【elasticsearch实战】从零开始设计全站搜索引擎
业务需求
最近需要一个全站搜索的功能,我们的站点的特点是数据多源,即有我们本地数据库,也包含了第三方数据源,我们的数据类型除了网页,还包括了各种类型的文档,例如:doc、pdf、excel、ppt等格式。搜索需求如下:
关键词检索
- 高亮搜索词
- 可以检索标题和正文内容
- 支持不通数据类型权重优先:例如doc类型文档优先级更好;
- 支持按相关度和时间维度排序
- 需要支持根据用户权限过滤部分显示文档
热门搜索词
- 统计每日用户搜索词,按搜索次数排序
- 热度按时间范围统计 T+1 统计,前n天的搜索词
参考百度热词:

输入词联想
- 用户输入搜索词后,进行输入词联想推荐,如下图:
业务分析
关键词检索
关键词检索的内容包括本地数据库和第三方数据源。
-
本地数据库存储在腾讯云的MySQL中,包括2类数据:
- 富文本网页数据存储在MySQL的text字段中
- 文档(doc、ppt、pdf、excel)数据存储在对象云存储中,我们使用了腾讯云COS存储,MySQL只存储了对象访问地址。
-
第三方数据源
第三方数据源需要和本地数据库es检索的结果混排后展示给页面显示。
热门搜索词
热门搜索词主要来源用户搜索,目前场景比较简单,每天定时任务统计N天前的用户搜词词频,按搜索频次降序排序,存储到MySQL或者redis中。
但这种方法可能存在问题,热搜词没有时间权重衰减, 例如:一个关键词10天前搜索了101次,昨天搜索了100次,10天前的词还能继续排在昨天的热词前面吗? 因此需要设计一个热词衰减权重,搜索时间越长热度权重应该相应的衰减。
联想搜索词
联想搜索需要在用户输入关键词时,联想用户可能想要搜索的词,该功能需要解决2个问题:
- 关联词来源
- 关联词方式
关联词来源可以通过用户搜索关键词记录来提取。
技术选型
技术选择可以根据业务和当前的系统环境来判断:
- 尽量不重复造轮子;
- 使用已有、成熟的、开源的技术栈;
- 能满足需求,成本低、技术可控。
搜索存储引擎目前最成熟活跃的方案非elasticsearch莫属,我们的系统基于腾讯云TSF微服务框架搭建,业务数据存在在腾讯云的MySQL中,因此搜索业务全文检索计划使用腾讯云最新版本的Elasticsearch 8.12。
es配置选择
在腾讯云es选择配置时,除了考虑文档数据量之外,还需要考虑使用的插件对配置的影响,例如腾讯云自研的QQ分词器,就比较占资源,这里提示最少要选择2核8G以上的配置,但我们在8.12版本选的这个配置时,也经常由于堆外内存过大导致了es出现OOM,最后不得不升级到8核16G,这里大家需要谨慎选择。
文档转换工具选择
我们的需求里面需要将不同类型的文档转换为纯文本,这里有几个开源的实现方案:
| 工具 | 优点 | 缺点 |
|---|---|---|
| 1. OpenOffice | 1. 一个开源的,功能强大的办公软件套装。 2. 支持多种格式的文档转换。 3. 支持多语言。 4. 可以运行在多种操作系统上。 | 1. 界面比较陈旧。 2. 某些高级功能不如付费的办公软件强大。 3. 需要较大的系统资源运行。 |
| 2. Tika | 1. Apache Tika是一个开源的文档类型和元数据提取工具。 2. 支持大量的文档格式。 3. 可以提取文档中的元数据和文本内容。 | 1. 对于一些复杂的文档格式,提取的结果可能不准确。 2. 需要Java环境运行。 |
