神经网络系列---损失函数
文章目录
- 损失函数
- 均方误差(Mean Squared Error,MSE):
- 平均绝对误差(Mean Absolute Error,MAE):
- 交叉熵损失函数(Cross-Entropy Loss):
- Hinge Loss:
- 交叉熵损失与对数似然损失(Log-Likelihood Loss):
- KL 散度损失(Kullback-Leibler Divergence Loss,KL Loss):
- 余弦相似度损失(Cosine Similarity Loss):
- 信息熵损失(Entropy Loss):
损失函数
神经网络中的损失函数用于衡量模型预测结果与实际标签之间的差异。选择适当的损失函数对于训练一个高效且准确的神经网络至关重要。以下是一些常见的神经网络损失函数:
- 我们假设
y_true和y_pred都是二维向量,表示批量样本的真实标签和预测结果。
均方误差(Mean Squared Error,MSE):
用于回归问题,计算预测值与实际值之间的平方差的均值。
均方误差(Mean Squared Error,MSE)是常用的回归问题中的损失函数,用于衡量模型预测结果与真实标签之间的差异。对于回归问题,我们预测的是连续值,而不是分类标签。均方误差计算方法是将每个预测值与对应的真实值之差的平方求和,然后再取平均,得到最终的损失值。
假设我们有一个批量样本,其中每个样本的真实标签为 y_true,模型预测结果为 y_pred。样本数为 N,则均方误差公式如下:
MSE = 1 N ∑ i = 1 N ( y true , i − y pred , i ) 2 \text{MSE} = \frac{1}{N} \sum_{i=1}^{N} (y_{\text{true},i} - y_{\text{pred},i})^2 MSE=N1i=1∑N(ytrue,i−ypred,i)2
其中:
- y true , i y_{\text{true},i} ytrue,i 是第
i个样本的真实标签值。 - y pred , i y_{\text{pred},i} ypred,i 是第
i个样本的模型预测结果。
均方误差衡量的是预测值与真实值之间的距离的平方,并求平均值。该值越小,表示模型的预测结果越接近真实标签,即模型的性能越好。
要计算均方误差(Mean Squared Error,MSE)损失函数对模型预测结果 y_pred 的偏导数,我们需要使用链式法则(Chain Rule)来求解。在以下偏导数公式中,y_true 表示真实标签,y_pred 表示模型预测的结果。
对于第 i 个样本的预测结果 y_pred[i],均方误差损失函数对 y_pred[i] 的偏导数公式如下:
∂ MSE ∂ y pred [ i ] = 2 N ( y pred [ i ] − y true [ i ] ) \frac{\partial \text{MSE}}{\partial y_{\text{pred}[i]}} = \frac{2}{N} (y_{\text{pred}[i]} - y_{\text{true}[i]}) ∂ypred[i]∂MSE=N2(ypred[i]−ytrue[i])
其中:
- N N N 是样本数(Batch Size)。
- y true [ i ] y_{\text{true}[i]} ytrue[i] 是第
i个样本的真实标签值。 - y pred [ i ] y_{\text{pred}[i]} ypred[i] 是第
i个样本的模型预测结果。
这个公式表示在均方误差损失函数中,对于每个样本的预测结果 y_pred[i],偏导数的值是预测结果与真实标签之差的2倍除以样本数。
注意,这个偏导数的计算是针对每个样本的预测结果 y_pred[i] 的,而不是整个批量样本的预测结果 y_pred。
在实际训练过程中,我们通常将均方误差损失函数的偏导数与其他梯度一起用于反向传播算法,从而更新网络参数。这样可以通过梯度下降等优化算法来最小化均方误差损失,从而提高回归模型的准确性和性能。
MSE = (1/n) * Σ(y_pred - y_true)^2#include <cmath>//单个数据
double meanSquaredError(double y_true, double y_pred) {return pow(y_true - y_pred, 2);
}//多个数据
double batchMeanSquaredError(const std::vector<double>& y_true, const std::vector<double>& y_pred) {int batch_size = y_true.size();double loss = 0.0;for (int i = 0; i < batch_size; i++) {loss += pow(y_true[i] - y_pred[i], 2);}return loss / batch_size;
}// 计算 MSE 损失函数对 y_pred 的偏导数
std::vector<double> mseLossDerivative(const std::vector<double>& y_true, const std::vector<double>& y_pred) {int size = y_true.size();std::vector<double> derivative(size);for (int i = 0; i < size; i++) {derivative[i] = 2 * (y_pred[i] - y_true[i]);}return derivative;
}// 计算 MSE 损失函数对 y_pred 的偏导数
std::vector<std::vector<double>> batchMSELossDerivative(const std::vector<std::vector<double>>& y_true,const std::vector<std::vector<double>>& y_pred) {int batch_size = y_true.size();int size = y_true[0].size();std::vector<std::vector<double>> derivative(batch_size, std::vector<double>(size, 0.0));for (int i = 0; i < batch_size; i++) {for (int j = 0; j < size; j++) {derivative[i][j] = 2 * (y_pred[i][j] - y_true[i][j]);}}return derivative;
}平均绝对误差(Mean Absolute Error,MAE):
用于回归问题,计算预测值与实际值之间的绝对差的均值。
平均绝对误差(Mean Absolute Error,MAE)是常用的回归问题中的损失函数,用于衡量模型预测结果与真实标签之间的差异。对于回归问题,我们预测的是连续值,而不是分类标签。平均绝对误差计算方法是将每个预测值与对应的真实值之差的绝对值求和,然后再取平均,得到最终的损失值。
假设我们有一个批量样本,其中每个样本的真实标签为 y_true,模型预测结果为 y_pred。样本数为 N,则平均绝对误差公式如下:
MAE = 1 N ∑ i = 1 N ∣ y true , i − y pred , i ∣ \text{MAE} = \frac{1}{N} \sum_{i=1}^{N} \left| y_{\text{true},i} - y_{\text{pred},i} \right| MAE=N1i=1∑N∣ytrue,i−ypred,i∣
其中:
- y true , i y_{\text{true},i} ytrue,i 是第
i个样本的真实标签值。 - y pred , i y_{\text{pred},i} ypred,i 是第
i个样本的模型预测结果。
平均绝对误差衡量的是预测值与真实值之间的绝对距离,并求平均值。与均方误差相比,平均绝对误差更加鲁棒,因为它对异常值(离群点)不敏感。然而,均方误差在数学优化中更易处理,因为其导数计算较为简单。
要计算平均绝对误差(Mean Absolute Error,MAE)损失函数对模型预测结果 y_pred 的偏导数,我们需要使用链式法则(Chain Rule)来求解。在以下偏导数公式中,y_true 表示真实标签,y_pred 表示模型预测的结果。
对于第 i 个样本的预测结果 y_pred[i],平均绝对误差损失函数对 y_pred[i] 的偏导数公式如下:
∂ MAE ∂ y pred [ i ] = 1 N ∑ j = 1 N y pred [ j ] − y true [ j ] ∣ y pred [ j ] − y true [ j ] ∣ \frac{\partial \text{MAE}}{\partial y_{\text{pred}[i]}} = \frac{1}{N} \sum_{j=1}^{N} \frac{y_{\text{pred}[j]} - y_{\text{true}[j]}}{\left| y_{\text{pred}[j]} - y_{\text{true}[j]} \right|} ∂ypred[i]∂MAE=N1j=1∑N ypred[j]−ytrue[j] ypred[j]−ytrue[j]
其中:
- N N N 是样本数(Batch Size)。
- y true [ j ] y_{\text{true}[j]} ytrue[j] 是第
j个样本的真实标签值。 - y pred [ j ] y_{\text{pred}[j]} ypred[j] 是第
j个样本的模型预测结果。
这个公式表示在平均绝对误差损失函数中,对于每个样本的预测结果 y_pred[i],偏导数的值是每个样本的预测结果与真实标签之差的符号(正负号)的平均值。
注意,这个偏导数的计算是针对每个样本的预测结果 y_pred[i] 的,而不是整个批量样本的预测结果 y_pred。
