基于开源模型对文本和音频进行情感分析
应用场景
- 从商品详情页爬取商品评论,对其做舆情分析;
- 电话客服,对音频进行分析,做舆情分析;
通过开发相应的服务接口,进一步工程化;
模型选用
- 文本,选用了通义实验室fine-tune的structBERT 模型,基于大众点评的评论数据进行训练,使用预训练模型进行推理,CPU 能跑,支持模型微调,基本上不用微调了,因为他是基于电商领域的数据集进行训练的,基本够用,可本地部署;
参考论文:
title: Incorporating language structures into pre-training for deep language understanding
author:Wang, Wei and Bi, Bin and Yan, Ming and Wu, Chen and Bao, Zuyi and Xia, Jiangnan and Peng, Liwei and Si, Luo
journal:arXiv preprint arXiv:1908.04577,
year:2019
版本依赖:
modelscope-lib 最新版本
推理代码:
semantic_cls = pipeline(Tasks.text_classification, 'damo/nlp_structbert_sentiment-classification_chinese-base')comment0 = '非常厚实的一包大米,来自遥远的东北,盘锦大米,应该不错的,密封性很好。卖家的服务真是贴心周到!他们提供了专业的建议,帮助我选择了合适的商品。物流速度也很快,让我顺利收到了商品。'
result0 = semantic_cls(input=comment0)
if result0['scores'][0] > result0['scores'][1]:print("'" + comment0 + "',属于" + result0["labels"][0] + "评价")
else:print("'" + comment0 + "',属于" + result0["labels"][1] + "评价")comment1 = '食物的口感还不错,不过店员的服务态度可以进一步改善一下。'
result1 = semantic_cls(input=comment1)
if result1['scores'][0] > result1['scores'][1]:print("'" + comment1 + "',属于" + result1["labels"][0] + "评价")
else:print("'" + comment1 + "',属于" + result1["labels"][1] + "评价")comment2 = '衣服尺码合适,色彩可以再鲜艳一些,客服响应速度一般。'
result2 = semantic_cls(input=comment2)
if result2['scores'][0] > result2['scores'][1]:print("'" + comment2 + "',属于" + result2["labels"][0] + "评价")
else:print("'" + comment2 + "',属于" + result2["labels"][1] + "评价")comment3 = '物流慢,售后不好,货品质量差。'
result3 = semantic_cls(input=comment3)
if result3['scores'][0] > result3['scores'][1]:print("'" + comment3 + "',属于" + result3["labels"][0] + "评价")
else:print("'" + comment3 + "',属于" + result3["labels"][1] + "评价")comment4 = '物流包装顺坏,不过客服处理速度比较快,也给了比较满意的赔偿。'
result4 = semantic_cls(input=comment4)
if result4['scores'][0] > result4['scores'][1]:print("'" + comment4 + "',属于" + result4["labels"][0] + "评价")
else:print("'" + comment4 + "',属于" + result4["labels"][1] + "评价")comment5 = '冰箱制冷噪声较大,制冷慢。'
result5 = semantic_cls(input=comment5)
if result5['scores'][0] > result5['scores'][1]:print("'" + comment5 + "',属于" + result5["labels"][0] + "评价")
else:print("'" + comment5 + "',属于" + result5["labels"][1] + "评价")comment6 = '买了一件刘德华同款鞋,穿在自己脚上不像刘德华,像扫大街的。'
result6 = semantic_cls(input=comment6)
if result6['scores'][0] > result6['scores'][1]:print("'" + comment6 + "',属于" + result6["labels"][0] + "评价")
else:print("'" + comment6 + "',属于" + result6["labels"][1] + "评价")运行结果:
'非常厚实的一包大米,来自遥远的东北,盘锦大米,应该不错的,密封性很好。卖家的服务真是贴心周到!他们提供了专业的建议,帮助我选择了合适的商品。物流速度也很快,让我顺利收到了商品。',属于正面评价
'食物的口感还不错,不过店员的服务态度可以进一步改善一下。',属于正面评价
'衣服尺码合适,色彩可以再鲜艳一些,客服响应速度一般。',属于正面评价
'物流慢,售后不好,货品质量差。',属于负面评价
'物流包装顺坏,不过客服处理速度比较快,也给了比较满意的赔偿。',属于正面评价
'冰箱制冷噪声较大,制冷慢。',属于负面评价
'买了一件刘德华同款鞋,穿在自己脚上不像刘德华,像扫大街的。',属于负面评价
- 音频,选用了通义实验室 fine-tune的emotion2vec微调模型,CPU 能跑,可本地部署;
参考论文:
title: Self-Supervised Pre-Training for Speech Emotion Representation
author:Ma, Ziyang and Zheng, Zhisheng and Ye, Jiaxin and Li, Jinchao and Gao, Zhifu and Zhang, Shiliang and Chen, Xie
journal:arXiv preprint arXiv:2312.15185
year:2023
开源地址:
Official PyTorch code for extracting features and training downstream models with emotion2vec: Self-Supervised Pre-Training for Speech Emotion Representation
版本依赖:
modelscope >= 1.11.1
funasr>=1.0.5
推理代码:
from funasr import AutoModelmodel = AutoModel(model="iic/emotion2vec_base_finetuned", model_revision="v2.0.4")wav_file = f"{model.model_path}/example/test.wav"
res = model.generate(wav_file, output_dir="./outputs", granularity="utterance", extract_embedding=False)
print(res)scores = res[0]["scores"]max_score = 0
max_index = 0
i = 0
for score in scores:if score > max_score:max_score = scoremax_index = ii += 1print("音频分析后,情感基调为:" + res[0]["labels"][max_index])运行结果
rtf_avg: 0.263: 100%|██████████| 1/1 [00:02<00:00, 2.64s/it]
[{'key': 'rand_key_2yW4Acq9GFz6Y', 'labels': ['生气/angry', '厌恶/disgusted', '恐惧/fearful', '开心/happy', '中立/neutral', '其他/other', '难过/sad', '吃惊/surprised', '<unk>'], 'scores': [0.06824027001857758, 0.030794354155659676, 0.20301730930805206, 0.09666425734758377, 0.12219445407390594, 0.06753909587860107, 0.13648174703121185, 0.11873088777065277, 0.1563376784324646]}]
音频分析后,情感为:恐惧/fearfulProcess finished with exit code 0
相关文章:

基于开源模型对文本和音频进行情感分析
应用场景 从商品详情页爬取商品评论,对其做舆情分析;电话客服,对音频进行分析,做舆情分析; 通过开发相应的服务接口,进一步工程化; 模型选用 文本,选用了通义实验室fine-tune的st…...

SQL中为什么不要使用1=1
最近看几个老项目的SQL条件中使用了11,想想自己也曾经这样写过,略有感触,特别拿出来说道说道。 编写SQL语句就像炒菜,每一种调料的使用都可能会影响菜品的最终味道,每一个SQL条件的加入也可能会影响查询的执行效率。那…...

python 几种常见的音频数据读取、保存方式
1. soundfile 库的使用 soundfile库是一个Python库,主要用于读取和写入音频文件。它支持多种音频格式,包括WAV、AIFF、FLAC和OGG等。通过soundfile库,用户可以方便地将numpy数组存储到音频文件或者将音频文件加载到numpy数组中。此外&#x…...

关于msvcr120.dll丢失怎样修复的详细解决步骤方法分享,msvcr120.dll文件的相关内容
在电脑使用过程中,我们经常遇到各种系统错误,其中msvcr120.dll丢失是一个常见问题。msvcr120.dll文件是Visual C Redistributable for Visual Studio 2015/2017的一个组件,主要用于支持某些应用程序的正常运行。当电脑出现msvcr120.dll丢失情…...
简单几步通过DD工具把云服务器系统Linux改为windows
简单几部通过DD安装其他系统,当服务器的web控制台没有我们要装的系统,就需要通过DD(Linux磁盘)工具来更改系统,(已知支持KVM系统) 本文如何简单的更换系统,不通过web控制台来更换&a…...

使用 package.json 配置代理解决 React 项目中的跨域请求问题
使用 package.json 配置代理解决 React 项目中的跨域请求问题 当我们在开发前端应用时,经常会遇到跨域请求的问题。为了解决这个问题,我们可以通过配置代理来实现在开发环境中向后端服务器发送请求。 在 React 项目中,我们可以使用 package…...

