Java分布式全局ID(一)
随着互联网的不断发展,互联网企业的业务在飞速变化,推动着系统架构也在不断地发生变化。
如今微服务技术越来越成熟,很多企业都采用微服务架构来支撑内部及对外的业务,尤其是在高
并发大流量的电商业务场景下,微服务更是企业首选的架构模式。随着业务发展壮大,用户量暴
涨,单节点处理能力就会成为瓶颈,如果并发量居高不下,服务器很容易因负载过高而导致崩溃
宕机。出于高并发,高可用的考虑,项目就应该演变到分布式架构了。然而分布式环境下我们又
会面临更多的挑战需要去应对。比如:1、分布式系统中接口繁多,重试机制必不可少,接口幂等性问题?2、如果下单、付款分布在不同的服务上,如何保证跨服务事务?3、高并发场景下资源共享问题?4、分库分表后,引发了ID重复问题?那么,我们需要如何解决分布式呢?
文章目录
- 🔥分布式全局唯一ID
- 🔥分布式全局唯一ID解决方案
- 🔥什么是雪花算法SonwFlake
- 🔥雪花算法SonwFlake落地实现
- 🔥雪花算法SonwFlake落地实现之Mybatis Plus
🔥分布式全局唯一ID

何为 ID
日常开发中,我们需要对系统中的各种数据使用 ID 唯一表示,比如用户 ID 对应且仅对应一个人,商品 ID 对应且仅对应一件商品,订单 ID 对应且仅对应一个订单。
为什么需要分布式ID
随着系统数据量越来越大,单数据库压力太大无法维持性能,所以可能就需要变成一主多从这样读写分离,随着继续扩大一主多从也无法支撑了。这时就需要分库分表,这样的话就会出现不同库表之间的数据id不能再依赖数据库自增的id,而需要外部一种方式生成全局统一的唯一id。
分布式ID需要满足什么条件
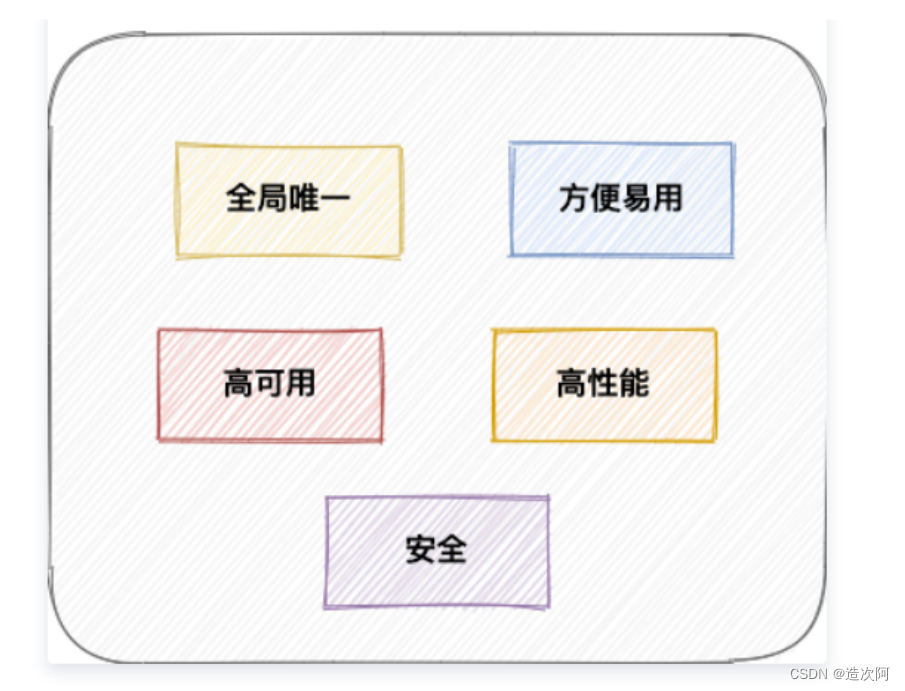
⭐唯一性:全局必须唯一。
⭐高性能:不能在生成id上浪费过多的时间,使其成为功能的性能瓶颈。
⭐高可用:必须保证可用性。
⭐趋势递增:这个不是必须的,但是最好还是满足,因为比如innodb索引就是按照键值排序的,所以有序性可以让维护索引的效率提高。
🔥分布式全局唯一ID解决方案

