week04day03(爬虫 beautifulsoup4、)
一. 使用bs4解析网页
'''
下载bs4 - pip install beautifulsoup4
使用的时候 import bs4专门用于解析网页的第三方库
在使用bs4的时候往往会依赖另一个库lxml
pip install lxml
'''
网页代码
<!DOCTYPE html>
<html><head><meta charset="utf-8"><title>Title</title></head><body><h2>电影大全</h2><div id="box1"><div class="item"><p>肖生克的救赎</p><span>评分:</span><span class="score">9.7</span></div><div class="item"><p>霸王别姬</p><span>评分:</span><span class="score">9.6</span></div><div class="item"><p>阿甘正传</p><span>评分:</span><span class="score">9.5</span></div><img src="https://img9.doubanio.com/view/photo/s_ratio_poster/public/p457760035.webp" class=""><div id="box2"><div><p>我是段落1</p></div></div></div></body>
</html>
对以上代码进行操作:
from bs4 import BeautifulSoup
# bs4 用法
# 1.准备需要解析的数据
html = open('for_bs4.html',encoding='utf-8').read()# 2.生成基于网页源代码的bs4对象
soup = BeautifulSoup(html,'lxml')# 3.获取标签
# soup.select() 在整个网页中获取css选择器选中的所以标签
#soup.select_one() 在整个网页中获取css选择器中的第一个标签result = soup.select('#box1 p')
print(result)
result1 = soup.select_one('#box1 p')
print(result1)'''
总结:标签对象.select(css选择器) 获取css选择器所有标签,返回一个列表,列表中元素是标签对象标签对象.select_one(css选择器) 获取第一个标签,结果是标签对象
'''result3 =soup.select('p')
#print(result3)result4 = soup.select('#box2')
#print(result4)#4. 获取标签内容和标签属性
p = soup.select_one('p')
img = soup.select_one('img')# a.获取标签内容 标签对象.text
print(p.text) #肖申克的救赎
# b. 获取标签的属性值
print(img.attrs['src'])
# https://b0.bdstatic.com/ugc/mFgjRS-3T9fHnYC3CAxHHwba8a3cbd3af3e42ddda89fa78b831a5f.jpg@h_1280二. 爬取豆瓣电影的信息
from bs4 import BeautifulSoup
import requests
import csv# 1.获取网页数据
def get_net_data(url: str):# headers进行伪装成正常的浏览器访问headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'}# 获取网页代码信息response = requests.get(url=url, headers=headers)# 返回解析后的代码信息return response.text# 2.解析网页数据
# ol class='grid_view' ->li ->div .item
#这里的html 就是第一步中解析网页代码后的信息
def analyse_data(html: str):# 生成基于网页源代码的bs4对象soup = BeautifulSoup(html, 'lxml')# 将所需要的电影信息代码块都获取下来all_films_div = soup.select('.grid_view>li>.item')all_data = []# 遍历每一个代码块,一个代码块都是一部电影的具体信息for div in all_films_div:name = div.select_one('.title').textinfo = div.select_one('.bd>p').text.strip().split('\n')[-1].strip()time, country, category = info.split('/')score = div.select_one('.rating_num').textcomment_count = div.select('.star>span')[-1].text[:-3]intro = div.select_one('.inq').textall_data.append([name, score, time.strip(), country.strip(), category.strip(), comment_count, intro])f = open('../files/第一页电影数据.csv','w',encoding='utf-8',newline='')#创建一个 CSV 文件写入器,并将其关联到一个已经打开的文件对象 f 上,就是在创建的第一页数据电影文件中准备录入信息writer = csv.writer(f)# 写的是表头 writerow 只写一行writer.writerow(['电影名字','评分','上映时间','发行国家地区','类型','评论人数','简介'])# csv文件中写入内容writer.writerows(all_data)if __name__ == '__main__':# for q in range(0, 251, 25):# url1 = f'https://movie.douban.com/top250?start={q}&filter='result = get_net_data(url='https://movie.douban.com/top250') #返回的是 response.textanalyse_data(result)三. 爬取250部电影(二只爬取了第一页内容,网站有很多页)
from bs4 import BeautifulSoup
import requests
import csv# 1.获取网页数据
