卷积神经网络的原理及实现
专栏:神经网络复现目录
卷积神经网络
本章介绍的卷积神经网络(convolutional neural network,CNN)是一类强大的、为处理图像数据而设计的神经网络。 基于卷积神经网络架构的模型在计算机视觉领域中已经占主导地位,当今几乎所有的图像识别、目标检测或语义分割相关的学术竞赛和商业应用都以这种方法为基础。
文章部分文字和代码来自《动手学深度学习》
文章目录
- 卷积神经网络
- 从全连接层到卷积层
- 两个性质
- 1. 平移不变性
- 2. 局部性
- 卷积的数理逻辑
- 使用平移不变性推导
- 使用局部性推导
- 通道
- 图像卷积
- 互相关运算
- 定义
- 代码实现
- 卷积层
- 图像中目标的边缘检测
- 构造图像
- 构造卷积核
- 进行卷积运算
- 卷积核的获取
- 特征映射和感受野
- 填充和步幅
- 填充
- 步幅
- 多输入多输出通道
- 多输入通道
- 多通道输出
- 1 ×\times× 1 卷积层
- 汇聚层/池化层
- 最大汇聚层和平均汇聚层
- pytorch中的使用
- 多个通道
- 卷积神经网络(LeNet)
- 定义
- 实现
- 模型
- 训练
- 测试
从全连接层到卷积层
首先思考一个问题:为什么不使用全连接层?我们在上一节明明取得了很好的效果。
答: 全连接层有其巨大的缺陷,参数过多 ,由于计算机性能的限制,过多的参数使其并不能拥有较多的层数,故没有办法达到很好的效果。
举个例子:
假设我们有一个足够充分的照片数据集,数据集中是拥有标注的照片,每张照片具有百万级像素,这意味着网络的每次输入都有一百万个维度。 即使将隐藏层维度降低到1000,这个全连接层也将有个参数。 想要训练这个模型将不可实现,因为需要有大量的GPU、分布式优化训练的经验和超乎常人的耐心。
下面我们开始学习如何简化网络。
两个性质
首先我们学习计算机视觉网络框架中比较重要的两个性质:
1. 平移不变性
平移不变性(Translation Invariance)是指一个模型对于输入数据的平移操作不敏感。也就是说,如果对于输入数据进行平移操作后,模型输出不变,则模型具有平移不变性。
通俗的说:不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”。
在计算机视觉领域,图像是由像素点组成的,每个像素点都具有一个坐标。由于图像中物体的位置、大小、旋转等都可能发生变化,如果模型不能处理平移操作,那么在图像中同一物体的不同位置上都要训练一个独立的模型,这将导致需要训练的模型数目大大增加。
一个例子是对于一个图像分类任务,如果对输入图像进行平移操作,比如将图像整体向左平移一个像素,那么图像的内容和类别并没有发生变化,但是像素矩阵的数值却发生了变化。如果我们的模型没有考虑到这种平移操作,那么对于同一张图像的不同平移版本,模型可能会做出不同的预测结果。因此,为了提高模型的泛化能力,我们需要考虑平移不变性,使得模型对于图像平移的变化具有鲁棒性。
2. 局部性
局部性是指在一个数据集中,相邻的数据往往具有相关性或者相似性。这种相关性或相似性可能是空间上的,也可能是时间上的,或者是其他方面的。例如,对于一组包含了大量图片的数据集,其中相邻的图片很可能是相似的,即它们有相似的纹理、颜色、形状等等特征。在图像处理任务中,通常会利用局部性来设计卷积神经网络,以利用相邻像素之间的相关性。
卷积神经网络中是指:神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测。
一个计算机视觉的例子是图像识别,其中局部性是指每个图像中的像素点只与其周围像素相关,而不受图像其他部分的影响。这是因为在图像中,每个像素点的意义仅仅取决于其在图像中的位置,而与整个图像的大小和形状无关。例如,如果我们想要识别一张包含猫的图片,我们只需要观察每个像素点的灰度值,以及每个像素点周围的一些像素,而不需要考虑图像的整体形状和大小。因此,计算机视觉中的许多算法都利用了这种局部性来实现高效的图像处理和分析。
卷积的数理逻辑
首先,多层感知机的输入是二维图像XXX,其隐藏表示HHH在数学上是一个矩阵,在代码中表示为二维张量。 其中XXX和HHH具有相同的形状。 为了方便理解,我们可以认为,无论是输入还是隐藏表示都拥有空间结构。
使用[X]i,j[X]_{i,j}[X]i,j和[H]i,j[H]_{i,j}[H]i,j分别表示输入图像和隐藏表示中位置(i,j)处的像素。 为了使每个隐藏神经元都能接收到每个输入像素的信息,我们将参数从权重矩阵(如同我们先前在多层感知机中所做的那样)替换为四阶权重张量。假设包含偏置参数,我们可以将全连接层形式化地表示为:
[H]i,j=[U]i,j+[W]i,j[X]=[U]i,j+∑k∑l[W]i,j,k,l[X]k,l=[U]i,j+∑a∑b[V]i,j,a,b[X]i+a,j+b.[ H ] _ { i , j }=[ U ] _ { i , j } +[ W ] _ { i , j } [ X ] \\ = [ U ] _ { i , j } + \sum _ { k } \sum _ { l } [ W ] _ { i , j , k , l } [ X ] _ { k , l }\\ = [ U ] _ { i , j } + \sum _ { a } \sum _ { b } [ V ] _ { i , j , a , b } [ X ] _ { i + a , j + b } .[H]i,j=[U]i,j+[W]i,j[X]=[U]i,j+k∑l∑[W]i,j,k,l[X]k,l=[U]i,j+a∑b∑[V]i,j,a,b[X]i+a,j+b.
其中,从W到V的转换只是形式上的转换,因为在这两个四阶张量的元素之间存在一一对应的关系。 我们只需重新索引下标(k,l),使k=i+a,l=j+b,由此可得[V]i,j,a,b=[W]i,j,i+a,j+b[ V ] _ { i , j ,a,b}=[ W ] _ { i , j,i+a,j+b }[V]i,j,a,b=[W]i,j,i+a,j+b 。索引a和b通过在正偏移和负偏移之间移动覆盖了整个图像。
使用平移不变性推导
现在引用上述的第一个原则:平移不变性。 这意味着检测对象在输入XXX中的平移,应该仅导致隐藏表示HHH中的平移,不改变值。
也就是说,VVV和UUU实际上不依赖于的(iii,jjj)值,即
[V]i,j,a,b=[V]a,b[ V ] _ { i , j ,a,b}=[ V ] _ { a,b}[V]i,j,a,b=[V]a,b
还记得刚才我们说什么吗?
不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应
上述公式就是这个意思,不依赖对象出现的位置,位置坐标并不是参数,于是有了简化。
并且U是一个常数,比如u。因此,我们可以简化定义为:
[H]i,j=u+∑a∑b[V]a,b[X]i+a,j+b[ H ] _ { i , j } = u + \sum _ { a } \sum _ { b } [V ] _ { a,b} [ X ] _ {i + a , j + b } [H]i,j=u+a∑b∑[V]a,b[X]i+a,j+b
使用局部性推导
现在引用上述的第二个原则:局部性。如上所述,为了收集用来训练参数[H]i,j[ H ] _ { i , j }[H]i,j的相关信息,我们不应偏离到距(i,j)很远的地方。这意味着在|a|>△或|b|>△的范围之外,我们可以设置 [V]a,b=0[V ] _ { a,b}=0[V]a,b=0,因此公式可简化为:
[H]i,j=u+∑a=−△△∑b=−△△[V]a,b[X]i+a,j+b[ H ] _ { i , j } = u + \sum _ { a =-△}^△ \sum _ {b =-△}^△ [V ] _ { a,b} [ X ] _ {i + a , j + b } [H]i,j=u+a=−△∑△b=−△∑△[V]a,b[X]i+a,j+b
这样我们得出了卷积的公式
通道
然而这种方法有一个问题:我们忽略了图像一般包含三个通道/三种原色(红色、绿色和蓝色)。 实际上,图像不是二维张量,而是一个由高度、宽度和颜色组成的三维张量,比如包含1024 ∗*∗ 1024 ∗*∗ 3个像素。 前两个轴与像素的空间位置有关,而第三个轴可以看作每个像素的多维表示。 因此,我们将X索引为[X]i,j,k[ X] _ { i , j,k }[X]i,j,k,由此卷积相应地调整为[V]a,b,c[V] _ { a,b,c }[V]a,b,c
此外,由于输入图像是三维的,我们的隐藏表示HHH也最好采用三维张量。 换句话说,对于每一个空间位置,我们想要采用一组而不是一个隐藏表示。这样一组隐藏表示可以想象成一些互相堆叠的二维网格。 因此,我们可以把隐藏表示想象为一系列具有二维张量的通道(channel)。 这些通道有时也被称为特征映射(feature maps),因为每个通道都向后续层提供一组空间化的学习特征。 直观上可以想象在靠近输入的底层,一些通道专门识别边缘,而一些通道专门识别纹理。
为了支持输入X和隐藏表示H中的多个通道,我们可以在中添加第四个坐标,即d。综上所述,
[H]i,j,d=ud+∑a=−△△∑b=−△△∑c[V]a,b,c,d[X]i+a,j+b,c[ H ] _ { i , j ,d} = u_d + \sum _ { a =-△}^△ \sum _ {b =-△}^△\sum _ {c } [V ] _ { a,b,c,d} [ X ] _ {i + a , j + b,c } [H]i,j,d=ud+a=−△∑△b=−△∑△c∑[V]a,b,c,d[X]i+a,j+b,c
其中隐藏表示HHH中的索引ddd表示输出通道,而随后的输出将继续以三维张量HHH作为输入进入下一个卷积层。
图像卷积
互相关运算
定义
互相关运算(cross-correlation operation)是卷积运算的一种形式,两者在计算方式上类似,但是卷积运算通常会在核函数上进行翻转(也称为旋转180度),而互相关运算则不进行翻转。
具体来说,给定一个输入张量和一个卷积核张量,它们在输入的每个位置上做卷积操作,可以将卷积核看作一个模板,在输入上滑动这个模板,对于模板覆盖的区域进行元素乘积的累加,将其作为输出的对应位置的值。互相关运算与卷积运算的区别在于,卷积运算在计算中会先将卷积核进行翻转(或旋转180度),再进行与输入的元素乘积和求和,而互相关运算则不翻转卷积核,直接进行元素乘积和求和。
数学公式表示:
对于二维输入张量 XXX 和卷积核张量 KKK,它们的互相关运算可以表示为:
Yi,j=∑a=1h∑b=1wXi+a−1,j+b−1Ka,bY_{i,j}=\sum_{a=1}^{h}\sum_{b=1}^{w}X_{i+a-1,j+b-1}K_{a,b}Yi,j=∑a=1h∑b=1wXi+a−1,j+b−1Ka,b
其中,hhh 和 www 分别是卷积核的高度和宽度,iii 和 jjj 分别是输出张量 YYY 中的高度和宽度的索引。这个公式可以理解为,对于输出张量 YYY 中的每一个位置 (i,j)(i,j)(i,j),用输入张量 XXX 中以 (i,j)(i,j)(i,j) 为左上角的 h×wh\times wh×w 的矩形区域与卷积核 KKK 进行元素乘积和求和,得到输出张量 YYY 中位置 (i,j)(i,j)(i,j) 的值。
图示:
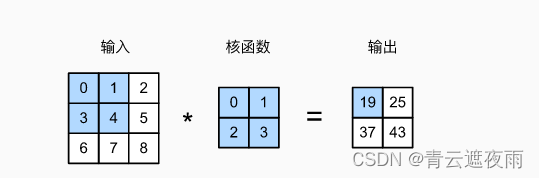
输出矩阵的大小与 输入矩阵大小和核函数大小有关,公式为:

代码实现
import torch
from torch import nn
from d2l import torch as d2ldef corr2d(X, K): #@save"""计算二维互相关运算"""h, w = K.shapeY = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))for i in range(Y.shape[0]):for j in range(Y.shape[1]):Y[i, j] = (X[i:i + h, j:j + w] * K).sum()return Y
卷积层
class Conv2D(nn.Module):def __init__(self, kernel_size):super().__init__()self.weight = nn.Parameter(torch.rand(kernel_size))self.bias = nn.Parameter(torch.zeros(1))def forward(self, x):return corr2d(x, self.weight) + self.bias
这是一个使用 PyTorch 实现的二维卷积层的简单代码。其中,kernel_size 参数表示卷积核的大小。
在初始化方法 init 中,我们使用 nn.Parameter 创建了权重张量 self.weight 和偏置项 self.bias,它们都是可训练的模型参数。
在前向传播方法 forward 中,我们调用了之前定义的互相关函数 corr2d,将输入 x 和权重张量 self.weight 作为输入进行卷积运算,并加上偏置项 self.bias。
这个简单的实现只是展示了卷积层的基本实现思路,实际的卷积层还有很多优化和扩展,例如不同的卷积操作、不同的卷积核初始化方法、多通道卷积等。
图像中目标的边缘检测
学到这里可以进行一个卷积层的简单实验:通过像素变化的位置,来检测图像中不同颜色的边缘。
构造图像
X = torch.ones((6, 8))
X[:, 2:6] = 0
结果:
[[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]]
构造卷积核
K = torch.tensor([[1.0, -1.0]])
这个卷积核在进行互关连运算时,如果水平相邻的元素一致,则输出0,否则为其他值(在这里为1)
进行卷积运算
Y = corr2d(X, K)
Y
结果为:
[[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.]]
这样我们就找到了水平边缘,但是如果图像转置一下,得出的结果为全0,说明没有垂直边缘
猜想:
我们在进行了水平边缘检测后,可以对原图像转置,此时得出的结果为垂直边缘监测,二者的叠加基本可以确定图像的边缘
卷积核的获取
如果我们只需寻找黑白边缘,那么以上[1, -1]的边缘检测器足以。然而,当有了更复杂数值的卷积核,或者连续的卷积层时,我们不可能手动设计滤波器。那么我们是否可以学习由X生成Y的卷积核呢?
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率for i in range(10):Y_hat = conv2d(X)l = (Y_hat - Y) ** 2conv2d.zero_grad()l.sum().backward()# 迭代卷积核conv2d.weight.data[:] -= lr * conv2d.weight.gradif (i + 1) % 2 == 0:print(f'epoch {i+1}, loss {l.sum():.3f}')
这里的X,Y都已知
以上代码实现了一个简单的二维卷积神经网络,其具体实现过程如下:
首先定义了一个 nn.Conv2d 的卷积层,它有 1 个输入通道,1 个输出通道,卷积核大小为 (1, 2),且不使用偏置项。
定义输入数据 X 和标签 Y,并且对数据进行了 reshape,使其变为四维格式,即 (批量大小, 通道数, 图像高度, 图像宽度),在这里批量大小和通道数都为 1。
设定学习率为 3e-2。
进行训练,共迭代 10 次。每次迭代,首先通过 conv2d(X) 得到网络的输出 Y_hat,接着计算网络的损失,这里采用均方误差 (MSE) 作为损失函数。然后使用 conv2d.zero_grad() 将卷积核的梯度清零,再计算网络参数(即卷积核)的梯度,并执行一次梯度下降更新卷积核。最后每迭代 2 次,输出一次损失值。
训练之后我们观察得到的权重
conv2d.weight.data.reshape((1, 2))
结果为:

接近我们刚才设置的卷积核。
特征映射和感受野
特征映射(Feature Map)是指卷积神经网络在每一层卷积计算时,由卷积核对输入数据做卷积得到的输出结果。具体来说,卷积操作通过将卷积核在输入数据上滑动,每次计算卷积核与输入数据对应位置的内积,然后将结果填充到输出特征映射的对应位置,最终形成了输出特征映射。
在卷积神经网络中,每一层都会通过多个卷积核生成多个特征映射,每个特征映射对应着输入数据中不同的特征。例如,在图像识别任务中,一层特征映射可能对应着图像的边缘特征,而另一层特征映射则对应着纹理特征。
感受野(receptive field)是指卷积神经网络中,输出特征图上的每一个像素点在输入图像上映射的区域大小。具体来说,对于输出特征图上的一个像素点,它对应输入图像上的一个区域,这个区域就是它的感受野。
在卷积神经网络中,每层特征图的感受野大小会随着网络的层数不断增加而增加。对于一个卷积层,它的感受野大小取决于它的卷积核大小、步幅以及填充大小。具体来说,假设输入特征图的大小为 Hin×WinH_{in}\times W_{in}Hin×Win,输出特征图的大小为 Hout×WoutH_{out}\times W_{out}Hout×Wout,卷积核大小为 k×kk\times kk×k,步幅为 sss,填充大小为 ppp,那么输出特征图上的一个像素点在输入特征图上的感受野大小就是 (k−1)×d+p(k-1)\times d+p(k−1)×d+p,其中 d=⌊(Hin−1)/s⌋+1d=\lfloor (H_{in}-1)/s\rfloor +1d=⌊(Hin−1)/s⌋+1 是输入特征图在这个维度上的大小。对于具有多个通道的输入和输出特征图,它们的感受野大小是在每个通道上独立计算的。
填充和步幅
假设以下情景: 有时,在应用了连续的卷积之后,我们最终得到的输出远小于输入大小。这是由于卷积核的宽度和高度通常大于所导致的。比如,一个240 ∗*∗ 240像素的图像,经过10层的5 ∗*∗ 5卷积后,将减少到像素。如此一来,原始图像的边界丢失了许多有用信息。而填充是解决此问题最有效的方法; 有时,我们可能希望大幅降低图像的宽度和高度。例如,如果我们发现原始的输入分辨率十分冗余。步幅则可以在这类情况下提供帮助。
填充
如上所述,在应用多层卷积时,我们常常丢失边缘像素。 由于我们通常使用小卷积核,因此对于任何单个卷积,我们可能只会丢失几个像素。 但随着我们应用许多连续卷积层,累积丢失的像素数就多了。 解决这个问题的简单方法即为填充(padding):在输入图像的边界填充元素(通常填充元素是0)。在下图中,我们将 3 ∗*∗ 3 输入填充到 5 ∗*∗ 5,输出也增加到4 ∗*∗ 4
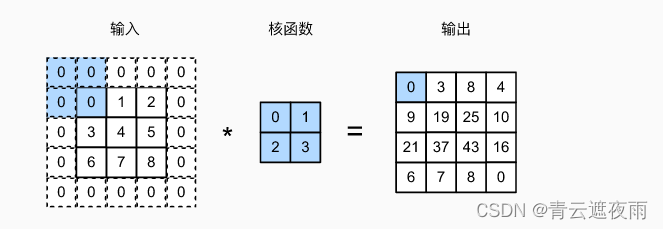
卷积神经网络中卷积核的高度和宽度通常为奇数,例如1、3、5或7。 选择奇数的好处是,保持空间维度的同时,我们可以在顶部和底部填充相同数量的行,在左侧和右侧填充相同数量的列。
此外,使用奇数的核大小和填充大小也提供了书写上的便利。对于任何二维张量X,当满足: 1. 卷积核的大小是奇数; 2. 所有边的填充行数和列数相同; 3. 输出与输入具有相同高度和宽度 则可以得出:输出Y[i, j]是通过以输入X[i, j]为中心,与卷积核进行互相关计算得到的。
比如,在下面的例子中,我们创建一个高度和宽度为3的二维卷积层,并在所有侧边填充1个像素。给定高度和宽度为8的输入,则输出的高度和宽度也是8。
import torch
from torch import nn
# 为了方便起见,我们定义了一个计算卷积层的函数。
# 此函数初始化卷积层权重,并对输入和输出提高和缩减相应的维数
def comp_conv2d(conv2d, X):# 这里的(1,1)表示批量大小和通道数都是1X = X.reshape((1, 1) + X.shape)Y = conv2d(X)# 省略前两个维度:批量大小和通道return Y.reshape(Y.shape[2:])# 请注意,这里每边都填充了1行或1列,因此总共添加了2行或2列
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
X = torch.rand(size=(8, 8))
comp_conv2d(conv2d, X).shape
当卷积核的高度和宽度不同时,我们可以填充不同的高度和宽度,使输出和输入具有相同的高度和宽度。在如下示例中,我们使用高度为5,宽度为3的卷积核,高度和宽度两边的填充分别为2和1。
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
comp_conv2d(conv2d, X).shape
步幅
在计算互相关时,卷积窗口从输入张量的左上角开始,向下、向右滑动。 在前面的例子中,我们默认每次滑动一个元素。 但是,有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素。
在卷积神经网络中,步幅(stride)是指卷积核在对输入进行卷积操作时每次滑动的距离,也就是卷积核每次移动的像素数。与填充(padding)一样,步幅是卷积操作的一项超参数,通常由设计者根据网络的结构和输入数据的特点来设置。当步幅为1时,卷积核每次只移动一个像素,此时输出特征图的大小和输入特征图的大小相同。当步幅大于1时,输出特征图的大小会减小,卷积操作的感受野也会变大,即每个输出像素所对应的输入像素的范围会变大。较大的步幅可以减小计算量和内存占用,但可能会导致信息丢失。
下面,我们将高度和宽度的步幅设置为2,从而将输入的高度和宽度减半。
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
comp_conv2d(conv2d, X).shape
多输入多输出通道
多输入通道
在卷积神经网络中,输入通常不是单个二维矩阵,而是由多个二维矩阵组成的三维数组(例如,RGB图像就是由三个二维矩阵组成的三维数组)。同样的,卷积核也可以具有多个输入通道。在这种情况下,我们需要对每个输入通道分别计算互相关,然后将它们相加得到输出通道。这是因为不同的输入通道在不同的特征上可能有不同的响应,因此我们需要分别对它们进行卷积操作,并将它们的输出相加,以得到最终的输出通道。
在数学上,假设输入具有cic_ici个通道,卷积核具有coc_oco个输出通道,卷积核的高度为khk_hkh,宽度为kwk_wkw,输入的高度和宽度分别为XhX_hXh和XwX_wXw,输出的高度和宽度分别为YhY_hYh和YwY_wYw。那么,我们可以将卷积操作写成以下形式:
Yo,x,y=∑i=1ci∑p=1kh∑q=1kwWo,i,p,qXi,x+p−1,y+q−1+boY_{o,x,y} = \sum_{i=1}^{c_i}\sum_{p=1}^{k_h}\sum_{q=1}^{k_w}W_{o,i,p,q}X_{i,x+p-1,y+q-1}+b_oYo,x,y=i=1∑cip=1∑khq=1∑kwWo,i,p,qXi,x+p−1,y+q−1+bo
其中,Wo,i,p,qW_{o,i,p,q}Wo,i,p,q表示卷积核在输出通道ooo和输入通道iii之间的参数,bob_obo是偏置参数,Xi,x+p−1,y+q−1X_{i,x+p-1,y+q-1}Xi,x+p−1,y+q−1表示输入中通道iii和位置(x+p−1,y+q−1)(x+p-1,y+q-1)(x+p−1,y+q−1)处的像素值,Yo,x,yY_{o,x,y}Yo,x,y表示输出中通道ooo和位置(x,y)(x,y)(x,y)处的像素值。注意,这里我们假设输入和卷积核的高度和宽度相同,因此我们可以将它们的索引分别合并为x+p−1x+p-1x+p−1和y+q−1y+q-1y+q−1。
需要注意的是,如果输入数据有cic_ici个通道,那么每个卷积核就需要有cic_ici个相应的二维权重矩阵。这些矩阵的形状为kh×kwk_h\times k_wkh×kw。我们将它们合并成一个四维张量,形状为co×ci×kh×kwc_o\times c_i\times k_h\times k_wco×ci×kh×kw。
示例:
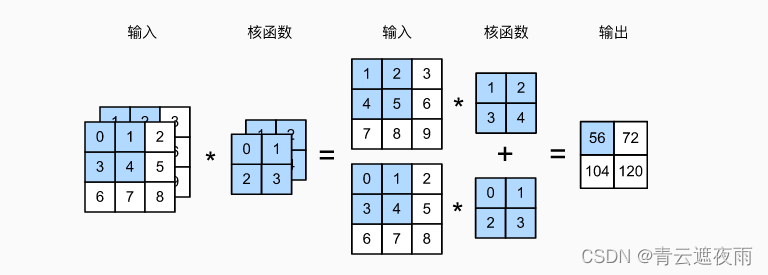
代码实现
import torch
from d2l import torch as d2ldef corr2d_multi_in(X, K):# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])corr2d_multi_in(X, K)
结果为tensor([[ 56., 72.],[104., 120.]])
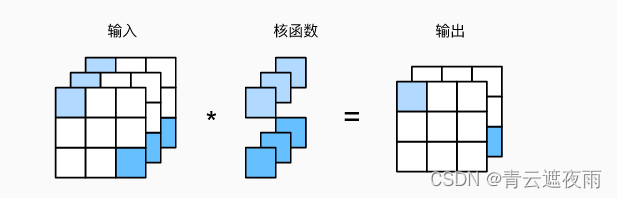
多通道输出
多输出通道是卷积神经网络中的一种常见设计。在单通道卷积中,我们使用一个固定的卷积核对输入进行卷积运算,得到一个输出通道的结果。而在多输出通道中,我们使用多个卷积核对输入进行卷积运算,每个卷积核对应一个输出通道,最终得到多个通道的结果。这些输出通道之间可以看作是不同的特征提取器,每个特征提取器可以识别输入中不同的特征,进一步增加了模型的表达能力。在卷积神经网络中,多输出通道通常在卷积层后接上池化层或下一层的卷积层,以进一步提取高级特征。
def corr2d_multi_in_out(X, K):# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。# 最后将所有结果都叠加在一起return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
举个例子:
假设我们有一个3x3的输入图像,其中包含2个通道(即深度为2)。我们想要使用一个形状为(2,2,3,3)的卷积核在这个图像上执行卷积操作,其中输出通道数为2。这意味着我们将使用2个形状为(2,3,3)的卷积核,分别将每个通道的输入转换为2个输出通道。以下是代码示例:
import torch
import torch.nn as nn# 输入图像大小为 3x3,深度为 2
input_data = torch.randn(1, 2, 3, 3)# 定义一个深度为 2,输出通道为 2,卷积核大小为 3x3 的卷积层
conv = nn.Conv2d(in_channels=2, out_channels=2, kernel_size=3)# 打印卷积核的权重矩阵
print(conv.weight)# 对输入数据进行卷积操作
output_data = conv(input_data)# 输出数据大小为 1x2x1x1
print(output_data.size())在这个例子中,我们定义了一个深度为2,输出通道数为2,卷积核大小为3x3的卷积层。输入数据包含一个批量大小为1,深度为2,大小为3x3的图像。输出数据的大小为1x2x1x1,表示有一个批量,深度为2,大小为1x1的输出图像。卷积核权重矩阵的大小为2x2x3x3,其中2x2表示输出通道数和输入通道数,3x3表示卷积核的大小。
pytorch实现:
import torch
from torch import nn# 输入通道数=3, 输出通道数=2, 卷积核大小=3x3
conv2d = nn.Conv2d(3, 2, kernel_size=(3, 3), bias=False)
X = torch.rand(1, 3, 5, 5)
Y = conv2d(X)
print(Y.shape)1 ×\times× 1 卷积层
1 ×\times× 1 卷积层,看起来并没有什么意义, 毕竟,卷积的本质是有效提取相邻像素间的相关特征,而1 ×\times× 1卷积显然没有此作用。尽管如此,1 ×\times× 1 卷积层仍然十分流行,经常包含在复杂深层网络的设计中。下面,让我们详细地解读一下它的实际作用。
在深度学习中,1 x 1 卷积层经常被用来控制网络的通道数,即通过增加或者减少通道数来影响网络的复杂度。
在卷积操作中,输入数据和卷积核都是多维数组。对于 1×11 \times 11×1 的卷积操作,相当于在每个通道上对每个像素的数值进行加权求和,得到一个标量输出。因此,1×11 \times 11×1 卷积层本质上是一个全连接层,但是它又具备了卷积层的一些特性,例如平移不变性等。
一个常见的应用场景是使用 1×11 \times 11×1 卷积层来增加或者减少卷积层的通道数。例如,我们可以使用 1×11 \times 11×1 卷积层来代替全连接层,从而在卷积神经网络中加入全局平均池化(Global Average Pooling)层,或者将高维特征映射投影到低维空间中,以达到降低计算复杂度的目的。
汇聚层/池化层
通常当我们处理图像时,我们希望逐渐降低隐藏表示的空间分辨率、聚集信息,这样随着我们在神经网络中层叠的上升,每个神经元对其敏感的感受野(输入)就越大。
而我们的机器学习任务通常会跟全局图像的问题有关(例如,“图像是否包含一只猫呢?”),所以我们最后一层的神经元应该对整个输入的全局敏感。通过逐渐聚合信息,生成越来越粗糙的映射,最终实现学习全局表示的目标,同时将卷积图层的所有优势保留在中间层。
最大汇聚层和平均汇聚层
与卷积层类似,汇聚层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口(有时称为汇聚窗口)遍历的每个位置计算一个输出。 然而,不同于卷积层中的输入与卷积核之间的互相关计算,汇聚层不包含参数。 相反,池运算是确定性的,我们通常计算汇聚窗口中所有元素的最大值或平均值。这些操作分别称为最大汇聚层(maximum pooling)和平均汇聚层(average pooling)。
在这两种情况下,与互相关运算符一样,汇聚窗口从输入张量的左上角开始,从左往右、从上往下的在输入张量内滑动。在汇聚窗口到达的每个位置,它计算该窗口中输入子张量的最大值或平均值。计算最大值或平均值是取决于使用了最大汇聚层还是平均汇聚层。

