13.西瓜书——半监督学习
1.概述

(1) 纯半监督学习 (Pure Semi-Supervised Learning)
纯半监督学习是一种典型的半监督学习方法,它的主要特点是同时利用有标签数据和无标签数据进行模型训练。目标是通过整合这两种类型的数据来提高模型的泛化性能。在这个过程中,无标签数据被用来揭示数据的底层结构或分布,而有标签数据则用来指导模型进行正确的分类或预测。
想象你在教一个朋友识别不同种类的水果。你给他们看几个苹果、香蕉和橙子,并告诉他们各是什么。这就像标记数据,因为你给了他们带正确答案的示例。
但你还有一个大篮子混合的水果,你没有时间去仔细查看。你的朋友尝试根据他们从你给的几个示例中学到的东西来判断每种水果是什么。这就像未标记数据。你的朋友正在使用他们从几个示例中学到的知识来对所有其他的水果进行猜测。
在纯半监督学习中,计算机使用少量的标记数据来学习一些东西。然后,它试图将所学的知识应用于大量的未标记数据,为那些数据猜测标签。这有点像用有根据的猜测来填补空白。
(2)直推学习 (Transductive Learning)
直推学习与传统的归纳学习(如纯半监督学习)不同,因为它专注于对特定无标签样本的预测,而不是构建一个可以泛化到新数据的模型。在直推学习中,我们通常假设训练时使用的无标签样本就是最终在测试时需要预测的样本。因此,直推学习的目标是在这些特定的无标签样本上获得最佳的预测性能。
在半监督学习的背景下,直推学习可能会利用有标签数据来构建一个初步模型,然后利用该模型对无标签数据进行预测,并根据这些预测来优化模型。但是,与纯半监督学习不同,直推学习并不关注模型在新数据上的泛化能力。
(3)主动学习 (Active Learning)
主动学习在半监督学习中扮演着特殊的角色。在这种方法中,模型不是被动地接受所有可用的有标签和无标签数据,而是主动选择它认为最“有用”或“信息量最大”的样本进行标注。这种方法通常涉及与一个或多个专家(或标注者)的交互,他们会根据模型的请求提供标签。
在半监督学习的设置中,主动学习可以用于逐步增加有标签数据集的大小。通过精心选择哪些无标签样本进行标注,主动学习可以在保持标注成本较低的同时,显著提高模型的性能。
总的来说,纯半监督学习、直推学习和主动学习都是利用有标签和无标签数据来提高模型性能的方法,但它们在如何使用这些数据以及追求的目标上有所不同。纯半监督学习注重模型的泛化能力,直推学习关注特定样本的预测性能,而主动学习则通过主动选择样本进行标注来优化模型。
2.生成式方法
生成式方法的核心点在于它假设所有数据(无论是否有标签)都是由一个潜在的概率模型生成的。这个模型描述了数据的联合概率分布P(x, c),其中x是特征,c是类别标签。生成式方法的目标是学习这个潜在模型的所有参数,包括那些与无标签数据相关的参数。
在生成式方法中,无标签数据被用来揭示数据的底层结构或分布,这有助于模型更好地理解数据的整体特性。通过结合有标签数据和无标签数据,生成式方法能够构建一个更全面的模型,该模型不仅能够对已标记的数据进行分类,还能够对未标记的数据进行预测。
具体来说,生成式方法通常涉及以下步骤:
-
模型假设:首先,需要假设一个生成式模型来描述数据的联合概率分布P(x, c)。这个模型可以是任何适合数据的概率模型,如高斯混合模型(GMM)、朴素贝叶斯等。
-
参数学习:然后,使用有标签数据和无标签数据来学习模型的参数。这通常涉及使用EM算法或其他优化技术来最大化数据的似然性。在EM算法的上下文中,E步用于估计无标签数据的类别概率,而M步用于更新模型参数以最大化似然函数。
-
分类器构建:一旦模型参数被学习,就可以使用这些参数来构建分类器。分类器基于条件概率分布P(c|x)进行预测,该分布可以从学习到的联合概率分布P(x, c)中推导出来。
