Linux【进程理解】
文章目录
- Linux【进程理解】
- 一、冯诺依曼体系结构
- 二、操作系统OS
- 1.深入理解操作系统
- 2.深入理解系统调用和库函数
- 四、 进程
- (一)描述进程-PCB
- (二)组织进程和查看进程
- (三)通过系统调用创建进程-fork初识
- (四)进程状态
- (五)僵尸进程
- (六)孤儿进程
Linux【进程理解】
一、冯诺依曼体系结构
以前的计算机是由输入单元:包括键盘, 鼠标,扫描仪, 写板等和中央处理器(CPU):含有运算器和控制器等和输出单元:显示器,打印机等,而现在的计算机大部分都遵守冯诺依曼体系,在以前的基础上增加了内存,如下图:

各个位置的解释:
1、不考虑缓存情况,这里的CPU能且只能对内存进行读写,不能访问外设(输入或输出设备)外设(输入或输出设备)要输入或者输出数据,也只能写入内存或者从内存中读取即所有设备都只能直接和内存打交道。
2、输入、输出设备称之为外围设备,外设一般会比较慢一些,比如磁盘相对于内存是比较慢的。
3、因为有了内存的存在,我们可以堆数据做预加载,CPU以后在进行数据计算的时候,就不需要访问外设了,直接伸手向内存要就可以。
以上从数据层面上可得出两个结论:
1.CPU只和内存打交道
2.外设只和内存打交道
为什么执行一个程序要先把它加载到内存上:
可执行程序是一个文件,存放于磁盘上,自己的代码和数据上面各种编译好二进制指令是由的CPU去执行的,CPU要访问对应的代码和数据只伸手向内存要,所以运行软件,必须加载到内存,这是有体系结构决定的。
硬件层面,单机和跨主机之间数据流是如何流向的:
- 比如在我们进行播放音乐,首先会把对应的软件,软件客户端加载到内存上,会被CPU执行,就能看到图形化界面,当点击播放的时候,又从网卡里网络里,帮我们把数据拿到计算机里面,然后把它拿到内存里,因为软件音乐也在内存里面,音乐把数据拿到再做计算,对数据进行解析,把对应的计算结果再返回给内存,在内存里显示到外设上,音乐里显示的这个外设就叫做音响。
- 再比和朋友聊天的时候,比如在电脑上聊QQ,自己的电脑是一台冯诺曼体系,朋友也是,自己发送一条信息,从键盘输入数据到内存,数据要做计算,比如要进行加密,进行CPU计算,把计算的结果写回到内存,把该数据显示到输出设备,里面有个网卡,把数据发送到网卡上,然后送到网络里,最后朋友通过输入设备即网卡拿到数据,交给对应的内存,CPU执行解密操作,再写回到内存,再把数据刷新到输出设备,比如对方的显示器。
所以数据流向是由硬件所决定的,数据在流动的时候,必须遵守冯诺依曼规则来进行流动的。
二、操作系统OS
1.深入理解操作系统
什么情况下把什么数据预加载到什么位置,内存空间不够了怎么办,数据和文件应该保存在什么位置,硬件是做不到的,所以要另一款软件产生,它叫做操作系统即OS。
操作系统是一个进行软硬件资源管理的软件。
操作系统包括:内核(进程管理,内存管理,文件管理,驱动管理,其他程序(例如函数库,shell程序等等)
如何理解管理:
1、比如学校的校长和学生,学生修了多少学分,自己哪个专业的,哪个年纪的…自己进入公司,为公司贡献了多少价值,直系领导给自己的打分是多少,有没有完成在年初设定的工作目标,这些都是管理者拿到数据对我们进行管理。
得出结论1:管理和被管理者是不需要直接沟通的
得出结论2:管理的本质是对被管理对象的数据进行管理。
2、那管理者如何拿到被管理者的数据,在学校里是辅导员(其实相当于OS和软硬件之间的驱动程序),他拿到我们的数据,基本信息,各科成绩,在学生会是什么角色等,拿到交给校长做决策。
3、如果校长管理很多学生,基本信息一大堆,如果要开除一个学生,在那么多学生信息记录找到他,那么负担就会很大,得出结论3:管理者把数据拿到还不行,因为数据量很大,管理者很难对这个数据进行分析,就不能做到合法有效的决策。
如果校长(假设校长是一个程序员)要每一个学生的数据,他们的属性都是一样的,先定一个格式,对辅导员要每一个学生的姓名,电话,成绩…,在计算机层面上来说这是一个面向对象的过程,把每个同学抽象成结构体或类,用属性表征每一个同学。辅导员就把这些信息采集到结构体里面,校长写了个代码要把excel的数据读取出来,转换一个结构体,在结构体里面再加一个struct stu* next,每一个学生对应一个结构体对象,对应一个结点,用next指针进行链接起来,形成链表。
比如校长要找到学生数学成绩最好的同学,这样变成了对链表进行遍历,以数学成绩为键值找到数学成绩最高的,就把对应的结点拿到;要把一个成绩最低的同学开除掉,做出决策让辅导员把那名同学劝退,之后还需要在自己所管理的结点把他释放掉,这样就不用管理。决策开除哪名同学这种行为就转化成了对链表的删除和查找。
以上即对学生的所有操作被转化成了对链表结构的增删查改,就完成了一个建模的过程。对管理的动作进行一个建模,把具体的场景转成计算机语言叫做建模。
得出结论4:管理本质是先描述再组织,对学生做管理,先用结构体描述起来,把每一名同学用链表组织起来,按照特定或高效的数据结构比如搞一个搜索二叉树,有序链表,把被组织对象管理组织起来。再比如把设备构成一个结点,以某种方式链接起来,对硬件的管理变成一个对链表的增删查改。这就是一个建模的过程。
得出结论5:描述的过程就是面向对象的过程,组织的过程就是构成数据结构的过程,以后写的软件都跟管理有关。用语言进行面向对象,完成描述,数据结构帮我们完成再组织的过程
得出结论6:只有理解先描述再组织理解管理的本质,进而理解操作系统,要理解OS必须得懂语言和数据结构。
以上的校长(决策)对应的操作系统
辅导员(决策被执行)相当于硬件驱动
学生(参与执行)相当于硬件与软件
硬件驱动和硬件交互,拿到相关的数据,OS拿到数据做决策,结果交给驱动来执行,OS是一个真正的决策者,驱动帮我们做对应的执行的。每一种设备都有对应的驱动。
OS到底对硬件怎么做管理的:
通过各种驱动程序对各种硬件的各种属性信息做提取,OS将所有的硬件信息抽象面向对象式地构成一个先描述对应的设备结构体,获取信息之后填充设备结构体,构建设备结点,然后将所有的底层的管理的设备全部以某种数据结构管理起来,对设备的管理就转换成了一个对链表的管理,比如自己的 OS当前有一个硬件出问题了,一定是对应的硬件驱动程序报告给上层,或者直接在驱动层改了某一个结点的状态,OS在遍历检测的时候发现某个链表某个结点的状态bad,这个时候就坏掉了,这就是硬件与软件耦合的过程。其实对管理做建模。
2.深入理解系统调用和库函数
OS为什么要对软硬件资源做管理,因为计算机是为人服务的,OS管理的本质更好给人提供服务的。OS对下通过管理好软硬件资源(手段),对上给用户提供良好的执行环境(目的),良好体现在安全,稳定,高效,功能丰富。
银行系统类比举例:
银行里面有电脑,服务器,桌椅板凳,仓库,对应的员工宿舍,这些都是银行底层各种硬件设备。
银行里面有对应IT部门维护电脑服务器,后勤是维护桌椅板凳的,保安是维护仓库的等,这里的每一个每部门的人,是和底层硬件进行交互,对应硬件驱动。
行长是OS,对硬件做管理,比如IT部门对电脑服务器的管理得出了一个对应的要求,交给行长做决策,行长拿出了IT部门的清单,进行批准,对硬件做管理。
作为一家银行,里面有大量的员工,代表着任务,有些负责帮我们进行存款的,有些是借贷的,有些是接待的,员工是人,行长也是人,员工被行长管理,OS是一个软件,对硬件做管理也能对软件做管理。
银行行长(OS)为什么对这些做管理,他要通过对下管理好软硬件资源,对上给用户提供良好的环境。
OS会相信我们吗?
OS不会相信任何人,就如同银行不会相信我们,比如不能进去仓库,不能去翻他们的电服务器等。银行即要给我们提供服务,又不允许我们访问内部任何细节。比如我们去存钱,我们不会去仓库直接存,而是通过一个一个窗口即柜台,这样保证了银行给我们提供服务,又保证了自身的安全,就如同OS要给用户提供服务,不可能让用户跑到操作系统内部去访问或者修改,它并不是直接暴露自己的全部信息的,而是将特定功能以接口的方式给用户提供出来的,而这些接口在操作系统层面上叫做OS的系统调用。如图:

换句话说,OS对上提供的服务方式,是通过各种各样的系统调用来提供的,OS使用C语言来写的,这里的系统指的是OS,调用指的是OS设计的C函数,OS给我们提供C语言的函数,可以通过调用者这样的函数去完成使用OS的功能,就如同自己存钱,但是自己不擅长也不能,只能把这种需求通过窗口交给柜台工作人员,帮我们去操作,这样能保证OS的封装性,也能保证给用户提供特定的功能。
但是系统调用使用起来成本会高一些,有些接口需要自己懂OS,所以就由很多的人基于上面的系统调用接口来帮我们做二次的软件的开发,比如帮助我们写windows下图形化界面,以及shell和工具集,给我们提供命令行,有一大堆指令,不需要关心这些指令怎么做的,只要输入指令就能达到特定的目的,比如touch创建一个文件,实际上这个touch指令内部调用了系统调用和通过OS贯穿体系结构向我们的磁盘硬件设备写入;比如在C语言调用print函数是往显示器上打印,显示器是硬件,只有OS才有权利往硬件写入数据即硬件读写,不能直接绕过OS去操作的,而必须通过系统调用接口去访问硬件设备;有些人有了编程的需求,就设计了一门语言比如C/C++语言,但是设计好了,在标准库里面可能需要封装一些标准库进行效率的提升,但是在标准库里面也有一些方法访问硬件,比如读写文件,打开文件,键盘色读取,显示器的输出,所以就需要一堆C语言接口完成这个IO操作,所以就包含了头文件stdio.h,里面的IO接口底层一定要调用系统调用接口。
如果想在OS上面进行打游戏,听音乐,办公,一定有人会基于上层的图形化界面窗口,来编写上层应用比如QQ,QQ音乐,最终通过对应网络的功能来完成某种桌面级软件的编写。我们所写的代码都是应用层代码,用不用系统接口取决于某种场景,一般是上层应用,如果需要使用系统接口,调系统调用再通过OS,硬件驱动,才能访问到硬件。
总结:
在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用。但是系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有些开发者可以对部分系统调用进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。
四、 进程
(一)描述进程-PCB
进程:
程序运行起来就变成了一个进程或者说可执行程序加载到内存就变成一个进程。以前的任何启动并运行程序的行为是由OS帮助我们将程序转换为一个进程,完成特定的任务。
如何变成一个进程:
可执行程序本质就是一个普通二进制文件,文件等于内容+属性,然后OS将代码和数据加载对应的内存,CPU才能访问我们的代码和数据,这样还不是一个进程,怎么才能变成一个进程,是需要被操作系统管理它,因为当在磁盘中加载了成百上千个程序到内存,要让计算机帮助我们去执行各自的任务时候,OS面对那么多的程序,OS必须得管理它们。而何为管理,前面说了管理的本质是先把进程描述起来,再把进程组织起来。操作系统会给每一个进程在加载到内存时候,OS帮我们在内核当中创建一个数据结构对象,在书里叫做PCB,在linux叫做task_struct,task_struct是Linux内核的一种数据结构,它会被装载到内存里并且包含着进程的信息。
进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
每加载一个进程,OS在内核创建一个PCB对象,也就是说程序加载到内存,不仅仅是把代码和数据加载到内存,也要为了便于管理代码和数据,为对应的代码和数据创建对应的描述结构体,里面很多属性,但是都是task_struct,所以可以在里面新增对应的结构体指针,让PCB之间通过特定数据结构关联起来。对进程做任何管理就转换成了对于进程PCB结构形成的链表的增删查改。
所以进程=内核关于进程的数据结构+当前进程代码和数据。
task_ struct属性:
1.标示符: 描述本进程的唯一标示符,用来区别其他进程。
2.状态: 任务状态,退出代码,退出信号等。
3.优先级: 相对于其他进程的优先级。
4.程序计数器: 程序中即将被执行的下一条指令的地址。
5.内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
6.上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
7.I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
8.记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。 其他信息
(二)组织进程和查看进程
组织进程:
可以在内核源代码里找到它。所有运行在系统里的进程都以task_struct链表的形式存在内核里。
查看进程:
1、进程的信息可以通过 /proc 系统文件夹查看如:要获取PID为1的进程信息,你需要查看 /proc/1 这个文件夹。大多数进程信息同样可以使用top和ps这些用户级工具来获取。poc里面内容是一个内存级的文件系统,只有OS启动的时候才会存在。一旦进程被创建好,OS自动地在/poc目录下创建一个以新增进程PID命名的文件夹。
如图:

2、也还可以通过ps ajx | head -1&& ps ajx | grep fork1命令来查看进程状态,逻辑与前面的是把ps ajx的输出结果第一行的属性名提取出来,逻辑与后面是把属性名和对应的信息关联起来。
运行下面进程:


(三)通过系统调用创建进程-fork初识
通过系统调用获取进程标示符
进程id(PID)和父进程id(PPID)
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("pid: %d\n", getpid());
printf("ppid: %d\n", getppid());
return 0;
}
以上是分别获得子进程的ID,和父进程的ID。
如图1:


看图分析:
为什么会打印两行2,以现在的理解是这个printf打印2,被执行了两次,有两执行流,,打印这一串的pid时不一样的,两个进程,在后面两行里一个进程pid是20539,另一个ppid20539,所以这两创建的进程是父子关系,所以成功调用pid创建子进程。也能看到,是父进程打印的1,而1683是bash。
bash命令行解释器,本质上也是一个进程。
命令行启动的所有的程序,最终会变成进程,而该进程对应的父进程都是bash。
如图2;
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{int ret = fork();if(ret < 0){perror("fork");return 1;}else if(ret == 0){//childprintf("I am child : %d!, ret: %d,&ret:%p\n", getpid(), ret,&ret);}else{ //fatherprintf("I am father : %d!, ret: %d,%ret:%p\n", getpid(), ret,&ret);}sleep(1);return 0;
}