MAE = (1/n) * Σ|y_pred - y_true|
#include <cmath>
//单个数据
double meanAbsoluteError(double y_true, double y_pred) {return fabs(y_true - y_pred);
}//多个数据
double batchMeanAbsoluteError(const std::vector<double>& y_true, const std::vector<double>& y_pred) {int batch_size = y_true.size();double loss = 0.0;for (int i = 0; i < batch_size; i++) {loss += fabs(y_true[i] - y_pred[i]);}return loss / batch_size;
}// 计算 MAE 损失函数对 y_pred 的偏导数
std::vector<double> maeLossDerivative(const std::vector<double>& y_true, const std::vector<double>& y_pred) {int size = y_true.size();std::vector<double> derivative(size);for (int i = 0; i < size; i++) {derivative[i] = (y_pred[i] > y_true[i]) ? 1 : -1;}return derivative;
}// 计算 MAE 损失函数对 y_pred 的偏导数
std::vector<std::vector<double>> batchMAELossDerivative(const std::vector<std::vector<double>>& y_true,const std::vector<std::vector<double>>& y_pred) {int batch_size = y_true.size();int size = y_true[0].size();std::vector<std::vector<double>> derivative(batch_size, std::vector<double>(size, 0.0));for (int i = 0; i < batch_size; i++) {for (int j = 0; j < size; j++) {derivative[i][j] = (y_pred[i][j] > y_true[i][j]) ? 1 : -1;}}return derivative;
}交叉熵损失函数(Cross-Entropy Loss):
用于分类问题,衡量模型输出概率分布与实际标签的差异。
交叉熵损失函数(Cross-Entropy Loss)是用于衡量分类模型预测结果与真实标签之间差异的常用损失函数。对于多类别分类问题,它是一种广泛使用的损失函数。以下是交叉熵损失函数的数学公式:
假设我们有一个批量样本,其中每个样本有 C 个类别。y_true 表示真实标签的独热编码形式,y_pred 表示模型预测的类别概率向量。
交叉熵损失函数公式如下:
CrossEntropyLoss = − 1 N ∑ i = 1 N ∑ j = 1 C y true , i , j ⋅ log ( y pred , i , j ) \text{CrossEntropyLoss} = - \frac{1}{N} \sum_{i=1}^{N} \sum_{j=1}^{C} y_{\text{true},i,j} \cdot \log(y_{\text{pred},i,j}) CrossEntropyLoss=−N1i=1∑Nj=1∑Cytrue,i,j⋅log(ypred,i,j)
其中:
- N N N 是批量样本的数量(Batch Size)。
- C C C 是类别的数量。
- y true , i , j y_{\text{true},i,j} ytrue,i,j 表示第
i个样本的真实标签中类别j的值,它是一个0或1的独热编码。 - y pred , i , j y_{\text{pred},i,j} ypred,i,j 表示第
i个样本的模型预测结果中类别j的概率。
交叉熵损失函数是一个非负数,当模型预测结果与真实标签完全匹配时,损失为0。它的值越小表示模型的预测结果与真实标签越接近,即模型的性能越好。
在实际应用中,通常结合梯度下降等优化算法,将交叉熵损失函数用于训练神经网络,从而调整网络参数以最小化损失函数。这样可以提高分类模型的准确性和性能。
要计算交叉熵损失函数对模型预测结果 y_pred 的偏导数,我们需要使用链式法则(Chain Rule)来求解。在以下偏导数公式中,y_true 表示真实标签的独热编码形式,y_pred 表示模型预测的类别概率向量。
对于第 i 个样本的第 j 个类别,交叉熵损失函数对 y_pred[i][j] 的偏导数公式如下:
∂ CrossEntropyLoss ∂ y pred [ i ] [ j ] = − y true [ i ] [ j ] y pred [ i ] [ j ] \frac{\partial \text{CrossEntropyLoss}}{\partial y_{\text{pred}[i][j]}} = - \frac{y_{\text{true}[i][j]}}{y_{\text{pred}[i][j]}} ∂ypred[i][j]∂CrossEntropyLoss=−ypred[i][j]ytrue[i][j]
其中:
- y true [ i ] [ j ] y_{\text{true}[i][j]} ytrue[i][j] 是第
i个样本的真实标签中类别j的值,它是一个0或1的独热编码。 - y pred [ i ] [ j ] y_{\text{pred}[i][j]} ypred[i][j] 是第
i个样本的模型预测结果中类别j的概率。
这个公式表示在交叉熵损失函数中,对于每个样本的每个类别,偏导数的值是真实标签中类别值与模型预测结果中类别概率的比值的负数。
请注意,交叉熵损失函数对于真实标签中非零值(即对应真实类别的位置)的偏导数是负无穷大,因为在这些位置上 y true [ i ] [ j ] y_{\text{true}[i][j]} ytrue[i][j] 是1,而 y pred [ i ] [ j ] y_{\text{pred}[i][j]} ypred[i][j] 逼近于0,导致分母接近于0。这就是为什么在实际应用中,通常使用计算机的浮点数精度范围内的小值(如1e-9)来避免除以0的情况,从而保证计算的稳定性。
对于二分类问题:
Binary Cross-Entropy = -[y_true * log(y_pred) + (1 - y_true) * log(1 - y_pred)]对于多分类问题:
Categorical Cross-Entropy = -Σ(y_true * log(y_pred))
#include <cmath>// 单个数据 - 二分类double NetWork::binaryCrossEntropyLoss(double y_pred, double y_true){y_pred = std::max(std::min(y_pred, 1.0 - 1e-15), 1e-15); // 避免log(0)的情况return -(y_true * log(y_pred) + (1 - y_true) * log(1 - y_pred));}// 计算交叉熵损失函数对 y_pred 的偏导数 - 单个数据 - 二分类double binaryCrossEntropyLossDerivative(double y_pred, double y_true){// 计算predicted_prob对于损失函数L1和L2的偏导数double d_L1 = -y_true / std::max(std::min(y_pred, 1.0 - 1e-15), 1e-15);double d_L2 = (1.0 - y_true) / (1.0 - std::max(std::min(y_pred, 1.0 - 1e-15), 1e-15));// 计算predicted_prob对于总损失L的偏导数double d_L = d_L1 + d_L2;return d_L;}//单个数据 - 多分类double NetWork::categoricalCrossEntropyLoss(const Eigen::VectorXd& y_true,const Eigen::VectorXd& y_pred){int class_size = y_true.rows();// 类别数double loss = 0.0;for (int i = 0; i < class_size; i++){loss -= y_true(i) * log(std::max(std::min(y_pred(i), 1.0 - 1e-15), 1e-15));}return loss;// 求平均损失}// 计算交叉熵损失函数对 y_pred 的偏导数 - 单个数据 - 多分类Eigen::VectorXd NetWork::categoricalCrossEntropyLossDerivative(const Eigen::VectorXd& y_true, const Eigen::VectorXd& y_pred){int size = y_true.size();Eigen::VectorXd derivative(size);for (int i = 0; i < size; i++){derivative[i] = -y_true[i] / std::max(std::min(y_pred[i], 1.0 - 1e-15), 1e-15);}return derivative;}//多个数据 - 多分类double batchCategoricalCrossEntropy(const std::vector<std::vector<double>>& y_true,const std::vector<std::vector<double>>& y_pred) {int batch_size = y_true.size();int num_classes = y_true[0].size();double loss = 0.0;for (int i = 0; i < batch_size; i++) {for (int j = 0; j < num_classes; j++) {loss += -y_true[i][j] * log(std::max(std::min(y_pred[i][j], 1.0 - 1e-15), 1e-15));}}return loss / batch_size;}// 计算交叉熵损失函数对 y_pred 的偏导数 - 多分类
