掌握BeautifulSoup4:爬虫解析器的基础与实战【第91篇—BeautifulSoup4】
掌握BeautifulSoup4:爬虫解析器的基础与实战
网络上的信息浩如烟海,而爬虫技术正是帮助我们从中获取有用信息的重要工具。在爬虫过程中,解析HTML页面是一个关键步骤,而BeautifulSoup4正是一款功能强大的解析器,能够轻松解析HTML和XML文档。本文将介绍BeautifulSoup4的基础知识,并通过实际代码示例进行演示。

BeautifulSoup4简介:
BeautifulSoup4是Python中一个用于解析HTML和XML文档的库,它提供了许多便捷的方法来浏览、搜索和修改文档树。BeautifulSoup4支持多种解析器,其中最常用的是基于Python标准库的html.parser。
安装BeautifulSoup4:
pip install beautifulsoup4
基础知识:
-
解析HTML文档:
使用BeautifulSoup4解析HTML文档非常简单,只需要将HTML文档传递给BeautifulSoup类即可。from bs4 import BeautifulSouphtml_doc = "<html><head><title>My Title</title></head><body><p>Hello, BeautifulSoup4!</p></body></html>" soup = BeautifulSoup(html_doc, 'html.parser') -
标签选择器:
Beautiful Soup提供了多种标签选择器,最常用的是通过标签名来选择。# 选择所有的段落标签 paragraphs = soup.find_all('p') -
标签属性:
通过指定标签的属性来选择元素。# 选择class为'example'的div标签 example_div = soup.find('div', class_='example')
代码实战:
接下来,我们将通过一个简单的实例演示BeautifulSoup4的使用,从一个网页中提取标题和链接。
import requests
from bs4 import BeautifulSoup# 发送HTTP请求获取页面内容
url = 'https://example.com'
response = requests.get(url)
html_content = response.text# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html_content, 'html.parser')# 提取标题和链接
title = soup.title.text
links = soup.find_all('a')# 打印结果
print(f"页面标题:{title}")print("页面链接:")
for link in links:print(f"{link.get('href')}")
这个例子中,我们首先发送HTTP请求获取网页内容,然后使用BeautifulSoup解析HTML。通过soup.title可以获取页面的标题,通过soup.find_all('a')可以获取所有链接标签。最后,我们打印标题和所有链接的地址。
BeautifulSoup4是一个功能强大而灵活的HTML解析库,使得在爬虫项目中处理HTML文档变得更加轻松。通过学习基础知识和实际代码实例,我们可以更好地利用BeautifulSoup4从网页中提取所需信息。在实际项目中,合理运用BeautifulSoup4能够大大提高爬虫的效率和灵活性。
数据处理与异常处理:
在实际虫项目中,对于从网页中提取的数据,通常需要进行进一步的处理。BeautifulSoup提供了一些方法来处理提取的文本数据,如去除空白字符、提取数字等。同时,在进行页面解析时,考虑到网页结构可能变化或者异常情况的发生,我们也需要添加适当的异常处理机制。
# 数据处理与异常处理示例
for link in links:try:# 提取链接文本并去除首尾空白字符link_text = link.text.strip()# 提取链接地址link_url = link.get('href')# 打印处理后的结果print(f"链接文本:{link_text}, 链接地址:{link_url}")# 进一步处理数据,比如提取数字if link_text.isdigit():number = int(link_text)print(f"提取到数字:{number}")except Exception as e:# 异常处理,打印异常信息print(f"处理链接时发生异常:{e}")
在这个例子中,我们首先使用strip()方法去除链接文本的首尾空白字符,然后通过isdigit()方法判断是否为数字,并进行相应的处理。同时,通过异常处理机制,我们能够捕获并打印在处理链接时可能发生的异常。
高级功能与定制化:
BeautifulSoup4还提供了一些高级功能,如CSS选择器、正则表达式等,使得页面解析更加灵活。此外,我们还可以通过定制化解析器、过滤器等方式,满足不同场景下的需求。
# 使用CSS选择器提取数据
main_content = soup.select_one('#main-content').text# 使用正则表达式匹配特定模式的数据
import re
pattern = re.compile(r'\b\d{3}-\d{2}-\d{4}\b')