如果我们所对应的父进程创建成功,子进程的pid会返回给父进程,0返回给子进程,反悔失败返回-1。
如上结果fork有两个返回值。
fork做了什么:
创建子进程,创建独立的PCB,里面的指针指针指向内存中的代码和数据,并且代码是只读的,数据部分是当有一个执行流尝试修改数据的时候,OS会自动给我们当前进程触发写时拷贝。子进程没有自己的独立的代码和数据,默认创建子进程会共享父进程的代码和数据,代码共享直接共享,数据是以写时拷贝的方式进行的双方查看的。
如何创建的子进程:
fork之后,执行流会变成2个执行流。
fork之后,谁先运行由调度器决定。
fork之后,fork之后的代码共享,通常我们通过if和else if来进行执行流分流。
父子进程代码共享,数据各自开辟空间,私有一份(采用写时拷贝),fork 之后通常要用 if 进行分流。
fork如何看待代码和数据:
进程在运行的时候,是具有独立性的,父子进程运行的时候,也是一样的。代码是共享的不影响,数据以写时拷贝的方式各自私有一份。
fork如何理解两个返回值问题(浅浅理解):
当我们准备最后的return语句,是不是函数的主题功能已经跑完了?所谓的返回是向调用者告知结果,当我们函数内部准备执行return的时候我们的主题功能已经完成,当有一个fork系统调用,父进程调用fork,里面有一个执行流进来调用里面的代码,fork本质上是OS提供的一个函数,接着如前面所说函数内部return的时候主题功能完成,说明子进程创建出来,甚至又可能被调度,最后fork是一个函数,也要return返回对应的返回值,当在返回的时候,return是语句,意味着当再往后执行的时候父进程可以被调度,子进程有它的执行流也要去执行,所以return要执行两次,让我们好像看到两个返回值。
总结:有一个共识,函数在执行return的时候,其实该做的工作已经做完了,在return之前,父进程早已把子进程所有工作都准备好了,只是最后告诉上层创建成功没成功,所以最后要执行r对应的return,但父进程在执行return的时候,return也是一条语句,就跟对应的printf一样在后续的执行流当中代码是共享的,父子各自执行了两次,只不过这个return在fork函数在内部看不到。
新的问题:
可是接收它的返回值的时候,在C语言上用的是一个变量,怎么一个变量会出现两个不同的值,返回值的时候是向这个变量写入的过程,当fork返回的时候,这个变量是父进程定义的一个局部变量,当它在写回时,OS自动对发生写时拷贝,就看到了地址一样,同一个变量的内容不一样,因为底层帮我们进行了写时拷贝,看起来地址一样,其实被存到了不同的空间。可视打出的地址是一样的,怎么访问的值不一样,即便发生了写时拷贝,只有一个原因,就是这个地址不是物理地址,,如果它是物理地址,此时看到的是不同的地址有不同的内容,所以C/C++用到的所有的地址都不是物理地址,是虚拟地址。
fork对应的返回值是由两个的,怎么理解:fork是一个函数,当它在内部执行我们对应return的时候,一定是父子进程都执行了return,所以才有两返回值。
(四)进程状态
进程在CPU跑的时候,不一定一直在运行,在CPU跑一会,把这个进程拿下来,把另一个进程拿上来。这是基于大量进程切换的分时系统,让每一进程都运行一点,然后让别人通过切换的方式让大家都在一个时间段内都得以推进,CPU在进行快速切换,人很难看到它的时间差,导致人看着它们好像同时运行。进程在运行的时候,是可以被OS管理和调度的,凭什么调度它,凭什么让这个进程运行在CPU上,凭什么让别人不在CPU运行,这去取决于进程状态 ,要理解它, 先理解阻塞和挂起。
阻塞:进程因为等待某种条件就绪,而导致的一种不推进的状态,即进程卡住了,就是没被CPU执行调度的或者没被使用导致被卡主。
为什么阻塞?
进程要通过等待的方式,等具体的资源被别人使用完成之后,再被自己使用。
阻塞一定是在等待某种资源。资源可以是磁盘,网卡,显卡的各种外设,如果这些资源在被进程使用,如果一段时间没被使用,就会卡顿。阻塞就是等待某种资源就绪的过程。比如下载一个任务,在下载的时候,网突然没了,CPU不再执行这个进程,把它设为阻塞状态,等网好了再把它拿过来。
理解等待某种资源:
OS一款搞管理的软件,管理的本质是先描述,再组织,OS管理网卡各种外设的时候,就是先描述再组织,对设备的管理就对链表的增删查改,这些硬件结构体都是struct,假如命名为struct dev,用链表链接起来,而OS里面存在大量的进程,OS需要对它们进行管理,也是先描述再组织,OS就存在大量task_struct结构体。假如一个进程在被CPU运行的时候,CPU发现它要等待一个网卡资源,也就是网络资源,所以这个进程就得去找网络。而在struct dev结构体里存在一个struct task_struct* queue,就是指针是为了链接,当有一个进程要去找资源的时候,不能在CPU上跑了,这时候进程就把进程的PCB链接在它所等待的设备队列的尾部,就叫做该进程等待某种资源。
所谓的进程阻塞一定是等待某种资源,一个进程都有自己的PCB,把它们放在对应的某种资源所维护的队列中就叫做阻塞
举例:
有人写了个C语言里cin和scanf代码,启运行之后变成进程,等待客户输入,如果不输入,这个进程就没被OS调度,它在等待键盘输入,键盘是OS里的一个设备,需要管理它,先描述再组织,为了管理它创建键盘对应的struct dev设备,它里面也可以(有指针)在内核当中维护对应的队列结构,把代码运行起来,OS发现这个进程需要输入,得从键盘拿到数据再能被运行,这个进程在键盘的等待队列当中去等待,也就是说这个进程是阻塞在这个键盘上的,当在键盘输入数据时,OS让进程知道有键盘输入了,进程就拿着这个PCB放在CPU上去执行。
总结:当一个进程被调度就是拿着它的PCB通过它的结构体找到它的代码和数据去运行,如果发现它的代码和数据当中有些资源没有就绪,就只需要将对应的进程控制块从CPU某些特定的队列当中拿下来,放到所等待的某种资源处排队,叫做该进程等待某种资源。那么这个进程不会被CPU调度,不会被调度在用户来看就卡住了。
通过阻塞的概念理解一个点:OS对进程做任何状态性的变化,一定和此进程当前处在某些队列当中是强相关的。
阻塞:阻塞就是不被调度,一定是因为当前进程需要等待某种资源就绪,一定是进程task_struct结构体需要在某种OS管理的资源下排队,不认为只在CPU排队,在其他资源上也会排队。
挂起:假设是CPU外面,里面内存里有一个进程,它的PCB里面的指针指向代码和数据,它被CPU调度,假设是一个下载任务,有些原因没网了,OS对进程说不能在CPU上跑了不要调度了,让其他进程去跑,所以这个进程就把自己的PCB链入到了对应的网卡设备队列当中,这个进程就是阻塞了。有一刻,OS当中内存资源非常紧张,需要通过自己的一套算法把占有内存的,闲置的一些不被调度的代码和数据交换到磁盘中,所以这部分的代码和数据就可以被释放了,OS就腾出了一些空间,当这个进程所的等待的资源就绪的时候,需要再被调度之前,就把代码和数据换入到内存中,然后把这个进程放在CPU运行。把进程的代码和数据暂时性地由OS交换到磁盘时,此时这个进程就被称为挂起状态。全程是阻塞挂起状态。
这时候需要谈Linux进程的不同状态。一个进程可以有几个状态。
下面的状态在kernel源代码里定义
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};
task_struct是一个结构体,内部会包含各种属性,就有状态。所谓进程的变化去改上面的整数。
R状态:R状态不一定在CPU上运行,系统里可能会存在10几个R状态,但是这里面当中只有几个在CPU运行,那么在CPU里进程被调度运行时,也要维护一个对应的运行队列,由OS维护,所以CPU在进行调度进程的时候,只需要从运行队列当中去挑选指定的进程去运行,这样的状态是R状态,所以进程是什么状态,一般看这个进程在哪排队,所以R状态并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列里。是结构以对象在排队,内部包含next指针可以把所有进程关联起来。
S睡眠状态: 意味着进程在等待事件完成,这里的睡眠有时候也叫做可中断睡 睡眠,本质是一种阻塞状态
R,S状态举例:如果一个程序里面有一个死循环,在结果上看一直在打印,在一些人来看一定是在运行,如下:

printf循环打印是访问外设的行为,printf的本质是向外设打印信息,当CPU执行printf代码的时候,在底层的就需要访问外设,可这是在频繁打印时,外设不一定是就绪,当前这个进程并没有在CPU上排队,只在外设当中排队,当设备就绪了,才把数据写到外设当中,意思就说刚刚的S状态叫阻塞状态的一种,是以休眠的状态进行阻塞的,当前进程并没有真的一直在CPU运行队列中等,而是printf而导致的等待某种资源。所以是S之类的状态,CPU和外设相比较,CPU的速度很快,不允许在持有CPU的同时,还在等外设,在等外设的那几毫秒,能跑成千上万行代码,所以在用ps查的时候有大部分状态是S,只有很少是R,如果把printf状态注释掉,就是R状态,因为没有代码当中没有任何访问资源,while是一个纯计算的代码,只会用CPU资源。
D磁盘休眠状态:有时候也叫不可中断睡眠状态,在这个状态的进程通常会等待IO的结束。
D状态举例理解:
假设一个内存里有一个进程,它要做向磁盘里面写入大量数据,这个进程想把数据存磁盘里面,只要存进去才能在CPU上跑,但是磁盘太慢,需要等一等,进程就等就设置为S状态,就在磁盘的内核数据结构中等,这个时候,磁盘开始进行把那些数据进行拷贝,在进行拷贝的时候,OS发现内存资源非常紧张,它发现这个进程在这什么都不干,要把它kill掉,这个磁盘的数据在写数据,磁盘空间不足,去找进程写入失败,但找不到了,这些数据就有可能丢了。怎么能保证这个进程不被杀死,就可以设置为D状态,OS就无法杀死它。只有自己醒来才能杀死他,有时候关机也不行。本质上也是一种阻塞状态。
T停止状态: 本质也是一种阻塞状态,一个进程正在运行,后来不想让它运行,不终止,只是暂停,kill命令(kill -l查看信号)可以向SIGSTOP(19)信号发送命令,kill -19 进程ID号,这样进程就被终止了,再用ps查就变成T状态,如果想它继续进行,kill -18 进程ID号,就能继续运行。小t是追踪式的暂停,类似于在代码中的断点,就能插到t
如果我们的进程后面带+号,那是在前台运行,可以用ctrl+c终止它,如果没有是在后台运行,就需要kill -9 进程ID 就能kill掉。
休眠是等待某种资源,真正的阻塞状态,暂停状态是为了OS在不kill掉进程的条件下,停止这个进程的某种行为。
X死亡状态:这个状态只是一个返回状态,不会在任务列表里看到这个状态,是一个瞬时转状态。
Z状态:Z状态叫僵尸状态,进程已经退出,但资源没有完全被释放时处于的一种状态,也即是等待后续被处理的一种状态。
(五)僵尸进程
为什么要创建进程:
因为要执行自己的代码,要让进程帮我们做事,为什么要执行自己的代码,肯定是想完成一项工作。有两种结果,关心和不关心。如果关心结果,比如在c语言里有一个main的返回值,return它叫做进程退出码,任何命令行启动的进程都是bash的子进程,所以当运行的时候,父进程bash创建子进程,让它帮父进程办事,但是父进程怎么知道办成功没,是通过进程退出码知道的,用echo ¥?命令看以查看退出码。
理解Z状态:
如果一个进程退出了,立马X状态,作为父进程就没有机会拿到退出结果,linux当中,当进程退出时候,不会立即彻底退出,而是要维持一个状态叫做Z状态即僵尸状态,方便后续父进程读取子进程退出结果。
如图把子进程kill掉,子进程会变成Z转态被后续父进程读结果:


如何看待僵尸状态:
子进程退出,但不回收子进程,维持Z状态,这样会占大量资源,可用资源变少,父进程如果一直不读取,那子进程就一直处于Z状态,维护退出状态本身就是要用数据维护,也属于进程基本信息,所以保存task_struct(PCB)中,换言之,Z状态一直不退出,PCB一直都要维护,为什么会造成内存资源的浪费,因为数据结构对象本身就要占用内存,比如C/C++中定义一个结构体变量(对象),是要在内存的某个位置进行开辟空间,不归还OS,最终造成内存泄漏。
(六)孤儿进程
理解孤儿进程:
如果父进程退出,子进程会被OS自动领养,通过让1号进程又称为OS成为它的新的父进程,此时子进程就称之为“孤儿进程”。
如图在代码里写个循环,让父进程里面计数–,减到小于0就退出,之后查看子进程的状态:

父进程退出之后也应该立马处于Z状态,在结果里并没有看到父进程僵尸状态,如果子进程退出,看到过子进程是Z状态,那是因为上次没有回收,里面的代码没有写完是没有等待的(要wait()调用),而现在的父进程退出之后,也有自己的父进程即bash,bash把它回收了。
里面有个细节,被领养之后,状态有S+进变为S,由前台进程变为后台进程,需要 kill -9 进程ID,也可以killall 进程名称,干掉进程。
什么要领养:
如果不领养,这个孤儿进程就没有父进程,未来这个孤儿进程,就没有进程·替他收尸,最终孤儿进程永远在OS中处于游离状态,永远占据OS相关的内存资源,造成内存泄漏。即子进程后续在退出,无人回收。
相关文章:
Linux【进程理解】
文章目录Linux【进程理解】一、冯诺依曼体系结构二、操作系统OS1.深入理解操作系统2.深入理解系统调用和库函数四、 进程(一)描述进程-PCB(二)组织进程和查看进程(三)通过系统调用创建进程-fork初识&#x…...

【华为OD机试2023】数组的中心位置 C++ Java Python
【华为OD机试2023】数组的中心位置 C++ Java Python 前言 如果您在准备华为的面试,期间有想了解的可以私信我,我会尽可能帮您解答,也可以给您一些建议! 本文解法非最优解(即非性能最优),不能保证通过率。 Tips1:机试为ACM 模式 你的代码需要处理输入输出,input/cin接收…...

“大数据时代下的地理信息可视化:ECharts地图和数据面板实践“
数据可视化是一种数据分析技术,它通过将数据转化为图形或图表等可视化方式,以便更好地理解和解释数据。在实际应用中,数据可视化被广泛用于数据监控、业务分析、决策支持等领域。而ECharts是一款优秀的数据可视化工具,它具有丰富的…...
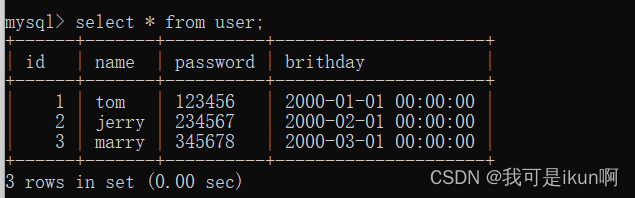
MySQL数据库基础
目录 数据库介绍 什么是数据库 数据库的分类 1. 数据库的操作 创建数据库 显示数据库 使用数据库 删除数据库 2. 表的操作 创建表 删除表 3. 常用数据类型 插入数据 查询数据 从本篇起就又要开始新的篇章了,数据结构初级阶段的就告一段落了࿰…...