std::vector<std::vector<double>> batchCrossEntropyLossDerivative(const std::vector<std::vector<double>>& y_true,const std::vector<std::vector<double>>& y_pred) {int batch_size = y_true.size();int size = y_true[0].size();std::vector<std::vector<double>> derivative(batch_size, std::vector<double>(size, 0.0));for (int i = 0; i < batch_size; i++) {for (int j = 0; j < size; j++) {derivative[i][j] = -y_true[i][j] / std::max(std::min(y_pred[i][j], 1.0 - 1e-15), 1e-15);}}return derivative;
}Hinge Loss:
用于支持向量机(SVM)和一些特定的分类问题。
Hinge Loss(合页损失)是一种常用的用于支持向量机(SVM)和一些分类任务的损失函数。它在处理二分类问题时非常常见,特别是用于支持向量机中的线性分类和最大间隔分类。
对于二分类问题,假设我们有一个批量样本,其中每个样本的真实标签为 y_true,模型预测的结果为 y_pred。Hinge Loss 的计算方法如下:
Hinge Loss = 1 N ∑ i = 1 N max ( 0 , 1 − y true , i ⋅ y pred , i ) \text{Hinge Loss} = \frac{1}{N} \sum_{i=1}^{N} \max(0, 1 - y_{\text{true},i} \cdot y_{\text{pred},i}) Hinge Loss=N1i=1∑Nmax(0,1−ytrue,i⋅ypred,i)
其中:
- N N N 是样本数(Batch Size)。
- y true , i y_{\text{true},i} ytrue,i 是第
i个样本的真实标签,取值为+1或-1。 - y pred , i y_{\text{pred},i} ypred,i 是第
i个样本的模型预测结果,也是一个+1或-1的值。
Hinge Loss 衡量的是模型预测结果与真实标签之间的差异,并利用了间隔(margin)的概念。如果模型的预测结果与真实标签的符号相同,意味着预测正确,Hinge Loss 为0。如果预测结果与真实标签的符号相反,意味着预测错误,Hinge Loss 此时正比于预测结果与真实标签之差,当它大于1时损失开始增加。
Hinge Loss 的特点是,对于预测结果与真实标签的差异小于1的情况,损失为0,这被称为“合页点”(hinge point)。只有当预测结果与真实标签的差异大于等于1时,损失开始增加。
Hinge Loss 是一个非平滑的损失函数,因此其偏导数在某些点上不存在或为零。在通常情况下,Hinge Loss 的导数在预测结果与真实标签之差等于1的时候是不可导的(不连续)。然而,我们可以使用次梯度(subgradient)的概念来处理这个问题。
对于第 i 个样本的预测结果 y_pred[i],Hinge Loss 对 y_pred[i] 的偏导数公式如下:
$$
\frac{\partial \text{Hinge Loss}}{\partial y_{\text{pred}[i]}} =
\begin{cases}
- y_{\text{true}[i]} & \text{if } 1 - y_{\text{true}[i]} \cdot y_{\text{pred}[i]} > 0 \
0 & \text{otherwise}
\end{cases}
$$
其中:
- y true [ i ] y_{\text{true}[i]} ytrue[i] 是第
i个样本的真实标签,取值为+1或-1。 - y pred [ i ] y_{\text{pred}[i]} ypred[i] 是第
i个样本的模型预测结果,也是一个+1或-1的值。
在上面的偏导数公式中,如果预测结果与真实标签之差大于1(即 1 − y true [ i ] ⋅ y pred [ i ] > 0 1 - y_{\text{true}[i]} \cdot y_{\text{pred}[i]} > 0 1−ytrue[i]⋅ypred[i]>0),则偏导数为 -y_{\text{true}[i]}。否则,偏导数为0。
由于 Hinge Loss 在预测结果与真实标签之差等于1的点是不可导的,因此我们在这些点上使用次梯度 -y_{\text{true}[i]} 来近似表示导数的方向。
Hinge Loss = max(0, 1 - y_true * y_pred)
#include <vector>
#include <algorithm>double hingeLoss(double y_true, double y_pred) {return std::max(0.0, 1 - y_true * y_pred);
}double batchHingeLoss(const std::vector<std::vector<double>>& y_true,const std::vector<std::vector<double>>& y_pred) {int batch_size = y_true.size();double loss = 0.0;for (int i = 0; i < batch_size; i++) {double max_margin = 0.0;for (size_t j = 0; j < y_true[i].size(); j++) {max_margin = std::max(max_margin, 1 - y_true[i][j] * y_pred[i][j]);}loss += max_margin;}return loss / batch_size;
}// 计算 Hinge Loss 函数对 y_pred 的偏导数
std::vector<double> hingeLossDerivative(const std::vector<double>& y_true, const std::vector<double>& y_pred) {int size = y_true.size();std::vector<double> derivative(size);for (int i = 0; i < size; i++) {derivative[i] = (y_true[i] * y_pred[i] < 1) ? -y_true[i] : 0;}return derivative;
}// 计算 Hinge Loss 函数对 y_pred 的偏导数
std::vector<std::vector<double>> batchHingeLossDerivative(const std::vector<std::vector<double>>& y_true,const std::vector<std::vector<double>>& y_pred) {int batch_size = y_true.size();int size = y_true[0].size();std::vector<std::vector<double>> derivative(batch_size, std::vector<double>(size, 0.0));for (int i = 0; i < batch_size; i++) {for (int j = 0; j < size; j++) {derivative[i][j] = (y_true[i][j] * y_pred[i][j] < 1) ? -y_true[i][j] : 0;}}return derivative;
}交叉熵损失与对数似然损失(Log-Likelihood Loss):
- 对数似然损失(Log-Likelihood Loss)的偏导数:
假设我们有一个批量样本,其中每个样本有 C 个类别。y_true 表示真实标签的独热编码形式,y_pred 表示模型预测的类别概率向量。
对数似然损失函数的数学公式如下:
LogLikelihoodLoss = − 1 N ∑ i = 1 N ∑ j = 1 C y true , i , j ⋅ log ( y pred , i , j ) \text{LogLikelihoodLoss} = -\frac{1}{N} \sum_{i=1}^{N} \sum_{j=1}^{C} y_{\text{true},i,j} \cdot \log(y_{\text{pred},i,j}) LogLikelihoodLoss=−N1i=1∑Nj=1∑Cytrue,i,j⋅log(ypred,i,j)
其中:
- N N N 是批量样本的数量(Batch Size)。
- C C C 是类别的数量。
