java Spring JdbcTemplate配合mysql实现数据批量修改
其实这个操作和批量添加挺像的 调的同一个方法
首先 我们看数据库结构
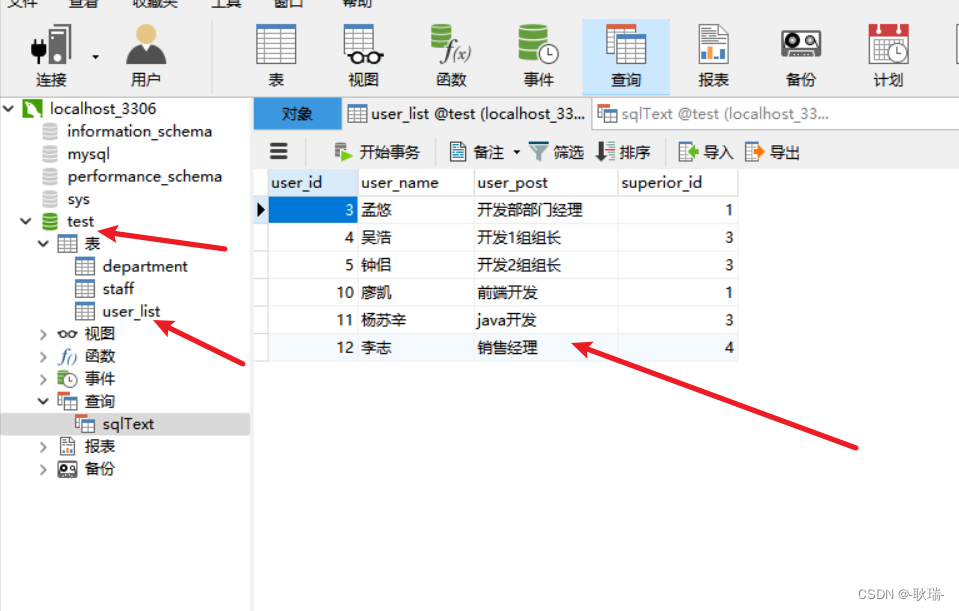
这是我本地的 mysql 里面有一个test数据库 里面有一张user_list表
然后创建一个java项目 然后 引入对应的JAR包
在src下创建 dao 目录
在下面创建一个接口 叫 BookDao 参考代码如下
package dao;import mydata.user_list;
import java.util.List;public interface BookDao {void reviseUser(List<Object []> user_list);
}
这里 我们顶一个了一个reviseUser抽象方法 引入了一个以数组泛型的List集合
然后 我们在dao 目录下创建一个类 我这里叫 BookDaoImpl
参考代码如下
package dao;import mydata.user_list;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Repository;import java.util.Arrays;
import java.util.List;@Repository
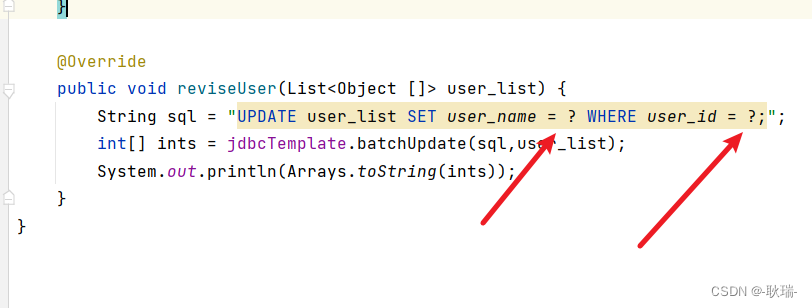
public class BookDaoImpl implements BookDao {@Autowiredprivate JdbcTemplate jdbcTemplate;@Overridepublic void reviseUser(List<Object []> user_list) {String sql = "UPDATE user_list SET user_name = ? WHERE user_id = ?;";int[] ints = jdbcTemplate.batchUpdate(sql,user_list);System.out.println(Arrays.toString(ints));}
}
这里 我们实现了BookDao接口 然后重写了 他的 reviseUser方法 这里 我们调用了jdbcTemplate的batchUpdate
第一个参数 接收一段sql语句 第二个参数 则是一个数组泛型集合
然后 在 src下创建目录 叫 senvice
下面创建一个类 叫 BookService
参考代码如下
package senvice;import dao.BookDao;