def get_net_data(url: str):# headers进行伪装成正常的浏览器访问headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'}# 获取网页代码信息response = requests.get(url=url, headers=headers)# 返回解析后的代码信息return response.text# 2.解析网页数据
# ol class='grid_view' ->li ->div .item
#这里的html 就是第一步中解析网页代码后的信息
def analyse_data(html: str):# 生成基于网页源代码的bs4对象soup = BeautifulSoup(html, 'lxml')# 将所需要的电影信息代码块都获取下来all_films_div = soup.select('.grid_view>li>.item')all_data = []# 遍历每一个代码块,一个代码块都是一部电影的具体信息for div in all_films_div:name = div.select_one('.title').textinfo = div.select_one('.bd>p').text.strip().split('\n')[-1].strip()time, country, category = info.split('/')score = div.select_one('.rating_num').textcomment_count = div.select('.star>span')[-1].text[:-3]intro = div.select_one('.inq').textall_data.append([name, score, time.strip(), country.strip(), category.strip(), comment_count, intro])f = open('../files/250部电影数据.csv','w',encoding='utf-8',newline='')#创建一个 CSV 文件写入器,并将其关联到一个已经打开的文件对象 f 上,就是在创建的第一页数据电影文件中准备录入信息writer = csv.writer(f)# 写的是表头 writerow 只写一行writer.writerow(['电影名字','评分','上映时间','发行国家地区','类型','评论人数','简介'])# csv文件中写入内容writer.writerows(all_data)'''
在这里有所改变,看下面代码,上面都一样
'''
if __name__ == '__main__':for page in range(0, 250, 25):url = f'https://movie.douban.com/top250?start={page}&filter='result = get_net_data(url=url) #返回的是 response.textanalyse_data(result)四. os模块(看创建的文件是否存在,不存在进行创建,这是避免使用open的时候出现文件不存在的报错)
import os
if not os.path.exists('../files/abc'):os.mkdir('../files/abc')
五. 爬取英雄联盟的英雄名字(json)方法
json在netwok 中的 fetch/xhr 中找
import requests
response = requests.get('https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js')
result = response.json()for x in result['hero']:print(x['name'],x['alias'])-
找到network(网络),然后点击Fetch/XHR
-
一一找到名称列表的文件,通过preview(预览)查看是否我们需要的数据
-
查看json数据结构,并获取数据
六.下载安妮的皮肤
import requests# 1.定义一个函数
#img:是图片链接
def download(img: str, name: str):res = requests.get(img)with open(f'../skin/{name}.jpg', 'wb') as f:# 因为是图片所有用contentf.write(res.content)# 2.主程序入口下载图片
#用的还是json 还是network 下 fetch/xhr找
if __name__ == '__main__':response = requests.get('https://game.gtimg.cn/images/lol/act/img/js/hero/1.js')result = response.json()for x in result['skins']:name = x['name']img_url = x['mainImg']if not img_url:img_url = x['chromaImg']download(img_url,name)相关文章:
week04day03(爬虫 beautifulsoup4、)
一. 使用bs4解析网页 下载bs4 - pip install beautifulsoup4 使用的时候 import bs4专门用于解析网页的第三方库 在使用bs4的时候往往会依赖另一个库lxml pip install lxml 网页代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><…...
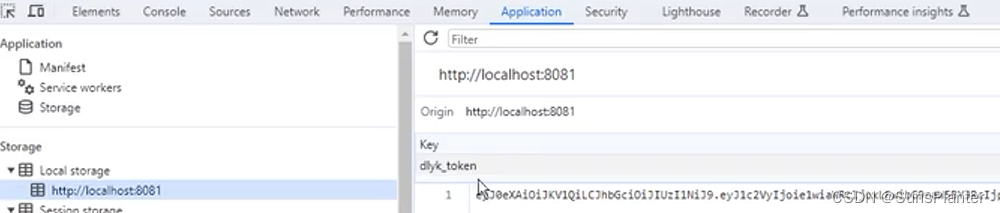
04 动力云客之登录后获取用户信息+JWT存进Redis+Filter验证Token + token续期
1. 登录后获取用户信息 非常好实现. 只要新建一个controller, 并调用SS提供的Authentication对象即可 package com.sunsplanter.controller;RestController public class UserController {GetMapping(value "api/login/info")public R loginInfo(Authentication a…...

RISC-V知识总结 —— 指令集
资源1: RISC-V China – RISC-V International 资源2: RISC-V International – RISC-V: The Open Standard RISC Instruction Set Architecture 资源3: RV32I, RV64I Instructions — riscv-isa-pages documentation 1. 指令集架构的类型 在讨论RISC-V或任何处理器架构时&…...
