ES相关问题
在Elasticsearch(ES)集群中,节点根据其配置和角色可以分为以下几种主要类型:
-
Master Node(主节点): 主节点负责管理整个集群的元数据,如索引的创建、删除、分片分配等。它维护着集群的状态,并处理集群级别的变更操作。为了确保高可用性,通常会设置多个候选主节点,通过选举机制确定一个主节点,而其他候选节点则处于待命状态,当当前主节点不可用时进行接管。
-
Data Node(数据节点): 数据节点是存储实际数据的地方,它们负责执行索引和搜索操作。数据节点持有分片(shards),并参与文档的CRUD(创建、读取、更新、删除)操作以及搜索请求的执行。
-
Ingest Node(摄取节点): 摄取节点是一种特殊的节点,用于处理进入Elasticsearch前的数据预处理工作。它可以包含一系列的处理器管道,对数据进行清洗、转换、过滤等操作。
-
Coordinating Node(协调节点): 所有节点都可以充当协调节点的角色,不过通常客户端请求首先到达的是非数据节点或专门配置为仅承担此角色的节点。协调节点负责将客户端请求路由到适当的节点进行处理,并聚合返回结果。
-
Machine Learning Node(机器学习节点): 在Elasticsearch的X-Pack插件或更高级版本中,提供了机器学习功能。机器学习节点专用于运行复杂的分析任务,例如异常检测、预测分析等。
每个节点可以根据配置文件中的node.master、node.data等属性来定义其是否能够成为主节点、数据节点或两者皆可。通常建议集群设计时应考虑主节点与数据节点分离以提高系统稳定性和性能。此外,用户可以根据集群规模和需求调整不同类型的节点数量和配置,以实现最优的资源分配和负载均衡。
在Elasticsearch(简称ES)中,协调节点(Coordinator Node)是处理客户端请求的关键角色。当一个客户端向集群发送搜索、索引、更新或删除请求时,它可以将请求发送到任何集群中的节点。这个接收到请求的节点就充当了协调器的角色。
协调节点的主要职责包括:
-
路由请求:根据文档的索引和分片信息决定哪些数据节点包含请求所需的数据,并将请求转发给相应的主或者副本分片所在的节点。
-
聚合响应:从各个数据节点收集查询结果,并合并这些结果,执行排序、聚合等操作,最终返回给客户端一个完整的响应。
-
负载均衡:在多个数据节点之间平衡请求负载,确保集群资源的有效利用。
-
错误处理:如果某个数据节点在处理请求时发生故障,协调节点会负责重新路由请求至其他可用的数据节点。
Elasticsearch(ES)最初是作为全文搜索引擎和分析引擎而设计的,主要用于处理结构化、半结构化和非结构化的文本数据。然而,在近年来的发展中,Elasticsearch 增加了对向量存储与搜索的支持,使其也能够作为向量数据库使用。
向量数据库是一种特殊类型的数据库系统,专门用于存储、索引和检索高维向量数据,这些数据在诸如计算机视觉、自然语言处理、推荐系统等领域的机器学习应用中非常常见。例如,深度学习模型产生的特征向量可以用来表示图像、文本或用户兴趣等信息。
具体到 Elasticsearch 的向量功能:
-
向量字段类型:Elasticsearch 中引入了
dense_vector字段类型,允许用户存储固定长度的浮点数数组,即向量数据。 -
相似性搜索:支持基于向量距离度量(如余弦相似度)进行高效的相似性搜索,能够在大规模数据集上快速找到与查询向量最相似的记录。
-
近实时:保持了其近实时搜索的特点,这意味着向量数据一旦被索引,几乎可以立即用于查询。
-
可扩展性:得益于 Elasticsearch 的分布式架构,它可以轻松处理 PB 级别的向量数据,并且随着集群规模的增长,可以水平扩展以应对更大的数据量和更复杂的查询负载。
-
聚合与分析:除了基本的相似性搜索外,还可以结合其他 Elasticsearch 功能,实现对向量数据的复杂分析和可视化。
-
集成:与 Elastic Stack 的其余组件(如 Kibana 和 Logstash)紧密集成,为用户提供了一个端到端的解决方案,包括数据摄取、分析和展示。
因此,尽管 Elasticsearch 不是传统意义上的纯向量数据库,但它通过增强对向量数据的支持,已经在很多场景下扮演了向量数据库的角色,并且在AI和ML领域具有重要的实用价值。
Elasticsearch(ES)和Milvus是两种不同类型的数据库系统,它们的设计目标、主要用途以及数据模型存在显著差异。
Elasticsearch:
- 类型与用途:Elasticsearch 是一个分布式全文搜索引擎,基于Apache Lucene库构建,适用于文档型数据的搜索、分析和存储。它支持结构化、半结构化文本数据,并且在近年来也扩展了对向量数据的支持。
- 数据模型:Elasticsearch 的数据组织形式为索引(Index)下的文档(Document),每个文档由一系列字段组成,可以包含文本、数字、布尔值等多种类型的数据,包括新增的