UUID
Java本身提供了UUID,这是一个唯一的字符串,它可以不依赖其他工具在本地生成。
优点
⭐代码实现简单
⭐本地生成,没有性能问题
⭐全球唯一的,数据迁移容易
缺点
⭐每次生成的ID是无序的,不满足趋势递增
⭐UUID是字符串,而且比较长,占用空间大,查询效率低
⭐ID没有含义,可读性差
依靠数据库自增字段生成
一个数据库压力大就搞多个数据库,之后搞一个Step步长的概念,每个数据库的自增起始值不同,但是他们的增长Step相同。如下图所示。
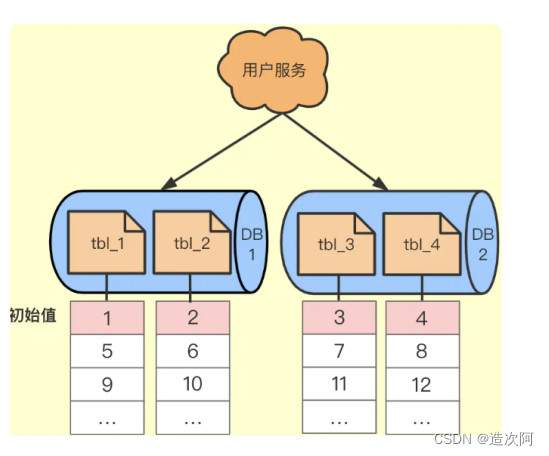
优点
⭐返回的分布式ID是趋势递增的id唯一。解决了单点问题,即使一个宕机其他的还可以提供服务。
缺点
⭐单点压力还是很大,因为DB本身写操作就耗时间。最主要的问题还是扩容困难,比如要加一台DB3是很难加进来的,除非停机,将所有DB的id进行修改,同时修改步长。
号段模式
它没有采用新插入记录返回id的方案,而是一个业务类型就是一行数据,用一行数据来维护这个业务的自增id。服务来修改这行数据的max_id,比如当前max_id值是0,那么来给max_id加上1000,如果返回成功,就代表这个服务获得了1-1000这段分布式id,之后将这段缓存在服务内部,用完之后再来表中取。
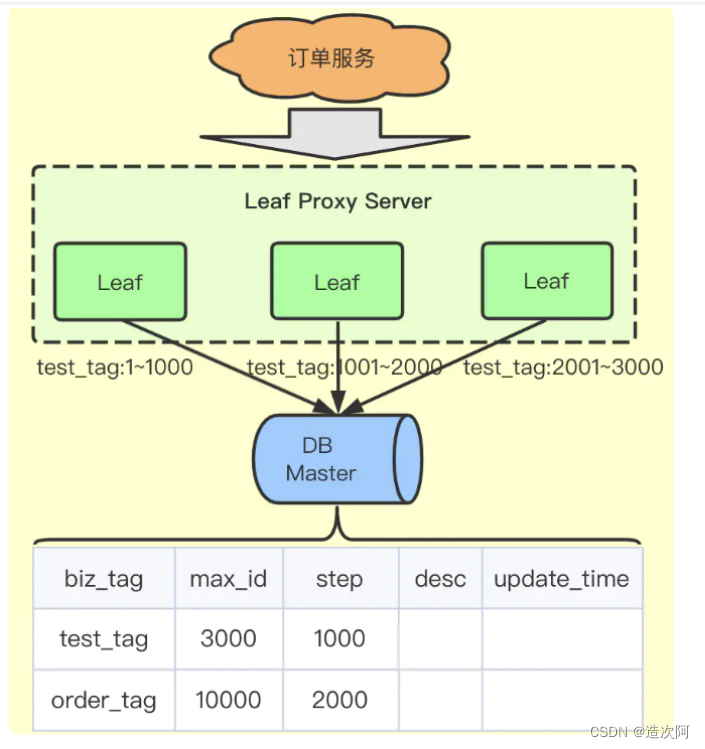
优点
⭐效率很高,db的压力减小,而且一张表可以维护很多业务的分布式id。
缺点
⭐复杂性提高,需要系统为了这个生成方案对号段进行缓存。
Redis自增key方案
通过incr命令让一个key自增,自增后的值作为分布式id。

