ELK日志管理实现的3种常见方法
ELK日志管理实现的3种常见方法
1. 日志收集方法
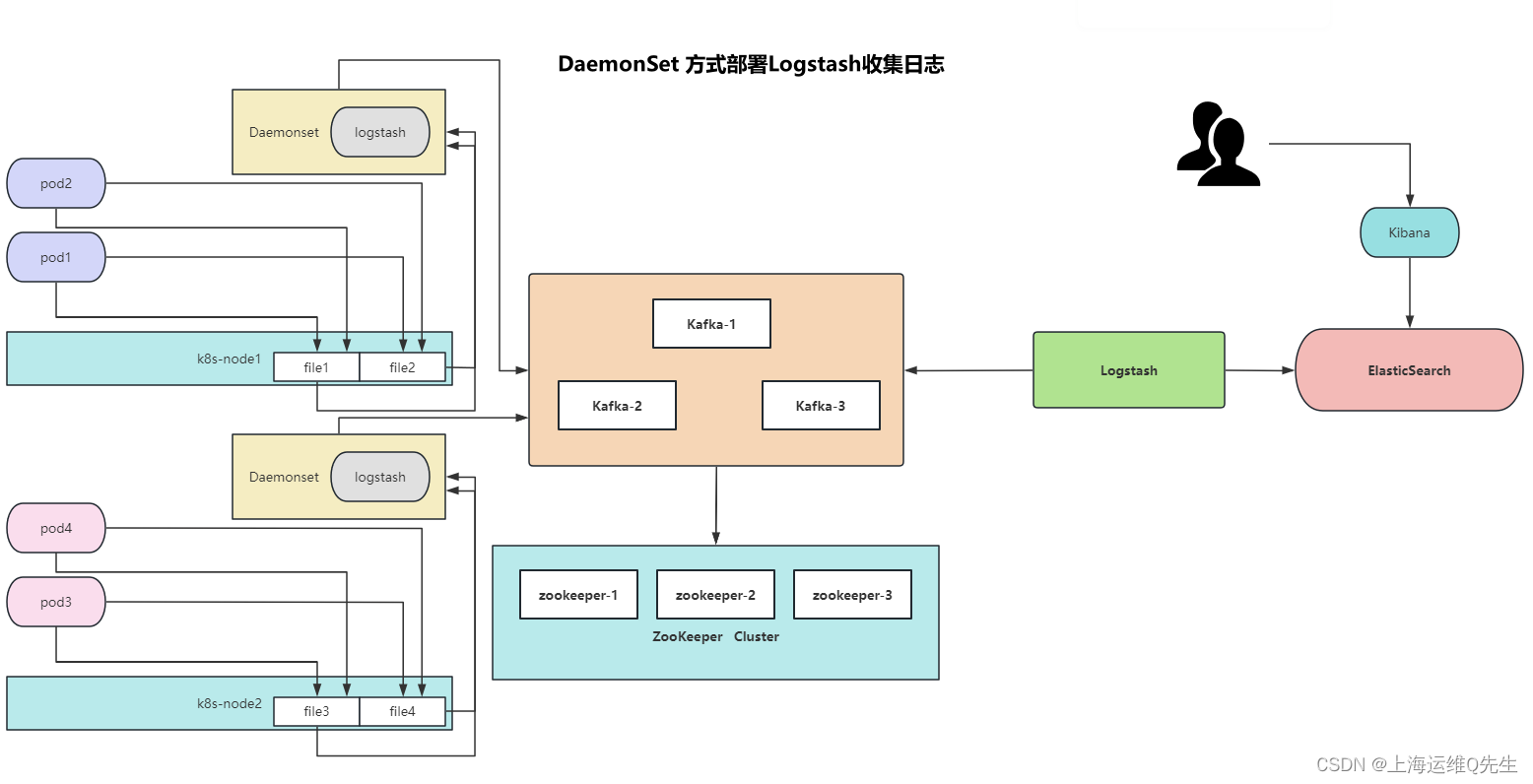
1.1 使用DaemonSet方式日志收集
通过将node节点的/var/log/pods目录挂载给以DaemonSet方式部署的logstash来读取容器日志,并将日志吐给kafka并分布写入Zookeeper数据库.再使用logstash将Zookeeper中的数据写入ES,并通过kibana将数据进行展示.
标准日志和错误日志:
标准日志 -->/dev/stdout
错误日志 ----> /dev/stderr
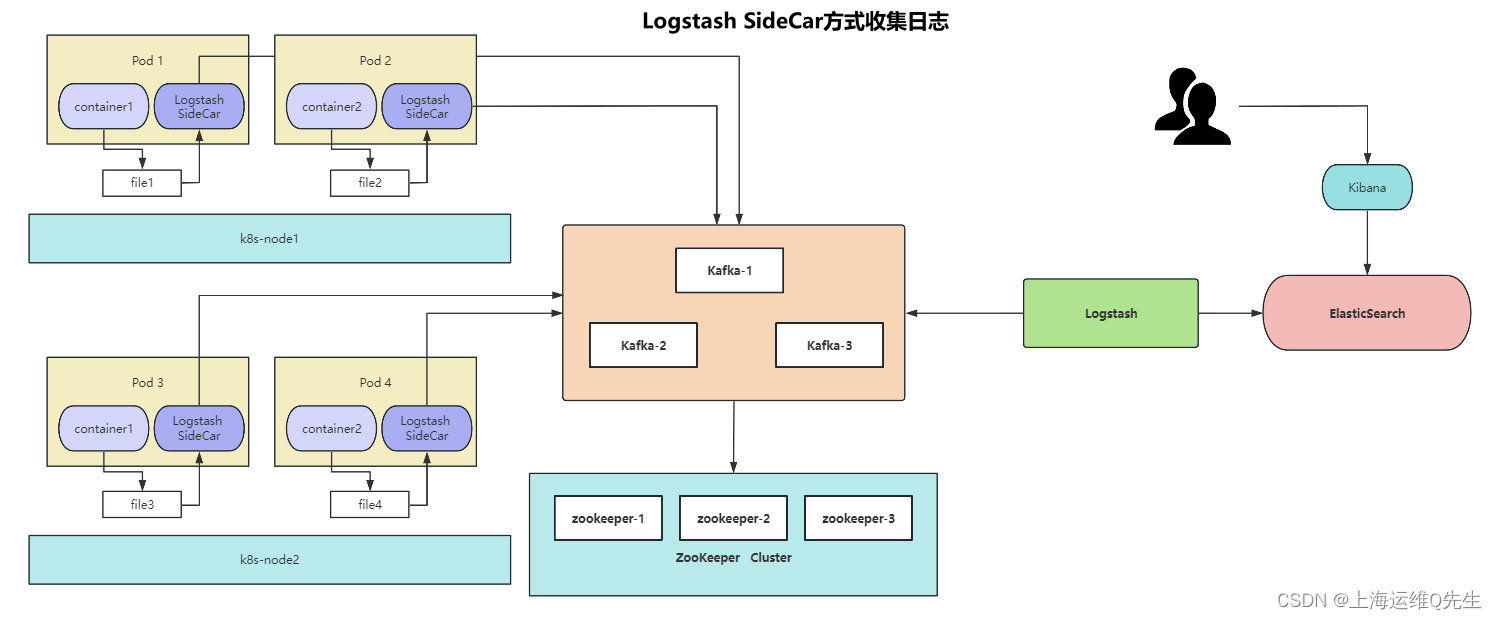
1.2 使用Logstash SideCar日志收集
pod中两个容器,1个是业务容器,另一个是日志收集容器,通过emptydir实现文件共享
1.3 容器镜像中filebeat进程日志收集
对业务容器镜像修改,容器中启动filebeat
3种方式的对比:
- daemonset资源占用更少
- sidecar和filebeat可以更多的定制,但sidecar资源占用会更多
2. ElasticSearch集群部署
2.1 ElasticSearch器安装
- 下载deb包
清华源下载elasticsearch-7.12.1-amd64.deb
https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/apt/pool/main/e/elasticsearch/elasticsearch-7.12.1-amd64.deb
- 3台ES服务器安装
dpkg -i elasticsearch-7.12.1-amd64.deb
- 修改配置文件
vi /etc/elasticsearch/elasticsearch.yml
cluster.name: k8s-els # 保证一样
node.name: es-01 # 3台保证不同
#bootstrap.memory_lock: true # 启动占用内存,如果打开需要修改/etc/elasticsearch/jvm.options# 在/etc/elasticsearch/jvm.options中打开以下选项确保内存占用是连续的## -Xms4g## -Xmx4g
# 监听地址和端口
network.host: 192.168.31.101 # 也可以写成0.0.0.0
http.port: 9200
# 集群中有哪些服务器
discovery.seed_hosts: ["192.168.31.101", "192.168.31.102","192.168.31.103"]
# 哪些服务器可以作为master
cluster.initial_master_nodes: ["192.168.31.101", "192.168.31.102","192.168.31.103"]
# 删除数据不允许模糊匹配
action.destructive_requires_name: true
- 启动elasticsearch
systemctl enable --now elasticsearch.service
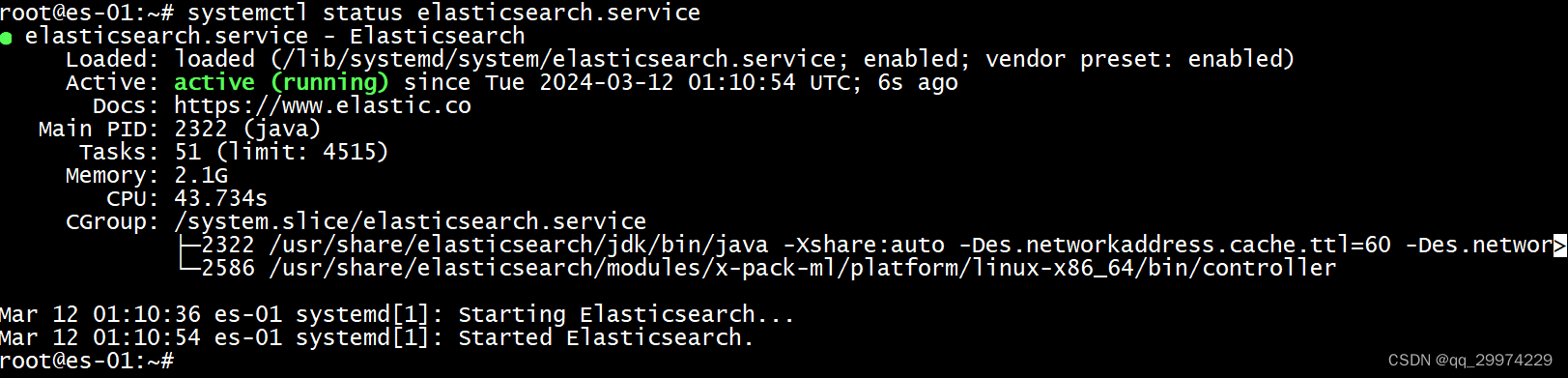
- 确认服务启动完成
systemctl status elasticsearch.service
2.2 Kibana安装
- 下载
清华源下载kibana-7.12.1-amd64.deb
https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/apt/pool/main/k/kibana/kibana-7.12.1-amd64.deb
- 安装
dpkg -i kibana-7.12.1-amd64.deb
- 修改配置
vi /etc/kibana/kibana.yml
修改内容
server.port: 5601
server.host: "192.168.31.101" # 也可以写成0.0.0.0
elasticsearch.hosts: ["http://192.168.31.101:9200"] # 任意一个节点即可
i18n.locale: "zh-CN"
- 启动服务
systemctl enable --now kibana
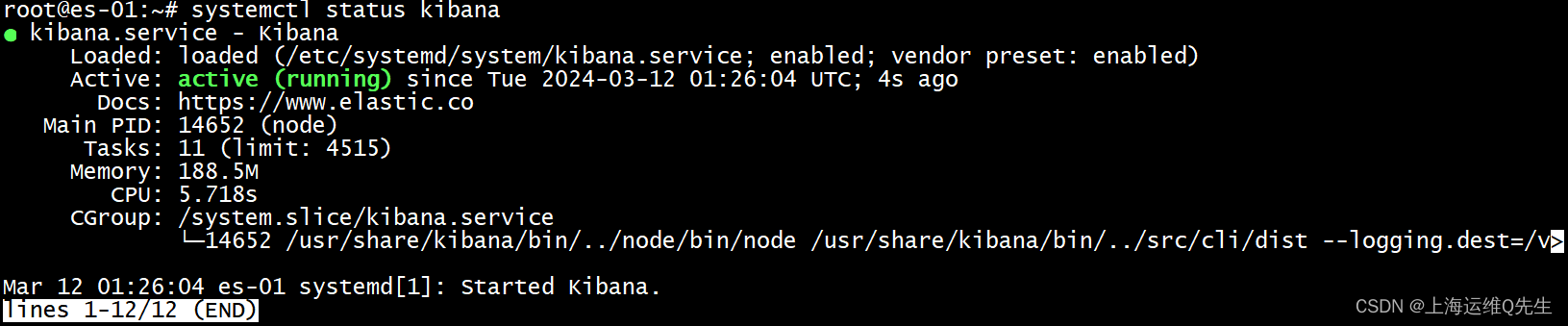
- 确认服务
systemctl status kibana
3. Zookeeper集群部署
3.1 Zookeeper安装
- 下载
官网下载zookeeper3.6.4(https://zookeeper.apache.org/)
https://archive.apache.org/dist/zookeeper/zookeeper-3.6.4/apache-zookeeper-3.6.4-bin.tar.gz
- 安装
zookeeper依赖jdk8,先安装jdk8
apt install openjdk-8-jdk -y
解压缩zookeeper
mkdir /apps
cd /apps
tar xf apache-zookeeper-3.6.4-bin.tar.gz
ln -sf /apps/apache-zookeeper-3.6.4-bin /apps/zookeeper
- 配置修改
cd /apps/zookeeper/conf/
cp zoo_sample.cfg zoo.cfg
修改配置文件
vi /apps/zookeeper/conf/zoo.cfg
# 检查时间间隔
tickTime=2000
# 初始化次数
initLimit=10
# 存活检查次数
syncLimit=5
# 数据目录
dataDir=/data/zookeeper
# 客户端端口
clientPort=2181
# 集群配置 2888数据同步,3888集群选举
server.1=192.168.31.111:2888:3888
server.2=192.168.31.112:2888:3888
server.3=192.168.31.113:2888:3888
创建数据id
mkdir -p /data/zookeeper
echo 1 > /data/zookeeper/myid # 其他节点依次为2和3
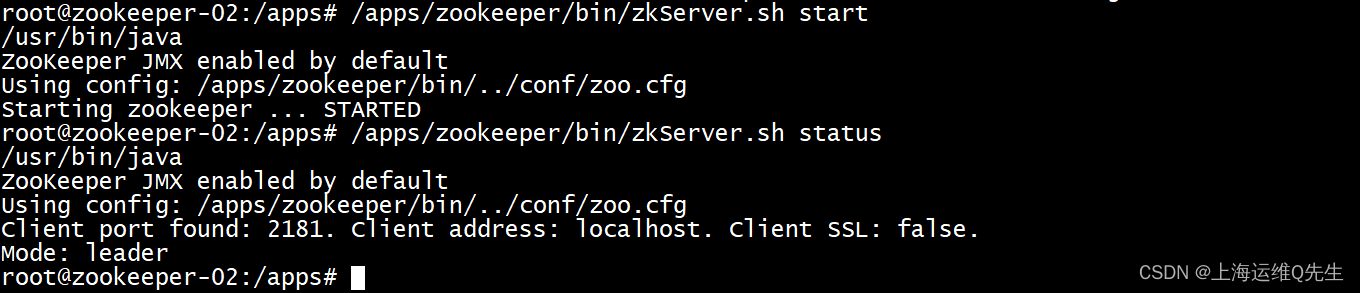
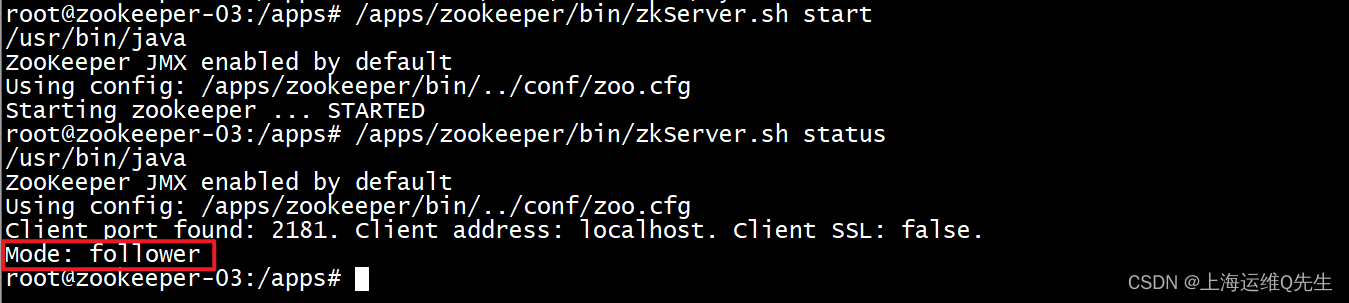
