基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的障碍物检测系统(深度学习代码+UI界面+训练数据集)
摘要:开发障碍物检测系统对于道路安全性具有关键作用。本篇博客详细介绍了如何运用深度学习构建一个障碍物检测系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5,展示了不同模型间的性能指标,如mAP、F1 Score等。文章深入解释了YOLOv8的原理,提供了相应的Python代码、训练数据集,并集成了一个基于PySide6的界面。
系统能够精准检测和分类障碍物,支持通过图片、图片文件夹、视频文件及摄像头进行检测,包含柱状图分析、标记框类别、类别统计、可调Conf、IOU参数和结果可视化等功能。还设计了基于SQLite的用户管理界面,支持模型切换和UI自定义。本文旨在为深度学习初学者提供实用指导,代码和数据集见文末。本文结构如下:
文章目录
- 前言
- 1. 数据集介绍
- 2. 系统界面效果
- 3. YOLOv8算法原理
- 4. 代码简介
- 4.1 模型预测
- 4.2 模型训练
- 4.3 YOLOv5、YOLOv6、YOLOv7和YOLOv8对比
- 4.4 代码实现
- 5. 障碍物检测系统实现
- 5.1 系统设计思路
- 5.2 登录与账户管理
- 下载链接
- 6. 总结与展望
- 结束语
➷点击跳转至文末所有涉及的完整代码文件下载页☇
基于深度学习的障碍物检测系统演示与介绍(YOLOv8/v7/v6/v5模型+PySide6界面+训练数据集)
前言
在当今社会,障碍物检测系统在多个领域扮演着不可或缺的角色,特别是在自动驾驶、智能监控、机器人导航以及无人机航拍等技术的快速发展过程中。这些系统能够有效识别和定位环境中的障碍物,从而为自动化决策提供重要信息,确保操作安全和效率。障碍物检测不仅关乎技术的进步,更是推动智能化社会发展的关键。例如,在自动驾驶领域,准确的障碍物检测能够显著减少交通事故,提高道路安全性。在工业应用中,障碍物检测能够提升机器人的工作效率和灵活性,使其能够在复杂环境下自主作业。

近年来,基于深度学习的障碍物检测技术取得了显著进展,尤其是YOLO(You Only Look Once)系列算法的发展,为实时障碍物检测提供了强大的技术支持。从YOLOv11到最新的YOLOv8,每一个版本的更新都在检测速度、准确性以及模型鲁棒性方面带来了突破。这些算法通过单次前向传播即可完成目标检测任务,大幅提高了处理速度,使得实时障碍物检测成为可能。
此外,Transformer-based的检测算法,如DETR(Detection Transformer)和其后续改进版本,通过引入Transformer架构,实现了对目标检测流程的简化,消除了对锚点的依赖,提供了一种全新的视角来理解障碍物检测问题。
在数据集方面,从早期的PASCAL VOC到COCO,再到最近的Open Images和Google’s Waymo Open Dataset,随着数据集规模的增加和多样性的提升,使得模型训练更加充分,进一步提高了障碍物检测的性能。特别是在自动驾驶领域,高质量的数据集如KITTI和Waymo Open Dataset提供了丰富的场景和障碍物信息,为研究人员提供了验证和测试算法的平台。
尽管取得了显著进展,障碍物检测技术仍面临着众多挑战,如在极端天气条件下的检测能力、小目标的识别问题、以及动态场景下的实时性问题等。这些挑战要求算法不仅要具备高准确性,还需要能够适应各种复杂多变的环境条件。为此,研究人员正在探索融合多模态信息(如雷达、激光雷达与视觉信息的结合)、利用更深层次的网络架构、以及引入注意力机制等先进技术,以提升检测算法的鲁棒性和适应性。
本博客所做的工作是基于YOLOv8算法构建一个障碍物检测系统,展示系统的界面效果,详细阐述其算法原理,提供代码实现,以及分享该系统的实现过程。希望本博客的分享能给予读者一定的启示,推动更多的相关研究。本文的主要贡献如下:
- 采用最先进的YOLOv8算法进行障碍物检测,并与YOLOv72、YOLOv63、YOLOv54等算法进行比较:本文不仅采用了当前最先进的目标检测算法—YOLOv8进行障碍物检测,而且还详细比较了其与YOLOv7、YOLOv6、YOLOv5等算法的性能差异。通过这种对比,我们不仅展示了YOLOv8在效率和精准度上的优势,而且为读者提供了一种量化分析不同算法性能的方法。
- 利用PySide6实现障碍物检测系统的用户界面:通过采用Python的PySide6库,本文展示了如何开发一个既美观又友好的用户界面,使得用户能够更直观、便捷地使用障碍物检测系统。这不仅促进了YOLOv8算法的应用,也推动了障碍物检测技术的实际应用进程。
- 包含登录管理功能,提升系统安全性:本文在系统设计中加入了登录管理功能,旨在提升系统的安全性,并为未来添加更多个性化功能铺垫基础。这一创新点不仅增强了系统的安全保护,也为用户提供了更加个性化的使用体验。
- 对YOLOv8模型进行深入研究:本文不仅应用了YOLOv8算法进行障碍物检测,而且还对该算法的性能进行了全面的评估,包括精准度、召回率等关键指标的详细分析。这种深入的研究有助于读者更加全面地理解YOLOv8算法的性能,并为算法的进一步优化提供了实践基础。
- 提供完整的数据集和代码资源包:为了便于读者更好地理解和应用YOLOv8及其他版本算法在障碍物检测系统中的实践,本文提供了一套完整的数据集和代码资源包。这些资源不仅包括用于训练和测试的详细数据集,还有实现障碍物检测系统的完整代码,使读者能够直接复现实验结果,进而在此基础上进行进一步的研究和开发。
1. 数据集介绍
在本博客中,我们将深入探讨一个为障碍物检测系统设计的数据集,本数据集包含9172张图像,这些图像被分为7844张训练图像、865张验证图像以及463张测试图像,以确保算法能够在足够大的样本上学习并准确评估其性能。图像涵盖了从都市交通到人行道的多样场景,其中包括各类移动和固定障碍物,如汽车、电线杆、行人等。在预处理过程中,所有图像被统一调整至640x640像素的分辨率,即使这样的拉伸可能会改变原有的宽高比,但它确保了模型接收到的输入尺寸的一致性,这是多数先进的目标检测算法的标准要求。

我们的数据集类别分布表明了城市环境中障碍物出现的频率,其中汽车、电线杆和行人是最常见的三类。这一分布特点提示我们,在自动驾驶和智能监控等应用场景中,这些类别的高识别准确率是至关重要的。但同时,我们也注意到,一些类别如自行车和摩托车的样本数量较少,这可能影响模型对这些类别的检测性能,需要通过数据增强或过采样等技术来平衡类别分布。