dense_vector字段用于向量数据。 - 查询方式:擅长全文检索、模糊匹配、聚合分析等复杂查询,通过JSON格式的DSL(Domain Specific Language)进行查询。
- 实时性:具有近实时搜索能力,索引更新后几乎立即可见。
- 可扩展性:高度可扩展,适合大数据量场景下的横向扩展。
- 一致性保证:对于复杂的ACID事务支持较弱,更适合最终一致性场景。
Milvus:
- 类型与用途:Milvus 是一款专为人工智能应用设计的开源向量数据库,主要用于处理大规模的非结构化向量数据,如图像特征、语音特征、文本语义表示等。
- 数据模型:Milvus 主要存储和检索高维向量数据,它的核心在于高效的相似性搜索功能,即根据向量之间的距离度量来查找相似项。
- 查询方式:特别关注点/向量相似度搜索,提供了针对向量数据的精确或模糊查询机制,如基于余弦相似度的近邻搜索(Approximate Nearest Neighbor Search, ANNS)。
- 实时性与效率:Milvus 优化了海量向量数据的插入、查询性能,尤其是在实时流式处理和离线批处理方面做了很多工作以提高效率。
- 可扩展性:同样具备良好的水平扩展能力,支持在多节点集群中进行高效的大规模向量检索。
- 一致性保证:由于其专注于向量检索而非传统数据库事务,因此在一致性模型上侧重于满足特定应用场景需求,例如确保向量索引的最终一致性。
总结来说:
- 如果您的主要任务是对文本、日志或其他结构化/半结构化数据执行全文搜索、数据分析和报表生成,Elasticsearch 将是一个很好的选择。
- 而当您需要处理大量机器学习产生的向量数据,例如做图像识别、推荐系统中的用户兴趣相似度匹配时,Milvus 的专业向量搜索能力和高性能特点使其成为理想的选择。两者可以根据实际业务需求互补使用或者单独部署。
在预处理阶段生成或训练词向量的主要方法有以下几种:
-
Word2Vec:
- CBOW(Continuous Bag-of-Words):通过当前单词周围的上下文单词来预测目标单词,从而得到每个单词的向量表示。
- Skip-gram:给定一个中心词,模型试图预测其周围的上下文词。这种方法可以较好地捕捉到词与词之间的共现关系。
-
GloVe (Global Vectors for Word Representation):
- GloVe基于全局统计信息(如词频和共现矩阵),通过优化目标函数直接学习词向量,使得向量的内积近似于词语的共生概率。
-
FastText:
- FastText在Word2Vec的基础上加入了字符n-gram特征,能更好地处理罕见词汇,并且对词形变化具有较好的泛化能力。
-
神经网络语言模型(NNLMs):
- 早期的神经网络语言模型如LSTM、GRU等可以用来预测句子中下一个词的概率,在此过程中,隐藏层的状态通常被用作词嵌入。
-
Transformer-based Models:
- BERT (Bidirectional Encoder Representations from Transformers):通过遮蔽语言模型(MLM)和下一句预测任务进行预训练,从而为每个词生成上下文相关的向量表示。
- ELMo (Embeddings from Language Models):也采用双向语言模型,但输出的是不同层次LSTM状态的加权和,得到动态的词向量。
-
Sentence Encoders:
- 不仅考虑单个词,还考虑整个句子的编码器,例如
Universal Sentence Encoder和BERT-as-service可以直接提供整个句子的向量表示。
- 不仅考虑单个词,还考虑整个句子的编码器,例如
-
预训练语言模型的转换(Fine-tuning):
- 使用预先在大规模无标注文本上训练好的模型(如BERT、RoBERTa、GPT系列等),针对特定NLP任务进行微调时,也可以提取出高质量的词向量。
每种方法都有其特点和适用场景,选择哪种方法取决于应用场景的需求以及资源限制。通常情况下,这些预训练模型能够在大量的未标注文本数据上学习到丰富的语言结构和语义信息,因此所得到的词向量在许多自然语言处理任务中表现优秀。
当然,目前有很多开源服务和工具可以用来生成或训练词向量。以下是一些流行的开源库和服务:
-
Gensim:
- Gensim是一个非常流行的Python库,它包含了多种用于生成词向量的方法,包括Word2Vec、FastText等模型的实现。
-
TensorFlow / TensorFlow Hub:
- TensorFlow是Google开发的一个广泛使用的机器学习框架,其中包含了预训练模型如BERT和Universal Sentence Encoder(USE),以及用于训练自定义词嵌入模型的功能。
- TensorFlow Hub则提供了许多预训练的词向量和句子嵌入模块,可以直接下载并集成到项目中。
