[项目设计]高并发内存池
目录
1、项目介绍
2、高并发内存池整体框架设计
3、thread cache
<1>thread cache 哈希桶对齐规则
<2>Thread Cache类设计
4、Central Cache
<1>Central Cache类设计
5、page cache
<1>Page Cache类设计
6、性能分析
<1>定长内存池实现
<2>基数树
7、项目源码及项目总结
1、项目介绍
应用技术
什么是内存池?
想必大家看到这几个字也应该自己能想出个大概,简单来说内存池是指程序预先从操作系统申请一块足够大内存,然后自己管理。此后,当程序中需要申请内存的时候,不是直接向操作系统申请,而是直接从内存池中获取;同理,当程序释放内存的时候,并不真正将内存返回给操作系统,而是返回内存池。当程序退出(或者特定时间)时,内存池才将之前申请的内存真正释放。
内存池主要解决了效率问题,避免频繁找操作系统申请内存。 其次如果作为系统的内存分配器的角度,还需要解决一下内存碎片的问题。
那么什么是内存碎片呢?
内存碎片分为外碎片和内碎片,内碎片我们在下文项目中具体解释(这里我们简单概述一下),这里我们主要看比较容易理解的外碎片如图:
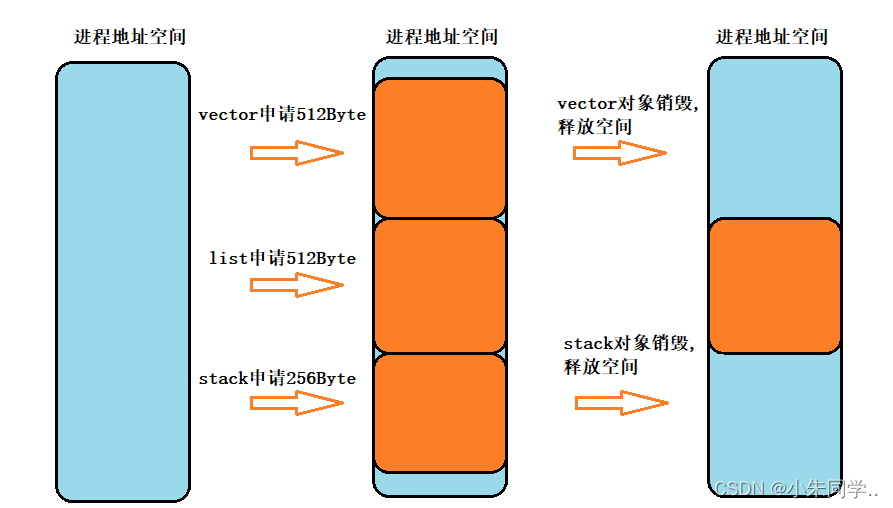
现有768Byte的空间,但是如果我们要申请超过512Byete的空间却申请不出来,因为这两块空间碎片化不连续了。
内碎片:内部碎片是由于一些对齐的需求,导致分配出去的空间中一些内存无法被利用。(具体见下文哈希桶对齐规则)
注:我们下面实现的内存池主要是是尝试解决的是外部碎片的问题,同时也尽可能的减少内部碎片的产生。
malloc
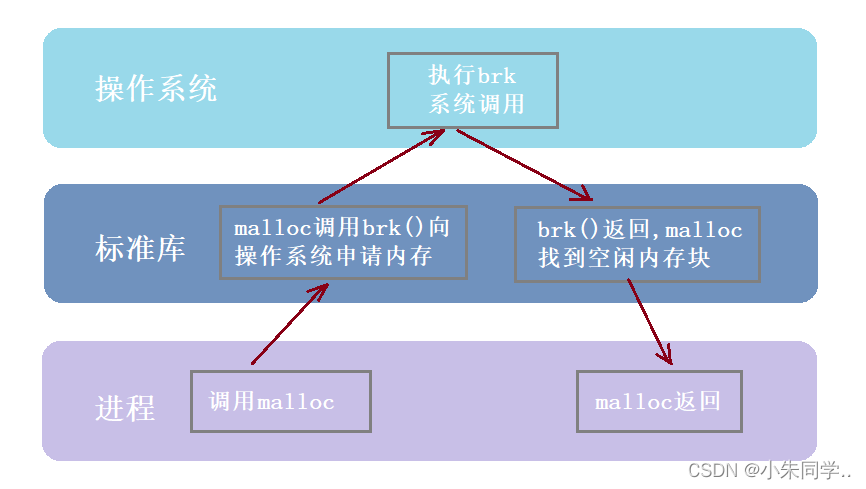
2、高并发内存池整体框架设计
- 性能问题。
- 多线程环境下,锁竞争问题。
- 内存碎片问题。

3、thread cache
thread cache是哈希桶结构,每个桶是一个按桶位置映射大小的内存块对象的自由链表。每个线程都会有一个thread cache对象,这样每个线程在这里获取对象和释放对象时是无锁的。
thread cache支持小于等于256KB内存的申请,如果我们将每种字节数的内存块都用一个自由链表进行管理的话,那么此时我们就需要20多万个自由链表,光是存储这些自由链表的头指针就需要消耗大量内存,这显然是得不偿失的。
这时我们可以选择做一些平衡的牺牲,让这些字节数按照某种规则进行对齐(见下文对齐规则),例如我们让这些字节数都按照8字节进行向上对齐(考虑到32位和64位下指针大小),那么thread cache的结构就是下面这样的,此时当线程申请1~8字节的内存时会直接给出8字节,而当线程申请9~16字节的内存时会直接给出16字节,以此类推。
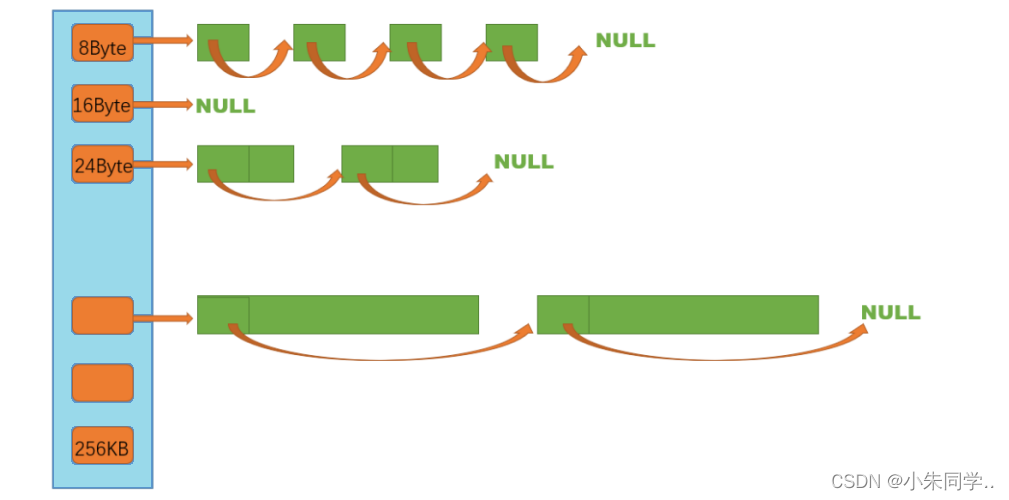
通过上图分析我们需要一个自由链表来管理内存块,下面我们来对自由链表进行封装(仅写出当前一些很容易想到的接口,后序需要我们在进行添加)。
class FreeList {
private:void* _freelist = nullptr;size_t _size = 0; //记录链表长度size_t _MaxSize = 1; //控制慢增长
public:void push(void* obj) {assert(obj);//头插CurNext(obj) = _freelist;_freelist = obj;++_size;}void* popFront() {assert(_freelist);void* cur = _freelist;_freelist = CurNext(_freelist);--_size;return cur;}bool Empty() {return _freelist == nullptr;}size_t& Size() {return _size;}size_t& MaxSize() {return _MaxSize;}
};<1>thread cache 哈希桶对齐规则
| 字节数 | 对齐数 | 哈希桶下标 | 区间桶数量 |
| [1,128] | 8byte对齐 | freelist[0,16) | 16 |
| [128+1,1024] | 16byte对齐 | freelist[16,72) | 56 |
| [1024+1,8*1024] | 128byte对齐 | freelist[72,128) | 56 |
| [8*1024+1,64*1024] | 1024byte对齐 | freelist[128,184) | 56 |
| [64*1024+1,256*1024] | 8*1024byte对齐 | freelist[184,208) | 24 |
上文中我们已经提到过内碎片这个概念,我们应该尽可能减少内碎片的产生。按照上面对齐规则的话整体控制在10%左右的内碎片浪费,第一个区间我们不做考虑因为1字节就算对齐到2字节也会产生50%的空间浪费,我们从第二个区间开始计算比如我们申请130个字节实际给到的是145字节实际多给了15字节。15/145 ≈ 0.103,浪费了大概在10左右,下面几个区间大家可以自己计算下浪费率也是大概在10%左右。
有了对齐规则我们还需要计算出相应的内存对应在哪一个桶中,如上表中每个区间都有一定桶的数量如[1,128]有16个桶那么我们申请1~8字节都对应在下标0号桶中,9~16字节都对应在下标1号桶中于是我们需要一个函数来处理计算。
对齐规则和下标映射规则编写
为了后序使用方便我们,将其封装在一个类当中。
static const size_t PAGE_SHIFT = 13;
static const size_t MAX_BYTES = 256 * 1024; //最大字节数//计算对象大小对齐规则
class SizeClass {