通过边界框位置的分布图,我们发现大多数障碍物主要集中在图像的中心区域,这反映了图像采集时的一个常见偏差。对此,我们可以通过在数据增强过程中引入空间变换,如平移和旋转,以提升模型对图像边缘区域障碍物的检测能力。此外,边界框尺寸的分布表明数据集中存在大量小尺寸目标,这对目标检测算法来说是一个已知的挑战。因此,我们可能需要采用专门的算法优化或改进模型架构来提高对这些小目标的检测率。博主使用的类别代码如下:
Chinese_name = { "Bicycle": "自行车","Bus": "公共汽车","Car": "汽车", "Dog": "狗","Electric pole": "电线杆", "Motorcycle": "摩托车","Person": "人","Traffic signs": "交通标志","Tree": "树","Uncovered manhole": "井盖未盖"}
综上所述,我们的数据集不仅通过数量和多样性来支持模型的训练,而且也通过细致的预处理和增强处理来确保算法能够适应真实世界的复杂性。数据集中详尽的标注信息将有助于训练阶段的监督学习,而类别和尺寸的分布分析则为我们在数据集增强和模型设计上提供了宝贵的指导。通过对这个数据集的深入研究,我们期望提升障碍物检测系统的性能,同时为该领域的研究和应用贡献出更加精确、高效的检测技术。
2. 系统界面效果
系统以PySide6作为GUI库,提供了一套直观且友好的用户界面。下面,我将详细介绍各个主要界面的功能和设计。
(1)系统提供了基于SQLite的注册登录管理功能。用户在首次使用时需要通过注册界面进行注册,输入用户名和密码后,系统会将这些信息存储在SQLite数据库中。注册成功后,用户可以通过登录界面输入用户名和密码进行登录。这个设计可以确保系统的安全性,也为后续添加更多个性化功能提供了可能性。

(2)在主界面上,系统提供了支持图片、视频、实时摄像头和批量文件输入的功能。用户可以通过点击相应的按钮,选择要进行障碍物检测的图片或视频,或者启动摄像头进行实时检测。在进行检测时,系统会实时显示检测结果,并将检测记录存储在数据库中。

(3)此外,系统还提供了一键更换YOLOv8模型的功能。用户可以通过点击界面上的"更换模型"按钮,选择不同的YOLOv8模型进行检测。与此同时,系统附带的数据集也可以用于重新训练模型,以满足用户在不同场景下的检测需求。

(4)为了提供更个性化的使用体验,这里系统支持界面修改,用户可以自定义图标、文字等界面元素。例如,用户可以根据自己的喜好,选择不同风格的图标,也可以修改界面的文字描述。

3. YOLOv8算法原理
YOLOv8算法作为最新一代的快速目标检测系统,它是YOLO系列算法的最新迭代。YOLO的全称是"You Only Look Once",这体现了其设计理念——即在目标检测任务中实现快速且准确的目标定位与分类。与之前的版本相比,YOLOv8进一步优化了算法架构,并集成了多项最新技术,以提高检测的准确率与速度。
YOLOv8的整体架构分为三个主要部分:Backbone(主干网络)、Neck(连接网络)和Head(检测头)。在Backbone部分,YOLOv8采用了CSP(Cross Stage Partial networks)结构,这种结构的设计旨在平衡网络的参数量与计算效率,CSP结构通过部分地交叉连接特征层,使得在较低的计算成本下,网络能够更有效地学习到特征的多样性。这种设计不仅提高了特征的表征能力,而且减少了计算资源的需求,使得模型更适合在资源受限的环境中部署。

在YOLOv8的设计中,Neck部分采用了空间金字塔池化(Spatial Pyramid Pooling, SPP)和特征金字塔网络(Feature Pyramid Networks, FPN)的策略来进一步提升目标检测的性能。SPP模块的引入可以有效地解决输入图像尺寸固定的限制,允许网络在不同尺寸的特征图上执行池化操作,这确保了即使在输入尺寸变化时,网络也能维持输出特征的空间尺度。而FPN则通过融合多个不同分辨率的特征图来增强模型对多尺度目标的检测能力,尤其是小尺寸目标的识别。
YOLOv8算法还采用了自适应标签分配(adaptive label assignment)机制,这是一个较为新颖的设计。在传统的目标检测算法中,通常是根据固定的规则来分配正负样本,但这种方法可能并不总是最优的。自适应标签分配机制通过学习的方式动态调整正负样本的分界线,可以根据实际模型在训练过程中的表现来决定样本标签,这样的策略更加灵活,可以提高模型对各种复杂场景的适应能力。
在模型训练过程中,YOLOv8还采用了AutoML技术,进一步优化模型结构和超参数。通过机器学习的方法来自动调整网络结构和参数设置,YOLOv8能够更加精确地适配于特定的任务和数据集。此外,自动化的训练流程也降低了模型调优的门槛,允许研究者和开发者在较短的时间内获得更好的性能。
从技术实现的角度来看,YOLOv8在结合先进的网络结构和自适应策略的同时,也在算法的效率和实用性上做出了考量。随着深度学习技术的不断进步,YOLOv8的这些创新特性显著提升了障碍物检测的准确率和实时性,使其成为目前目标检测技术中的先进算法之一。
4. 代码简介
在本节中,我们将详细介绍如何使用YOLOv8进行障碍物检测的代码实现。代码主要分为两部分:模型预测和模型训练。
4.1 模型预测
在模型预测部分,首先导入了OpenCV库和YOLO模型。OpenCV库是一个开源的计算机视觉和机器学习软件库,包含了众多的视觉处理函数,使用它来读取和处理图像。YOLO模型则是要用到的目标检测模型。
import cv2
from ultralytics import YOLO
接着,加载自行训练好的YOLO模型。这个模型是在大量的图像上预训练得到的,可以直接用于目标检测任务。
model.load_model(abs_path("weights/best-yolov8n.pt", path_type="current"))
然后,使用OpenCV读取了一个图像文件,这个图像文件作为要进行目标检测的图像输入。
img_path = abs_path("test_media/1.jpg")
image = cv_imread(img_path)
在读取了图像文件之后,将图像大小调整为850x500,并对图像进行预处理,就可以使用模型进行预测了。
image = cv2.resize(image, (850, 500))
pre_img = model.preprocess(image)
pred, superimposed_img = model.predict(pre_img)