- y true , i , j y_{\text{true},i,j} ytrue,i,j 表示第
i个样本的真实标签中类别j的值,它是一个0或1的独热编码。 - y pred , i , j y_{\text{pred},i,j} ypred,i,j 表示第
i个样本的模型预测结果中类别j的概率。
对数似然损失函数对 y_pred 的偏导数公式如下:
∂ LogLikelihoodLoss ∂ y pred [ i ] [ j ] = − y true [ i ] [ j ] y pred [ i ] [ j ] \frac{\partial \text{LogLikelihoodLoss}}{\partial y_{\text{pred}[i][j]}} = -\frac{y_{\text{true}[i][j]}}{y_{\text{pred}[i][j]}} ∂ypred[i][j]∂LogLikelihoodLoss=−ypred[i][j]ytrue[i][j]
用于多类别分类问题,类似于分类问题中的交叉熵损失。
Log-Likelihood Loss = -log(y_pred[y_true])
#include <cmath>double logLikelihoodLoss(double y_true[], double y_pred[], int classes) {double loss = 0.0;for (int i = 0; i < classes; i++) {loss -= y_true[i] * log(y_pred[i]);}return loss;
}double batchLogLikelihoodLoss(const std::vector<std::vector<double>>& y_true,const std::vector<std::vector<double>>& y_pred) {int batch_size = y_true.size();int num_classes = y_true[0].size();double loss = 0.0;for (int i = 0; i < batch_size; i++) {for (int j = 0; j < num_classes; j++) {loss += -y_true[i][j] * log(y_pred[i][j]);}}return loss / batch_size;
}// 对数似然损失函数对 y_pred 的偏导数
std::vector<std::vector<double>> batchLogLikelihoodLossDerivative(const std::vector<std::vector<double>>& y_true,const std::vector<std::vector<double>>& y_pred) {int batch_size = y_true.size();int num_classes = y_true[0].size();std::vector<std::vector<double>> derivative(batch_size, std::vector<double>(num_classes, 0.0));for (int i = 0; i < batch_size; i++) {for (int j = 0; j < num_classes; j++) {derivative[i][j] = -y_true[i][j] / y_pred[i][j];}}return derivative;
}
KL 散度损失(Kullback-Leibler Divergence Loss,KL Loss):
用于衡量两个概率分布之间的差异。
- KL 散度(Kullback-Leibler Divergence)的偏导数:
KL 散度用于衡量两个概率分布之间的距离。假设有两个概率分布 P P P 和 Q Q Q,其中 y_true 表示真实概率分布的独热编码形式,y_pred 表示模型预测的概率分布。
KL 散度的数学公式如下:
KL ( P ∥ Q ) = ∑ i = 1 C P ( i ) ⋅ log ( P ( i ) Q ( i ) ) \text{KL}(P \| Q) = \sum_{i=1}^{C} P(i) \cdot \log\left(\frac{P(i)}{Q(i)}\right) KL(P∥Q)=i=1∑CP(i)⋅log(Q(i)P(i))
其中:
- C C C 是类别的数量。
- P ( i ) P(i) P(i) 表示真实概率分布中类别
i的概率。 - Q ( i ) Q(i) Q(i) 表示模型预测概率分布中类别
i的概率。
KL 散度对 y_pred 的偏导数公式如下:
∂ KL ( P ∥ Q ) ∂ y pred [ i ] = − P ( i ) y pred [ i ] \frac{\partial \text{KL}(P \| Q)}{\partial y_{\text{pred}[i]}} = -\frac{P(i)}{y_{\text{pred}[i]}} ∂ypred[i]∂KL(P∥Q)=−ypred[i]P(i)
请注意,KL 散度是非对称的,即 KL ( P ∥ Q ) ≠ KL ( Q ∥ P ) \text{KL}(P \| Q) \neq \text{KL}(Q \| P) KL(P∥Q)=KL(Q∥P),因此在计算时需要注意分子和分母的位置。
KL Loss = Σ(y_true * log(y_true / y_pred))
#include <cmath>//单个数据
double klDivergenceLoss(double y_true[], double y_pred[], int classes) {double loss = 0.0;for (int i = 0; i < classes; i++) {if (y_true[i] != 0.0) {loss += y_true[i] * log(y_true[i] / y_pred[i]);}}return loss;
}
//多个数据
double batchKLDivergenceLoss(const std::vector<std::vector<double>>& y_true,const std::vector<std::vector<double>>& y_pred) {int batch_size = y_true.size();int num_classes = y_true[0].size();double loss = 0.0;for (int i = 0; i < batch_size; i++) {for (int j = 0; j < num_classes; j++) {if (y_true[i][j] != 0.0) {loss += y_true[i][j] * log(y_true[i][j] / y_pred[i][j]);}}}return loss / batch_size;
}// KL 散度对 y_pred 的偏导数
std::vector<std::vector<double>> batchKLDivergenceDerivative(const std::vector<std::vector<double>>& P,const std::vector<std::vector<double>>& Q) {int batch_size = P.size();int num_classes = P[0].size();std::vector<std::vector<double>> derivative(batch_size, std::vector<double>(num_classes, 0.0));for (int i = 0; i < batch_size; i++) {for (int j = 0; j < num_classes; j++) {derivative[i][j] = -P[i][j] / Q[i][j];}}return derivative;
}
余弦相似度损失(Cosine Similarity Loss):
用于度量向量之间的余弦相似度。
余弦相似度损失(Cosine Similarity Loss)是用于衡量向量之间相似度的一种损失函数。它通常用于训练嵌入模型(Embedding Model)或进行相关性学习任务,特别是在自然语言处理(NLP)和推荐系统等领域。
假设我们有一个批量样本,其中每个样本有两个向量表示,分别是 v1 和 v2,余弦相似度损失的计算方法如下:
Cosine Similarity Loss = 1 N ∑ i = 1 N 1 − cosine_similarity ( v 1 i , v 2 i ) \text{Cosine Similarity Loss} = \frac{1}{N} \sum_{i=1}^{N} 1 - \text{cosine\_similarity}(v1_i, v2_i) Cosine Similarity Loss=N1i=1∑N1−cosine_similarity(v1i,v2i)
其中:
- N N N 是样本数(Batch Size)。
- v 1 i v1_i v1i 是第
i个样本的第一个向量。 - v 2 i v2_i v2i 是第
i个样本的第二个向量。 - cosine_similarity ( v 1 i , v 2 i ) \text{cosine\_similarity}(v1_i, v2_i) cosine_similarity(v1i,v2i) 是计算向量
v1_i和v2_i之间的余弦相似度。
余弦相似度是一个衡量两个向量方向之间相似程度的指标,取值范围在 -1 到 1 之间。当余弦相似度为1时,表示两个向量完全相似;当余弦相似度为-1时,表示两个向量完全相反;当余弦相似度为0时,表示两个向量正交(垂直)。
余弦相似度损失的计算是通过计算向量之间的余弦相似度并将其从1中减去,然后对所有样本取平均得到最终的损失值。这样做的目的是使余弦相似度尽可能接近1,从而提高向量之间的相似度。