public://20 8 --> 24//110 8 --> 112//容易想到的//size_t _AlignSize(size_t bytes, size_t alignNum) {// size_t alignSize;// if (bytes % alignNum == 0) {// alignSize = bytes;// }// else {// alignSize = (bytes / alignNum + 1) * alignNum;// }// return alignSize;//}static inline size_t _AlignSize(size_t bytes, size_t alignNum){return ((bytes + alignNum - 1) & ~(alignNum - 1));}//对齐大小计算static inline size_t AlignSize(size_t bytes) {//assert(bytes <= MAX_BYTES);if (bytes <= 128) {return _AlignSize(bytes, 8);}else if (bytes <= 1024) {return _AlignSize(bytes, 16);}else if (bytes <= 8 * 1024) {return _AlignSize(bytes, 128);}else if (bytes <= 64 * 1024) {return _AlignSize(bytes, 1024);}else if (bytes <= 256 * 1024) {return _AlignSize(bytes, 8 * 1024);}else {return _AlignSize(bytes, 1 << PAGE_SHIFT); //页对齐}}//容易想到的//size_t _Index(size_t bytes, size_t alignNum) {// if (bytes % alignNum == 0) {// return bytes / alignNum - 1; //下标从0开始// }// else {// return bytes / alignNum;// }//}//20 3 --> 1//130 4 --> 8//好的实现方法static inline size_t _Index(size_t bytes, size_t align_shift){return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;}// 计算映射的哪一个自由链表桶static inline size_t Index(size_t bytes){assert(bytes <= MAX_BYTES);static int group_array[4] = { 16, 56, 56, 56 }; // 每个区间有多少个链if (bytes <= 128) {return _Index(bytes, 3); //传2的次方}else if (bytes <= 1024) {return _Index(bytes - 128, 4) + group_array[0];}else if (bytes <= 8 * 1024) {return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];}else if (bytes <= 64 * 1024) {return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];}else if (bytes <= 256 * 1024) {return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];}else {assert(false);}return -1;}
};<2>Thread Cache类设计
通过上述内存申请分析,可以想到我们需要申请内存函数和释放内存函数(释放内存函数分两种情况:链表长度较短直接将对象挂在链表中,链表长度过长释放链表)以及从中心缓存(central cache)获取对象的一个函数。如下定义:
class ThreadCache {
private:FreeList _freelists[NFREELIST];
public:void* Allocate(size_t size); //申请内存void Deallocate(void* ptr, size_t size); //释放内存void ListTooLong(FreeList& list, size_t size); //链表太长释放链表//从中心缓存获取对象void* FetchFromCentralCache(size_t index, size_t size);
};//TLS thread local storage --> 线程局部存储
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;接口实现:
//申请内存
void* ThreadCache::Allocate(size_t size) {assert(size <= MAX_BYTES);//传过来申请字节数计算出对齐大小(实际给到的内存大小)size_t alignSize = SizeClass::AlignSize(size);size_t index = SizeClass::Index(size);if (!_freelists[index].Empty()) {return _freelists[index].popFront();}else {//从中心缓存获取对象//...}
}
//释放内存
void ThreadCache::Deallocate(void* ptr, size_t size) {assert(ptr);assert(size <= MAX_BYTES);//找到对应桶位置进行插入size_t index = SizeClass::Index(size);_freelists[index].push(ptr);//当链表长度大于一次申请的最大内存值将其还给central cacheif (_freelists[index].Size() >= _freelists[index].MaxSize()) {ListTooLong(_freelists[index], size);}
}
//链表太长释放链表
void ThreadCache::ListTooLong(FreeList& list, size_t size) {//首先从原链表中将这段链表删除,接着还给中心缓存//在freelist中增加区间删除函数void* start = nullptr;void* end = nullptr;list.PopRange(start, end, list.Size());//将链表还给中心缓存//...