| 3. Ingest Attachment | 1. Elasticsearch的一个插件,可以用来提取各种文件的内容。 2. 使用Apache Tika进行文档解析。 3. 可以直接与Elasticsearch集成,方便进行全文搜索。 | 1. 需要Elasticsearch环境。 2. 对于一些复杂的文档格式,提取的结果可能不准确。 |
| 4. FsCrawler | 1. FsCrawler是一个简单的文件系统爬虫,可以用来索引文件和文件夹。 2. 支持OCR和全文搜索。 3. 可以直接与Elasticsearch集成。 | 1. 需要Java环境运行。 2. 只能处理文件系统中的文件,不能处理网络上的文件。 |
我结合自身业务的情况,选了上面4种之外的方法,我们文档存储在腾讯云COS,直接调用`腾讯云API转html 或者text文档:文档转 HTML
如果没有使用腾讯云我这边推荐使用`FsCrawler, 可参考我之前的博文。
数据传输选型
我们的数据存储在MySQL,文档数据存储在对象存储腾讯云COS中,需要近实时的将文档数据的变更同步到es数据库中,有以下一些同步方案。
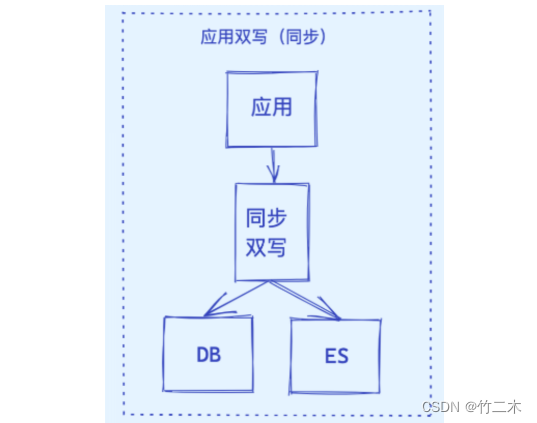
同步方案选型
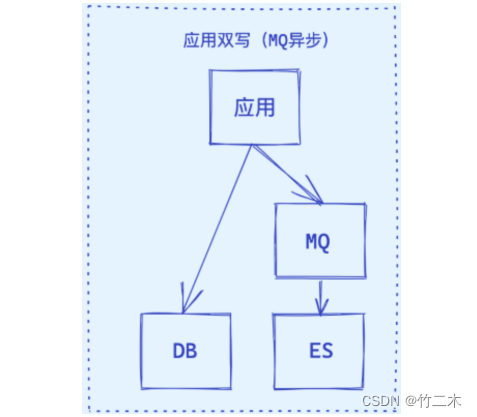
- 应用同步双写
- 应用异步双写
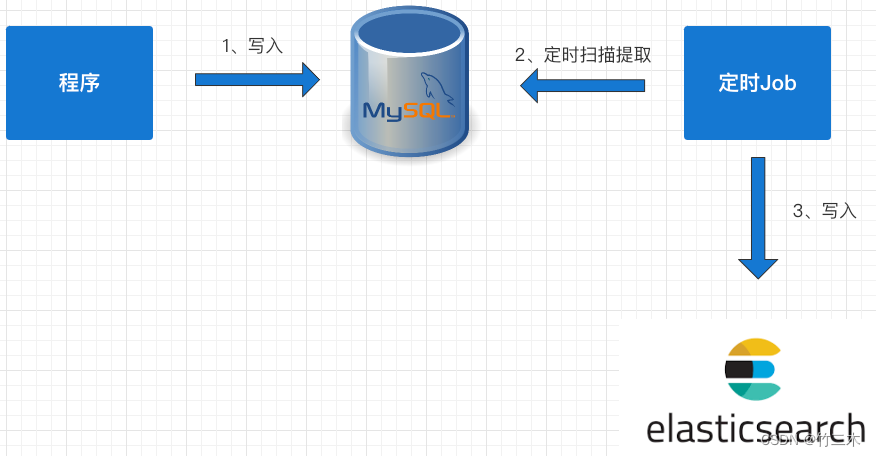
- 基于MySQL的抽取
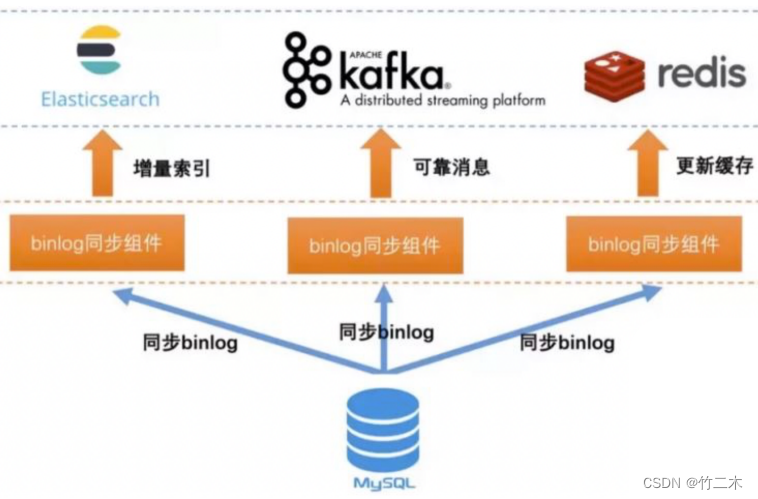
- 基于Binlog实时同步
四种方案原理和对比如下:
| 方案 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 1. 应用同步双写 | 当应用程序对MySQL进行写操作时,同时对Elasticsearch进行写操作。 | 1. 实时性较高。 2. 数据同步过程相对简单。 | 1. 对应用程序造成较大压力。 2. 需要应用程序维护两个数据源。 3. 一旦出现错误,可能导致数据不一致。 |
| 2. 应用异步双写 | 当应用程序对MySQL进行写操作时,将写操作记录到消息队列,然后异步地对Elasticsearch进行写操作。 | 1. 对应用程序的压力较小。 2. 数据同步过程相对简单。 | 1. 实时性较差。 2. 需要应用程序维护两个数据源。 3. 一旦出现错误,可能导致数据不一致。 |
| 3. 基于MySQL的定时任务抽取 | 定时从MySQL中抽取数据,然后将数据写入到Elasticsearch。 | 1. 对应用程序无影响。 2. 可以自定义同步周期。 | 1. 实时性较差。 2. 需要额外的定时任务维护。 3. 需要对MySQL进行查询操作,可能影响性能。 |
| 4. 基于MySQL的Binlog日志同步 | 通过解析MySQL的Binlog日志,实时地将数据变更写入到Elasticsearch。 | 1. 实时性较高。 2. 对应用程序无影响。 3. 可以保证数据一致性。 | 1. 需要解析Binlog日志,实现较为复杂。 2. 需要额外的同步工具或中间件。 3. 需要对MySQL的Binlog日志进行维护。 |
我们考虑综合考虑了实时性要求和对应用的改造影响,选择了方案4: 基于MySQL的Binlog日志同步。
那么异步同步工具有又怎么选择呢?
同步工具选型
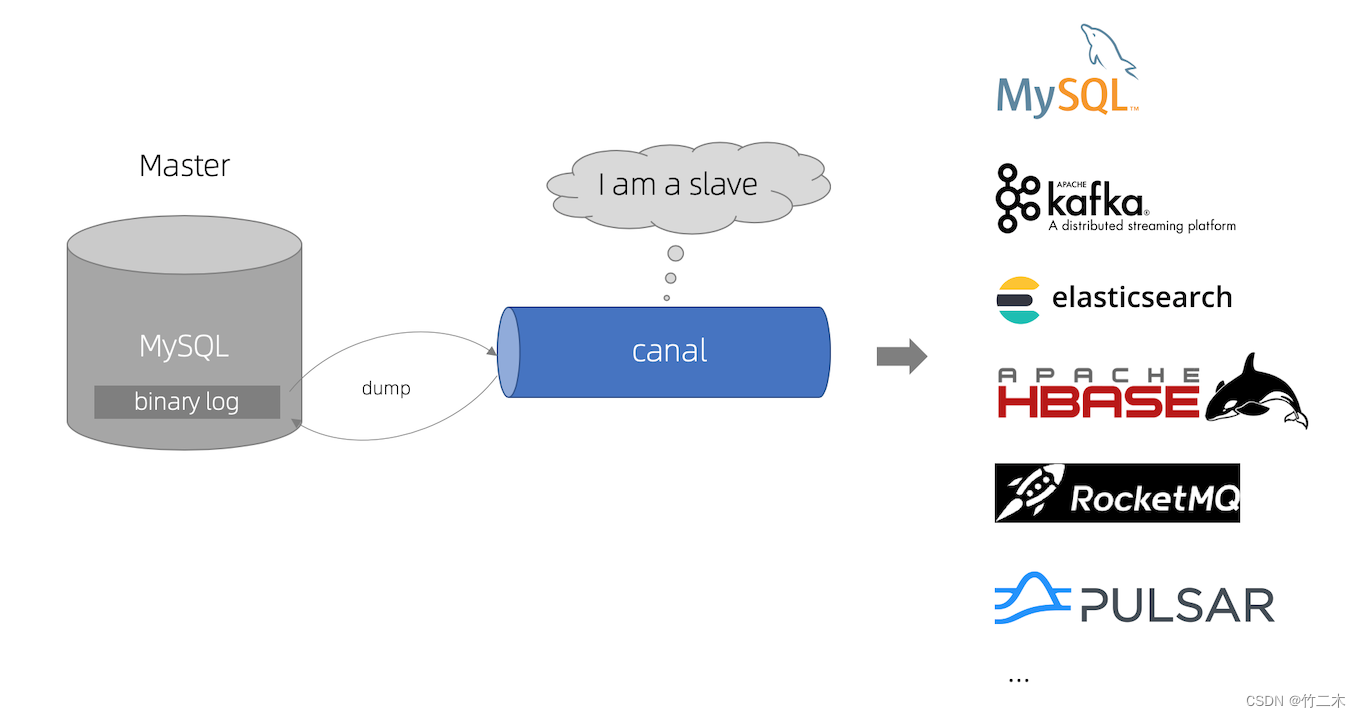
同步工具开源方案目前最活跃的应该是阿里巴巴开源的canal ,可以看github官网的原理介绍
- MySQL主备复制原理:
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志- 事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
- canal 工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
我们结合自己的业务场景和系统现状选择了腾讯云DTS做数据传输工具, 另外自研了数据传输的中间件,来解决不同数据表结构的适配问题,统一适配数据格式之后,将数据从新写入kafka,然后通过logstash 读取kafka数据写入binlog。
整体设计
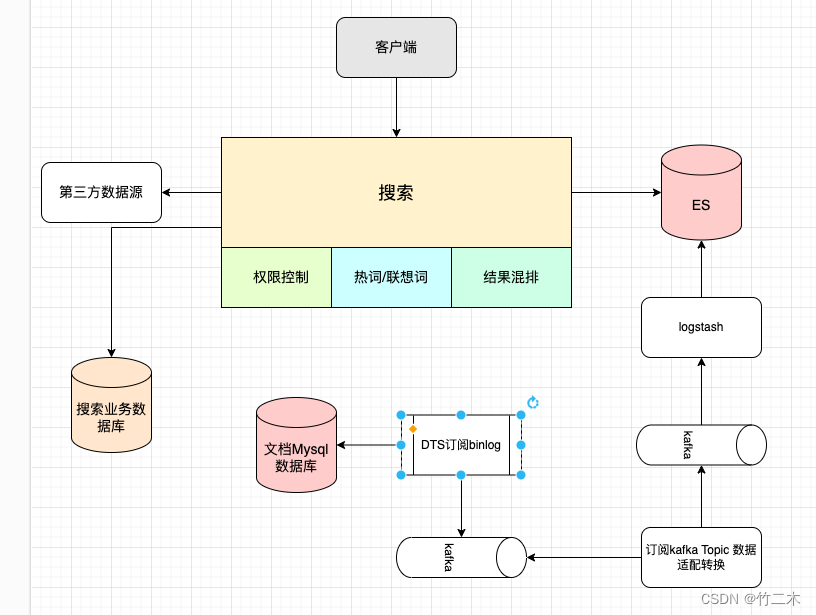
架构图
架构图如下
- 搜索服务:基础的关键词检索能力、权限控制、热词/联想词、搜索结果混排、查询第三方数据
- 数据转换服务:读取
kafka的binlog转换成满足es索引结构的json对象,再写入kafka,通过logstash写入es中。
详细设计
该服务包括:搜索门户api、权限控制、搜索能力、搜索混排、搜索热词、联想关键词。
搜索混排
由于自主维护的数据和第三方数据源数据都存储在es中,因此可以直接使用评分进行合并,如下图所示。
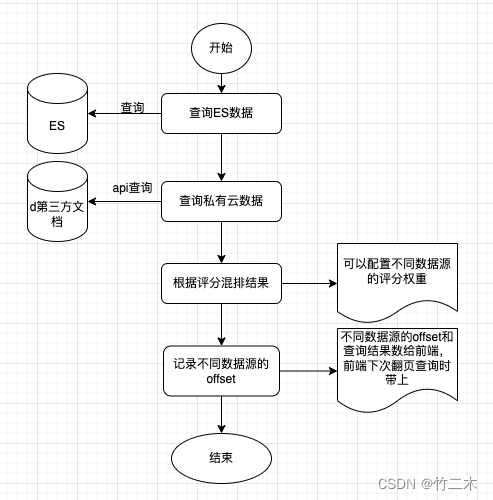
注意:
- 可以配置不同数据源的评分权重(或者评分算法)以便优先要展示的结果;
- 需要记录不同数据源的偏移量和不同数据的查询结果,以便实现下次查询分页处理;
- 查询ES和查询私有云数据使用协程并行操作,等待2个结果共同返回处理。
另外你的第三方数据源没有存储在es数据库中,不能直接给出文档评分的,可以考虑以下混排方案:
| 方案 | 原理 | 优点 | 缺点 |
|---|---|---|---|
es临时建索引做混排 | 将来自不同数据源的数据在Elasticsearch中创建一个临时索引,然后在该索引上进行搜索和排序。 | 1. 利用Elasticsearch强大的搜索功能。2. 支持复杂的查询和排序。 | 1. 需要创建临时索引,可能影响性能。 2. 需要处理索引的创建和删除。 3. 可能需要处理数据源之间的数据差异。 |
Lucene内存混排 | 将来自不同数据源的数据加载到Lucene内存索引中,然后在内存索引上进行搜索和排序。 | 1. 高性能,因为数据存储在内存中。 2. 支持复杂的查询和排序。 | 1. 内存占用较高。 2. 需要处理 Lucene内存索引的创建和维护。3. 可能需要处理数据源之间的数据差异。 |
| 分词词频内存混排 | 根据分词和词频对来自不同数据源的数据进行内存中的排序,然后返回排序后的结果。 | 1. 实现相对简单。 2. 内存占用相对较低。 | 1. 只支持基于分词和词频的排序。 2. 对于复杂的查询和排序需求,可能不够灵活。 3. 可能需要处理数据源之间的数据差异。 |
翻页方案
由于要对2个数据源进行混排,要支持搜索跳页比较困难,因此在功能实现上目前只能支持上下翻页来实现
翻页计算公式
前端需要保存每一页es 和 api 两个数据源的偏移量:EsOffset 和 ApiOffset,可以使用对象数组保存pageArrays[0] = {EsOffset: 0, ApiOffset: 0 } , 翻页计算公式如下:
-
当前页码计算公式:
PageNo =(EsOffset+ApiOffset) /PageSize -
上一页:将当前页码减1 :
pageArrays[(EsOffset+ApiOffset)/ PageSize - 1 ], 获取上一页页面缓存的上一页 EsOffset 和 ApiOffset -