- 启动服务
/apps/zookeeper/bin/zkServer.sh start
5.确认
/apps/zookeeper/bin/zkServer.sh status
确认状态是leader或者是follower
3.2 Kafka安装
1.下载
官网下载kafka(https://zookeeper.apache.org/)
https://dlcdn.apache.org/kafka/3.7.0/kafka_2.13-3.7.0.tgz
- 安装
解压kafka包
tar xf kafka_2.13-3.7.0.tgz
ln -sf /apps/kafka_2.13-3.7.0 /apps/kafka
- 配置修改
cd /apps/kafka/config/
vi server.properties
修改内容
# 节点id保证不重复
broker.id=111
# 本机ip
listeners=PLAINTEXT://192.168.31.111:9092 # 确保每台服务器定义自己的ip
# 日志目录
log.dirs=/data/kafka-logs
# 数据保留时间 默认7天
log.retention.hours=168
# zookeeper集群连接配置
zookeeper.connect=192.168.31.111:2181,192.168.31.112:2181,192.168.31.113:2181
-
启动服务
3台服务器上,以daemon方式启动服务
/apps/kafka/bin/kafka-server-start.sh -daemon /apps/kafka/config/server.properties
- 确认
启动后会监听在9092端口
ss -ntlp|grep 9092

通过offset Explorer
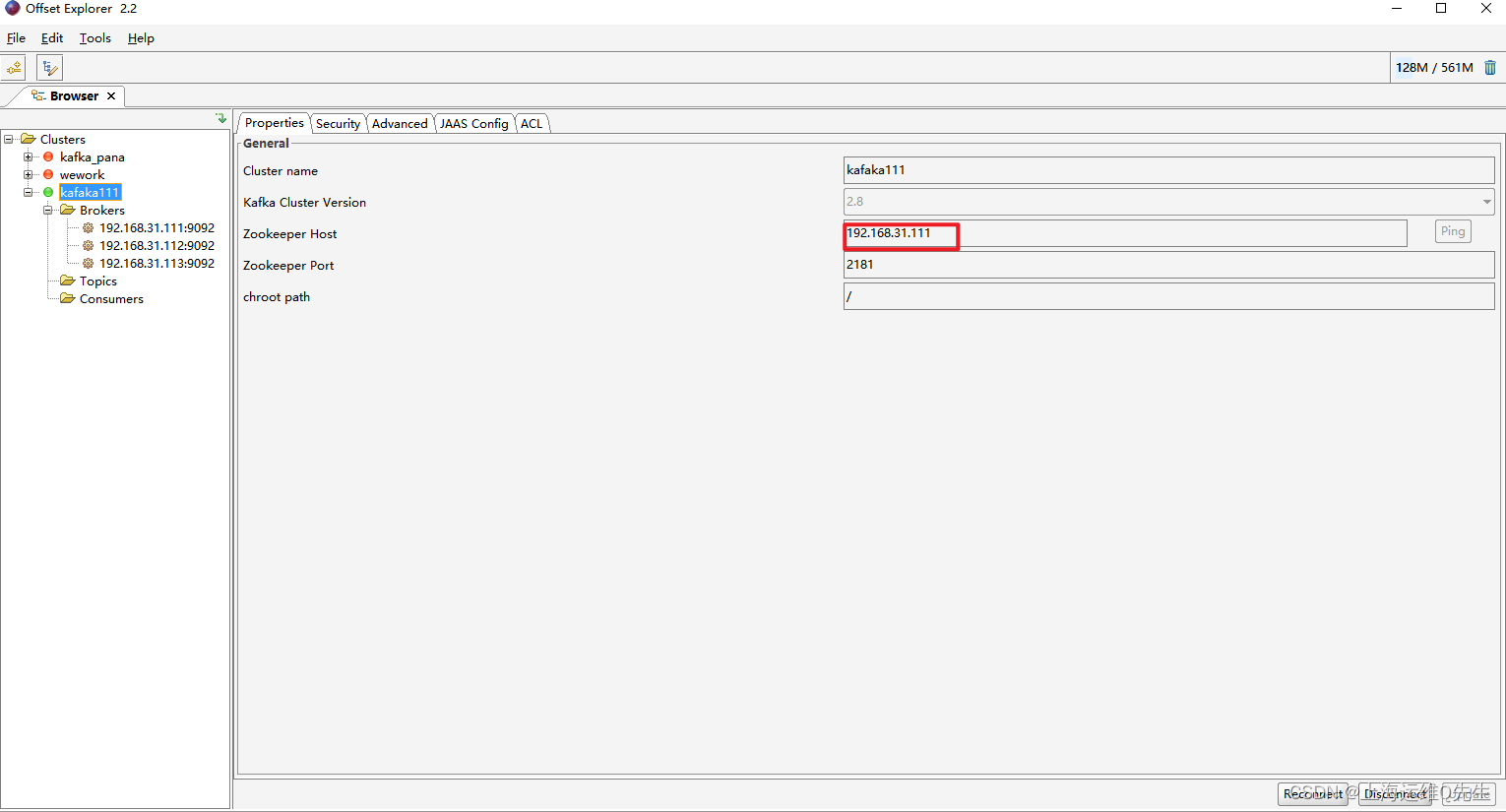
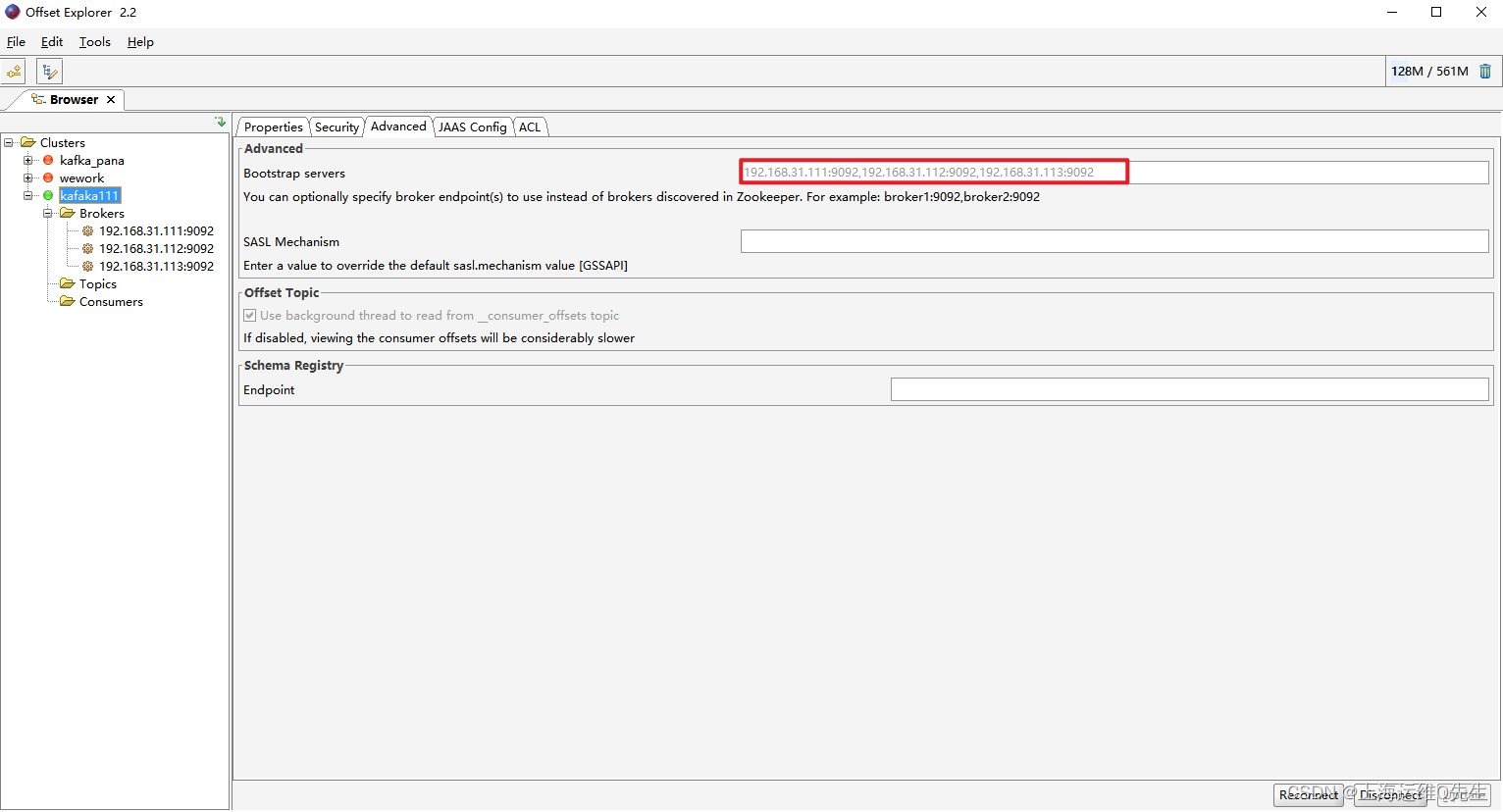
4. Logstash安装
- 下载
logstash-7.12.1-amd64.deb
https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/apt/pool/main/l/logstash/logstash-7.12.1-amd64.deb
- 安装
apt install openjdk-8-jdk -y
dpkg -i logstash-7.12.1-amd64.deb
- 配置修改
vi /etc/logstash/conf.d/daemonset-log-to-es.conf
input {kafka {bootstrap_servers => "192.168.31.111:9092,192.168.31.112:9092,192.168.31.113:9092"topics => ["jsonfile-log-topic"]codec => "json"}
}output {#if [fields][type] == "app1-access-log" {if [type] == "jsonfile-daemonset-applog" {elasticsearch {hosts => ["192.168.31.101:9200","192.168.31.102:9200"]index => "jsonfile-daemonset-applog-%{+YYYY.MM.dd}"}}if [type] == "jsonfile-daemonset-syslog" {elasticsearch {hosts => ["192.168.31.101:9200","192.168.31.102:9200"]index => "jsonfile-daemonset-syslog-%{+YYYY.MM.dd}"}}}
- 启动
systemctl enable --now logstash.service
- 测试
systemctl status logstash.service
5. DaemonSet
5.1 构建镜像
Dockerfile
FROM logstash:7.12.1
USER root
WORKDIR /usr/share/logstash
#RUN rm -rf config/logstash-sample.conf
ADD logstash.yml /usr/share/logstash/config/logstash.yml
ADD logstash.conf /usr/share/logstash/pipeline/logstash.conf
logstash.conf
input {file {#path => "/var/lib/docker/containers/*/*-json.log" #dockerpath => "/var/log/pods/*/*/*.log"start_position => "beginning"type => "jsonfile-daemonset-applog"}file {path => "/var/log/*.log"start_position => "beginning"type => "jsonfile-daemonset-syslog"}
}output {if [type] == "jsonfile-daemonset-applog" {kafka {bootstrap_servers => "${KAFKA_SERVER}"topic_id => "${TOPIC_ID}"batch_size => 16384 #logstash每次向ES传输的数据量大小,单位为字节codec => "${CODEC}" } }if [type] == "jsonfile-daemonset-syslog" {kafka {bootstrap_servers => "${KAFKA_SERVER}"topic_id => "${TOPIC_ID}"batch_size => 16384codec => "${CODEC}" #系统日志不是json格式}}
}
logstash.yml
http.host: "0.0.0.0"
#xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200" ]
构建镜像
nerdctl build -t harbor.panasonic.cn/baseimages/logstash:v7.12.1-json-file-log-v2 .