}//从中心缓存获取对象
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size) {//慢反馈调节算法//1、最开始不会一次向central cache批量要太多,因为要太多有可能会用不完//2、如果不断size大小内存需求,那么batchNum就会不断增长直到上限//3、size越小一次向central cache要的batchNum越小//4、size越大一次向central cache要的batchNum越大size_t batchNum = std::min(_freelists[index].MaxSize(), SizeClass::NumMoveSize(size));if (_freelists[index].MaxSize() == batchNum) {_freelists[index].MaxSize() += 1;}//调用cnetral cache中获取对象接口//...
}线程局部存储TLS(Thread Local Storage)
要实现每个线程无锁的访问属于自己的thread cache,我们需要用到线程局部存储TLS(Thread Local Storage),这是一种变量的存储方法,使用该存储方法的变量在它所在的线程是全局可访问的,但是不能被其他线程访问到,这样就保持了数据的线程独立性。但不是每个线程被创建时就立马有了属于自己的thread cache,而是当该线程调用相关申请内存的接口时才会创建自己的thread cache。
在FreeList类中添加PopRange函数
void PopRange(void*& start, void*& end, size_t n) {assert(n <= _size);start = _freelist;end = start;for (int i = 0; i < n - 1; i++) {end = CurNext(end);}_freelist = CurNext(end);CurNext(end) = nullptr;_size -= n;}在SizeClass类中添加NumMoveSize函数
// 一次thread cache从中心缓存获取多少个//也就是计算可以给到你几个对象//其中上限512,下限2也可以理解为限制桶中链表的长度static size_t NumMoveSize(size_t size){assert(size > 0);// [2, 512],一次批量移动多少个对象的(慢启动)上限值//对象越小,计算出的上限越高//对象越大,计算出的上限越低int num = MAX_BYTES / size;if (num < 2)num = 2;if (num > 512)num = 512;return num;}4、Central Cache

<1>Central Cache类设计
根据上图我们可以知道central cache也是一个哈希桶结构,通中挂的是一个个的span并且是双链表,而sapn中又包含了freellist,如下定义:
首先定义一个SpanNode的节点来表示一个个的Span对象
struct SpanNode {PAGE_ID _pageId = 0; //大块内存起始页号size_t _n = 0; //页的数量SpanNode* _next = nullptr;SpanNode* _prev = nullptr;void* _freeList = nullptr; //自由链表size_t _size = 0; //切好小对象大小size_t _useCount = 0; //分配给thread cache小块内存数量bool _isUse = false; //是否正在被使用};接着实现一个双链表结构用来将Span挂接起来
class SpanList {
private:SpanNode* _head = nullptr; //头节点std::mutex _mtx; //桶锁
public:SpanList() {_head = new SpanNode;_head->_next = _head;_head->_prev = _head;}~SpanList() {delete _head;}std::mutex& getMutex() {return _mtx;}SpanNode* Begin() {return _head->_next;}SpanNode* end() {return _head;}bool Empty() {return _head->_next == _head;}void Insert(SpanNode* pos, SpanNode* newSpan) {assert(pos && newSpan);SpanNode* prev = pos->_prev;prev->_next = newSpan;newSpan->_prev = prev;pos->_prev = newSpan;newSpan->_next = pos; }void Erase(SpanNode* pos) {assert(pos);assert(pos != _head);SpanNode* prev = pos->_prev;SpanNode* next = pos->_next;prev->_next = next;next->_prev = prev;}SpanNode* PopFront() {SpanNode* ret = _head->_next;Erase(ret);return ret;}void PushFront(SpanNode* spanNode) {Insert(Begin(), spanNode);}
};Central Cache类定义
//单例模式(懒汉)
class CentralCache {
private:SpanList _SpanLists[NFREELIST];
private:CentralCache() {}CentralCache(const CentralCache&) = delete;static CentralCache _sInst; //类外初始化
public:static CentralCache* GetInStance() {return &_sInst;}// 获取一个非空的spanNodeSpanNode* GetOneSpan(SpanList& list, size_t size);// 从中心缓存获取一定数量的对象给thread cachesize_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);// 将一定数量的对象释放到spanvoid ReleaseListToSpans(void* start, size_t byte_size);
};接口实现:
// 获取一个非空的spanNode
SpanNode* CentralCache::GetOneSpan(SpanList& list, size_t size) {//查看当前桶中的每个SpanNode节点是否有未分配的对象SpanNode* it = list.Begin();while (it != list.end()) {if (it->_freeList != nullptr) {return it;}else {it = it->_next;}}//走到这里说明当前桶中每个节点没有未分配的对象了,找pageCache要//...}// 从中心缓存获取一定数量的对象给thread cache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size) {size_t index = SizeClass::Index(size);//这里会涉及多个线程同时从中心缓存获取内存的情况,故应该加锁_SpanLists[index].getMutex().lock();SpanNode* spanNode = GetOneSpan(_SpanLists[index], size);assert(spanNode);assert(spanNode->_freeList);//从spanNode中获取batchNum个对象,如果不够有多少拿多少start = spanNode->_freeList;end = start;int i = 0;int ActualNum = 1;while (i < batchNum - 1 && CurNext(end) != nullptr) {end = CurNext(end);++i;++ActualNum;}//从spanNode将这段链表删除,并统计出该spanNode中自由链表已经使用的数量spanNode->_freeList = CurNext(end);CurNext(end) = nullptr;spanNode->_useCount += ActualNum;_SpanLists[index].getMutex().unlock();return ActualNum;
}
