【深度学习笔记】3_14 正向传播、反向传播和计算图
3.14 正向传播、反向传播和计算图
前面几节里我们使用了小批量随机梯度下降的优化算法来训练模型。在实现中,我们只提供了模型的正向传播(forward propagation)的计算,即对输入计算模型输出,然后通过autograd模块来调用系统自动生成的backward函数计算梯度。基于反向传播(back-propagation)算法的自动求梯度极大简化了深度学习模型训练算法的实现。本节我们将使用数学和计算图(computational graph)两个方式来描述正向传播和反向传播。具体来说,我们将以带 L 2 L_2 L2范数正则化的含单隐藏层的多层感知机为样例模型解释正向传播和反向传播。
3.14.1 正向传播
正向传播是指对神经网络沿着从输入层到输出层的顺序,依次计算并存储模型的中间变量(包括输出)。为简单起见,假设输入是一个特征为 x ∈ R d \boldsymbol{x} \in \mathbb{R}^d x∈Rd的样本,且不考虑偏差项,那么中间变量
z = W ( 1 ) x , \boldsymbol{z} = \boldsymbol{W}^{(1)} \boldsymbol{x}, z=W(1)x,
其中 W ( 1 ) ∈ R h × d \boldsymbol{W}^{(1)} \in \mathbb{R}^{h \times d} W(1)∈Rh×d是隐藏层的权重参数。把中间变量 z ∈ R h \boldsymbol{z} \in \mathbb{R}^h z∈Rh输入按元素运算的激活函数 ϕ \phi ϕ后,将得到向量长度为 h h h的隐藏层变量
h = ϕ ( z ) . \boldsymbol{h} = \phi (\boldsymbol{z}). h=ϕ(z).
隐藏层变量 h \boldsymbol{h} h也是一个中间变量。假设输出层参数只有权重 W ( 2 ) ∈ R q × h \boldsymbol{W}^{(2)} \in \mathbb{R}^{q \times h} W(2)∈Rq×h,可以得到向量长度为 q q q的输出层变量
o = W ( 2 ) h . \boldsymbol{o} = \boldsymbol{W}^{(2)} \boldsymbol{h}. o=W(2)h.
假设损失函数为 ℓ \ell ℓ,且样本标签为 y y y,可以计算出单个数据样本的损失项
L = ℓ ( o , y ) . L = \ell(\boldsymbol{o}, y). L=ℓ(o,y).
根据 L 2 L_2 L2范数正则化的定义,给定超参数 λ \lambda λ,正则化项即
s = λ 2 ( ∥ W ( 1 ) ∥ F 2 + ∥ W ( 2 ) ∥ F 2 ) , s = \frac{\lambda}{2} \left(\|\boldsymbol{W}^{(1)}\|_F^2 + \|\boldsymbol{W}^{(2)}\|_F^2\right), s=2λ(∥W(1)∥F2+∥W(2)∥F2),
其中矩阵的Frobenius范数等价于将矩阵变平为向量后计算 L 2 L_2 L2范数。最终,模型在给定的数据样本上带正则化的损失为
J = L + s . J = L + s. J=L+s.
我们将 J J J称为有关给定数据样本的目标函数,并在以下的讨论中简称目标函数。
3.14.2 正向传播的计算图
我们通常绘制计算图来可视化运算符和变量在计算中的依赖关系。图3.6绘制了本节中样例模型正向传播的计算图,其中左下角是输入,右上角是输出。可以看到,图中箭头方向大多是向右和向上,其中方框代表变量,圆圈代表运算符,箭头表示从输入到输出之间的依赖关系。