需要注意的是,生成式方法的性能在很大程度上取决于所选择的模型假设是否与实际数据分布相匹配。如果模型假设不准确,那么利用无标签数据可能会降低模型的泛化性能。因此,在选择生成式方法时,需要仔细考虑数据的特性和领域知识,以确保模型假设的合理性。
3.半监督SVM
半监督支持向量机(Semi-Supervised Support Vector Machine,简称S3VM)是支持向量机在半监督学习上的推广。与传统的监督SVM不同,S3VM通过结合有标签数据和无标签数据来提高分类器的性能。
在不考虑未标记样本时,支持向量机试图找到最大间隔划分超平面。而在考虑未标记样本后,S3VM试图找到能将两类有标记样本分开,且穿过数据低密度区域的划分超平面。其基本假设是“低密度分隔”,这是聚类假设在考虑了线性超平面划分后的推广。
S3VM的基本思想和步骤如下:
- 利用有标签的数据训练传统的监督SVM,得到一个初步的决策边界。
- 利用未标签的数据,尝试优化在第一步得到的分类器。这通常通过在决策边界周围引入一些未标签样本来实现。
- 通过半监督优化的方式,最小化有标签样本的分类误差,并在同时最大化未标签样本对分类边界的贡献。这可以通过各种技术来实现,如转导支持向量机(Transductive Support Vector Machines,TSVM)。
- 重复上述步骤,直到模型收敛或达到预定的迭代次数。
需要注意的是,引入未标签样本可能会增加过拟合的风险,因此在使用S3VM时需要注意模型的泛化能力。此外,S3VM的目标是在减少对标签的依赖性的同时提高分类性能,这使得它在处理部分标记数据时具有优势。
4.图半监督学习
图半监督学习(Graph-Based Semi-Supervised Learning)是半监督学习的一个分支,它利用图结构来表示数据之间的相似性和关系。在这种方法中,数据点被表示为图中的节点,而节点之间的边表示数据点之间的相似性。标签信息可以从已标记的节点传播到未标记的节点,从而利用未标记数据来提高分类器的性能。
图半监督学习通常基于以下假设:相似的数据点应具有相似的标签。为了利用这个假设,图半监督学习算法定义了一个相似度矩阵,用于度量数据点之间的相似性。然后,根据相似度矩阵和已标记数据的标签信息,算法构建一个图模型,并通过优化目标函数来学习未标记数据的标签。
图半监督学习的核心点:
-
图结构表示:图半监督学习将数据表示为图结构,其中节点代表数据点,边代表数据点之间的相似性。这种表示方法能够捕捉数据之间的复杂关系。
-
相似度度量:在图半监督学习中,定义相似度矩阵是关键。这个矩阵度量了数据点之间的相似性,是后续标签传播和模型构建的基础。
-
标签传播:已标记数据的标签信息通过图结构传播到未标记数据。这通常是通过迭代过程实现的,其中标签根据数据点之间的相似性逐渐传播到整个图。
-
利用未标记数据:图半监督学习的目标是通过结合有标签数据和无标签数据来提高分类性能。未标记数据通过图结构中的相似性关系被有效地利用起来。
5.基于分歧的方法
基于分歧的方法(Disagreement-Based Methods)是半监督学习中的一种常用策略,它主要利用多个学习器之间的分歧或差异来优化模型的性能。这种方法的核心思想是,当不同的学习器对同一个未标记样本的预测结果存在分歧时,这个样本很可能位于分类边界附近,因此具有较高的信息量。通过合理地利用这些分歧,我们可以提高模型的泛化能力和鲁棒性。
基于分歧的方法通常涉及以下步骤:
-
学习器的生成:首先,需要生成多个不同的学习器。这些学习器可以是同质的(如多个决策树或神经网络),也可以是异质的(如决策树、支持向量机和朴素贝叶斯的组合)。每个学习器都应该具有一定的预测能力,并且它们之间应该存在分歧。
-
分歧的度量:接下来,需要定义一个度量标准来衡量学习器之间的分歧程度。常见的度量标准包括投票熵、KL散度、欧氏距离等。这些度量标准可以帮助我们识别出那些在学习器之间存在较大分歧的样本。