import mydata.user_list;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.util.List;@Service
public class BookService {@Autowiredprotected BookDao BookDao;public void reviseUser(List<Object []> user_list){BookDao.reviseUser(user_list);}
}
这里 我们多做了一层调用而已 为了架构
然后 在src下创建一个 bean.xml配置文件
参考代码如下
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"><!-- 数据库连接池 --><bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"destroy-method="close"><property name="url" value="jdbc:mysql:///test" /><!--对应SQLyog里的数据库--><property name="username" value="root" /> <!-- 用户名 --><property name="password" value="root" /> <!-- 密码 --><property name="driverClassName" value="com.mysql.jdbc.Driver" /></bean><!-- JdbcTemplate对象 --><bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate"><!--注入dataSource属性--><property name="dataSource" ref="dataSource"></property></bean><context:component-scan base-package="senvice"></context:component-scan><context:component-scan base-package="dao"></context:component-scan></beans>
这些基本的链接数据库配置 我就不多讲了
然后 我们在src目录下创建测试类 编写代码如下
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import senvice.BookService;import java.util.ArrayList;
import java.util.List;public class text {public static void main(String args[]) {ApplicationContext context = new ClassPathXmlApplicationContext("bean.xml");BookService bookService = context.getBean("bookService", BookService.class);List<Object[]> batehArgs = new ArrayList<>();Object[] o1 = {"曹操",10};Object[] o2 = {"刘备",11};Object[] o3 = {"孙权",12};batehArgs.add(o1);batehArgs.add(o2);batehArgs.add(o3);bookService.reviseUser(batehArgs);}
}
之所以这样写 是因为我们写的sql 第一个问号对应要修改成什么样的名称 第二个 则是条件id
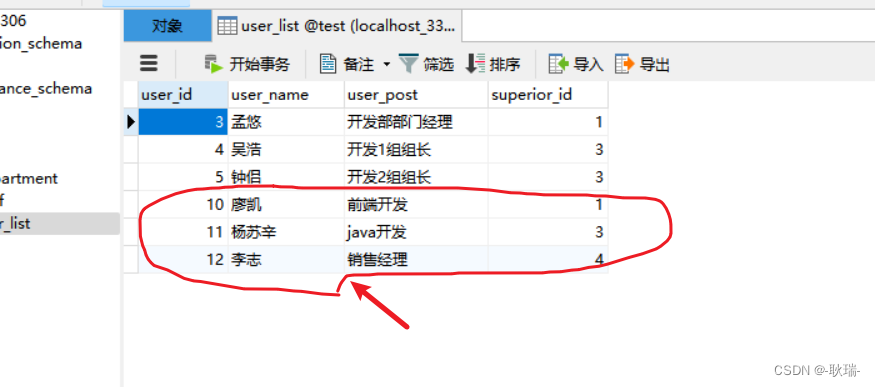
我们这里写的几个id分别是 10 11 12
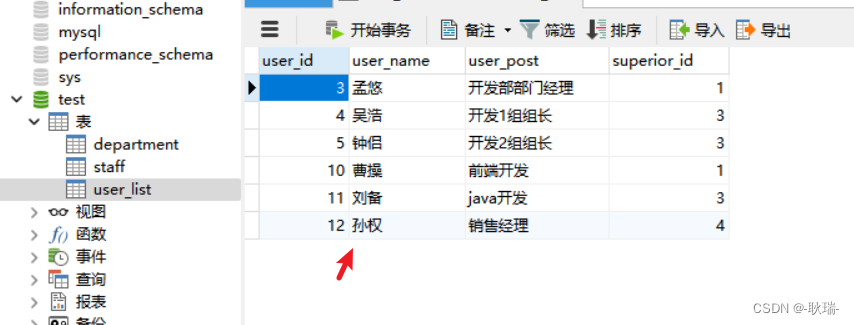
我们看一下这几条数据
然后 我们运行测试类代码
运行结果如下

可以看到 系统控制台显示运行成功 返回了每次sql的影响行数都是一行
我们到数据库 刷新表并重新打开
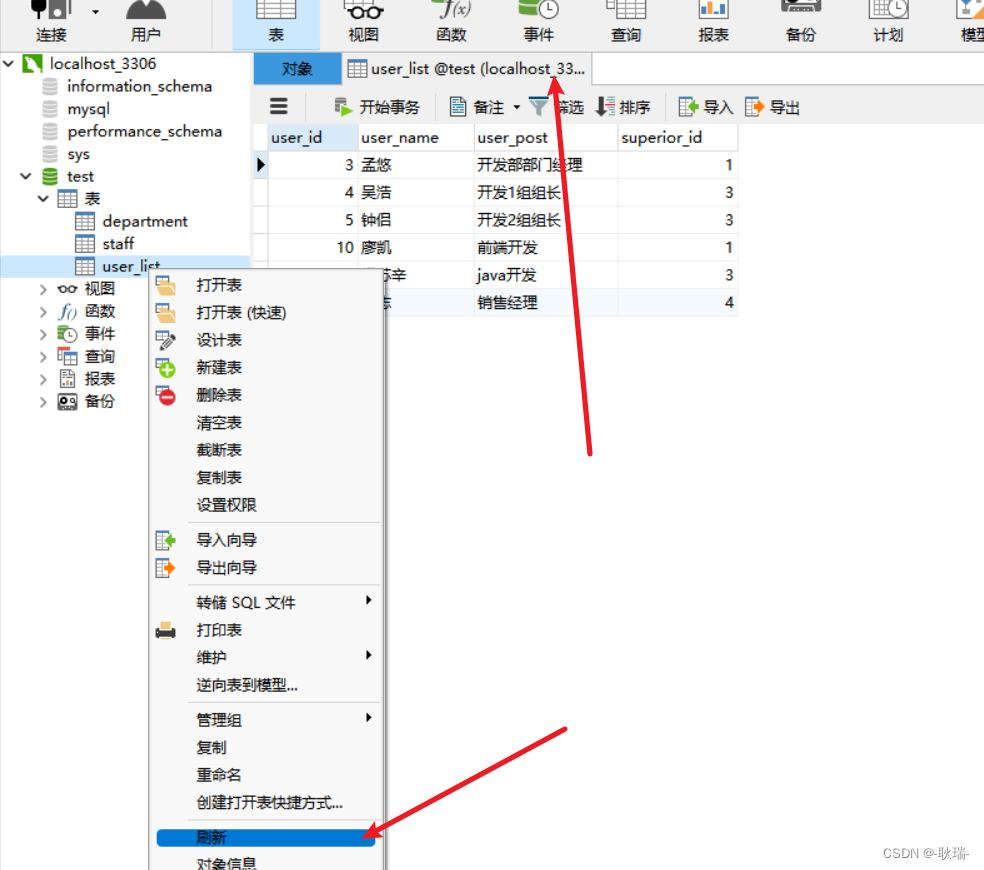
我们这几条数据就修改成功啦
相关文章:
java Spring JdbcTemplate配合mysql实现数据批量修改
其实这个操作和批量添加挺像的 调的同一个方法 首先 我们看数据库结构 这是我本地的 mysql 里面有一个test数据库 里面有一张user_list表 然后创建一个java项目 然后 引入对应的JAR包 在src下创建 dao 目录 在下面创建一个接口 叫 BookDao 参考代码如下 package dao;impo…...
《算法分析与设计》笔记总结
《算法分析与设计》笔记总结第一章 算法引论1.1 算法与程序1.2 表达算法的抽象机制1.3 描述算法1.4 算法复杂性分析第二章 递归与分治策略2.1 递归的概念2.2 分治法的基本思想2.3 二分搜索技术2.4 大整数乘法2.5 Strassen矩阵乘法2.7 合并排序2.8 快速排序2.9 线性时间选择2.10…...

序列化与反序列化概念
序列化是指将对象的状态信息转换为可以存储或传输的形式的过程。 在Java中创建的对象,只要没有被回收就可以被复用,但是,创建的这些对象都是存在于JVM的堆内存中,JVM处于运行状态时候,这些对象可以复用, 但…...