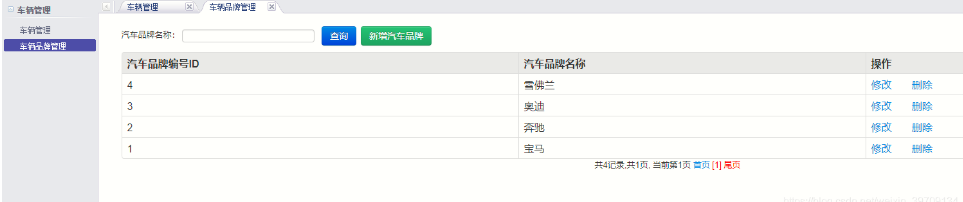
基于Java jsp+mysql+Spring的汽车出租平台租赁网站平台设计和实现
基于Java jspmysqlSpring的汽车出租平台租赁网站平台设计和实现 博主介绍:5年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 央顺技术团队 Java毕设项目精品实战案例《1000套》 欢迎点赞 收藏 ⭐留…...
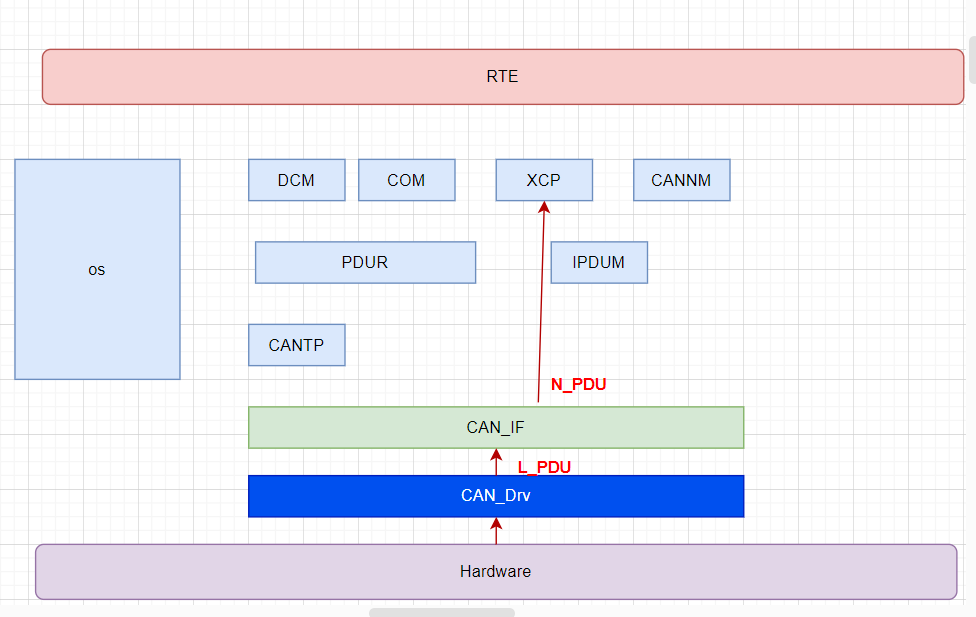
[AutoSar]BSW_Com 01 Can通信入门
目录 关键词平台说明一、车身CAN简介二、相关模块三、Can报文分类及信号流路径3.1 应用报文3.2 应用报文(多路复用multiplexer)3.3 诊断报文3.4 网络管理报文3.5 XCP报文(标定报文) 关键词 嵌入式、C语言、autosar、OS、BSW 平台…...

离散数学 第七单元 tree
目录 树的定义 树的特点 Spanning Tree 生成树(重要!) 生成树算法 DFS 深度优先 BFS 广度优先 Minimun Spanning Tree 最小生成树 Kruscal算法 Prim算法 根树 根数的遍历 前序遍历 中序遍历 后序遍历 表达式的二叉树 中缀…...