4.2 模型训练
在本博客中,我们将深入探讨如何利用先进的深度学习模型YOLOv8,构建一个高效精准的障碍物检测系统。我们将从头开始,逐步解析涉及到的代码片段,分享如何准备环境、加载模型以及执行训练等关键步骤。
首先,我们需要确保我们的编程环境已经配置好所有必要的库。这包括操作系统接口库os,我们的深度学习工具库torch,以及用于解析配置文件的yaml库。这些库是构建和训练深度学习模型不可或缺的部分。导入这些库之后,我们将使用一个来自ultralytics的YOLO模块,它提供了一个预先构建好的YOLOv8模型,以便我们可以直接使用。紧接着,我们设置了训练将要在哪个设备上进行,这是通过检查是否有CUDA可用来决定的。
import osimport torch
import yaml
from ultralytics import YOLO # 导入YOLO模型
from QtFusion.path import abs_path
device = "cuda:0" if torch.cuda.is_available() else "cpu"
接着,我们定义了一些基本的训练参数,如工作进程数workers和批次大小batch。这些参数对训练过程至关重要,因为它们直接影响了数据的加载速度以及模型的训练效率。为了训练模型,我们需要加载数据集的配置文件。这个配置文件包含了训练模型时所需要的关键信息,如类别标签和图像的路径。代码通过abs_path函数获取了数据集配置文件的绝对路径,然后将其转换为UNIX风格的路径,这有助于防止跨平台时路径表示的差异问题。
workers = 1
batch = 8data_name = "Obstacle"
data_path = abs_path(f'datasets/{data_name}/{data_name}.yaml', path_type='current') # 数据集的yaml的绝对路径
unix_style_path = data_path.replace(os.sep, '/')# 获取目录路径
directory_path = os.path.dirname(unix_style_path)')
随后,我们读取并更新了YAML配置文件,将其path项指向正确的目录。这一步骤确保我们的训练模型可以正确地访问到数据集的位置。
# 读取YAML文件,保持原有顺序
with open(data_path, 'r') as file:data = yaml.load(file, Loader=yaml.FullLoader)
# 修改path项
if 'path' in data:data['path'] = directory_path# 将修改后的数据写回YAML文件with open(data_path, 'w') as file:yaml.safe_dump(data, file, sort_keys=False)
在加载预训练模型的部分,我们加载了预训练模型,随后启动了训练过程。这部分代码通过指定数据集配置文件路径、训练设备、工作进程数、图像尺寸、训练周期和批次大小等参数,调用了model.train方法来开始训练。
model = YOLO(abs_path('./weights/yolov5nu.pt', path_type='current'), task='detect') # 加载预训练的YOLOv8模型
# model = YOLO('./weights/yolov5.yaml', task='detect').load('./weights/yolov5nu.pt') # 加载预训练的YOLOv8模型
# Training.
results = model.train( # 开始训练模型data=data_path, # 指定训练数据的配置文件路径device=device, # 自动选择进行训练workers=workers, # 指定使用2个工作进程加载数据imgsz=640, # 指定输入图像的大小为640x640epochs=120, # 指定训练100个epochbatch=batch, # 指定每个批次的大小为8name='train_v5_' + data_name # 指定训练任务的名称
)model = YOLO(abs_path('./weights/yolov8n.pt'), task='detect') # 加载预训练的YOLOv8模型
results2 = model.train( # 开始训练模型data=data_path, # 指定训练数据的配置文件路径device=device, # 自动选择进行训练workers=workers, # 指定使用2个工作进程加载数据imgsz=640, # 指定输入图像的大小为640x640epochs=120, # 指定训练100个epochbatch=batch, # 指定每个批次的大小为8name='train_v8_' + data_name # 指定训练任务的名称
)
在障碍物检测领域,对训练过程的损失函数进行分析是至关重要的。它不仅反映了模型学习的状况,还指示了模型的性能可能存在的问题。
首先,我们看到训练集和验证集的box_loss,即定位损失,都随着训练过程逐渐下降,这是一个良好的迹象,表明模型在逐渐学习如何准确地定位图像中的物体。特别是在训练初期,损失下降得非常迅速,随着时间的推移,这种下降趋势放缓,但整体上保持了稳定的下降。这反映了模型参数在经过反复迭代后,正逐步趋于最优解。接着我们看到cls_loss,分类损失,这反映了模型在对物体进行分类时的性能。同样,训练和验证集上的分类损失都持续减少,并趋于平稳。一般来说,较低的分类损失意味着模型在区分不同类别的物体上做得越来越好。尽管如此,我们也注意到验证集上的损失稍高于训练集,这可能暗示着模型在训练数据上的表现比在未见过的数据上要好。
对于df1_loss,它可能代表一个合成的损失指标,通常包括了定位损失和分类损失的结合,或者可能是一个特定于YOLOv8模型的损失函数。这个指标的下降趋势与之前提到的box_loss和cls_loss类似,进一步验证了模型整体上在学习过程中的改善。

精度指标部分,precision和recall对于目标检测模型来说至关重要。精度指标表明了模型预测为正类别的样本中实际为正的比例,而召回率则表示所有正样本中被模型正确预测出来的比例。图中,我们看到训练过程中的精度在经历初期的波动之后逐渐趋于稳定,而召回率则在经过一个显著的上升后趋于稳定,这表明模型在保持较高水平的精确性的同时,也能找到大多数正样本。
最后,mAP50和mAP50-95作为评价目标检测算法的重要指标,分别表示在IoU阈值为0.5时的平均精度,和在IoU阈值从0.5到0.95不同阈值下平均精度的均值。从这两个指标的曲线我们可以看出,模型在IoU阈值为0.5时表现较好,随着阈值增加到0.95,模型表现出的平均精度有所下降。这表明模型对于定位精度要求较高的情况仍有提升空间,但整体上性能表现是令人满意的。
在深度学习模型的评估过程中,精确度-召回率(Precision-Recall,简称PR)曲线是衡量模型性能的重要工具,特别是在目标检测任务中,它能够揭示模型对于不同类别目标检测能力的细致情况。根据提供的PR曲线图,我们可以对YOLOv8模型在障碍物检测任务上的性能进行专业分析。