nerdctl push harbor.panasonic.cn/baseimages/logstash:v7.12.1-json-file-log-v2
5.2 DaemonSet
DaemonSet yaml文件
apiVersion: apps/v1
kind: DaemonSet
metadata:name: logstash-elasticsearchnamespace: kube-systemlabels:k8s-app: logstash-logging
spec:selector:matchLabels:name: logstash-elasticsearchtemplate:metadata:labels:name: logstash-elasticsearchspec:tolerations:# this toleration is to have the daemonset runnable on master nodes# remove it if your masters can't run pods- key: node-role.kubernetes.io/masteroperator: Existseffect: NoSchedulecontainers:- name: logstash-elasticsearchimage: harbor.panasonic.cn/baseimages/logstash:v7.12.1-json-file-log-v1env:- name: "KAFKA_SERVER"value: "192.168.31.111:9092,192.168.31.112:9092,192.168.31.113:9092"- name: "TOPIC_ID"value: "jsonfile-log-topic"- name: "CODEC"value: "json"
# resources:
# limits:
# cpu: 1000m
# memory: 1024Mi
# requests:
# cpu: 500m
# memory: 1024MivolumeMounts:- name: varlog #定义宿主机系统日志挂载路径mountPath: /var/log #宿主机系统日志挂载点- name: varlibdockercontainers #定义容器日志挂载路径,和logstash配置文件中的收集路径保持一直#mountPath: /var/lib/docker/containers #docker挂载路径mountPath: /var/log/pods #containerd挂载路径,此路径与logstash的日志收集路径必须一致readOnly: falseterminationGracePeriodSeconds: 30volumes:- name: varloghostPath:path: /var/log #宿主机系统日志- name: varlibdockercontainershostPath:path: /var/lib/docker/containers #docker的宿主机日志路径path: /var/log/pods #containerd的宿主机日志路径
部署
kubectl apply daemonset.yaml
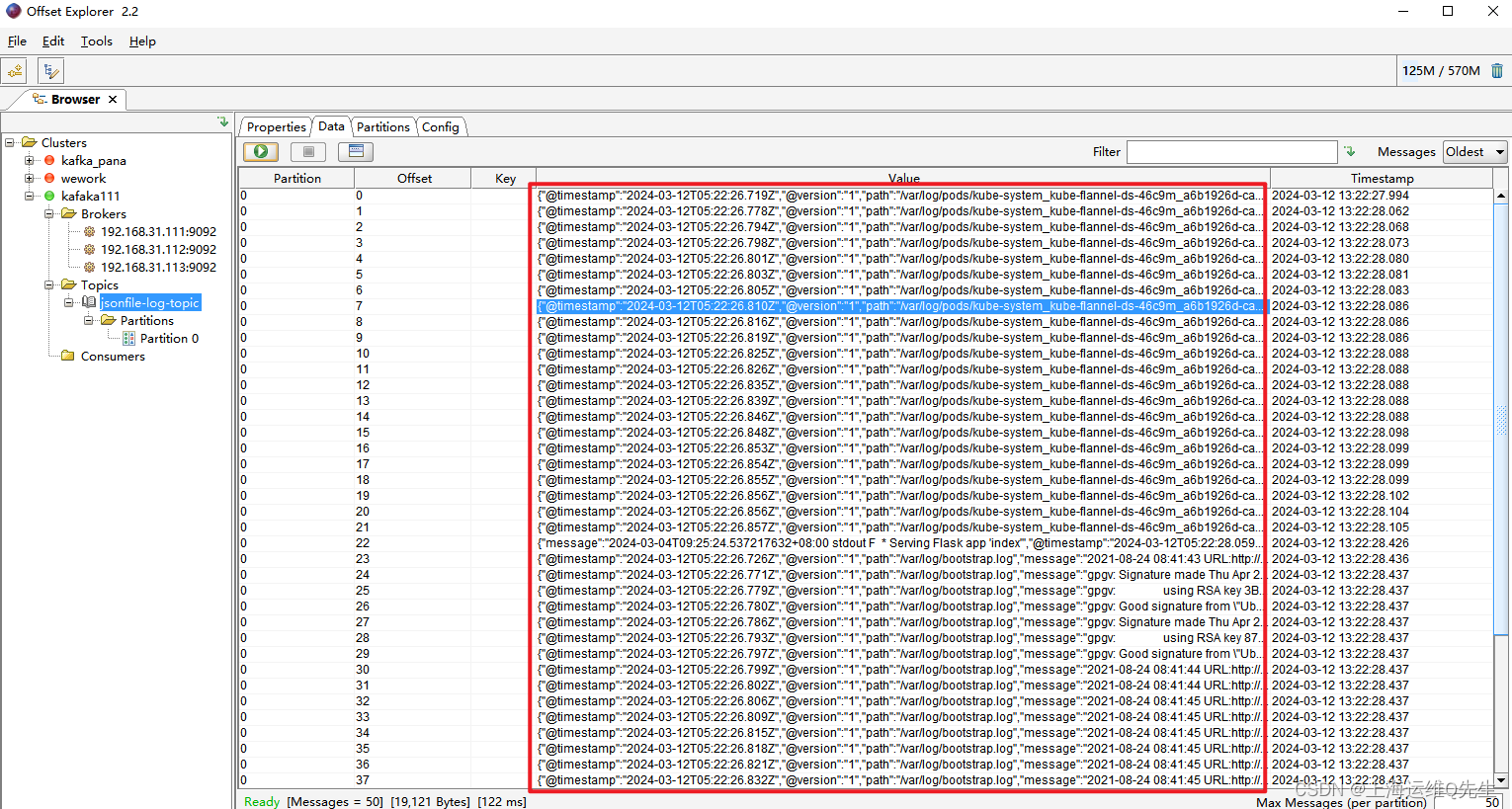
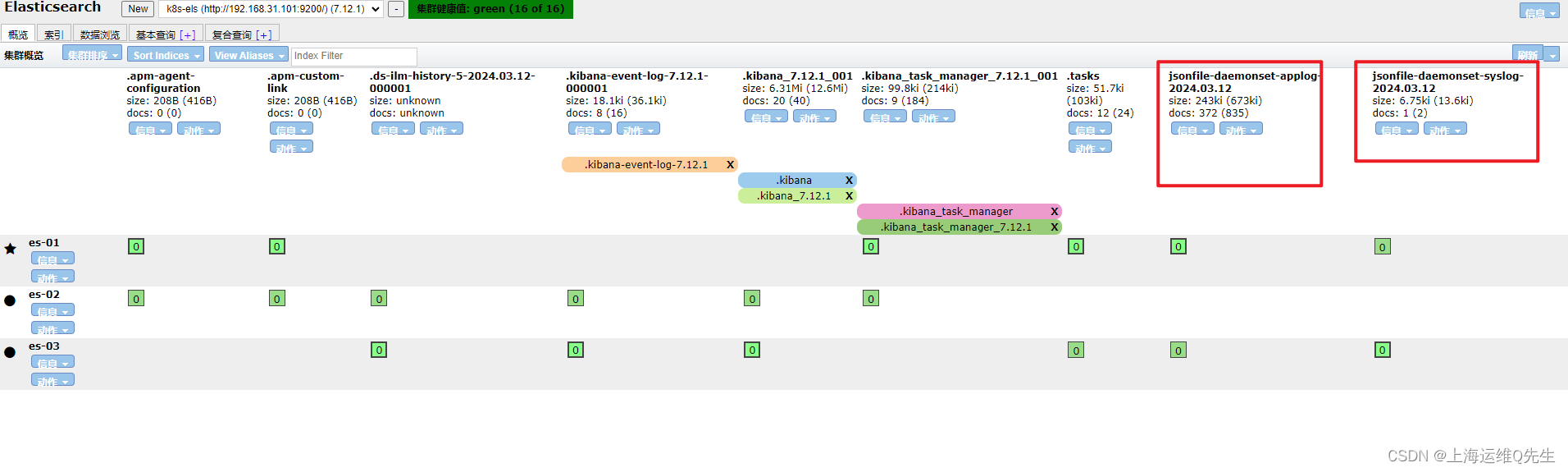
此时在Elasticsearch的dashboard上已经可以看到applog和syslog
配置logstash服务器将日志从kafka抽到es上
vi /etc/logstash/conf.d/daemonset-log-to-es.conf
配置kafka地址和es地址
input {kafka {bootstrap_servers => "192.168.31.111:9092,192.168.31.112:9092,192.168.31.113:9092"topics => ["jsonfile-log-topic"]codec => "json"}
}output {#if [fields][type] == "app1-access-log" {if [type] == "jsonfile-daemonset-applog" {elasticsearch {hosts => ["192.168.31.101:9200","192.168.31.102:9200"]index => "jsonfile-daemonset-applog-%{+YYYY.MM.dd}"}}if [type] == "jsonfile-daemonset-syslog" {elasticsearch {hosts => ["192.168.31.101:9200","192.168.31.102:9200"]index => "jsonfile-daemonset-syslog-%{+YYYY.MM.dd}"}}}
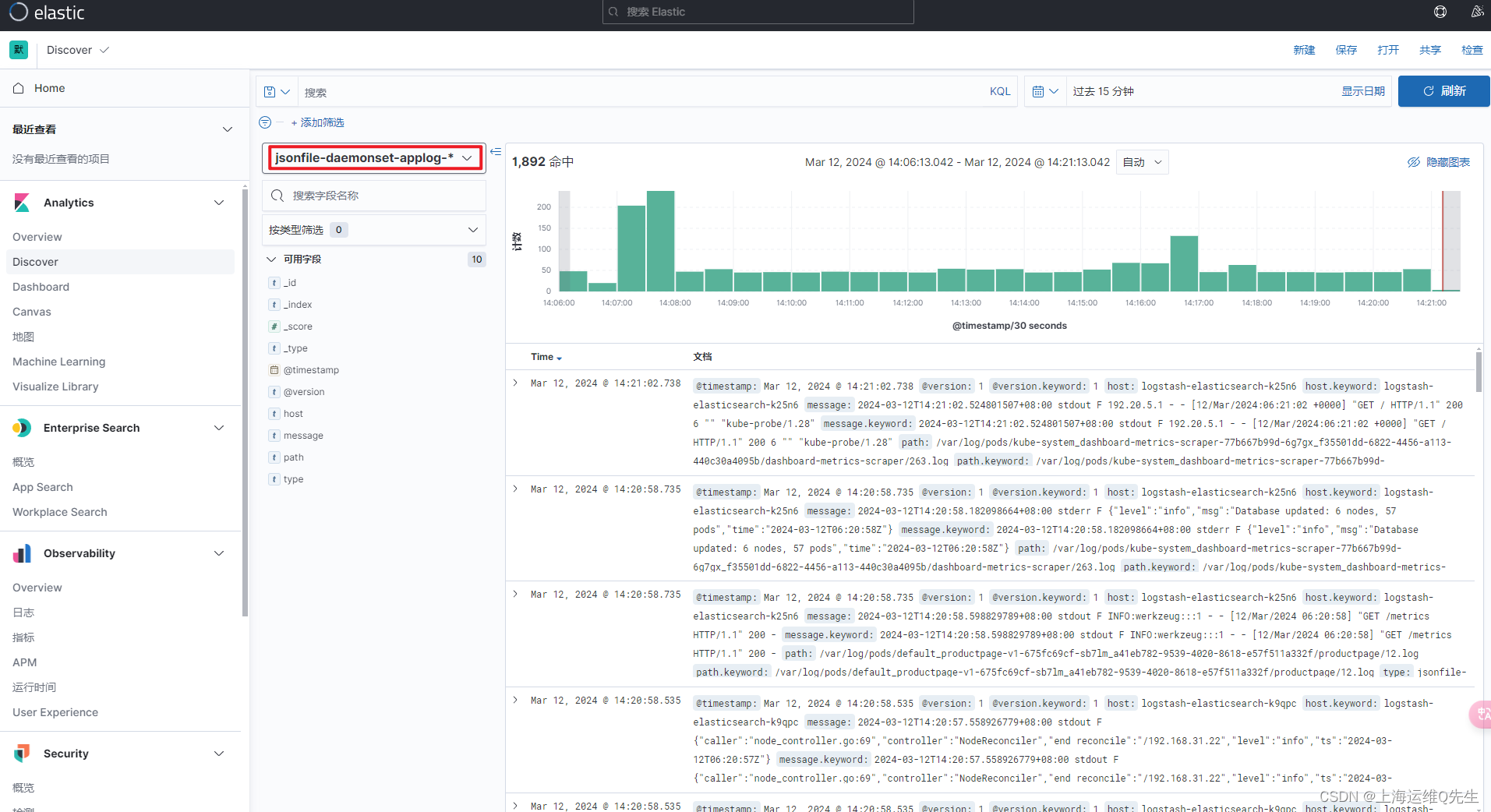
重启服务后可以在es服务器上看到相关数据
相关内容也符合我们的预期