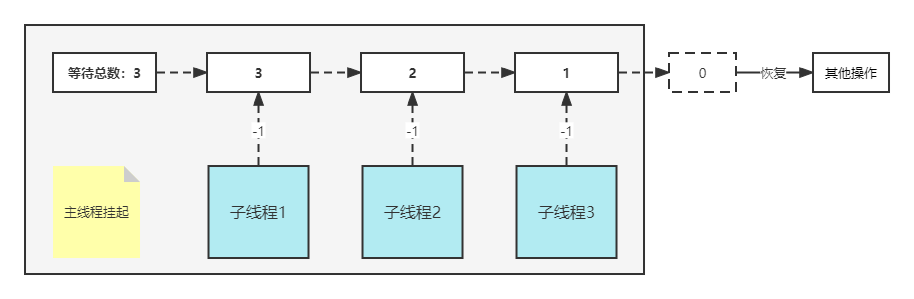
【Java并发编程】CountDownLatch
CountDownLatch是JUC提供的解决方案 CountDownLatch 可以保证一组子线程全部执行完牛后再进行主线程的执行操作。例如,主线程启动前,可能需要启动并执行若干子线程,这时就可以通过 CountDownLatch 来进行控制。 CountDownLatch是通过一个线程…...

【iOS】Blocks
BlockBlocks概要什么是Blocks?Block语法Block类型变量截获自动变量值__block说明符Blocks的实现Block的实质Blocks概要 什么是Blocks? Blocks可简单概括为: 带有自动变量(局部变量)的匿名函数 在使用Blocks时&#x…...
Java Volatile的三大特性
本文通过学习:周阳老师-尚硅谷Java大厂面试题第二季 总结的volatile相关的笔记volatile是Java虚拟机提供的轻量级的同步机制,三大特性为:保证可见性、不保证原子性、禁止指令重排一、保证可见性import java.util.concurrent.TimeUnit;class M…...
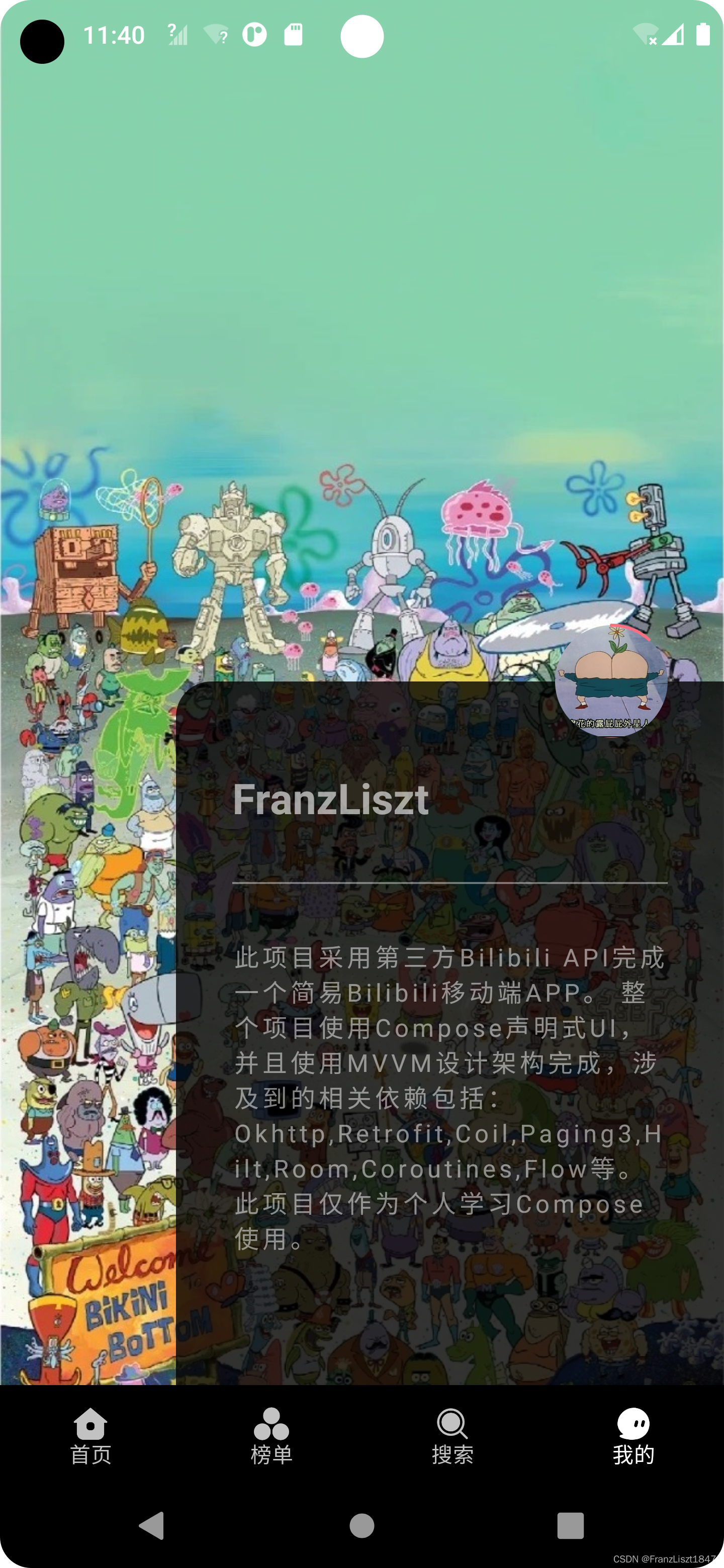
Android Compose——一个简单的Bilibili APP
Bilibili移动端APP简介依赖效果登录效果WebView自定义TobRow的Indicator大小首页推荐LazyGridView使用Paging3热门排行榜搜索模糊搜索富文本搜索结果视频详情合集信息Coroutines进行网络请求管理,避免回调地狱添加suspendwithContextGit项目链接末简介 此Demo采用A…...