matches = soup.find_all(text=pattern)# 定制化解析器示例
from bs4 import SoupStraineronly_a_tags = SoupStrainer("a")
custom_soup = BeautifulSoup(html_content, 'html.parser', parse_only=only_a_tags)
在这个例子中,我们通过select_one()方法使用CSS选择器提取id为main-content的元素的文本内容,通过正则表达式匹配特定模式的文本数据,以及通过SoupStrainer定制化解析器,只解析<a>标签的内容。
遵循爬虫道德准则:
在进行网络爬虫的过程中,我们需要遵循一定的爬虫道德准则,以确保爬虫行为的合法性和对被爬取网站的尊重。以下是一些爬虫道德准则:
-
尊重网站的
robots.txt文件: 网站的robots.txt文件通常包含了该站点对爬虫的访问规则,爬虫应该遵守这些规则。通过检查robots.txt文件,可以了解哪些页面可以被爬取,哪些不可以。 -
设置适当的爬虫速率: 爬虫在请求网页时应该遵循适当的速率,以避免对服务器造成过大的负担。设置合理的爬虫速率有助于维护和改善爬虫的可持续性。
-
标识爬虫身份: 在HTTP请求的Header中包含爬虫的身份信息,例如User-Agent,以便网站管理员能够识别爬虫并联系到负责人。这有助于建立信任关系。
-
避免对服务器造成过大压力: 合理设计爬虫策略,避免在短时间内发送大量请求,以免对目标服务器造成不必要的负担,有可能导致被封禁。
安全注意事项:
在爬虫项目中,安全性是一个重要的考虑因素。以下是一些安全注意事项:
-
防范反爬虫机制: 有些网站可能会设置反爬虫机制,如验证码、IP封锁等。爬虫应该考虑这些机制,并进行相应的处理,以确保正常的爬取行为。
-
处理异常情况: 在爬虫过程中,可能会遇到网络异常、页面结构变化等情况。合理设置异常处理机制,记录日志,以便及时发现和解决问题。
-
遵循法律法规: 在进行爬虫活动时,务必遵循相关的法律法规,尊重他人的合法权益。不得进行恶意爬取、盗取信息等违法行为。
实用技巧与优化建议:
在进行爬虫开发时,除了掌握基础知识和遵循道德准则外,一些实用技巧和优化建议也能提高爬虫效率和可维护性。
-
使用Session保持会话: 在爬虫过程中,通过使用
requests.Session可以保持一个会话,复用TCP连接,提高请求效率,并在多次请求之间保持一些状态信息,如登录状态。import requests# 创建Session对象 session = requests.Session()# 使用Session发送请求 response = session.get('https://example.com') -
避免频繁请求相同页面: 对于相同的页面,可以考虑缓存已经获取的页面内容,以减轻服务器负担,并提高爬虫的效率。
-
使用多线程或异步请求: 在大规模爬取数据时,考虑使用多线程或异步请求,以加速数据获取过程。但要注意线程安全性和对目标网站的负载。
-
定时任务与调度: 对于长时间运行的爬虫任务,考虑使用定时任务和调度工具,确保爬虫按计划执行,同时避免对目标服务器造成不必要的压力。
-
日志记录: 在爬虫项目中加入合适的日志记录,记录关键信息和异常情况,有助于排查问题和监控爬虫运行状态。
-
随机化请求头和IP代理: 通过随机化请求头和使用IP代理,可以减小被识别为爬虫的概率,同时提高爬虫的稳定性。
import fake_useragent from bs4 import BeautifulSoup import requests# 随机生成User-Agent headers = {'User-Agent': fake_useragent.UserAgent().random}# 使用IP代理 proxies = {'http': 'http://your_proxy', 'https': 'https://your_proxy'}response = requests.get('https://example.com', headers=headers, proxies=proxies) -
模拟浏览器行为: 有些网站通过检测爬虫的请求头信息来进行反爬虫,此时可以模拟浏览器行为,使请求更接近正常用户的行为。
from selenium import webdriver# 使用Selenium模拟浏览器 driver = webdriver.Chrome() driver.get('https://example.com')
通过结合这些实用技巧和优化建议,可以使爬虫更加高效、稳定,同时降低被识别为爬虫的概率。
不断学习与更新:
由于网络环境和网站结构的不断变化,爬虫技术也需要不断学习和更新。关注网络爬虫领域的最新发展,学习新的工具和技术,不仅有助于解决新问题,还能提高爬虫项目的适应性和可维护性。
在学习过程中,建议参与相关技术社区、论坛,与其他爬虫开发者交流经验,分享问题和解决方案。这样可以更全面地了解爬虫领域的最新趋势和实践经验,从而更好地提升自己的技能水平。
案例实战:使用BeautifulSoup4爬取新闻信息
让我们通过一个实际案例,使用BeautifulSoup4爬取一个新闻网站的信息。这个案例将演示如何从网页中提取新闻标题、链接和发布时间等信息。
import requests
from bs4 import BeautifulSoup
from datetime import datetime# 发送HTTP请求获取新闻页面内容