下一页:
EsOffset = EsOffset + EsUsedItemCount,ApiOffset = ApiOffset + ApiUsedItemCount, 获取下一页的EsOffset 和 ApiOffset
注意:查询到第一页时,可清空页面分页缓存数组对象,重新存储。
翻页举例说明
-
查询首页,假设没页显示20条数据
-
请求参数:EsOffset = 0,ApiOffset=0, PageSize=20
-
返回结果:
EsOffset = 0,ApiOffset=0,EsUsedItemCount=7,ApiUsedItemCount=13, EsHasNextPage=true,ApiHasNextPage=true
-
前端需要需要页面需要保存当前第一页页面的 EsOffset=0 和 ApiOffset=0,PageNo = (0 + 0) / 20 = 0 ,页面缓存数据: pageArrays=[{EsOffset: 0, ApiOffset: 0 }]
-
继续查询下一页
-
请求参数:
EsOffset = EsOffset + EsUsedItemCount=> 0 + 7 = 7,ApiOffset=ApiOffset+ApiUsedItemCount = 0 + 13 = 13, PageSize=20 -
返回结果:
EsOffset = 7,ApiOffset=13, EsUsedItemCount = 12,ApiUsedItemCount = 8, EsHasNextPage=true,ApiHasNextPage=true -
前端继续缓存当前分页数据:
EsOffset=7 和 ApiOffset=13,PageNo = (7 + 13) / 20 = 1, pageArrays=[{EsOffset: 0, ApiOffset: 0 },{EsOffset: 7, ApiOffset: 13}]
-
-
查询上一页
-
请求参数:当前页码减1
(EsOffset+ApiOffset)/ PageSize - 1 => (7 + 13)/20 - 1 = 0 EsOffset = pageArrays[0].EsOffset = 0,ApiOffset=pageArrays[0].ApiOffset = 0, PageSize = 20 -
返回结果:与第一页一致
如果是查询第一数据,清空缓存数组,重新缓存当前分页数据。
权限处理
搜索权限需要满足根据用户权限过滤部分无权限的文档,以下是召回前处理和召回后处理权限的方案对比。
| 方案 | 实现 | 优点 | 缺点 |
|---|---|---|---|
| 召回前过滤 | 在查询时,根据用户的权限对文档进行过滤,只返回有权限查看的文档。 | 1. 查询结果直接满足权限要求。 2. 减少了无关文档的返回,提高了性能。 | 1. 需要在查询时处理权限信息。 2. 对于复杂的权限体系,实现可能较为复杂。 |
| 召回后过滤 | 先查询所有文档,然后根据用户的权限对查询结果进行过滤。 | 1. 查询过程简单,不需要处理权限信息。 2. 适用于简单的权限体系。 | 1. 可能返回大量无关文档,影响性能。 2. 需要在查询后处理权限信息,增加了实现复杂度。 |
根据我的需求和场景,对性能要求较高,我们使用召回前过滤。如果希望简化查询过程,页可以考虑使用召回后过滤。
下面是在文档的权限格式,包含文档有权限的用户ID和部门ID
"privilege": {"data": [{"type": "staff","id": "xxxx"},{"type": "department","id": 1}]}