近自由电子近似
假设 potential 的变化是非常小的 我们可以找到一条平均线 代表的就是我们的平均值 这样我们用原来的 就可以得到一个 和平均的这条线相比,上下变化不大,这个对我们薛定谔方程求解能带来很大的便利 我们就可以得到一个平均势场 这样的话,…...

【JavaWeb】从输入URL到展示出页面的过程
目录 DNS域名解析 检查hosts文件 查询缓存 查询本地DNS服务器 编辑查询根域名服务器等 三次握手建立连接 发送请求 响应请求 页面渲染 断开连接 这些过程简单的理解为先找到某人地址,给他发送消息可以去他家拿东西吗?他同意后拿到他的东西在…...
)
华为OD机试真题Java实现【数字涂色】真题+解题思路+代码(20222023)
数字涂色 题目 疫情过后,希望小学终于又重新开学了,三年二班开学第一天的任务是将后面的黑板报重新制作。黑板上已经写上了N个正整数,同学们需要给这每个数分别上一种颜色。为了让黑板报既美观又有学习意义,老师要求同种颜色的所有数都可以被这种颜色中最小的那个数整除。…...

Log Structure Merge Tree
LSM是一种基于日志追加写的数据结构,非常适合为具有高写入数据提供索引访问 LSM基于以下前提 内存读写速度远高于磁盘,但内存有限磁盘顺序读写速度远高于随机读写 结构 WAL WAL(write-ahead log)是用于在系统错误时提供持久化,在写入数据…...

Python QT5设计UI界面教程
简介:PyQT5开发常用知识,零基础上手,需配合我之前写的博文,配置好QT设计工具和ui文件转py文件的工具。博文为:使用Python PyQt5实现一个简单的图像识别软件;页面效果如下: 1.设计菜单栏 Contai…...

uniapp系列-图文并茂手把手教你hbuilder进行uniapp云端打包 - 安心打包
什么是安心打包 提交App的模块配置信息到云端,在云端打包机生成原生代码包 为什么使用云打包 更安全:打包时不提交应用代码、证书等信息更快速:非首次打包时不用提交云端打包机排队等待,本地直接出包省流量:减少了打…...

【精品】SpringBoot中基于拦截器实现登录验证功能
拦截器简介 拦截器是属于springmvc体系的,只能拦截controller的请求。拦截器(Interceptor)是一种动态拦截方法调用的机制,在SpringMVC中动态拦截控制器方法的执行。 Interceptor 作用 日志记录:记录请求信息的日志&…...

哈工大服务科学与工程第一章作业
服务的概念服务是个非常广义的概念——涉及到经济、管理、业务、IT领域以下是一些各方对服务的定义:服务是一方向另一方提供的任意活动和好处。它是不可触知的,不形成任何所有权问题,其生产可能与物质产品有关,也可能无关。服务是…...

SpringMVC源码:参数解析、方法调用与返回值处理
参考资料: 《SpringMVC源码解析系列》 《SpringMVC源码分析》 《Spring MVC源码》 写在开头:本文为个人学习笔记,内容比较随意,夹杂个人理解,如有错误,欢迎指正。 前文: 《SpringMVC源码&a…...

【MySQL】表的数据处理
哈喽,大家好!我是保护小周ღ,本期为大家带来的是 MySQL 数据表中数据的基本处理的操作,数据表的增删改查,更多相关知识敬请期待:保护小周ღ *★,*:.☆( ̄▽ ̄)/$:*.★*一、 添加数据&a…...

反思当下所处的环境,有没有让你停滞不前、随波逐流
环境对人的影响真的很大,小时候的环境、长大后的环境、工作环境、生活环境、好的环境、差的环境......我们都生活在一定的环境中所以既是环境的产物,又是环境的创造者与改造者。我们与环境的关系是相辅相成的我们的生活和工作当中接触到的人或事或物&…...
后端-签到成功)
小程序(十四)后端-签到成功
文章目录一、持久层1、CheckinMapper.xml2、CheckinMapper.java3、TbHolidaysDao.xml4、TbHolidaysDao.java5、TbWorkdayDao.xml6、TbWorkdayDao.java二、业务层1、 CheckinService.java三、conroller层1、编写 TbUserDao.xml 文件,查询员工的入职日期。2、编写 TbU…...