PR曲线图中每条曲线代表一个类别的性能,曲线下的面积(AUC)越大,表明模型在该类别上的性能越好。根据上图,我们可以看到不同类别的精度和召回率表现出明显的差异。例如,对于“Bus”(巴士)和“Dog”(狗)这两个类别,模型展示出非常高的精度,这可以从它们的PR曲线紧贴右上角和对应的高数值可以看出,“Bus”和“Dog”的精度分别达到0.922和0.949。这意味着模型在大部分情况下能够准确地识别出这两类对象,并且当模型预测图像中有这些对象时,它通常是正确的。
然而,对于“Electric pole”(电线杆)这一类别,模型的表现则不尽如人意,精度仅为0.253。这表明模型在识别电线杆时存在较大的困难,可能是因为电线杆的形态多变或与背景融合度较高,导致模型在这一类别上的预测既不准确也不可靠。这也提示我们,在后续的模型训练和优化中,需要对电线杆这一类别的数据进行增强,或是改进模型架构以提升其识别能力。对于“Person”(行人)和“Traffic signs”(交通标志)这两个类别,模型的精度分别为0.578和0.597,表现出一定的检测能力,但仍有提升空间。行人的检测在安全相关的应用中尤为关键,而交通标志的正确识别对于自动驾驶系统来说同样重要,这些结果指出我们需要对这些类别采取特别关注,可能需要进一步调整模型训练策略,或者收集更多多样化和难度较高的数据来提高模型的鲁棒性。
总的来说,模型的整体mAP@0.5为0.732,表明在IoU阈值为0.5时,模型的平均性能已经相对较好。然而,模型在各个类别上的性能还是存在明显差异,这提醒我们在训练过程中需要针对性地对不同类别进行优化,以期达到更均衡和提升的目标检测性能。通过继续深入分析模型在不同类别上的表现,我们可以找到模型的弱点,并据此采取措施进行改进,从而让我们的障碍物检测系统更加可靠和强大。
4.3 YOLOv5、YOLOv6、YOLOv7和YOLOv8对比
(1)实验设计:

本实验旨在评估和比较YOLOv5、YOLOv6、YOLOv7和YOLOv8几种模型在障碍物检测任务上的性能。为了实现这一目标,博主分别使用使用相同的数据集训练和测试了这四个模型,从而可以进行直接的性能比较。本文将比较分析四种模型,旨在揭示每种模型的优缺点,探讨它们在工业环境中实际应用的场景选择。
| 模型 | 图像大小 (像素) | mAPval 50-95 | CPU ONNX 速度 (毫秒) | A100 TensorRT 速度 (毫秒) | 参数数量 (百万) | FLOPs (十亿) |
|---|---|---|---|---|---|---|
| YOLOv5nu | 640 | 34.3 | 73.6 | 1.06 | 2.6 | 7.7 |
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv6N | 640 | 37.5 | - | - | 4.7 | 11.4 |
| YOLOv7-tiny | 640 | 37.4 | - | - | 6.01 | 13.1 |
(2)度量指标:
- F1-Score:F1-Score是精确率(Precision)和召回率(Recall)的调和平均值。精确率是指模型正确识别的正例与所有识别为正例的案例之比,而召回率是指模型正确识别的正例与所有实际正例之比。F1-Score对于不平衡的数据集或者需要同时考虑精确率和召回率的任务特别重要。
- mAP(Mean Average Precision):mAP是衡量模型在多个类别上平均检测准确度的指标。它计算了模型在所有类别上的平均精度,是目标检测领域中常用的性能度量。
| 名称 | YOLOv5nu | YOLOv6n | YOLOv7-tiny | YOLOv8n |
|---|---|---|---|---|
| mAP | 0.732 | 0.675 | 0.700 | 0.732 |
| F1-Score | 0.73 | 0.66 | 0.70 | 0.72 |
(3)实验结果分析:
在本节中,我们将深入分析并比较在同一数据集上应用不同版本的YOLO算法——YOLOv5nu、YOLOv6n、YOLOv7-tiny和YOLOv8n——的性能表现。评估标准采用了两个核心的度量指标:平均精度均值(mAP)和F1-Score。这两个指标广泛用于目标检测领域,以衡量模型在识别任务中的准确性和鲁棒性。
首先,我们来看mAP,这个指标考虑了所有类别、所有检测难度的平均表现,因此是模型性能的综合反映。从实验结果来看,YOLOv5nu和YOLOv8n展示出了最佳的mAP,为0.732,而YOLOv6n的mAP为0.675,性能略低于其他版本。YOLOv7-tiny的mAP为0.700,介于两者之间。这些数据表明,最新版本的YOLOv8n在维持YOLOv5nu较高性能的同时,可能引入了改进的架构或优化算法,提高了其精度。
接着我们分析F1-Score,这是精确率和召回率的调和平均数,更侧重于模型的准确性和召回能力的平衡。在这方面,YOLOv5nu和YOLOv7-tiny的表现较为接近,分别为0.73和0.70,而YOLOv8n的F1-Score略低于YOLOv5nu,为0.72。这表明在精确率和召回率之间的平衡上,YOLOv5nu可能略占优势。YOLOv6n的F1-Score为0.66,是四个版本中最低的,这可能意味着其在准确性或召回率上存在一些不足。