优点
⭐有序递增,可读性强
⭐性能较高
缺点
⭐占用带宽,依赖Redis
雪花算法(SnowFlake)
SnowFlake生成的是一个Long类型的值,Long类型的数据占用8个字节,也就是64位。SnowFlake将64进行拆分,每个部分具有不同的含义,当然机器码、序列号的位数可以自定义也可以。

优点
⭐本地生成,不依赖中间件。
⭐生成的分布式id足够小,只有8个字节,而且是递增的。
缺点
⭐时钟回拨问题,强烈依赖于服务器的时间,如果时间出现时间回拨就可能出现重复的id。
🔥什么是雪花算法SonwFlake

Snowflake常称为雪花算法,是Twitter开源的分布式ID生成算法,生成后是一个64bit的long型数值,组成部分引入了时间戳,基本保持了自增。
雪花算法作用
⭐生成的所有的id都是随着时间递增
⭐分布式系统内不会产生重复的id
SnowFlake算法优点
⭐高性能高可用:生成时不依赖于数据库,完全在内存中生成
⭐高吞吐:每秒钟能生成数百个的自增ID
⭐ ID自增:存入数据库中,索引效率高
SnowFlake算法的缺点
依赖系统时间,如果系统时间被回调,或者改变,可能会造成ID冲突或者重复
雪花算法组成

注意:
⭕1位,不用,二进制中的最高位是符号位,1表示负数,0表示正数,由于我们生成的雪花算法都是正整数,所以这里是0 。
⭕41位,这里的时间戳是表示的是从起始时间算起,到生成id时间所经历的时间戳,也就是(当前时间戳-起始时间戳(固定)) 这里一共是41位,范围就是(0~ 2^41-1),这么大的毫秒数转化成时间就是大约69年 。
⭕10位,这里的10位代表工作机器id,一共可以部署在(2^10=1024)台机器上面,10位又可以分为前面五位是数据中心id(0~31),后面五位是机器id(0-31) 。
⭕共12位,序列位,一共可用(0 ~ 2^12-1)共4096个数字。
🔥雪花算法SonwFlake落地实现

Hutool简介
Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相关API的学习成本,提高工作效率,使Java拥有函数式语言般的优雅,让Java语言也可以“甜甜的”。
引入相关依赖
hutool工具包已经提供雪花算法ID生成的工具类。
<!--
https://mvnrepository.com/artifact/cn.hutool/hu
tool-all -->
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.13</version>
</dependency>
Snowflake
分布式系统中,有一些需要使用全局唯一ID的场景,有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。Twitter的Snowflake 算法就是这种生成器。
//参数1为机器标识
//参数2为数据标识
Snowflake snowflake = IdUtil.getSnowflake(1,
1);
long id = snowflake.nextId();
//简单使用
long id = IdUtil.getSnowflakeNextId();
String id = snowflake.getSnowflakeNextIdStr();
雪花算法SpringBoot引用
config文件
package com.example.demo.config;
import cn.hutool.core.lang.Snowflake;
import cn.hutool.core.net.NetUtil;
import cn.hutool.core.util.IdUtil;
import lombok.extern.slf4j.Slf4j;
import
org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
@Slf4j
@Component
public class IdGeneratorSnowflake {private long workerId = 0; //第几号机房private long datacenterId = 1; //第几号机器private Snowflake snowflake =
IdUtil.getSnowflake(workerId, datacenterId);@PostConstruct //构造后开始执行,加载初始化工作public void init(){try{//获取本机的ip地址编码workerId =
NetUtil.ipv4ToLong(NetUtil.getLocalhostStr());log.info("当前机器的workerId: " +
workerId);}catch (Exception e){e.printStackTrace();log.warn("当前机器的workerId获取失败 -
---> " + e);workerId =
NetUtil.getLocalhostStr().hashCode();}}/**
分布式全局唯一ID实现_雪花算法SonwFlake落地实现之
Mybatis Plus
初始化工程* 生成id* @return*/public synchronized long snowflakeId(){return snowflake.nextId();}
}
🔥雪花算法SonwFlake落地实现之Mybatis Plus

