Python面试笔记
Python面试笔记
- Python
- Q. Python中可变数据类型与不可变数据类型,浅拷贝与深拷贝详解
- Q. 解释什么是lambda函数?它有什么好处?
- Q. 什么是装饰器?
- Q. 什么是Python的垃圾回收机制?
- Q. Python内置函数dir的用法?
- Q. Python中两边都有下划线的方法有什么含义?
- Q. Python中单下划线和双下划线的区别
- Q. __new__和__init__区别
- Q. 什么是迭代器和⽣成器?
- Q. 什么是异常处理?
- Q. Python断言(assert)
- Q. Python中`*` 和 `**`用法?
Python
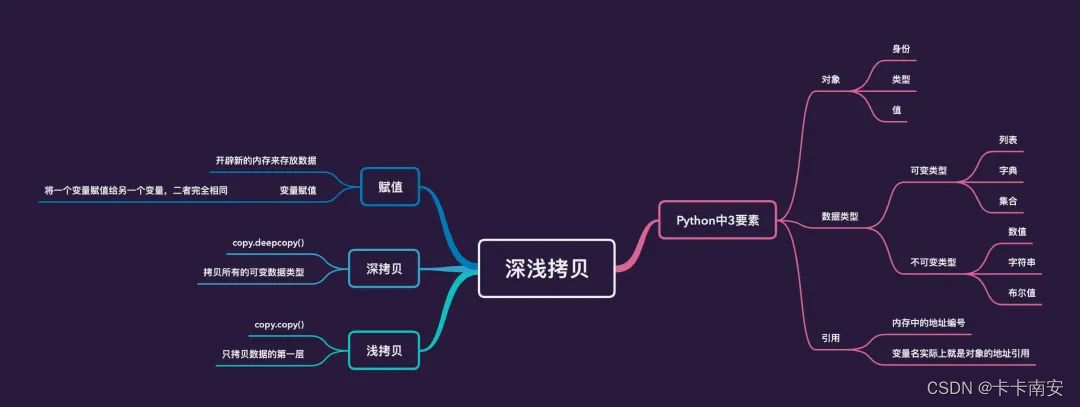
Q. Python中可变数据类型与不可变数据类型,浅拷贝与深拷贝详解
【Python基础】Python的深浅拷贝讲解
Q. 解释什么是lambda函数?它有什么好处?
Lambda函数是Python中的匿名函数。
Lambda函数在Python中被广泛使用,主要是因为它们提供了一种快速定义单行最小函数的方式,而无需使用常规的def关键字。这种函数通常用于需要一个简单操作的地方,例如在列表推导式、map()、filter()等高阶函数中作为参数传递。Lambda函数的基本语法结构是:lambda parameters_list: expression,其中parameters_list是函数的参数列表,而expression则是基于这些参数的表达式,该表达式的结果将被返回。
Lambda函数的优点主要包括代码简洁、无需增加额外变量、即时定义与使用。具体内容如下:
- 代码简洁:由于lambda函数通常只包含一个表达式,因此代码非常简洁,可以提高代码的可读性。
- 无需增加额外变量:因为lambda函数是匿名的,所以不需要为其分配一个名字,这有助于减少程序中的变量数量,避免命名冲突。
- 即时定义与使用:可以在需要时立刻定义并使用,不必像常规函数那样先定义再调用。
# case 1
add = lambda x, y: x + y
result = add(3, 5)
print(result) # 输出:8
# case 2
students = [("Alice", 25), ("Bob", 20), ("Charlie", 30)]
students.sort(key=lambda student: student[1])
print(students) # 输出:[('Bob', 20), ('Alice', 25), ('Charlie', 30)]
# case 3
numbers = [1, 2, 3, 4, 5, 6]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers) # 输出:[2, 4, 6]
Lambda表达式通常⽤于需要传递函数作为参数的函数(例如 map 、 filter 、 sorted 等),或
者在需要定义⾮常简单的匿名函数时。
总之,尽管lambda函数有许多优点,但它们也受到一些限制,如只能包含一个表达式,不能包含复杂的逻辑或语句,且没有文档字符串和名称。因此,在决定是否使用lambda函数时,应当根据实际需求和上下文进行权衡。
Q. 什么是装饰器?
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。
def my_decorator(func): def wrapper(): print("Something is happening before the function is called.") func() print("Something is happening after the function is called.") return wrapper @my_decorator
def say_hello(): print("Hello!") # 当调用 say_hello 时,实际上是调用了装饰器返回的 wrapper 函数
say_hello()输出:
Something is happening before the function is called.
Hello!
Something is happening after the function is called.