关于当链表太长时要将内存还给SpanNode时情况稍微有点复杂,需要好好思考一下。因为还回来的链表中的每个节点的地址我们没办法确定是否连续的。这就导致有可能换回来一个链表但其中的节点分布于_SpanList的多个SpanNode节点中,这就需要对其筛选让其进入不同的桶中(这部分代码我们放到Page Cache中来实现,因为Central Cache中的SpanNode节点都是Page Cache分配给他的),这里我们先把大概逻辑顺一下如下图:

测试代码如下:
void TestAddressPage() {PAGE_ID id1 = 3000;PAGE_ID id2 = 3001;char* p1 = (char*)(id1 << PAGE_SHIFT);char* p2 = (char*)(id2 << PAGE_SHIFT);while (p1 < p2) {cout << (void*)p1 << " : " << ((PAGE_ID)p1 >> PAGE_SHIFT) << endl;p1 += 8;}
}执行结果:

由上图我们可以看出,事实和我们的推论是一样的。释放内存代码如下图:
//将一定数量的对象释放到span
void CentralCache::ReleaseListToSpans(void* start, size_t byte_size) {size_t index = SizeClass::Index(byte_size);_SpanLists[index].getMutex().lock();//将传过来的链表一个个头插进对应的spanNode中while (start) {void* next = CurNext(start);//通过链表每个节点的地址来获取对应的spanNode地址SpanNode* SpanNode = PageCache::GetInstance()->MapObjectToSpan(start);CurNext(start) = SpanNode->_freeList;SpanNode->_freeList = start;SpanNode->_useCount--; //每头插回来一个已使用数量减一//当SpanNode已使用数量为0时说明该节点中的自由链表节点都还回来了,继续归还给PageCache处理if (SpanNode->_useCount == 0) {//归还给PageCache//...}start = next;}_SpanLists[index].getMutex().unlock();
}5、page cache
首先,central cache的映射规则与thread cache保持一致,而page cache的映射规则与它们都不相同。page cache的哈希桶映射规则采用的是直接定址法,比如1号桶挂的都是1页的span,2号桶挂的都是2页的span,以此类推。
其次,central cache每个桶中的span被切成了一个个对应大小的对象,以供thread cache申请。而page cache当中的span是没有被进一步切小的,因为page cache服务的是central cache,当central cache没有span时,向page cache申请的是某一固定页数的span,而如何切分申请到的这个span就应该由central cache自己来决定。
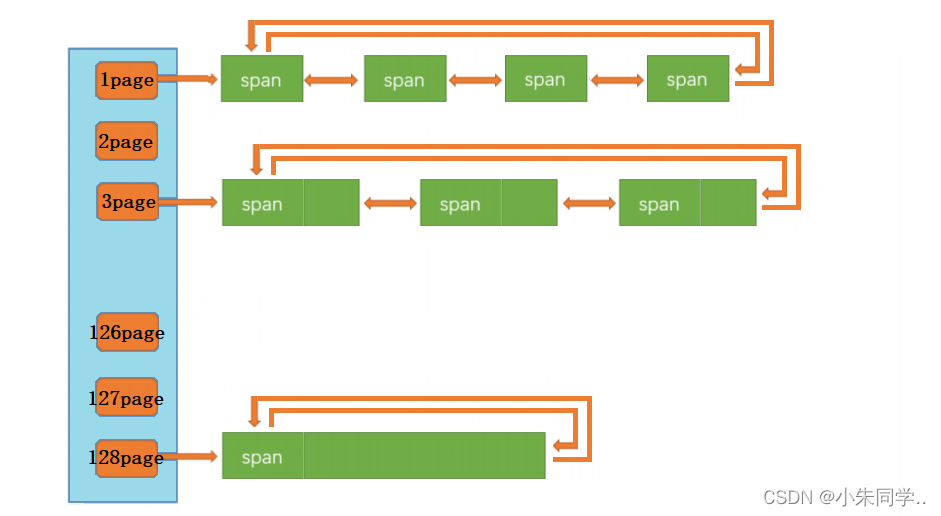
注:上图中1page和3page桶下面挂的链在最开始的时候是没有的他们都是由128page(我们每次向系统申请的是固定大小128page)切分后挂到上面的(切分逻辑见下文代码)。
<1>Page Cache类设计
通过上面的分析我们可以知道Page Cache和Central Cache一样是被多个线程共享的故也应该将其设计为单例模式,上面在讲Central Cache释放逻辑是提到我们要根据自由链的节点地址找到其对应SpanNode节点故我们还应该添加其映射关系这里我们采用unordered_map进行映射。此外我们还需要对Central Cache提供对象的接口、回收SpanNode的接口、获取映射关系的接口,如下定义:
static const size_t NPAGES = 129; //下标是从0开始的class PageCache {
private:SpanList _pageLists[NPAGES];std::unordered_map<PAGE_ID, SpanNode*> _idSpanNodeMap;std::mutex _PageMtx;
private:PageCache() {};PageCache(const PageCache&) = delete;static PageCache _sInst;
public:static PageCache* GetInstance() {return &_sInst;}std::mutex& GetMutex() {return _PageMtx;}//获取n页SpanNodeSpanNode* NewSpan(size_t n);//获取从对象到SpanNode的映射SpanNode* MapObjectToSpanNode(void* obj);//释放空闲SpanNode回到PageCache,并合并相邻的SpanNodevoid ReleaseSpanNodeToPageCache(SpanNode* SpanNode);
};代码实现:
当Page Cache中无内存时我们需要向系统取申请内存,故我们应该提供一个向系统申请内存的接口,如下
windows和Linux下如何直接向堆申请页为单位的大块内存:// 去堆上按页申请空间
inline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else// linux下brk mmap等
#endifif (ptr == nullptr)throw std::bad_alloc();return ptr;
}inline static void SystemFree(void* ptr)
{
#ifdef _WIN32VirtualFree(ptr, 0, MEM_RELEASE);
#else// linux下sbrk unmmap等
#endif
}static const size_t NPAGES = 129; //下标是从0开始的PageCache PageCache::_sInst;//获取n页SpanNode
SpanNode* PageCache::NewSpan(size_t n) {assert(n > 0);//大于128页直接向堆申请内存if (n > NPAGES - 1) {void* ptr = SystemAlloc(n);SpanNode* spanNode = new SpanNode;spanNode->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT; //右移13位相当于除8kspanNode->_n = n;_idSpanNodeMap[spanNode->_pageId] = spanNode; //建立映射方便释放内存return spanNode;}//检查对应桶中是否有sapnNodeif (!_pageLists[n].Empty()) {SpanNode* nSpanNode = _pageLists[n].PopFront();//将其中节点建立映射关系映射for (PAGE_ID i = 0; i < nSpanNode->_n; i++) {_idSpanNodeMap[nSpanNode->_pageId + i] = nSpanNode;}return nSpanNode;}//检查后面桶中是否有SpanNode节点,有则进行切分for (size_t i = n + 1; i < NPAGES; i++) {if (!_pageLists[i].Empty()) {//找到第i个桶不为空时先将其取出,切分出n个后在放回相应桶中SpanNode* ISpanNode = _pageLists[i].PopFront();//开辟出一个节点进行切分,然后返回SpanNode* NSpanNode = new SpanNode;NSpanNode->_n = n;NSpanNode->_pageId = ISpanNode->_pageId;ISpanNode->_pageId += n;ISpanNode->_n -= n;_pageLists[ISpanNode->_n].PushFront(ISpanNode);//存储ISpanNode起始页号映射方便回收_idSpanNodeMap[ISpanNode->_pageId] = ISpanNode;_idSpanNodeMap[ISpanNode->_pageId + ISpanNode->_n - 1] = ISpanNode;for (PAGE_ID i = 0; i < NSpanNode->_n; i++) {_idSpanNodeMap[NSpanNode->_pageId + i] = NSpanNode;}return NSpanNode;}}//走到这里说明后面的桶中没有剩余的SpanNode节点,找系统申请一页SpanNode* bigSpanNode = new SpanNode;void* ptr = SystemAlloc(NPAGES - 1);bigSpanNode->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT; bigSpanNode->_n = NPAGES - 1;_pageLists[bigSpanNode->_n].PushFront(bigSpanNode); //将申请的大页span放入哈希桶中return NewSpan(n); //重新调用进行切分}