我们在设计索引mapping时
{"mappings": {"properties": {"privilege": {"properties": {"data": {"type": "nested","properties": {"type": {"type": "keyword"},"id": {"type": "keyword"}}}}}}}
}
查询权限过滤参数:
GET /your_index/_search
{"query": {"bool": {"must": [{"match_all": {}}],"filter": [{"nested": {"path": "privilege.data","query": {"bool": {"must": [{"term": {"privilege.data.type": "staff"}},{"term": {"privilege.data.id": "xxxx"}}]}}}},{"nested": {"path": "privilege.data","query": {"bool": {"must": [{"term": {"privilege.data.type": "department"}},{"term": {"privilege.data.id": "1"}}]}}}}]}}
}
搜索行为日志收集
需要满足用户搜索历史记录,首先需要收集用户搜索行为日志。
通过收集用户搜索关键词存储在MySQL,每日定时任务统计热词和联想词来实现热门搜索榜和搜索联想词。
搜索热词设计
通过收集用户搜索词来统计热搜词, 其中热搜词的热度通过统计搜词词频来统计,统计包括热度周期,T+n 天的搜词次数排序,可以设计一个热度公式。
-
初始热度权重: w (默认1)
-
单位时间词频: c :(时间单位可以是 分钟、小时、天等,例如:以天为单位统计)
-
统计时间段数:T:(例如:连续统计30天关键词搜索频次)
-
单位时间热度: w / T(每个单位时间热度权重)
-
距离当前时间单位: n (例如计算最近30天,昨天的单位为:0)
一个词热度计算公式:
hot = [(T - 0)* c0 + (T - 1) * c1 + (T-2) * c2 + … + (T-n) * cn] * (w / T)
我们以按天统计,统计30天为例,每天的访问词频从近到远为: c0, c1, c2, … cn ( n 从0到29), 热度默认权重:1,时间段 T = 30(最近30天)
hot = [(30 - 0) * c0 + (30 -1) * c1 + (30-2)c2 + … + (30 - 29) * c29] * 1 / 30
=> (30c1 + 29 * c2 + 28 * c3 + …+ c29) / 30
化简后可以得到热度公式:
h o t = ∑ i = 0 n = 29 ( T − i ) ∗ c i ∗ w / T hot= \sum_{i=0}^{n=29} (T-i)*ci * w/T hot=i=0∑n=29(T−i)∗ci∗w/T -
每天定时任务统计用户搜索词,使用公式根据近30天的热度值,按从大到小排序top n;
-
将top n 结果存储到
MySQL中,方便后续人工干预。
思考:同义词合并逻辑,类似词的搜索建议合并成一个词条,避免相似词太多。
搜索联想词设计
搜索联想词,使用了es的数据类型Completion,Elasticsearch 提供了一个叫做 Completion Suggester 的功能,它是一个基于前缀的自动完成建议器,可以用来实现关键词联想。当你输入一个词的前缀时,它就可以提供一些可能的完成建议。