为了计算余弦相似度损失(Cosine Similarity Loss)对向量 v1_i 和 v2_i 的偏导数,我们需要先计算余弦相似度对向量的偏导数,然后再根据链式法则将其传递给损失函数。在以下偏导数公式中,v1_i 和 v2_i 表示第 i 个样本的两个向量。
设余弦相似度为 cos_sim \text{cos\_sim} cos_sim,则余弦相似度损失对向量 v1_i 的偏导数为:
∂ Cosine Similarity Loss ∂ v 1 i = − 1 N ( 1 − cos_sim ( v 1 i , v 2 i ) ) ∂ cos_sim ( v 1 i , v 2 i ) ∂ v 1 i \frac{\partial \text{Cosine Similarity Loss}}{\partial v1_i} = - \frac{1}{N} \left(1 - \text{cos\_sim}(v1_i, v2_i)\right) \frac{\partial \text{cos\_sim}(v1_i, v2_i)}{\partial v1_i} ∂v1i∂Cosine Similarity Loss=−N1(1−cos_sim(v1i,v2i))∂v1i∂cos_sim(v1i,v2i)
余弦相似度损失对向量 v2_i 的偏导数为:
∂ Cosine Similarity Loss ∂ v 2 i = − 1 N ( 1 − cos_sim ( v 1 i , v 2 i ) ) ∂ cos_sim ( v 1 i , v 2 i ) ∂ v 2 i \frac{\partial \text{Cosine Similarity Loss}}{\partial v2_i} = - \frac{1}{N} \left(1 - \text{cos\_sim}(v1_i, v2_i)\right) \frac{\partial \text{cos\_sim}(v1_i, v2_i)}{\partial v2_i} ∂v2i∂Cosine Similarity Loss=−N1(1−cos_sim(v1i,v2i))∂v2i∂cos_sim(v1i,v2i)
接下来,我们需要计算余弦相似度对向量的偏导数。假设向量 v1_i 和 v2_i 的维度都为 d,则余弦相似度 cos_sim ( v 1 i , v 2 i ) \text{cos\_sim}(v1_i, v2_i) cos_sim(v1i,v2i) 的计算方法为:
cos_sim ( v 1 i , v 2 i ) = v 1 i ⋅ v 2 i ∥ v 1 i ∥ ⋅ ∥ v 2 i ∥ \text{cos\_sim}(v1_i, v2_i) = \frac{v1_i \cdot v2_i}{\|v1_i\| \cdot \|v2_i\|} cos_sim(v1i,v2i)=∥v1i∥⋅∥v2i∥v1i⋅v2i
其中 ⋅ \cdot ⋅ 表示向量的点积, ∥ ⋅ ∥ \| \cdot \| ∥⋅∥ 表示向量的范数(模长)。
现在,我们计算余弦相似度对向量 v1_i 的偏导数:
∂ cos_sim ( v 1 i , v 2 i ) ∂ v 1 i = v 2 i ∥ v 1 i ∥ ⋅ ∥ v 2 i ∥ − v 1 i ⋅ v 2 i ∥ v 1 i ∥ 3 ⋅ ∥ v 2 i ∥ v 1 i \frac{\partial \text{cos\_sim}(v1_i, v2_i)}{\partial v1_i} = \frac{v2_i}{\|v1_i\| \cdot \|v2_i\|} - \frac{v1_i \cdot v2_i}{\|v1_i\|^3 \cdot \|v2_i\|} v1_i ∂v1i∂cos_sim(v1i,v2i)=∥v1i∥⋅∥v2i∥v2i−∥v1i∥3⋅∥v2i∥v1i⋅v2iv1i
接着,我们计算余弦相似度对向量 v2_i 的偏导数:
∂ cos_sim ( v 1 i , v 2 i ) ∂ v 2 i = v 1 i ∥ v 1 i ∥ ⋅ ∥ v 2 i ∥ − v 1 i ⋅ v 2 i ∥ v 1 i ∥ ⋅ ∥ v 2 i ∥ 3 v 2 i \frac{\partial \text{cos\_sim}(v1_i, v2_i)}{\partial v2_i} = \frac{v1_i}{\|v1_i\| \cdot \|v2_i\|} - \frac{v1_i \cdot v2_i}{\|v1_i\| \cdot \|v2_i\|^3} v2_i ∂v2i∂cos_sim(v1i,v2i)=∥v1i∥⋅∥v2i∥v1i−∥v1i∥⋅∥v2i∥3v1i⋅v2iv2i
最后,我们将上述结果代入余弦相似度损失对向量的偏导数公式,得到最终的偏导数计算公式。
请注意,对于余弦相似度损失函数的偏导数计算,需要根据具体的向量表示和损失函数的定义进行推导。以上给出的是一种常见情况下的计算方法,实际应用中可能会根据具体的问题和模型定义进行调整。
Cosine Similarity Loss = 1 - (y_true * y_pred) / (||y_true|| * ||y_pred||)
#include <cmath>
//单个数据
double cosineSimilarityLoss(double y_true[], double y_pred[], int dimensions) {double dotProduct = 0.0;double norm_y_true = 0.0;double norm_y_pred = 0.0;for (int i = 0; i < dimensions; i++) {dotProduct += y_true[i] * y_pred[i];norm_y_true += pow(y_true[i], 2);norm_y_pred += pow(y_pred[i], 2);}norm_y_true = sqrt(norm_y_true);norm_y_pred = sqrt(norm_y_pred);double similarity = dotProduct / (norm_y_true * norm_y_pred);return 1 - similarity;
}//多个数据
double batchCosineSimilarityLoss(const std::vector<std::vector<double>>& y_true,const std::vector<std::vector<double>>& y_pred) {int batch_size = y_true.size();int dimensions = y_true[0].size();double loss = 0.0;for (int i = 0; i < batch_size; i++) {double dotProduct = 0.0;double norm_y_true = 0.0;double norm_y_pred = 0.0;for (int j = 0; j < dimensions; j++) {dotProduct += y_true[i][j] * y_pred[i][j];norm_y_true += pow(y_true[i][j], 2);norm_y_pred += pow(y_pred[i][j], 2);}norm_y_true = sqrt(norm_y_true);norm_y_pred = sqrt(norm_y_pred);double similarity = dotProduct / (norm_y_true * norm_y_pred);loss += 1 - similarity;}return loss / batch_size;
}// 计算余弦相似度损失函数对 y_pred 的偏导数
std::vector<double> cosineSimilarityLossDerivative(const std::vector<double>& y_true, const std::vector<double>& y_pred) {int size = y_true.size();std::vector<double> derivative(size);double norm_y_true = 0.0;double norm_y_pred = 0.0;double dotProduct = 0.0;for (int i = 0; i < size; i++) {dotProduct += y_true[i] * y_pred[i];norm_y_true += pow(y_true[i], 2);norm_y_pred += pow(y_pred[i], 2);}norm_y_true = sqrt(norm_y_true);norm_y_pred = sqrt(norm_y_pred);for (int i = 0; i < size; i++) {derivative[i] = (y_true[i] / (norm_y_true * norm_y_pred)) - (dotProduct * pow(y_true[i], 2) / pow(norm_y_true, 3) * norm_y_pred);}return derivative;
}// 计算余弦相似度损失函数对 y_pred 的偏导数