Q. 什么是Python的垃圾回收机制?
Python的垃圾回收机制主要负责自动管理内存,释放不再使用的对象所占用的内存空间。
Python的垃圾回收机制主要包括以下几种:
- 引用计数(Reference Counting)。这是Python中最基本的垃圾回收方法。每个对象都有一个引用计数,记录有多少个变量指向该对象。当引用计数为0时,表示该对象不再被使用,可以被回收。
- 标记-清除(Mark and Sweep)。这种方法用于处理循环引用的情况。当内存空间即将被占满时,Python会暂停程序,从头到尾扫描所有对象,并标记所有可达的对象。然后,清除所有未被标记的对象,回收它们占用的内存空间。
- 分代回收(Generational Collection)。为了提高垃圾回收的效率,Python引入了分代回收机制。对象被分为不同的代,如第0代和第1代等。新创建的对象通常放在第0代,而经过多次垃圾回收仍然存活的对象会被提升到更高的代。垃圾回收器会更多地检查低代中的对象,而对高代中的对象进行较少的检查,从而提高垃圾回收的效率。
需要注意的是,Python的垃圾回收机制是自动进行的,开发者不需要手动管理内存。垃圾回收器会根据需要定期启动,并在合适的时机回收不再使用的对象。
Q. Python内置函数dir的用法?
在 Python 中,dir() 是一个内置函数,用于查找对象的所有属性和方法。它返回一个字符串列表,包含了对象的所有属性和方法的名称。
class MyClass:def __init__(self):self.name = "John"def say_hello(self):print("Hello, world!")obj = MyClass()print("对象 obj 的属性和方法:", dir(obj))输出:
对象 obj 的属性和方法: ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name', 'say_hello']
Q. Python中两边都有下划线的方法有什么含义?
在Python中,两边都有双下划线的方法名被称为魔法方法(magic methods)。这些方法是Python语言的基础,它们为Python提供了强大的内置功能。例如,__init__ 方法是类的构造函数,__str__ 方法定义了对象被转换为字符串时的行为。
以下是一个简单的类示例,它定义了一个带有两边都有双下划线的方法:
class MyClass:def __init__(self, value):self.value = valuedef __str__(self):return f"MyClass with value: {self.value}"# 使用类
obj = MyClass(10)
print(obj) # 输出: MyClass with value: 10
Python中还有很多其他的魔法方法,以下是一些常用的魔法方法:
__init__:构造函数,当一个对象被创建时会自动调用。
__del__:析构函数,当一个对象被销毁时会自动调用。
__str__:返回一个对象的字符串表示,通常用于print函数。
__repr__:返回一个对象的官方字符串表示,通常用于调试。
__call__:允许一个对象像函数那样被调用。
__getitem__、__setitem__、__delitem__:用于自定义索引操作,如obj[key]。
__len__:返回对象的长度,常用于len()函数。
__iter__:返回一个迭代器,用于遍历对象。
__enter__ 和 __exit__:用于实现上下文管理协议,如with语句。
__add__、__sub__、__mul__ 等:用于自定义算术运算符的行为。
这些魔法方法允许你自定义Python对象的行为,使其更符合你的需求。你可以根据需要实现这些方法来扩展Python类的功能。
Q. Python中单下划线和双下划线的区别
- “单下划线” 开始的成员变量叫做保护变量,意思是只有类对象和子类对象自己能访问到这些变量,需通过类提供的接口进行访问,不能用“from xxx import *”而导入;
- “双下划线” 开始的是私有成员,意思是只有类对象自己能访问,连子类对象也不能访问到这个数据。仍然可以通过_{classname}__name来访问__name变量。但是强烈建议你不要这么干,因为不同版本的Python解释器可能会把__name改成不同的变量名。
Q. __new__和__init__区别
__new__与__init__区别总共有四个方面:
- 功能上的区别: 前者生成类实例对象空间的,后者是初始化对象空间并给对象赋值的;
- 执行顺序: 先执行__new__方法生成类对象空间才能执行后者
- 返回值: 前者有返回值,后者没有返回值
- 前者是静态方法, 后者是构造方法。

