忆单词,题干是一个单词,给出4个选项,需要选出其中最接近题干单词的选项。 答对可以获得10粒大米,网站的创办者负责捐赠。如图 触发某些条件&a…...

【动态规划】【C++算法】2742. 给墙壁刷油漆
作者推荐 【数位dp】【动态规划】【状态压缩】【推荐】1012. 至少有 1 位重复的数字 本文涉及知识点 动态规划汇总 LeetCode2742. 给墙壁刷油漆 给你两个长度为 n 下标从 0 开始的整数数组 cost 和 time ,分别表示给 n 堵不同的墙刷油漆需要的开销和时间。你有…...
【后端高频面试题--设计模式上篇】
🚀 作者 :“码上有前” 🚀 文章简介 :后端高频面试题 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 往期精彩内容 【后端高频面试题–设计模式上篇】 【后端高频面试题–设计模式下篇】 【后端高频…...

P3141 [USACO16FEB] Fenced In P题解
题目 如果此题数据要小一点,那么我们可以用克鲁斯卡尔算法通过,但是这个数据太大了,空间会爆炸,时间也会爆炸。 我们发现,如果用 MST 做,那么很多边的边权都一样,我们可以整行整列地删除。 我…...

Android Compose 一个音视频APP——Magic Music Player
Magic Music APP Magic Music APP Magic Music APP概述效果预览-视频资源功能预览Library歌曲播放效果预览歌曲播放依赖注入设置播放源播放进度上一首&下一首UI响应 歌词歌词解析解析成行逐行解析 视频播放AndroidView引入Exoplayer自定义Exoplayer样式横竖屏切换 歌曲多任…...

Nginx实战:安装搭建
目录 前言 一、yum安装 二、编译安装 1.下载安装包 2.解压 3.生成makefile文件 4.编译 5.安装执行 6.执行命令软连接 7.Nginx命令 前言 nginx的安装有两种方式: 1、yum安装:安装快速,但是无法在安装的时候带上想要的第三方包 2、…...
Qt之条件变量QWaitCondition详解(从使用到原理分析全)
QWaitCondition内部实现结构图: 相关系列文章 C之Pimpl惯用法 目录 1.简介 2.示例 2.1.全局配置 2.2.生产者Producer 2.3.消费者Consumer 2.4.测试例子 3.原理分析 3.1.源码介绍 3.2.辅助函数CreateEvent 3.3.辅助函数WaitForSingleObject 3.4.QWaitCo…...

OpenSource - 一站式自动化运维及自动化部署平台
文章目录 orion-ops 是什么重构特性快速开始技术栈功能预览添砖加瓦License orion-ops 是什么 orion-ops 一站式自动化运维及自动化部署平台, 使用多环境的概念, 提供了机器管理、机器监控报警、Web终端、WebSftp、机器批量执行、机器批量上传、在线查看日志、定时调度任务、应…...
【后端高频面试题--设计模式下篇】
🚀 作者 :“码上有前” 🚀 文章简介 :后端高频面试题 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 后端高频面试题--设计模式下篇 往期精彩内容设计模式总览模板方法模式怎么理解模板方法模式模板方…...
这才是大学生该做的副业,别再痴迷于游戏了!
感谢大家一直以来的支持和关注,尤其是在我的上一个公众号被关闭后,仍然选择跟随我的老粉丝们,你们的支持是我继续前行的动力。为了回馈大家长期以来的陪伴,我决定分享一些实用的干货,这些都是我亲身实践并且取得成功的…...
Ubuntu20.04 安装jekyll
首先使根据官方文档安装:Jekyll on Ubuntu | Jekyll • Simple, blog-aware, static sites 如果没有报错,就不用再继续看下去了。 我这边在执行gem install jekyll bundler时报错,所以安装了rvm,安装rvm可以参考这篇文章Ubuntu …...

AWK语言
一. awk awk:报告生成器,格式化输出。 在 Linux/UNIX 系统中,awk 是一个功能强大的编辑工具,逐行读取输入文本,默认以空格或tab键作为分隔符作为分隔,并按模式或者条件执行编辑命令。而awk比较倾向于将一行…...