url = 'https://example-news-website.com'
response = requests.get(url)
html_content = response.text# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html_content, 'html.parser')# 提取新闻信息
news_list = []for news_item in soup.find_all('div', class_='news-item'):try:# 提取新闻标题title = news_item.find('h2').text.strip()# 提取新闻链接link = news_item.find('a')['href']# 提取发布时间time_string = news_item.find('span', class_='publish-time').text.strip()publish_time = datetime.strptime(time_string, '%Y-%m-%d %H:%M:%S')# 将提取的信息存入字典news_info = {'title': title, 'link': link, 'publish_time': publish_time}news_list.append(news_info)except Exception as e:# 异常处理,打印异常信息print(f"处理新闻时发生异常:{e}")# 打印提取的新闻信息
for news_info in news_list:print(f"标题:{news_info['title']}")print(f"链接:{news_info['link']}")print(f"发布时间:{news_info['publish_time']}")print("\n")
在这个案例中,我们首先发送HTTP请求获取新闻页面的HTML内容,然后使用BeautifulSoup解析HTML。通过观察网页结构,我们找到包含新闻信息的<div>标签,然后逐一提取新闻标题、链接和发布时间。最后,将提取的信息存入字典,并打印出来。
这个案例演示了如何结合BeautifulSoup4和Requests库进行实际的网页信息提取,是学习和使用爬虫技术的一个有趣的实践。
反爬虫策略应对:
在进行爬虫开发时,经常会遇到一些网站采取了反爬虫策略,为了防止被封禁或识别为爬虫,我们可以采取以下一些策略:
-
设置合理的请求头: 模拟正常浏览器的请求头,包括User-Agent等信息,以减小被识别为爬虫的概率。
-
使用IP代理: 轮换使用不同的IP地址,避免在短时间内发送大量请求,减轻服务器负担。
-
随机化请求频率: 随机化请求的时间间隔,避免定时、有规律的请求,减少被识别为爬虫的可能性。
-
处理验证码: 一些网站设置了验证码来防止爬虫,当遇到验证码时,需要通过程序自动识别或手动处理。
-
模拟浏览器行为: 使用工具如Selenium模拟浏览器行为,使爬虫请求更加接近正常用户的行为。
-
监测网站更新: 定期检查目标网站是否有更新,以及是否有新的反爬虫策略。灵活调整爬虫策略以适应变化。
这些策略并不是一劳永逸的,不同的网站可能需要采用不同的应对方法。在实际爬虫开发中,根据目标网站的具体情况,灵活选择合适的策略是非常重要的。
希望这篇技术博客对你在爬虫开发中有所帮助,祝你在爬虫的探索中取得丰硕的成果!
总结:
在这篇技术博客中,我们深入探讨了爬虫解析器BeautifulSoup4的基础知识和实战应用。通过介绍BeautifulSoup4的简介、安装以及基本用法,我们了解了如何使用它解析HTML和XML文档,以及如何通过标签选择器和属性选择器提取所需信息。
通过一个实际案例,我们演示了如何结合BeautifulSoup4和Requests库爬取新闻网站的信息,提取标题、链接和发布时间等关键信息。这个案例帮助读者更好地理解BeautifulSoup4在实际爬虫项目中的应用。
随后,我们探讨了爬虫的道德准则,提到了尊重网站robots.txt文件、设置适当的爬虫速率、标识爬虫身份等原则。同时,我们强调了安全性的重要性,包括处理异常情况、遵循法律法规、防范反爬虫机制等。
接着,我们分享了一系列实用技巧与优化建议,包括使用Session保持会话、避免频繁请求相同页面、使用多线程或异步请求等。这些技巧有助于提高爬虫效率、降低被封禁风险,并使爬虫项目更加稳定可靠。
在最后的章节中,我们通过案例实战展示了爬虫开发中的一些挑战,如反爬虫策略的应对。我们介绍了一些应对措施,包括设置合理的请求头、使用IP代理、随机化请求频率等。这些策略帮助读者更好地理解如何在面对反爬虫机制时保持爬虫的有效性。
最后,我们强调了不断学习与更新的重要性,鼓励读者关注爬虫领域的最新发展,积极参与技术社区,分享经验,以保持竞争力并取得更大的成就。
通过这篇技术博客,读者不仅可以掌握BeautifulSoup4的基础用法,还能学到实际应用的经验和一些建议。希望这篇文章能为爬虫开发者提供有益的指导,并鼓励他们在技术领域中不断成长。
相关文章:
掌握BeautifulSoup4:爬虫解析器的基础与实战【第91篇—BeautifulSoup4】
掌握BeautifulSoup4:爬虫解析器的基础与实战 网络上的信息浩如烟海,而爬虫技术正是帮助我们从中获取有用信息的重要工具。在爬虫过程中,解析HTML页面是一个关键步骤,而BeautifulSoup4正是一款功能强大的解析器,能够轻…...