-
PyTorch / Hugging Face Transformers:
- PyTorch是另一个深度学习框架,Hugging Face的Transformers库提供了基于Transformer架构的大量预训练模型,比如BERT、RoBERTa、DistilBERT等,并且支持加载和微调这些模型以获取词向量。
-
fastText:
- Facebook开源的fastText工具包可以轻松地训练词向量和文本分类器,尤其适合处理大规模数据集和多语言场景。
-
Spacy:
- Spacy是一个自然语言处理库,其中也包含了一些预训练的词向量模型,并且允许用户通过其接口方便地使用和扩展。
-
Apache MXNet 和 ONNX:
- 这些框架同样支持词向量相关的操作,并可能提供或链接到预训练模型资源。
-
DeepPavlov:
- 一个面向对话系统的开源库,也包含了训练词向量和其他NLP任务所需的功能。
这些开源服务通常都提供了详细的文档和API,使得开发者可以根据自己的需求选择合适的模型,并在本地进行训练或者直接应用已有的预训练模型来生成词向量。
当然,目前有很多开源服务和工具可以用来生成或训练词向量。以下是一些流行的开源库和服务:
-
Gensim:
- Gensim是一个非常流行的Python库,它包含了多种用于生成词向量的方法,包括Word2Vec、FastText等模型的实现。
-
TensorFlow / TensorFlow Hub:
- TensorFlow是Google开发的一个广泛使用的机器学习框架,其中包含了预训练模型如BERT和Universal Sentence Encoder(USE),以及用于训练自定义词嵌入模型的功能。
- TensorFlow Hub则提供了许多预训练的词向量和句子嵌入模块,可以直接下载并集成到项目中。
-
PyTorch / Hugging Face Transformers:
- PyTorch是另一个深度学习框架,Hugging Face的Transformers库提供了基于Transformer架构的大量预训练模型,比如BERT、RoBERTa、DistilBERT等,并且支持加载和微调这些模型以获取词向量。
-
fastText:
- Facebook开源的fastText工具包可以轻松地训练词向量和文本分类器,尤其适合处理大规模数据集和多语言场景。
-
Spacy:
- Spacy是一个自然语言处理库,其中也包含了一些预训练的词向量模型,并且允许用户通过其接口方便地使用和扩展。
-
Apache MXNet 和 ONNX:
- 这些框架同样支持词向量相关的操作,并可能提供或链接到预训练模型资源。
-
DeepPavlov:
- 一个面向对话系统的开源库,也包含了训练词向量和其他NLP任务所需的功能。
这些开源服务通常都提供了详细的文档和API,使得开发者可以根据自己的需求选择合适的模型,并在本地进行训练或者直接应用已有的预训练模型来生成词向量。
Milvus 与 ElasticSearch 有什么区别?这是我们经常被问到的问题。
两者都是面向非结构化数据做分析,ES 这边更多是作用在 文本这个点上,也是文本搜索的事实标准;Milvus 则作用在 embedding这个数据基础上,提供的是一种泛化的搜索能力,并不会像 ES 这样面向一种具体的非结构化数据。
整体上来看,其实整个分析和搜索的机制,ES 和 Milvus 还是有很大的相似性的,基本上大家都做同样的一件事情——把非结构化数据映射到一个空间里面,在空间里面做语义的相似度分析。像 ES 文本和查询条件通过 TF-IDF 这样一个统计量去放到子向量空间里面去做分析;Milvus 则是更多是把多样化的非结构化数据去经过一些神经网络作为 Encoder,映射到 embedding 空间里面去做分析。
参考:【2021 ECUG Con 干货分享】郭人通:Milvus:探索云原生的向量搜索引擎_数据 (sohu.com)
相关文章:

ES相关问题
在Elasticsearch(ES)集群中,节点根据其配置和角色可以分为以下几种主要类型: Master Node(主节点): 主节点负责管理整个集群的元数据,如索引的创建、删除、分片分配等。它维护着集群…...

基于Linux直接安装的Nginx版本升级方法
引言 随着版本的迭代和漏洞的发现,Nginx作为一款软件避免不了打补丁的命运。 以下基于Linux直接安装的Nginx版本升级。 以下操作均在本地虚拟机中操作验证,请验证后再线上操作。基于centos7测试。 前置资源 获取nginx的最新源码版本网址:…...

探索设计模式的魅力:状态模式揭秘-如何优雅地处理复杂状态转换
🌈 个人主页:danci_ 🔥 系列专栏:《设计模式》 💪🏻 制定明确可量化的目标,并且坚持默默的做事。 探索设计模式的魅力:状态模式揭秘-如何优雅地处理复杂状态转换 文章目录 一、案例…...