-
每日统计用户近3个月搜索词,排序前top n 个词;
-
将top n 写入es。(n >= 1000)。
索引模版
全文搜索模版
PUT _template/template_fulltext
{"index_patterns": ["fulltext-*"],"settings": {"number_of_shards": 1,"analysis": {"analyzer": {"ik_analyzer": {"type": "custom","tokenizer": "ik_max_word"}}}},"mappings": {"properties": {"title": {"type": "text","analyzer": "ik_analyzer"},"summary": {"type": "text","analyzer": "ik_analyzer"},"content": {"type": "text","analyzer": "ik_analyzer"},"author": {"type": "keyword"},"document_type": {"type": "keyword"},"url": {"type": "keyword"},"publish_date": {"type": "date"},"update_date": {"type": "date"},"privilege": {"properties": {"data": {"type": "nested","properties": {"department": {"type": "keyword"},"id": {"type": "keyword"}}}}}}}
}
联想词索引
PUT _template/template_suggest
{"index_patterns": ["suggest-*"],"settings": {"number_of_shards": 1},"mappings": {"properties": {"suggest": {"type": "completion"}}}
}
后续优化
数据源优化
-
文档质量优化:
- 清洗低质量文档;
- 去除重复文档;
-
排序优先级配置:支持不同来源数据设置不同权重。
搜索体验持续优化
-
搜索词库完善,补充分词器搜索词库:可以通过热门搜索词表和日常维护;
-
搜索词自动补全(completion类型)?
-
搜索词同义替换,输入错别字时能给出正确词的结果?
-
搜索点击率统计,即搜索命中结果的点击统计
参考文档
- Elasticsearch官网文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started.html
- 轻风博客: https://www.cnblogs.com/88223100/p/Four-data-synchronization-schemes-to-Elasticsearch.html
- 一本书讲透Elasticsearch:作者博客 https://blog.csdn.net/laoyang360
相关文章:
【elasticsearch实战】从零开始设计全站搜索引擎
业务需求 最近需要一个全站搜索的功能,我们的站点的特点是数据多源,即有我们本地数据库,也包含了第三方数据源,我们的数据类型除了网页,还包括了各种类型的文档,例如:doc、pdf、excel、ppt等格…...