初始化工程
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-bootstarter</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-bootstarter</artifactId><version>3.4.2</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connectorjava</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-startertest</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintageengine</artifactId></exclusion></exclusions></dependency></dependencies>
编写相关配置
在 application.yml 配置文件中添加 MySQL 数据库的相关配置:
spring.datasource.driver-classname=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://192.168.66.1
00:3306/test?serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=123456
开启MapperScan扫描
在 Spring Boot 启动类中添加 @MapperScan 注解,扫描 Mapper 文件夹:
@SpringBootApplication
@MapperScan("com.itbaizhan.sonwflake.mapper")
public class Application {public static void main(String[] args) {SpringApplication.run(Application.class,
args);}
}
编码
编写实体类 User.java
@Data
public class User {@TableId(type = IdType.ASSIGN_ID)// 雪花算法private Long id;private String name;private Integer age;private String email;
}
编写Mapper
public interface UserMapper extends
BaseMapper<User> {
}
添加测试类
@Testvoid createUser() {User user = new User();user.setName("张三");user.setAge(18);user.setEmail("23472@qq.com");userMapper.insert(user);}
相关文章:
Java分布式全局ID(一)
随着互联网的不断发展,互联网企业的业务在飞速变化,推动着系统架构也在不断地发生变化。 如今微服务技术越来越成熟,很多企业都采用微服务架构来支撑内部及对外的业务,尤其是在高 并发大流量的电商业务场景下,微服务…...
算法分析与设计之并查集详解
算法分析与设计之并查集1.前言2.并查集的基础2.1.关于动态连通性2.2.动态连通性的应用场景:2.3.对问题建模:2.4.建模思路:2.5.API2.7.Quick-Find算法:2.8.Quick-Union算法:3. 并查集的应用1.前言 本文主要介绍解决动态…...

Linux - 内存性能评估
文章目录概述free 命令指定的时间段内不间断地监控内存的使用情况通过watch与free相结合动态监控内存状况vmstat命令监控内存“sar –r”命令组合小结概述 内存的管理和优化是系统性能优化的一个重要部分,内存资源的充足与否直接影响应用系统的使用性能。在进行内存…...

00后初中辍学,转行程序员后,终于找到了女朋友
大家好,这里是程序员晚枫,今天继续分享我们的读者投稿,如需投稿赚稿费的朋友,请在后台私信我:投稿。下面我们进入正文吧~ 我是一位 00 后,从初一辍学,到目前为止已有 8 年的时间了,在…...