从源码解析Kruise(K8S)原地升级原理
从源码解析Kruise原地升级原理 本文从源码的角度分析 Kruise 原地升级相关功能的实现。 本篇Kruise版本为v1.5.2。 Kruise项目地址: https://github.com/openkruise/kruise 更多云原生、K8S相关文章请点击【专栏】查看! 原地升级的概念 当我们使用deployment等Wor…...

2024年【广东省安全员C证第四批(专职安全生产管理人员)】复审考试及广东省安全员C证第四批(专职安全生产管理人员)模拟考试题
题库来源:安全生产模拟考试一点通公众号小程序 广东省安全员C证第四批(专职安全生产管理人员)复审考试是安全生产模拟考试一点通总题库中生成的一套广东省安全员C证第四批(专职安全生产管理人员)模拟考试题࿰…...
udp服务器【Linux网络编程】
目录 一、UDP服务器 1、创建套接字 2、绑定套接字 3、运行 1)读取数据 2)发送数据 二、UDP客户端 创建套接字: 客户端不用手动bind 收发数据 处理消息和网络通信解耦 三、应用场景 1、服务端执行命令 2、Windows上的客户端 3…...
【k8s资源调度-Deployment】
1、标签和选择器 1.1 标签Label 配置文件:在各类资源的sepc.metadata.label 中进行配置通过kubectl 命令行创建修改标签,语法如下 创建临时label:kubectl label po <资源名称> apphello -n <命令空间(可不加࿰…...
【Oracle】玩转Oracle数据库(五):PL/SQL编程
前言 嗨,各位数据库达人!准备好迎接数据库编程的新挑战了吗?今天我们要探索的是Oracle数据库中的神秘魔法——PL/SQL编程!🔮💻 在这篇博文【Oracle】玩转Oracle数据库(五)࿱…...
JavaScript流程控制
文章目录 1. 顺序结构2. 分支结构2.1 if 语句2.2 if else 双分支语句2.3 if else if 多分支语句三元表达式 2.4 switch 语句switch 语句和 if else if语句区别 3. 循环结构3.1 for 循环断点调试 3.2 双重 for 循环3.3 while 循环3.4 do while 循环3.5 contiue break 关键字 4. …...

五个使用Delphi语言进行开发的案例
案例一:学生信息管理系统 某学校需要开发一个学生信息管理系统,用于记录学生的基本信息、成绩和考勤情况等。开发者使用Delphi语言进行开发,设计了一个包含多个窗体的应用程序。主窗体用于展示学生的列表和基本信息,其他窗体则用…...

蓝桥杯第1374题——锻造兵器
题目描述 小明一共有n块锻造石,第块锻造石的属性值为ai. 现在小明决定从这n块锻造石中任取两块来锻造兵器 通过周密计算,小明得出,只有当两块锻造石的属性值的差值等于C,兵器才能锻造成功 请你帮小明算算,他有多少种选…...
坚鹏:政府数字化转型数字机关、数据共享及电子政务类案例研究
政府数字化转型数字机关、数据共享及电子政务类案例研究 课程背景: 很多地方政府存在以下问题: 不清楚政府数字化转型的数字机关类成功案例 不清楚政府数字化转型的数据共享类成功案例 不清楚政府数字化转型的电子政务类成功案例 课程特色&…...
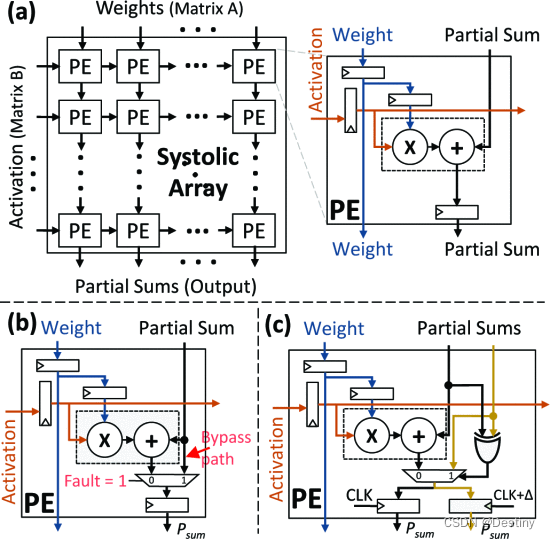
【架构】面向人工智能 (AI) 的硬件的可靠性(2021)
由于激进的技术扩展,现代系统越来越容易受到可靠性威胁的影响,例如软错误、老化和工艺变化。这些威胁在硬件级别表现为位翻转,并且根据位置,可能会损坏输出,从而导致不准确或潜在的灾难性结果。 传统的缓解技术基于冗…...