生成 Let‘s Encrypt 免费证书
文章目录 1. 安装 acme.sh2. 添加云服务商安全访问密钥并授权管理DNS记录3. 当前 Shell 添加安全访问密钥变量4. 生成证书5. 拷贝证书6. 清理安全访问密钥变量7. 打开脚本自动更新 代码仓库地址:https://github.com/Neilpang/acme.sh 1. 安装 acme.sh yum -y insta…...
)
int128的实现(基本完成)
虽然有一个声明叫_int128但是这并不是C标准: long long 不够用?详解 __int128 - FReQuenter - 博客园 (cnblogs.com) 网络上去找int128的另类实现方法,发现几乎都是在介绍_int128的 然后我就自己想了个办法,当时还没学C…...

【linux】使用 acme.sh 实现了 acme 协议生成免费的SSL 证书
acme.sh 实现了 acme 协议, 可以从 letsencrypt 生成免费的证书. 主要步骤: 安装 acme.sh生成证书copy 证书到 nginx/apache 或者其他服务更新证书更新 acme.sh出错怎么办, 如何调试 下面详细介绍. 1. 安装 acme.sh 安装很简单, 一个命令: curl https://get.acme.sh | sh…...

MACOS上面C/C++获取网卡索引,索引获取网卡接口名
依赖函数: if_nametoindex IF名字 to IF索引 if_indextoname IF索引 to IF名字 MACOS 10.7 版本支援(就是2011年发不OSX的第一个面向用的系统版本) int GetInterfaceIndex(const ppp::string& ifrName) noexcept{if (ifrName.empt…...

解决SSH远程登录开饭板出现密码错误问题
输入“adduser Zhanggong回车”,使用adduser命令创建开发板用户名为Zhanggong 输入密码“123456” 输入密码“123456”...

什么时候用ref和reactive
在Vue 3中,ref和reactive都是用于创建响应式数据的工具,但它们的使用场景有所不同。 使用ref的情况: 基本数据类型:当你需要响应式地处理基本数据类型(如数字、字符串、布尔值)时,应该使用ref…...

Java实战:Spring Boot实现邮件发送服务
本文将详细介绍如何在Spring Boot应用程序中实现邮件发送服务。我们将探讨Spring Boot集成邮件发送服务的基本概念,以及如何使用Spring Boot和第三方邮件服务提供商来实现邮件发送。此外,我们将通过具体的示例来展示如何在Spring Boot中配置和使用邮件发…...

重磅!MongoDB推出Atlas Stream Processing公共预览版
日前,MongoDB宣布推出Atlas Stream Processing公共预览版。 在Atlas平台上有兴趣尝试这项功能的开发者都享有完全的访问权限,可前往“阅读原文”链接点击了解更多详细信息或立即开始使用。 开发者喜欢文档型数据库的灵活性、易用性以及Query API查询方…...
dell戴尔电脑灵越系列Inspiron 15 3520原厂Win11系统中文版/英文版
Dell戴尔笔记本灵越3520原装出厂Windows11系统包,恢复出厂开箱预装OEM系统 链接:https://pan.baidu.com/s/1mMOAnvXz5NCDO_KImHR5gQ?pwd3nvw 提取码:3nvw 原厂系统自带所有驱动、出厂主题壁纸、系统属性联机支持标志、Office办公软件、MyD…...
k8s(3)
目录 一.K8S的三种网络 flannel的三种模式: 在 node01 节点上操作: calico的 三种模式: flannel 与 calico 的区别? 二.CoreDNS 在所有 node 节点上操作: 在 master01 节点上操作: 编辑 DNS 解析测试&#…...
Java多线程并发学习
一、Java 中用到的线程调度 1. 抢占式调度: 抢占式调度指的是每条线程执行的时间、线程的切换都由系统控制,系统控制指的是在系统某种运行机制下,可能每条线程都分同样的执行时间片,也可能是某些线程执行的时间片较长࿰…...

Curfew e-Pass 管理系统存在Sql注入漏洞 附源代码
免责声明:本文所涉及的信息安全技术知识仅供参考和学习之用,并不构成任何明示或暗示的保证。读者在使用本文提供的信息时,应自行判断其适用性,并承担由此产生的一切风险和责任。本文作者对于读者基于本文内容所做出的任何行为或决…...

记阿里云mysql丢表丢数据的实践记录
第一时间挂工单,联系工程师指引,现在回过来想,第一时间要确认发生时间。 1.通过性能视图(马后炮的总结,实际凭记忆恢复了三四次才找到数据) 2.先恢复数据 通过Navicat工具,结构同步࿰…...