代码实现:
import torch
from torch import nn
from d2l import torch as d2ldef pool2d(X, pool_size, mode='max'):p_h, p_w = pool_sizeY = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))for i in range(Y.shape[0]):for j in range(Y.shape[1]):if mode == 'max':Y[i, j] = X[i: i + p_h, j: j + p_w].max()elif mode == 'avg':Y[i, j] = X[i: i + p_h, j: j + p_w].mean()return Y
这段代码定义了一个名为pool2d的函数,用于实现二维池化操作。其中,输入X是一个二维张量,pool_size是一个元组,表示池化窗口的大小。函数通过遍历池化窗口内的元素来实现池化操作,并返回池化后的结果。
具体地,函数首先获取池化窗口的高度和宽度,然后根据池化窗口的大小和输入张量的形状计算输出张量的形状。在遍历输入张量时,函数根据mode参数指定的池化模式,分别计算池化窗口内的最大值或平均值,并将其赋值给输出张量的相应位置。最后,函数返回输出张量。
pytorch中的使用
这是一个输入图像
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4))
默认情况下,深度学习框架中的步幅与汇聚窗口的大小相同。 因此,如果我们使用形状为(3, 3)的汇聚窗口,那么默认情况下,我们得到的步幅形状为(3, 3)。
pool2d = nn.MaxPool2d(3)
pool2d(X)
结果为tensor([[[[10.]]]])
填充和步幅可以手动设定。
下面为填充1,步幅为2的池化层。
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
结果为:
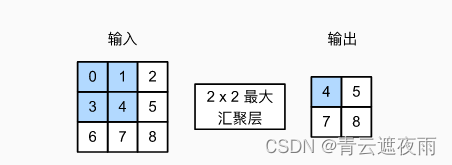
tensor([[[[ 5., 7.],[13., 15.]]]])
当然,我们可以设定一个任意大小的矩形汇聚窗口,并分别设定填充和步幅的高度和宽度。
pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1))
pool2d(X)
其中步幅为(2,3)表示在水平方向上移动两个位置,在垂直方向上移动三个位置。
多个通道
在处理多通道输入数据时,汇聚层在每个输入通道上单独运算,而不是像卷积层一样在通道上对输入进行汇总。 这意味着汇聚层的输出通道数与输入通道数相同。 下面,我们将在通道维度上连结张量X和X + 1,以构建具有2个通道的输入。
X = torch.cat((X, X + 1), 1)