从这些数据中我们可以观察到,虽然YOLOv8n在mAP上有优异的表现,但其F1-Score并未完全领先,这可能是因为YOLOv8n在处理某些类别或场景时,牺牲了一些召回率以换取更高的精确率。而YOLOv5nu则在两个指标上都表现良好,说明它在平衡精确率和召回率方面做得较为出色。YOLOv7-tiny作为轻量级版本,其性能表现超越了YOLOv6n,并与YOLOv5nu持平,展示了其设计上的优化。
综上所述,YOLOv5nu和YOLOv8n在性能上相对更优,而YOLOv6n则略显逊色。这样的比较结果对于实际应用场景选择合适的YOLO版本具有指导意义。尽管YOLOv8n在最新的mAP表现上达到了顶尖水平,但是在实际部署中,我们还需考虑模型的整体表现,包括F1-Score所代表的精确率和召回率平衡,以确保模型在各种情况下都能有可靠的表现。此外,对于资源受限的环境,YOLOv7-tiny以较好的性能和更低的资源需求,可能是一个合适的选择。通过这样的全面对比分析,我们可以为不同需求的使用场景提供更为精准的模型选择建议。
4.4 代码实现
在本篇博客中,我们将探讨如何利用Python语言和YOLOv8模型进行高效的障碍物检测。障碍物检测在自动驾驶、监控系统以及机器人导航等众多领域都有着至关重要的应用。通过本教程,我们将深入了解在这些应用中如何实现实时且准确的目标检测。
(1)引入必要的库
首先,我们从导入必要的Python库开始,这是编写任何Python程序的第一步。通过引入random库,我们为每个检测类别生成唯一的颜色,以便在可视化检测结果时能够清晰区分不同的目标。同样,sys和time库分别允许我们访问Python解释器的变量和函数,以及处理与时间相关的功能。为了提高障碍物检测系统的互动性,我们利用了PySide6库来创建图形用户界面,cv2库为我们处理和分析图像提供了强大的工具。
import random # 导入random模块,用于生成随机数
import sys # 导入sys模块,用于访问与Python解释器相关的变量和函数
import time # 导入time模块,用于处理时间
from QtFusion.config import QF_Config
import cv2 # 导入OpenCV库,用于处理图像
from QtFusion.widgets import QMainWindow # 从QtFusion库中导入FBaseWindow类,用于创建窗口
from QtFusion.utils import cv_imread, drawRectBox # 从QtFusion库中导入cv_imread和drawRectBox函数,用于读取图像和绘制矩形框
from PySide6 import QtWidgets, QtCore # 导入PySide6库中的QtWidgets和QtCore模块,用于创建GUI
from QtFusion.path import abs_path
from YOLOv8Model import YOLOv8Detector # 从YOLOv8Model模块中导入YOLOv8Detector类,用于加载YOLOv8模型并进行目标检测
from datasets.Obstacle.label_name import Label_listQF_Config.set_verbose(False)
(2)初始化模型
在加载模型和创建窗口类的过程中,我们首先初始化了一个YOLOv8检测器实例,并加载了预先训练好的模型权重。这一步骤是关键的,因为它为后续的图像检测奠定了基础。
cls_name = Label_list # 定义类名列表
colors = [[random.randint(0, 255) for _ in range(3)] for _ in range(len(cls_name))] # 为每个目标类别生成一个随机颜色model = YOLOv8Detector() # 创建YOLOv8Detector对象
model.load_model(abs_path("weights/best-yolov8n.pt", path_type="current")) # 加载预训练的YOLOv8模型
(3)设置主窗口
在我们的MainWindow类中,我们定义了窗口的大小、布局以及如何响应键盘事件。这为用户提供了一个简洁的界面,用以展示检测结果,并在需要时通过按键退出程序。
class MainWindow(QMainWindow): # 定义MainWindow类,继承自FBaseWindow类def __init__(self): # 定义构造函数super().__init__() # 调用父类的构造函数self.resize(640, 640) # 设置窗口的大小self.label = QtWidgets.QLabel(self) # 创建一个QLabel对象self.label.setGeometry(0, 0, 640, 640) # 设置QLabel的位置和大小def keyPressEvent(self, event): # 定义keyPressEvent函数,用于处理键盘事件if event.key() == QtCore.Qt.Key.Key_Q: # 如果按下的是Q键self.close() # 关闭窗口
(4)主程序流程
在主函数中,我们初始化了应用程序并创建了MainWindow的一个实例。然后我们读取了一个图像,并使用OpenCV库调整其大小。这个图像将被用作模型的输入。为了提高处理速度,我们对图像进行了预处理,以满足YOLOv8模型的输入要求。
app = QtWidgets.QApplication(sys.argv) # 创建QApplication对象
window = MainWindow() # 创建MainWindow对象img_path = abs_path("test_media/NightVehicle_SIXU_A04005.jpg") # 定义图像文件的路径
image = cv_imread(img_path) # 使用cv_imread函数读取图像image = cv2.resize(image, (850, 500)) # 将图像大小调整为850x500
pre_img = model.preprocess(image) # 对图像进行预处理
然后,我们进行了一系列操作,包括图像的读取、预处理、通过模型进行推理和后处理。最后,我们将处理好的图像显示在用户界面上,并计算了整个推理过程所需的时间。
t1 = time.time() # 获取当前时间(开始时间)
pred = model.predict(pre_img) # 使用模型进行预测
t2 = time.time() # 获取当前时间(结束时间)
use_time = t2 - t1 # 计算预测所用的时间det = pred[0] # 获取预测结果的第一个元素(检测结果)# 如果有检测信息则进入
if det is not None and len(det):det_info = model.postprocess(pred) # 对预测结果进行后处理for info in det_info: # 遍历检测信息# 获取类别名称、边界框、置信度和类别IDname, bbox, conf, cls_id = info['class_name'], info['bbox'], info['score'], info['class_id']label = '%s %.0f%%' % (name, conf * 100) # 创建标签,包含类别名称和置信度# 画出检测到的目标物image = drawRectBox(image, bbox, alpha=0.2, addText=label, color=colors[cls_id]) # 在图像上绘制边界框和标签print("推理时间: %.2f" % use_time) # 打印预测所用的时间
window.dispImage(window.label, image) # 在窗口的label上显示图像
# 显示窗口
window.show()
# 进入 Qt 应用程序的主循环
sys.exit(app.exec())
通过上述过程,我们不仅可以看到YOLOv8模型如何在实际场景中被应用,还能够对其检测性能进行准确的评估。每一步都紧密相扣,从为目标类别配色到图像的最终展示,每一环都是实现高效障碍物检测系统的重要组成部分。在未来的研究和应用中,这些细节对于进一步优化系统至关重要。
5. 障碍物检测系统实现
在实现一款实时障碍物检测系统时,我们采取了一种集成化的系统设计思路,力求打造一个既直观又高效的用户体验。我们的系统设计核心在于实现一个流畅的交互界面,以及快速准确的后端处理能力。
5.1 系统设计思路
我们的系统从界面到处理逻辑,都建立在紧密相连的模块上。前端界面,通过精心设计的MainWindow类提供,它不仅仅是展示结果的平台,更是用户交互的中心。界面上的每一个元素,从按钮到图像显示窗口,都经过了细致的考量,以确保用户可以轻松地导航并控制障碍物检测过程。

架构设计
我们的系统设计思路以三层架构为核心:处理层、界面层和控制层。在我们的系统设计中,重点放在了确保各个组件能够协同工作,同时保持足够的模块独立性,以便于未来的维护和升级。
- 处理层(Processing Layer):在处理层,我们集成了强大的YOLOv8Detector类,这是我们检测逻辑的核心。它搭载了先进的YOLOv8算法,可以快速识别并定位图像中的障碍物。我们通过精心编写的代码和算法优化,确保了即使在复杂的场景中,模型也能提供准确的检测结果。
- 界面层(UI Layer):界面层是用户与系统交流的“面孔”。我们设计的界面简洁直观,通过QtFusion库实现,它为用户提供了图像上传、结果展示和操作反馈等一系列交互功能。用户可以直接在界面上观察到模型的检测结果,这些结果以边界框的形式直观地标注在图像上,同时还显示了检测对象的类别和置信度。
- 控制层(Control Layer):我们利用PySide6框架强大的信号和槽机制。这使得用户界面(UI)层的任何操作,都可以无缝地触发控制层的响应。例如,当用户加载一张图像时,控制层会命令处理层的YOLOv8模型开始进行检测,处理完成后,检测结果会即时反馈至UI层,呈现在用户面前。

