【机器学习】特征选择之过滤式特征选择法

🎈个人主页:豌豆射手^
🎉欢迎 👍点赞✍评论⭐收藏
🤗收录专栏:机器学习
🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步!
【机器学习】特征选择之过滤式特征选择法
- 一 概念
- 二 步骤
- 三 优点
- 三 方差选择法(Variance Thresholding):
- 3.1 步骤
- 3.2 示例
- 四 互信息(Mutual Information):
- 4.1 步骤
- 4.2 示例
- 五 卡方检验(Chi-Square Test):
- 5.1 步骤
- 5.2 示例
- 六 皮尔逊相关系数(Pearson Correlation Coefficient):
- 6.1 步骤
- 6.2 示例
- 七 信息增益(Information Gain):
- 7.1 步骤
- 7.2 示例
- 八 各种方法的优缺点及适用场景
- 8.1 方差选择法:
- 8.2 互信息法:
- 8.3 卡方检验法:
- 8.4 皮尔逊相关系数法:
- 8.5 信息增益法:
- 总结
引言:
在机器学习领域,特征选择是一个至关重要的步骤,它可以帮助我们从原始数据中筛选出最具有代表性和信息量的特征,从而提高模型的性能和泛化能力。
而过滤式特征选择法是特征选择的一种常用方法,它在训练模型之前通过评估特征的某些统计属性或与目标变量之间的关系来进行特征筛选。
本文将介绍几种常见的过滤式特征选择方法,包括方差选择法、互信息、卡方检验、皮尔逊相关系数和信息增益。
我们将详细讨论每种方法的概念、步骤以及通过示例演示它们的应用。
此外,我们还会分析各种方法的优点、缺点以及适用场景,帮助读者在实际应用中选择合适的特征选择方法。

一 概念
过滤式特征选择是一种机器学习中的特征选择方法,它在模型训练之前通过对特征进行评估和排序,
即针对每个特征,使用某种度量方法对其进行评估,然后根据评估结果对特征的好坏进行排序。
再选择出与目标变量相关性较高的特征子集。
这种方法独立于具体的学习算法,通过对特征进行初步的过滤,提高了模型的泛化能力、降低了过拟合的风险,并且在计算效率上具有优势。
类比:
假设你是一位拥有一家小餐馆的业主,想要提高菜单的质量和效率。你决定使用过滤式特征选择方法来选择最适合的菜品。
首先,你收集了各种关于菜品的数据,包括菜品的成本、制作时间、受欢迎程度等特征。
接着,你对每个菜品的这些特征进行评估,比如成本与价格的比率、制作时间与受欢迎程度之间的关系等。
然后,根据评估结果,你对每个菜品的好坏进行排序,将最具潜力的菜品排在前面。
最后,在选择菜单时,你选择了与盈利相关性较高的特定菜品子集,这些菜品不仅在成本、制作时间上效率高,而且在受欢迎程度上也较好,从而提高了菜单的质量和效率,降低了成本,增加了盈利空间。
这种过滤式特征选择方法使得你的餐馆在不同的条件下都能保持竞争力。