)
力扣hot100题解(python版10-12题)
哎- -最近本来就没时间写算法 这算法怎么还这么难。。。 10、和为 K 的子数组 给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。 子数组是数组中元素的连续非空序列。 示例 1: 输入:nums [1,1,1]…...

【算法】复杂度分析
第一章、如何分析代码的执行效率和资源消耗 我们知道,数据结构和算法解决的是“快”和“省”的问题,也就是如何让代码运行得更快,一级如何让代码更节省计算机的存储空间。因此,执行效率是评价算法好坏的一个非常重要的指标。那么&…...

车载电子测试学习内容
搜集了一些车载测试的学习内容,大家可以参考。...
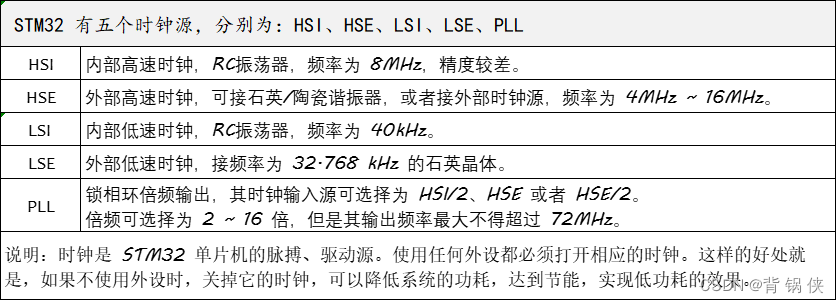
STM32F103x 的时钟源
AHB (Advanced High-performance Bus) 高速总线,用来接高速外设的。 APB (Advanced Peripheral Bus) 低速总线,用来接低速外设的,包含APB1 和 APB2。 APB1:上面连接的是低速外设,包括电源接口、备份接口、 CAN 、 US…...
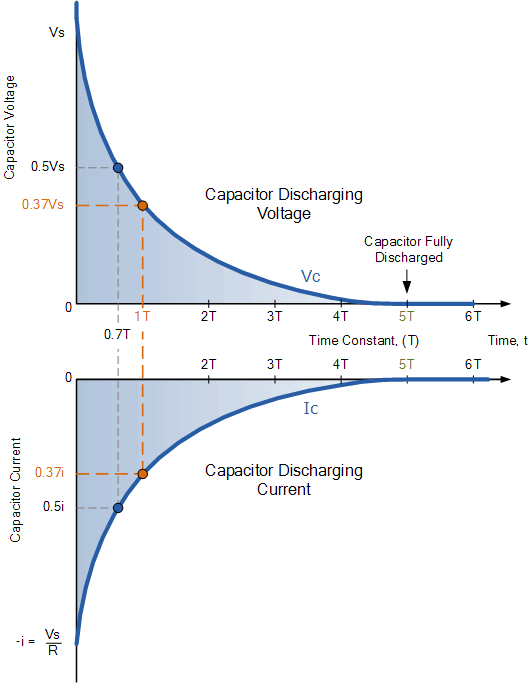
【电路笔记】-RC放电电路
RC放电电路 文章目录 RC放电电路1、概述2、RC放电电路3、RC放电电路示例当电压源从完全充电的 RC 电路中移除时,电容器 C 将通过电阻 R 放电。 1、概述 RC 放电电路利用电阻器-电容器组合的固有 RC 时间常数以指数衰减率对电容器进行放电。 在之前的 RC 充电电路教程中,我们…...

【C++STL】STL容器详解
创作不易,本篇文章如果帮助到了你,还请点赞 关注支持一下♡>𖥦<)!! 主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步! 🔥c系列专栏:C/C零基础到精通 🔥 给大…...