std::vector<std::vector<double>> batchCosineSimilarityLossDerivative(const std::vector<std::vector<double>>& y_true,const std::vector<std::vector<double>>& y_pred) {int batch_size = y_true.size();int size = y_true[0].size();std::vector<std::vector<double>> derivative(batch_size, std::vector<double>(size, 0.0));for (int i = 0; i < batch_size; i++) {double norm_y_true = 0.0;double norm_y_pred = 0.0;double dotProduct = 0.0;for (int j = 0; j < size; j++) {dotProduct += y_true[i][j] * y_pred[i][j];norm_y_true += pow(y_true[i][j], 2);norm_y_pred += pow(y_pred[i][j], 2);}norm_y_true = sqrt(norm_y_true);norm_y_pred = sqrt(norm_y_pred);for (int j = 0; j < size; j++) {derivative[i][j] = (y_true[i][j] / (norm_y_true * norm_y_pred)) - (dotProduct * pow(y_true[i][j], 2) / pow(norm_y_true, 3) * norm_y_pred);}}return derivative;
}信息熵损失(Entropy Loss):
用于最大化预测的不确定性,通常在生成模型中使用。
信息熵损失(Entropy Loss),也称为交叉熵损失(Cross-Entropy Loss),是一种用于衡量分类模型预测结果与真实标签之间差异的常用损失函数。它通常用于多类别分类问题,尤其是在神经网络中用于训练分类任务。
假设我们有一个批量样本,其中每个样本的真实标签用独热编码表示为 y_true,模型预测的类别概率向量为 y_pred。信息熵损失的计算方法如下:
Entropy Loss = − 1 N ∑ i = 1 N ∑ j = 1 C y true , i , j ⋅ log ( y pred , i , j ) \text{Entropy Loss} = - \frac{1}{N} \sum_{i=1}^{N} \sum_{j=1}^{C} y_{\text{true},i,j} \cdot \log(y_{\text{pred},i,j}) Entropy Loss=−N1i=1∑Nj=1∑Cytrue,i,j⋅log(ypred,i,j)
其中:
- N N N 是样本数(Batch Size)。
- C C C 是类别的数量。
- y true , i , j y_{\text{true},i,j} ytrue,i,j 表示第
i个样本的真实标签中类别j的值,它是一个0或1的独热编码。 - y pred , i , j y_{\text{pred},i,j} ypred,i,j 表示第
i个样本的模型预测结果中类别j的概率。
信息熵是信息论中的概念,用于衡量随机变量的不确定性。在分类任务中,信息熵损失函数的作用是最小化模型预测的类别概率分布与真实标签的差异,使得模型能够更好地预测正确类别。当模型的预测结果与真实标签完全匹配时,损失为0。信息熵损失越小,表示模型的预测结果与真实标签越接近,即模型的性能越好。
要计算信息熵损失(Entropy Loss)对模型预测结果 y_pred 的偏导数,我们需要使用链式法则(Chain Rule)来求解。在以下偏导数公式中,y_true 表示真实标签的独热编码形式,y_pred 表示模型预测的类别概率向量。
对于第 i 个样本的第 j 个类别,信息熵损失函数对 y_pred[i][j] 的偏导数公式如下:
∂ Entropy Loss ∂ y pred [ i ] [ j ] = − y true [ i ] [ j ] y pred [ i ] [ j ] \frac{\partial \text{Entropy Loss}}{\partial y_{\text{pred}[i][j]}} = - \frac{y_{\text{true}[i][j]}}{y_{\text{pred}[i][j]}} ∂ypred[i][j]∂Entropy Loss=−ypred[i][j]ytrue[i][j]
其中:
- y true [ i ] [ j ] y_{\text{true}[i][j]} ytrue[i][j] 是第
i个样本的真实标签中类别j的值,它是一个0或1的独热编码。 - y pred [ i ] [ j ] y_{\text{pred}[i][j]} ypred[i][j] 是第
i个样本的模型预测结果中类别j的概率。
这个公式表示在信息熵损失函数中,对于每个样本的每个类别,偏导数的值是真实标签中类别值与模型预测结果中类别概率的比值的负数。
请注意,信息熵损失函数对于真实标签中非零值(即对应真实类别的位置)的偏导数是负无穷大,因为在这些位置上 y_{\text{true}[i][j]} 是1,而 y_{\text{pred}[i][j]} 逼近于0,导致分母接近于0。这就是为什么在实际应用中,通常使用计算机的浮点数精度范围内的小值(如1e-9)来避免除以0的情况,从而保证计算的稳定性。
Entropy Loss = -Σ(y_pred * log(y_pred))
#include <cmath>
//单个数据
double entropyLoss(double y_pred[], int classes) {double loss = 0.0;for (int i = 0; i < classes; i++) {if (y_pred[i] != 0.0) {loss -= y_pred[i] * log(y_pred[i]);}}return loss;
}//多个数据
double batchEntropyLoss(const std::vector<std::vector<double>>& y_pred) {int batch_size = y_pred.size();int num_classes = y_pred[0].size();double loss = 0.0;for (int i = 0; i < batch_size; i++) {for (int j = 0; j < num_classes; j++) {if (y_pred[i][j] != 0.0) {loss += y_pred[i][j] * log(y_pred[i][j]);}}}return -loss / batch_size;
}// 计算信息熵损失函数对 y_pred 的偏导数
std::vector<double> entropyLossDerivative(const std::vector<double>& y_pred) {int size = y_pred.size();std::vector<double> derivative(size);for (int i = 0; i < size; i++) {derivative[i] = -log(y_pred[i]) - 1;}return derivative;
}// 计算信息熵损失函数对 y_pred 的偏导数
std::vector<std::vector<double>> batchEntropyLossDerivative(const std::vector<std::vector<double>>& y_pred) {int batch_size = y_pred.size();int size = y_pred[0].size();std::vector<std::vector<double>> derivative(batch_size, std::vector<double>(size, 0.0));for (int i = 0; i < batch_size; i++) {for (int j = 0; j < size; j++) {derivative[i][j] = -log(y_pred[i][j]) - 1;}}return derivative;
}我们假设输入数据是一个二维矩阵,其中每一行代表一个样本,每一列代表样本的特征。我们将使用C++标准库的向量来表示这些矩阵,并根据需要实现批量样本的损失函数。
相关文章:

神经网络系列---损失函数
文章目录 损失函数均方误差(Mean Squared Error,MSE):平均绝对误差(Mean Absolute Error,MAE):交叉熵损失函数(Cross-Entropy Loss):Hinge Loss&a…...
)
LeetCode每日一题 有效的字母异位词(哈希表)
题目描述 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。 示例 1: 输入: s "anagram", t "nagaram" 输…...
设计模式学习笔记 - 面向对象 - 8.实践:贫血模型和充血模型的原理及实践
1.Web开发常用的贫血MVC架构违背OOP吗? 前面我们依据讲过了面向对象四大特性、接口和抽象类、面向对象和面向过程编程风格,基于接口而非实现编程和多用组合少用继承设计思想。接下来,通过实战来学习如何将这些理论应用到实际的开发中。 大部…...

AI新纪元:可能的盈利之道
本文来源于Twitter大神宝玉(dotey)在聊 Sora 的时候,总结了 Sora 的价值和可能的盈利方向,我把这部分内容单独摘出来再整理一下。现在的生成式 AI 大家应该不陌生,用它总结文章、翻译、写作、画图,当然真正…...
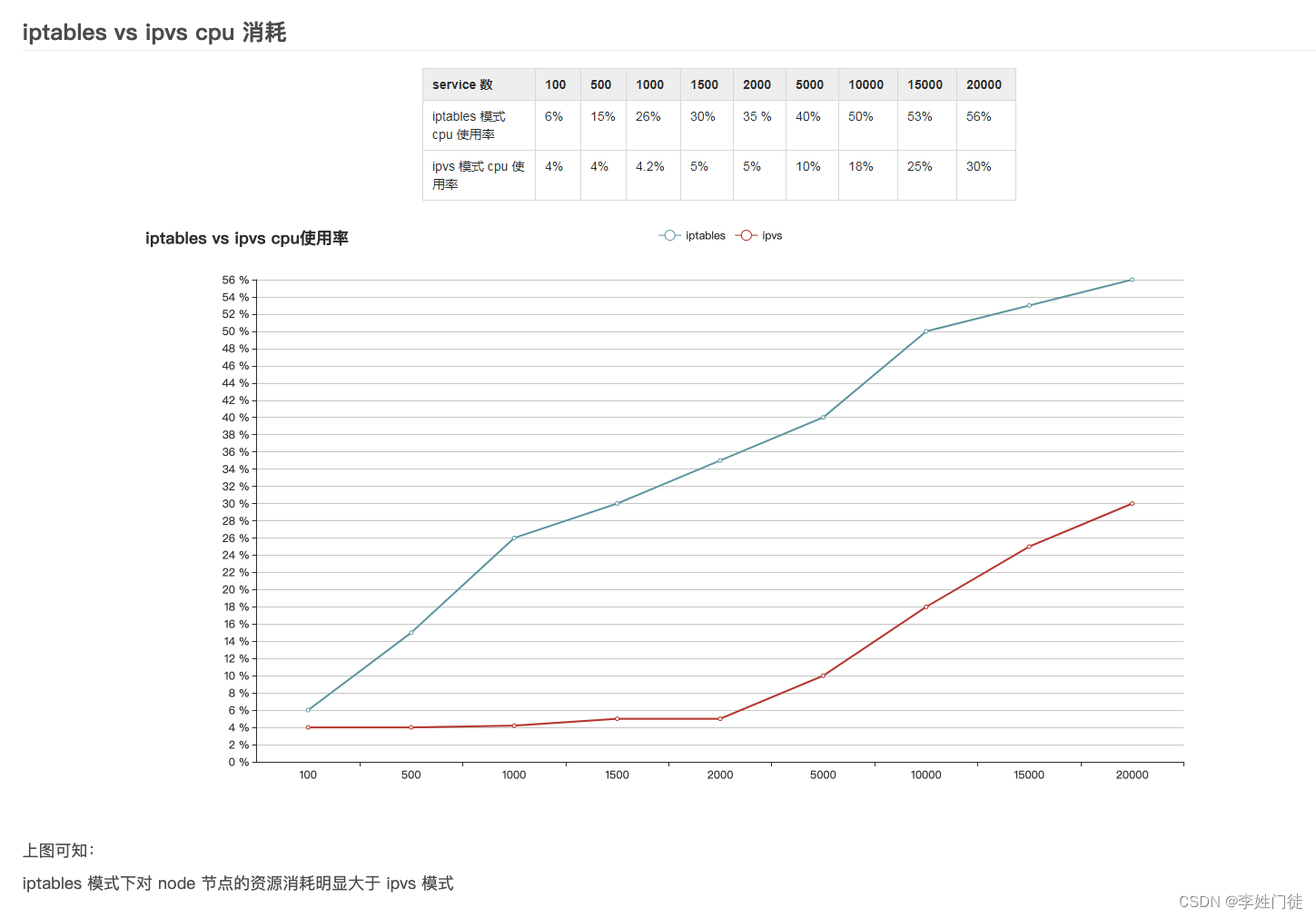
k8s的svc流量通过iptables和ipvs转发到pod的流程解析
文章目录 1. k8s的svc流量转发1.1 service 说明1.2 endpoints说明1.3 pod 说明1.4 svc流量转发的主要工作 2. iptables规则解析2.1 svc涉及的iptables链流程说明2.2 svc涉及的iptables规则实例2.2.1 KUBE-SERVICES规则链2.2.2 KUBE-SVC-EFPSQH5654KMWHJ5规则链2.2.3 KUBE-SEP-L…...