二 步骤
其步骤可以分为以下几个阶段:
**1 数据收集 **
首先,收集包含特征和目标变量的数据集。
确保数据集经过清洗和预处理,以排除缺失值、异常值等干扰因素。
2 特征评估:
针对每个特征,使用合适的评估方法来衡量其与目标变量之间的关系或特征本身的重要性。
常用的评估方法包括方差选择法、互信息、卡方检验、皮尔逊相关系数、信息增益等。
3 特征排序:
根据评估的结果,对每个特征进行排序,将重要性高的特征排在前面。
这有助于后续选择最具代表性的特征子集。
4 阈值设定(可选):
可以设定一个阈值,只选择排名在阈值之上的特征,或者选择前N个特征。
这有助于进一步筛选特征,减少模型复杂度。
5 特征选择:
根据设定的标准,选择最终的特征子集。
可以是按照排名选择前几个特征,也可以是根据阈值选择高于该阈值的特征。
过滤式特征选择的优点在于其独立于具体的学习算法,可以在任何模型训练之前对特征进行初步的筛选,从而提高模型的泛化能力、降低过拟合风险,并在计算效率上具有优势。
三 优点
过滤式特征选择是机器学习中常用的特征选择方法之一,其优点主要体现在以下几个方面:
1 简单而高效:
过滤式特征选择的算法通常简单而直观,不需要深入训练模型或进行复杂的计算。
这使得过滤式方法的实现非常高效,特别是对于大规模数据集,它们能够在相对较短的时间内完成特征选择。
2 独立于具体模型:
过滤式特征选择方法与具体的机器学习模型无关,因此可以在任何模型之前应用。
这种独立性使得它们成为预处理阶段的理想选择,可以在模型训练之前快速减小特征空间的维度。
3 降低计算成本:
由于过滤式方法在特征选择阶段并不涉及对模型的训练,其计算成本相对较低。
这对于资源受限或需要快速迭代的场景非常有利。
4 易解释性强:
过滤式方法通常基于统计学或信息论的原理,选择特征的依据较为清晰和可解释。
这有助于理解为什么选择了某些特征,从而增加了对特征选择过程的可信度。
5 有效防止过拟合:
过滤式特征选择可以在模型训练之前排除掉对预测目标贡献较小的特征,从而降低模型过拟合的风险。
通过减少噪声和不相关信息,过滤式方法有助于提高模型的泛化能力。
6 适用于高维数据:
当面对高维数据集时,过滤式特征选择是一个强有力的工具,因为它能够快速识别和保留对目标变量最具影响力的特征,减轻了维度灾难的影响。
总体而言,过滤式特征选择在简化问题、降低计算复杂性、提高模型的解释性和防止过拟合等方面具有显著的优点,使其成为机器学习中常用的特征选择策略之一。

三 方差选择法(Variance Thresholding):
方差选择法是过滤式特征选择方法中的一种常用技术,用于评估特征的重要性。
它基于特征的方差来判断特征的变化程度,认为方差较小的特征对目标变量的影响较小,因此可以将这些特征过滤掉。
3.1 步骤
1 数据准备:
首先,准备包含特征和目标变量的数据集。
确保数据集经过清洗和预处理,以排除缺失值、异常值等干扰因素。
2 计算特征的方差:
对于每个特征,计算其在数据集中的方差。
方差是衡量数据分布离散程度的一种度量,方差较小表示数据点之间的差异较小,而方差较大则表示数据点之间的差异较大。
3 设定阈值:
根据实际需求,设定一个方差的阈值。
这个阈值可以是根据领域知识或者经验来设定的,也可以是通过交叉验证等技术来确定的。
4 特征选择:
将方差小于阈值的特征过滤掉,保留方差大于阈值的特征作为最终的特征子集。
方差小的特征意味着其取值变化不大,可能缺乏足够的信息来对目标变量做出预测,因此可以考虑将其过滤掉。
方差选择法适用于连续型特征,对于离散型特征需要先进行编码转换。
虽然方差选择法简单易用,但也存在一些局限性,例如对特征之间的相关性不敏感,可能会忽略掉某些重要的特征。
因此,在使用时需要根据具体情况进行调整和综合考虑。
3.2 示例
import numpy as np
from sklearn.feature_selection import VarianceThreshold# 生成示例数据集
X = np.array([[0, 2, 0, 3],[0, 1, 4, 3],[0, 1, 1, 3]])# 创建方差选择器对象,设定方差阈值
selector = VarianceThreshold(threshold=0.6)# 拟合数据并进行特征选择
X_selected = selector.fit_transform(X)# 查看选择后的特征
print("原始数据集:\n", X)
print("经过方差选择后的数据集:\n", X_selected)
print("选择的特征索引:", selector.get_support(indices=True))
print("选择的特征的方差:", selector.variances_)这段代码首先导入了NumPy库和VarianceThreshold类,然后创建了一个简单的数据集X。
接着,创建了一个VarianceThreshold对象,并将阈值设为0.6。然后,使用fit_transform方法拟合数据并进行特征选择。
最后,打印了原始数据集、经过特征选择后的数据集、选择的特征索引以及选择的特征的方差。
值得注意的是,方差选择法是一种单变量特征选择方法,它仅根据特征的方差来进行选择,因此不考虑特征与目标变量之间的关系。