Unity3D MVC开发模式与开发流程详解
前言 MVC(Model-View-Controller)是一种常用的软件架构模式。将MVC应用于Unity3D开发可以提高项目的可维护性和可扩展性,使代码更加清晰和易于理解。本文将详细介绍Unity3D中MVC开发模式的应用以及开发流程,并给出技术详解和代码…...

简单介绍一下Android里面的IntentFirewall
源码链接 https://android.googlesource.com/platform/frameworks/base//633dc9b/services/java/com/android/server/firewall/IntentFirewall.java 源码如下: package com.android.server.firewall; import android.content.Intent; import android.content.Inte…...

Stable Diffusion 3 发布及其重大改进
1. 引言 就在 OpenAI 发布可以生成令人瞠目的视频的 Sora 和谷歌披露支持多达 150 万个Token上下文的 Gemini 1.5 的几天后,Stability AI 最近展示了 Stable Diffusion 3 的预览版。 闲话少说,我们快来看看吧! 2. 什么是Stable Diffusion…...

【后端】springboot项目
文章目录 1. 2.3.7.RELEASE版本搭建1.1 pom文件1.1.1 方式一1.1.2 方式二 1.2 启动类1.3 测试类 2. 引入Value乱码问题解决 【后端目录贴】 1. 2.3.7.RELEASE版本搭建 1.1 pom文件 1.1.1 方式一 <parent><groupId>org.springframework.boot</groupId><…...

React Native调用摄像头画面及拍照和保存图片到相册全流程
今天主要做了一个demo,功能很简单,就是调用手机摄像头画面,并且可以通过按钮控制拍照以及将图片保存到手机相册的功能,接下来我将从创建项目开始一步一步完成这个demo,各位只需要复制粘贴即可 创建React Native项目 npx react-native init yx_rnDemo --version 0.70.6 // 这里…...

Kubernetes基本部署概念
文章目录 命名空间(Namespaecs)查看命名空间查看带有命名空间对象下资源 文件存储持久卷(pv,Persistent Volumes)卷容量卷模式(volumeMode)访问模式(accessModes)回收策略…...

QT c++ 海康红外热像仪
//本文描述2通道海康通道红外热像仪预览和抓图 #include "mainwindow.h" #include "ui_mainwindow.h" MainWindow::MainWindow(QWidget *parent) : QMainWindow(parent) , ui(new Ui::MainWindow) { ui->setupUi(this); userID-1; …...
OpenAI 的 GPTs 提示词泄露攻击与防护实战:防御卷(一)
前面的OpenAI DevDay活动上,GPTs技术的亮相引起了广泛关注。随着GPTs的创建权限开放给Plus用户,社区里迅速涌现了各种有趣的GPT应用,这些都是利用了Prompt提示词的灵活性。这不仅展示了技术的创新潜力,也让人们开始思考如何获取他…...
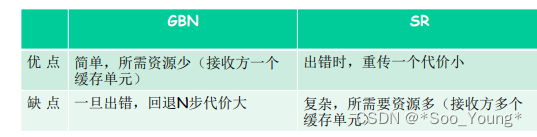
中科大计网学习记录笔记(十五):可靠数据传输的原理
前前言:看过本节的朋友应该都知道本节长度长的吓人,但其实内容含量和之前的差不多,老师在本节课举的例子和解释比较多,所以大家坚持看完是一定可以理解透彻的。本节课大部分是在提出问题和解决问题,先明确出现的问题是…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...

深入理解Optional:处理空指针异常
1. 使用Optional处理可能为空的集合 在Java开发中,集合判空是一个常见但容易出错的场景。传统方式虽然可行,但存在一些潜在问题: // 传统判空方式 if (!CollectionUtils.isEmpty(userInfoList)) {for (UserInfo userInfo : userInfoList) {…...

医疗AI模型可解释性编程研究:基于SHAP、LIME与Anchor
1 医疗树模型与可解释人工智能基础 医疗领域的人工智能应用正迅速从理论研究转向临床实践,在这一过程中,模型可解释性已成为确保AI系统被医疗专业人员接受和信任的关键因素。基于树模型的集成算法(如RandomForest、XGBoost、LightGBM)因其卓越的预测性能和相对良好的解释性…...