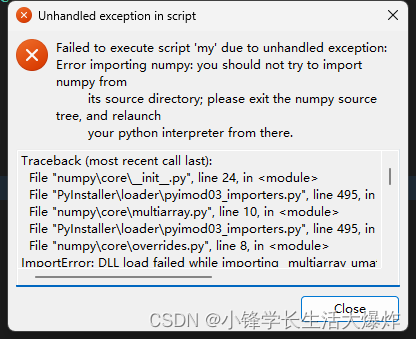
【踩坑】修复报错 you should not try to import numpy from its source directory
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 报错如下: 修复方法一: pip install pyinstaller5.9 修复方法二: pip install numpy1.24.1...

预测脱碳企业的信用评级-论文代码复现
文献来源 【Forecasting credit ratings of decarbonized firms: Comparative assessmentof machine learning models】 文章有代码复现有两个基本工作,1.是提取每个算法的重要性;2.计算每个算法的评价指标 算法有 CRT 分类决策树 ANN 人工神经网络 R…...

目标检测——KITTI目标跟踪数据集
KITTI目标跟踪数据集是由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创建的一个大规模自动驾驶场景下的计算机视觉算法评测数据集。这个数据集主要用于评估立体图像、光流、视觉测距、3D物体检测和3D跟踪等计算机视觉技术在车载环境下的性能这个数据集包含了在市区、乡村和…...

25-k8s集群中-RBAC用户角色资源权限
一、RBAC概述 1,k8s集群的交互逻辑(简单了解) 我们通过k8s各组件架构,知道各个组件之间是使用https进行数据加密及交互的,那么同理,我们作为“使用”k8s的各种资源的使用者,也是通过https进行数…...
Android 面试问题 2024 版(其二)
Android 面试问题 2024 版(其二) 六、多线程和并发七、性能优化八、测试九、安全十、Material设计和 **UX/UI** 六、多线程和并发 Android 中的进程和线程有什么区别? 答:进程是在自己的内存空间中运行的应用程序的单独实例&…...

SpringMVC的异常处理
异常分类 : 预期异常(检查型异常)和运行时异常 1、使用@ExceptionHandle注解处理异常 @ExceptionHandle(value={***.class} 异常类型) public modelandview handelException(){} 仅限当前类使用 2、全局处理方式 @ControllerAdvice + @ExceptionHandle 新建类 @Cont…...

【计算机网络】1 因特网概述
一.网络、互联网和因特网 1.网络(network),由若干结点(node)和连接这些结点的链路(link)组成。 2.多个网络还可以通过路由器互联起来,这样就构成了一个覆盖范围更大的网络…...

【Ubuntu】Anaconda的安装和使用
目录 1 安装 2 使用 1 安装 (1)下载安装包 官网地址:Unleash AI Innovation and Value | Anaconda 点击Free Download 按键。 然后 点击下图中的Download开始下载安装包。 (2)安装 在安装包路径下打开终端&#…...

OpenAI推出首个AI视频模型Sora:重塑视频创作与体验
链接:华为OD机考原题附代码 Sora - 探索AI视频模型的无限可能 随着人工智能技术的飞速发展,AI视频模型已成为科技领域的新热点。而在这个浪潮中,OpenAI推出的首个AI视频模型Sora,以其卓越的性能和前瞻性的技术,引领着…...
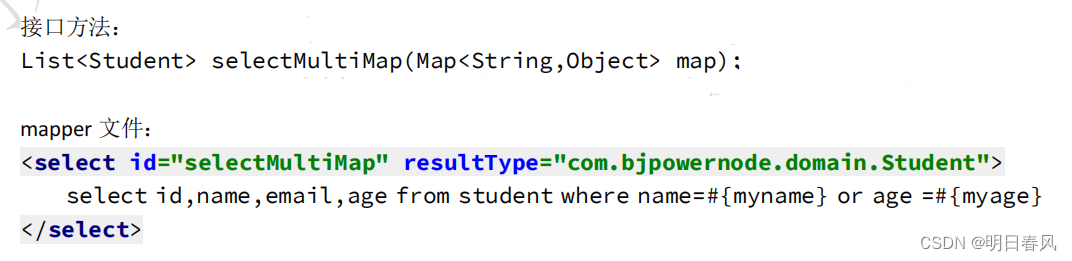
mybatis总结传参三
十、(不推荐)多个参数-按位置传参 参数位置从 0 开始, 引用参数语法 #{ arg 位置 } , 第一个参数是 #{arg0}, 第二个是 #{arg1} 注意: mybatis-3.3 版本和之前的版本使用 #{0},#{1} 方式, 从 myba…...
JSONVUE
1.JSON学习 1.概念: JSON是把JS对象变成字符串. 2.作用: 多用于网络中数据传输. JavaScript对象 let person{name:"张三",age:18}//将JS对象转换为 JSON数据let person2JSON{"name":"张三","age":18}; 3.JS对象与JSON字符串转换…...
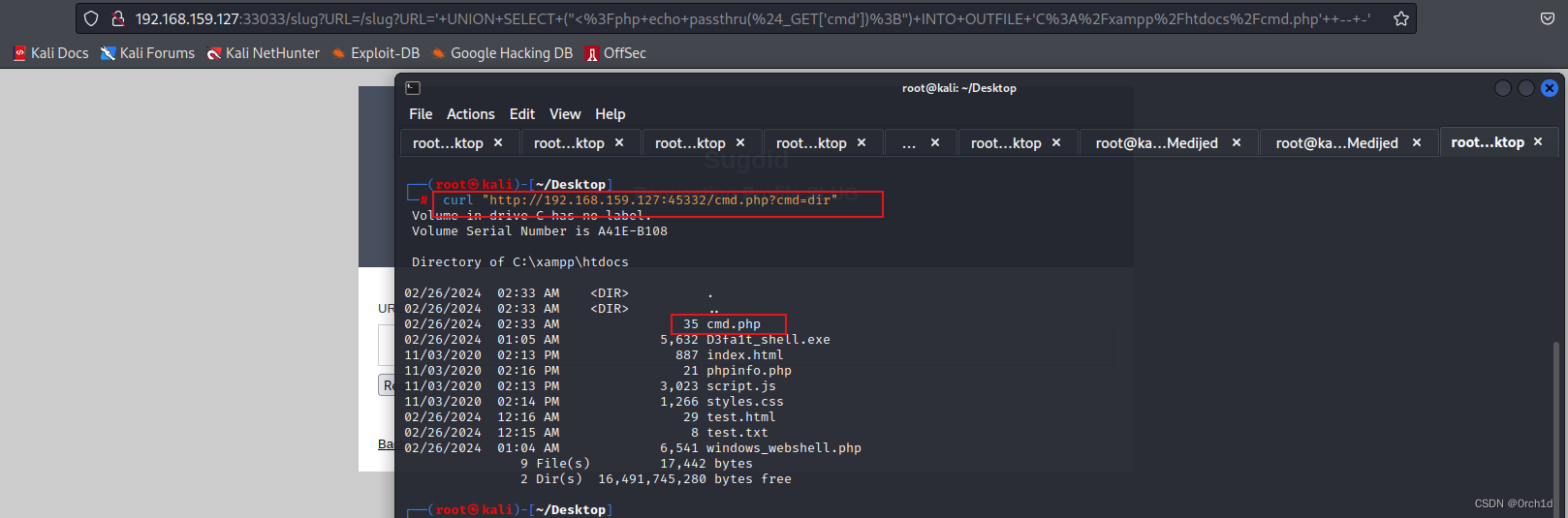
OSCP靶机--Medjed
OSCP靶机–Medjed 考点:(1.ftp文件上传 2.sql注入写shell 3.第三软件提权) 1.nmap ┌──(root㉿kali)-[~/Desktop] └─# nmap 192.168.200.127 -sV -sC -p- --min-rate 5000 Starting Nmap 7.92 ( https://nmap.org ) at 2024-02-25 19:42 EST Nmap scan repo…...