基于tcp协议的网络通信(基础echo版.多进程版,多线程版,线程池版),telnet命令
目录 基础版 思路 辅助函数 服务端 代码 运行情况 -- telnet ip 端口号 传输的数据为什么没有转换格式 客户端 思路 代码 多进程版 引入 问题 解决 注意点 服务端 代码 运行情况 进程池版(简单介绍) 多线程版 引入 问题解决 注意点 服务端 代码 …...

Ubuntu20系统安装完后没有WIFI
Ubuntu20系统安装完后没有WIFI 查看后发现是缺少网卡,经过查询之后,发现是HRex39/rtl8852be 然后查询了Kernel版本 Check the Kernel Version in Linux $ uname -srm Linux 5.15.0-67-generic x86_64然后进行下载安装 Build(for kernel < 5.18) …...

计算机视觉——目标检测(R-CNN、Fast R-CNN、Faster R-CNN )
前言、相关知识 1.闭集和开集 开集:识别训练集不存在的样本类别。闭集:识别训练集已知的样本类别。 2.多模态信息融合 文本和图像,文本的语义信息映射成词向量,形成词典,嵌入到n维空间。 图片内容信息提取特征&…...

log4j2.xml配置文件不生效
问题 使用springboot配置log4j2,添加了依赖并排除默认的logging依赖,配置了log4j2.xml文件,放在scr目录下,运行可以在控制台输出日志,但不受配置文件影响 解决 配置文件log4j2.xml放在resources目录下生效...

