分布式搜索引擎(3)
1.数据聚合
**[聚合(](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html)[aggregations](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html)[)](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html)**可以让我们极其方便的实现对数据的统计、分析、运算。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
1.1.聚合的种类
聚合常见的有三类:
-
**桶(Bucket)**聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
**度量(Metric)**聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
-
**管道(pipeline)**聚合:其它聚合的结果为基础做聚合
**注意:**参加聚合的字段必须是keyword、日期、数值、布尔类型
1.2.DSL实现聚合
现在,我们要统计所有数据中的酒店品牌有几种,其实就是按照品牌对数据分组。此时可以根据酒店品牌的名称做聚合,也就是Bucket聚合。
1.2.1.Bucket聚合语法
语法如下:
GET /hotel/_search
{"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果"aggs": { // 定义聚合"brandAgg": { //给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brand", // 参与聚合的字段"size": 20 // 希望获取的聚合结果数量}}}
}
结果如图:

1.2.2.聚合结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。
我们可以指定order属性,自定义聚合的排序方式:
GET /hotel/_search
{"size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","order": {"_count": "asc" // 按照_count升序排列},"size": 20}}}
}
1.2.3.限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
我们可以限定要聚合的文档范围,只要添加query条件即可:
GET /hotel/_search
{"query": {"range": {"price": {"lte": 200 // 只对200元以下的文档聚合}}}, "size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","size": 20}}}
}
这次,聚合得到的品牌明显变少了:

.2.4.Metric聚合语法
上节课,我们对酒店按照品牌分组,形成了一个个桶。现在我们需要对桶内的酒店做运算,获取每个品牌的用户评分的min、max、avg等值。
这就要用到Metric聚合了,例如stat聚合:就可以获取min、max、avg等结果。
语法如下:
GET /hotel/_search
{"size": 0, "aggs": {"brandAgg": { "terms": { "field": "brand", "size": 20},"aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算"score_stats": { // 聚合名称"stats": { // 聚合类型,这里stats可以计算min、max、avg等"field": "score" // 聚合字段,这里是score}}}}}
}
这次的score_stats聚合是在brandAgg的聚合内部嵌套的子聚合。因为我们需要在每个桶分别计算。
另外,我们还可以给聚合结果做个排序,例如按照每个桶的酒店平均分做排序:

1.2.5.小结
aggs代表聚合,与query同级,此时query的作用是?
- 限定聚合的的文档范围
聚合必须的三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合可配置属性有:
- size:指定聚合结果数量
- order:指定聚合结果排序方式
- field:指定聚合字段
1.3.RestAPI实现聚合
1.3.1.API语法
聚合条件与query条件同级别,因此需要使用request.source()来指定聚合条件。
聚合条件的语法:
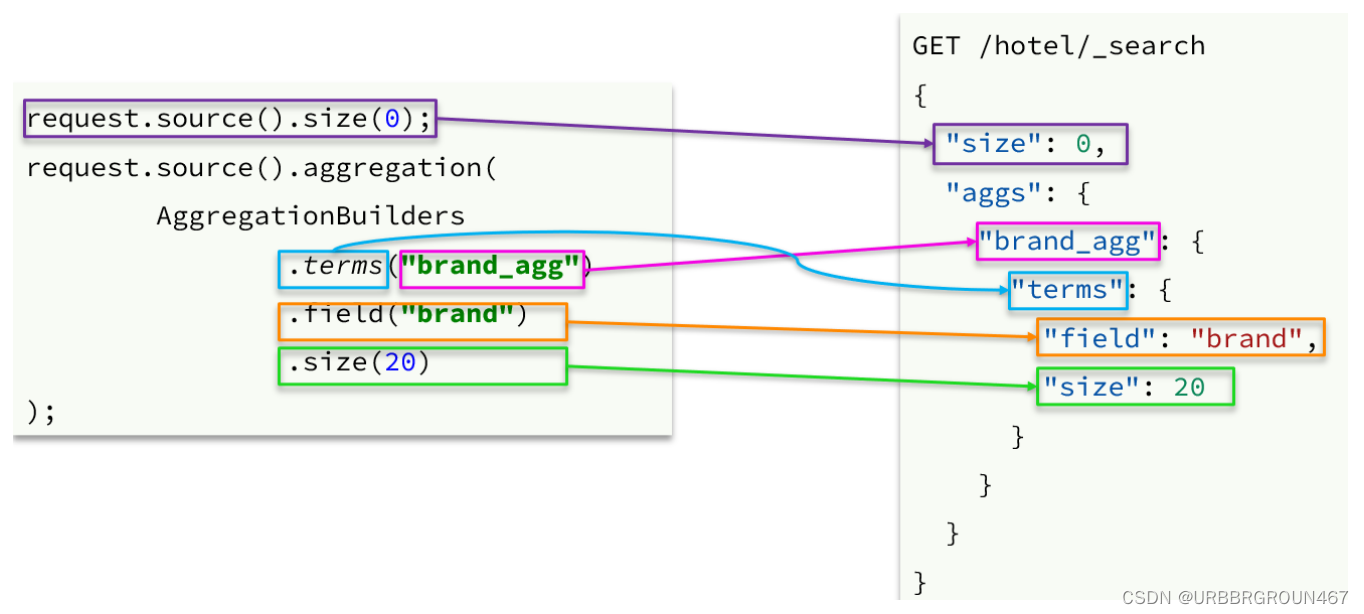
聚合的结果也与查询结果不同,API也比较特殊。不过同样是JSON逐层解析:

1.3.2.业务需求
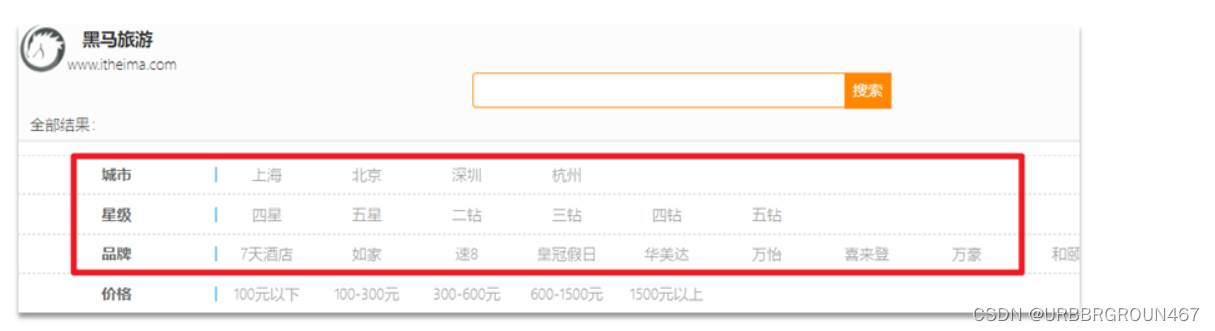
需求:搜索页面的品牌、城市等信息不应该是在页面写死,而是通过聚合索引库中的酒店数据得来的:
分析:
目前,页面的城市列表、星级列表、品牌列表都是写死的,并不会随着搜索结果的变化而变化。但是用户搜索条件改变时,搜索结果会跟着变化。
例如:用户搜索“东方明珠”,那搜索的酒店肯定是在上海东方明珠附近,因此,城市只能是上海,此时城市列表中就不应该显示北京、深圳、杭州这些信息了。
也就是说,搜索结果中包含哪些城市,页面就应该列出哪些城市;搜索结果中包含哪些品牌,页面就应该列出哪些品牌。
如何得知搜索结果中包含哪些品牌?如何得知搜索结果中包含哪些城市?
使用聚合功能,利用Bucket聚合,对搜索结果中的文档基于品牌分组、基于城市分组,就能得知包含哪些品牌、哪些城市了。
因为是对搜索结果聚合,因此聚合是限定范围的聚合,也就是说聚合的限定条件跟搜索文档的条件一致。
查看浏览器可以发现,前端其实已经发出了这样的一个请求:
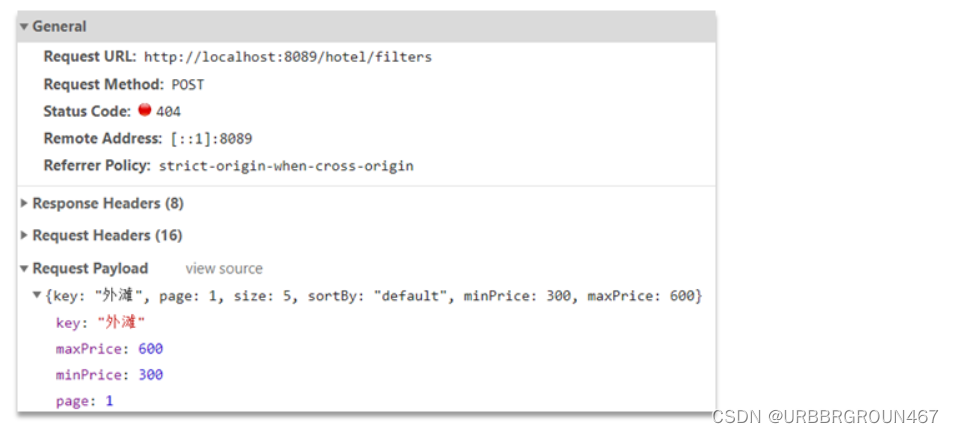
请求参数与搜索文档的参数完全一致。
返回值类型就是页面要展示的最终结果:

结果是一个Map结构:
- key是字符串,城市、星级、品牌、价格
- value是集合,例如多个城市的名称
1.3.3.业务实现
在cn.itcast.hotel.web包的HotelController中添加一个方法,遵循下面的要求:
- 请求方式:
POST - 请求路径:
/hotel/filters - 请求参数:
RequestParams,与搜索文档的参数一致 - 返回值类型:
Map<String, List<String>>
代码:
@PostMapping("filters")public Map<String, List<String>> getFilters(@RequestBody RequestParams params){return hotelService.getFilters(params);}
这里调用了IHotelService中的getFilters方法,尚未实现。
在cn.itcast.hotel.service.IHotelService中定义新方法:
Map<String, List<String>> filters(RequestParams params);
在cn.itcast.hotel.service.impl.HotelService中实现该方法:
@Override
public Map<String, List<String>> filters(RequestParams params) {try {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSL// 2.1.querybuildBasicQuery(params, request);// 2.2.设置sizerequest.source().size(0);// 2.3.聚合buildAggregation(request);// 3.发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果Map<String, List<String>> result = new HashMap<>();Aggregations aggregations = response.getAggregations();// 4.1.根据品牌名称,获取品牌结果List<String> brandList = getAggByName(aggregations, "brandAgg");result.put("品牌", brandList);// 4.2.根据品牌名称,获取品牌结果List<String> cityList = getAggByName(aggregations, "cityAgg");result.put("城市", cityList);// 4.3.根据品牌名称,获取品牌结果List<String> starList = getAggByName(aggregations, "starAgg");result.put("星级", starList);return result;} catch (IOException e) {throw new RuntimeException(e);}
}private void buildAggregation(SearchRequest request) {request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(100));request.source().aggregation(AggregationBuilders.terms("cityAgg").field("city").size(100));request.source().aggregation(AggregationBuilders.terms("starAgg").field("starName").size(100));
}private List<String> getAggByName(Aggregations aggregations, String aggName) {// 4.1.根据聚合名称获取聚合结果Terms brandTerms = aggregations.get(aggName);// 4.2.获取bucketsList<? extends Terms.Bucket> buckets = brandTerms.getBuckets();// 4.3.遍历List<String> brandList = new ArrayList<>();for (Terms.Bucket bucket : buckets) {// 4.4.获取keyString key = bucket.getKeyAsString();brandList.add(key);}return brandList;
}2.自动补全
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项,如图:

这种根据用户输入的字母,提示完整词条的功能,就是自动补全了。
因为需要根据拼音字母来推断,因此要用到拼音分词功能。
2.1.拼音分词器
要实现根据字母做补全,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件。地址:GitHub - infinilabs/analysis-pinyin: 🛵 This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
课前资料中也提供了拼音分词器的安装包:

安装方式与IK分词器一样,分三步:
①解压
②上传到虚拟机中,elasticsearch的plugin目录
③重启elasticsearch
④测试
详细安装步骤可以参考IK分词器的安装过程。
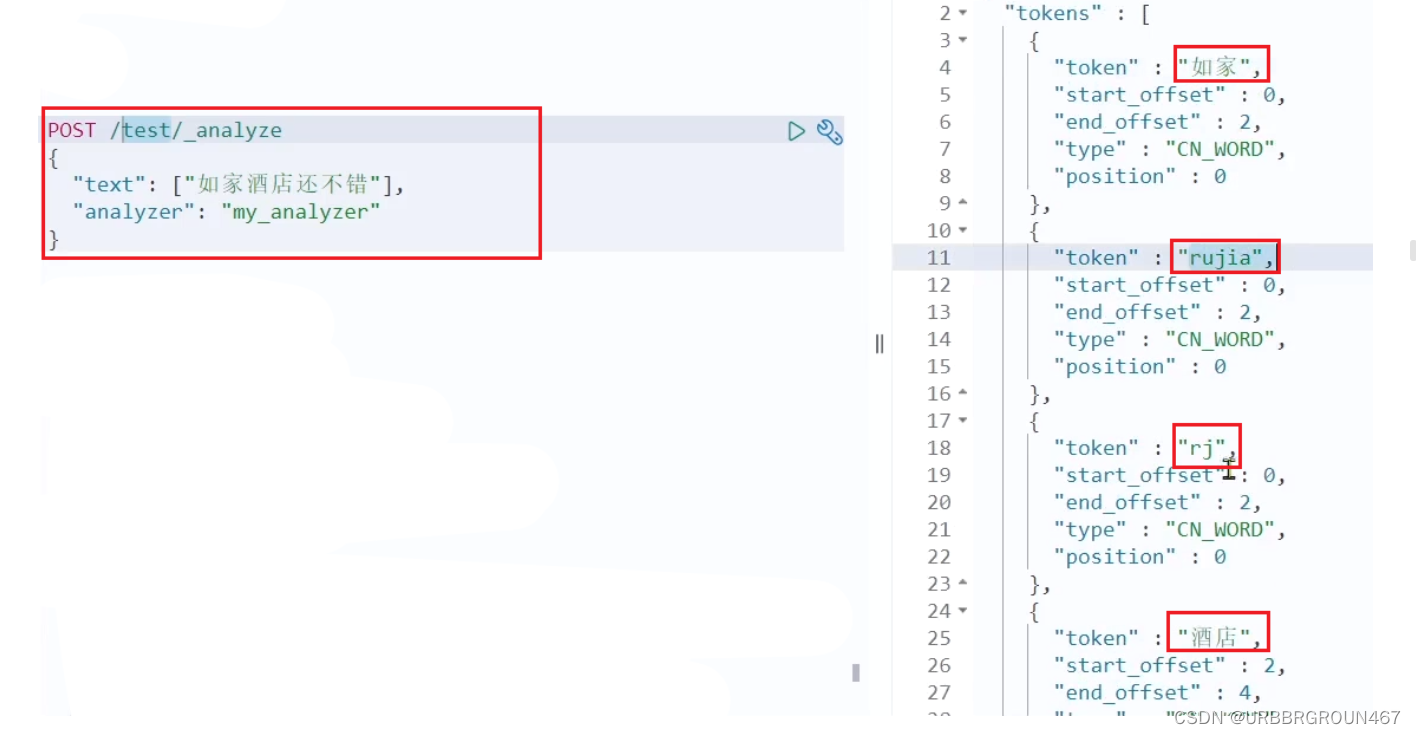
测试用法如下:
POST /_analyze
{"text": "如家酒店还不错","analyzer": "pinyin"
}
结果:

2.2.自定义分词器
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
elasticsearch中分词器(analyzer)的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
- tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
文档分词时会依次由这三部分来处理文档:

声明自定义分词器的语法如下:
PUT /test
{"settings": {"analysis": {"analyzer": { // 自定义分词器"my_analyzer": { // 分词器名称"tokenizer": "ik_max_word","filter": "py"}},"filter": { // 自定义tokenizer filter"py": { // 过滤器名称"type": "pinyin", // 过滤器类型,这里是pinyin"keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer","search_analyzer": "ik_smart"}}}
}
测试:
总结:
如何使用拼音分词器?
-
①下载pinyin分词器
-
②解压并放到elasticsearch的plugin目录
-
③重启即可
如何自定义分词器?
-
①创建索引库时,在settings中配置,可以包含三部分
-
②character filter
-
③tokenizer
-
④filter
拼音分词器注意事项?
- 为了避免搜索到同音字,搜索时不要使用拼音分词器
2.3.自动补全查询
elasticsearch提供了[Completion Suggester](https://www.elastic.co/guide/en/elasticsearch/reference/7.6/search-suggesters.html)查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
-
参与补全查询的字段必须是completion类型。
-
字段的内容一般是用来补全的多个词条形成的数组。
比如,一个这样的索引库:
// 创建索引库
PUT test
{"mappings": {"properties": {"title":{"type": "completion"}}}
}
然后插入下面的数据:
// 示例数据
POST test/_doc
{"title": ["Sony", "WH-1000XM3"]
}
POST test/_doc
{"title": ["SK-II", "PITERA"]
}
POST test/_doc
{"title": ["Nintendo", "switch"]
}
查询的DSL语句如下:
// 自动补全查询
GET /test/_search
{"suggest": {"title_suggest": {"text": "s", // 关键字"completion": {"field": "title", // 补全查询的字段"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}2.4.实现酒店搜索框自动补全
现在,我们的hotel索引库还没有设置拼音分词器,需要修改索引库中的配置。但是我们知道索引库是无法修改的,只能删除然后重新创建。
另外,我们需要添加一个字段,用来做自动补全,将brand、suggestion、city等都放进去,作为自动补全的提示。
因此,总结一下,我们需要做的事情包括:
-
修改hotel索引库结构,设置自定义拼音分词器
-
修改索引库的name、all字段,使用自定义分词器
-
索引库添加一个新字段suggestion,类型为completion类型,使用自定义的分词器
-
给HotelDoc类添加suggestion字段,内容包含brand、business
-
重新导入数据到hotel库
2.4.1.修改酒店映射结构
代码如下:
// 酒店数据索引库
PUT /hotel
{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}
}
2.4.2.修改HotelDoc实体
HotelDoc中要添加一个字段,用来做自动补全,内容可以是酒店品牌、城市、商圈等信息。按照自动补全字段的要求,最好是这些字段的数组。
因此我们在HotelDoc中添加一个suggestion字段,类型为List<String>,然后将brand、city、business等信息放到里面。
代码如下:
package cn.itcast.hotel.pojo;import lombok.Data;
import lombok.NoArgsConstructor;import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;private Object distance;private Boolean isAD;private List<String> suggestion;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();// 组装suggestionif(this.business.contains("/")){// business有多个值,需要切割String[] arr = this.business.split("/");// 添加元素this.suggestion = new ArrayList<>();this.suggestion.add(this.brand);Collections.addAll(this.suggestion, arr);}else {this.suggestion = Arrays.asList(this.brand, this.business);}}
}2.4.3.重新导入
重新执行之前编写的导入数据功能,可以看到新的酒店数据中包含了suggestion:

2.4.4.自动补全查询的JavaAPI
之前我们学习了自动补全查询的DSL,而没有学习对应的JavaAPI,这里给出一个示例:
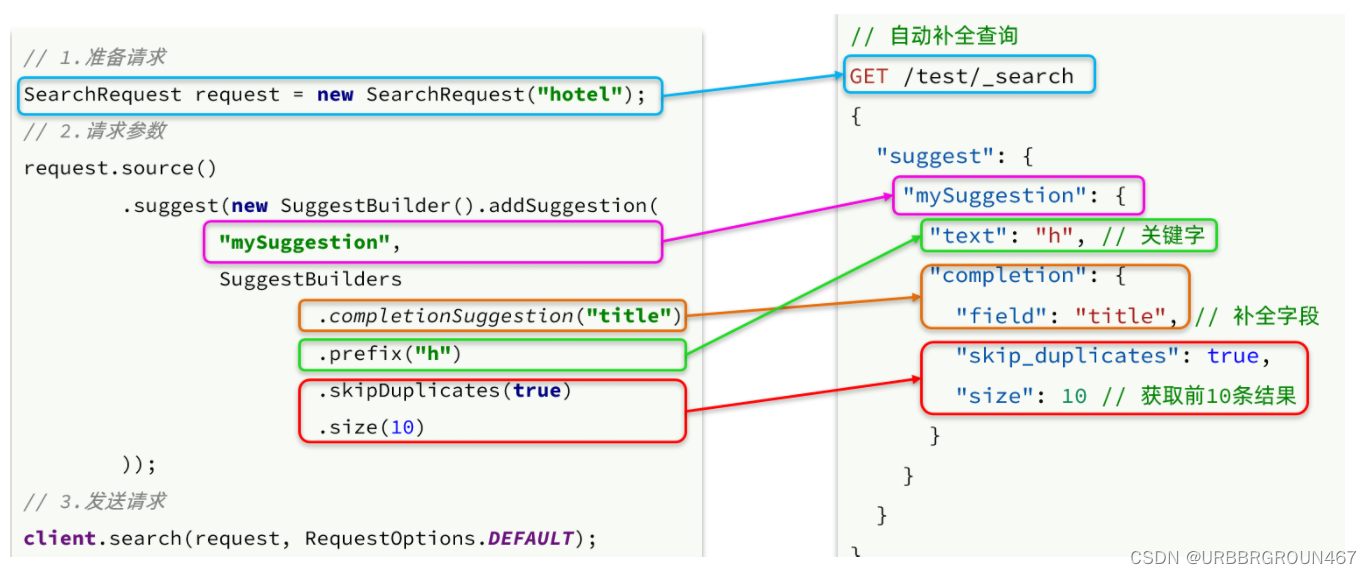
而自动补全的结果也比较特殊,解析的代码如下:

2.4.5.实现搜索框自动补全
查看前端页面,可以发现当我们在输入框键入时,前端会发起ajax请求:
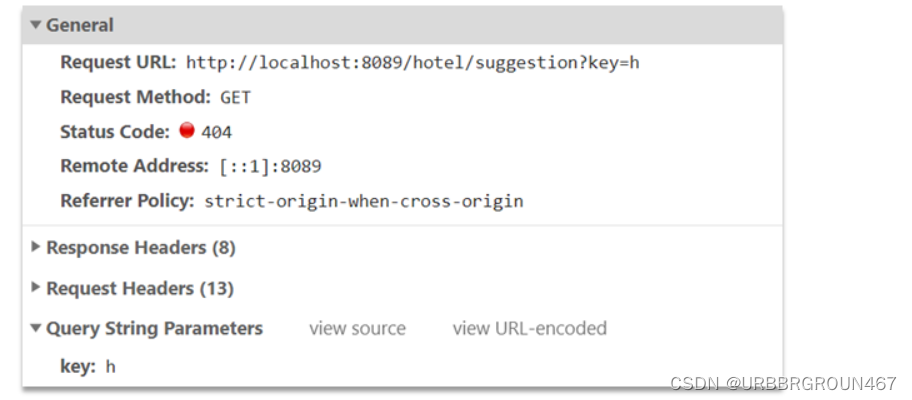
返回值是补全词条的集合,类型为List<String>
1)在cn.itcast.hotel.web包下的HotelController中添加新接口,接收新的请求:
@GetMapping("suggestion")
public List<String> getSuggestions(@RequestParam("key") String prefix) {return hotelService.getSuggestions(prefix);
}
2)在cn.itcast.hotel.service包下的IhotelService中添加方法:
List<String> getSuggestions(String prefix);
3)在cn.itcast.hotel.service.impl.HotelService中实现该方法:
@Override
public List<String> getSuggestions(String prefix) {try {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSLrequest.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix(prefix).skipDuplicates(true).size(10)));// 3.发起请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果Suggest suggest = response.getSuggest();// 4.1.根据补全查询名称,获取补全结果CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");// 4.2.获取optionsList<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();// 4.3.遍历List<String> list = new ArrayList<>(options.size());for (CompletionSuggestion.Entry.Option option : options) {String text = option.getText().toString();list.add(text);}return list;} catch (IOException e) {throw new RuntimeException(e);}
}3.数据同步
elasticsearch中的酒店数据来自于mysql数据库,因此mysql数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步。

3.1.思路分析
常见的数据同步方案有三种:
- 同步调用
- 异步通知
- 监听binlog
3.1.1.同步调用
方案一:同步调用

基本步骤如下:
- hotel-demo对外提供接口,用来修改elasticsearch中的数据
- 酒店管理服务在完成数据库操作后,直接调用hotel-demo提供的接口,
3.1.2.异步通知
方案二:异步通知

流程如下:
- hotel-admin对mysql数据库数据完成增、删、改后,发送MQ消息
- hotel-demo监听MQ,接收到消息后完成elasticsearch数据修改
3.1.3.监听binlog
方案三:监听binlog
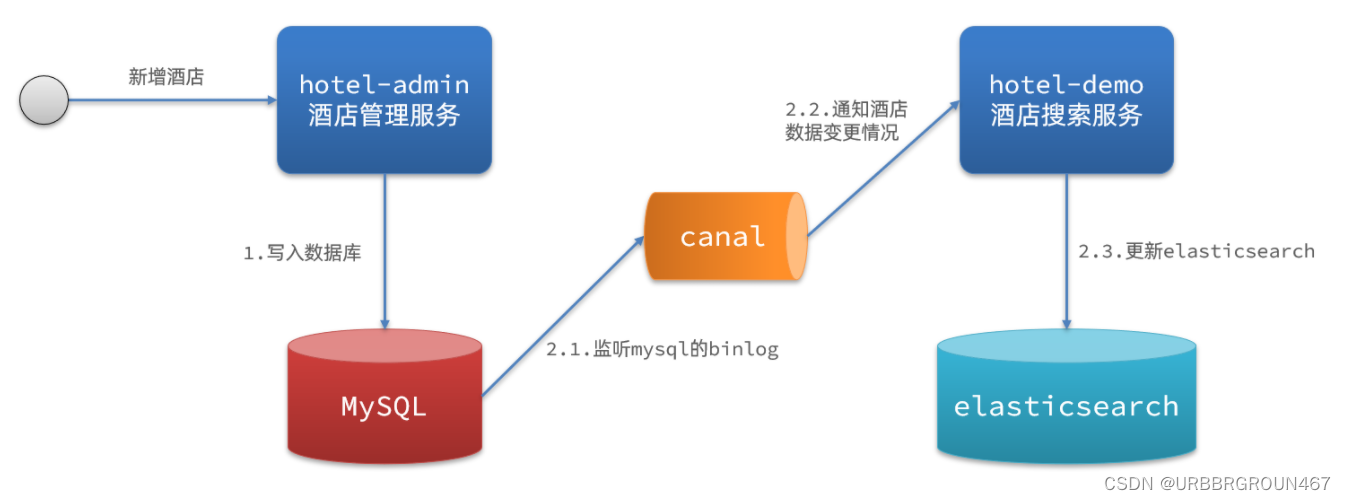
流程如下:
- 给mysql开启binlog功能
- mysql完成增、删、改操作都会记录在binlog中
- hotel-demo基于canal监听binlog变化,实时更新elasticsearch中的内容
3.1.4.选择
方式一:同步调用
- 优点:实现简单,粗暴
- 缺点:业务耦合度高
方式二:异步通知
- 优点:低耦合,实现难度一般
- 缺点:依赖mq的可靠性
方式三:监听binlog
- 优点:完全解除服务间耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高
3.2.实现数据同步
3.2.1.思路
利用课前资料提供的hotel-admin项目作为酒店管理的微服务。当酒店数据发生增、删、改时,要求对elasticsearch中数据也要完成相同操作。
步骤:
-
导入课前资料提供的hotel-admin项目,启动并测试酒店数据的CRUD
-
声明exchange、queue、RoutingKey
-
在hotel-admin中的增、删、改业务中完成消息发送
-
在hotel-demo中完成消息监听,并更新elasticsearch中数据
-
启动并测试数据同步功能
3.2.2.导入demo
导入课前资料提供的hotel-admin项目:

运行后,访问 http://localhost:8099
其中包含了酒店的CRUD功能:

3.2.3.声明交换机、队列
MQ结构如图:

1)引入依赖
在hotel-admin、hotel-demo中引入rabbitmq的依赖:
<!--amqp-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
2)声明队列交换机名称
在hotel-admin和hotel-demo中的cn.itcast.hotel.constatnts包下新建一个类MqConstants:
package cn.itcast.hotel.constatnts;public class MqConstants {/*** 交换机*/public final static String HOTEL_EXCHANGE = "hotel.topic";/*** 监听新增和修改的队列*/public final static String HOTEL_INSERT_QUEUE = "hotel.insert.queue";/*** 监听删除的队列*/public final static String HOTEL_DELETE_QUEUE = "hotel.delete.queue";/*** 新增或修改的RoutingKey*/public final static String HOTEL_INSERT_KEY = "hotel.insert";/*** 删除的RoutingKey*/public final static String HOTEL_DELETE_KEY = "hotel.delete";
}
3)声明队列交换机
在hotel-demo中,定义配置类,声明队列、交换机:
package cn.itcast.hotel.config;import cn.itcast.hotel.constants.MqConstants;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class MqConfig {@Beanpublic TopicExchange topicExchange(){return new TopicExchange(MqConstants.HOTEL_EXCHANGE, true, false);}@Beanpublic Queue insertQueue(){return new Queue(MqConstants.HOTEL_INSERT_QUEUE, true);}@Beanpublic Queue deleteQueue(){return new Queue(MqConstants.HOTEL_DELETE_QUEUE, true);}@Beanpublic Binding insertQueueBinding(){return BindingBuilder.bind(insertQueue()).to(topicExchange()).with(MqConstants.HOTEL_INSERT_KEY);}@Beanpublic Binding deleteQueueBinding(){return BindingBuilder.bind(deleteQueue()).to(topicExchange()).with(MqConstants.HOTEL_DELETE_KEY);}
}
3.2.4.发送MQ消息
在hotel-admin中的增、删、改业务中分别发送MQ消息:

3.2.5.接收MQ消息
hotel-demo接收到MQ消息要做的事情包括:
- 新增消息:根据传递的hotel的id查询hotel信息,然后新增一条数据到索引库
- 删除消息:根据传递的hotel的id删除索引库中的一条数据
1)首先在hotel-demo的cn.itcast.hotel.service包下的IHotelService中新增新增、删除业务
void deleteById(Long id);void insertById(Long id);
2)给hotel-demo中的cn.itcast.hotel.service.impl包下的HotelService中实现业务:
@Override
public void deleteById(Long id) {try {// 1.准备RequestDeleteRequest request = new DeleteRequest("hotel", id.toString());// 2.发送请求client.delete(request, RequestOptions.DEFAULT);} catch (IOException e) {throw new RuntimeException(e);}
}@Override
public void insertById(Long id) {try {// 0.根据id查询酒店数据Hotel hotel = getById(id);// 转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);// 1.准备Request对象IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());// 2.准备Json文档request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);// 3.发送请求client.index(request, RequestOptions.DEFAULT);} catch (IOException e) {throw new RuntimeException(e);}
}
3)编写监听器
在hotel-demo中的cn.itcast.hotel.mq包新增一个类:
package cn.itcast.hotel.mq;import cn.itcast.hotel.constants.MqConstants;
import cn.itcast.hotel.service.IHotelService;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;@Component
public class HotelListener {@Autowiredprivate IHotelService hotelService;/*** 监听酒店新增或修改的业务* @param id 酒店id*/@RabbitListener(queues = MqConstants.HOTEL_INSERT_QUEUE)public void listenHotelInsertOrUpdate(Long id){hotelService.insertById(id);}/*** 监听酒店删除的业务* @param id 酒店id*/@RabbitListener(queues = MqConstants.HOTEL_DELETE_QUEUE)public void listenHotelDelete(Long id){hotelService.deleteById(id);}
}
4.集群
单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。
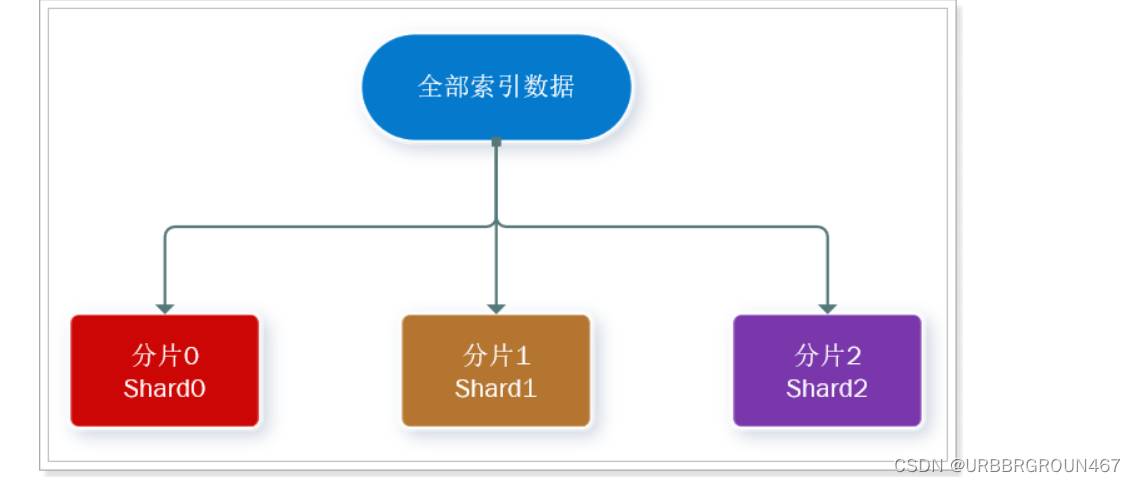
- 海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点
- 单点故障问题:将分片数据在不同节点备份(replica )
ES集群相关概念:
-
集群(cluster):一组拥有共同的 cluster name 的 节点。
-
节点(node) :集群中的一个 Elasticearch 实例
-
分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
解决问题:数据量太大,单点存储量有限的问题。
-
此处,我们把数据分成3片:shard0、shard1、shard2
-
主分片(Primary shard):相对于副本分片的定义。
-
副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样。
数据备份可以保证高可用,但是每个分片备份一份,所需要的节点数量就会翻一倍,成本实在是太高了!
为了在高可用和成本间寻求平衡,我们可以这样做:
- 首先对数据分片,存储到不同节点
- 然后对每个分片进行备份,放到对方节点,完成互相备份
这样可以大大减少所需要的服务节点数量,如图,我们以3分片,每个分片备份一份为例:
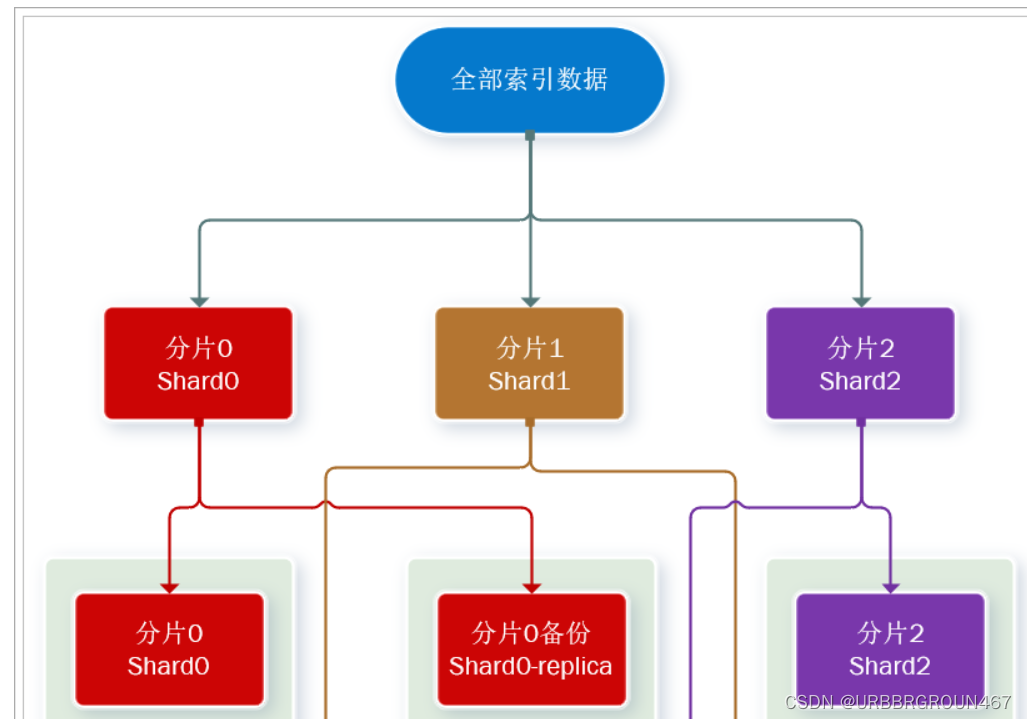

现在,每个分片都有1个备份,存储在3个节点:
- node0:保存了分片0和1
- node1:保存了分片0和2
- node2:保存了分片1和2
4.1.搭建ES集群
安装elasticsearch-CSDN博客
4.2.集群脑裂问题
4.2.1.集群职责划分
elasticsearch中集群节点有不同的职责划分:

默认情况下,集群中的任何一个节点都同时具备上述四种角色。
但是真实的集群一定要将集群职责分离:
- master节点:对CPU要求高,但是内存要求第
- data节点:对CPU和内存要求都高
- coordinating节点:对网络带宽、CPU要求高
职责分离可以让我们根据不同节点的需求分配不同的硬件去部署。而且避免业务之间的互相干扰。
一个典型的es集群职责划分如图:

4.2.2.脑裂问题
脑裂是因为集群中的节点失联导致的。
例如一个集群中,主节点与其它节点失联:

此时,node2和node3认为node1宕机,就会重新选主:
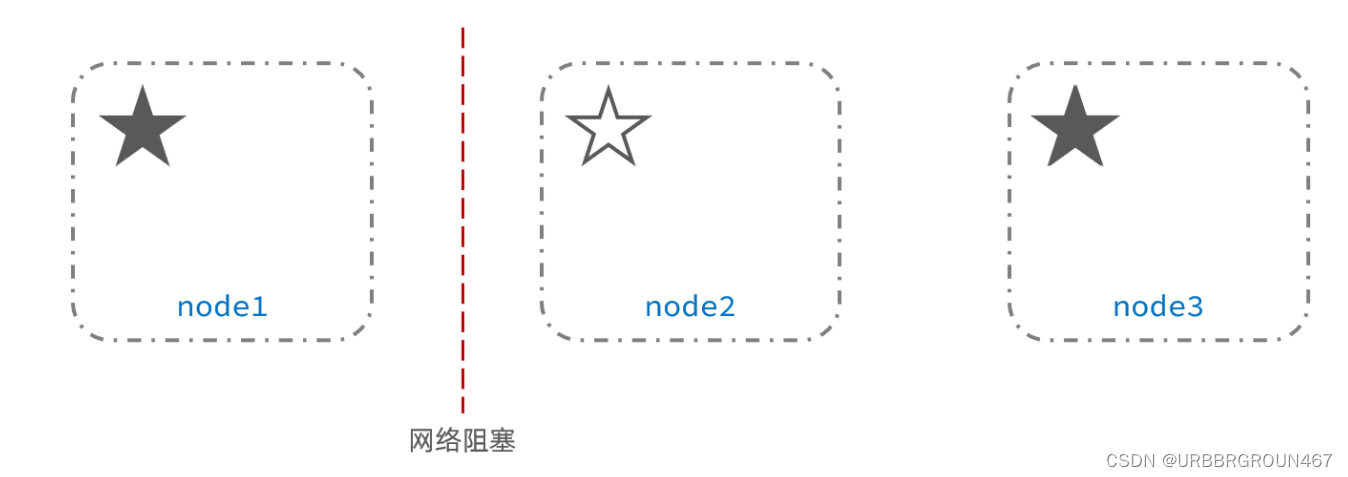
当node3当选后,集群继续对外提供服务,node2和node3自成集群,node1自成集群,两个集群数据不同步,出现数据差异。
当网络恢复后,因为集群中有两个master节点,集群状态的不一致,出现脑裂的情况:
解决脑裂的方案是,要求选票超过 ( eligible节点数量 + 1 )/ 2 才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题
例如:3个节点形成的集群,选票必须超过 (3 + 1) / 2 ,也就是2票。node3得到node2和node3的选票,当选为主。node1只有自己1票,没有当选。集群中依然只有1个主节点,没有出现脑裂。
4.2.3.小结
master eligible节点的作用是什么?
- 参与集群选主
- 主节点可以管理集群状态、管理分片信息、处理创建和删除索引库的请求
data节点的作用是什么?
- 数据的CRUD
coordinator节点的作用是什么?
-
路由请求到其它节点
-
合并查询到的结果,返回给用户
4.3.集群分布式存储
当新增文档时,应该保存到不同分片,保证数据均衡,那么coordinating node如何确定数据该存储到哪个分片呢?
4.3.1.分片存储测试
插入三条数据:

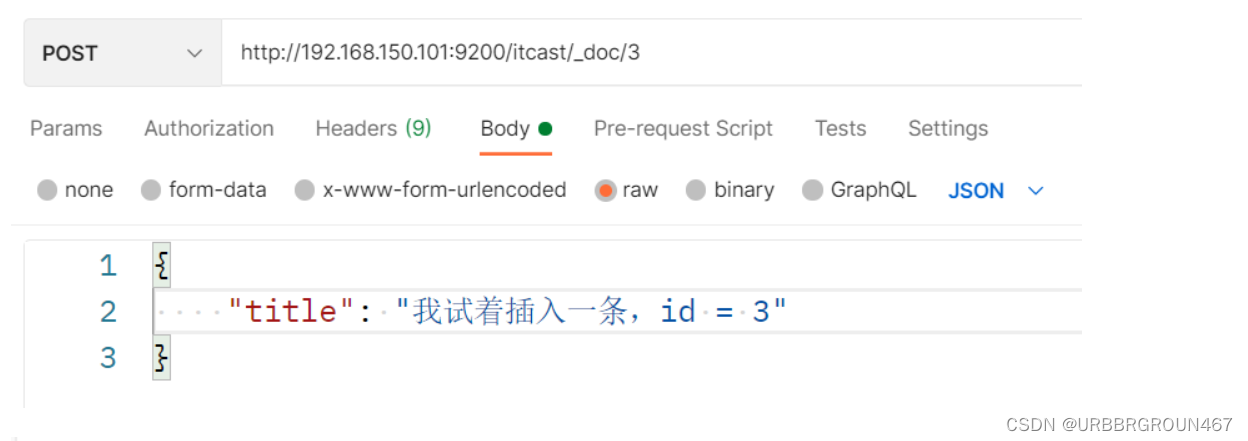
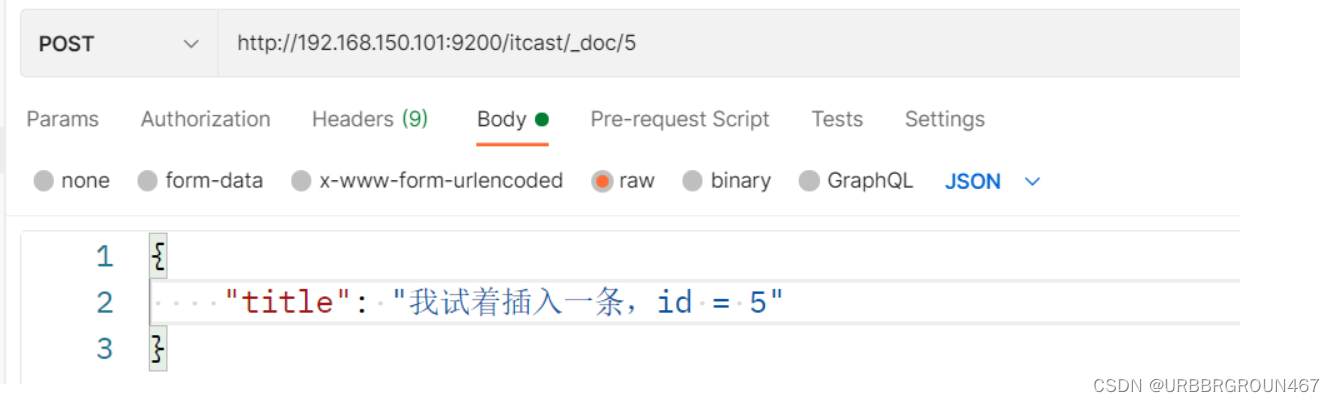
测试可以看到,三条数据分别在不同分片:

结果:

4.3.2.分片存储原理
elasticsearch会通过hash算法来计算文档应该存储到哪个分片:

说明:
- _routing默认是文档的id
- 算法与分片数量有关,因此索引库一旦创建,分片数量不能修改!
新增文档的流程如下:
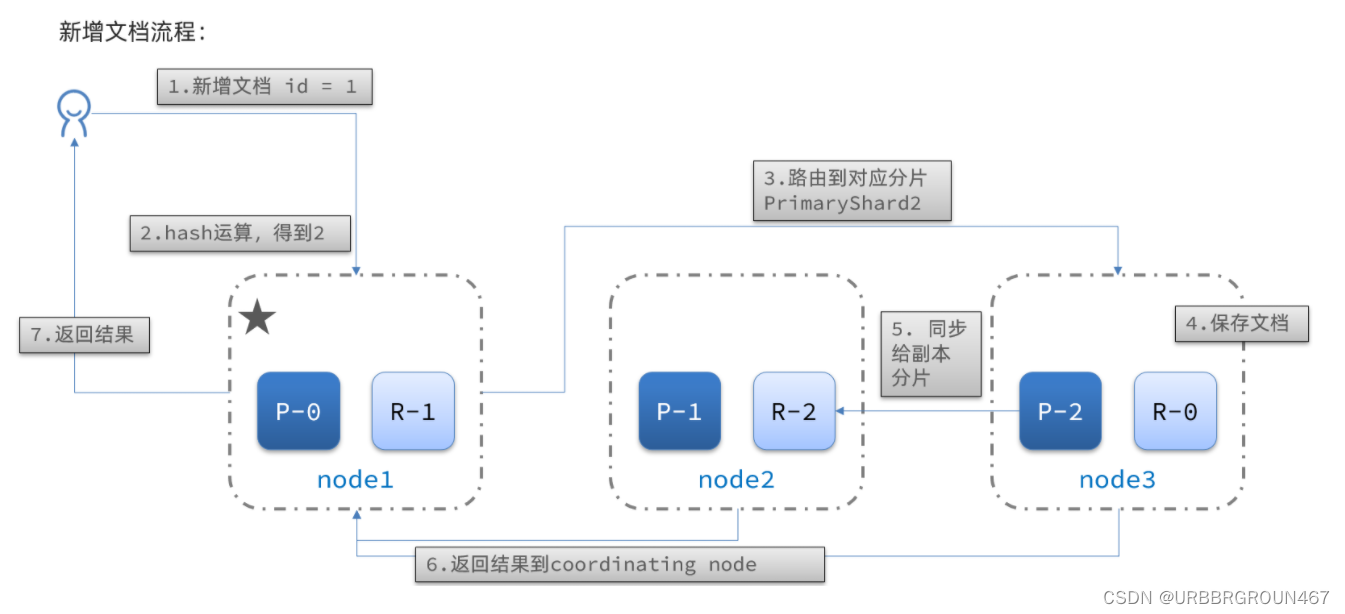
解读:
- 1)新增一个id=1的文档
- 2)对id做hash运算,假如得到的是2,则应该存储到shard-2
- 3)shard-2的主分片在node3节点,将数据路由到node3
- 4)保存文档
- 5)同步给shard-2的副本replica-2,在node2节点
- 6)返回结果给coordinating-node节点
4.4.集群分布式查询
elasticsearch的查询分成两个阶段:
-
scatter phase:分散阶段,coordinating node会把请求分发到每一个分片
-
gather phase:聚集阶段,coordinating node汇总data node的搜索结果,并处理为最终结果集返回给用户

4.5.集群故障转移
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据安全,这个叫做故障转移。
1)例如一个集群结构如图:

现在,node1是主节点,其它两个节点是从节点。
2)突然,node1发生了故障:
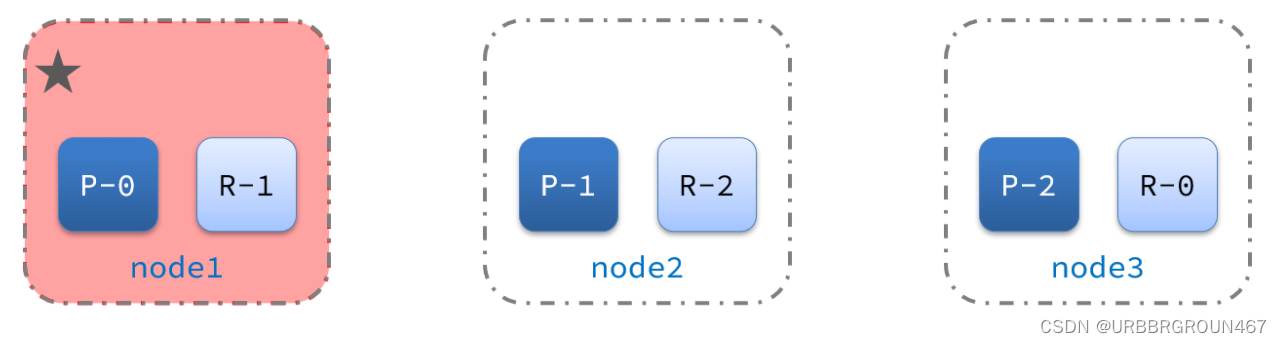
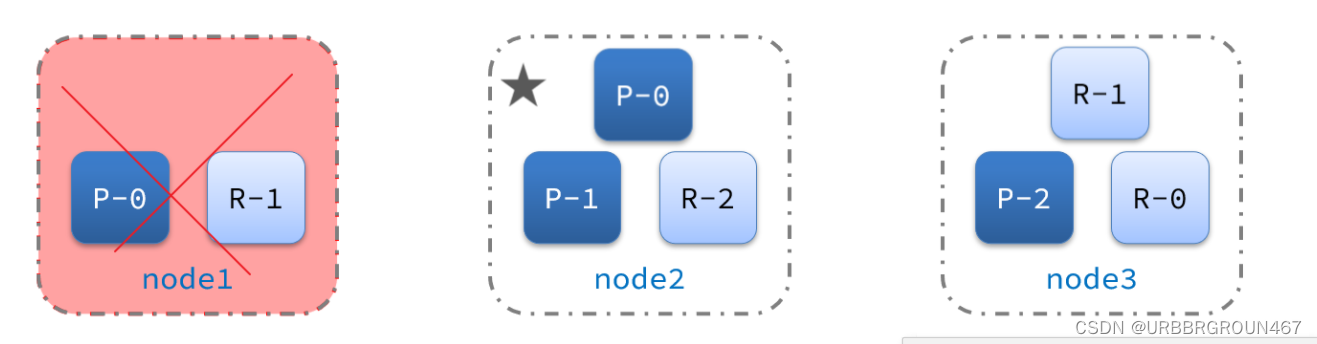
宕机后的第一件事,需要重新选主,例如选中了node2:
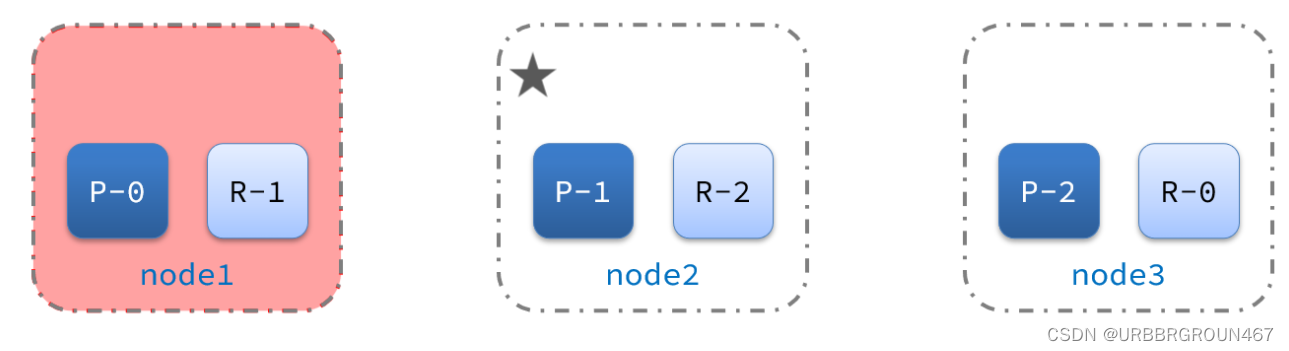
node2成为主节点后,会检测集群监控状态,发现:shard-1、shard-0没有副本节点。因此需要将node1上的数据迁移到node2、node3:
相关文章:
分布式搜索引擎(3)
1.数据聚合 **[聚合(](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html)[aggregations](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html)[)](https://www.ela…...
PostgreSQL开发与实战(6.3)体系结构3
作者:太阳 四、物理结构 4.1 软件安装目录 bin //二进制可执行文件 include //头文件目录 lib //动态库文件 share //文档以及配置模版文件4.2 数据目录 4.2.1 参数文件 pg_hba.conf //认证配置文件 p…...
ISIS接口MD5 算法认证实验简述
默认情况下,ISIS接口认证通过在ISIS协议数据单元(PDU)中添加认证字段,例如:MD5 算法,用于验证发送方的身份。 ISIS接口认证防止未经授权的设备加入到网络中,并确保邻居之间的通信是可信的。它可…...
Vue项目的搭建
Node.js 下载 Node.js — Download (nodejs.org)https://nodejs.org/en/download/ 安装 测试 winR->cmd执行 node -v配置 在安装目录下创建两个子文件夹node_cache和node_global,我的就是 D:\nodejs\node_cache D:\nodejs\node_global 在node_global文件下再创建一个…...