四 互信息(Mutual Information):
互信息(Mutual Information)是一种常用于过滤式特征选择的方法,它用于衡量两个变量之间的相关性或依赖性。
在特征选择中,互信息用于衡量特征与目标变量之间的相关性,从而确定哪些特征对于预测目标变量是最有用的。
4.1 步骤
1 数据准备:
首先,准备包含特征和目标变量的数据集。
确保数据集经过清洗和预处理,以排除缺失值、异常值等干扰因素。
2 计算互信息:
对于每个特征,计算其与目标变量之间的互信息。
互信息是一种衡量两个变量之间关联性的方法,表示一个变量中包含的关于另一个变量的信息量。
通常使用以下公式计算两个随机变量X和Y之间的互信息:

3 特征排序:
根据计算得到的互信息值,对特征进行排序,将互信息值较大的特征排在前面。
互信息值越大表示特征与目标变量之间的相关性越强,对于模型预测目标变量更有帮助。
4 选择特征:
根据设定的阈值或者选择前N个特征的策略,确定最终的特征子集。
通常情况下,可以选择互信息值大于某个阈值的特征,或者选择互信息值排名前几的特征作为最终的特征子集。
互信息法适用于连续型和离散型特征,对于离散型特征需要使用离散化方法进行处理。
与方差选择法相比,互信息法考虑了特征之间的非线性关系,因此更适用于不同类型的数据集。
然而,互信息法也可能受到样本数量的影响,因此在使用时需要注意样本量的大小。
4.2 示例
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import mutual_info_classif
from sklearn.datasets import load_iris# 加载示例数据集
iris = load_iris()
X, y = iris.data, iris.target# 创建互信息选择器对象,设定选择的特征数量
selector = SelectKBest(mutual_info_classif, k=2)# 拟合数据并进行特征选择
X_selected = selector.fit_transform(X, y)# 查看选择后的特征
print("原始数据集的形状:", X.shape)
print("经过互信息选择后的数据集的形状:", X_selected.shape)
print("选择的特征索引:", selector.get_support(indices=True))这段代码首先导入了SelectKBest类和mutual_info_classif函数,以及load_iris函数来加载一个示例数据集。
然后,创建了一个SelectKBest对象,使用互信息函数mutual_info_classif作为评分函数,并设定选择的特征数量为2。
接着,使用fit_transform方法拟合数据并进行特征选择。
最后,打印了原始数据集的形状、经过特征选择后的数据集的形状以及选择的特征索引。
互信息法是一种基于信息论的特征选择方法,它可以衡量两个变量之间的信息共享程度,从而找到与目标变量具有高互信息的特征。
五 卡方检验(Chi-Square Test):
过滤式特征选择方法中的卡方检验(Chi-Square Test)法是用于衡量分类变量之间关联性的一种统计方法。
在机器学习中,卡方检验常用于评估特征与目标变量之间的独立性,从而确定哪些特征对于分类任务是最为相关的。
5.1 步骤
1 数据准备:
准备包含分类特征和目标变量的数据集。
确保数据集经过清洗和预处理,以排除缺失值、异常值等干扰因素。
2 构建列联表(Contingency Table):
对于每一对分类特征和目标变量,构建一个列联表。
列联表是一个二维表格,展示了两个分类变量之间的频数分布。
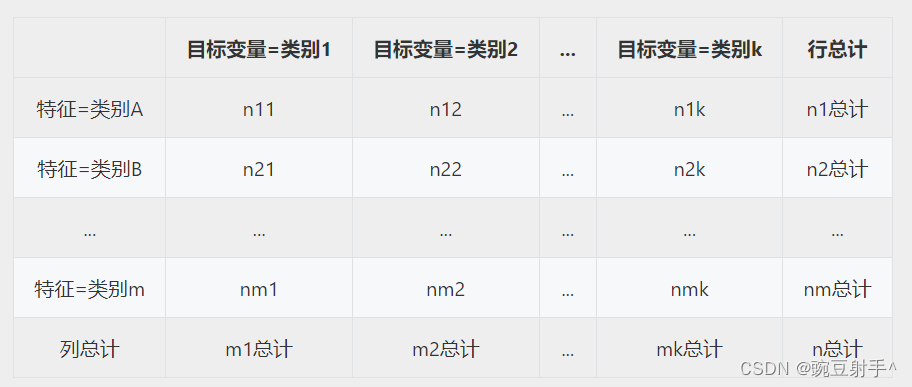
3 计算期望频数(Expected Frequencies):
对于每个单元格,计算其期望频数,即在特征和目标变量独立的情况下,该单元格的预期值。
4 计算卡方统计量:
对于每个单元格,计算卡方统计量(Chi-Square Statistic):
5 计算自由度:
计算自由度,自由度的计算为 ( df = (m-1) \times (k-1) ),其中m是特征的类别数,k是目标变量的类别数。
6 确定显著性水平:
选择显著性水平(通常设定为0.05),并根据卡方分布表查找临界值。
比较计算得到的卡方统计量与临界值,以判断特征与目标变量之间是否存在显著性关联。
7 特征选择:
根据卡方统计量的显著性水平,选择特征。
通常情况下,如果卡方统计量大于临界值,则认为特征与目标变量之间存在显著性关联,可以选择保留该特征。
卡方检验法主要适用于分类问题,特别是当特征和目标变量都是分类变量时。
需要注意的是,卡方检验法基于对独立性的假设,因此在使用时需要注意其局限性,特别是在特征之间存在非线性关系或者其他复杂关系的情况下。