-
样本的选择与利用:基于分歧的方法通常倾向于选择那些分歧较大的样本进行标记或加入训练集。这是因为这些样本往往位于分类边界附近,对于提高模型的性能具有重要意义。一种常见的做法是使用查询策略来选择最具信息量的样本进行标记,然后将这些样本加入训练集以更新模型。
-
模型的更新与优化:在利用分歧样本更新模型时,可以采用各种策略,如集成学习、协同训练等。集成学习通过结合多个学习器的预测结果来提高整体性能,而协同训练则通过迭代地选择分歧样本进行标记和更新模型来逐步优化性能。
想象你和你的朋友们在玩“夺旗”游戏,其中操场被划分为两个领土。领土之间的确切边界没有明确标出,对于一个特定的点是属于哪个领土,你的朋友们有争议。这个点,就像一个未标记的样本,因为其位置(靠近有争议的边界)可能极大地影响游戏的结果。如果你能准确确定这个点属于哪个领土,你就可以做出更好的战略决策。
在机器学习中,学习器(或模型)正尝试对数据点进行分类(就像确定那个点属于哪个领土)。当不同模型对同一个数据点做出不同分类预测时,这表明该数据点位于分类边界附近——模型不确定它属于这个类别还是那个类别的地方。这种不确定性是有信息量的,因为靠近边界的数据点是模型难以分类的,它们提供了有价值的信息,关于边界实际上可能在哪里,帮助进一步完善模型。
本质上,如果多个学习器对一个样本的分类存在分歧,这表明该样本提供了一个很好的学习机会。正是这些具有挑战性的、靠近边界的样本可以通过提供关于决策边界应如何调整的见解来帮助改进模型。识别并专注于这类样本允许更有效的学习和模型改进,特别是在标记数据稀缺但对准确定义分类边界至关重要的情景中。
6.半监督聚类
半监督聚类是一种结合了监督学习和无监督学习的方法,它利用少量的有标记数据和大量的无标记数据来进行聚类分析。与传统的无监督聚类相比,半监督聚类可以利用先验知识或领域信息来指导聚类过程,从而获得更准确的聚类结果。
半监督聚类的基本思想是利用有标记数据来初始化或约束聚类过程,然后利用无标记数据来进一步优化聚类结果。这种方法可以在一定程度上解决无监督聚类中由于数据分布复杂或存在噪声等问题导致的聚类效果不佳的问题。
基于约束的方法
基于约束的半监督聚类方法利用有标记数据提供的约束条件来指导聚类过程。这些约束条件可以分为两类:
-
必连约束(Must-Link Constraints):如果两个样本属于同一类别,则它们必须在聚类结果中被分配到同一个簇中。这种约束通常用于确保已知属于同一类别的样本不会被错误地分开。
-
勿连约束(Cannot-Link Constraints):如果两个样本属于不同的类别,则它们必须在聚类结果中被分配到不同的簇中。这种约束用于防止已知属于不同类别的样本被错误地聚集在一起。
基于距离的方法
基于距离的半监督聚类方法利用有标记数据和无标记数据之间的距离信息来优化聚类结果。这种方法通常包括以下步骤:
-
初始化:使用有标记数据作为种子点来初始化聚类中心。这些种子点可以是已知类别的样本的中心点或其他代表性点。
-
距离度量:计算无标记数据与初始化聚类中心之间的距离。这通常使用欧氏距离、余弦相似度等度量方法来完成。
-
迭代优化:根据距离度量结果,将无标记数据分配到最近的聚类中心所在的簇中。然后,根据新的簇成员更新聚类中心的位置,并重复此过程直到满足收敛条件(如达到最大迭代次数或聚类中心的位置变化小于某个阈值)。
相关文章:
13.西瓜书——半监督学习
1.概述 (1) 纯半监督学习 (Pure Semi-Supervised Learning) 纯半监督学习是一种典型的半监督学习方法,它的主要特点是同时利用有标签数据和无标签数据进行模型训练。目标是通过整合这两种类型的数据来提高模型的泛化性能。在这个过程中&#…...