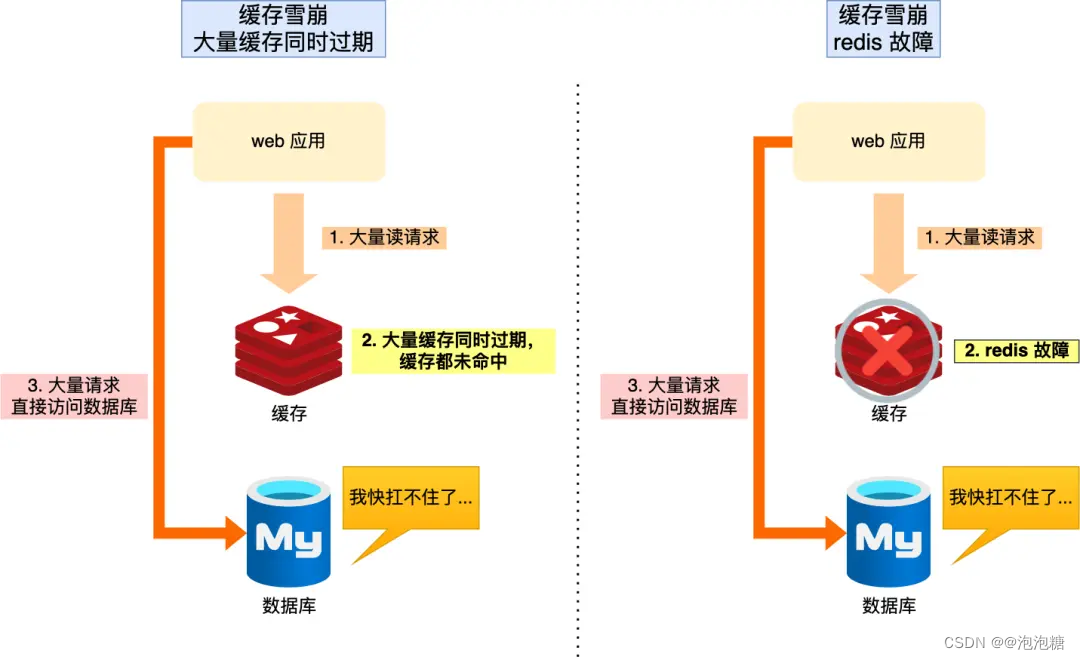
缓存篇—缓存雪崩
什么是缓存雪崩 通常我们为了保证缓存中的数据与数据库中的数据一致性,会给 Redis 里的数据设置过期时间,当缓存数据过期后,用户访问的数据如果不在缓存里,业务系统需要重新生成缓存,因此就会访问数据库,并…...
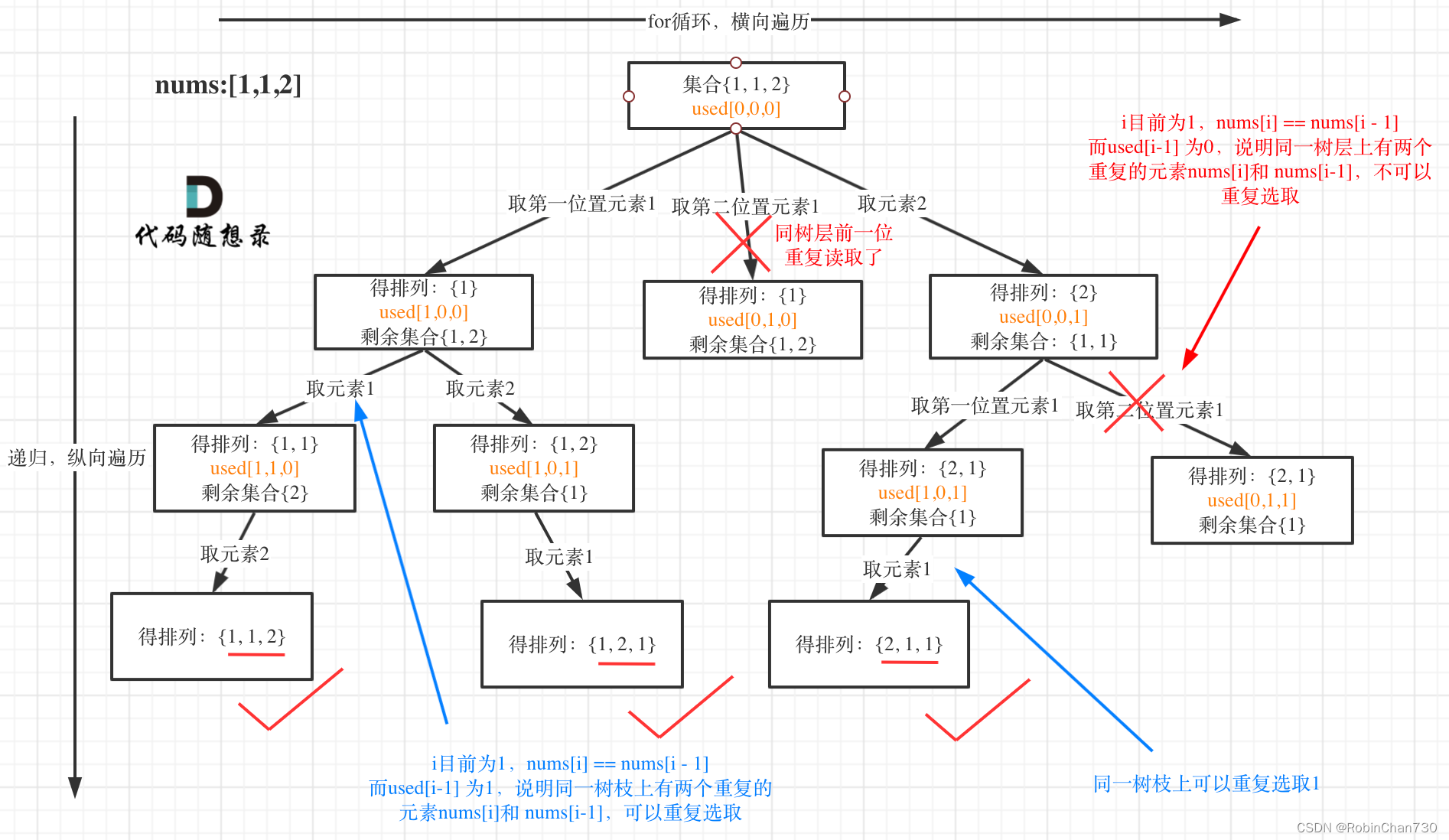
力扣日记2.22-【回溯算法篇】47. 全排列 II
力扣日记:【回溯算法篇】47. 全排列 II 日期:2023.2.22 参考:代码随想录、力扣 47. 全排列 II 题目描述 难度:中等 给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。 示例 1: 输…...