5.2 示例
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.datasets import load_iris# 加载示例数据集
iris = load_iris()
X, y = iris.data, iris.target# 创建卡方选择器对象,设定选择的特征数量
selector = SelectKBest(chi2, k=2)# 拟合数据并进行特征选择
X_selected = selector.fit_transform(X, y)# 查看选择后的特征
print("原始数据集的形状:", X.shape)
print("经过卡方检验选择后的数据集的形状:", X_selected.shape)
print("选择的特征索引:", selector.get_support(indices=True))这段代码首先导入了SelectKBest类和chi2函数,以及load_iris函数来加载一个示例数据集。
然后,创建了一个SelectKBest对象,使用卡方检验函数chi2作为评分函数,并设定选择的特征数量为2。
接着,使用fit_transform方法拟合数据并进行特征选择。
最后,打印了原始数据集的形状、经过特征选择后的数据集的形状以及选择的特征索引。
卡方检验法是一种用于衡量两个分类变量之间关联性的统计方法,用于特征选择时可以帮助找到与目标变量之间显著关联的特征。
六 皮尔逊相关系数(Pearson Correlation Coefficient):
过滤式特征选择中的皮尔逊相关系数法是一种用于衡量连续型特征之间线性关系的方法。
它通过计算特征与目标变量之间的皮尔逊相关系数,来评估特征与目标变量之间的线性相关性。
6.1 步骤
1 数据准备:
准备包含连续型特征和目标变量的数据集。
确保数据集经过清洗和预处理,以排除缺失值、异常值等干扰因素。
2 计算皮尔逊相关系数:
对于每个特征,计算其与目标变量之间的皮尔逊相关系数。
皮尔逊相关系数(Pearson correlation coefficient)是一个衡量两个变量之间线性关系强度和方向的统计量。
3 确定特征的重要性:
根据计算得到的皮尔逊相关系数的绝对值大小,确定特征与目标变量之间的线性关系强度。
绝对值越大表示关系越强,正负号表示关系的方向(正相关或负相关)。
4 设定阈值:
根据问题的具体情况,可以设定一个相关系数的阈值。
超过该阈值的特征被认为与目标变量具有较强的线性关系。
5 特征选择:
根据计算得到的皮尔逊相关系数,选择与目标变量相关性较强的特征。
可以选择保留超过阈值的特征,或者根据相关系数的大小排序选择前k个特征。
需要注意的是,皮尔逊相关系数主要适用于线性关系的检测,对于非线性关系的敏感度相对较低。
在存在非线性关系的情况下,其他非线性关系的度量方法可能更为适用。此外,相关系数是一种衡量变量之间关系的方法,不一定能捕捉到所有与目标变量的复杂关系。
因此,在使用过滤式特征选择方法时,需谨慎考虑特征之间的实际关系和问题的特点。
6.2 示例
import numpy as np
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression# 生成示例数据集
np.random.seed(0)
X = np.random.rand(100, 5) # 100个样本,5个特征
y = X[:, 0] + 2 * X[:, 1] + np.random.normal(0, 0.1, 100) # y与前两个特征相关# 创建皮尔逊相关系数选择器对象,设定选择的特征数量
selector = SelectKBest(f_regression, k=2)# 拟合数据并进行特征选择
X_selected = selector.fit_transform(X, y)# 查看选择后的特征
print("原始数据集的形状:", X.shape)
print("经过皮尔逊相关系数选择后的数据集的形状:", X_selected.shape)
print("选择的特征索引:", selector.get_support(indices=True))这段代码首先导入了SelectKBest类和f_regression函数。
然后,生成了一个简单的示例数据集X,其中包含100个样本和5个特征,目标变量y与前两个特征相关。
接着,创建了一个SelectKBest对象,使用f_regression函数作为评分函数,并设定选择的特征数量为2。
然后,使用fit_transform方法拟合数据并进行特征选择。
最后,打印了原始数据集的形状、经过特征选择后的数据集的形状以及选择的特征索引。
皮尔逊相关系数法是一种用于衡量两个连续变量之间线性相关性的方法,在特征选择中可以帮助找到与目标变量高度相关的特征。