//获取从对象到SpanNode的映射
SpanNode* PageCache::MapObjectToSpanNode(void* obj) {PAGE_ID id = (PAGE_ID)obj >> PAGE_SHIFT;std::unique_lock<std::mutex> lock(PageCache::GetInstance()->GetMutex()); //出作用域自动解锁auto ret = _idSpanNodeMap.find(id);if (ret != _idSpanNodeMap.end()) {//找到了进行返回return ret->second;}else {//找不到说明出问题了直接报错assert(false); return nullptr;}
}//释放空闲SpanNode回到PageCache,并合并相邻的SpanNode
void PageCache::ReleaseSpanNodeToPageCache(SpanNode* spanNode) {//大于128页直接还给堆if (spanNode->_n > NPAGES - 1) {//根据页号算出响应的地址,然后进行释放void* ptr = (void*)(spanNode->_pageId << PAGE_SHIFT);SystemFree(ptr);return;}//向前合并while (1) {PAGE_ID prev = spanNode->_pageId - 1;//找不到跳出循环auto ret = _idSpanNodeMap.find(prev);if (ret == _idSpanNodeMap.end()) {break;}//prevSpanNode正在被使用跳出循环SpanNode* prevSpanNode = ret->second;if (prevSpanNode->_isUse == true) {break;}//合并出超出128kb的spanNode不进行管理if (prevSpanNode->_n + spanNode->_n > NPAGES - 1) {break;}//进行合并spanNode->_pageId = prevSpanNode->_pageId;spanNode->_n += prevSpanNode->_n;_pageLists[prevSpanNode->_n].Erase(prevSpanNode);delete prevSpanNode;}//向后合并while (1) {PAGE_ID next = spanNode->_pageId - 1;//找不到跳出循环auto ret = _idSpanNodeMap.find(next);if (ret == _idSpanNodeMap.end()) {break;}//prevSpanNode正在被使用跳出循环SpanNode* nextSpanNode = ret->second;if (nextSpanNode->_isUse == true) {break;}//合并出超出128kb的spanNode不进行管理if (nextSpanNode->_n + spanNode->_n > NPAGES - 1) {break;}//进行合并spanNode->_n += nextSpanNode->_n;_pageLists[nextSpanNode->_n].Erase(nextSpanNode);delete nextSpanNode;}//放回哈希桶中_pageLists[spanNode->_n].PushFront(spanNode);spanNode->_isUse = false;存储ISpanNode起始页号映射方便回收_idSpanNodeMap[spanNode->_pageId] = spanNode;_idSpanNodeMap[spanNode->_pageId + spanNode->_n - 1] = spanNode;
}6、性能分析
参考了一段别人的测试代码,进行测试: 测试代码链接

这个时候不要去盲目改代码,我们可以在VS中找到性能分析来分析我们的程序看看是什么原因导致的,如下图:


 由此我们可以看出,我们大部分时间都浪费在锁上面了而且是map映射的时候,那么有什么办法呢?
由此我们可以看出,我们大部分时间都浪费在锁上面了而且是map映射的时候,那么有什么办法呢?
其实我们除了上面的锁浪费时间外,还有程序中的new我们可以替换成一个定长内存池(因为其效率比new要高一些,大家可以自行测试一下)。
<1>定长内存池实现
malloc其实就是一个通用的内存池,在什么场景下都可以使用,但这也意味着malloc在什么场景下都不会有很高的性能,因为malloc并不是针对某种场景专门设计的。定长内存池就是针对固定大小内存块的申请和释放的内存池,由于定长内存池只需要支持固定大小内存块的申请和释放,因此我们性能方面要比malloc高一些,并且在实现定长内存池时不需要考虑内存碎片等问题,因为我们申请/释放的都是固定大小的内存块。
代码如下:
template<class T>
class FiedMemoryPool {
private:char* _memory = nullptr; //指向大块内存的指针void* _freeList = nullptr;//还内存链接自由链表头指针size_t _residueBytes = 0; //剩余字节数
public:T* New() {T* obj = nullptr;//优先把还回来的对象重复利用if (_freeList) {void* next = *((void**)_freeList);obj = (T*)_freeList;_freeList = next;}else {//剩余内存不够一个对象大小时重新开辟内存if (_residueBytes < sizeof(T)) {_residueBytes = 128 * 1024;_memory = (char*)SystemAlloc(_residueBytes >> PAGE_SHIFT);if (_memory == nullptr) {throw std::bad_alloc();}}//给目标分配内存obj = (T*)_memory;size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T); //至少开辟一个指针大小_memory += objSize;_residueBytes -= objSize;}//用定位new显示调用其构造函数new (obj)T;return obj;}void Delete(T* obj) {//显示调用其析构函数obj->~T();//头插进自由链表*(void**)obj = _freeList;_freeList = obj;}
};有了定长内存池我们只需要将代码中new出来的对象替换成用定长内存池来申请就可以了(new 底层依然是调用malloc)由于这部分替换起来比较简单就不在详细讲述了,具体代码参考文章末尾项目源代码。
<2>基数树
基数树之所以能够提升效率是因为基数树在使用时是不用加锁的,基数树的空间一旦开辟好了就不会发生变化,因此无论什么时候去读取某个页的映射,都是对应在一个固定的位置进行读取的。并且我们不会同时对同一个页进行读取映射和建立映射的操作,因为我们只有在释放对象时才需要读取映射。
基数树代码链接
有了基数树我们只需要将PageCache中unorder_map定义的对象用基数树来定义就可以了,具体代码实现参考文章末尾源代码实现。
使用上面两种方法对项目进行优化后在进行测试,如图:
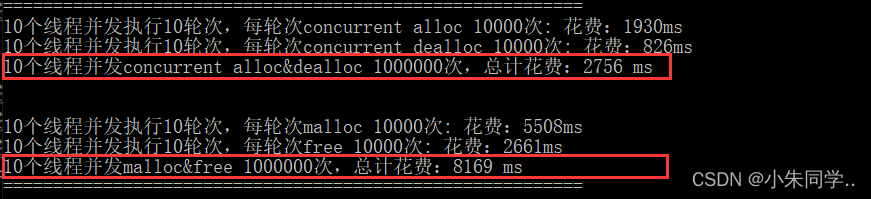
由上图很明显可以看出,此时我们实现的内存池在并发环境下效率更胜一筹。
7、项目源码
项目源码
项目到这里就算完成了,感觉有用的话期待大家点赞关注,项目中有哪些地方有疑问的话欢迎大家评论留言。
相关文章:
[项目设计]高并发内存池
目录 1、项目介绍 2、高并发内存池整体框架设计 3、thread cache <1>thread cache 哈希桶对齐规则 <2>Thread Cache类设计 4、Central Cache <1>Central Cache类设计 5、page cache <1>Page Cache类设计 6、性能分析 <1>定长内存池实现…...