C++进阶之路---继承(二)
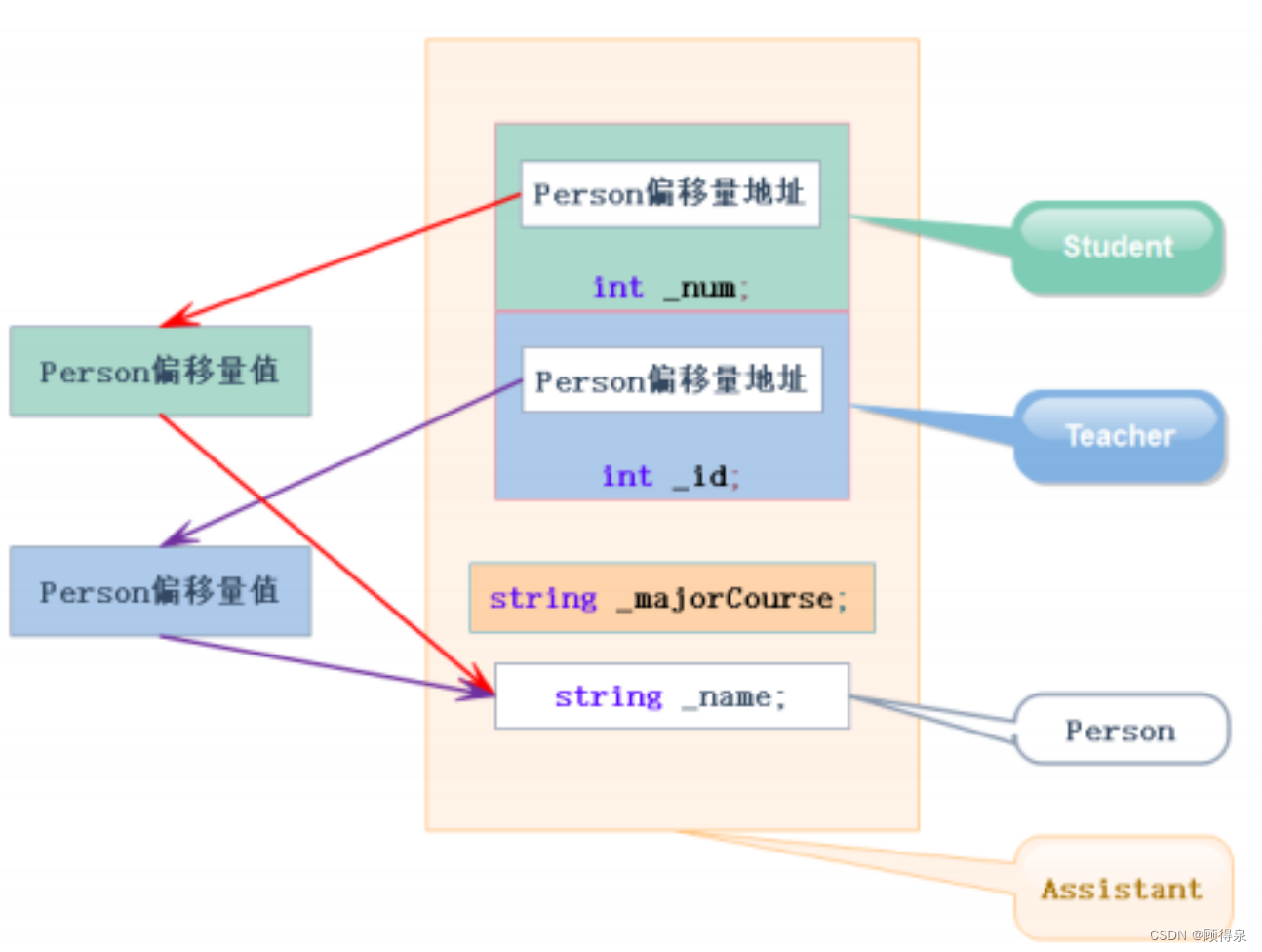
顾得泉:个人主页 个人专栏:《Linux操作系统》 《C从入门到精通》 《LeedCode刷题》 键盘敲烂,年薪百万! 一、继承与友元 友元关系不能继承,也就是说基类友元不能访问子类私有和保护成员。 class Student; class Per…...