七 信息增益(Information Gain):
信息增益法是一种常用的过滤式特征选择方法,通常用于处理分类问题。
它通过计算特征与目标变量之间的信息增益来评估特征的重要性。
7.1 步骤
1 数据准备:
准备包含特征和目标变量的标记数据集。
确保数据集已经经过清洗和预处理,特征已经被编码为可用于计算信息增益的形式(例如,数值型特征可能需要进行离散化)。
2 计算目标变量的初始熵:
首先,计算目标变量的初始熵,即在未进行特征划分之前的不确定性度量。
3 计算每个特征的信息增益:
对于每个特征,计算其与目标变量之间的信息增益。
信息增益是特征对目标变量带来的不确定性减少程度。
其计算公式为:
[ IG(X) = H(Y) - H(Y|X) ]
其中,(H(Y)) 是目标变量的初始熵,(H(Y|X)) 是在特征 (X) 条件下目标变量的条件熵,表示在特征 (X) 已知的情况下,目标变量的不确定性。
4 选择信息增益最大的特征:
从所有特征中选择具有最大信息增益的特征作为最优特征。
这意味着该特征能够在最大程度上减少目标变量的不确定性。
5 重复步骤3和步骤4:
可以选择重复计算信息增益,并选择下一个最优特征。
这样可以建立一个特征选择的顺序,可以选择特定数量的特征或直到满足某个条件为止。
6 特征选择:
根据计算得到的信息增益,选择具有最大信息增益的特征或按照一定的阈值选择重要性较高的特征。
这些特征被认为对于预测目标变量是最具有信息量的。
信息增益法是一种简单而直观的特征选择方法,特别适用于处理分类问题,并且对于离散型目标变量更为有效。然而,它也有一些局限性,例如对于连续型特征的处理可能不够优雅,而且可能会忽略特征之间的相关性。
7.2 示例
import numpy as np
from sklearn.feature_selection import mutual_info_classif# 生成示例数据集
np.random.seed(0)
X = np.random.rand(100, 5) # 100个样本,5个特征
y = np.random.randint(2, size=100) # 二分类目标变量# 计算每个特征的信息增益
information_gains = []
for feature_idx in range(X.shape[1]):# 计算特征与目标变量的互信息mutual_info = mutual_info_classif(X[:, feature_idx].reshape(-1, 1), y)[0]# 计算信息增益(在这个简化的例子中,我们假设类别的熵为常数)information_gain = mutual_infoinformation_gains.append(information_gain)# 根据信息增益对特征进行排序
selected_feature_indices = np.argsort(information_gains)[::-1][:2]# 查看选择后的特征
X_selected = X[:, selected_feature_indices]
print("原始数据集的形状:", X.shape)