3.14.3 反向传播
反向传播指的是计算神经网络参数梯度的方法。总的来说,反向传播依据微积分中的链式法则,沿着从输出层到输入层的顺序,依次计算并存储目标函数有关神经网络各层的中间变量以及参数的梯度。对输入或输出 X , Y , Z \mathsf{X}, \mathsf{Y}, \mathsf{Z} X,Y,Z为任意形状张量的函数 Y = f ( X ) \mathsf{Y}=f(\mathsf{X}) Y=f(X)和 Z = g ( Y ) \mathsf{Z}=g(\mathsf{Y}) Z=g(Y),通过链式法则,我们有
∂ Z ∂ X = prod ( ∂ Z ∂ Y , ∂ Y ∂ X ) , \frac{\partial \mathsf{Z}}{\partial \mathsf{X}} = \text{prod}\left(\frac{\partial \mathsf{Z}}{\partial \mathsf{Y}}, \frac{\partial \mathsf{Y}}{\partial \mathsf{X}}\right), ∂X∂Z=prod(∂Y∂Z,∂X∂Y),
其中 prod \text{prod} prod运算符将根据两个输入的形状,在必要的操作(如转置和互换输入位置)后对两个输入做乘法。
回顾一下本节中样例模型,它的参数是 W ( 1 ) \boldsymbol{W}^{(1)} W(1)和 W ( 2 ) \boldsymbol{W}^{(2)} W(2),因此反向传播的目标是计算 ∂ J / ∂ W ( 1 ) \partial J/\partial \boldsymbol{W}^{(1)} ∂J/∂W(1)和 ∂ J / ∂ W ( 2 ) \partial J/\partial \boldsymbol{W}^{(2)} ∂J/∂W(2)。我们将应用链式法则依次计算各中间变量和参数的梯度,其计算次序与前向传播中相应中间变量的计算次序恰恰相反。首先,分别计算目标函数 J = L + s J=L+s J=L+s有关损失项 L L L和正则项 s s s的梯度
∂ J ∂ L = 1 , ∂ J ∂ s = 1. \frac{\partial J}{\partial L} = 1, \quad \frac{\partial J}{\partial s} = 1. ∂L∂J=1,∂s∂J=1.
其次,依据链式法则计算目标函数有关输出层变量的梯度 ∂ J / ∂ o ∈ R q \partial J/\partial \boldsymbol{o} \in \mathbb{R}^q ∂J/∂o∈Rq:
∂ J ∂ o = prod ( ∂ J ∂ L , ∂ L ∂ o ) = ∂ L ∂ o . \frac{\partial J}{\partial \boldsymbol{o}} = \text{prod}\left(\frac{\partial J}{\partial L}, \frac{\partial L}{\partial \boldsymbol{o}}\right) = \frac{\partial L}{\partial \boldsymbol{o}}. ∂o∂J=prod(∂L∂J,∂o∂L)=∂o∂L.
接下来,计算正则项有关两个参数的梯度:
∂ s ∂ W ( 1 ) = λ W ( 1 ) , ∂ s ∂ W ( 2 ) = λ W ( 2 ) . \frac{\partial s}{\partial \boldsymbol{W}^{(1)}} = \lambda \boldsymbol{W}^{(1)},\quad\frac{\partial s}{\partial \boldsymbol{W}^{(2)}} = \lambda \boldsymbol{W}^{(2)}. ∂W(1)∂s=λW(1),∂W(2)∂s=λW(2).
现在,我们可以计算最靠近输出层的模型参数的梯度 ∂ J / ∂ W ( 2 ) ∈ R q × h \partial J/\partial \boldsymbol{W}^{(2)} \in \mathbb{R}^{q \times h} ∂J/∂W(2)∈Rq×h。依据链式法则,得到
∂ J ∂ W ( 2 ) = prod ( ∂ J ∂ o , ∂ o ∂ W ( 2 ) ) + prod ( ∂ J ∂ s , ∂ s ∂ W ( 2 ) ) = ∂ J ∂ o h ⊤ + λ W ( 2 ) . \frac{\partial J}{\partial \boldsymbol{W}^{(2)}} = \text{prod}\left(\frac{\partial J}{\partial \boldsymbol{o}}, \frac{\partial \boldsymbol{o}}{\partial \boldsymbol{W}^{(2)}}\right) + \text{prod}\left(\frac{\partial J}{\partial s}, \frac{\partial s}{\partial \boldsymbol{W}^{(2)}}\right) = \frac{\partial J}{\partial \boldsymbol{o}} \boldsymbol{h}^\top + \lambda \boldsymbol{W}^{(2)}. ∂W(2)∂J=prod(∂o∂J,∂W(2)∂o)+prod(∂s∂J,∂W(2)∂s)=∂o∂Jh⊤+λW(2).
沿着输出层向隐藏层继续反向传播,隐藏层变量的梯度 ∂ J / ∂ h ∈ R h \partial J/\partial \boldsymbol{h} \in \mathbb{R}^h ∂J/∂h∈Rh可以这样计算:
∂ J ∂ h = prod ( ∂ J ∂ o , ∂ o ∂ h ) = W ( 2 ) ⊤ ∂ J ∂ o . \frac{\partial J}{\partial \boldsymbol{h}} = \text{prod}\left(\frac{\partial J}{\partial \boldsymbol{o}}, \frac{\partial \boldsymbol{o}}{\partial \boldsymbol{h}}\right) = {\boldsymbol{W}^{(2)}}^\top \frac{\partial J}{\partial \boldsymbol{o}}. ∂h∂J=prod(∂o∂J,∂h∂o)=W(2)⊤∂o∂J.
