CDH-6.3.2内置spark-2.4.0的BUG
1. 背景
公司最近在新建集群,全部采用开源的大数据框架,并且将之前使用的阿里云的所有服务进行下线,其中就涉及到了旧任务的迁移。
2. 任务
2.1. 简述
我接手到一个之前的 spark 任务,是读取阿里 LogStore 数据,然后使用 spark streaming,将接收到的 LogStore 数据注册为表,之后运行 spark sql 进行分批处理,每 2 分钟一批,最后写入时序数据库。
2.2. 处理逻辑
spark sql 首先计算接收到的 2 分钟数据,对维度字段进行 group by,指标字段进行 sum、count 之类的聚合操作;然后将这两分钟的结果和之前从当天 0 点开始累积到上个 2 分钟的结果进行 union all,最后再次进行 group by 以及 sum、count 操作,最后将结果写出。
整体需求是,计算当天 0 点到每个 2 分钟的累加结果,类似于 flink sql 中的渐进式(或叫累计)窗口。
3. 改造方案
去掉从阿里的 LogStore 接收数据,而是从 kafka 接收数据,后面所有的处理逻辑都一样。
4. 出现的问题
将改造、重构后的代码部署到新建的大数据集群上运行,结果发现,计算的结果总是比之前的环境中大一些。
然后我们就开始进行代码级别的排查,一直以为是代码哪儿写错了。之前的代码接收 LogStore 的数据,而且是只接收了一个流的数据,但是改造之后,需要接收三个 kafka 主题的数据,在 spark 代码中,就变成了三个 InputDStream,然后分别将三个流注册为三张不同的表,最后再进行一个大的 sql 处理,示例代码见下面。
case class Table1(@BeanProperty var goods1: String, @BeanProperty var price1: Int) extends Serializable
case class Table2(@BeanProperty var goods2: String, @BeanProperty var price2: Int) extends Serializable
case class Table3(@BeanProperty var goods3: String, @BeanProperty var price3: Int) extends Serializable
object Stream extends Serializable {def main(args: Array[String]): Unit = {val masterUri = sys.props.getOrElse("spark.master", "local[4]")// 获取 spark 环境val conf = new SparkConf()val spark: SparkSession = SparkSession.builder().config(conf).master(masterUri).getOrCreate()val sparkContext = spark.sparkContextval ssc: StreamingContext = new StreamingContext(sparkContext, Seconds(120))val sqlContext = spark.sqlContext// ------------------------------------------------------------------------------------------------------------------------------------------------------------val kafkaParams: mutable.Map[String, Object] = mutable.Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "kafka01:9092",ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer].getCanonicalName,ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer].getCanonicalName,ConsumerConfig.GROUP_ID_CONFIG -> "test-1")// 保存 offset,最后手动提交val offsetRangesList = mutable.ListBuffer[Array[OffsetRange]]()val topic1 = Array("topic1")val tableName1 = "table1"val inputDS1: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topic1, kafkaParams))inputDS1.foreachRDD(rdd => {offsetRangesList += rdd.asInstanceOf[HasOffsetRanges].offsetRanges})inputDS1.map(_.value()).map(x => JSONUtil.toBean(x, classOf[Table1])).foreachRDD((rdd: RDD[Table1]) => {spark.createDataFrame(rdd).createOrReplaceTempView(tableName1)})val topic2 = Array("topic2")val tableName2 = "table2"val