28岁才转行软件测试,目前32了,我的一些经历跟感受
我是92年的,算是最早的90后,现在跟你介绍的时候还恬不知耻的说我是90后,哈哈,计算机专业普通本科毕业。在一个二线城市,毕业后因为自身能力问题、认知水平问题,再加上运气不好,换过多份工作&…...
Python导入模块的3种方式
很多初学者经常遇到这样的问题,即自定义 Python 模板后,在其它文件中用 import(或 from...import) 语句引入该文件时,Python 解释器同时如下错误:ModuleNotFoundError: No module named 模块名意思是 Pytho…...
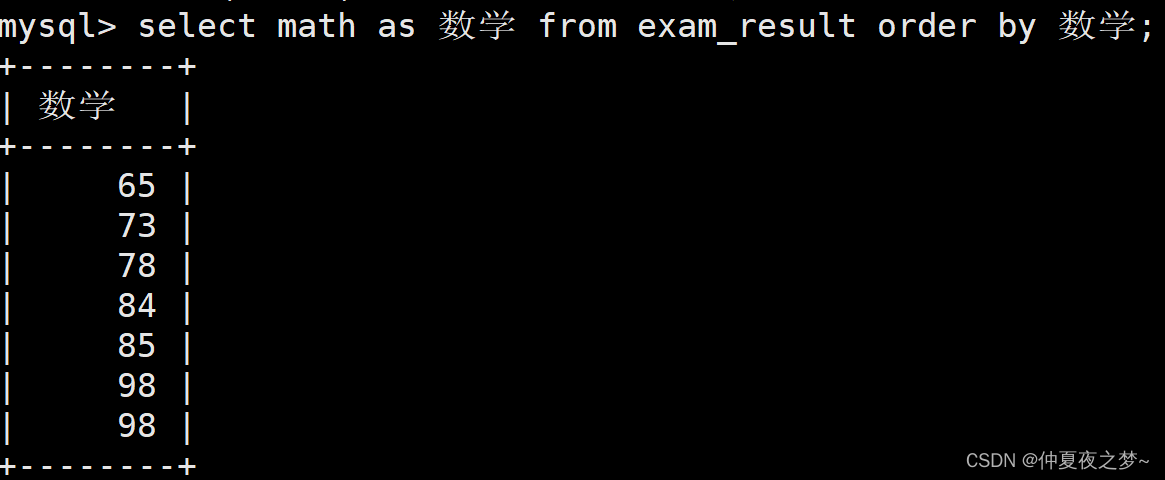
select 与 where、order by、limit 子句执行优先级比较
当 select 和 其他三种语句的一者或者多者同时出现时,他们之间是存在执行先后顺序的。 他们的优先级顺序是:where > select > order by > limit 目录 1、select 与 where 2、select 与 order by 3、order by 与 limit 4、优先级证明 1、s…...
Linux内核并发与竞争-原子操作
一.原子操作的概念首先看一下原子操作,原子操作就是指不能再进一步分割的操作,一般原子操作用于变量或者位操作。假如现在要对无符号整形变量 a 赋值,值为 3,对于 C 语言来讲很简单,直接就是: a3但是 C 语言…...

Java笔记-泛型的使用
参考: Java 泛型,你了解类型擦除吗? 泛型的使用 1、泛型的定义 可以广泛使用的类型,一种较为准确的说法就是为了参数化类型,或者说可以将类型当作参数传递给一个类或者是方法。 2、泛型的使用 2.1泛型类 public c…...