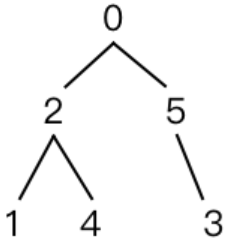
二叉树的最近公共祖先【Java实现】
题目描述 现有一棵n个结点的二叉树(结点编号为从0到n-1,根结点为0号结点),求两个指定编号结点的最近公共祖先。 注:二叉树上两个结点A、B的最近公共祖先是指:二叉树上存在的一个结点P,使得P既是…...
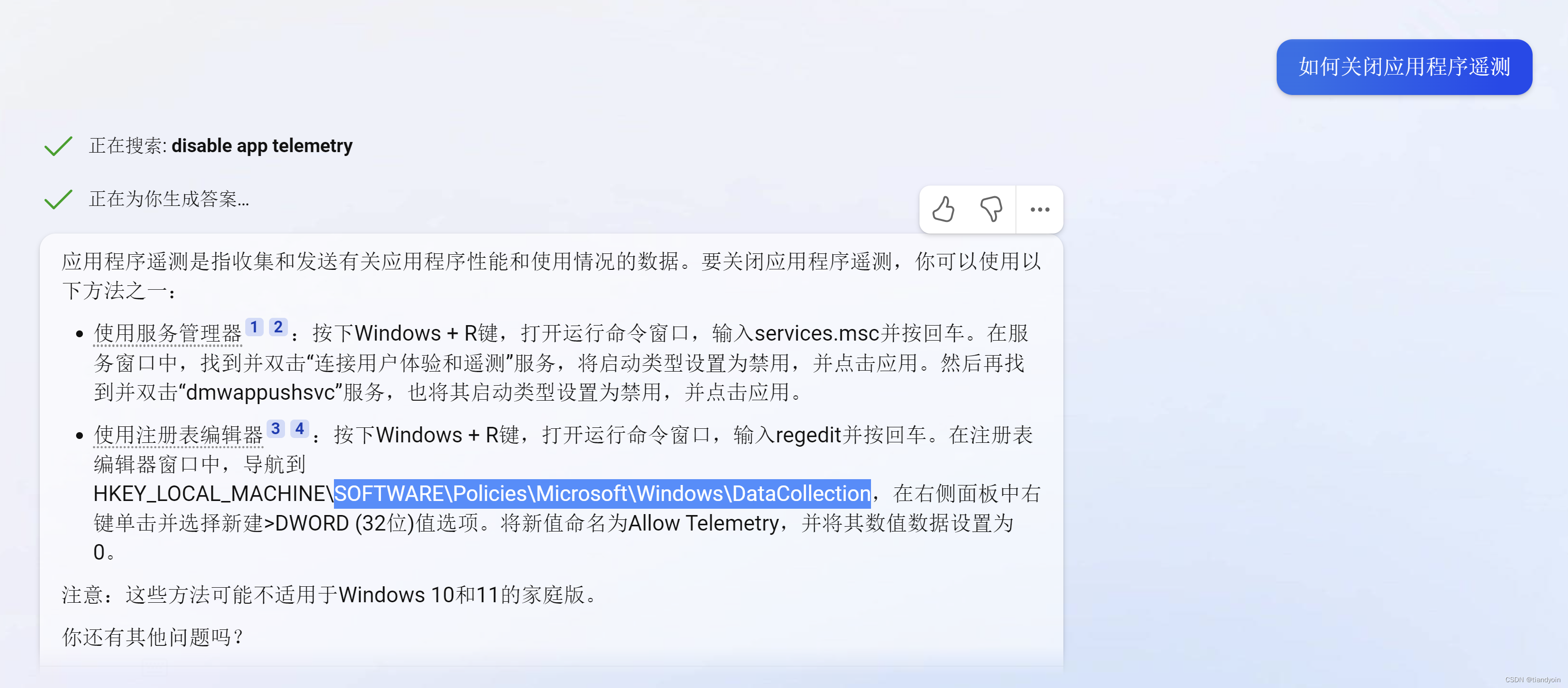
关闭应用程序遥测,禁止Windows收集用户信息
目录 1. 先创建还原点,防止意外 2. 界面设置 3. 服务 (1) GPEdit.msc - 本地计算机策略 - 计算机配置 - 管理模板 - Windows 组件 - 应用程序兼容性 - 关闭应用程序遥测 - 已启用 (2) GPEdit.msc - 本地计算机策略 - 计算机配置 - 管理模板 - Windows 组件 - 数…...