如何理解三大微分中值定理
文章看原文,自己写的只是备份 高等数学强化2:一元函数微分学 中值定理 极值点 拐点_一元函数中值定理-CSDN博客 高等数学强化3:一元函数积分学 P积分-CSDN博客 高等数学强化3:定积分几何应用-CSDN博客...
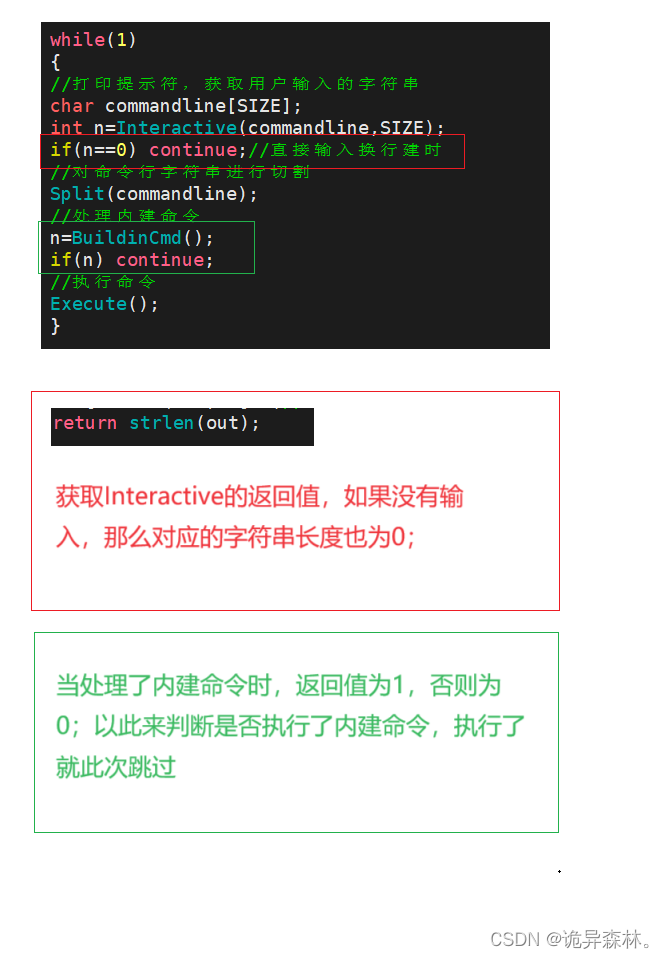
Linux--自定义shell
shell shell就是操作系统提供给用户与操作系统进行交互的命令行界面。它可以理解为一个用户与操作系统之间的接口,用户可以通过输入命令来执行各种操作,如文件管理、进程控制、软件安装等。Shell还可以通过脚本编程实现自动化任务。 常见的Unix系统中使…...

AIGC 实战:Ollama 和 Hugging Face 是什么关系?
Ollama和 Hugging Face 之间存在着双重关系: 1. Ollama是 Hugging Face 开发并托管的工具: Ollama是一个由 Hugging Face 自行开发的开源项目。它主要用于在本地运行大型语言模型 (LLM),特别是存储在 GPT 生成的统一格式 (GPT-Generated Un…...