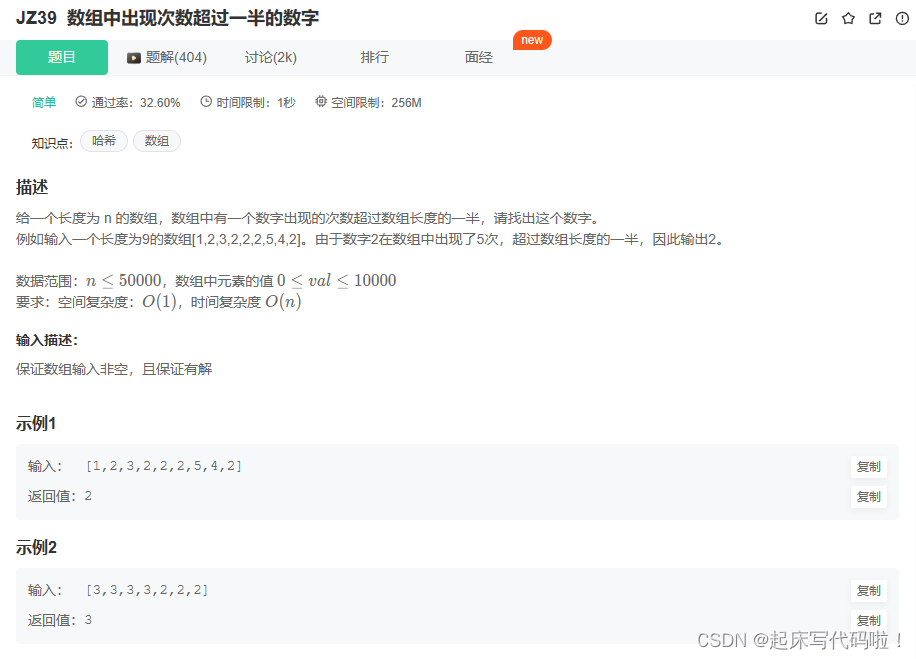
C及C++每日练习(3)
选择题: 1.以下程序的输出结果是() #include <stdio.h> main() { char a[10] {1, 2, 3, 4, 5, 6, 7, 8, 9, 0}, *p; int i; i 8; p a i; printf("%s\n", p - 3); } A.6 B. 6789 C. 6 D.789 对于本题࿰…...

黑马点评-附近商户实现
GEO数据结构 Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,根据经纬度来检索数据。 GEO本质上是基于sortedSet实现的,在Sorted Set中,每个成员都是与一个分数(score)相关联的,这个分数用于对成员进行排序…...

安装nginx:手动安装和yum安装
本文在centos7.9下分别尝试了yum安装和手动安装,记录一下试验过程。为后来者少踩点坑。 下载 下载地址:链接 。建议下载稳定版本,也就是Stable Version,这里下载的是 nginx-1.24.0 # 我下载在如下文件夹 mkdir/opt/apps cd /op…...

【C++ STL详解】——string类
目录 前言 一、string类对象的常见构造 二、string类对象的访问及遍历 1.下标【】(底层operator【】函数) 编辑 2.迭代器 3.范围for 4.at 5.back和front 三、string类对象的容量操作 1.size 和 length 2.capacity 3.empty 4.clear 5.res…...
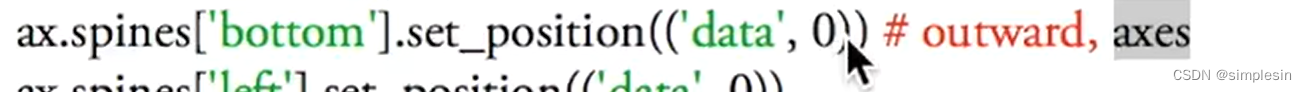
MatplotlibPython 1 3.7
放大数据,如果想仔细看某一行的数据的时候 可以调不同的颜色,图片的长宽高,以及线的种类 plt.figure 这个命令下的所有东西都在这个figure里面 plt.xlim 改变坐标轴的范围 plt.xlabel 改变坐标轴的总名称 plt.xticks 换单位 plt.yt…...