print("经过信息增益选择后的数据集的形状:", X_selected.shape)
print("选择的特征索引:", selected_feature_indices)这段代码首先导入了mutual_info_classif函数,然后生成了一个简单的示例数据集。
接着,对每个特征计算了其与目标变量的互信息,然后将特征根据信息增益进行排序,选择了排名前两的特征。
最后,打印了原始数据集的形状、经过特征选择后的数据集的形状以及选择的特征索引。
请注意,这只是一个简单的演示,实际应用中可能需要更复杂的方法,并且使用决策树等模型时,特征选择往往是嵌入式的一部分。
八 各种方法的优缺点及适用场景
以下是几种常见的过滤式特征选择方法及其优缺点以及适用场景:
8.1 方差选择法:
优点:
简单易实现,仅需计算特征的方差即可。
适用于在特征方差较小的情况下快速识别并删除低方差特征,可以减少数据维度。
缺点:
只考虑了特征的方差,忽略了特征与目标变量之间的关系。
对特征之间的相关性不敏感。
适用场景:
当特征方差较小或者特征稀疏时,可以考虑使用方差选择法。
8.2 互信息法:
优点:
考虑了特征与目标变量之间的非线性关系。
对于特征与目标变量之间的任何关系形式都是一种通用方法。
缺点:
计算复杂度较高,需要对每个特征进行计算,因此在大规模数据集上可能效率较低。
在数据集较小的情况下可能过拟合。
适用场景:
数据集规模较小且特征与目标变量之间的关系复杂时,可以考虑使用互信息法。
8.3 卡方检验法:
优点:
适用于分类问题,可以快速识别特征与目标变量之间的相关性。
对类别型的特征选择效果较好。
缺点:
对于连续型特征不太适用。
对特征之间的相关性不敏感。
适用场景:
在处理分类问题并且特征为类别型变量时,可以考虑使用卡方检验法。
8.4 皮尔逊相关系数法:
优点:
能够有效衡量特征与目标变量之间的线性相关性。
简单易懂,计算速度较快。
缺点:
仅适用于线性关系的特征选择,对于非线性关系效果较差。
对异常值敏感。
适用场景:
当特征与目标变量之间存在线性关系,并且数据集没有太多异常值时,可以考虑使用皮尔逊相关系数法。
8.5 信息增益法:
优点:
适用于分类问题,可以在决策树等树型模型中进行特征选择。
考虑了特征与目标变量之间的信息量。
缺点:
通常需要使用决策树等模型来计算信息增益,计算复杂度较高。
对连续型特征不太适用。
适用场景:
在处理分类问题且希望使用决策树等树型模型时,可以考虑使用信息增益法。
总结
特征选择在机器学习中扮演着至关重要的角色,它可以提高模型的效率、降低过拟合风险,并且在处理大规模数据集时可以减少计算成本。
本文介绍了过滤式特征选择的几种常见方法,包括方差选择法、互信息、卡方检验、皮尔逊相关系数和信息增益。
通过详细讨论每种方法的步骤和示例,读者可以更加深入地理解这些方法的原理和应用场景。
此外,我们还分析了各种方法的优缺点,帮助读者根据实际情况选择最合适的特征选择方法。
在实际应用中,需要综合考虑数据集的特点、模型的要求以及计算资源等因素,来选择最适合的特征选择方法,从而提高模型的性能和泛化能力。
通过合理的特征选择,我们可以更好地理解数据、提取数据的有效信息,并建立更加精确和高效的机器学习模型。