X264简介-Android使用(一)
X264 简介及使用 1、简介 2、环境搭建 3、使用 4、小结 简介 官网连接:https://www.videolan.org/developers/x264.html 官方文档:https://wiki.videolan.org/Category:X264/ x264是用于编码H.264/MPEG-4 AVC视频流的免费软件库。它世界上最流行的…...
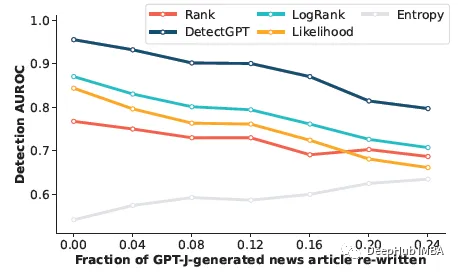
DetectGPT:使用概率曲率的零样本机器生成文本检测
DetectGPT的目的是确定一段文本是否由特定的llm生成,例如GPT-3。为了对段落 x 进行分类,DetectGPT 首先使用通用的预训练模型(例如 T5)对段落 ~xi 生成较小的扰动。然后DetectGPT将原始样本x的对数概率与每个扰动样本~xi进行比较。…...
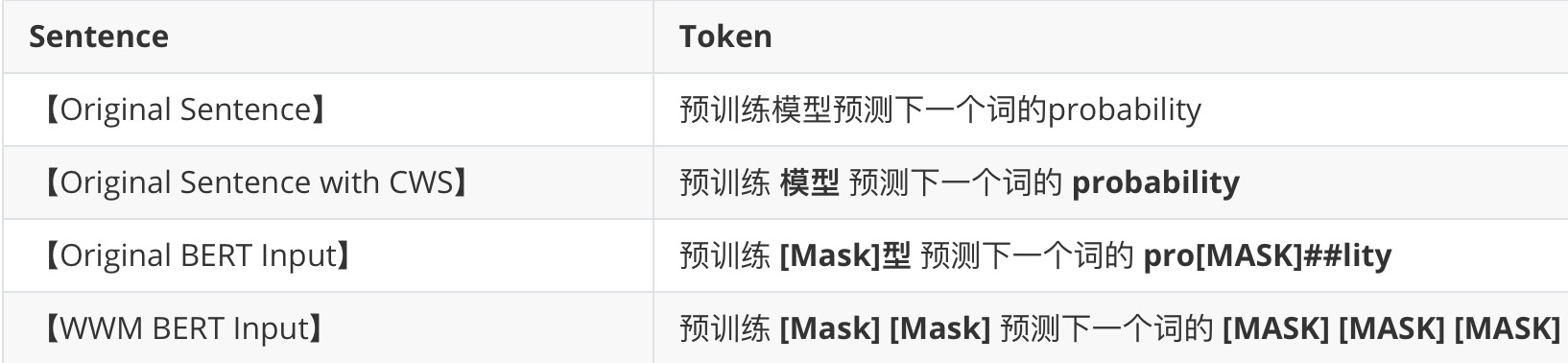
【深度学习】BERT变体—BERT-wwm
1.BERT-wwm 1-1 Whole Word Masking Whole Word Masking (wwm)是谷歌在2019年5月31日发布的一项BERT的升级版本,主要更改了原预训练阶段的训练样本生成策略。 原有基于WordPiece的分词方式会把一个完整的词切分成若干个子词,在生成训练样本时ÿ…...
)
【华为OD机试真题 java、python、c++】优秀学员统计【2022 Q4 100分】(100%通过)
代码请进行一定修改后使用,本代码保证100%通过率。本文章提供java、python、c++三种代码 题目描述 公司某部门软件教导团正在组织新员工每日打卡学习活动,他们开展这项学习活动已经一个月了,所以想统计下这个月优秀的打卡员工。 每个员工会对应一个id,每天的打卡记录记录当…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...
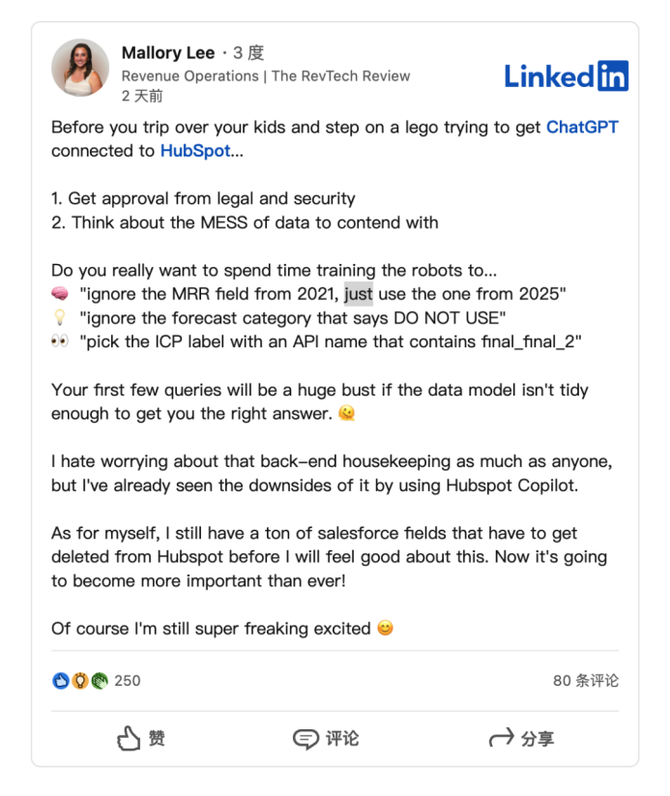
HubSpot推出与ChatGPT的深度集成引发兴奋与担忧
上周三,HubSpot宣布已构建与ChatGPT的深度集成,这一消息在HubSpot用户和营销技术观察者中引发了极大的兴奋,但同时也存在一些关于数据安全的担忧。 许多网络声音声称,这对SaaS应用程序和人工智能而言是一场范式转变。 但向任何技…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...