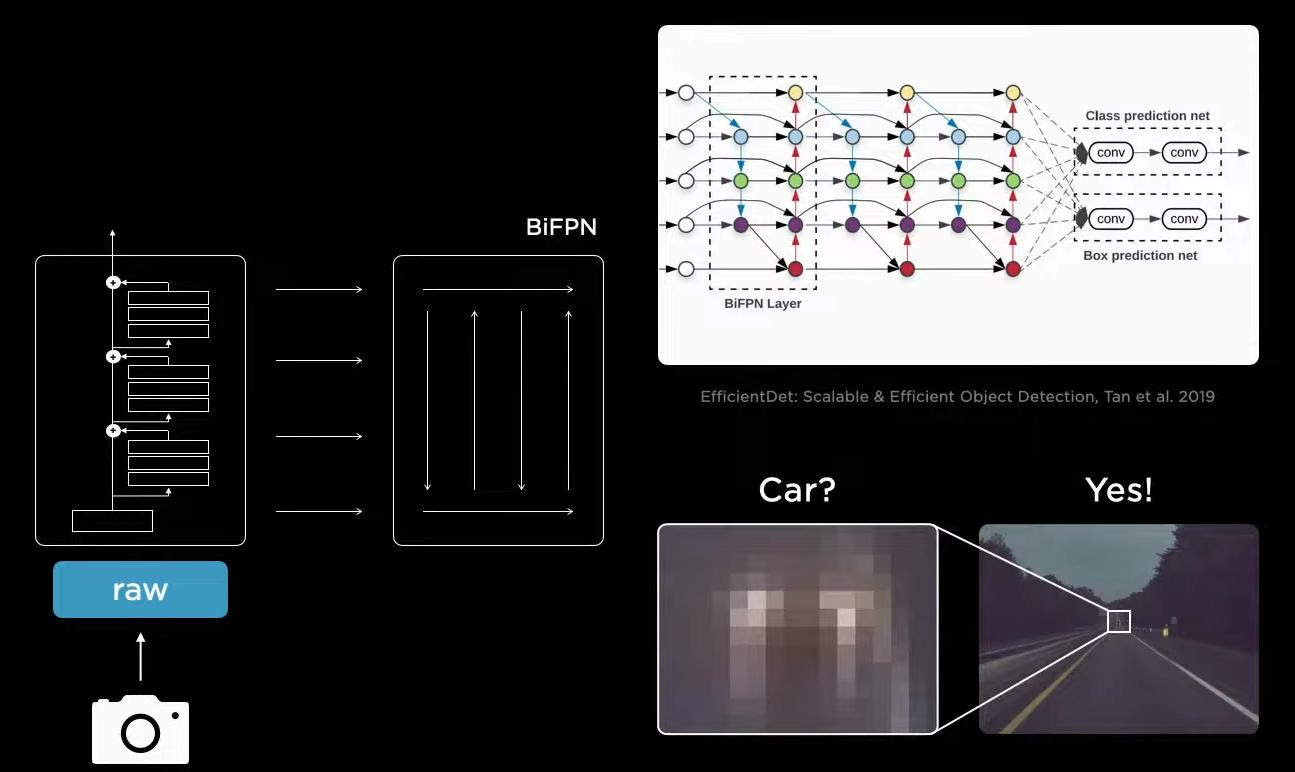
特斯拉无人驾驶解读
来源于Tesla AI Day Tesla无人驾驶算法的核心任务就是如何理解我们所看到的一切呢?也就是说,不使用高端的设备,比如激光雷达,仅仅使用摄像头就能够将任务做得很好。Tesla使用环绕型的8个摄像头获得输入。 第一步是特征提取模块Backbone,无论什么任务都离不开特征…...
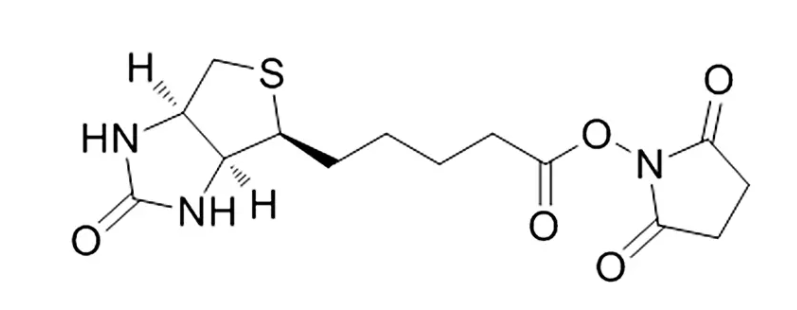
生物素-琥珀酰亚胺酯Biotin-NHS;CAS号:35013-72-0;可对溶液中的抗体,蛋白质和任何其他含伯胺的大分子进行简单有效的生物素标记。
结构式: 生物素-琥珀酰亚胺酯Biotin NHS CAS号:35013-72-0 英文名称:Biotin-NHS 中文名称:D-生物素 N-羟基琥珀酰亚胺酯;生物素-琥珀酰亚胺酯 CAS号:35013-72-0 密度:1.50.1 …...
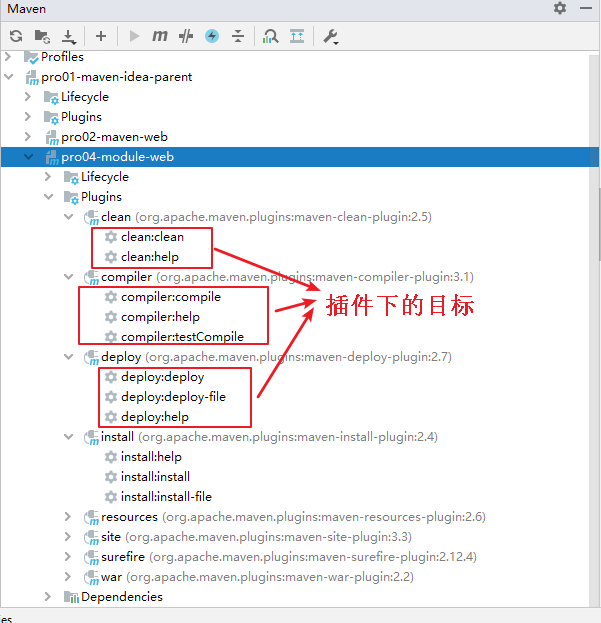
Maven_第五章 核心概念
目录第五章 其他核心概念1、生命周期①作用②三个生命周期③特点2、插件和目标①插件②目标3、仓库第五章 其他核心概念 1、生命周期 ①作用 为了让构建过程自动化完成,Maven 设定了三个生命周期,生命周期中的每一个环节对应构建过程中的一个操作。 …...

【深度学习】人脸识别工程化落地
文章目录前言1、facenet2、使用2.1.其它blog2.2 实践总结前言 老早以前就希望能写一篇关于人脸识别的工程化落地的案例,一年前做疲劳驾驶时使用的dlib插件,它封装好了,人脸检测、对齐、相似度计算三个部分,就是插件比较难装,但同时也少了很多…...
AOP面向切面编程思想。
目录 一、AOP工作流程 1、基本概念 2、AOP工作流程 二、AOP核心配置 1、AOP切入点表达式 2、AOP通知类型 三、AOP通知获取数据 1、获取参数 2、获取返回值 3、获取异常 四、AOP事务管理 1、Spring事务简介 2、Spring事务角色 3、事务属性 一、AOP工作流程 1、…...

实验7-变治技术及动态规划初步
目录 1.统计个数 2.数塔dp -A 3.Horspool算法 4.计数排序 5.找零问题1-最少硬币 1.统计个数 【问题描述】有n个数、每个元素取值在1到9之间,试统计每个数的个数 【输入形式】第一行,n的值;第二行...
JVM垃圾回收机制GC理解
目录JVM垃圾回收分代收集如何识别垃圾引用计数法可达性分析法引用关系四种类型: 强、软、弱、虚强引用软引用 SoftReference弱引用 WeakReferenceWeakHashMap软引用与虚引用的使用场景虚引用与引用队列引用队列虚引用 PhantomReference垃圾回收算法引用计数复制 Cop…...