此外,我们的系统设计还特别考虑了扩展性和模块化。通过这种方式,当未来有新的模型或者处理逻辑出现时,我们可以轻松地将它们集成到现有系统中。整个系统不仅具备了强大的实时处理能力,同时也保持了足够的灵活性,以适应不断发展的技术需求。
综上所述,这个交互式障碍物检测系统是一个综合了前沿技术、优秀用户体验和高度可扩展性的系统。无论是对于研究人员探索新算法,还是对于实际应用中的工程师来说,它都提供了一个强有力的工作平台。
系统流程
在本篇博客中,我们深入探讨了构建一个高效的交互式障碍物检测系统的全流程,此系统基于强大的YOLOv8模型和用户友好的图形界面。从用户启动应用程序的那一刻起,我们的设计旨在提供一个无缝、直观且功能全面的体验。

- 用户的旅程开始于MainWindow类的实例化,这一过程不仅涉及界面的初始化,还包括了各种参数的配置。这个阶段是整个应用的基础,确保了用户能够拥有一个清晰、易操作的起点。我们的界面设计考虑到了用户的各种需求,无论是希望通过实时摄像头捕捉动态场景,还是分析已有的视频文件或静态图像,系统都能提供简单直接的方式进行选择和操作。
- 一旦输入源被用户选定,系统立刻行动起来,展开一系列的媒体处理任务。这些任务包括但不限于摄像头的实时配置、视频的逐帧读取或是图像文件的加载,所有这些都是在后台无缝进行,以确保用户的体验不受影响。
- 随着媒体输入的准备就绪,系统进入了核心阶段——连续帧的处理。在预处理阶段,系统通过对图像进行缩放、色彩空间的转换和归一化等操作,确保每一帧图像都满足YOLOv8模型的输入要求。紧接着,在检测与识别阶段,经过预处理的图像被送入YOLOv8模型进行精确的障碍物检测。这一步骤的结果不仅仅是标出障碍物的位置,还包括对障碍物类别的识别,为后续的分析和决策提供了重要依据。
- 在界面更新阶段,我们的系统展示了它真正的力量。随着检测结果的产出,界面实时更新以展示每个检测到的障碍物,并附上相应的类别标签。此外,系统还提供了丰富的交互操作,用户可以轻松保存检测结果、查询系统信息,甚至通过界面上的控件对检测结果进行进一步的筛选和分析。
- 媒体控制功能为用户提供了更高层次的操作自由度,用户可以随时启动或停止摄像头捕捉、视频播放或图像分析,这一切都可以通过简单直观的操作来完成。这种设计不仅大大增强了用户体验,也使得系统能够适应更多样化的应用场景。
综上所述,通过精心设计的系统流程和功能模块,我们的交互式障碍物检测系统不仅展现了YOLOv8模型的强大性能,同时也为用户提供了一个易于操作、功能丰富的平台。
5.2 登录与账户管理
在我们的障碍物检测系统中,一个重要的特点是我们为用户提供了一个完善的账户管理体系。这一体系基于PySide6构建的图形用户界面(GUI)和SQLite数据库后端,使用户能够轻松进行账户的注册、登录、密码修改、头像设置以及账户注销等操作。这种设计思路的主要目的是为了增强用户体验,让用户在使用障碍物检测系统时能够拥有更多的个性化和安全性。

用户首次使用系统时,将被引导至登录界面,这里他们可以选择注册新账户。注册过程简洁明了,只需要填写基本信息和设置密码即可。一旦注册成功,用户即可利用这些凭证登录系统。登录界面还提供了密码修改和头像设置的选项,这些小细节的关照使得每个用户的账户更加个性化,同时也增强了账户的安全性。
登录后,用户将进入主界面,这里是障碍物检测的操作核心。用户可以在这里选择输入源,包括静态图片、视频文件或实时摄像头捕获的图像。系统后端将调用媒体处理器和YOLOv8模型对输入源进行处理,实现实时的障碍物检测和识别。处理结果不仅会在界面上实时展示,用户还可以通过一系列交互操作,如保存检测结果到个人账户、查询检测历史记录等,这些操作都依托于用户账户进行管理。

我们的系统设计确保了用户界面的直观性和易用性,使用户可以毫不费力地管理自己的账户和检测任务。此外,用户还可以在登录界面进行账户注销操作,系统将清除用户的个人信息和保存的数据,保障用户隐私安全。我们通过这套账户管理体系,不仅为用户提供了便捷的服务,同时也确保了数据的安全性和私密性。
通过上述设计,我们的障碍物检测系统不仅在技术上实现了先进的目标检测功能,还在用户体验上提供了全面的考量。我们希望通过这种人性化的设计,使用户在享受障碍物检测技术带来的便利的同时,也能感受到系统对他们个人隐私和安全的重视。随着技术的不断进步和用户需求的不断变化,我们将继续优化和完善这一系统,以适应更广泛的应用场景和用户需求。
下载链接
若您想获得博文中涉及的实现完整全部资源文件(包括测试图片、视频,py, UI文件,训练数据集、训练代码、界面代码等),这里已打包上传至博主的面包多平台,见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:

完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件下载请见演示与介绍视频的简介处给出:➷➷➷
演示与介绍视频:https://www.bilibili.com/video/BV1ox421y76C/

在文件夹下的资源显示如下,下面的链接中也给出了Python的离线依赖包,读者可在正确安装Anaconda和Pycharm软件后,复制离线依赖包至项目目录下进行安装,另外有详细安装教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境配置教程;
离线依赖安装教程:https://www.bilibili.com/video/BV1hv421C7g8/
离线依赖库下载链接:https://pan.baidu.com/s/1y6vqa9CtRmC72SQYPh1ZCg?pwd=33z5 (提取码:33z5)
6. 总结与展望
在本博客中,我们详细介绍了一个基于YOLOv8模型的实时障碍物检测系统。系统以模块化的方式设计,充分采用了合理的架构设计,带来良好的可维护性和可扩展性。其用户界面友好,能够提供实时的障碍物检测和识别结果展示,同时支持用户账户管理,以便于保存和管理检测结果和设置。
该系统支持摄像头、视频、图像和批量文件等多种输入源,能够满足用户在不同场景下的需求。在后面可以添加更多预训练模型,增加检测和识别的种类;优化用户界面,增强个性化设置;并积极聆听用户反馈,以期不断改进系统,以更好地满足用户的需求。
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
Terven J, Cordova-Esparza D. A comprehensive review of YOLO: From YOLOv1 to YOLOv8 and beyond[J]. arXiv preprint arXiv:2304.00501, 2023. ↩︎
Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 7464-7475. ↩︎
Li C, Li L, Jiang H, et al. YOLOv6: A single-stage object detection framework for industrial applications[J]. arXiv preprint arXiv:2209.02976, 2022. ↩︎
Wu W, Liu H, Li L, et al. Application of local fully Convolutional Neural Network combined with YOLO v5 algorithm in small target detection of remote sensing image[J]. PloS one, 2021, 16(10): e0259283. ↩︎
相关文章:
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的障碍物检测系统(深度学习代码+UI界面+训练数据集)
摘要:开发障碍物检测系统对于道路安全性具有关键作用。本篇博客详细介绍了如何运用深度学习构建一个障碍物检测系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5,展示了不同模型间的性能…...