Q. 什么是迭代器和⽣成器?
迭代器(Iterator)和⽣成器(Generator)都是Python中⽤于处理迭代的重要概念,允许逐个访问数据项,⽽⽆需将所有数据加载到内存中,这在处理⼤型数据集合时⾮常有⽤。尽管有⼀些相似之处,但在实现和⽤法上有⼀些关键的区别。
1.迭代器(Iterator)
迭代器是⼀个对象,它可以通过调⽤ __next__() ⽅法逐个返回集合中的元素。迭代器通常⽤于遍
历集合,如列表、元组、字典等,以及⾃定义的可迭代对象。的核⼼特点是惰性计算,即只在需要时才计算下⼀个元素。
Python的内置函数 iter() 可以⽤于将可迭代对象转换为迭代器,⽽ next() 函数⽤于获取迭代
器的下⼀个元素。当没有更多元素可供迭代时,迭代器会引发 StopIteration 异常。
numbers = [1, 2, 3, 4, 5]
iter_numbers = iter(numbers)
print(next(iter_numbers)) # 输出:1
print(next(iter_numbers)) # 输出:2
2.生成器(Generator)
生成器是⼀种特殊的迭代器,它可以通过函数来创建。⽣成器函数使⽤ yield 关键字来产⽣值,并且会保持函数的状态,以便在下⼀次调⽤时继续执⾏。⽣成器允许按需⽣成数据,⽽不必将所有数据存储在内存中。
⽣成器有两种创建⽅式:
- 使⽤⽣成器函数:定义⼀个函数,其中包含 yield 语句来⽣成值。
def countdown(n):while n > 0:yield nn -= 1
gen = countdown(5)
for num in gen:print(num)
- 使⽤⽣成器表达式:类似于列表推导式,但是使⽤圆括号⽽不是⽅括号,并且按需⽣成数据。
gen = (x for x in range(5))
for num in gen:print(num)
⽣成器通常⽤于处理⼤型数据集或需要逐个⽣成数据的情况,因为不需要⼀次性加载所有数据到内存中,从⽽节省了内存资源。
总之,迭代器和⽣成器都是处理迭代的强⼤⼯具,允许⾼效地处理⼤型数据集和按需⽣成数据。可以根据任务的需求选择使⽤哪种⽅式。
Q. 什么是异常处理?
异常处理是⼀种编程技术,⽤于在程序执⾏期间捕获、处理和处理可能发⽣的异常情况或错误。异常是指在程序执⾏过程中出现的不正常情况,可能导致程序崩溃或产⽣不可预料的结果。异常处理的⽬标是使程序能够优雅地应对异常情况,⽽不是因异常⽽终⽌或崩溃。
在Python中,异常处理通常使⽤ try 和 except 语句来实现。基本的异常处理结构如下:
try:# 可能引发异常的代码块
except ExceptionType:# 处理异常的代码块
- try 语句块包含可能引发异常的代码,它会被监视以检查是否发⽣异常。
- 如果在 try 块中的代码引发了指定类型的异常( ExceptionType ),则程序将跳转到与该异常匹配的 except 块,执⾏异常处理代码。
- 如果在 try 块中没有引发异常,则 except 块将被跳过,程序将继续执⾏ try 块之后的代码。
try:num = int(input("请输⼊⼀个整数:"))result = 10 / num
except ZeroDivisionError:print("除以零错误")
except ValueError:print("输⼊不是有效的整数")
else:print("结果是:", result)
finally:print("结束")
- else语句块中的代码会在try块没有抛出任何异常的情况下运行。
- finally语句块中的代码无论是否发生异常都会被执行。
Q. Python断言(assert)
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况,例如我们的代码只能在 Linux 系统下运行,可以先判断当前系统是否符合条件。
语法格式如下:
assert expression
#等价于:
if not expression:raise AssertionError#assert后面也可以紧跟参数:assert expression [, arguments]
#等价于:
if not expression:raise AssertionError(arguments)
例子:
>>> assert True # 条件为 true 正常执行
>>> assert False # 条件为 false 触发异常
Traceback (most recent call last):File "<stdin>", line 1, in <module>
AssertionError
>>> assert 1==1 # 条件为 true 正常执行
>>> assert 1==2 # 条件为 false 触发异常
Traceback (most recent call last):File "<stdin>", line 1, in <module>
AssertionError>>> assert 1==2, '1 不等于 2'
Traceback (most recent call last):File "<stdin>", line 1, in <module>
AssertionError: 1 不等于 2
>>>
Q. Python中* 和 **用法?
在 Python 中,* 和 ** 具有语法多义性,具体来说是有四类用法。
1.算数运算
>>> 2 * 5 #乘法
//10
>>> 2 ** 5 #乘方
//32
2.函数形参
*args 和 **kwargs 主要用于函数定义。
你可以将不定数量的参数传递给一个函数。不定的意思是:预先并不知道, 函数使用者会传递多少个参数给你, 所以在这个场景下使用这两个关键字。其实并不是必须写成 *args 和 **kwargs。 *(星号) 才是必须的. 你也可以写成 *ar 和 **k 。而写成 *args 和**kwargs 只是一个通俗的命名约定。
python函数传递参数的方式有两种:
- 位置参数(positional argument)
- 关键词参数(keyword argument)
*args 与 **kwargs 的区别,两者都是 python 中的可变参数:
*args表示任何多个无名参数,它本质是一个 tuple**kwargs表示关键字参数,它本质上是一个 dict
如果同时使用 *args 和 **kwargs 时,必须 *args 参数列要在 **kwargs 之前。
>>> def fun(*args, **kwargs):
... print('args=', args)
... print('kwargs=', kwargs)
...