精通Nmap:网络扫描与安全的终极武器
一、引言 Nmap,即NetworkMapper,是一款开源的网络探测和安全审计工具。它能帮助您发现网络中的设备,并识别潜在的安全风险。在这个教程中,我们将一步步引导您如何有效地使用Nmap,让您的网络更加安全。 因为Nmap还有图…...

Java 学习和实践笔记(11)
三大神器: 官方网址: http://www.jetbrains.com/idea/ 官方网址: https://code.visualstudio.com/ 官方网址: http://www.eclipse.org 装好了idea社区版,并试运行以下代码,OK! //TIP To <b>Run</b> code, press &l…...

开发实体类
开发实体类之间先在pom文件中加入该依赖 <!-- 开发实体类--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><scope>provided</scope></dependency>我们在实体类中声明各个属…...

人工智能学习与实训笔记(十五):Scikit-learn库的基础与使用
人工智能专栏文章汇总:人工智能学习专栏文章汇总-CSDN博客 本篇目录 一、介绍 1. 1 Scikit-learn的发展历程及定义 1.2 理解算法包、算法库及算法框架之间的区别和联系 二、Scikit-learn官网结构 三、安装与设置 3.1 Python环境的安装与配置 3.2 Scikit-lea…...

插值与拟合算法介绍
在数据处理和科学计算领域,插值与拟合是两种极为重要的数据分析方法。它们被广泛应用于信号处理、图像处理、机器学习、金融分析等多个领域,对于理解和预测数据趋势具有至关重要的作用。本文将深入浅出地介绍这两种算法的基本原理,并结合C语言编程环境探讨如何在CSDN开发者社…...

下一代Windows系统曝光:基于GPT-4V,Agent跨应用调度,代号UFO
下一代Windows操作系统提前曝光了?? 微软首个为Windows而设的智能体(Agent) 亮相: 基于GPT-4V,一句话就可以在多个应用中无缝切换,完成复杂任务。整个过程无需人为干预,其执行成功…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

基于Java+VUE+MariaDB实现(Web)仿小米商城
仿小米商城 环境安装 nodejs maven JDK11 运行 mvn clean install -DskipTestscd adminmvn spring-boot:runcd ../webmvn spring-boot:runcd ../xiaomi-store-admin-vuenpm installnpm run servecd ../xiaomi-store-vuenpm installnpm run serve 注意:运行前…...