QT信号与槽实现方式
1、第一种实现方式 在QT开发工具UI界面先拖入按钮,然后鼠标右键拖入按钮,点击选中槽,在页面选着需要的信号,然后OK,随即将会跳转到类的.cpp文件,(这种UI代码结合的方式,会自动去绑定…...

Yarn面试重点
文章目录 1. 简述Yarn集群的架构2. Yarn 的任务提交流程是怎样的?3. yarn的资源调度的三种模型 1. 简述Yarn集群的架构 YARN(Yet Another Resource Negotiator)是Hadoop 2.x引入的资源管理器,用于管理Hadoop集群中的资源和作业调…...

高速口光口通信
1.通过transceiver ip 设置好硬件连接配置 2.open example 用自己的模块替换掉tx和rx数据模块 3.大小端问题—— 4.配置gt收发器的rx的k码时候需要设置anybyte便于高效率接收。 5.开发数据产生模块和接收校验模块都需要使用TXUSRCLK2,但是TXUSRCLK线速度/内部数据位宽。——…...

python--剑指offer--15. 二进制中1的个数
编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 ‘1’ 的个数(也被称为 汉明重量).)。 提示: 请注意,在某些语言(如 Java&…...

uniapp h5 部署
uniapp 配置 服务器文件路径 打包文件结构 //nginx 配置 server {listen 8300;server_name bfqcwebsiteapp;charset utf-8;#允许跨域请求的域,* 代表所有add_header Access-Control-Allow-Origin *;#允许带上cookie请求add_header Access-Control-Allow-C…...

排序算法:快速排序(递归)
文章目录 一、创始人托尼霍尔的快速排序二、挖坑法三、前后指针法 所属专栏:C初阶 引言:这里所说的快速排序有三种,第一种是霍尔大佬自创的,还有一种叫做挖坑法,另外一种叫前后指针法 一、创始人托尼霍尔的快速排序 1.这里我们先…...
)
蓝桥杯每日一题(BFS)
1562 微博转发 开始思路错误点:在用拉链法保存关注信息的时候,因为要看一个用户发的有多少转发的,所以要以用户为坑位,所有关注这个坑位的用户为链表。(开始弄反了) e数组存某个用户的idx,ne是…...

【C语言】linux内核pci_save_state
一、中文注释 //include\linux\pci.h /* 电源管理相关的例程 */ int pci_save_state(struct pci_dev *dev);//drivers\pci\pci.c /*** pci_save_state - 在挂起前保存PCI设备的配置空间* dev: - 我们正在处理的PCI设备*/ int pci_save_state(struct pci_dev *dev) {int i;/* X…...
轻松打造完美原型:9款在线工具推荐
早年,UI设计师选择的工具有限,功能相对单一,大多数在线原型设计工具都是国外的,语言和网络都增加了设计工作的负担。如今,国内外有许多在线原型设计工具,不仅可以在浏览器上使用,而且还具有团队…...

Vue3中Pinia状态管理库学习笔记
pinia的基本使用 <template><div><h2>Home View</h2> <h2>count:{{ counterStore.count }}</h2><h2>count:{{ count }}</h2><button click"increment">count1</button></div> </template>…...

共谋企业出海新篇章纷享销客荣获数字中国企业峰会“卓越成果奖”
3月9日,2024数字中国企业峰会在杭州西湖中维香溢大酒店成功举办,众多数字化领域专家、知名企业 CIO 代表到场。峰会旨在推动数字化转型与创新发展,为企业出海和国际合作搭建交流与合作的平台。本次峰会的颁奖环节,纷享销客凭借其卓…...

【MySQL】group_concat 函数和 locate 函数运用之找到每篇文章的主题
力扣题 1、题目地址 2199. 找到每篇文章的主题 2、模拟表 表:Keywords Column NameTypetopic_idintwordvarchar (topic_id, word) 是该表的主键(具有唯一值的列的组合)。该表的每一行都包含一个主题的 id 和一个用于表达该主题的词。可…...
RedisCluster集群中的插槽为什么是16384个?
RedisCluster集群中的插槽为什么是16384个? CRC16的算法原理。 1.根据CRC16的标准选择初值CRCIn的值2.将数据的第一个字节与CRCIn高8位异或3.判断最高位,若该位为0左移一位,若为1左移一位再与多项式Hex码异或4.重复3至9位全部移位计算结束5…...

一直出现问题,发现服务器磁盘空间已满导致,腾出服务器磁盘空间命令
要解决服务器磁盘空间已满的问题,你可以按照以下步骤操作: 查看磁盘使用情况:使用df -h, du -s -h ./*命令来查看服务器的磁盘空间使用情况。查找大文件:使用du -a | sort -rn | head -5命令来找出占用空间最大的前5个…...

吴恩达机器学习笔记 二十三 倾斜数据集的误差指标 精确率 召回率 精确率与召回率的平衡 F1分数
如果数据集的正例和反例的比例非常倾斜,常用的错误指标如 准确率(accuracy) 并不好用。此时可以用精确率和召回率。 精确率(precision):真阳的样本数/预测为阳的样本数真阳数/(真阳假阳) 召回率(recall):…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...