>>> fun(1, 2, 3, 4, A='a', B='b', C='c', D='d')
//args= (1, 2, 3, 4)
//kwargs= {'A': 'a', 'B': 'b', 'C': 'c', 'D': 'd'}
使用*args:
>>> def fun(name, *args):
... print('你好:', name)
... for i in args:
... print("你的宠物有:", i)
...
>>> fun("Geek", "dog", "cat")
//你好: Geek
//你的宠物有: dog
//你的宠物有: cat
使用 **kwargs :
>>> def fun(**kwargs):
... for key, value in kwargs.items():
... print("{0} 喜欢 {1}".format(key, value))
...
>>> fun(Geek="cat", cat="box")
//Geek 喜欢 cat
//cat 喜欢 box
3.函数实参(解引用)
如果函数的形参是定长参数,也可以使用 *args 和 **kwargs 调用函数,类似对元组和字典进行解引用:
>>> def fun(data1, data2, data3):
... print("data1: ", data1)
... print("data2: ", data2)
... print("data3: ", data3)
...
>>> args = ("one", 2, 3)
>>> fun(*args)
data1: one
data2: 2
data3: 3
>>> kwargs = {"data3": "one", "data2": 2, "data1": 3}
>>> fun(**kwargs)
data1: 3
data2: 2
data3: one
4.序列解包
序列解包没有**
>>> a, b, *c = 0, 1, 2, 3
>>> a
0
>>> b
1
>>> c
[2, 3]
相关文章:
Python面试笔记
Python面试笔记 PythonQ. Python中可变数据类型与不可变数据类型,浅拷贝与深拷贝详解Q. 解释什么是lambda函数?它有什么好处?Q. 什么是装饰器?Q. 什么是Python的垃圾回收机制?Q. Python内置函数dir的用法?Q…...

springboot 查看和修改内置 tomcat 版本
解析Spring Boot父级依赖 去到项目的根pom文件中,找到parent依赖: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>${springboot.version}…...
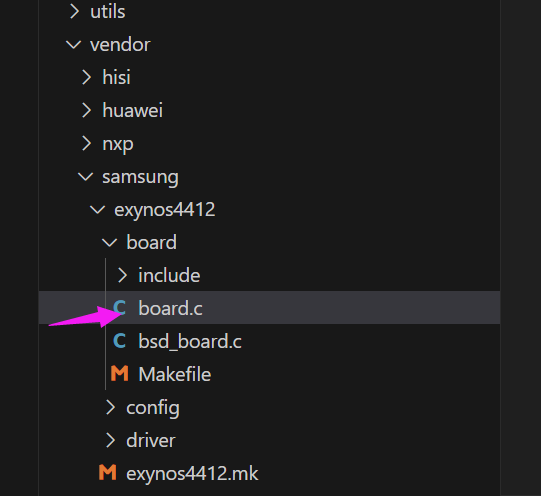
003——移植鸿蒙
目录 一、顶层Make分析 二、添加一个新的单板 2.1 Kconfig 2.2 Makefile 2.2.1 顶层Makefile 2.2.2 platform下的Makefile 2.2.3 platform下的bsp.mk文件 2.3 编译与调试 2.4 解决链接错误 三、内核启动流程的学习 3.1 韦东山老师总结的启动四步 3.2 启动文件分析…...

罗马数字转整数-力扣通过自己编译器编译
学会将力扣题目用自己自带的编译软件编译---纯自己想的本题解法 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例如, 罗马数字 2 写做 II ,即为两…...
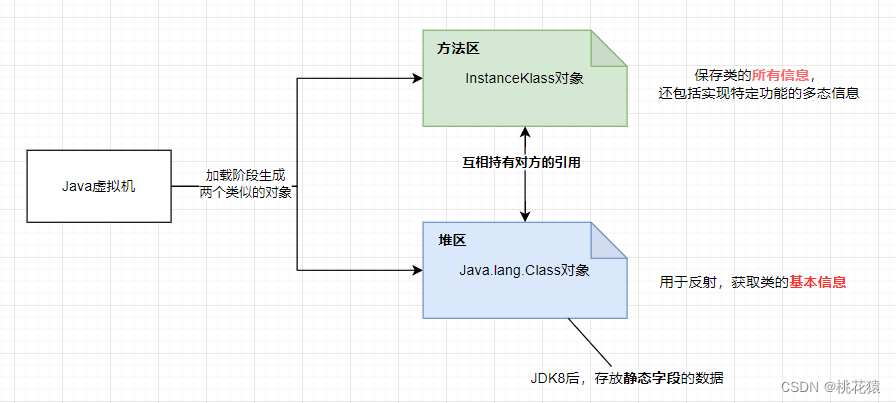
深入解析JVM加载机制
一、背景 Java代码被编译器变成生成Class字节码,但字节码仅是一个特殊的二进制文件,无法直接使用。因此,都需要放到JVM系统中执行,将Class字节码文件放入到JVM的过程,简称类加载。 二、整体流程 三、阶段逻辑分析 3…...