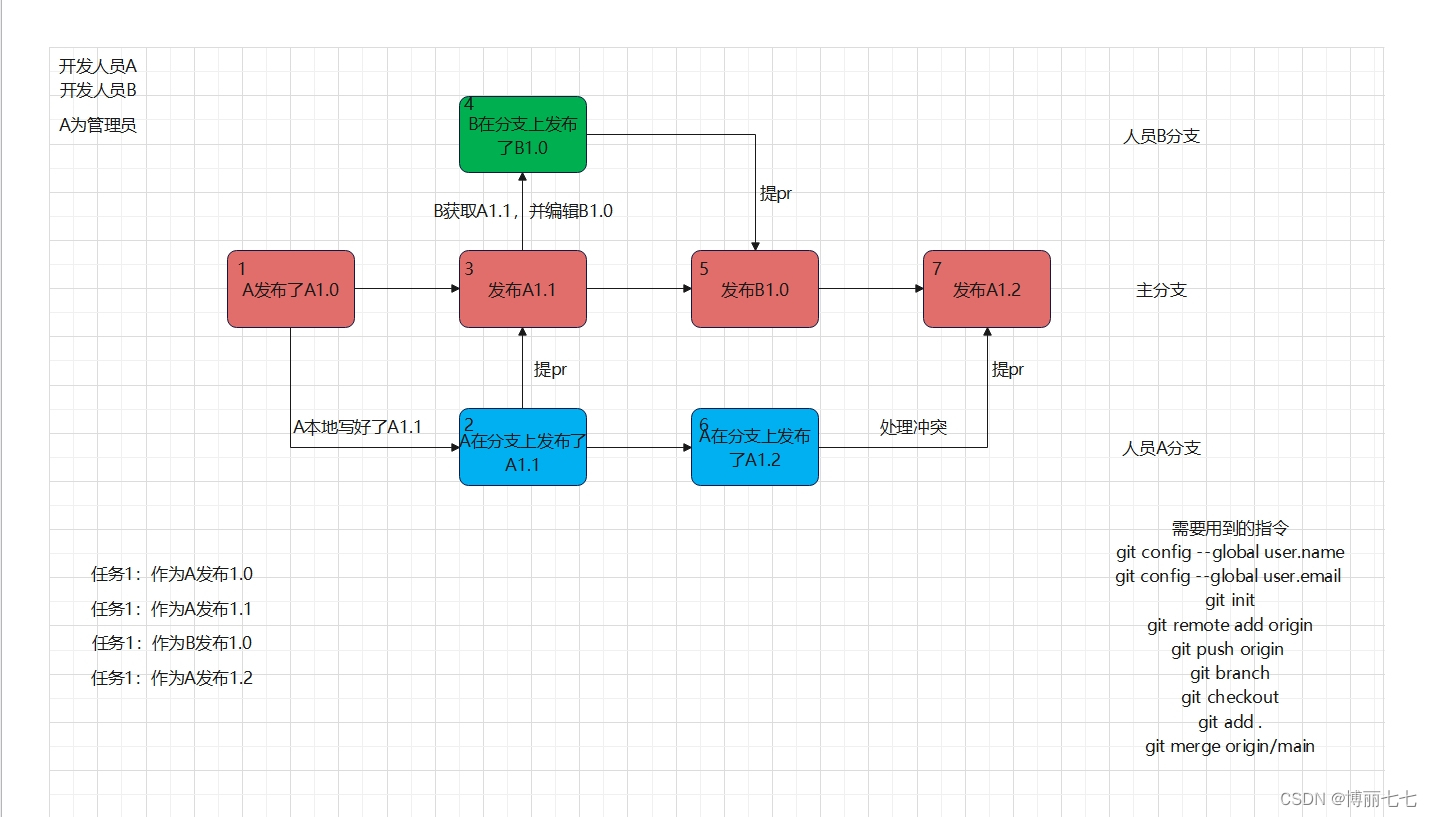
Gitee教程2(完整流程)
1.配置git git config --global user.name "用户名" git config --global user.email "密码" 如何获取? gitee右上角加号点击新建仓库,仓库名随便起一个就行 找到这条命令,把这两句一个一个复制到vscode终端就行 2.创建g…...

Go 1.22 中的 for 循环新特性详解
目录 每次迭代都创建新变量 支持整数类型循环 小结 在 Go 语言中,for 循环是实现迭代的主要方式。Go 中的 for 循环非常灵活,有多种使用方式,包括传统的三部分 for 循环、类似于其他语言中的 while 循环以及迭代集合的 range 循环。 在 1…...