如下所示,汇聚后输出通道的数量仍然是2。
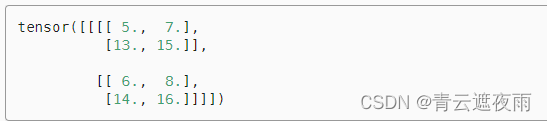
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
卷积神经网络(LeNet)
定义
LeNet是深度学习领域的一个经典卷积神经网络模型,由Yann LeCun等人于1998年提出,被广泛应用于手写数字识别和其他图像识别任务。LeNet的网络结构相对简单,包含两个卷积层和三个全连接层,是卷积神经网络的基础。LeNet对于现代的图像识别任务来说可能过于简单,但其对于深度学习的发展有着重要的贡献,是深度学习领域不可或缺的一部分。
总体来看,LeNet(LeNet-5)由两个部分组成:
卷积编码器:由两个卷积层组成;
全连接层密集块:由三个全连接层组成。
输入层:接收输入的图像数据,一般为灰度图或者RGB彩色图像。
第一个卷积层:对输入进行卷积操作,使用的卷积核的大小为5x5,输出通道数为6,不使用填充,步幅为1。
第一个池化层:对第一个卷积层的输出进行下采样,使用的窗口大小为2x2,步幅为2,池化方式为平均池化或最大池化。
第二个卷积层:对第一个池化层的输出进行卷积操作,使用的卷积核的大小为5x5,输出通道数为16,不使用填充,步幅为1。
第二个池化层:对第二个卷积层的输出进行下采样,使用的窗口大小为2x2,步幅为2,池化方式为平均池化或最大池化。
全连接层1:将第二个池化层的输出展开成向量,并经过一个全连接层,输出大小为120。
全连接层2:对第一层全连接层的输出进行处理,输出大小为84。
输出层:对第二层全连接层的输出进行处理,输出大小为分类任务的类别数目。
手写数字识别的架构如图所示。
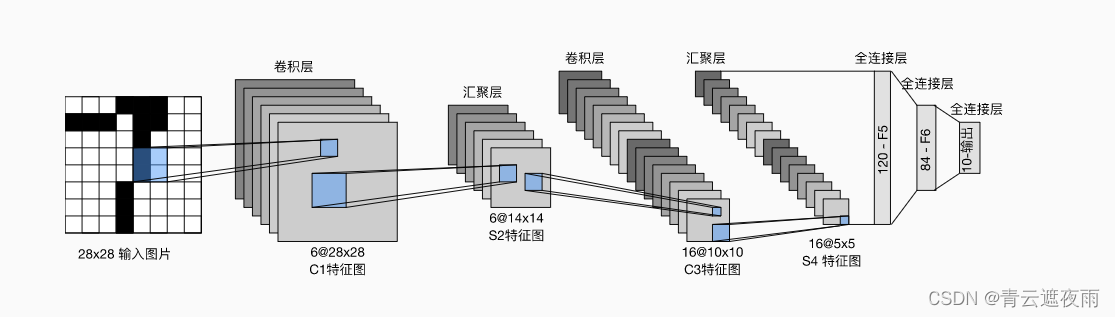
在此图示中,输入图片的尺寸为32*32,图示有误
-
C1层(卷积层):6@28×28
该层使用了6个卷积核,每个卷积核的大小为5×5,这样就得到了6个feature map(特征图)。
每个卷积核(5×5)与原始的输入图像(32×32)进行卷积,这样得到的feature map(特征图)大小为(32-5+1)×(32-5+1)= 28×28 -
S2层(下采样层,也称池化层):6@14×14
这一层主要是做池化或者特征映射(特征降维),池化单元为2×2,因此,6个特征图的大小经池化后即变为14×14。回顾本文刚开始讲到的池化操作,池化单元之间没有重叠,在池化区域内进行聚合统计后得到新的特征值,因此经2×2池化后,每两行两列重新算出一个特征值出来,相当于图像大小减半,因此卷积后的28×28图像经2×2池化后就变为14×14。 -
C3层(卷积层):16@10×10
C3层有16个卷积核,卷积模板大小为5×5。每个卷积核都与S2的6@14*14进行互关系运算,得到16个通道
与C1层的分析类似,C3层的特征图大小为(14-5+1)×(14-5+1)= 10×10 -
S4(下采样层,也称池化层):16@5×5
与S2的分析类似,池化单元大小为2×2,因此,该层与C3一样共有16个特征图,每个特征图的大小为5×5。 -
C5层(卷积层/全连接层):120
该层有120个卷积核,每个卷积核的大小仍为5×5,因此有120个特征图。由于S4层的大小为5×5,而该层的卷积核大小也是5×5,因此特征图大小为(5-5+1)×(5-5+1)= 1×1。这样该层就刚好变成了全连接,这只是巧合,如果原始输入的图像比较大,则该层就不是全连接了。 -
F6层(全连接层):84
F6层有84个单元,之所以选这个数字的原因是来自于输出层的设计,对应于一个7×12的比特图,如下图所示:

-
OUTPUT层(输出层):10
Output层也是全连接层,共有10个节点,分别代表数字0到9。如果第i个节点的值为0,则表示网络识别的结果是数字i。
实现
模型
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10))
或者是
import torch.nn as nn
import torch.nn.functional as Fclass LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.conv1 = nn.Conv2d(3, 16, 5) # in_channels=3 out_channels=16 kernel=5self.pool1 = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(16, 32, 5)self.pool2 = nn.MaxPool2d(2, 2)self.fc1 = nn.Linear(32*5*5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)# 调用上面定义的函数def forward(self, x):x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)x = self.pool1(x) # output(16, 14, 14)x = F.relu(self.conv2(x)) # output(32, 10, 10)x = self.pool2(x) # output(32, 5, 5)x = x.view(-1, 32*5*5) # output(32*5*5)x = F.relu(self.fc1(x)) # output(120)x = F.relu(self.fc2(x)) # output(84)x = self.fc3(x) # output(10)return x训练
import torch
import torchvision
import torch.nn as nnfrom model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoaderdef main():transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# 50000张训练图片# 第一次使用时要将download设置为True才会自动去下载数据集train_set = torchvision.datasets.CIFAR10(root='./data', train=True,download=False, transform=transform)train_loader = DataLoader(train_set, batch_size=36,shuffle=True, num_workers=0)# 10000张验证图片# 第一次使用时要将download设置为True才会自动去下载数据集val_set = torchvision.datasets.CIFAR10(root='./data', train=False,download=False, transform=transform)val_loader = DataLoader(val_set, batch_size=5000,shuffle=False, num_workers=0)val_data_iter = iter(val_loader)val_image, val_label = val_data_iter.next()# classes = ('plane', 'car', 'bird', 'cat',# 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 定义模型和损失函数net = LeNet()loss_function = nn.CrossEntropyLoss()# 定义优化器optimizer = optim.Adam(net.parameters(),lr=0.001)# 对训练集迭代5次epochs = 5for epoch in range(epochs):running_loss = 0for step,data in enumerate(train_loader,start=0): # step从start开始inputs,labels = data# 梯度清零optimizer.zero_grad()outputs = net(inputs)# 计算损失函数loss = loss_function(outputs,labels)# 反向传播并更新参数loss.backward()optimizer.step()running_loss += loss.item()if step%500 == 499:with torch.no_grad():outputs = net(val_image)predict_y = torch.max(outputs,dim=1)[1]accuracy = (predict_y==val_label).sum().item() / val_label.size(0)print('[%d %3d] train_loss: %.3f test_accuracy: %.3f' %(epoch+1,step+1,running_loss/500,accuracy))running_loss = 0print('Finished Training')save_path = './Lenet.pth'torch.save(net.state_dict(),save_path)
if __name__ == '__main__':main()
这段代码是一个基于LeNet网络结构进行CIFAR10分类的训练代码,主要步骤如下:
导入必要的Python包,包括PyTorch中的torch、torchvision、torch.nn等模块,以及用于数据加载的DataLoader。
定义数据预处理,包括将图像转换为Tensor格式、标准化处理等操作。
加载训练集和验证集,使用DataLoader将数据分批次读取。
定义LeNet网络结构和损失函数,此处使用交叉熵损失函数。
定义Adam优化器。
进行训练,共进行5个epoch,每个epoch对训练集进行一次完整的遍历,每次遍历对数据分批次读取并进行网络的前向计算、反向传播、参数更新等操作。
每500个batch输出一次训练损失和测试精度。
保存训练好的模型参数。
测试
import torch
import torchvision.transforms as transforms
from PIL import Imagefrom model import LeNetdef main():transform = transforms.Compose([transforms.Resize((32, 32)), # 对输入的图片尺寸进行调整transforms.ToTensor(), # Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor. (H x W x C)->(C x H x W)transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')net = LeNet()net.load_state_dict(torch.load('Lenet.pth')) # 加载模型im = Image.open('data/plane.jpg')im = transform(im) # [C, H, W]# 增加一个维度,batchim = torch.unsqueeze(im, dim=0) # [N, C, H, W] 增加一个batch维度with torch.no_grad():outputs = net(im)predict = torch.max(outputs, dim=1)[1].numpy()print(classes[int(predict)])if __name__ == '__main__':main()
相关文章:
卷积神经网络的原理及实现
专栏:神经网络复现目录 卷积神经网络 本章介绍的卷积神经网络(convolutional neural network,CNN)是一类强大的、为处理图像数据而设计的神经网络。 基于卷积神经网络架构的模型在计算机视觉领域中已经占主导地位,当今…...

【C++知识点】重载
✍个人博客:https://blog.csdn.net/Newin2020?spm1011.2415.3001.5343 📚专栏地址:C/C知识点 📣专栏定位:整理一下 C 相关的知识点,供大家学习参考~ ❤️如果有收获的话,欢迎点赞👍…...

apscheduler三种定时触发方式
#第一种# date: 特定的时间点触发# 2019-01-01 00:00:00 准时执行# import time # from apscheduler.schedulers.blocking import BlockingScheduler # # def my_job(): # print(time.strftime(%Y-%m-%d %H:%M:%S, time.localtime(time.time()))) # sched BlockingSchedu…...
802.11 service服务类型
802.11 serviceservice定义service分类按照模块分为两类按照功能分为六类数据传输相关服务分布式服务DS(Distribution Service)整合服务IS(Integration Service)关联(association)重关联(reasso…...
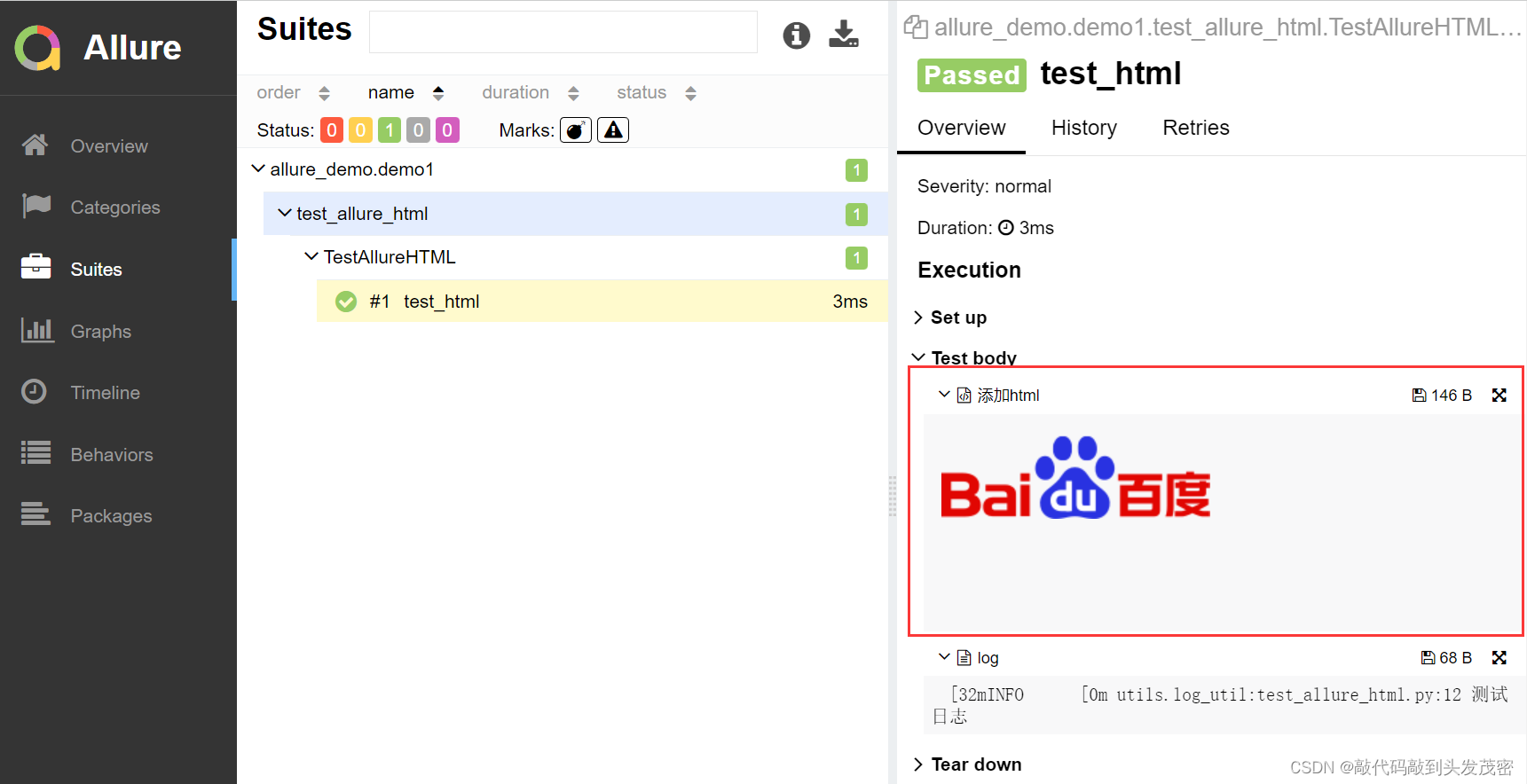
pytest测试框架——allure报告
文章目录一、allure的介绍二、allure的运行方式三、allure报告的生成方式一、在线报告、会直接打开默认浏览器展示当前报告方式二、静态资源文件报告(带index.html、css、js等文件),需要将报告布置到web服务器上。四、allure中装饰器1、实现给…...
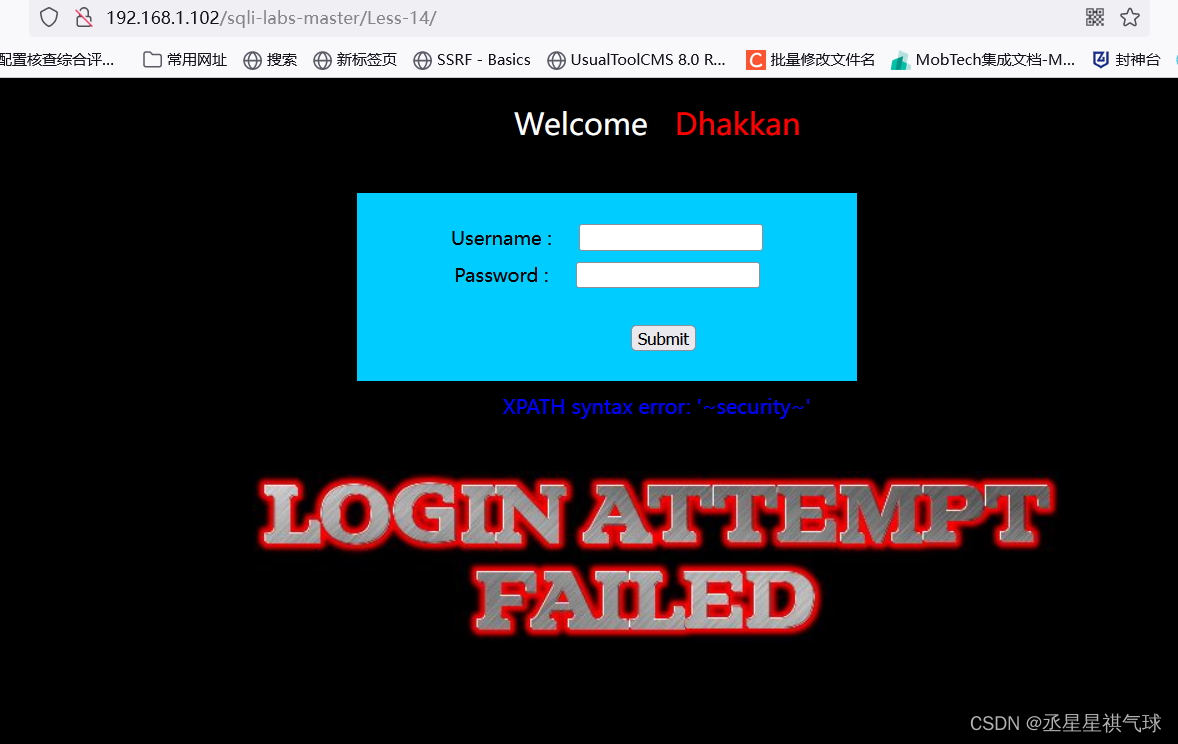
SQLI-Labs(3)8-14关【布尔盲注和时间盲注】
目录 第八关 第九关: 第十关 第十一关 第十二关 第十三关 第十四关 第八关 我们用测试语句来测试是否为注入点 从上图中得知存在注入点,那么接下来就是爆列 一共有三列,接下来用union select 和报错注入都试一下发现没有回显点&…...