python redis中blpop和lpop的区别
python redis中lpop()方法是获取并删除左边第一个对象。 def lpop(self,name: str,count: Optional[int] None,) -> Union[Awaitable[Union[str, List, None]], Union[str, List, None]]:"""Removes and returns the first elements of the list name.By de…...

第四百一十回
文章目录 1. 概念介绍2. 方法与细节2.1 获取方法2.2 使用细节 3. 示例代码4. 内容总结 我们在上一章回中介绍了"如何获取当前系统语言"相关的内容,本章回中将介绍如何获取时间戳.闲话休提,让我们一起Talk Flutter吧。 1. 概念介绍 我们在本章…...
)
程序员的README——编写可维护的代码(一)
用户行为不可预测,网络不可靠,事情总会出错。生产环境下的软件必须一直保持可用状态。 编写可维护的代码有助于你应对不可预见的情况,可维护的代码有内置的保护、诊断和控制。 切记通过安全和有弹性的编码实践进行防御式编程来保护你的系统&a…...
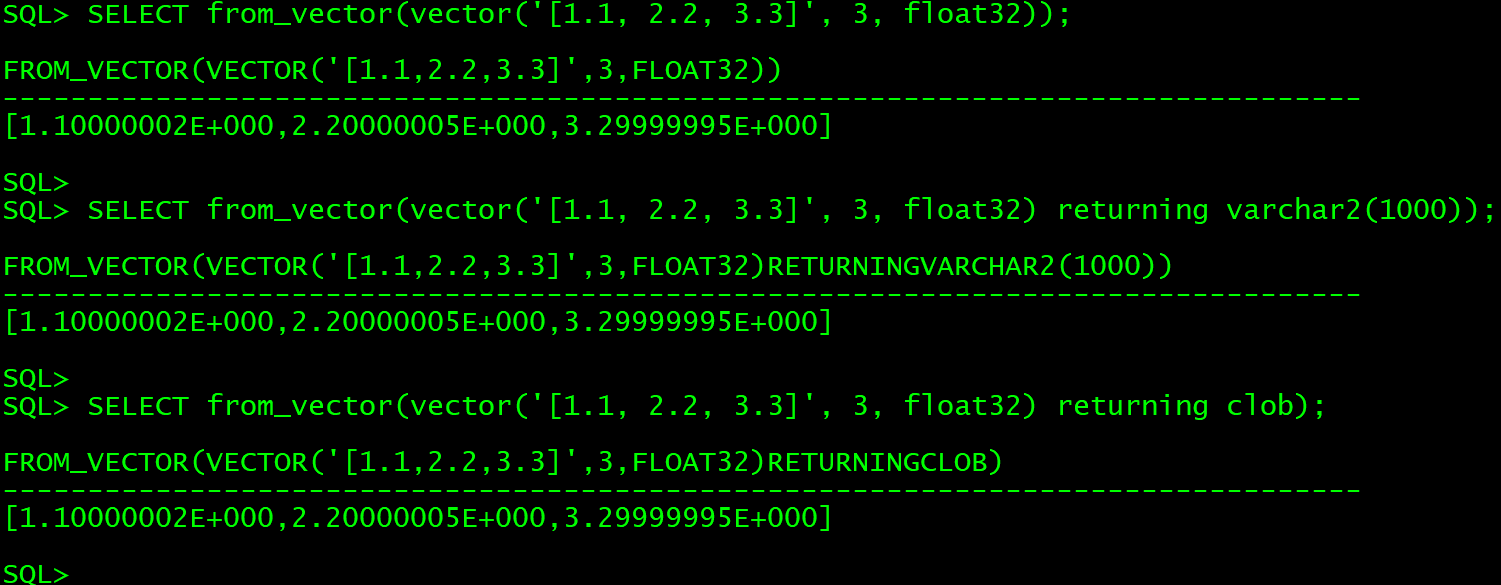
数据库管理-第160期 Oracle Vector DB AI-11(20240312)
数据库管理160期 2024-03-12 数据库管理-第160期 Oracle Vector DB & AI-11(20240312)1 向量的函数操作to_vector()将vector转换为标准值vector_norm()vector_dimension_count()vector_dimension_format() 2 将向量转换为字符串或CLOBvector_seriali…...
boost库笔记)
(C++进阶)boost库笔记
目录 1、boost::function 1.1 概述 1.2 boost包装器和C11包装器对比 1.2、代码示例 1、boost::function 1.1 概述 boost::function 是 Boost 库中提供的一个通用函数对象包装器,它可以存储指向任何可调用对象的指针,并且可以在任何时候通过 operat…...