从零开始学HCIA之SDN04
1、VXLAN数据封装 (1)Original L2 Frame,原始以太网报文,业务应用的以太网帧。 (2)VXLAN Header,VXLAN协议新定义的VXLAN头,长度为8字节。VXLAN ID(VNI)为2…...

GET 和 POST 有什么区别?
1.从缓存的角度,GET 请求会被浏览器主动缓存下来,留下历史记录,而 POST 默认不会。 2.从编码的角度,GET 只能进行 URL 编码,只能接收 ASCII 字符,而 POST 没有限制。 3.从参数的角度,GET 一般放…...
Qt学习--继承(并以分文件实现)
基类 & 派生类 一个类可以派生自多个类,这意味着,它可以从多个基类继承数据和函数。定义一个派生类,我们使用一个类派生列表来指定基类。类派生列表以一个或多个基类命名。 总结:简单来说,父类有的,子…...

软考75-上午题-【面向对象技术3-设计模式】-设计模式的要素
一、题型概括 上午、下午题(试题五、试题六,二选一) 每一个设计模式都有一个对应的类图。 二、23种设计模式 创建型设计模式:5 结构型设计模式:7 行为设计模式:11 考试考1-2种。 三、设计模式的要素 3…...
Matlab|面向低碳经济运行目标的多微网能量互联优化调度
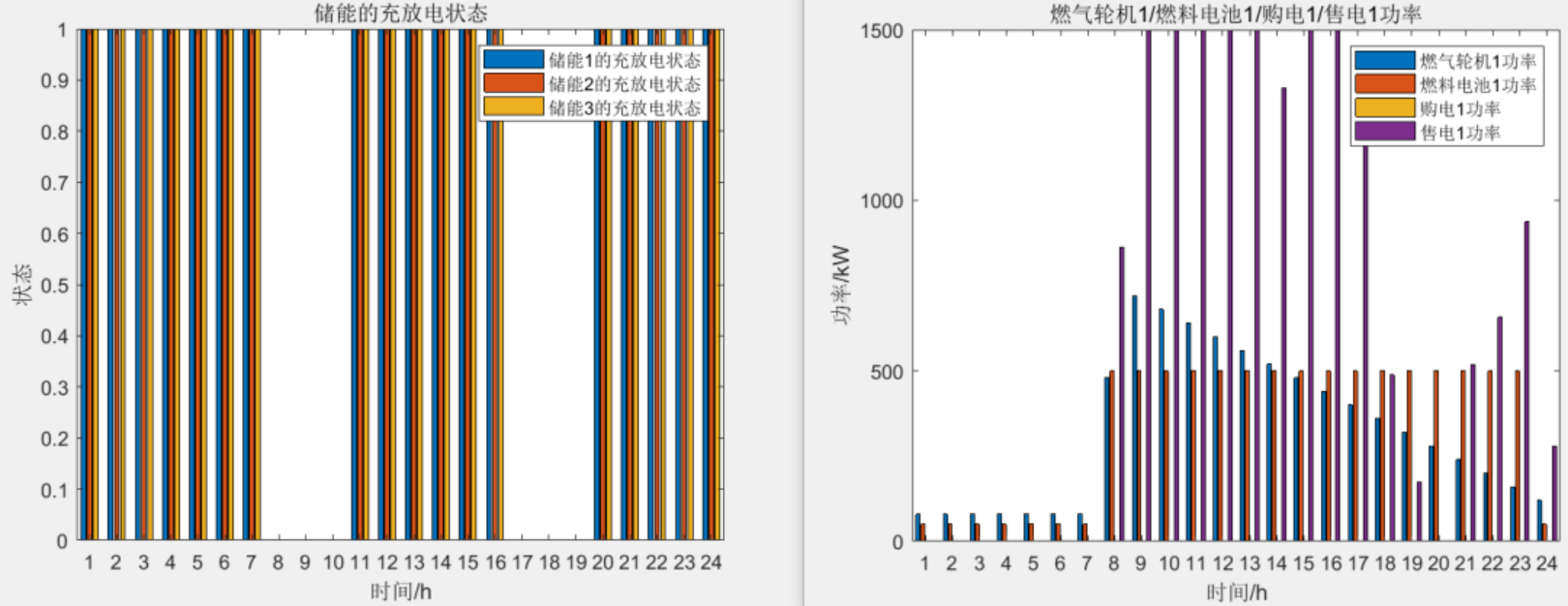
目录 主要内容 优化流程 部分程序 结果一览 下载链接 主要内容 该程序为多微网协同优化调度模型,系统在保障综合效益的基础上,调度时优先协调微网与微网之间的能量流动,将与大电网的互联交互作为备用,降低微网与大电…...
3.Gen<I>Cam文件配置
Gen<I>Cam踩坑指南 我使用的是大恒usb相机,第一步到其官网下载大恒软件安装包,安装完成后图标如图所示,之后连接相机,打开软件,相机显示一切正常。之后查看软件的安装目录如图,发现有GenICam和GenTL两个文件&am…...
用法详细介绍)
【兆易创新GD32H759I-EVAL开发板】 TLI(TFT LCD Interface)用法详细介绍
大纲 1. 引言 2. TLI外设特点 3. TLI硬件架构 4. TLI寄存器功能 5. TLI的配置和使用步骤 6. TLI图层概念 7. 图像处理和显示优化 8. 基于GD32H759I-EVAL开发板的TLI应用示例 1. 引言 在当今的嵌入式系统设计中,图形用户界面(GUI)的应…...
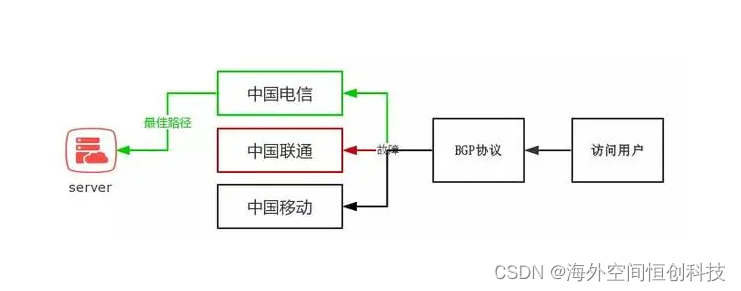
恒创科技:什么是BGP线路服务器?BGP机房的优点是什么?
在当今的互联网架构中,BGP(边界网关协议)线路服务器和BGP机房扮演着至关重要的角色。BGP作为一种用于在自治系统(AS)之间交换路由信息的路径向量协议,它确保了互联网上的数据能够高效、准确地从一个地方传输到另一个地方。那么,究竟什么是BGP…...
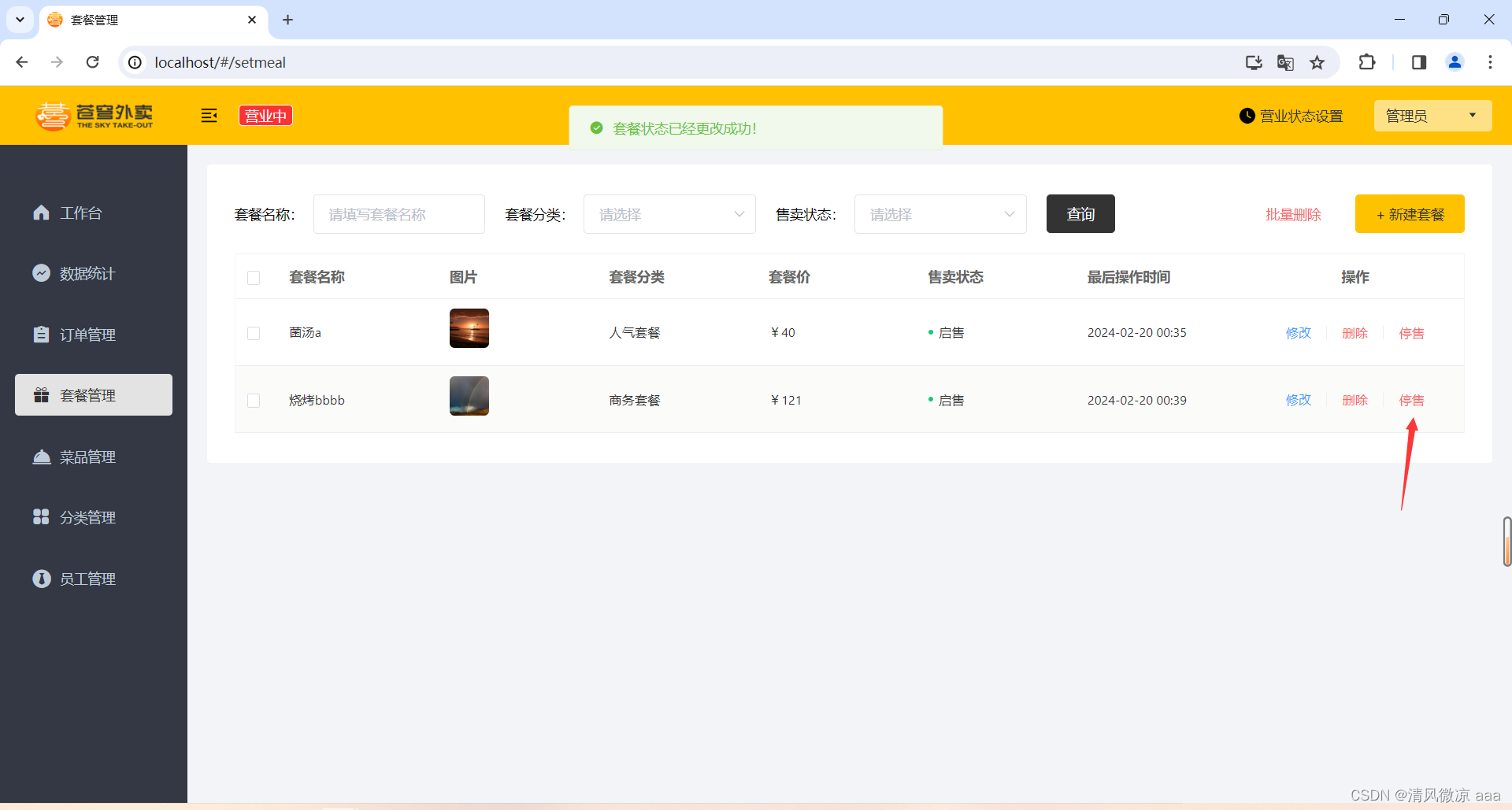
苍穹外卖-day04:项目实战-套餐管理(新增套餐,分页查询套餐,删除套餐,修改套餐,起售停售套餐)业务类似于菜品模块
苍穹外卖-day04 课程内容 新增套餐套餐分页查询删除套餐修改套餐起售停售套餐 要求: 根据产品原型进行需求分析,分析出业务规则设计接口梳理表之间的关系(分类表、菜品表、套餐表、口味表、套餐菜品关系表)根据接口设计进行代…...