由于激活函数 ϕ \phi ϕ是按元素运算的,中间变量 z \boldsymbol{z} z的梯度 ∂ J / ∂ z ∈ R h \partial J/\partial \boldsymbol{z} \in \mathbb{R}^h ∂J/∂z∈Rh的计算需要使用按元素乘法符 ⊙ \odot ⊙:
∂ J ∂ z = prod ( ∂ J ∂ h , ∂ h ∂ z ) = ∂ J ∂ h ⊙ ϕ ′ ( z ) . \frac{\partial J}{\partial \boldsymbol{z}} = \text{prod}\left(\frac{\partial J}{\partial \boldsymbol{h}}, \frac{\partial \boldsymbol{h}}{\partial \boldsymbol{z}}\right) = \frac{\partial J}{\partial \boldsymbol{h}} \odot \phi'\left(\boldsymbol{z}\right). ∂z∂J=prod(∂h∂J,∂z∂h)=∂h∂J⊙ϕ′(z).
最终,我们可以得到最靠近输入层的模型参数的梯度 ∂ J / ∂ W ( 1 ) ∈ R h × d \partial J/\partial \boldsymbol{W}^{(1)} \in \mathbb{R}^{h \times d} ∂J/∂W(1)∈Rh×d。依据链式法则,得到
∂ J ∂ W ( 1 ) = prod ( ∂ J ∂ z , ∂ z ∂ W ( 1 ) ) + prod ( ∂ J ∂ s , ∂ s ∂ W ( 1 ) ) = ∂ J ∂ z x ⊤ + λ W ( 1 ) . \frac{\partial J}{\partial \boldsymbol{W}^{(1)}} = \text{prod}\left(\frac{\partial J}{\partial \boldsymbol{z}}, \frac{\partial \boldsymbol{z}}{\partial \boldsymbol{W}^{(1)}}\right) + \text{prod}\left(\frac{\partial J}{\partial s}, \frac{\partial s}{\partial \boldsymbol{W}^{(1)}}\right) = \frac{\partial J}{\partial \boldsymbol{z}} \boldsymbol{x}^\top + \lambda \boldsymbol{W}^{(1)}. ∂W(1)∂J=prod(∂z∂J,∂W(1)∂z)+prod(∂s∂J,∂W(1)∂s)=∂z∂Jx⊤+λW(1).
3.14.4 训练深度学习模型
在训练深度学习模型时,正向传播和反向传播之间相互依赖。下面我们仍然以本节中的样例模型分别阐述它们之间的依赖关系。
一方面,正向传播的计算可能依赖于模型参数的当前值,而这些模型参数是在反向传播的梯度计算后通过优化算法迭代的。例如,计算正则化项 s = ( λ / 2 ) ( ∥ W ( 1 ) ∥ F 2 + ∥ W ( 2 ) ∥ F 2 ) s = (\lambda/2) \left(\|\boldsymbol{W}^{(1)}\|_F^2 + \|\boldsymbol{W}^{(2)}\|_F^2\right) s=(λ/2)(∥W(1)∥F2+∥W(2)∥F2)依赖模型参数 W ( 1 ) \boldsymbol{W}^{(1)} W(1)和 W ( 2 ) \boldsymbol{W}^{(2)} W(2)的当前值,而这些当前值是优化算法最近一次根据反向传播算出梯度后迭代得到的。
另一方面,反向传播的梯度计算可能依赖于各变量的当前值,而这些变量的当前值是通过正向传播计算得到的。举例来说,参数梯度 ∂ J / ∂ W ( 2 ) = ( ∂ J / ∂ o ) h ⊤ + λ W ( 2 ) \partial J/\partial \boldsymbol{W}^{(2)} = (\partial J / \partial \boldsymbol{o}) \boldsymbol{h}^\top + \lambda \boldsymbol{W}^{(2)} ∂J/∂W(2)=(∂J/∂o)h⊤+λW(2)的计算需要依赖隐藏层变量的当前值 h \boldsymbol{h} h。这个当前值是通过从输入层到输出层的正向传播计算并存储得到的。
因此,在模型参数初始化完成后,我们交替地进行正向传播和反向传播,并根据反向传播计算的梯度迭代模型参数。既然我们在反向传播中使用了正向传播中计算得到的中间变量来避免重复计算,那么这个复用也导致正向传播结束后不能立即释放中间变量内存。这也是训练要比预测占用更多内存的一个重要原因。另外需要指出的是,这些中间变量的个数大体上与网络层数线性相关,每个变量的大小跟批量大小和输入个数也是线性相关的,它们是导致较深的神经网络使用较大批量训练时更容易超内存的主要原因。
小结
- 正向传播沿着从输入层到输出层的顺序,依次计算并存储神经网络的中间变量。
- 反向传播沿着从输出层到输入层的顺序,依次计算并存储神经网络中间变量和参数的梯度。
- 在训练深度学习模型时,正向传播和反向传播相互依赖。
注:本节与原书基本相同,原书传送门
相关文章:
【深度学习笔记】3_14 正向传播、反向传播和计算图
3.14 正向传播、反向传播和计算图 前面几节里我们使用了小批量随机梯度下降的优化算法来训练模型。在实现中,我们只提供了模型的正向传播(forward propagation)的计算,即对输入计算模型输出,然后通过autograd模块来调…...
Jenkins详解
目录 一、Jenkins CI/CD 1、 Jenkins CI/CD 流程图 2、介绍 Jenkins 1、Jenkins概念 2、Jenkins目的 3、特性 4、产品发布流程 3、安装Jenkins 1、安装JDK 2、安装tomcat 3.安装maven 4安装jenkins 5.启动tomcat,并页面访问 5.添加节点 一、Jenkins CI/…...