inputDS2: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topic2, kafkaParams))inputDS2.foreachRDD(rdd => {offsetRangesList += rdd.asInstanceOf[HasOffsetRanges].offsetRanges})inputDS2.map(_.value()).map(x => JSONUtil.toBean(x, classOf[Table2])).foreachRDD((rdd: RDD[Table2]) => {spark.createDataFrame(rdd).createOrReplaceTempView(tableName2)})val topic3 = Array("topic3")val tableName3 = "table3"val inputDS3: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topic3, kafkaParams))inputDS3.foreachRDD(rdd => {offsetRangesList += rdd.asInstanceOf[HasOffsetRanges].offsetRanges})// 所有计算和结果写出都在下面维护inputDS3.map(_.value()).map(x => JSONUtil.toBean(x, classOf[Table3])).foreachRDD(foreachFunc = (rdd: RDD[Table3]) => {spark.createDataFrame(rdd).createOrReplaceTempView(tableName3)// 从 hdfs 读取上一批次的计算结果val lastDataDF: DataFrame = sqlContext.read.format("csv").option("header", "true").load("hdfs:///spark/latest-data")lastDataDF.createOrReplaceTempView("last_result")// 计算最新的结果val resultDF: DataFrame = spark.sql("真正要执行的 sql 语句")// 将结算结果进行输出,这里简单调用 show ,只是为了演示resultDF.show(10)// 将本批次结果写入 hdfs,供下次计算前初始化使用resultDF.write.option("header", "true").mode(SaveMode.Overwrite).csv("hdfs:///spark/latest-data")// 手动提交 offsetfor (offsetRanges <- offsetRangesList) {inputDS3.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)}offsetRangesList.clear()// 清理掉内存中的结果数据resultDF.unpersist()})ssc.start()ssc.awaitTermination()}}
我的做法是,将三个主题对应的流分别处理,然后各自注册为表,并且在最后一个主题的 foreachRdd 函数中进行 sql 的执行和结果的输出。
注意第三个主题对应流里面的处理流程:
- 接收本批次数据,先从 hdfs 对应路径获取上批次结果,注册名为
last_result的表。 - 执行真正的 sql 计算逻辑。
- 将结果写出,为了代码演示,只是简单的使用
show()函数进行输出。 - 将本批次的计算结果保存到 hdfs,然后手动提交 offset。
由于我的逻辑中,每次处理,都需要将本批次的计算结果和 0 点到上一批次的计算进行合并处理,所以每次都会将本批次的计算结果写出到 hdfs,此时就出现了问题,最后算出来的每批次结果值都比正确结果多一些。
然后我们就把每批次的结果值,不但输出到 hdfs 进行保存,而且还把他们输出到 mysql,查看其详细的计算结果,看到底是哪一步出了问题。
通过观察 mysql 中每批次的详细计算结果,我们发现,同一个商品,在一个批次计算中,居然出现了相同时间的两条计算结果数据,但理论上应该是只有一条才对。此时我们才发现了问题所在:由于 spark 框架计算由于,某一批次的计算结果中,对 group by 中出现的字段,并没有做到真正的唯一聚合,而是出现了多条。而且我是把每批次的计算结果都写入到 hdfs,也没有对结果数据进行去重,所以下批次数据计算时,通过上批次写入到 hdfs 的结果进行 last_result 表的初始化后,last_result 表中对于同一个维度组合,就会出现多条数据,本批次聚合计算完之后,最终的结果值就多了。而且,这种情况只出现在设置 spark 任务为多并发时才会出现,如果提交时只给一个 executor,并且只给 1 核 CPU,就不会出现问题。
最后手动部署了 apache spark-2.3.2,替换掉之前使用的 CDH-6.3.2 内置的 spark-2.4.0,重新运行任务,就没问题了。
5. 总结
CDH-6.3.2 中内置的 spark-2.4.0 有 bug,在实时数据处理上,如果是多并发处理,遇到 group by 时,对于同一个维度组合,可能会出现多条数据。
至于 hive on spark 和 spark on hive 的方式使用 CDH 内置的这个版本的 spark 会不会出现问题,目前还没去做验证,不过我们还是决定重新部署线上使用的 spark,替换为 apache spark 的稳定版本。
相关文章:

CDH-6.3.2内置spark-2.4.0的BUG
1. 背景 公司最近在新建集群,全部采用开源的大数据框架,并且将之前使用的阿里云的所有服务进行下线,其中就涉及到了旧任务的迁移。 2. 任务 2.1. 简述 我接手到一个之前的 spark 任务,是读取阿里 LogStore 数据,然…...
SpringCloud之ElasticSearch笔记
ElasticSearch 初识ElasticSearch ElasticSearch是什么 ElasticSearch一个基于Lucene的底层的开源的分布式搜索引擎,可用来实现搜索,日志统计,分析,系统监控 正向索引和倒排索引 正向索引:逐条扫描(my…...

数字图像学笔记 —— 17. 图像退化与复原(自适应滤波之「最小二乘方滤波」)
文章目录维纳滤波的缺点约束最小二乘方滤波给一个实际例子吧维纳滤波的缺点 维纳滤波(Wiener Filter),虽然是一种非常强大的退化图像还原算法,但是从实验过程我们也发现它存在着致命的缺陷,那就是要求输入退化系统的 …...
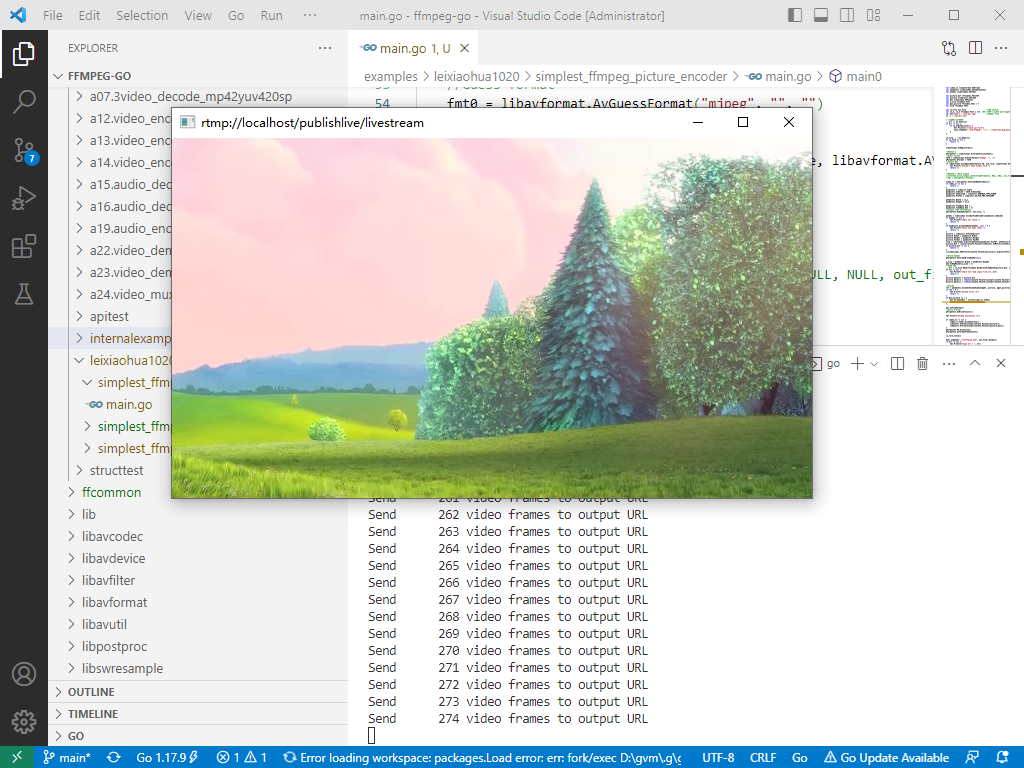
2023-03-05:ffmpeg推送本地视频至lal流媒体服务器(以RTMP为例),请用go语言编写。
2023-03-05:ffmpeg推送本地视频至lal流媒体服务器(以RTMP为例),请用go语言编写。 答案2023-03-05: 使用 github.com/moonfdd/ffmpeg-go 库。 先启动lal流媒体服务器软件,然后再执行命令: go…...
MathType7最新版免费数学公式编辑器
话说我也算是 MathType准资深(DB)用户了,当然自从感觉用DB不好之后,我基本上已经抛弃它了,只是前不久因为个别原因又捡起来用了用,30天试用期间又比较深入的折腾了下,也算是变成半个MathType砖家,coco玛奇朵简单介绍一下这款软件:在很可能看到这儿的你还没有出生的某个年月&…...