MapReduce面试重点
文章目录 1. 简述MapReduce整个流程2. join原理 1. 简述MapReduce整个流程 数据划分(Input Splitting):开始时,输入数据被分割成逻辑上的小块,每个块被称为Input Split。 映射(Map):每个Input Split 由一个或多个Map任务处理&…...
从主函数中输入10个等长字符串,用一个函数对他们排序,然后在主函数输出这10个已排好序的字符串)
C语言简单题(7)从主函数中输入10个等长字符串,用一个函数对他们排序,然后在主函数输出这10个已排好序的字符串
从主函数中输入10个等长字符串,用一个函数对他们排序,然后在主函数输出这10个已排好序的字符串 /* 从主函数中输入10个等长字符串,用一个函数对他们排序,然后在主函数输出这10个已排好序的字符串 */ #include<stdio.h> …...

光伏科普|太阳能光伏发电应用场景有哪些?
太阳能光伏发电的应用领域其实非常广泛,很多人会不相信,但在我们的日常生活中随处可见太阳能光伏产业,本文将详细介绍其应用场景有哪些。 一、工业领域厂房 太阳能光伏发电作为一种清洁、可再生的能源,安装在工业领域厂房&#…...

Go 构建高效的二叉搜索树联系簿
引言 树是一种重要的数据结构,而二叉搜索树(BST)则是树的一种常见形式。在本文中,我们将学习如何构建一个高效的二叉搜索树联系簿,以便快速插入、搜索和删除联系人信息。 介绍二叉搜索树 二叉搜索树是一种有序的二叉…...

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的交通信号灯识别系统(深度学习+UI界面+训练数据集+Python代码)
摘要:本研究详细介绍了一种采用深度学习技术的交通信号灯识别系统,该系统集成了最新的YOLOv8算法,并与YOLOv7、YOLOv6、YOLOv5等早期算法进行了性能评估对比。该系统能够在各种媒介——包括图像、视频文件、实时视频流及批量文件中——准确地…...
函数类型)
以太坊开发学习-solidity(三)函数类型
目录 函数类型 函数类型 solidity官方文档里把函数归到数值类型 函数类型是一种表示函数的类型。可以将一个函数赋值给另一个函数类型的变量, 也可以将一个函数作为参数进行传递,还能在函数调用中返回函数类型变量。 函数类型有两类:- 内部&…...

教你把公司吃干抹净、榨干带走
大家好: 衷心希望各位点赞。 您的问题请留在评论区,我会及时回答 正文 打工人一定要做到够自私,把公司的一切为我所用,你要知道闷头打工是没有出路的。聪明的人会以最快的速度榨干带走公司的一切资源、人脉、技能,为…...

开发指南007-导出Excel
平台上开发导出Excel比过去的单体架构要复杂些,因为前端和后台不在一个进程空间里。 后台的操作是先生成excel文件,技术路线是jxl <dependency><groupId>net.sourceforge.jexcelapi</groupId><artifactId>jxl</artifactId&g…...

滑块验证码
1.这里针对滑块验证给了一个封装的组件verifition,使用直接可以调用 2.组件目录 3.每个文件的内容 3.1 Api文件中只有一个index.js文件,用来存放获取滑块和校验滑块结果的api import request from /router/axios//获取验证图片 export function reqGe…...