这篇文章到这里就结束了
谢谢大家的阅读!
如果觉得这篇博客对你有用的话,别忘记三连哦。
我是甜美的江,让我们我们下次再见


相关文章:
【机器学习】特征选择之过滤式特征选择法
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进…...
C#_扩展方法
简述: 扩展方法所属类必需是静态类(类名依据规范通常为XXXExtension,XXX为被扩展类)扩展方法必需是公有的静态方法扩展方法的首个参数由this修饰,参数类型为被扩展类型 示例: static class DoubleExtens…...
LeetCode 热题 100 | 二叉树(一)
目录 1 基础知识 1.1 先序遍历 1.2 中序遍历 1.3 后序遍历 2 94. 二叉树的中序遍历 3 104. 二叉树的最大深度 4 226. 翻转二叉树 5 101. 对称二叉树 菜鸟做题,语言是 C 1 基础知识 二叉树常见的遍历方式有: 先序遍历中序遍历后序遍历…...

k8s之nodelocaldns与CoreDNS组件
在 Kubernetes 集群中,通常是先通过 NodeLocal DNS Cache 进行域名解析,如果 NodeLocal DNS Cache 没有找到对应的域名解析结果,才会向 CoreDNS 发起请求。在部署层面上看nodelocaldns会在每个节点上运行一个 DNS 缓存服务,而Core…...

Java中的访问修饰符
Java中的访问修饰符 java 提供四种访问控制修饰符号,用于控制方法和属性(成员变量)的访问权限: 公开级别:用 public 修饰,对外公开受保护级别:用 protected 修饰,对子类和同一个包中的类公开默认级别:没有修饰符号,向同一个包的类公开私有级别:用 private 修饰,只…...
【论文解读】transformer小目标检测综述
目录 一、简要介绍 二、研究背景 三、用于小目标检测的transformer 3.1 Object Representation 3.2 Fast Attention for High-Resolution or Multi-Scale Feature Maps 3.3 Fully Transformer-Based Detectors 3.4 Architecture and Block Modifications 3.6 Improved …...
springboot215基于springboot技术的美食烹饪互动平台的设计与实现
美食烹饪互动平台的设计与实现 摘 要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统美食信息管理难度大&…...

Rust核心:【所有权】相关知识点
rust在内存资源管理上采用了(先进优秀?算吗)但特立独行的设计思路:所有权。这是rust的核心,贯穿在整个rust语言的方方面面,并以此为基点来重新思考和重构软件开发体系。 涉及到的概念点:借用&am…...
单片机05__串口USART通信__按键控制向上位机传输字符串
串口USART通信 通用UART介绍 1.通信的概念 计算机与外界进行信息交换的过程称之为通信。 在通信的过程中,通信双方都需要遵守的规则称之为通信协议。 硬件协议:将数据以什么样的方式传输过去 软件协议:将数据以什么样的顺序传输过去 2.常用…...
实习日志30
概要 高拍仪硬件通信原理,WebSocket源码解析(JavaScript) WebSocket 是 HTML5 开始提供的一种在单个 TCP 连接上进行全双工通讯的协议。 WebSocket 使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据…...

【MySQL】探索表结构、数据类型和基本操作
表、记录、字段 数据库的E-R(entity-relationship,实体-关系)模型中有三个主要概念: 实体集 、 属性 、 关系集 。 一个实体集对应于数据库中的一个表,一个实体则对应于数据库表 中的一行,也称为一条记录。…...

解决采集时使用selenium被屏蔽的办法
解决采集时使用selenium被屏蔽的办法 实用seleniumbase uc模式 from seleniumbase import Driver driver Driver(ucTrue) # 使用UC模式UC模式是基于undetected-chromedriver 但做了一些优化更新,使用起来更方便 官方例子: from seleniumbase import …...

stream流-> 判定 + 过滤 + 收集
List<HotArticleVo> hotArticleVos hotArticleVoList .stream() .filter(x -> x.getChannelId().equals(wmChannel.getId())).collect(Collectors.toList()); 使用Java 8中的Stream API对一个名为hotArticleVoList的列表进行过滤操作,筛选出符合指定条件…...