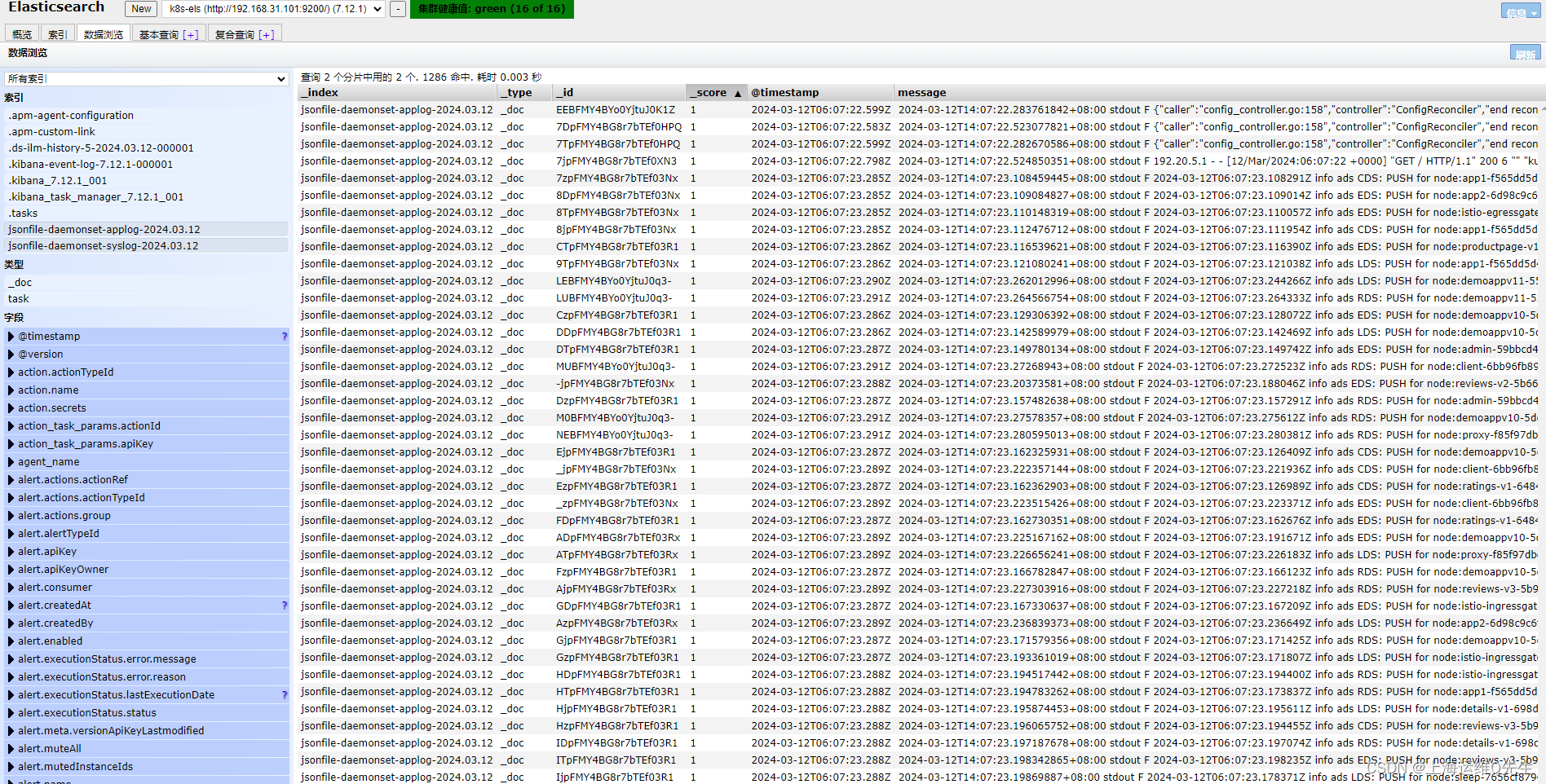
手动加入一段日志
root@k8s-master01# echo 'test-20240312-14:13' >> /var/log/dpkg.log
日志也出现在els中
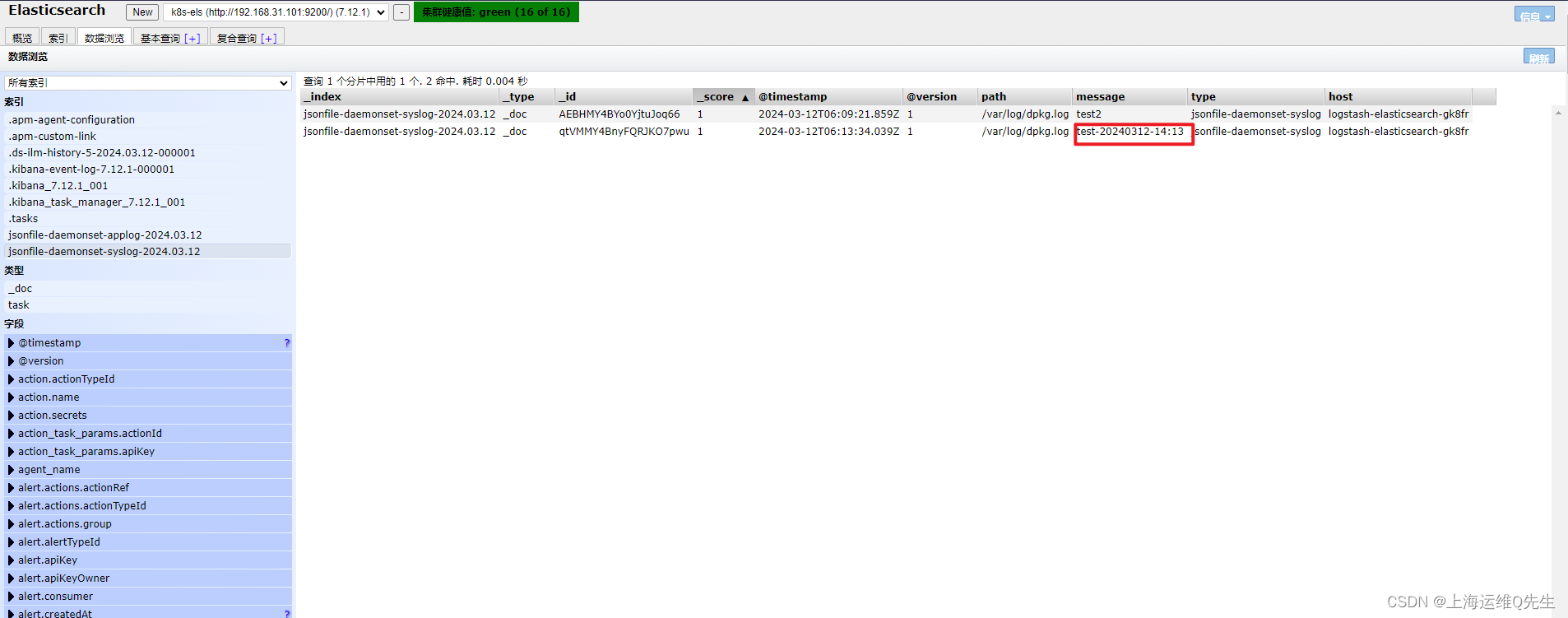
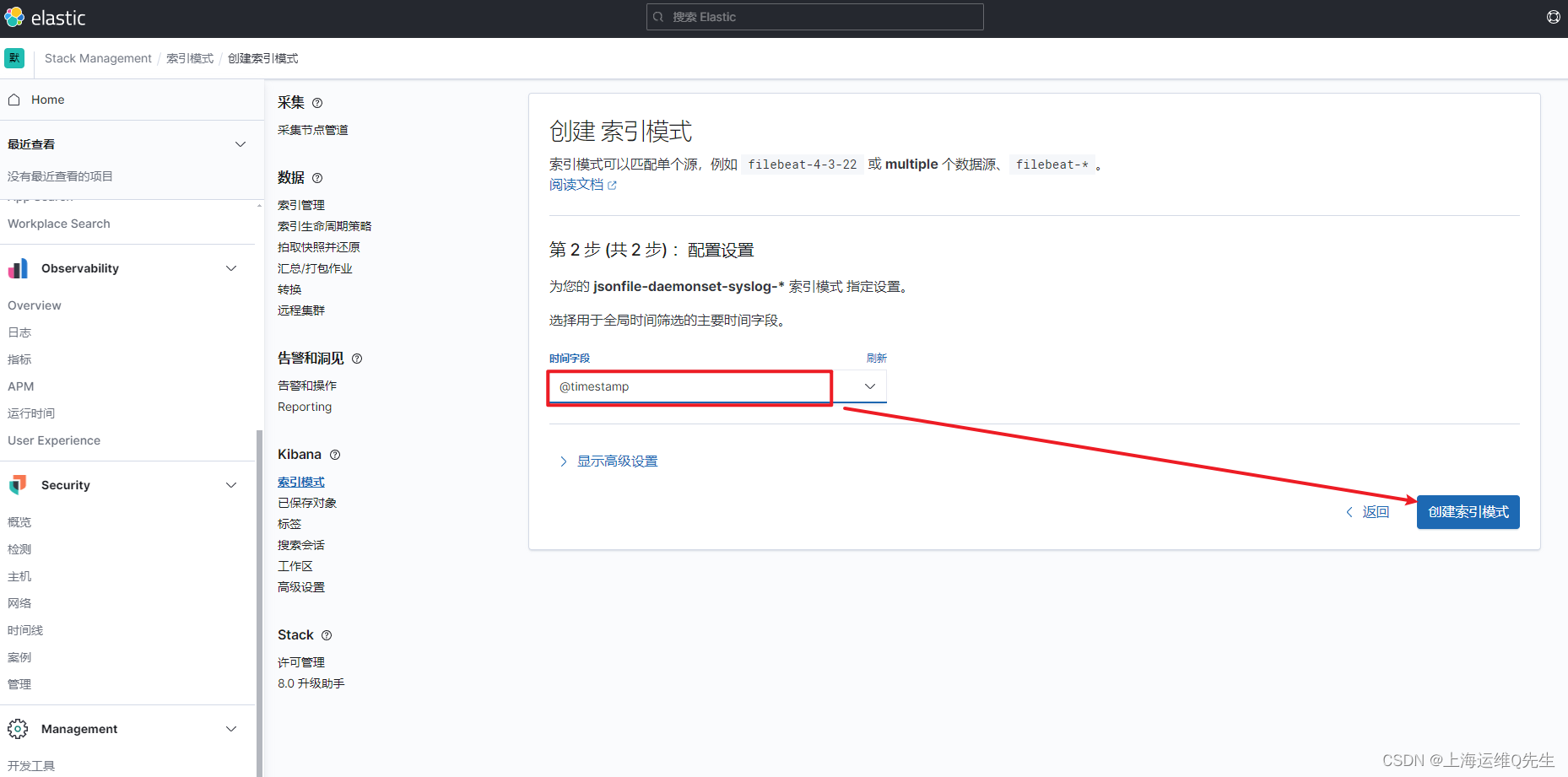
es服务器上创建syslog索引
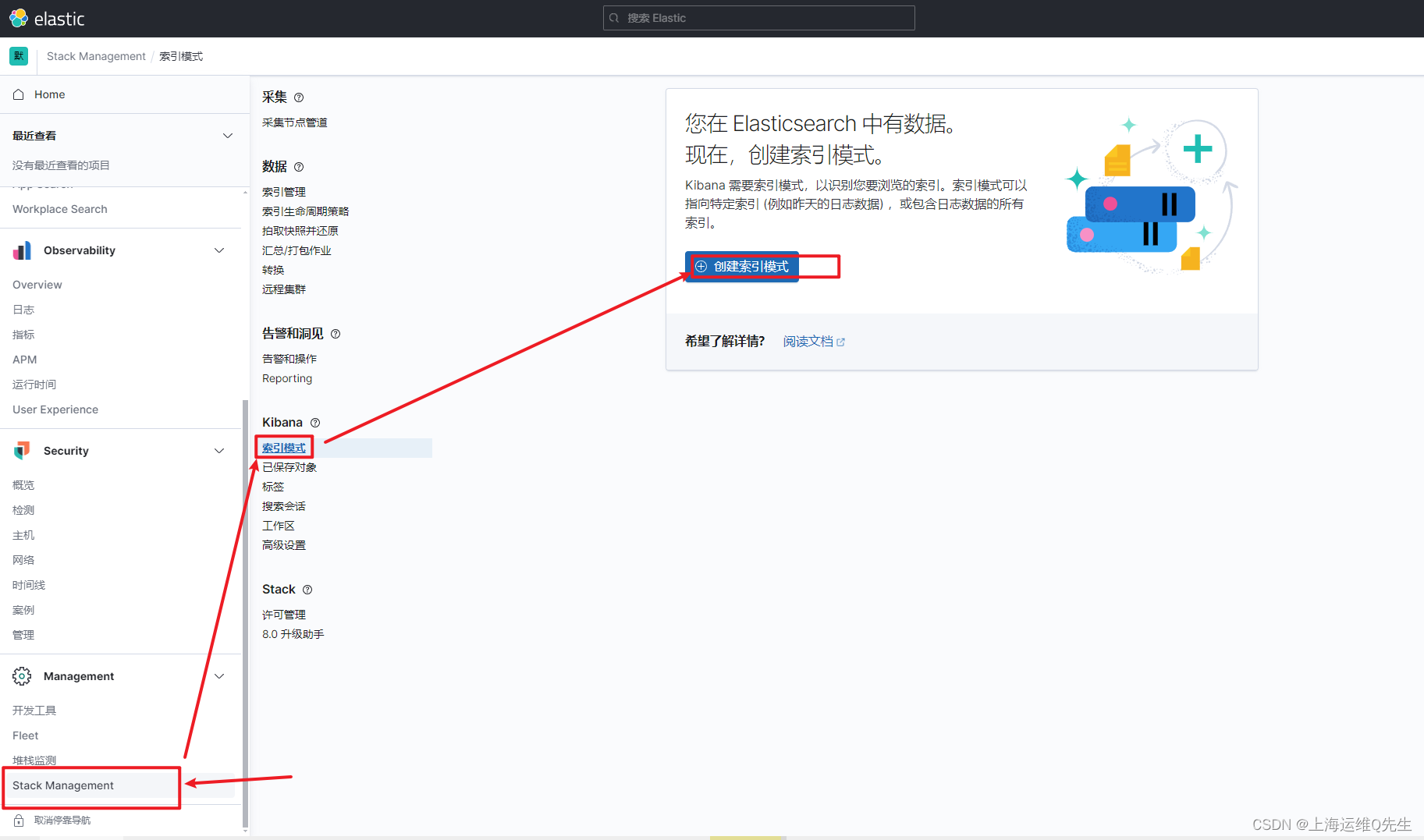
日志前缀加*匹配日志
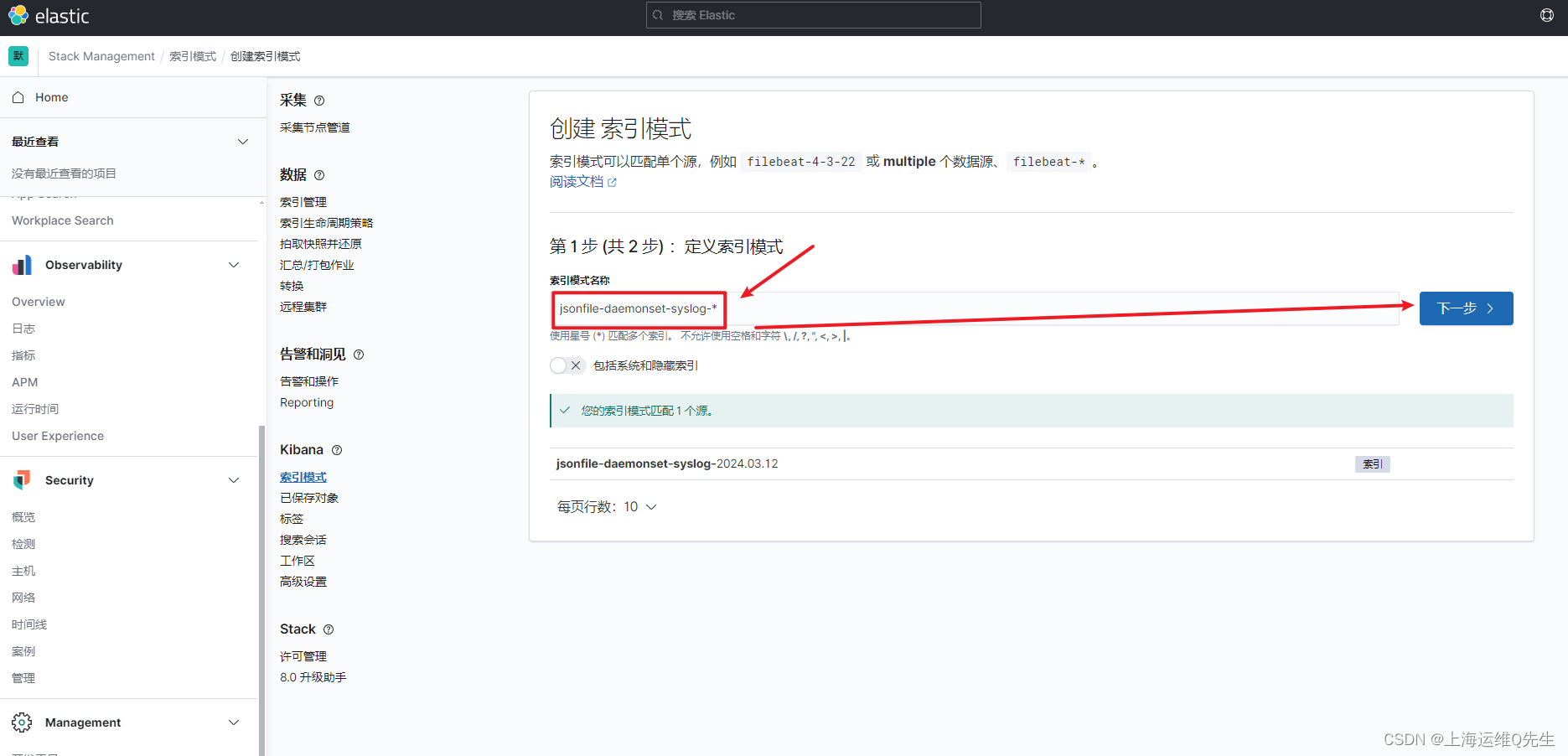
选择timestramp
同样,再次创建applog
6. SideCar
6.1 构建镜像
dockerfile
FROM logstash:7.12.1USER root
WORKDIR /usr/share/logstash
#RUN rm -rf config/logstash-sample.conf
ADD logstash.yml /usr/share/logstash/config/logstash.yml
ADD logstash.conf /usr/share/logstash/pipeline/logstash.conf
logstash.conf
input {file {path => "/var/log/applog/catalina.out"start_position => "beginning"type => "app1-sidecar-catalina-log"}file {path => "/var/log/applog/localhost_access_log.*.txt"start_position => "beginning"type => "app1-sidecar-access-log"}
}output {if [type] == "app1-sidecar-catalina-log" {kafka {bootstrap_servers => "${KAFKA_SERVER}"topic_id => "${TOPIC_ID}"batch_size => 16384 #logstash每次向ES传输的数据量大小,单位为字节codec => "${CODEC}" } }if [type] == "app1-sidecar-access-log" {kafka {bootstrap_servers => "${KAFKA_SERVER}"topic_id => "${TOPIC_ID}"batch_size => 16384codec => "${CODEC}"} }
}
logstash.yml
http.host: "0.0.0.0"
#xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200"
build-commond.sh
#!/bin/bash#docker build -t harbor.magedu.local/baseimages/logstash:v7.12.1-sidecar .#docker push harbor.magedu.local/baseimages/logstash:v7.12.1-sidecar
nerdctl build -t harbor.panasonic.cn/baseimages/logstash:v7.12.1-sidecar .
nerdctl push harbor.panasonic.cn/baseimages/logstash:v7.12.1-sidecar
6.2 SideCar
tomcat-app1.yaml
kind: Deployment
apiVersion: apps/v1
metadata:labels:app: pana-tomcat-app1-deployment-labelname: pana-tomcat-app1-deployment #当前版本的deployment 名称namespace: pana
spec:replicas: 3selector:matchLabels:app: pana-tomcat-app1-selectortemplate:metadata:labels:app: pana-tomcat-app1-selectorspec:containers:- name: sidecar-containerimage: harbor.panasonic.cn/baseimages/logstash:v7.12.1-sidecarimagePullPolicy: IfNotPresent#imagePullPolicy: Alwaysenv:- name: "KAFKA_SERVER"value: "192.168.31.111:9092,192.168.31.112:9092,192.168.31.113:9092"- name: "TOPIC_ID"value: "tomcat-app1-topic"- name: "CODEC"value: "json"volumeMounts:- name: applogsmountPath: /var/log/applog- name: pana-tomcat-app1-containerimage: registry.cn-hangzhou.aliyuncs.com/zhangshijie/tomcat-app1:v1imagePullPolicy: IfNotPresent#imagePullPolicy: Alwaysports:- containerPort: 8080protocol: TCPname: httpenv:- name: "password"value: "123456"- name: "age"value: "18"resources:limits:cpu: 1memory: "512Mi"requests:cpu: 500mmemory: "512Mi"volumeMounts:- name: applogsmountPath: /apps/tomcat/logsstartupProbe:httpGet:path: /myapp/index.htmlport: 8080initialDelaySeconds: 5 #首次检测延迟5sfailureThreshold: 3 #从成功转为失败的次数periodSeconds: 3 #探测间隔周期readinessProbe:httpGet:#path: /monitor/monitor.htmlpath: /myapp/index.htmlport: 8080initialDelaySeconds: 5periodSeconds: 3timeoutSeconds: 5successThreshold: 1failureThreshold: 3livenessProbe:httpGet:#path: /monitor/monitor.htmlpath: /myapp/index.htmlport: 8080initialDelaySeconds: 5periodSeconds: 3timeoutSeconds: 5successThreshold: 1failureThreshold: 3volumes:- name: applogs #定义通过emptyDir实现业务容器与sidecar容器的日志共享,以让sidecar收集业务容器中的日志emptyDir: {}
tomcat-service.yaml
---
kind: Service
apiVersion: v1
metadata:labels:app: pana-tomcat-app1-service-labelname: pana-tomcat-app1-servicenamespace: pana
spec:type: NodePortports:- name: httpport: 80protocol: TCPtargetPort: 8080nodePort: 40080selector:app: pana-tomcat-app1-selector
sidecar.conf
input {kafka {bootstrap_servers => "192.168.31.111:9092,192.168.31.112:9092,192.168.31.113:9092"topics => ["tomcat-app1-topic"]codec => "json"}
}output {#if [fields][type] == "app1-access-log" {if [type] == "app1-sidecar-access-log" {elasticsearch {hosts => ["192.168.31.101:9200","192.168.31.102:9200"]index => "sidecar-app1-accesslog-%{+YYYY.MM.dd}"}}#if [fields][type] == "app1-catalina-log" {if [type] == "app1-sidecar-catalina-log" {elasticsearch {hosts => ["192.168.31.101:9200","192.168.31.102:9200"]index => "sidecar-app1-catalinalog-%{+YYYY.MM.dd}"}}
# stdout {
# codec => rubydebug
# }
}
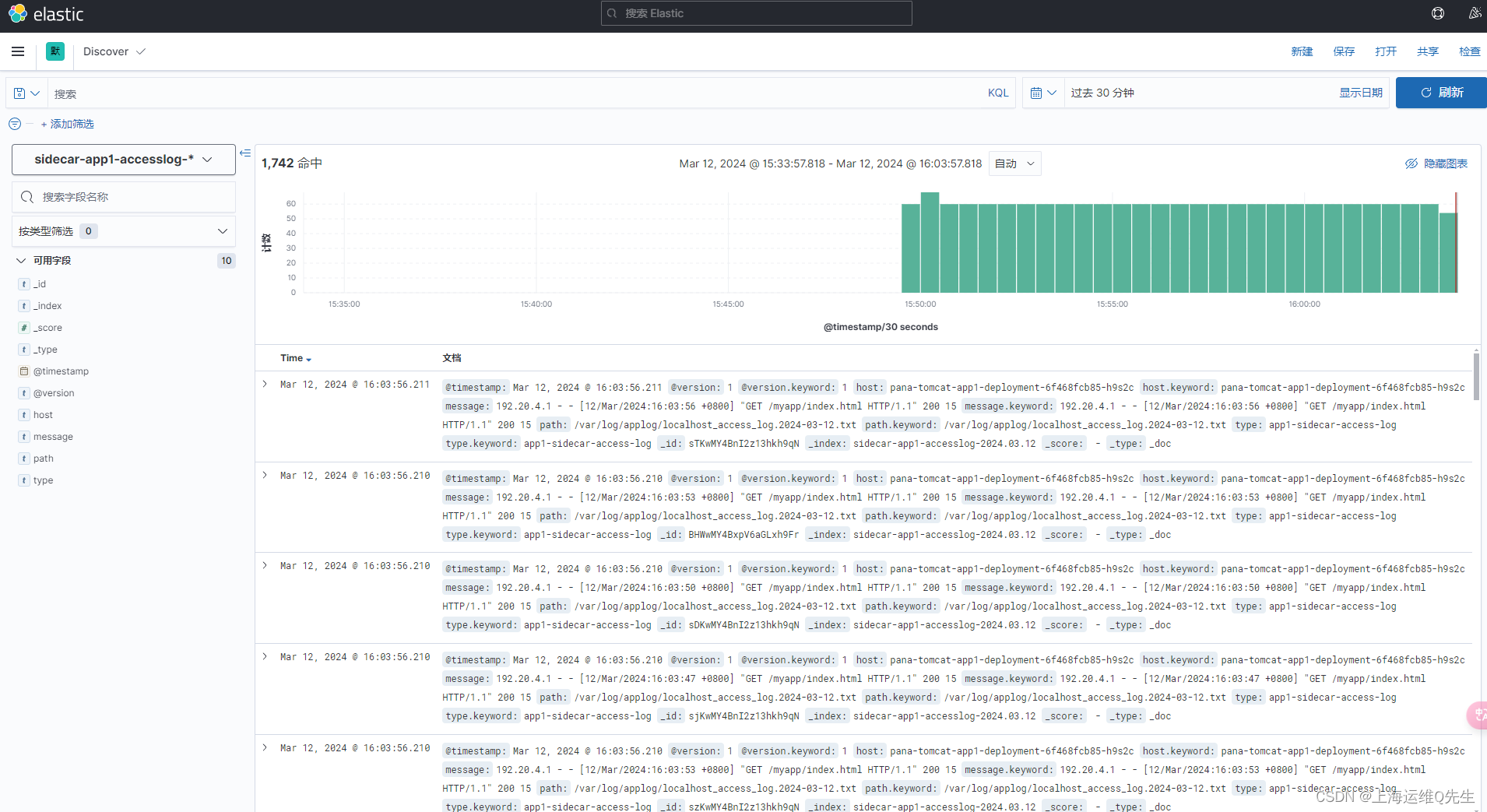
7. 容器镜像中安装filebeat
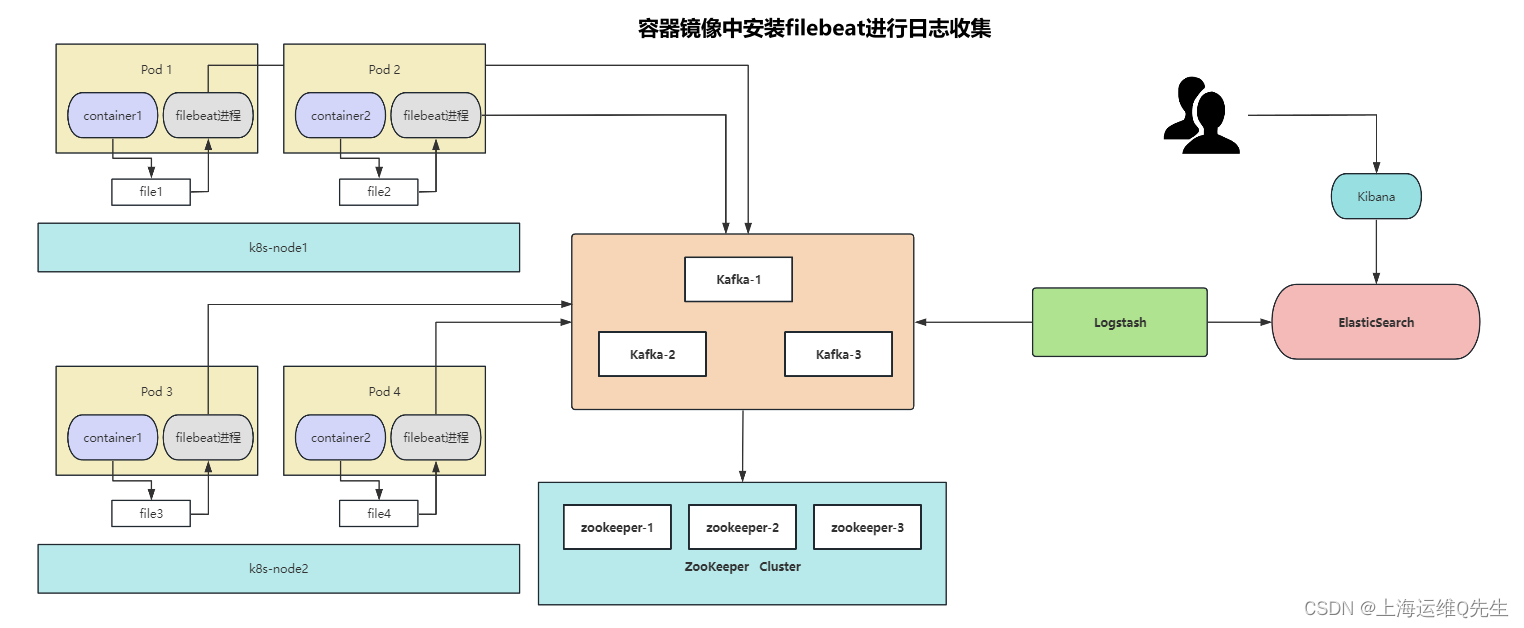
7.1 镜像制作
1.Dockerfile
filebeat-7.12.1-amd64.deb 从清华镜像源获取 https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/apt/pool/main/f/filebeat/
#tomcat web1
FROM tomcat:8.5.99-jdk8ADD filebeat-7.12.1-amd64.deb /tmp/
RUN dpkg -i /tmp/filebeat-7.12.1-amd64.deb && rm -f /tmp/filebeat-7.12.1-amd64.deb