ESP32学习笔记03-日志打印
ESP32日志 日志分为5个等级 ESP_LOGE - error (lowest)ESP_LOGW - warningESP_LOGI - infoESP_LOGD - debugESP_LOGV - verbose (highest)API 0.头文件 #include "esp_log.h"1.给一个日志标签设置等级...

mongoTemplate非string类型模糊查询
需求 为方便使用人员对任务Task的搜索,需要根据number实现模糊搜索。 背景 之前设计的number是long类型,但是mongodb只支持string类型的正则匹配。 方案 修改number为string类型;新增一个冗余字段,用于模糊查询;在…...

Redis是单线程还是多线程?Redis的10种数据类型,有哪些应用场景?
目录专栏导读一、同样是缓存,用map不行吗?二、Redis为什么是单线程的?三、Redis真的是单线程的吗?四、Redis优缺点1、优点2、缺点五、Redis常见业务场景六、Redis常见数据类型1、String2、List3、Hash4、Set5、Zset6、BitMap7、Bi…...
到底什么才是幻读?
💗推荐阅读文章💗 🌸JavaSE系列🌸👉1️⃣《JavaSE系列教程》🌺MySQL系列🌺👉2️⃣《MySQL系列教程》🍀JavaWeb系列🍀👉3️⃣《JavaWeb系列教程》…...
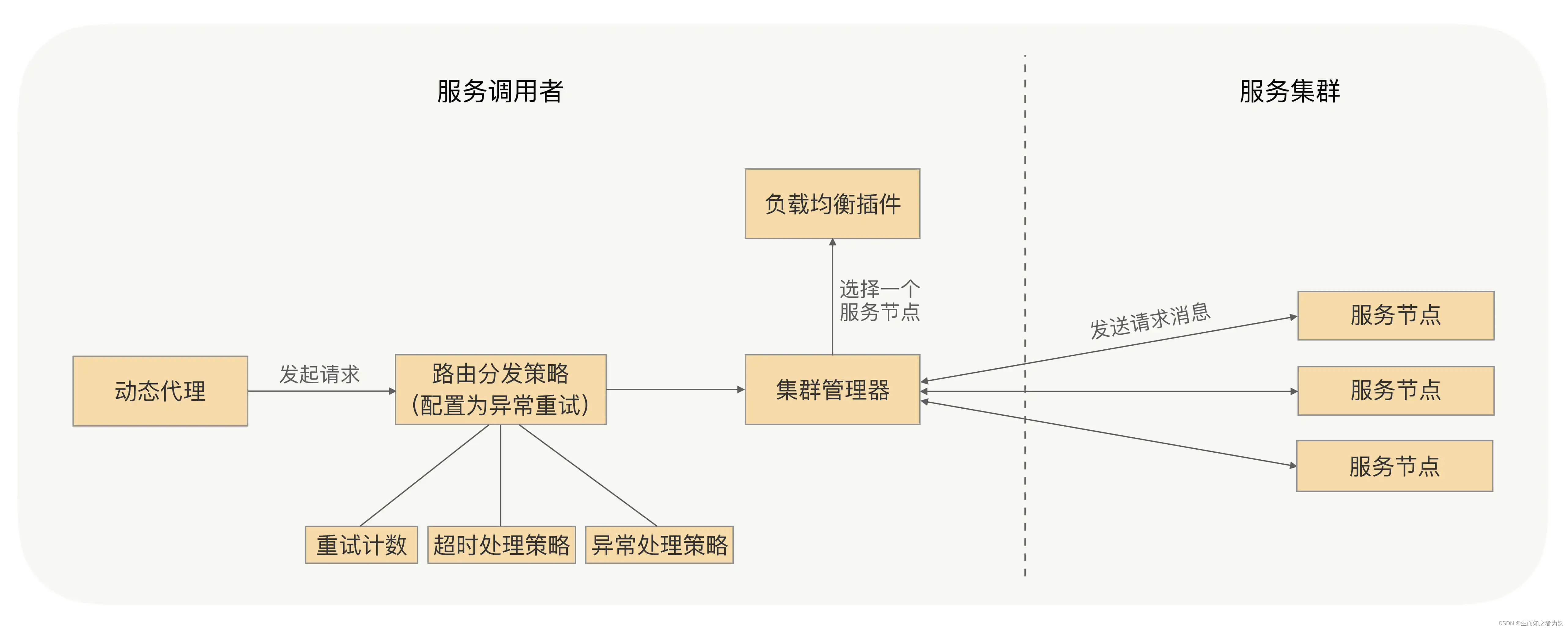
RPC重试机制和控制方案
重试机制 因为网络抖动等原因导致 RPC 调用失败,这时候使用重试机制可以提高请求的最终成功率,减少故障影响,让系统运行更稳定。 重试简易实现方案 在重试的过程中,为了能够在约定的时间内进行安全可靠地重试,在每次…...