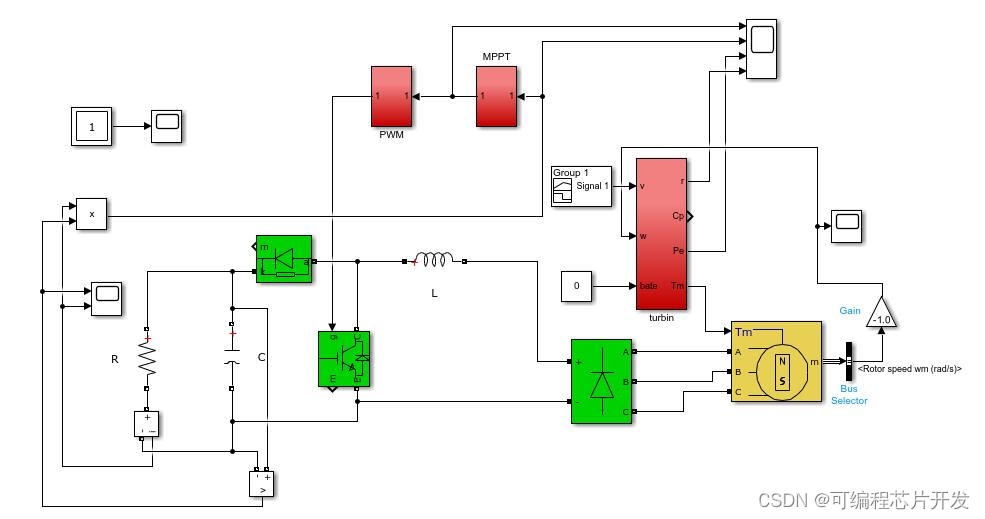
基于MPPT最大功率跟踪算法的涡轮机控制系统simulink建模与仿真
目录 1.课题概述 2.系统仿真结果 3.核心程序与模型 4.系统原理简介 5.完整工程文件 1.课题概述 基于MPPT最大功率跟踪算法的涡轮机控制系统simulink建模与仿真.mppt采用爬山法实现,仿真输出MPPT控制效果,功率,转速等。 2.系统仿真结果 …...

Hbase和Clickhouse对比简单总结
Hbase和Clickhouse是两种不同的数据库系统,它们各自适用于不同的场景。以下是两者之间的对比: 数据模型: HBase 是一种基于列的存储系统,它适合处理大规模的数据集,特别是那些需要快速随机访问的场景。ClickHouse 则是…...
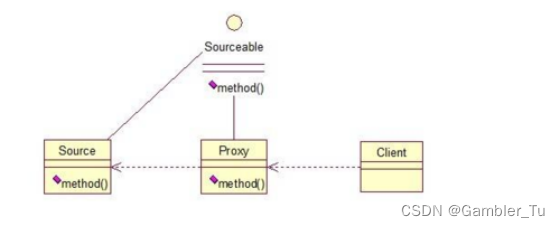
Spring基础之AOP和代理模式
文章目录 理解AOPAOP的实现原理 AOP代理模式静态代理动态代理1-JDK动态代理2-CGLIB动态代理 总结 理解AOP OOP - - Object Oriented Programming 面向对象编程 AOP - - Aspect Oriented Programming 面向切面编程 AOP是Spring提供的关键特性之一。AOP即面向切面编程࿰…...

二层交换机和三层交换机区别
01、二层交换机 二层交换机,也被称为数据链路层交换机,是在OSI模型的数据链路层(第二层)进行数据交换的设备。它基于MAC(Media Access Control)地址来转发数据包,实现局域网内部的数据传输 1、…...
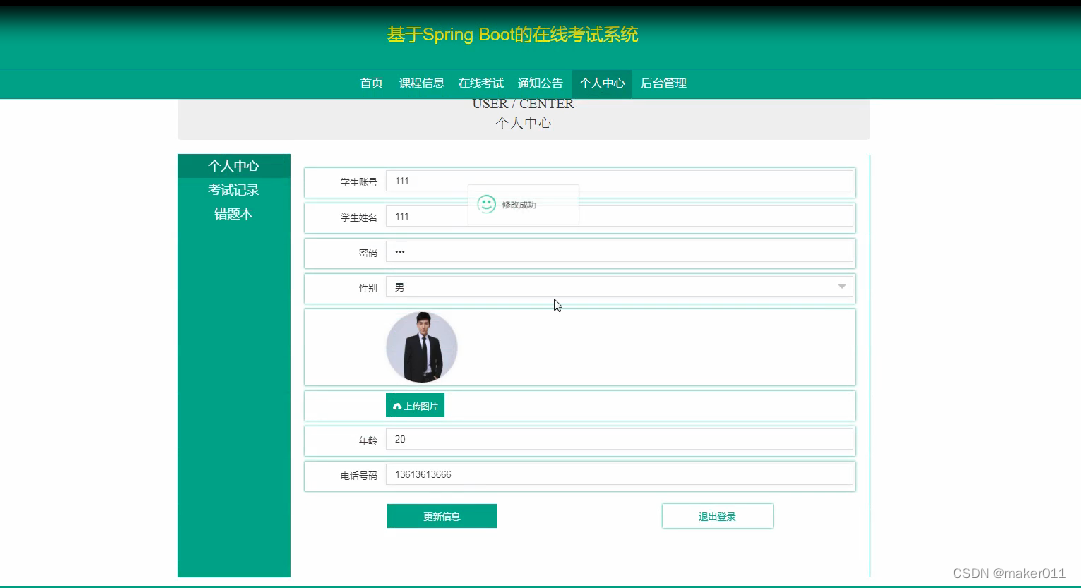
【Java程序设计】【C00267】基于Springboot的在线考试系统(有论文)
基于Springboot的在线考试系统(有论文) 项目简介项目获取开发环境项目技术运行截图 项目简介 本系统是基于Springboot的在线考试系统;本系统主要分为管理员、教师和学生三种角色; 管理员登录系统后,可以对首页&#x…...