ADD catalina.sh /usr/local/tomcat/bin/catalina.sh
ADD server.xml /usr/local/tomcat/conf/server.xml
ADD myapp.tar.gz /usr/local/tomcat/webapps/myapp/
ADD run_tomcat.sh /usr/local/tomcat/bin/run_tomcat.sh
ADD filebeat.yml /etc/filebeat/filebeat.yml
ADD sources.list /etc/apt/sources.listEXPOSE 8080 8443CMD ["/usr/local/tomcat/bin/run_tomcat.sh"]
run_tomcat.sh
#!/bin/bash
/usr/share/filebeat/bin/filebeat -e -c /etc/filebeat/filebeat.yml -path.home /usr/share/filebeat -path.config /etc/filebeat -path.data /var/lib/filebeat -path.logs /var/log/filebeat &
/usr/local/tomcat/bin/catalina.sh start
tail -f /etc/hosts
server.xml
<Host name="localhost" appBase="/usr/local/tomcat/webapps" unpackWARs="false" autoDeploy="false">
镜像制作
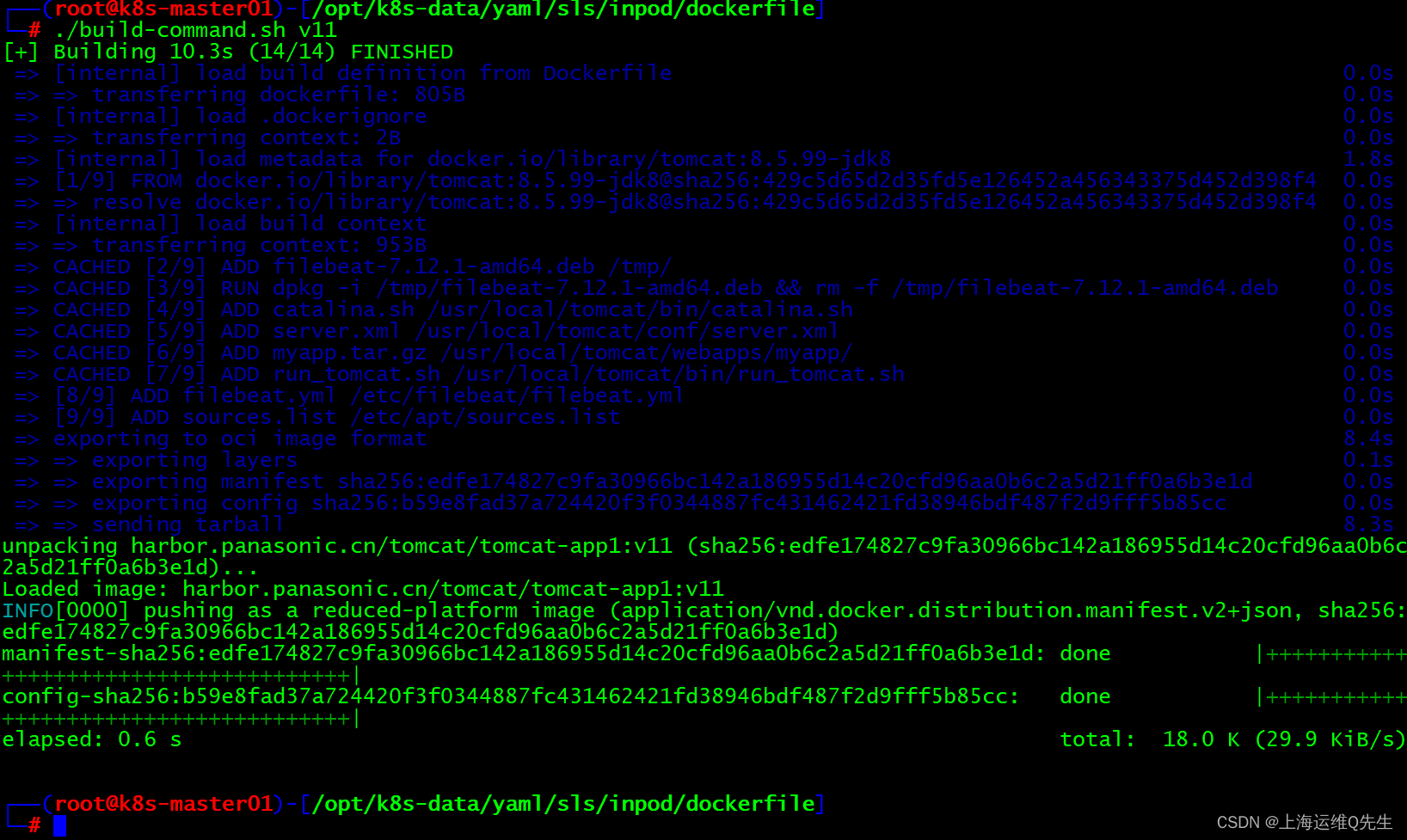
7.2 服务创建
- serviceaccount
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: filebeat-serviceaccount-clusterrolelabels:k8s-app: filebeat-serviceaccount-clusterrole
rules:
- apiGroups: [""] # "" indicates the core API groupresources:- namespaces- pods- nodesverbs:- get- watch- list---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: filebeat-serviceaccount-clusterrolebinding
subjects:
- kind: ServiceAccountname: defaultnamespace: pana
roleRef:kind: ClusterRolename: filebeat-serviceaccount-clusterroleapiGroup: rbac.authorization.k8s.io
- deployment
kind: Deployment
apiVersion: apps/v1
metadata:labels:app: pana-tomcat-app1-filebeat-deployment-labelname: pana-tomcat-app1-filebeat-deploymentnamespace: pana
spec:replicas: 2selector:matchLabels:app: pana-tomcat-app1-filebeat-selectortemplate:metadata:labels:app: pana-tomcat-app1-filebeat-selectorspec:containers:- name: pana-tomcat-app1-filebeat-containerimage: harbor.panasonic.cn/tomcat/tomcat-app1:v11imagePullPolicy: IfNotPresentports:- containerPort: 8080protocol: TCPname: httpenv:- name: "password"value: "123456"- name: "age"value: "18"resources:limits:cpu: 1memory: "512Mi"requests:cpu: 500mmemory: "512Mi"
- service
---
kind: Service
apiVersion: v1
metadata:labels:app: pana-tomcat-app1-filebeat-service-labelname: pana-tomcat-app1-filebeat-servicenamespace: pana
spec:type: NodePortports:- name: httpport: 80protocol: TCPtargetPort: 8080nodePort: 30092selector:app: pana-tomcat-app1-filebeat-selector