深入理解 Dubbo:构建分布式服务治理体系
目录 1. 介绍 2. Dubbo 的核心概念 2.1 服务提供者(Provider)与服务消费者(Consumer) 2.2 注册中心(Registry) 2.3 监控中心(Monitor) 3. Dubbo 的功能特性 3.1 远程调用&…...

唤起原生IOS和安卓Android app的方法
大家好我是咕噜美乐蒂,很高兴又和大家见面了! 要唤起原生 iOS 或 Android 应用程序,你可以使用以下方法: 唤起原生 iOS 应用程序 在 iOS 上,你可以使用自定义 URL 方案或 Universal Links 来唤起原生应用程序。以下…...
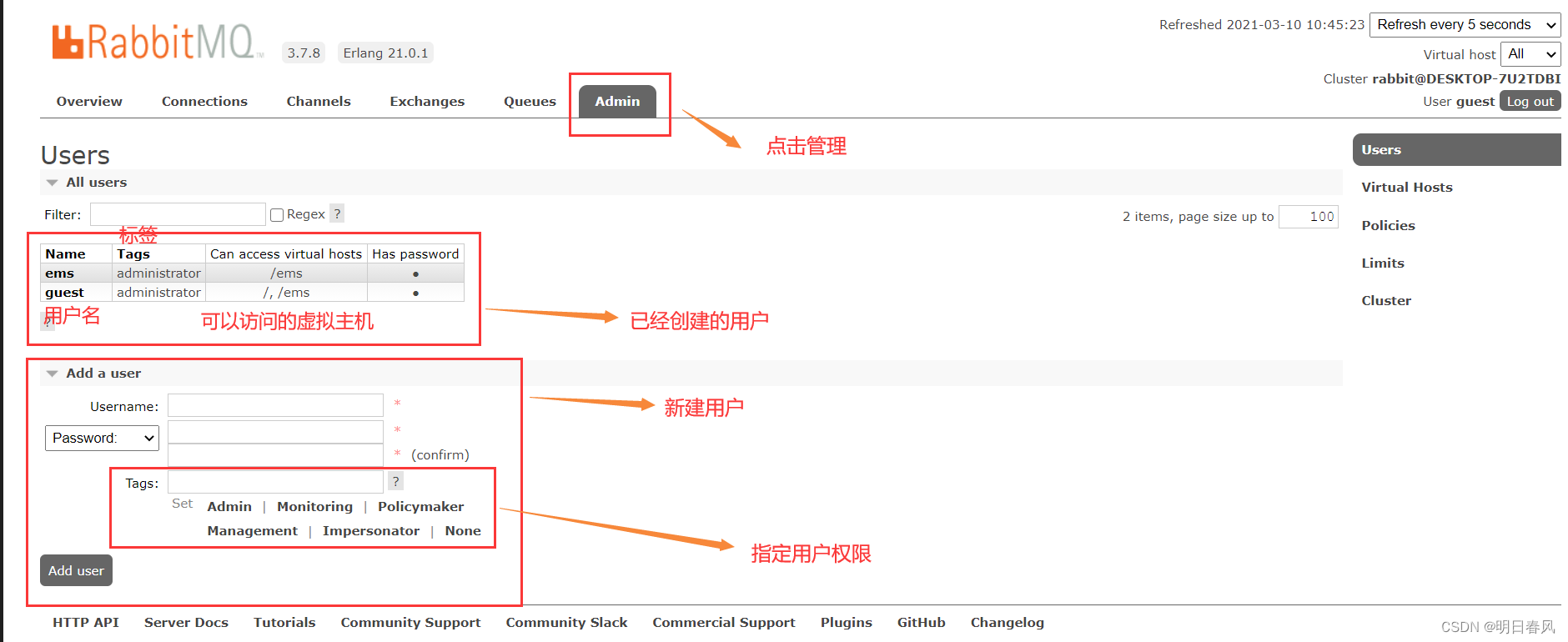
RabbitMQ的web控制端介绍
2.1 web管理界面介绍 connections:无论生产者还是消费者,都需要与RabbitMQ建立连接后才可以完成消息的生产和消费,在这里可以查看连接情况channels:通道,建立连接后,会形成通道,消息的投递、获取…...