——代码随想录算法训练营Day41)
【LeetCode】416. 分割等和子集(中等)——代码随想录算法训练营Day41
题目链接:416. 分割等和子集 题目描述 给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。 示例 1: 输入:nums [1,5,11,5] 输出:true 解释&#x…...

51单片机学习(4)-----独立按键进一步控制LED灯
前言:感谢您的关注哦,我会持续更新编程相关知识,愿您在这里有所收获。如果有任何问题,欢迎沟通交流!期待与您在学习编程的道路上共同进步。 目录 一. 独立按键灵活控制LED 程序一:单个独立按键控制多个…...

Redis 学习笔记 3:黑马点评
Redis 学习笔记 3:黑马点评 准备工作 需要先导入项目相关资源: 数据库文件 hmdp.sql后端代码 hm-dianping.zip包括前端代码的 Nginx 启动后端代码和 Nginx。 短信登录 发送验证码 PostMapping("code") public Result sendCode(RequestP…...
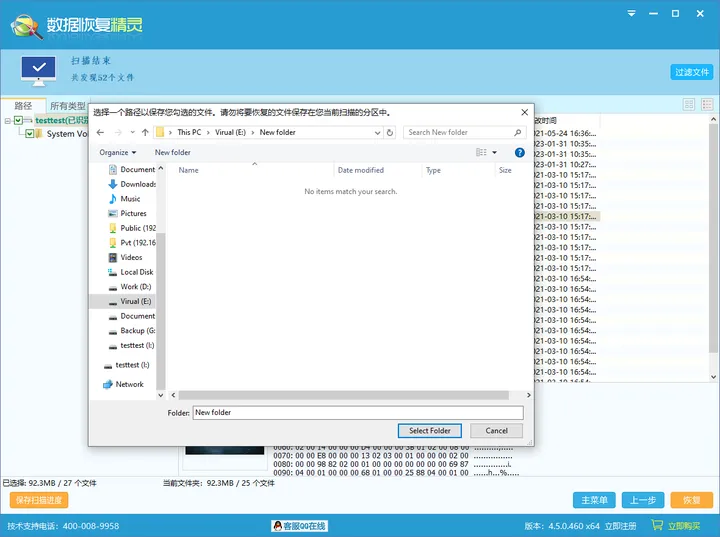
电脑恢复删除数据的原理和方法
在恢复数据的时候,很多人都会问,为什么删除的数据还能恢复?本篇和大家一起了解下硬盘上数据的存储方式,文件被删除的时候具体发生了什么,帮助大家理解数据恢复的基本原理。最后还会分享一个好用的数据恢复工具并附上图…...
SpringBoot和SpringCloud的区别,使用微服务的好处和缺点
SpringBoot是一个用于快速开发单个Spring应用程序的框架,通过提供默认配置和约定大于配置的方式,快速搭建基于Spring的应用。让程序员更专注于业务逻辑的编写,不需要过多关注配置细节。可以看成是一种快速搭建房子的工具包,不用从…...