kubectl apply -f *.yaml
7.3 logstash配置
input {kafka {bootstrap_servers => "192.168.31.111:9092,192.168.31.112:9092,192.168.31.113:9092"topics => ["filebeat-tomcat-app1"]codec => "json"}
}output {if [fields][type] == "filebeat-tomcat-catalina" {elasticsearch {hosts => ["192.168.31.101:9200","192.168.31.102:9200"]index => "filebeat-tomcat-catalina-%{+YYYY.MM.dd}"}}if [fields][type] == "filebeat-tomcat-accesslog" {elasticsearch {hosts => ["192.168.31.101:9200","192.168.31.102:9200"]index => "filebeat-tomcat-accesslog-%{+YYYY.MM.dd}"}}
}
重启logstash服务
systemctl restart logstash
7.4 sls日志查询
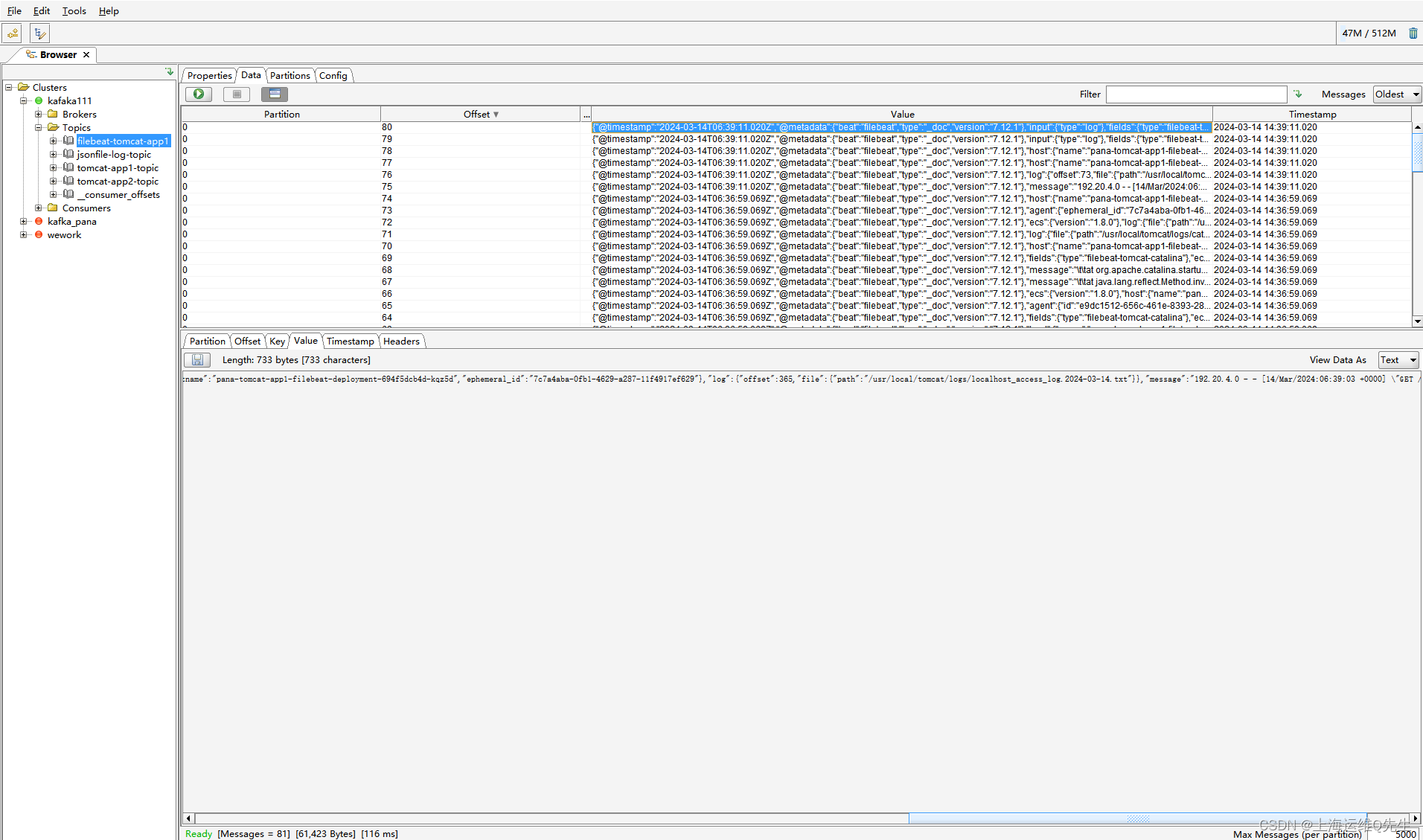
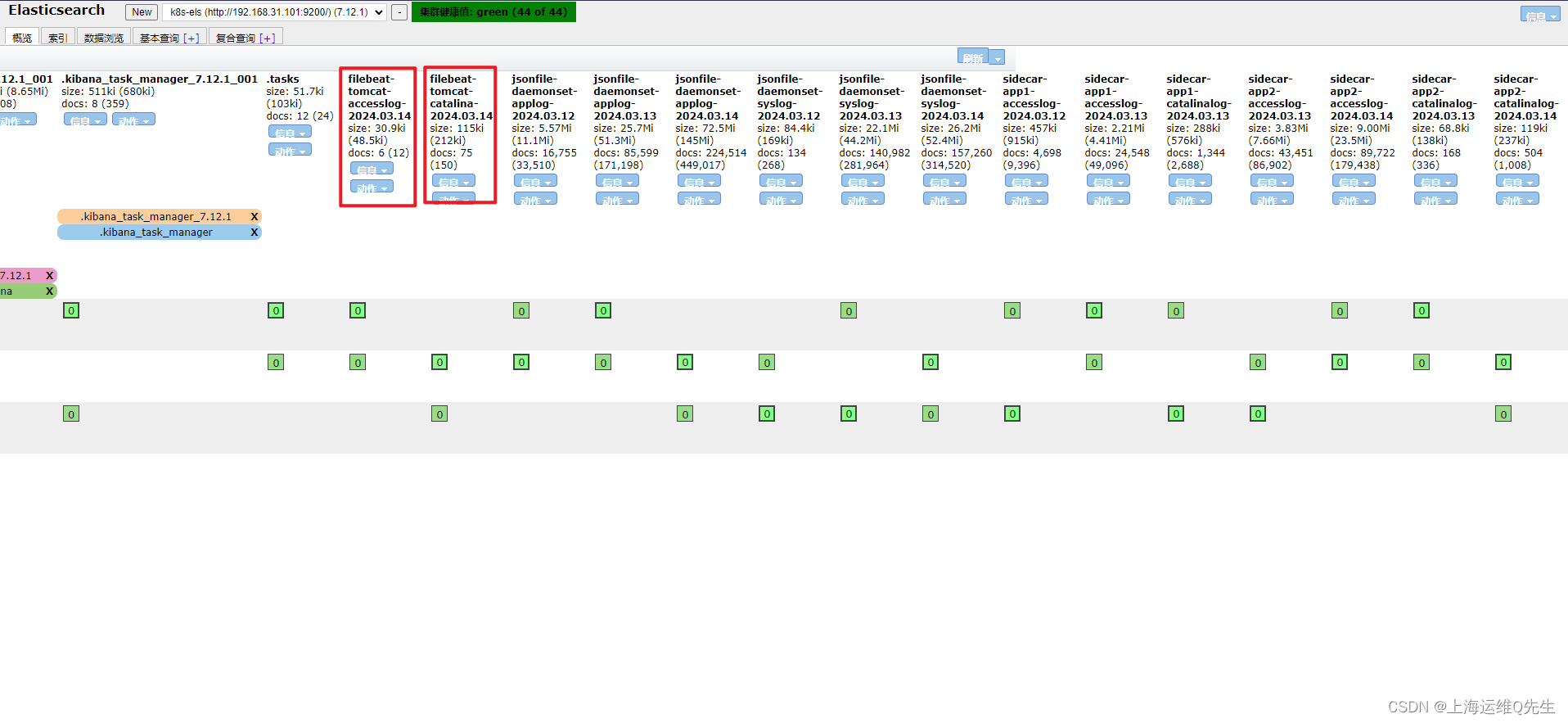
相关文章:
ELK日志管理实现的3种常见方法
ELK日志管理实现的3种常见方法 1. 日志收集方法 1.1 使用DaemonSet方式日志收集 通过将node节点的/var/log/pods目录挂载给以DaemonSet方式部署的logstash来读取容器日志,并将日志吐给kafka并分布写入Zookeeper数据库.再使用logstash将Zookeeper中的数据写入ES,并通过kibana…...

深度强化学习01
Random variable Probability Density Function 期望 Random Sampling 学习视频 这绝对是我看过最好的深度强化学习!从入门到实战,7小时内干货不断!_哔哩哔哩_bilibili...
C++ 智能指针的使用
智能指针类型 在C程序中,普通变量使用栈内存,为函数运行时专用,结束后会自动释放,无须考虑内存释放问题。 但堆内存是共用的,其使用是通过指针变量的new来分配,使用delete来释放,因指针使用方便…...
Flutter 核心原理 - UI 框架(UI Framework)
Flutter 既能保证很高的开发效率,又能获得很好的性能。 这两年 Flutter 技术热度持续提高,整个 Flutter 生态和社区也发生了翻天覆地的变化。目前Flutter 稳定版发布到了3.0,现在已经支持移动端、Web端和PC端,通过Flutter 开发的…...

Hive优化
工作中涉及到优化部分不多,下面的一些方案可能会缺少实际项目支撑,这里主要是为了完备一下知识体系。 参考的hive参数管理文档地址:https://cwiki.apache.org/confluence/display/Hive/ConfigurationProperties 对于Hive优化,可以…...

React 的 diff 算法
React 的 diff 算法的演进。 在 React 16 之前,React 使用的是称为 Reconciliation 的 diff 算法。Reconciliation 算法通过递归地比较新旧虚拟 DOM 树的每个节点,找出节点的差异,并将这些差异应用到实际的 DOM 上。整个过程是递归的&#x…...
综合知识篇07-软件架构设计考点(2024年软考高级系统架构设计师冲刺知识点总结系列文章)
专栏系列文章: 2024高级系统架构设计师备考资料(高频考点&真题&经验)https://blog.csdn.net/seeker1994/category_12593400.html案例分析篇00-【历年案例分析真题考点汇总】与【专栏文章案例分析高频考点目录】(2024年软考高级系统架构设计师冲刺知识点总结-案例…...
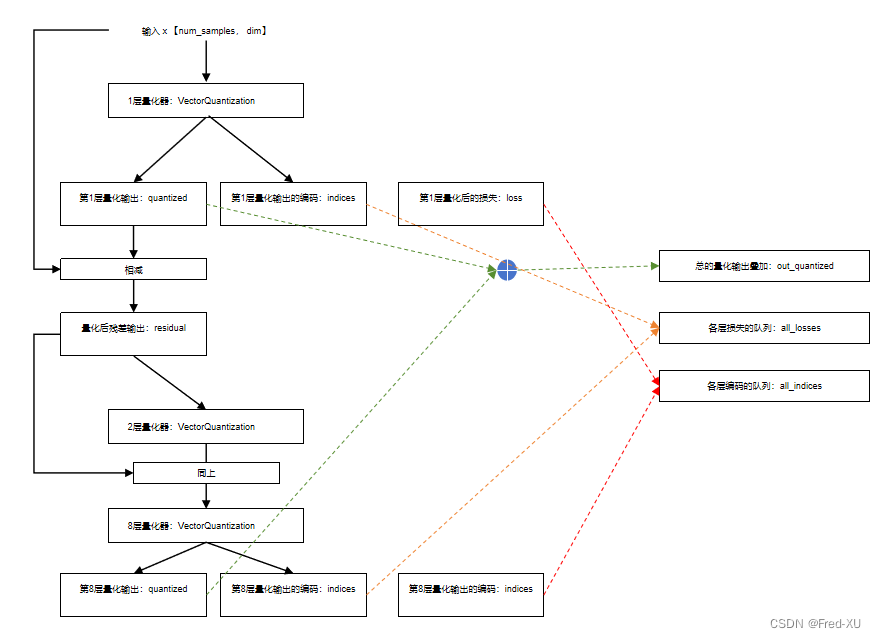
【GPT-SOVITS-05】SOVITS 模块-残差量化解析
说明:该系列文章从本人知乎账号迁入,主要原因是知乎图片附件过于模糊。 知乎专栏地址: 语音生成专栏 系列文章地址: 【GPT-SOVITS-01】源码梳理 【GPT-SOVITS-02】GPT模块解析 【GPT-SOVITS-03】SOVITS 模块-生成模型解析 【G…...

Flutter第四弹:Flutter图形渲染性能
目标: 1)Flutter图形渲染性能能够媲美原生? 2)Flutter性能优于React Native? 一、Flutter图形渲染原理 1.1 Flutter图形渲染原理 Flutter直接调用Skia。 Flutter不使用WebView,也不使用操作系统的原生控件,而是…...