“Vue学习注意事项:掌握核心特性,注意性能优化和第三方库的使用“
Vue是一款易学易用的JavaScript框架,它可以帮助开发者构建动态、高性能的用户界面。Vue的核心概念包括数据绑定、指令、计算属性和组件化,学习Vue需要注意以下几个点:1. 理解Vue的基本概念和用法Vue的基本概念包括模板、组件、数据绑定、计算…...
计算机网络协议详解(二)
文章目录🔥HTTP协议介绍🔥HTTP协议特点🔥HTTP协议发展和版本🔥HTTP协议中URI、URL、URN🔥HTTP协议的请求分析🔥HTTP协议的响应分析🔥MIME类型🔥HTTP协议介绍 HTTP协议介绍 什么是超…...
【CSS】CSS 复合选择器 ② ( 子元素选择器 | 交集选择器 )
文章目录一、子元素选择器1、语法说明2、代码分析3、代码示例二、交集选择器1、语法说明2、代码示例一、子元素选择器 1、语法说明 子元素选择器 可以选择 某个基础选择器 选择出的 元素组 的 直接子元素 ( 亲儿子元素 ) 中 使用基础选择器 选择 元素 ; 子元素选择器语法 : 父选…...

Java集合专题
文章目录框架体系CollectionListArrayListLinkedListVectorSetHashSetLinkedHashSetTreeSetMapHashMapHashtableLinkedHashMapTreeMapPropertiesCollections框架体系 1、集合主要分了两组(单列集合,双列集合) 2、Collection接口有两个重要的子…...
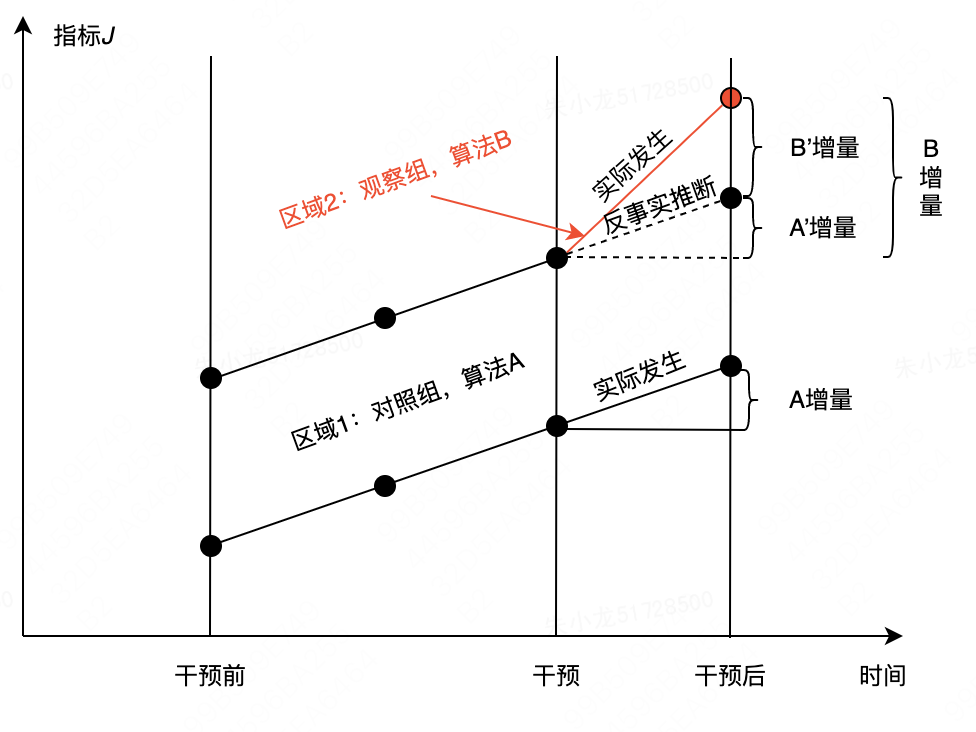
双重差分法(DID):算法策略效果评估的利器
文章目录算法评估DID原理简单实例Python实现算法评估 作为一名算法出身的人,曾长期热衷于算法本身的设计和优化。至于算法的效果评估,通常使用公开数据集做测试,然后对比当前已公开的结果,便可得到结论。 但是在实际落地过程中&…...