【无标题】动态给结构体赋值
#include <stdio.h> #include <stdlib.h> #include <string.h> typedef struct { int id; char name[20]; double score; } Student; int main() { Student *p (Student *)malloc(sizeof(Student)); if (p NULL) { printf(“Memory allocation failed.”…...

centos7 soft raid每周自动同步的问题
之前redhat老版本时也遇到过这样的问题https://blog.csdn.net/jolly10/article/details/108768360centos7解决的办法略有不同,记录一下:centos7默认是每周日凌晨1点进行raid检查,有点太频繁了[oracleqht117 data]$ ls /etc/cron*/etc/cron.de…...

嵌入式Linux内核代码风格
这是一个简短的文档,描述了linux内核的首选代码风格。代码风格是因人而异的,而且我 不愿意把我的观点强加给任何人,不过这里所讲述的是我必须要维护的代码所遵守的风格, 并且我也希望绝大多数其他代码也能遵守这个风格。请在写代码…...

Andorid:关于Binder几个面试问题
1.简单介绍下binderbinder是一种进程间通讯的机制进程间通讯需要了解用户空间和内核空间每个进程拥有自己的独立虚拟机,系统为他们分配的地址空间都是互相隔离的。如两个进程需要进行通讯,则需要使用到内核空间做载体,内核空间是所有进程共享…...

【剑指Offer-Java】包含min函数的栈?
题目 定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min 函数在该栈中,调用 min、push 及 pop 的时间复杂度都是 O(1)。 MinStack minStack new MinStack(); minStack.push(-2); minStack.push(0); minStack.push(-3); minStack.min()…...

红队APT——邮件钓鱼攻击SwaksOffice漏洞RLO隐藏压缩释放
目录 (一)采用自己搭建Ewomail配合Swaks 0x01 搭建过程 0x02 配置转发信息 (二)网页钓鱼-克隆修改...

【Java|基础篇】超详细讲解运算符
文章目录1. 什么是运算符2. 算术运算符隐式类型转换强制类型转换字符串的拼接字符相加自增和自减运算符3.赋值运算符4. 关系运算符5. 逻辑运算符短路与(&&)和短路或(||)6.三目运算符7. 位运算符8. 移位运算1. 什么是运算符 运算符用于执行程序代码运算,会针…...
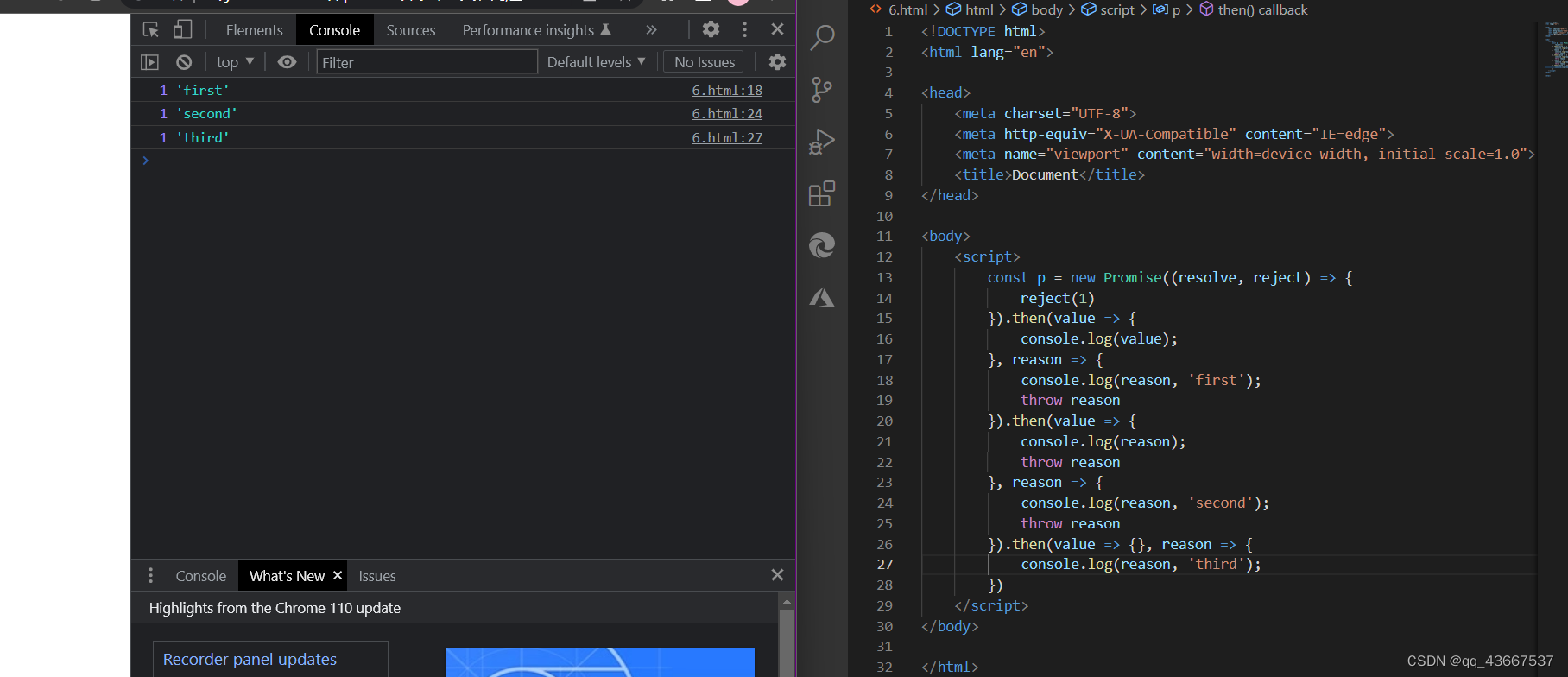
Promise-异步回调
1.理解Promise promise是ES6提出的异步编程的新的解决方案,通过链式调用解决ajax回调地狱 从语法上看,promise是一个构造函数,自己身上有all、reject、resolve方法,原型上有then、catch方法 从功能上看,Promise对象用…...

【设计模式之美 设计原则与思想:设计原则】21 | 理论七:重复的代码就一定违背DRY吗?如何提高代码的复用性?
在上一节课中,我们讲了 KISS 原则和 YAGNI 原则,KISS 原则可以说是人尽皆知。今天,我们再学习一个你肯定听过的原则,那就是 DRY 原则。它的英文描述为:Don’t Repeat Yourself。中文直译为:不要重复自己。将…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...
AxureRP-Pro-Beta-Setup_114413.exe (6.0.0.2887)
Name:3ddown Serial:FiCGEezgdGoYILo8U/2MFyCWj0jZoJc/sziRRj2/ENvtEq7w1RH97k5MWctqVHA 注册用户名:Axure 序列号:8t3Yk/zu4cX601/seX6wBZgYRVj/lkC2PICCdO4sFKCCLx8mcCnccoylVb40lP...