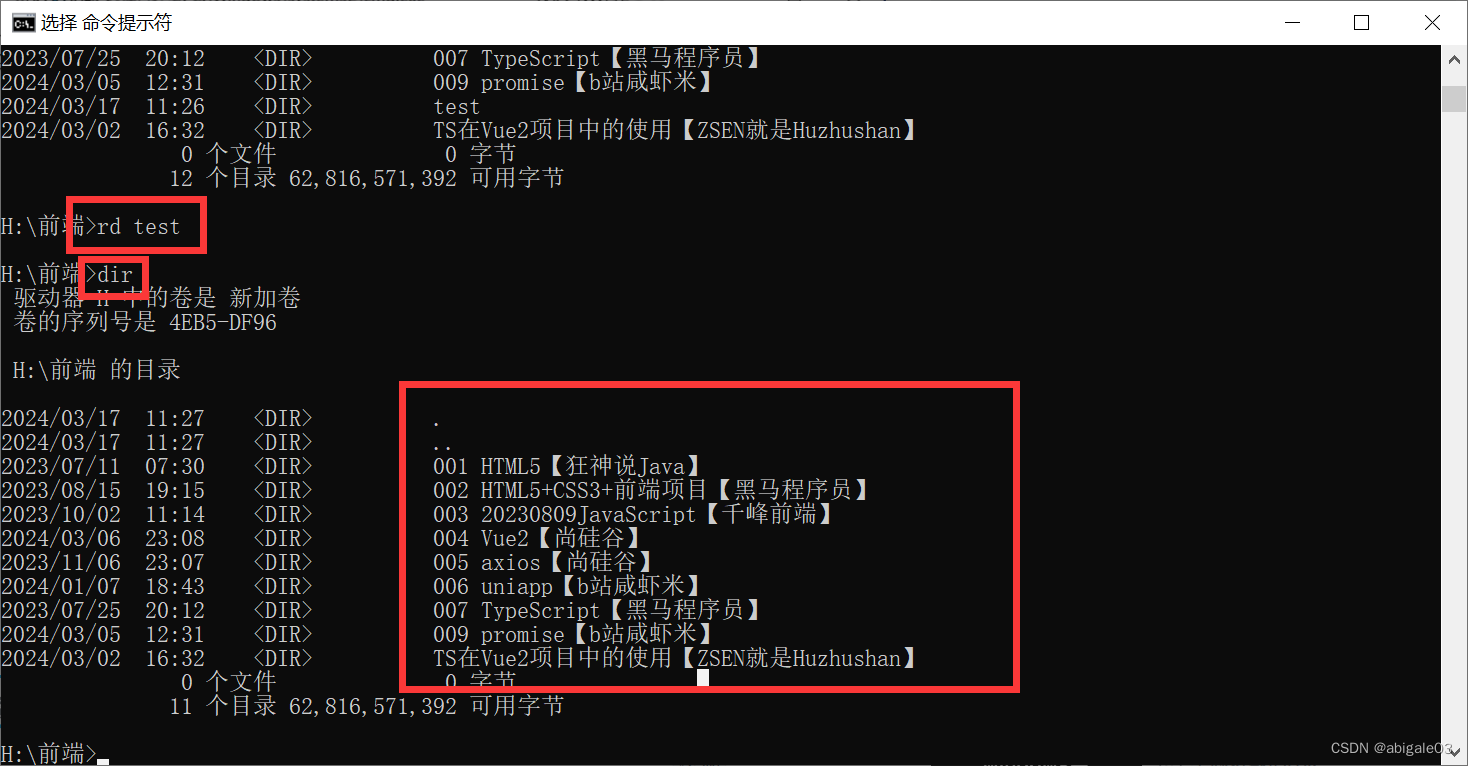
cmd常用指令
cmd全称Command Prompt,中文译为命令提示符。 命令提示符是在操作系统中,提示进行命令输入的一种工作提示符。 在不同的操作系统环境下,命令提示符各不相同。 在windows环境下,命令行程序为cmd.exe,是一个32位的命令…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...
uniapp 小程序 学习(一)
利用Hbuilder 创建项目 运行到内置浏览器看效果 下载微信小程序 安装到Hbuilder 下载地址 :开发者工具默认安装 设置服务端口号 在Hbuilder中设置微信小程序 配置 找到运行设置,将微信开发者工具放入到Hbuilder中, 打开后出现 如下 bug 解…...
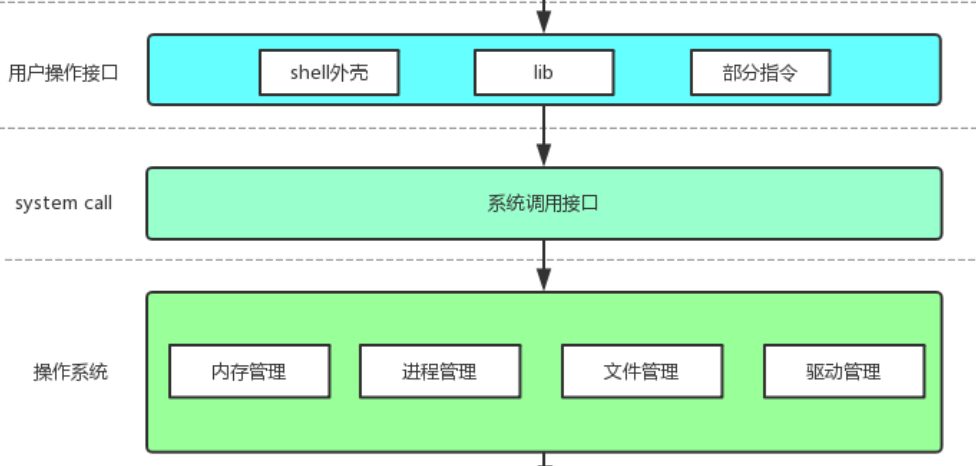
【Linux手册】探秘系统世界:从用户交互到硬件底层的全链路工作之旅
目录 前言 操作系统与驱动程序 是什么,为什么 怎么做 system call 用户操作接口 总结 前言 日常生活中,我们在使用电子设备时,我们所输入执行的每一条指令最终大多都会作用到硬件上,比如下载一款软件最终会下载到硬盘上&am…...