Java8 Stream API 详解:流式编程进行数据处理
🏷️个人主页:牵着猫散步的鼠鼠 🏷️系列专栏:Java全栈-专栏 🏷️个人学习笔记,若有缺误,欢迎评论区指正 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默&…...

【机器学习】特征选择之过滤式特征选择法
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进…...
C#_扩展方法
简述: 扩展方法所属类必需是静态类(类名依据规范通常为XXXExtension,XXX为被扩展类)扩展方法必需是公有的静态方法扩展方法的首个参数由this修饰,参数类型为被扩展类型 示例: static class DoubleExtens…...
LeetCode 热题 100 | 二叉树(一)
目录 1 基础知识 1.1 先序遍历 1.2 中序遍历 1.3 后序遍历 2 94. 二叉树的中序遍历 3 104. 二叉树的最大深度 4 226. 翻转二叉树 5 101. 对称二叉树 菜鸟做题,语言是 C 1 基础知识 二叉树常见的遍历方式有: 先序遍历中序遍历后序遍历…...

k8s之nodelocaldns与CoreDNS组件
在 Kubernetes 集群中,通常是先通过 NodeLocal DNS Cache 进行域名解析,如果 NodeLocal DNS Cache 没有找到对应的域名解析结果,才会向 CoreDNS 发起请求。在部署层面上看nodelocaldns会在每个节点上运行一个 DNS 缓存服务,而Core…...