【Unity】Unity与安卓交互
问题描述 Unity和安卓手机进行交互,是我们开发游戏中最常见的场景。本教程将从一个简单的例子来演示一下。 本教程需要用到Android Studio2021.1.1 1.Android Studio新建一个工程 2.选择Empty Activity 然后点击Next 3.点击Finish完成创建 4.选择File-New-New Mo…...

QYFB-02 无线风力报警仪 风速风向超限声光报警
产品概述 无线风力报警仪是由测控报警仪、无线风速风向传感器和太阳能供电盒组成,可观测大气中的瞬时风速,具有风速报警设定和报警输出控制功能;风力报警仪采用无线信号传输、显示屏输出,风速显示采用高亮LED数码管显示ÿ…...
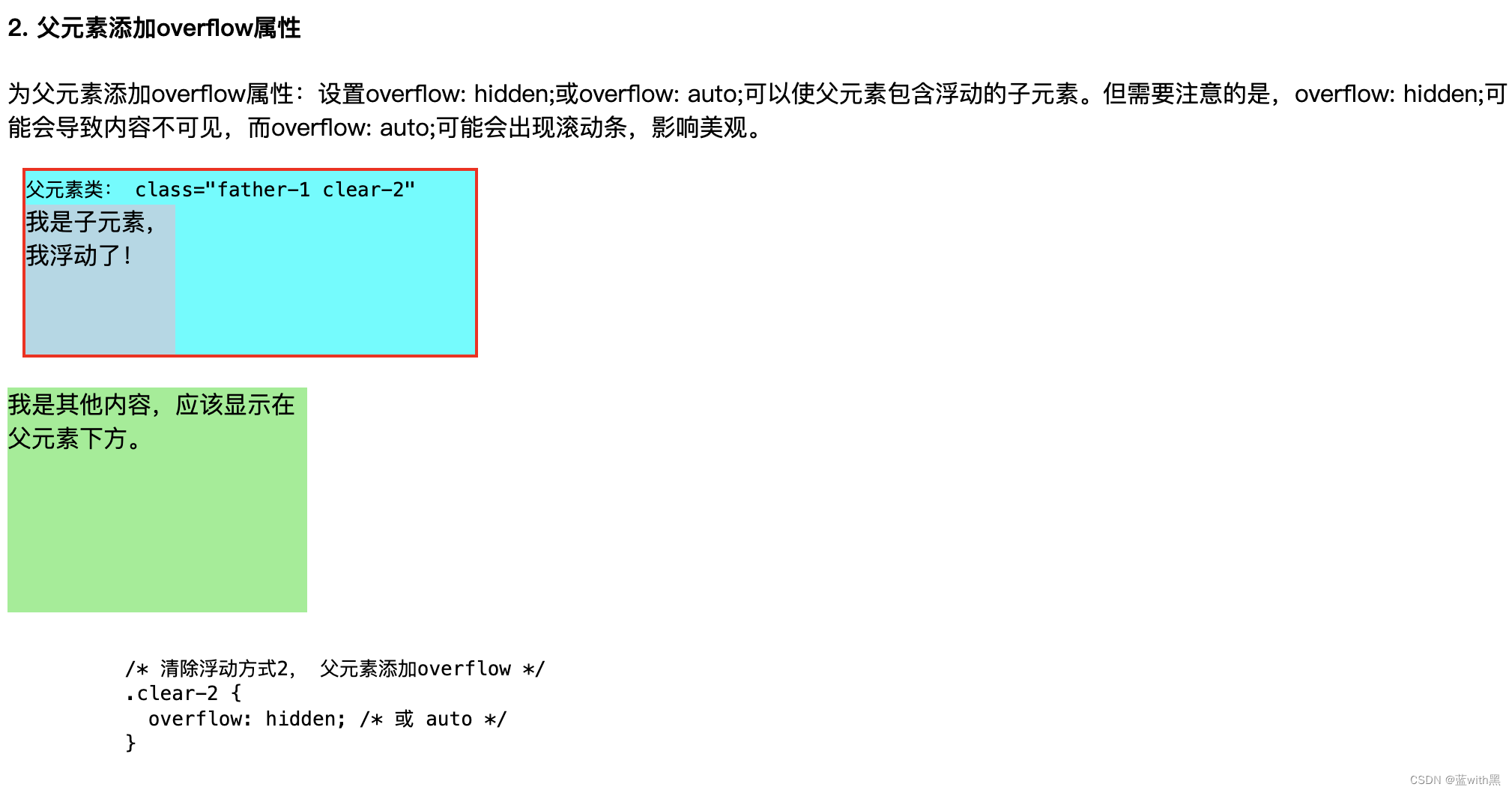
css知识:盒模型盒子塌陷BFC
1. css盒模型 标准盒子模型,content-box 设置宽度即content的宽度 width content 总宽度content(width设定值) padding border IE/怪异盒子模型,border-box width content border padding 总宽度 width设定值 2. 如何…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...
 error)
【前端异常】JavaScript错误处理:分析 Uncaught (in promise) error
在前端开发中,JavaScript 异常是不可避免的。随着现代前端应用越来越多地使用异步操作(如 Promise、async/await 等),开发者常常会遇到 Uncaught (in promise) error 错误。这个错误是由于未正确处理 Promise 的拒绝(r…...

云原生周刊:k0s 成为 CNCF 沙箱项目
开源项目推荐 HAMi HAMi(原名 k8s‑vGPU‑scheduler)是一款 CNCF Sandbox 级别的开源 K8s 中间件,通过虚拟化 GPU/NPU 等异构设备并支持内存、计算核心时间片隔离及共享调度,为容器提供统一接口,实现细粒度资源配额…...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...
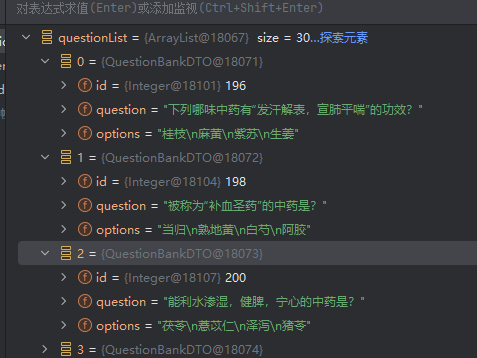
jdbc查询mysql数据库时,出现id顺序错误的情况
我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。 Query("SELECT NEW com…...