Ubuntu系统复制(U盘-电脑硬盘)
所需环境 电脑自带硬盘:1块 (1T) U盘1:Ubuntu系统引导盘(用于“U盘2”复制到“电脑自带硬盘”) U盘2:Ubuntu系统盘(1T,用于被复制) !!!建议“电脑…...
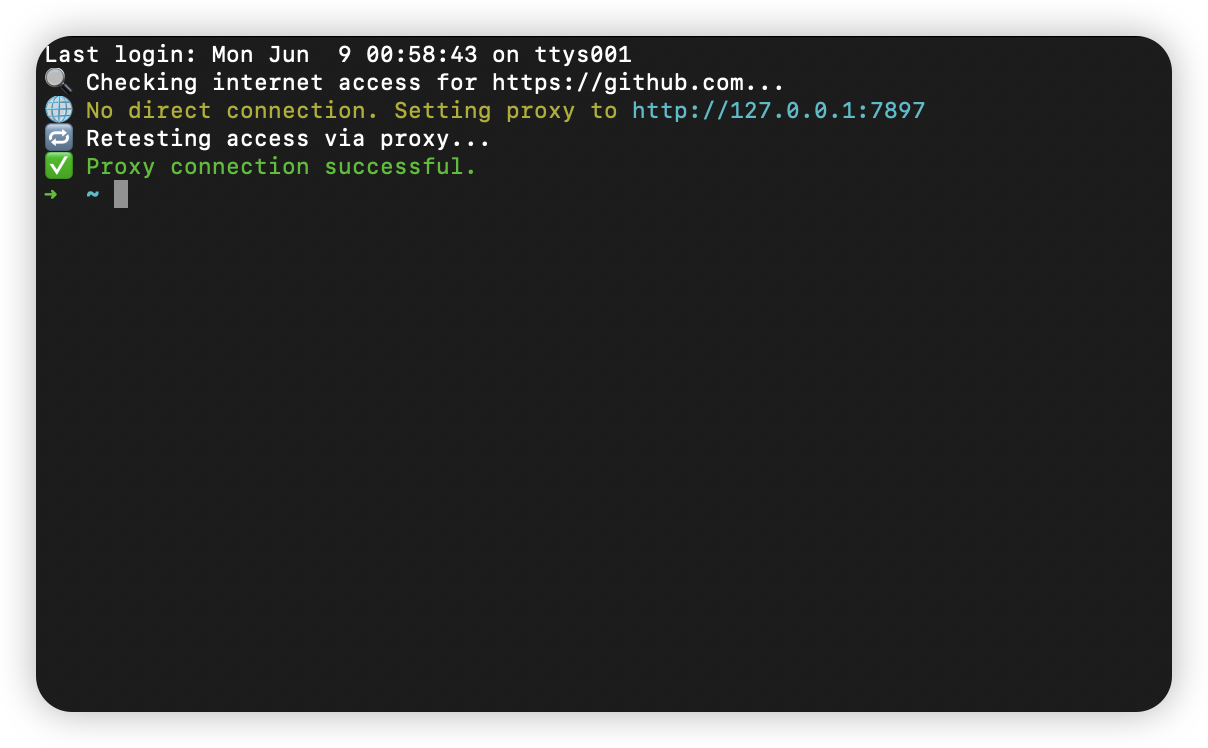
macOS 终端智能代理检测
🧠 终端智能代理检测:自动判断是否需要设置代理访问 GitHub 在开发中,使用 GitHub 是非常常见的需求。但有时候我们会发现某些命令失败、插件无法更新,例如: fatal: unable to access https://github.com/ohmyzsh/oh…...

拟合问题处理
在机器学习中,核心任务通常围绕模型训练和性能提升展开,但你提到的 “优化训练数据解决过拟合” 和 “提升泛化性能解决欠拟合” 需要结合更准确的概念进行梳理。以下是对机器学习核心任务的系统复习和修正: 一、机器学习的核心任务框架 机…...