Java中的访问修饰符
Java中的访问修饰符 java 提供四种访问控制修饰符号,用于控制方法和属性(成员变量)的访问权限: 公开级别:用 public 修饰,对外公开受保护级别:用 protected 修饰,对子类和同一个包中的类公开默认级别:没有修饰符号,向同一个包的类公开私有级别:用 private 修饰,只…...
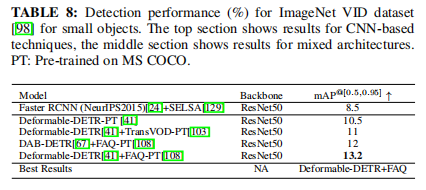
【论文解读】transformer小目标检测综述
目录 一、简要介绍 二、研究背景 三、用于小目标检测的transformer 3.1 Object Representation 3.2 Fast Attention for High-Resolution or Multi-Scale Feature Maps 3.3 Fully Transformer-Based Detectors 3.4 Architecture and Block Modifications 3.6 Improved …...
springboot215基于springboot技术的美食烹饪互动平台的设计与实现
美食烹饪互动平台的设计与实现 摘 要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统美食信息管理难度大&…...

Rust核心:【所有权】相关知识点
rust在内存资源管理上采用了(先进优秀?算吗)但特立独行的设计思路:所有权。这是rust的核心,贯穿在整个rust语言的方方面面,并以此为基点来重新思考和重构软件开发体系。 涉及到的概念点:借用&am…...
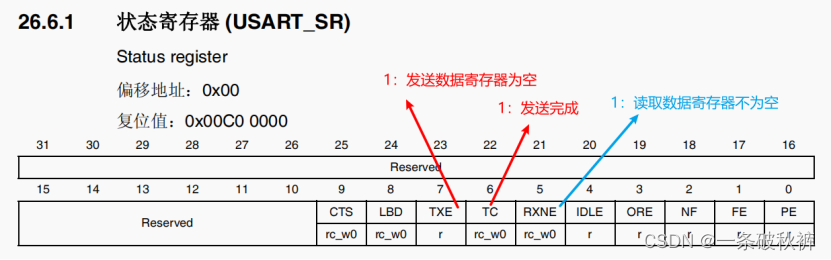
单片机05__串口USART通信__按键控制向上位机传输字符串
串口USART通信 通用UART介绍 1.通信的概念 计算机与外界进行信息交换的过程称之为通信。 在通信的过程中,通信双方都需要遵守的规则称之为通信协议。 硬件协议:将数据以什么样的方式传输过去 软件协议:将数据以什么样的顺序传输过去 2.常用…...
实习日志30
概要 高拍仪硬件通信原理,WebSocket源码解析(JavaScript) WebSocket 是 HTML5 开始提供的一种在单个 TCP 连接上进行全双工通讯的协议。 WebSocket 使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据…...

【MySQL】探索表结构、数据类型和基本操作
表、记录、字段 数据库的E-R(entity-relationship,实体-关系)模型中有三个主要概念: 实体集 、 属性 、 关系集 。 一个实体集对应于数据库中的一个表,一个实体则对应于数据库表 中的一行,也称为一条记录。…...

解决采集时使用selenium被屏蔽的办法
解决采集时使用selenium被屏蔽的办法 实用seleniumbase uc模式 from seleniumbase import Driver driver Driver(ucTrue) # 使用UC模式UC模式是基于undetected-chromedriver 但做了一些优化更新,使用起来更方便 官方例子: from seleniumbase import …...

stream流-> 判定 + 过滤 + 收集
List<HotArticleVo> hotArticleVos hotArticleVoList .stream() .filter(x -> x.getChannelId().equals(wmChannel.getId())).collect(Collectors.toList()); 使用Java 8中的Stream API对一个名为hotArticleVoList的列表进行过滤操作,筛选出符合指定条件…...

人工智能在测绘行业的应用与挑战
目录 一、背景 二、AI在测绘行业的应用方向 1. 自动化特征提取 2. 数据处理与分析 3. 无人机测绘 4. 智能导航与路径规划 5. 三维建模与可视化 6. 地理信息系统(GIS)智能化 三、发展前景 1. 技术融合 2. 精准测绘 3. 智慧城市建设 4. 可…...