【备战面试】每日10道面试题打卡-Day4
本篇总结的是Java集合知识相关的面试题,后续也会更新其他相关内容 文章目录1、HashMap在JDK1.7和JDK1.8中有哪些不同?2、HashMap 的长度为什么是2的幂次方?3、HashMap的扩容操作是怎么实现的?4、HashMap是怎么解决哈希冲突的&…...

热乎的面经——初出茅庐
⭐️前言⭐️ 本篇文章记录博主与2023.03.04面试上海柯布西公司,一面所被问及的面试问题,回答答案仅供参考。 🍉欢迎点赞 👍 收藏 ⭐留言评论 📝私信必回哟😁 🍉博主将持续更新学习记录收获&am…...

数据库中各种锁汇总
本文汇总简记数据库中的各种锁。 名称英文名称定义解释悲观锁Pessimistic Lock在访问数据前先加锁,防止其他事务的并发修改数据通过获取锁来保证数据的独占性,从而避免并发修改数据带来的问题。乐观锁Optimistic Lock在修改数据时先不加锁,而…...
p76 - Python 开发-内外网收集 Socket子域名DNS
数据来源 Python 开发相关知识点: 1.开发基础环境配置说明 Windows10Pycharm 2.Python 开发学习的意义 学习相关安全工具原理 掌握自定义工具及拓展开发解决实战中无工具或手工麻烦批量化等情况 在二次开发 Bypass,日常任务,批量测试利用…...

QCC51XX--eFush Key加密
https://blog.csdn.net/weixin_42162924/article/details/125828901?spm=1001.2014.3001.5502 在开始讲eFush Key加密操作之前,说一下这个操作的作用就是将自己的固件采用硬件的方式进行加密。 操作步骤 1.创建一个txt文本文件,参考文档“Qualcomm BlueSuite v3.1.4 Release…...
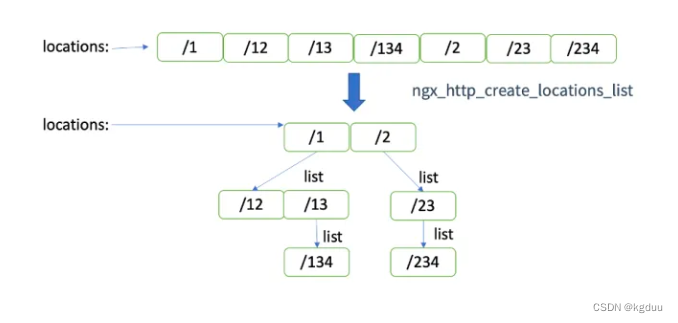
nginx http模块
1.模块依赖2. 模块的初始化2.1 location的定义location的定义包含以下几种location [ | ~ | ~* | ^~ ] uri { ... } location name { ... }:表示精确匹配,只有请求的url路径与后面的字符串完全相等时,才会命中,不支持location嵌套~ÿ…...

守护进程 || 精灵进程
目录 守护进程(deamon) || 精灵进程 特点 什么是前台进程组 把自己写的服务器deamon deamon代码 守护进程(deamon) || 精灵进程 特点 01. 他的PPID是1(附件特征)02. COMMAND --- 称为进程启动的命令03…...