一文带你入门angular(中)
一、angular中的dom操作原生和ViewChild两种方式以及css3动画 1.原生操作 import { Component } from angular/core;Component({selector: app-footer,templateUrl: ./footer.component.html,styleUrls: [./footer.component.scss] }) export class FooterComponent {flag: b…...
设计多线程。)
单例设计模式共享数据问题分析、解决(c++11)设计多线程。
系列文章目录 单例设计模式共享数据问题分析、解决; 文章目录系列文章目录前言一、单例模式1.1 基本概念1.2 单例设计模式共享数据问题分析、解决1.3 std::call_once()介绍二、代码案例1.代码示例总结前言 关键内容:c11、多线程、共享数据、单例类 本章内容参考git…...

Embedding-based Retrieval in Facebook Search
facebook的社交网络检索与传统的搜索检索的差异是,除了考虑文本,还要考虑搜索者的背景。通用搜索主要考虑的是文本匹配,并没有涉及到个性化。像淘宝,youtube这些其实都是涉及到了用户自身行为的,除了搜索还有推荐&…...

xmu 离散数学 卢杨班作业详解【8-12章】
文章目录第八章 树23456810第九章46811第十章24567第十一章14571116第十二章131317第八章 树 2 (2) 设有k片树叶 2∗m2∗43∗3k2*m2*43*3k2∗m2∗43∗3k n23kn23kn23k mn−1mn-1mn−1 联立解得k9 T中有9片树叶 3 有三颗非同构的生成树 4 (1) c --abc e–abed f–dgf…...

Linux入门篇-权限管理
简介 用户管理也是和权限相关的知识点。权限的作用 权限对于普通文件和目录文件作用是不一样的 。[kioskfoundation0 ~]$ ls -l total 264 -rw-rw-r--. 2 kiosk kiosk 31943 May 29 2019 ClassPrep.txt -rw-rw-r--. 2 kiosk kiosk 7605 Jun 14 2019 ClassRHAPrep.txt -rw-rw-r…...
Linux(基于 Centos7) 常用操作
1.Linux 简介Linux 是一种 免费使用、自由传播的类 Unix 操作系统Linux操作系统内核,由林纳斯托瓦兹在1991年10月5日首次发布...Linux 是一套开源操作系统,它有稳定、消耗资源小、安全性高等特点大多数人都是直接使用 Linux 发行版(就是将 Li…...

Math类详解与Random类、三种随机数生成方式(java)
文章目录📖前言:🎀认识Random类🎀三种随机数生成方式🎀Math类的用途🎀Math类的方法📖前言: 本篇博客主要以介绍Math类的常用方法及认识Random类,及三种随机数生成方式 …...