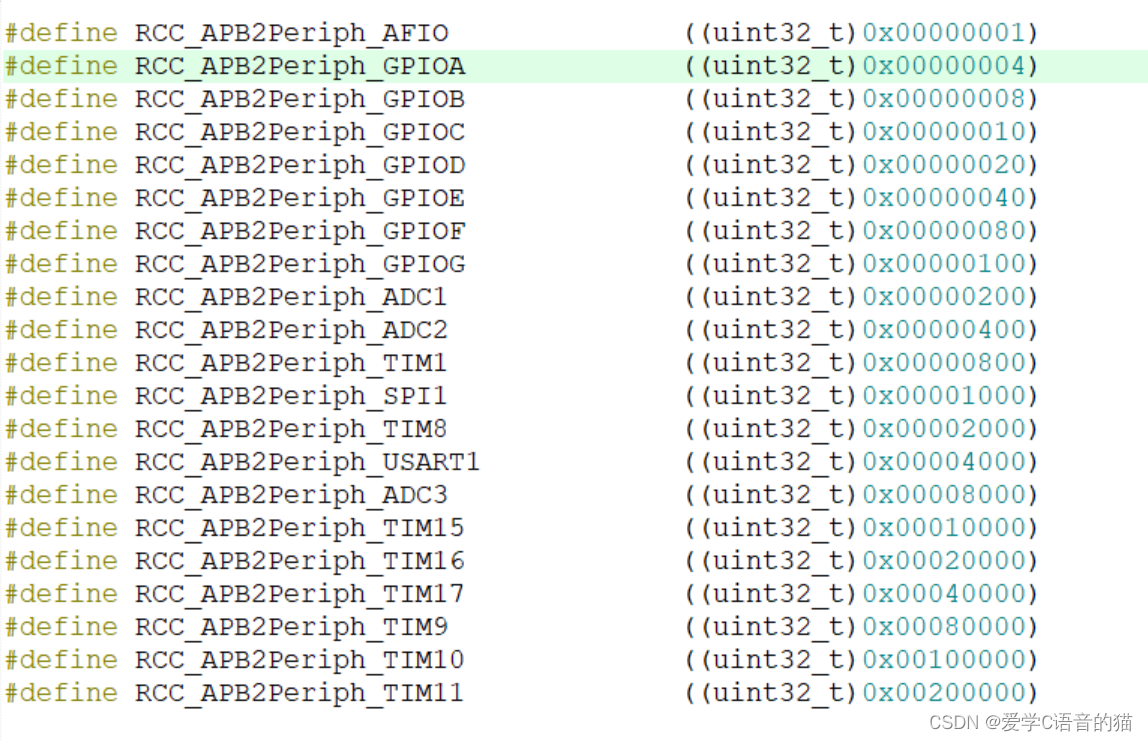
32单片机基础:GPIO输出
目录 简介: GPIO输出的八种模式 STM32的GPIO工作方式 GPIO支持4种输入模式: GPIO支持4种输出模式: 浮空输入模式 上拉输入模式 下拉输入模式 模拟输入模式: 开漏输出模式:(PMOS无效,就…...
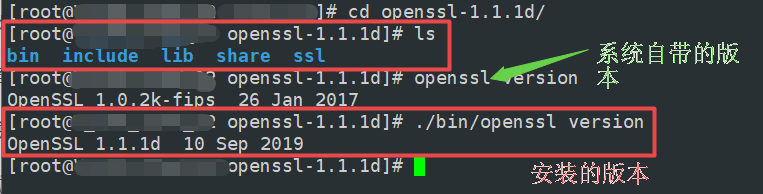
【linux】查看openssl程序的安装情况
【linux】查看openssl程序的安装情况 1、查看安装包信息 $ rpm -qa |grep openssl 2、安装路径 $ rpm -ql openssl $ rpm -ql openssl-libs $ rpm -ql openssl-devel 3、相关文件和目录 /usr/bin/openssl /usr/include/openssl /usr/lib64/libssl.so.* /usr/lib64/libcrypto…...

高防服务器主要运用在哪些场景?
高防服务器主要是用来防御DDOS攻击的服务器,能够为客户提供安全维护,高防服务器能够帮助网站拒绝服务攻击,定时扫描网络主节点,进行查找可能会出现的安全漏洞的服务类型,高防服务器也会根据不同的IDC机房环境来提供硬防…...

Eureka:微服务中的服务注册与发现机制
引言 在微服务架构中,由于服务数量巨大并且各个服务的实例可能会频繁上下线,因此服务注册和发现机制至关重要。 那么,有什么工具或技术可以帮助我们解决这个问题呢? 答案就是Eureka。 一、Eureka简介 Eureka是Netflix公司开源的…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

AirSim/Cosys-AirSim 游戏开发(四)外部固定位置监控相机
这个博客介绍了如何通过 settings.json 文件添加一个无人机外的 固定位置监控相机,因为在使用过程中发现 Airsim 对外部监控相机的描述模糊,而 Cosys-Airsim 在官方文档中没有提供外部监控相机设置,最后在源码示例中找到了,所以感…...