自然语言转SQL的应用场景探索
自然语言转SQL的应用场景探索 1. 自然语言转sql有哪些解决方案2. 自然语言转sql有哪些应用场景3. 自然语言转sql在智能制造领域有哪些应用场景 1. 自然语言转sql有哪些解决方案 自然语言转SQL(NL2SQL)是一个涉及自然语言处理(NLP)…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...
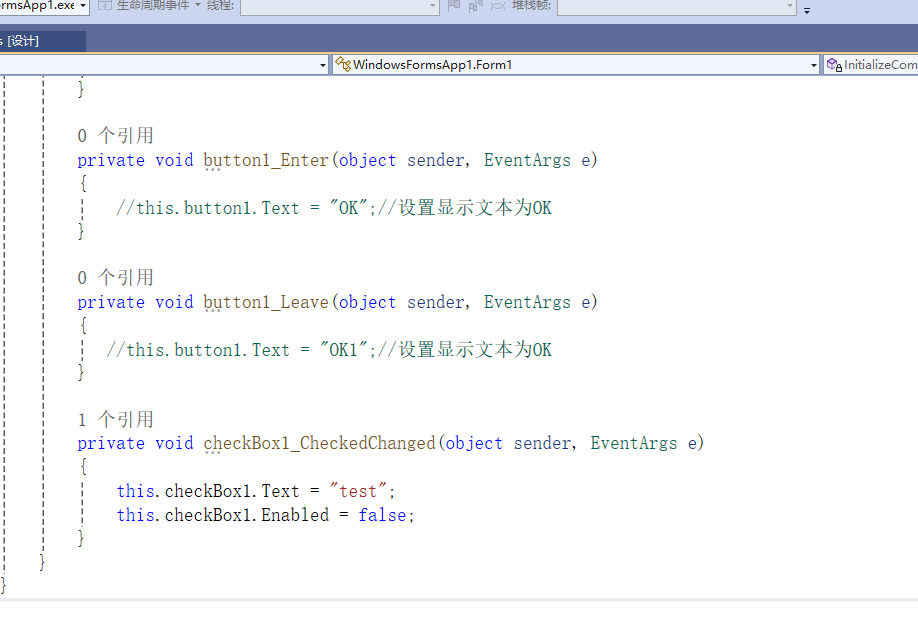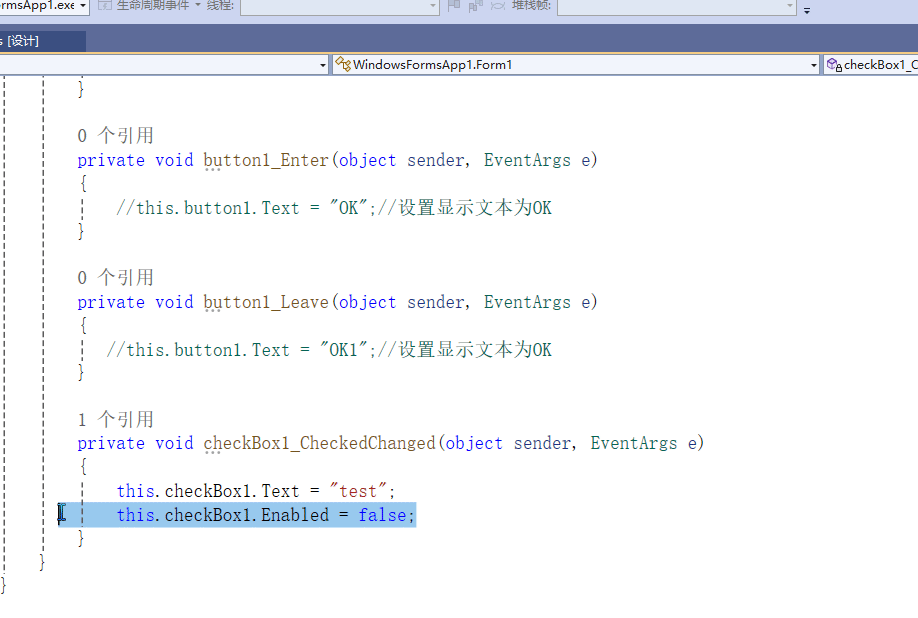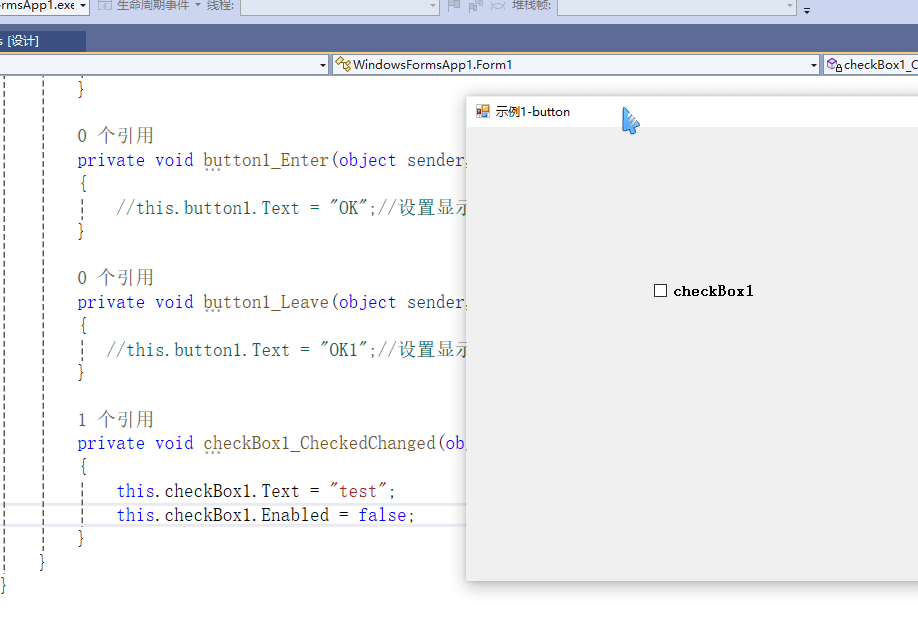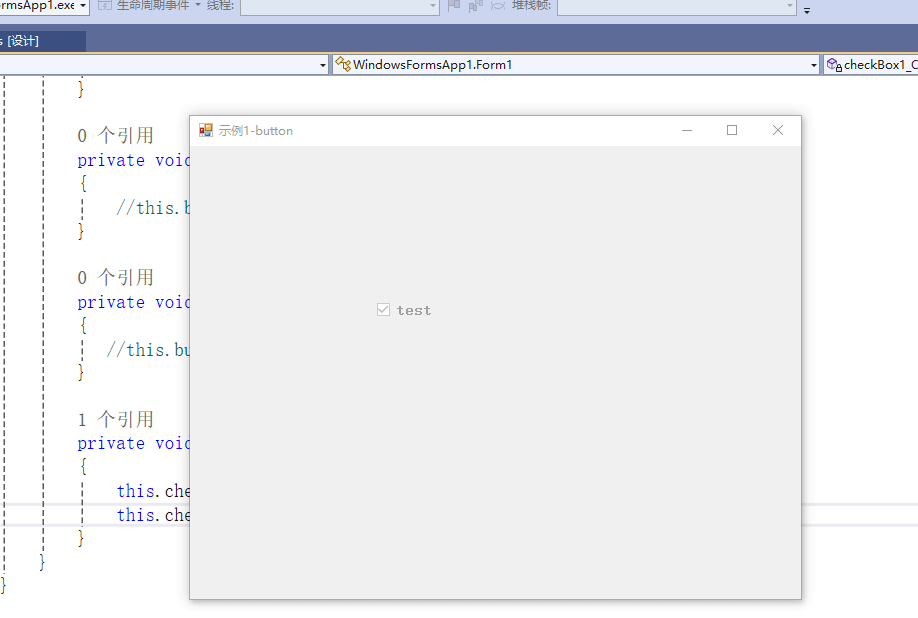
C# winform教程(二)----checkbox
一、作用 提供一个用户选择或者不选的状态,这是一个可以多选的控件。 二、属性 其实功能大差不差,除了特殊的几个外,与button基本相同,所有说几个独有的 checkbox属性 名称内容含义appearance控件外观可以变成按钮形状checkali…...

手动给中文分词和 直接用神经网络RNN做有什么区别
手动分词和基于神经网络(如 RNN)的自动分词在原理、实现方式和效果上有显著差异,以下是核心对比: 1. 实现原理对比 对比维度手动分词(规则 / 词典驱动)神经网络 RNN 分词(数据驱动)…...
设计模式-3 行为型模式
一、观察者模式 1、定义 定义对象之间的一对多的依赖关系,这样当一个对象改变状态时,它的所有依赖项都会自动得到通知和更新。 描述复杂的流程控制 描述多个类或者对象之间怎样互相协作共同完成单个对象都无法单独度完成的任务 它涉及算法与对象间职责…...