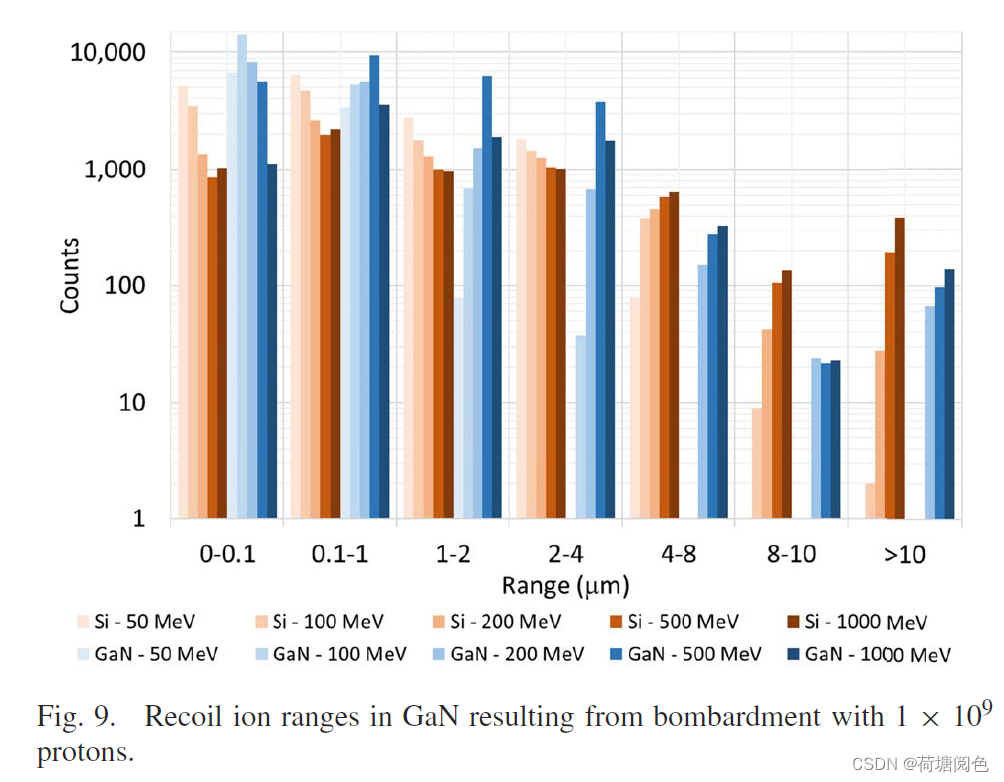
[氮化镓]GaN中质子反冲离子的LET和射程特性
这篇文件是一篇关于氮化镓(GaN)中质子反冲离子的线性能量转移(LET)和射程特性的研究论文,发表在《IEEE Transactions on Nuclear Science》2021年5月的期刊上。论文的主要内容包括: 研究背景:氮…...
【项目】C++ 基于多设计模式下的同步异步日志系统
前言 一般而言,业务的服务都是周而复始的运行,当程序出现某些问题时,程序员要能够进行快速的修复,而修复的前提是要能够先定位问题。 因此为了能够更快的定位问题,我们可以在程序运行过程中记录一些日志,通…...

安卓国产百度网盘与国外云盘软件onedrive对比
我更愿意使用国外软件公司的产品,而不是使用国内百度等制作的流氓软件。使用这些国产软件让我不放心,他们占用我的设备大量空间,在我的设备上推送运行各种无用的垃圾功能。瞒着我,做一些我不知道的事情。 百度网盘安装包大小&…...

健身·健康行业Web3新尝试:MATCHI
随着区块链技术进入主流,web3 运动已经开始彻底改变互联网,改写从游戏到金融再到艺术的行业规则。现在,MATCHI的使命是颠覆健身行业。 MATCHI是全球首个基于Web3的在线舞蹈健身游戏和全球首个Web3舞蹈游戏的发起者,注册于新加坡&a…...

VB.NET高级面试题:什么是 VB.NET?与 Visual Basic 6.0 相比有哪些主要区别?
什么是 VB.NET?与 Visual Basic 6.0 相比有哪些主要区别? VB.NET是一种面向对象的编程语言,是微软公司推出的.NET平台上的一种编程语言,用于构建Windows应用程序、Web应用程序和Web服务等。它是Visual Basic的后续版本࿰…...
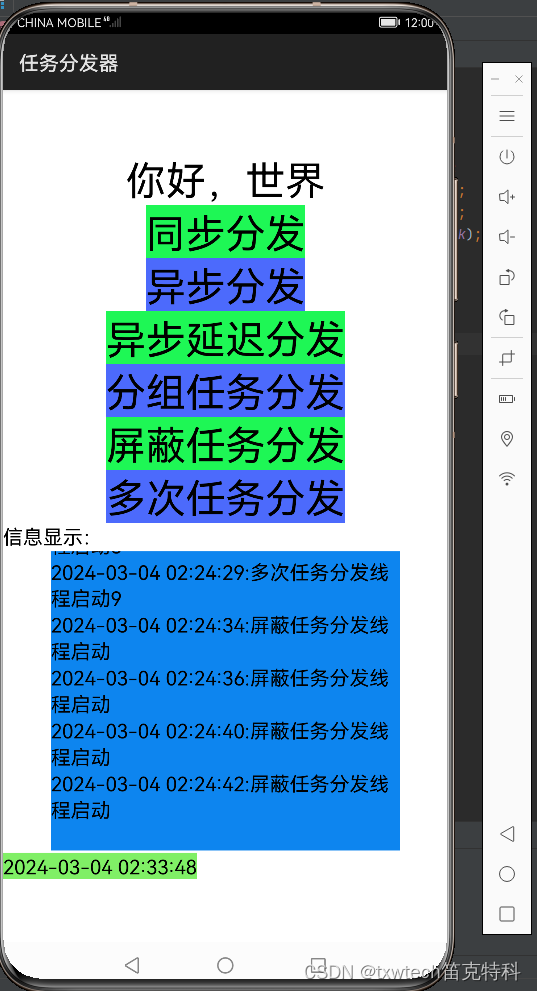
30.HarmonyOS App(JAVA)鸿蒙系统app多线程任务分发器
HarmonyOS App(JAVA)多线程任务分发器 打印时间,记录到编辑框textfield信息显示 同步分发,异步分发,异步延迟分发,分组任务分发,屏蔽任务分发,多次任务分发 参考代码注释 场景介绍 如果应用的业务逻辑比…...

伺服电机编码器的分辨率指得是什么?
伺服电机编码器的分辨率是伺服电机编码器的重要参数。 一般来说,具体的伺服电机编码器型号可以找到对应的分辨率值。 伺服电机编码器的分辨率和精度不同,但也有一定的关系。 伺服电机编码器的分辨率是多少? 1、伺服编码器(同步伺…...

WPF中使用LiveCharts绘制散点图
一、背景 这里的代码使用MVVM模式进行编写 二、Model public class DataPoint{public double X { get; set; }public double Y { get; set; }} 三、ViewModel public class ScatterChartViewModel{public SeriesCollection Series { get; set; }public ScatterChartViewMod…...
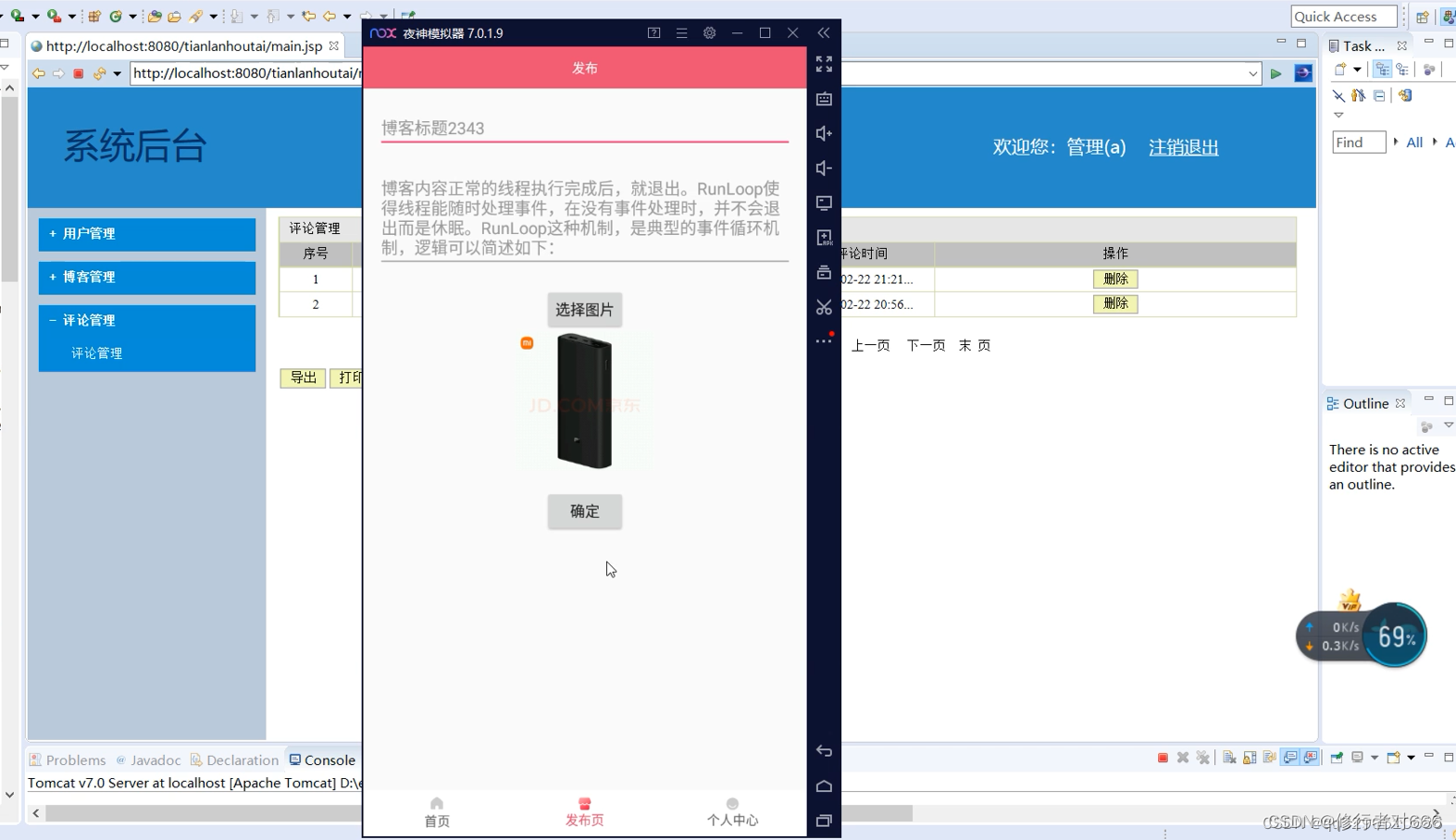
Android Studio实现内容丰富的安卓博客发布平台
获取源码请点击文章末尾QQ名片联系,源码不免费,尊重创作,尊重劳动 项目编号078 1.开发环境android stuido jdk1.8 eclipse mysql tomcat 2.功能介绍 安卓端: 1.注册登录 2.查看博客列表 3.查看博客详情 4.评论博客, 5.…...
【GPT-SOVITS-01】源码梳理
说明:该系列文章从本人知乎账号迁入,主要原因是知乎图片附件过于模糊。 知乎专栏地址: 语音生成专栏 系列文章地址: 【GPT-SOVITS-01】源码梳理 【GPT-SOVITS-02】GPT模块解析 【GPT-SOVITS-03】SOVITS 模块-生成模型解析 【G…...

数据结构大合集02——线性表的相关函数运算算法
函数运算算法合集02 顺序表的结构体顺序表的基本运算的实现1. 建立顺序表2. 顺序表的基本运算2.1 初始化线性表2. 2 销毁顺序表2.3 判断顺序表是否为空表2.4 求顺序表的长度2.5 输出顺序表2.6 按序号求顺序表中的元素2.7 按元素值查找2.8 插入数据元素2.9 删除数据元素 单链表的…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...

数据结构:递归的种类(Types of Recursion)
目录 尾递归(Tail Recursion) 什么是 Loop(循环)? 复杂度分析 头递归(Head Recursion) 树形递归(Tree Recursion) 线性递归(Linear Recursion)…...

[USACO23FEB] Bakery S
题目描述 Bessie 开了一家面包店! 在她的面包店里,Bessie 有一个烤箱,可以在 t C t_C tC 的时间内生产一块饼干或在 t M t_M tM 单位时间内生产一块松糕。 ( 1 ≤ t C , t M ≤ 10 9 ) (1 \le t_C,t_M \le 10^9) (1≤tC,tM≤109)。由于空间…...

WEB3全栈开发——面试专业技能点P4数据库
一、mysql2 原生驱动及其连接机制 概念介绍 mysql2 是 Node.js 环境中广泛使用的 MySQL 客户端库,基于 mysql 库改进而来,具有更好的性能、Promise 支持、流式查询、二进制数据处理能力等。 主要特点: 支持 Promise / async-await…...