四、分类算法 - 随机森林
目录 1、集成学习方法 2、随机森林 3、随机森林原理 4、API 5、总结 sklearn转换器和估算器KNN算法模型选择和调优朴素贝叶斯算法决策树随机森林 1、集成学习方法 2、随机森林 3、随机森林原理 4、API 5、总结...

pytorch -- DataLoader
定义 提供了给定数据集的迭代器 torch.utils.data.DataLoader(dataset, batch_size1, 每次拿多少数据 shuffleNone, 是否打乱 samplerNone, batch_samplerNone, num_workers0, 多进程(加载数据时采用)默认是0,使用主进程加载数据 collate_fnNone, p…...

【MySQL面试复习】索引创建的原则有哪些?
系列文章目录 在MySQL中,如何定位慢查询? 发现了某个SQL语句执行很慢,如何进行分析? 了解过索引吗?(索引的底层原理)/B 树和B树的区别是什么? 什么是聚簇索引(聚集索引)和非聚簇索引…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

Kafka主题运维全指南:从基础配置到故障处理
#作者:张桐瑞 文章目录 主题日常管理1. 修改主题分区。2. 修改主题级别参数。3. 变更副本数。4. 修改主题限速。5.主题分区迁移。6. 常见主题错误处理常见错误1:主题删除失败。常见错误2:__consumer_offsets占用太多的磁盘。 主题日常管理 …...

yaml读取写入常见错误 (‘cannot represent an object‘, 117)
错误一:yaml.representer.RepresenterError: (‘cannot represent an object’, 117) 出现这个问题一直没找到原因,后面把yaml.safe_dump直接替换成yaml.dump,确实能保存,但出现乱码: 放弃yaml.dump,又切…...

车载诊断架构 --- ZEVonUDS(J1979-3)简介第一篇
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...
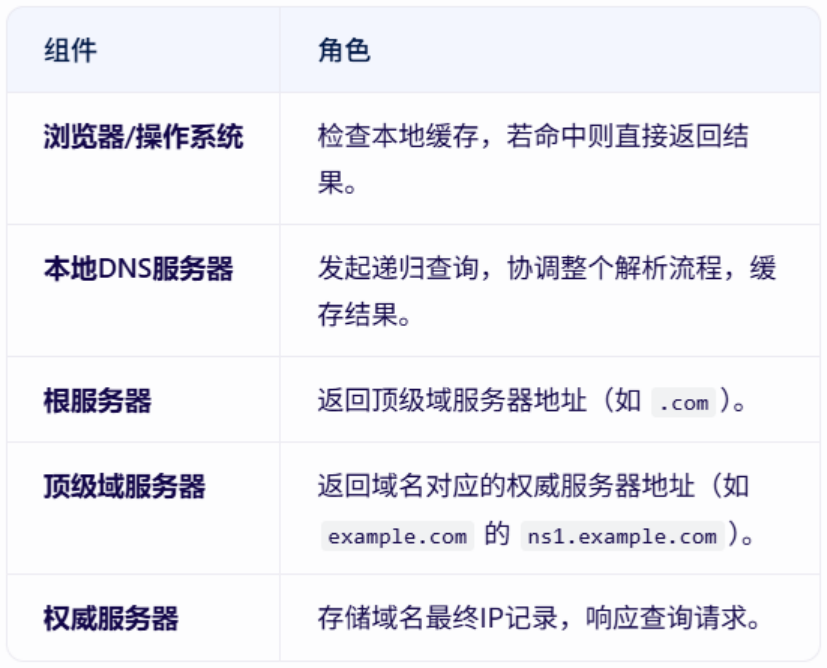
【JavaEE】万字详解HTTP协议
HTTP是什么?-----互联网的“快递小哥” 想象我们正在网上购物:打开淘宝APP,搜索“蓝牙耳机”,点击商品图片,然后下单付款。这一系列操作背后,其实有一个看不见的“快递小哥”在帮我们传递信息,…...