【pytorch】使用mixup技术扩充数据集进行训练
目录1.mixup技术简介2.pytorch实现代码,以图片分类为例1.mixup技术简介 mixup是一种数据增强技术,它可以通过将多组不同数据集的样本进行线性组合,生成新的样本,从而扩充数据集。mixup的核心原理是将两个不同的图片按照一定的比例…...

面向对象设计模式:创建型模式之单例模式
1. 单例模式,Singleton Pattern 1.1 Definition 定义 单例模式是确保类有且仅有一个实例的创建型模式,其提供了获取类唯一实例(全局指针)的方法。 单例模式类提供了一种访问其唯一的对象的方式,可以直接访问…...
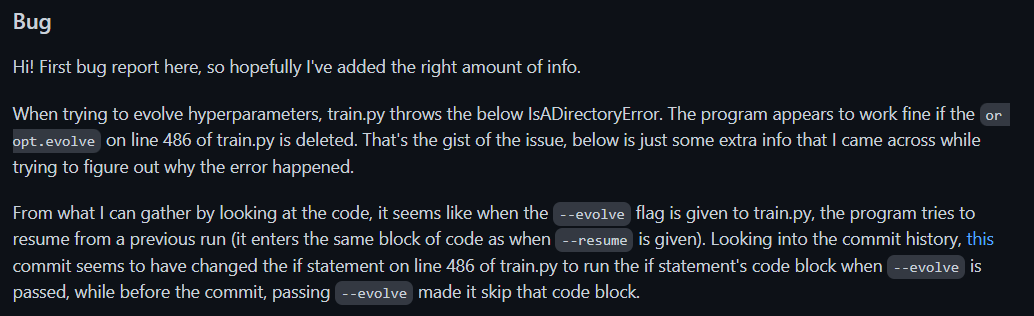
IsADirectoryError: [Errno 21] Is a directory: ‘.‘
项目场景: 基于YOLOv5的室内场景识别 工具:colab 问题描述 Traceback (most recent call last): File “train.py”, line 630, in main(opt) File “train.py”, line 494, in main d torch.load(last, map_location‘cpu’)[‘opt’] File “/usr/…...

判断三角面片与空间中球体是否相交
文章目录一、问题描述二、解题思路 在做项目时遇到了一个数学问题,即,如何判断给定一个三角面片与空间中某个球体有相交部分?这个问题看似简单,实际处理起来需要一些方法和手段。一、问题描述 已知空间中球体的球心位置center&a…...