起重机起升机构的安全装置有哪些?
起重机起升机构的安全装置是保障吊装作业安全的关键部件,主要用于防止超载、失控、断绳等危险情况。以下是常见的安全装置及其功能和原理: 一、超载保护装置(核心安全装置) 1. 起重量限制器 功能:实时监测起升载荷&a…...
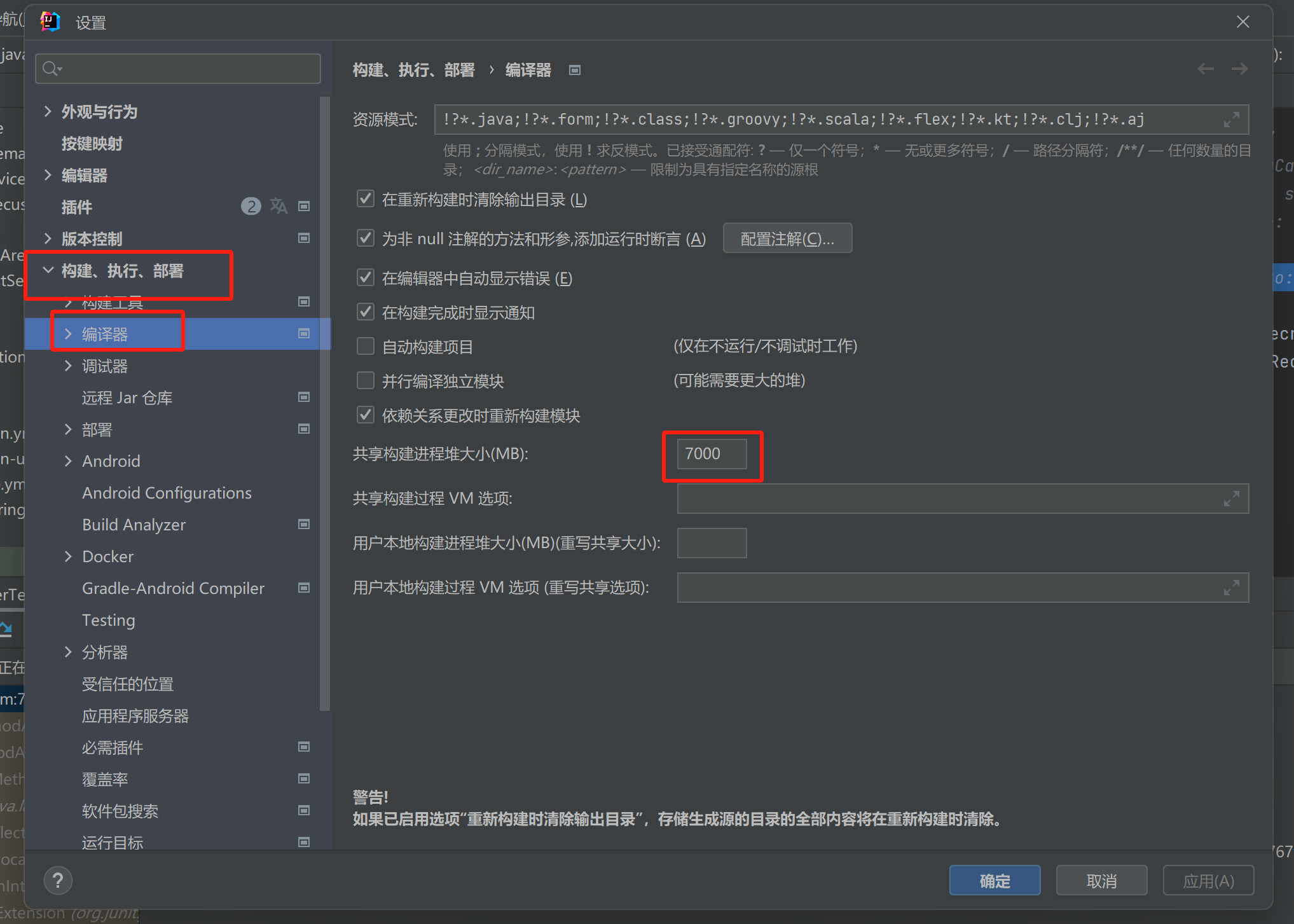
【记录坑点问题】IDEA运行:maven-resources-production:XX: OOM: Java heap space
问题:IDEA出现maven-resources-production:operation-service: java.lang.OutOfMemoryError: Java heap space 解决方案:将编译的堆内存增加一点 位置:设置setting-》构建菜单build-》编译器Complier...