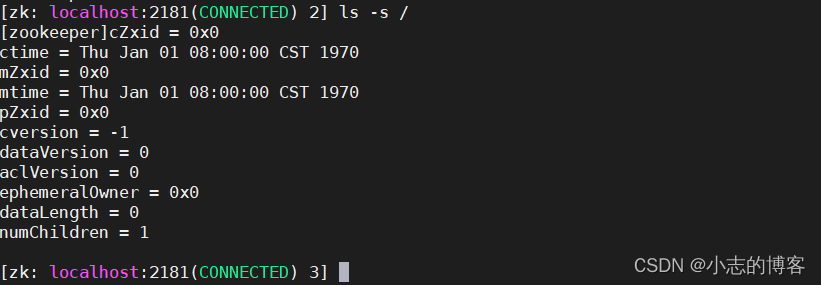
Zookeeper3.5.7版本——客户端命令行操作(znode 节点数据信息)
目录一、命令行语法二、znode 节点数据信息2.1、查看当前znode中所包含的内容2.2、查看当前节点详细数据2.3、节点详细数据解释一、命令行语法 命令行语法列表 命令基本语法功能描述help显示所有操作命令ls path使用 ls 命令来查看当前 znode 的子节点 [可监听]-w 监听子节点变…...

如何写好单测
1、为什么要写单测? 单测即单元测试(Unit Test),是对软件的基本组成单元进行的测试,比如函数、过程或者类的方法。其意义是: 功能自测,发现功能缺陷自我Code Review测试驱动开发促进代码重构并…...

CDH-6.3.2内置spark-2.4.0的BUG
1. 背景 公司最近在新建集群,全部采用开源的大数据框架,并且将之前使用的阿里云的所有服务进行下线,其中就涉及到了旧任务的迁移。 2. 任务 2.1. 简述 我接手到一个之前的 spark 任务,是读取阿里 LogStore 数据,然…...
SpringCloud之ElasticSearch笔记
ElasticSearch 初识ElasticSearch ElasticSearch是什么 ElasticSearch一个基于Lucene的底层的开源的分布式搜索引擎,可用来实现搜索,日志统计,分析,系统监控 正向索引和倒排索引 正向索引:逐条扫描(my…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

接口自动化测试:HttpRunner基础
相关文档 HttpRunner V3.x中文文档 HttpRunner 用户指南 使用HttpRunner 3.x实现接口自动化测试 HttpRunner介绍 HttpRunner 是一个开源的 API 测试工具,支持 HTTP(S)/HTTP2/WebSocket/RPC 等网络协议,涵盖接口测试、性能测试、数字体验监测等测试类型…...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...
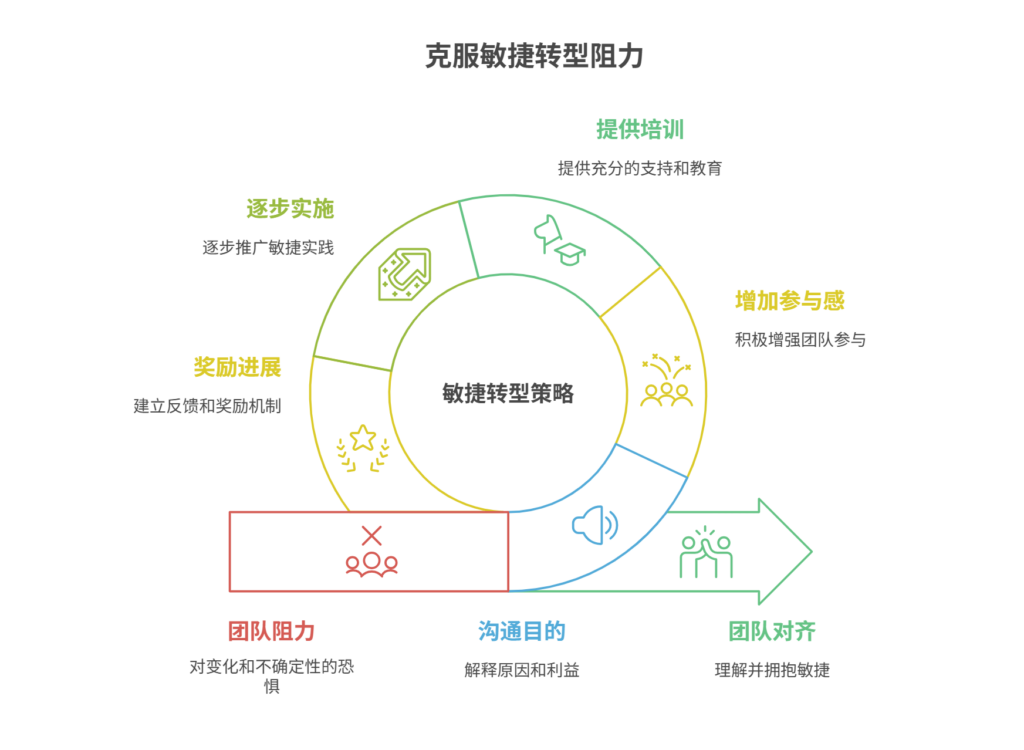
如何应对敏捷转型中的团队阻力
应对敏捷转型中的团队阻力需要明确沟通敏捷转型目的、提升团队参与感、提供充分的培训与支持、逐步推进敏捷实践、建立清晰的奖励和反馈机制。其中,明确沟通敏捷转型目的尤为关键,团队成员只有清晰理解转型背后的原因和利益,才能降低对变化的…...