GitHub登不上:修改hosts文件来解决(GitHub520,window)
参考链接:GitHub520: 本项目无需安装任何程序,通过修改本地 hosts 文件,试图解决: GitHub 访问速度慢的问题 GitHub 项目中的图片显示不出的问题 花 5 分钟时间,让你"爱"上 GitHub。 (gitee.com) GitHub网站…...
01-DevOps代码上线-git入门及gitlab远程仓库
一、准备学习环境 10.0.0.71-gitlab 2c2g-20GB 10.0.0.72-jenkins 2c2g-20GB 10.0.0.73-sonarqube 1c1g-20GB 10.0.0.74-nexus 1c1g-20GB 10.0.0.75-dm 1c1g-20GB (模拟写代码服务器) 在centos系统中&…...

EdgeX Foundry 安全模式安装部署
文章目录 一、安装准备1.官方文档2. 克隆服务器3.安装 Docker4.安装 docker-compose 二、安装部署1.docker-comepse2.启动 EdgeX Foundry3.访问 UI3.1. consul3.2. EdgeX Console EdgeX Foundry # EdgeX Foundryhttps://iothub.org.cn/docs/edgex/ https://iothub.org.cn/docs…...
网络安全-appcms-master
一、环境 gethub上面自己找appcms-master 二、分析一下源码以及闯关思路 首先是有一个函数循环以及函数过滤,我们的post会将我们所传的所有val值去进行一个循环,之后通过htmlspecialchars这个函数进行过滤和转换所以val值不能通过单双引号闭合注入的方…...

ThreadLocal 与 synchronized 区别
我的理解 目的都是为了一个大前提:操作内容的线程安全。 任务不同:synchronized 解决的是多线程下线程操作权限的问题,以及原子性的保证。通过对锁的竞争,达到对资源的访问有序。 ThreadLocal是解决的事多线程下资源的隔离问题,即…...
灵魂指针,教给(二)
欢迎来到白刘的领域 Miracle_86.-CSDN博客 系列专栏 C语言知识 先赞后看,已成习惯 创作不易,多多支持! 目录 一、数组名的理解 二、使用指针访问数组 三、一维数组传参本质 四、冒泡排序 五、二级指针 六、指针数组 七、指针数组…...

线程安全--浅谈Ad-hoc与加锁的区别
浅谈Ad-hoc 与加锁 两者要解决的都是对对象的语义混乱操作,即有个count进行累加操作。 我的理解/文心一言的反馈如下: 加锁是保证我们对同一个count在多线程下的访问有序,即“读写-修改-写入”具有原子性。 而Ad-hoc机制就是通过程序员自己定义一个私有…...

数据治理实战——翼支付金融板块业务数仓建设和数据治理之路
目录 一、数据治理背景 二、数据治理建设内容 2.1 组织协同 2.2 平台建设 2.3 数据应用治理 2.4 数据规范 2.5 数据安全 三、企业级数仓建设 3.1 调研阶段 2.2 平台护航 2.3 数仓分层 2.4 维度建模 2.4.1 维度建模四步曲 2.4.2 命名规范 2.4.3 资产沉淀 2.4.4 …...

[Buuctf] [MRCTF2020]Transform
1.查壳 64位exe文件,没有壳 2.用64位IDA打开 找到主函数,F5查看伪代码 从后往前看,有一个判断语句,是两个数组进行比较的,我们双击byte_40F0E0查看里面的内容 所以能够推出byte_414040的内容,byte_4140…...

【C++】C++模板基础知识篇
个人主页 : zxctscl 文章封面来自:艺术家–贤海林 如有转载请先通知 文章目录 1. 泛型编程2. 函数模板2.1 函数模板概念2.2 函数模板格式2.3 函数模板的原理2.4 函数模板的实例化2.5 模板参数的匹配原则 3. 类模板3.1 类模板的定义格式3.2 类模板的实例化…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...