【题解-洛谷】P10480 可达性统计
题目:P10480 可达性统计 题目描述 给定一张 N N N 个点 M M M 条边的有向无环图,分别统计从每个点出发能够到达的点的数量。 输入格式 第一行两个整数 N , M N,M N,M,接下来 M M M 行每行两个整数 x , y x,y x,y,表示从 …...
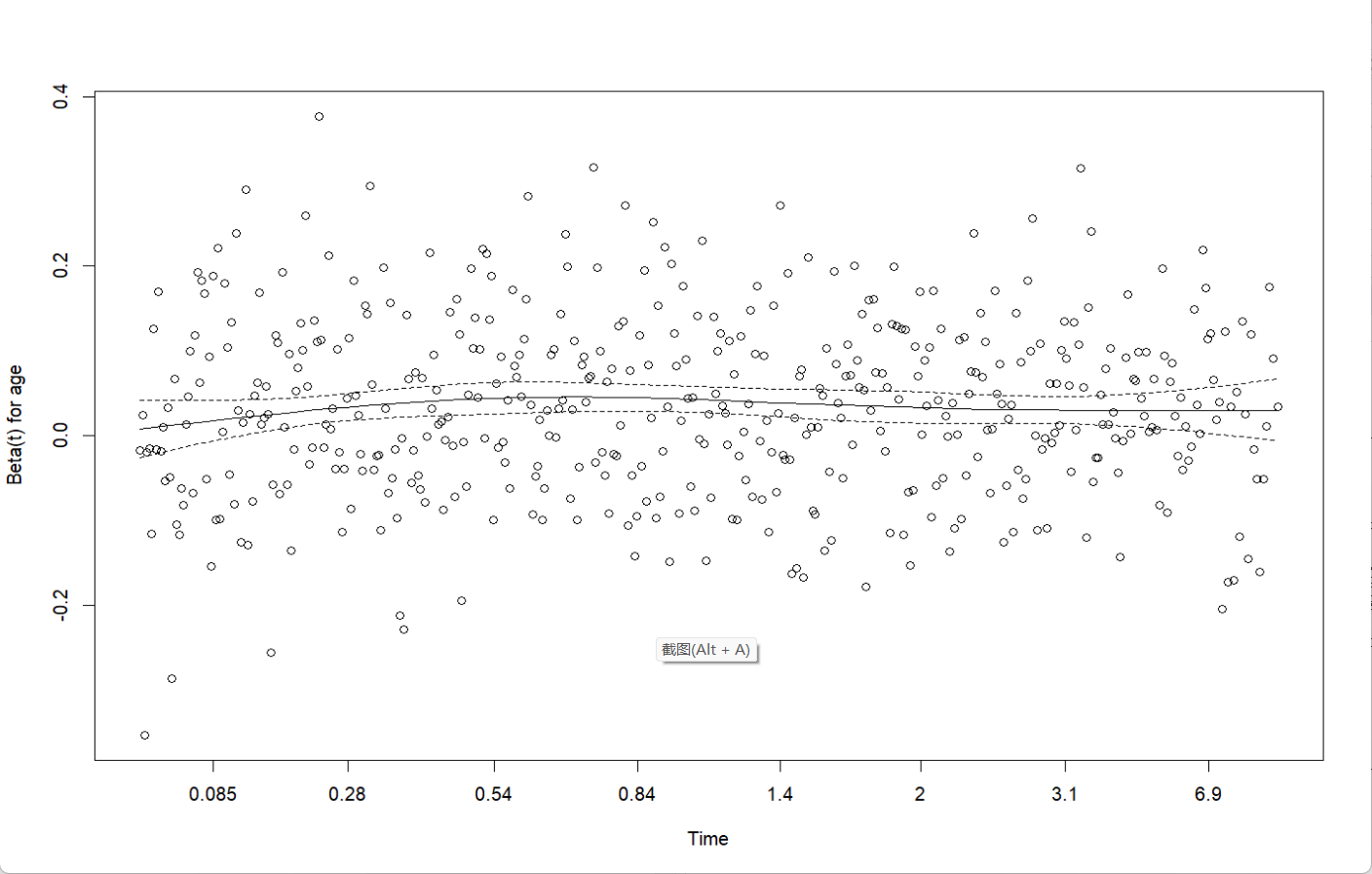
从0开始学习R语言--Day17--Cox回归
Cox回归 在用医疗数据作分析时,最常见的是去预测某类病的患者的死亡率或预测他们的结局。但是我们得到的病人数据,往往会有很多的协变量,即使我们通过计算来减少指标对结果的影响,我们的数据中依然会有很多的协变量,且…...

Angular中Webpack与ngx-build-plus 浅学
Webpack 在 Angular 中的概念 Webpack 是一个模块打包工具,用于将多个模块和资源打包成一个或多个文件。在 Angular 项目中,Webpack 负责将 TypeScript、HTML、CSS 等文件打包成浏览器可以理解的 JavaScript 文件。Angular CLI 默认使用 Webpack 进行项目…...