人工智能在测绘行业的应用与挑战
目录 一、背景 二、AI在测绘行业的应用方向 1. 自动化特征提取 2. 数据处理与分析 3. 无人机测绘 4. 智能导航与路径规划 5. 三维建模与可视化 6. 地理信息系统(GIS)智能化 三、发展前景 1. 技术融合 2. 精准测绘 3. 智慧城市建设 4. 可…...

四、分类算法 - 随机森林
目录 1、集成学习方法 2、随机森林 3、随机森林原理 4、API 5、总结 sklearn转换器和估算器KNN算法模型选择和调优朴素贝叶斯算法决策树随机森林 1、集成学习方法 2、随机森林 3、随机森林原理 4、API 5、总结...

pytorch -- DataLoader
定义 提供了给定数据集的迭代器 torch.utils.data.DataLoader(dataset, batch_size1, 每次拿多少数据 shuffleNone, 是否打乱 samplerNone, batch_samplerNone, num_workers0, 多进程(加载数据时采用)默认是0,使用主进程加载数据 collate_fnNone, p…...

【MySQL面试复习】索引创建的原则有哪些?
系列文章目录 在MySQL中,如何定位慢查询? 发现了某个SQL语句执行很慢,如何进行分析? 了解过索引吗?(索引的底层原理)/B 树和B树的区别是什么? 什么是聚簇索引(聚集索引)和非聚簇索引…...

四种主流的prompt框架
省流版: 文章介绍了在使用GPT时的四种prompt框架,有利于使用者打磨提问风格,与GPT进行更好的交互以提高生产力,能帮助大家有效提高工作效率~ 创作不易,如果对你有帮助的话,还请三连支持~ 想要使用Prompt…...
 E. Matrix Problem(费用流))
Educational Codeforces Round 160 (Rated for Div. 2) E. Matrix Problem(费用流)
原题链接:E. Matrix Problem 题目大意: 给出一个 n n n 行 m m m 列的 0 / 1 0/1 0/1 矩阵,再给出一些限制条件:一个长为 n n n 的数组 a a a,和一个长为 m m m 的数组 b b b 。 其中 a i a_{i} ai 表示第 …...
基于SpringBoot的气象数据监测分析大屏
项目描述 临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。这里根据疫情当下,你想解决的问…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...
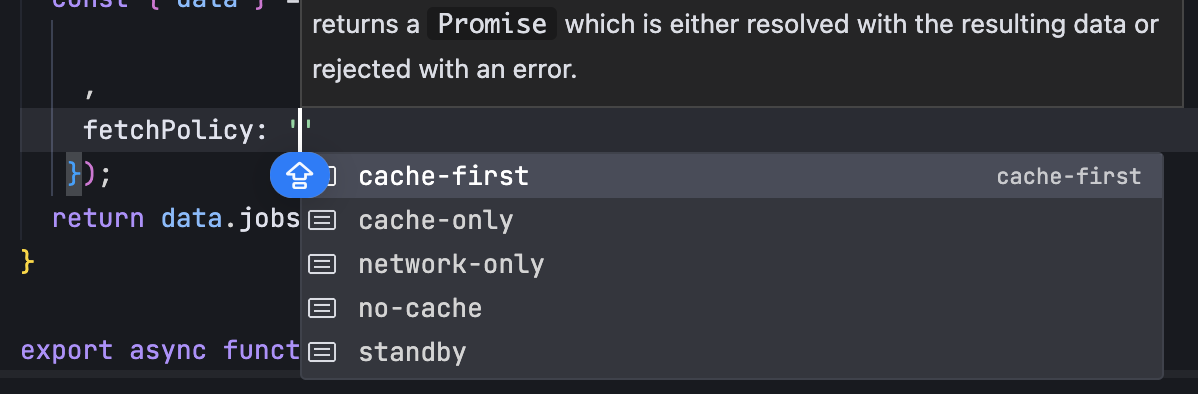
GraphQL 实战篇:Apollo Client 配置与缓存
GraphQL 实战篇:Apollo Client 配置与缓存 上一篇:GraphQL 入门篇:基础查询语法 依旧和上一篇的笔记一样,主实操,没啥过多的细节讲解,代码具体在: https://github.com/GoldenaArcher/graphql…...