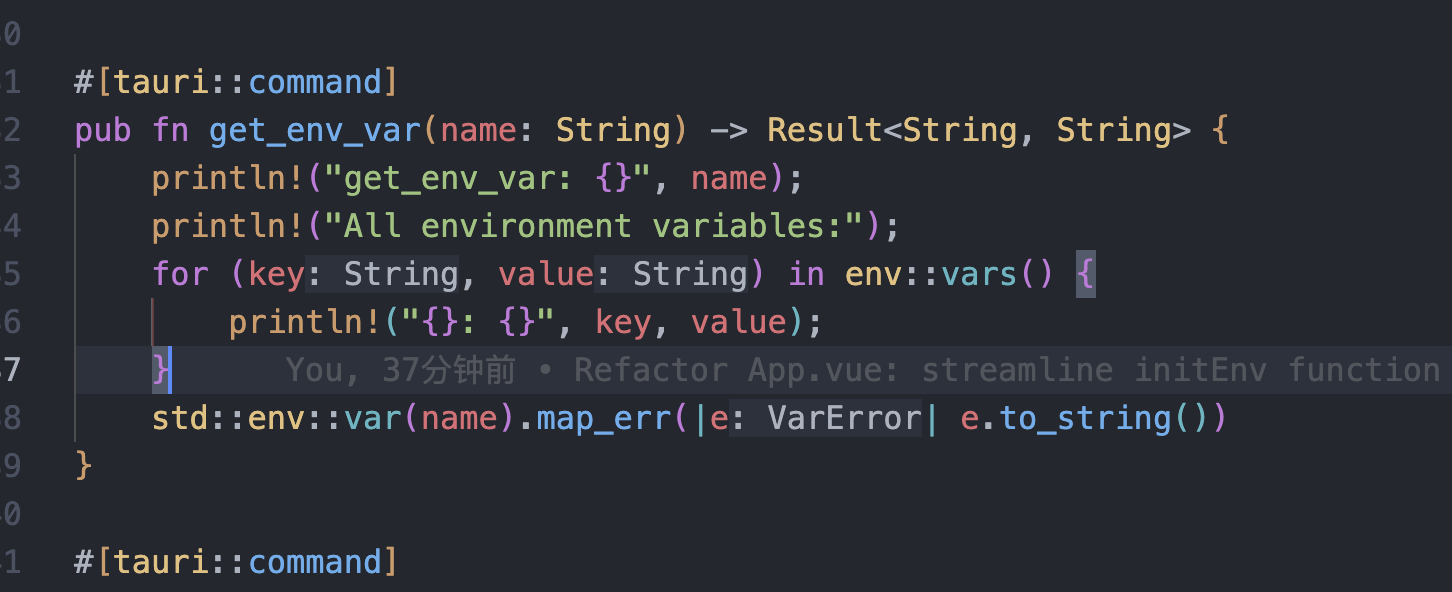
tauri项目,如何在rust端读取电脑环境变量
如果想在前端通过调用来获取环境变量的值,可以通过标准的依赖: std::env::var(name).ok() 想在前端通过调用来获取,可以写一个command函数: #[tauri::command] pub fn get_env_var(name: String) -> Result<String, Stri…...