Mac编译QT程序出现Undefined symbols for architecture x86_64
在Mac编写日志服务类, Logging_d.h内容如下 #pragma once #include <QLoggingCategory> Q_DECLARE_LOGGING_CATEGORY(hovering) Q_DECLARE_LOGGING_CATEGORY(creation) Q_DECLARE_LOGGING_CATEGORY(mouseevents) Q_DECLARE_LOGGING_CATEGORY(state) Q_DECLARE_LOGGING_C…...
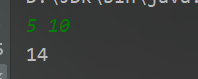
蓝桥杯-李白打酒加强版
蓝桥杯-李白打酒加强版1、问题描述2、解题思路3、代码实现1、问题描述 话说大诗人李白, 一生好饮。幸好他从不开车。 一天, 他提着酒显, 从家里出来, 酒显中有酒 2 斗。他边走边唱: 无事街上走,提显去打酒。 逢店加一倍, 遇花喝一斗。 这一路上, 他一共遇到店 N 次…...
 记录第一场ABC)
AtCoder Beginner Contest 292 (A - E) 记录第一场ABC
AtCoder Beginner Contest 292 A - E前言Q1 A - CAPS LOCKQ2 Yellow and Red CardQ3 Four VariablesQ4 D - Unicyclic ComponentsQ5 E - Transitivity前言 本来晚上在打Acwing周赛,最后一题Trie想不出来咋写,看群里有人说ABC要开始了,想着没…...
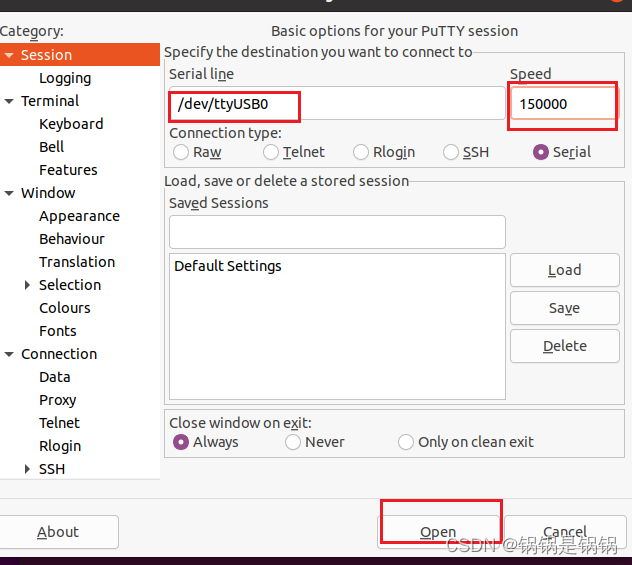
ubuntu安装使用putty
一、安装 安装虚拟机串口 sudo apt-get install putty sudo apt install -y setserial 二、使用 虚拟机连接串口 sudo setserial -g /dev/ttyS* 查看硬件对应串口 找到不是unknown的串口 sudo putty...

【CS144】Lab5与Lab6总结
Lab5与Lab6Lab汇总Lab5概述Lab6概述由于Lab5和Lab6相对比较简单(跟着文档一步一步写就行),于是放在一起做一个简单概述(主要是懒得写了…) Lab汇总 Lab5概述 lab5要求实现一个IP与Ethernet(以太网&#x…...

GDScript 导出变量 (Godot4.0)
概述 导出变量的功能在3.x版本中也是有的,但是4.0版本对其进行了语法上的改进。 导出变量在日常的游戏制作中提供节点的自定义参数化调节功能时非常有用,除此之外还用于自定义资源。 本文是(Bilibili巽星石)在4.0官方文档《GDScr…...
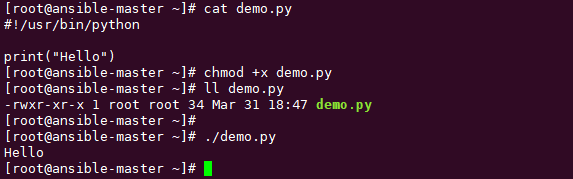
shell:#!/usr/bin/env python作用是什么
我们经常会在别人的脚本文件里看到第一行是下面这样 #!/usr/bin/python或者 #!/usr/bin/env python 那么他们有什么用呢? 要理解它,得把这一行语句拆成两部分。 第一部分是 #! 第二部分是 /usr/bin/python 或者 /usr/bin/env python 关于 #! 这个…...

计算机行业AIGC算力时代系列报告-ChatGPT芯片算力:研究框架
报告下载: 计算机行业AIGC算力时代系列报告-ChatGPT芯片算力:研究框架 简介 “AI算力时代已经来临,计算机行业正在经历着一场前所未有的变革!” 这是一个充满活力和兴奋的时代,人工智能(AI)已…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...

TSN交换机正在重构工业网络,PROFINET和EtherCAT会被取代吗?
在工业自动化持续演进的今天,通信网络的角色正变得愈发关键。 2025年6月6日,为期三天的华南国际工业博览会在深圳国际会展中心(宝安)圆满落幕。作为国内工业通信领域的技术型企业,光路科技(Fiberroad&…...

人工智能--安全大模型训练计划:基于Fine-tuning + LLM Agent
安全大模型训练计划:基于Fine-tuning LLM Agent 1. 构建高质量安全数据集 目标:为安全大模型创建高质量、去偏、符合伦理的训练数据集,涵盖安全相关任务(如有害内容检测、隐私保护、道德推理等)。 1.1 数据收集 描…...