ABB新款ACS880-04-650A-3逆变器模块ACS88004650A3加急发货
全球商业别名:ACS880-04-650A-3 产品编号:3AUA0000137885 ABB型号名称:ACS880-04-650A-3 目录描述:低压交流工业单传动模块,IEC:Pn 355 kW,650 A,400 V,UL:Pl…...

Science Robotics 封面论文:美国宇航局喷气推进实验室开发了自主蛇形机器人,用于冰雪世界探索
人们对探索冰冷的卫星(如土卫二)的兴趣越来越大,这可能具有天体生物学意义。然而,由于地表或冰口内的环境极端,获取样本具有挑战性。美国宇航局的喷气推进实验室正在开发一种名为Exobiology Extant Life Surveyor&…...
flutter环境搭建实践
Dart Dart 是一种客户端和服务器端的编程语言,最早由 Google 提出。它被设计用于构建高性能、高度可伸缩和可靠的应用程序。Dart 可以编译成本地代码或者在虚拟机中直接运行。在移动应用开发中,Dart 主要用于开发 Flutter 应用。 Flutter 和 Dart 的关…...

CentOS无法解析部分网站(域名)
我正在安装helm软件,参考官方文档,要求下载 get-helm-3 这个文件。 但是我执行该条命令后,报错 连接被拒绝: curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 # curl: (7) Fai…...

使用HttpRequest工具类调用第三方URL传入普通以及文件参数并转换MultipartFile成File
使用HttpRequest工具类调用第三方URL传入普通以及文件参数 一、依赖及配置二、代码1、模拟第三方服务2、调用服务3、效果实现 一、依赖及配置 <!--工具依赖--><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId&g…...

24计算机考研调剂 | 武汉科技大学
武汉科技大学冶金新技术与功能金属材料研究梯队招收研究生 考研调剂招生信息 学校:武汉科技大学 专业: 工学->治金工程 工学->材料科学与工程 工学->计算机科学与技术 工学->动力工程及工程热物理 工学->机械工程 年级:2024 招生人数:20 招生状态:正在招…...

个人网站制作 Part 11 添加用户权限管理 | Web开发项目
文章目录 👩💻 基础Web开发练手项目系列:个人网站制作🚀 添加用户权限管理🔨使用Passport.js🔧步骤 1: 修改Passport本地策略 🔨修改用户模型🔧步骤 2: 修改用户模型 🔨…...
百科源码生活资讯百科门户类网站百科知识,生活常识
百科源码生活资讯百科门户类网站百科知识,生活常识 百科源码安装环境 支持php5.6,数据库mysql即可,需要有子目录权限,没有权限的话无法安装 百科源码可以创建百科内容,创建活动内容。 包含用户注册,词条创建ÿ…...

Linux 用户和用户组管理
Linux 用户和用户组管理 Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。 用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一…...
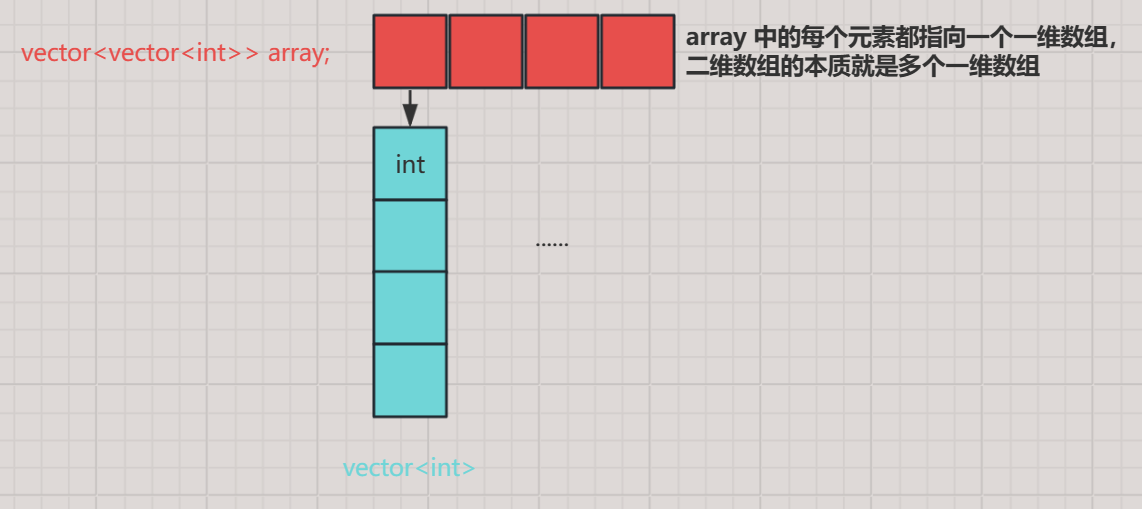
【C++ 08】vector 顺序表的常见基本操作
文章目录 前言🌈 Ⅰ vector 类对象的定义1. 定义格式2. vector 对象的构造 🌈 Ⅱ vector 类对象的容量🌈 Ⅲ vector 类对象的访问🌈 Ⅳ vector 类对象的修改🌈 Ⅴ vector 定义二维数组 前言 vector 介绍 vector 是一…...
Day67:WEB攻防-Java安全JNDIRMILDAP五大不安全组件RCE执行不出网
知识点: 1、Java安全-RCE执行-5大类函数调用 2、Java安全-JNDI注入-RMI&LDAP&高版本 3、Java安全-不安全组件-Shiro&FastJson&JackJson&XStream&Log4j Java安全-RCE执行-5大类函数调用 Java中代码执行的类: GroovyRuntimeExecPr…...

GCNv2_SLAM-CPU详细安装教程(ubuntu18.04)
GCNv2_SLAM-CPU详细安装教程-ubuntu18.04 前言一、安装第三方库1.安装Pangolin2.安装OpenCV3.安装Eigen4.安装Pytorch(c) 二、安装以及运行GCNv2_SLAM1.安装编译GCNv2_SLAM2.RGBD模式模式运行演示案例 总结 前言 paper:https://arxiv.org/pdf/1902.11046.pdf githup::https://…...

使用gitee自动备份文件
需求 舍友磁盘前两天gg了,里面的论文没有本地备份,最后费劲巴拉的在坚果云上找到了很早前的版本。我说可以上传到github,建一个私人仓库就行了,安全性应该有保证,毕竟不是啥学术大亨,不会有人偷你论文。但是…...

智慧城市新篇章:数字孪生的力量与未来
随着信息技术的迅猛发展和数字化浪潮的推进,智慧城市作为现代城市发展的新模式,正在逐步改变我们的生活方式和社会结构。在智慧城市的构建中,数字孪生技术以其独特的优势,为城市的规划、管理、服务等方面带来了革命性的变革。本文…...
python讲解(2)
目录 一.变量与赋值 二.字符串类型 引号: 三引号: 字符串拼接 三.len函数 四.注释 注释的方法 一.# 二.文档字符串 注释的要求 群体注释 五.python的报错 六.bool类型 一.变量与赋值 python中的变量是不需要声明的,直接定义即…...
安卓安装Magisk面具以及激活EdXposed
模拟器:雷电模拟器 安卓版本: Android9 文中工具下载链接合集:https://pan.baidu.com/s/1c1X3XFlO2WZhqWx0oE11bA?pwdr08s 前提准备 模拟器需要开启system可写入和root权限 一、安装Magisk 1. 安装magisk 将magisk安装包拖入模拟器 点击:…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...