继承下的缺省参数值和访问说明符
前言 本文将介绍 C 继承体系下,函数缺省参数的绑定和函数访问说明符的绑定。这些奇怪的问题实际上不应在我们的代码中出现,但它们能帮助我们理解 C 的动态绑定和静态绑定,也能帮助我们更好的通过面试。 缺省参数值 先来看一段代码…...
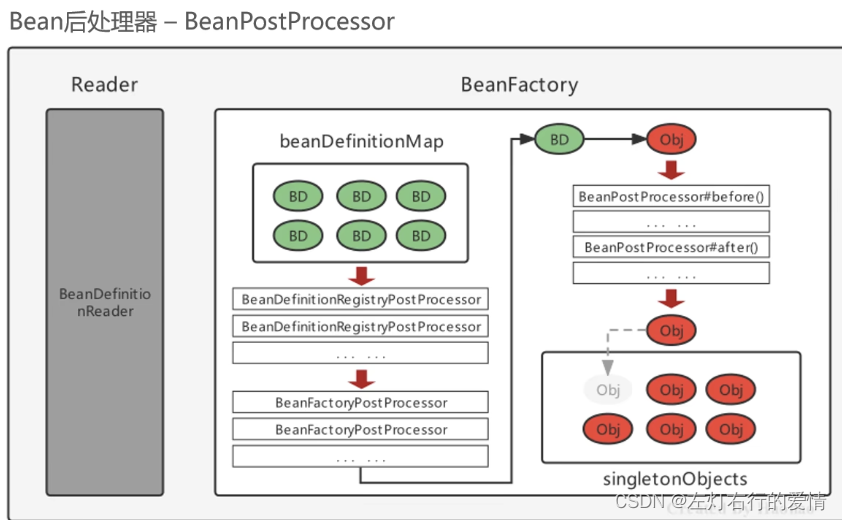
Spring核心模块—— BeanFactoryPostProcessorBeanPostProcessor(后处理器)
后置处理器前言Spring的后处理器BeanFactoryPostProcessor(工厂后处理器)执行节点作用基本信息经典场景子接口——BeanDefinitiRegistryPostProcessor基本介绍用途具体原理例子——注册BeanDefinition使用Spring的BeanFactoryPostProcessor扩展点完成自定…...
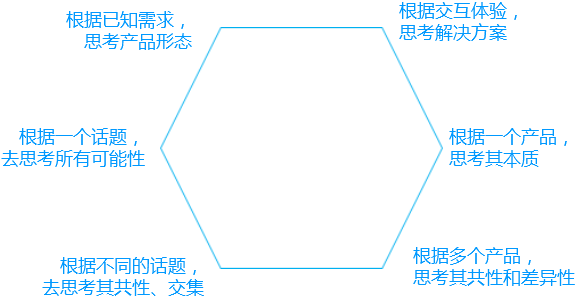
产品新人如何培养产品思维?
什么是产品思维?其实很难定义,不同人有不同的定义。有的人定义为以用户为中心打磨一个完美体验的产品;有的定义为从需求调研到需求上线各个步骤需要思考的点,等等。本文想讨论的产品思维是:怎么去发现问题,…...

「兔了个兔」CSS如此之美,看我如何实现可爱兔兔LOADING页面(万字详解附源码)
💂作者简介: THUNDER王,一名热爱财税和SAP ABAP编程以及热爱分享的博主。目前于江西师范大学会计学专业大二本科在读,同时任汉硕云(广东)科技有限公司ABAP开发顾问。在学习工作中,我通常使用偏后…...
【Java】阻塞队列 BlcokingQueue 原理、与等待唤醒机制condition/await/singal的关系、多线程安全总结
在实习过程中使用阻塞队列对while sleep 轮询机制进行了改造,提升了发送接收的效率,这里做一点点总结。 自从Java 1.5之后,在java.util.concurrent包下提供了若干个阻塞队列,BlcokingQueue继承了Queue接口,是线程安全…...

【水下图像增强】Enhancing Underwater Imagery using Generative Adversarial Networks
原始题目Enhancing Underwater Imagery using Generative Adversarial Networks中文名称使用 GAN 增强水下图像发表时间2018年1月11日平台ICRA 2018来源University of Minnesota, Minneapolis MN文章链接https://arxiv.org/abs/1801.04011开源代码官方:https://gith…...

Maven专题总结—详细版
第一章 为什么使用Maven 获取jar包 使用Maven之前,自行在网络中下载jar包,效率较低。如【谷歌、百度、CSDN…】使用Maven之后,统一在一个地址下载资源jar包【阿里云镜像服务器等…】 添加jar包 使用Maven之前,将jar复制到项目工程…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

解读《网络安全法》最新修订,把握网络安全新趋势
《网络安全法》自2017年施行以来,在维护网络空间安全方面发挥了重要作用。但随着网络环境的日益复杂,网络攻击、数据泄露等事件频发,现行法律已难以完全适应新的风险挑战。 2025年3月28日,国家网信办会同相关部门起草了《网络安全…...

Caliper 配置文件解析:fisco-bcos.json
config.yaml 文件 config.yaml 是 Caliper 的主配置文件,通常包含以下内容: test:name: fisco-bcos-test # 测试名称description: Performance test of FISCO-BCOS # 测试描述workers:type: local # 工作进程类型number: 5 # 工作进程数量monitor:type: - docker- pro…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...