C++中的容器
1.1 线性容器1)std::array看到这个容器的时候肯定会出现这样的问题:为什么要引入 std::array 而不是直接使用 std::vector?已经有了传统数组,为什么要用 std::array?先回答第一个问题,与 std::vector 不同,…...
2023备战金三银四,Python自动化软件测试面试宝典合集(五)
接上篇八、抓包与网络协议8.1 抓包工具怎么用 我原来的公司对于抓包这块,在 App 的测试用得比较多。我们会使用 fiddler 抓取数据检查结果,定位问题,测试安全,制造弱网环境;如:抓取数据通过查看请求数据,请…...

SpringDI自动装配BeanSpring注解配置和Java配置类
依赖注入 上篇博客已经提到了DI注入方式的构造器注入,下面采用set方式进行注入 基于set方法注入 public class User {private String name;private Address address;private String[] books;private List<String> hobbys;private Map<String,String>…...
2月面经:真可惜...拿了小米的offer,字节却惨挂在三面
我是2月份参加字节跳动和华为的面试的,虽然我只拿下了小米的offer,但是我自己也满足了,想把经验分享出来,进而帮助更多跟我一样想进大厂的同行朋友们,希望大家可以拿到理想offer。 自我介绍 我是16年从南京工业大学毕…...

磐云PY-B8 网页注入
文章目录1.使用渗透机场景windows7中火狐浏览器访问服务器场景中的get.php,根据页面回显获取Flag并提交;2.使用渗透机场景windows7中火狐浏览器访问服务器场景中的post.php,根据页面回显获取Flag并提交;3.使用渗透机场景windows7中…...

多传感器融合定位十-基于滤波的融合方法Ⅰ其二
多传感器融合定位十-基于滤波的融合方法Ⅰ其二3. 滤波器基本原理3.1 状态估计模型3.2 贝叶斯滤波3.3 卡尔曼滤波(KF)推导3.4 扩展卡尔曼滤波(EKF)推导3.5 迭代扩展卡尔曼滤波(IEKF)推导4. 基于滤波器的融合4.1 状态方程4.2 观测方程4.3 构建滤波器4.4 Kalman 滤波实际使用流程4…...
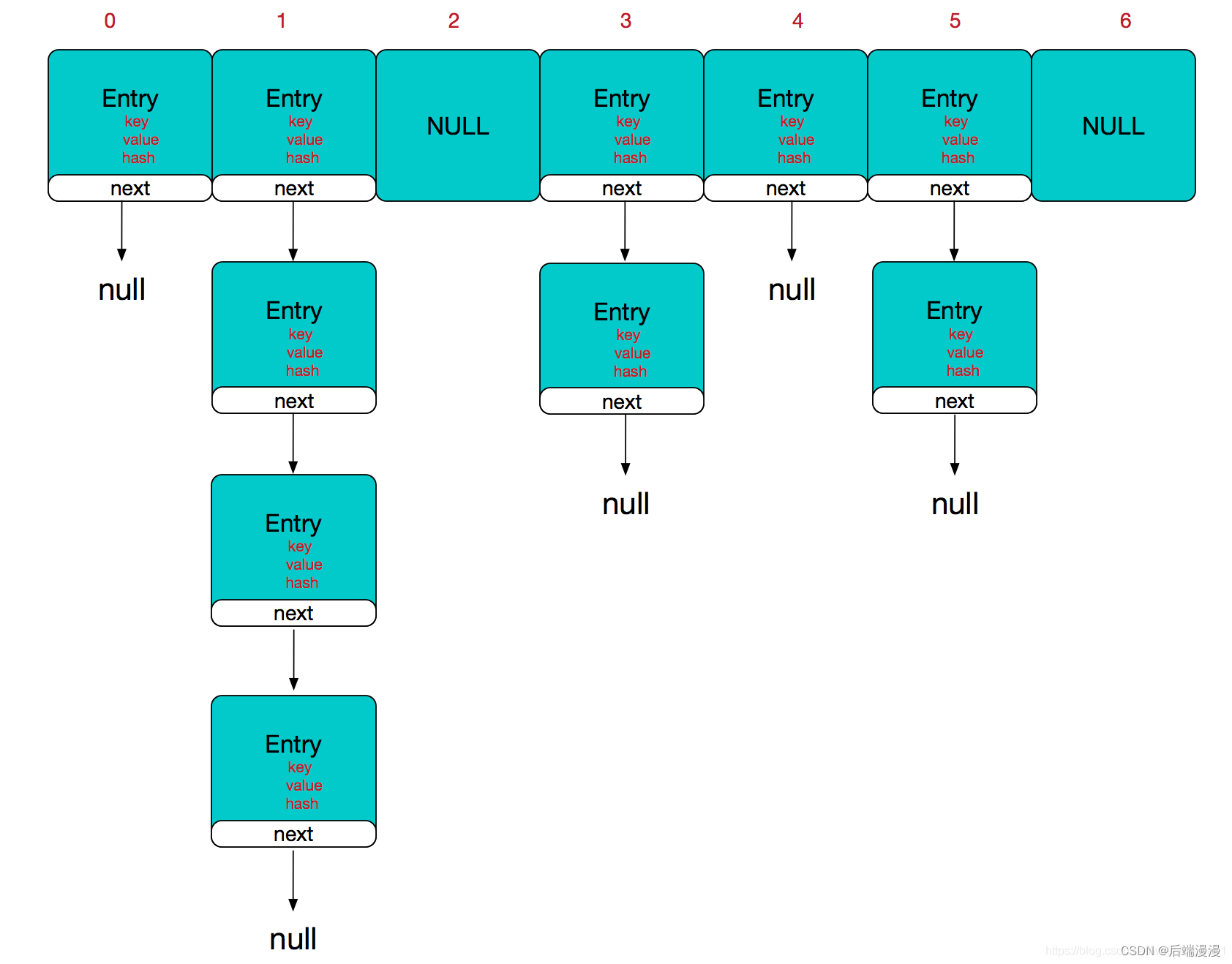
Java集合面试题:HashMap源码分析
文章目录一、HashMap源码二、HashMap数据结构模型图三、HashMap中如何确定元素位置四、关于equals与hashCode函数的重写五、阅读源码基本属性参考文章:史上最详细的 JDK 1.8 HashMap 源码解析参考文章:Hash详解参考文章:hashCode源码分析参考…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...