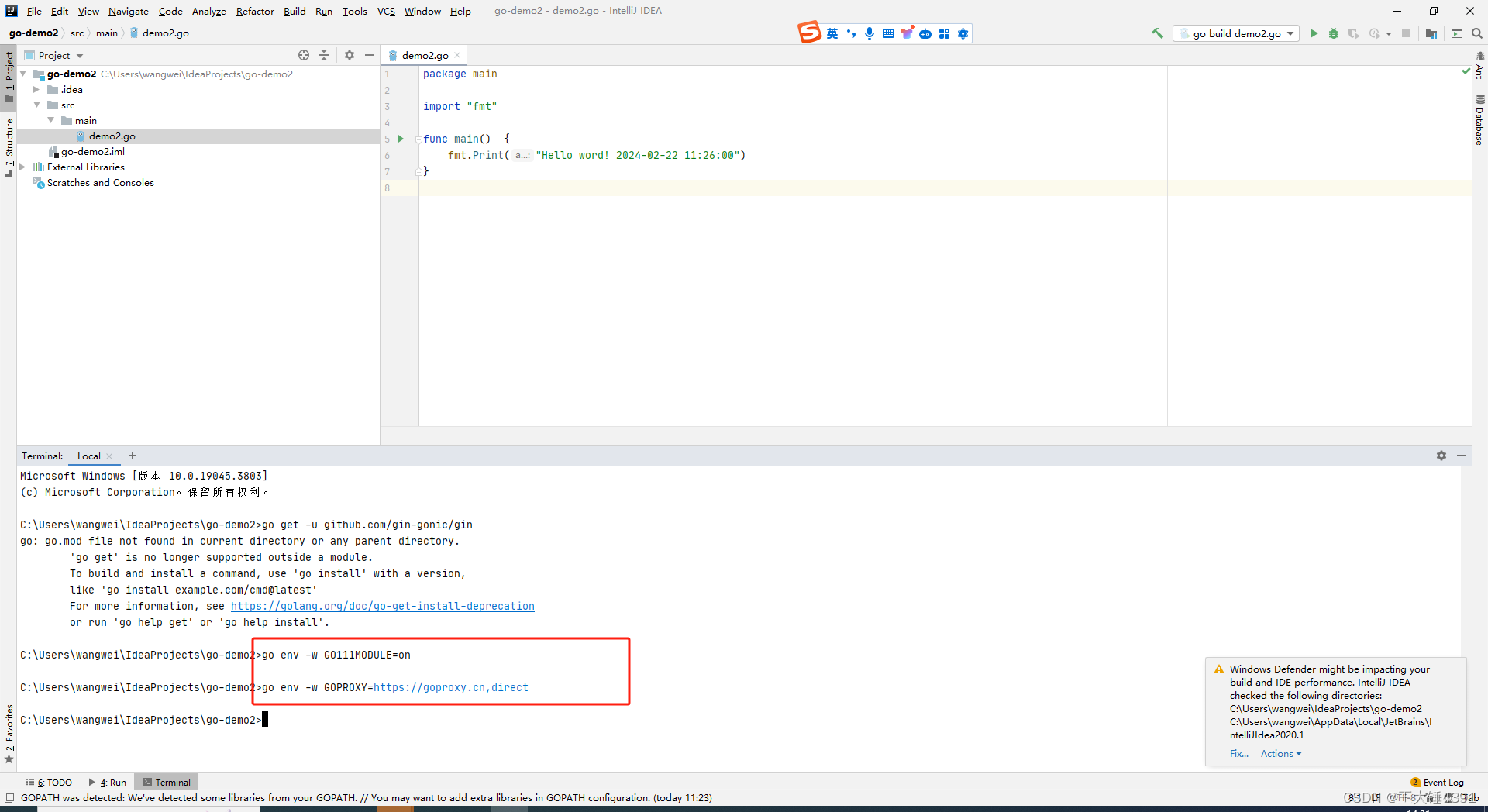
igolang学习2,golang开发配置国内镜像
go env -w GO111MODULEon go env -w GOPROXYhttps://goproxy.cn,direct...
R语言空间分析、模拟预测与可视化
随着地理信息系统(GIS)和大尺度研究的发展,空间数据的管理、统计与制图变得越来越重要。R语言在数据分析、挖掘和可视化中发挥着重要的作用,其中在空间分析方面扮演着重要角色,与空间相关的包的数量也达到130多个。在本…...

体育赛事直播系统软件开发
体育赛事直播系统的软件开发是一个复杂的项目,需要多个方面的准备和工作。以下是开发这样一个系统可能涉及的主要步骤和考虑因素: 需求分析和规划:首先需要明确系统的功能需求,包括直播视频的流媒体处理、用户管理、直播赛事安排…...

使用 kind 集群安装运行极狐GitLab Runner【上】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 关于 kind kind 是一个用来运行本地 Kubernetes 机群的工具&a…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...

【学习笔记】erase 删除顺序迭代器后迭代器失效的解决方案
目录 使用 erase 返回值继续迭代使用索引进行遍历 我们知道类似 vector 的顺序迭代器被删除后,迭代器会失效,因为顺序迭代器在内存中是连续存储的,元素删除后,后续元素会前移。 但一些场景中,我们又需要在执行删除操作…...