深入探索C与C++的混合编程
实现混合编程的技术细节 混合使用C和C可能由多种原因驱动。一方面,现有的大量优秀C语言库为特定任务提供了高效的解决方案,将这些库直接应用于C项目中可以节省大量的开发时间和成本。另一方面,C的高级特性如类、模板和异常处理等,…...

数组中的flat方法如何实现
数组的成员有时还是数组,Array.prototype.flat()用于将嵌套的数组“拉平”,变成一维的数组。该方法返回一个新数组,对原数据没有影响。 [1, 2, [3, 4]].flat() // [1, 2, 3, 4]那flat怎么来实现呢? 1、使用while循环 实现的代码…...

计算机考研|北航北理北邮怎么选?
北航985,北理985,北邮211 虽然北邮事211,但是北邮的计算机实力一点也不弱,学科评级,计算机是A 北航计算机评级也是A,北理的计算机评级是A- 所以,这三所学校在实力上来说,真的大差…...
面试算法-52-对称二叉树
题目 给你一个二叉树的根节点 root , 检查它是否轴对称。 示例 1: 输入:root [1,2,2,3,4,4,3] 输出:true 解 class Solution {public boolean isSymmetric(TreeNode root) {return dfs(root, root);}public boolean dfs(Tr…...

独立维基和验收测试框架 Fitnesse 入门介绍
拓展阅读 junit5 系列教程 基于 junit5 实现 junitperf 源码分析 Auto generate mock data for java test.(便于 Java 测试自动生成对象信息) Junit performance rely on junit5 and jdk8.(java 性能测试框架。压测测试报告生成。) Fitnesse 完全集成的独立维基和验收测试…...
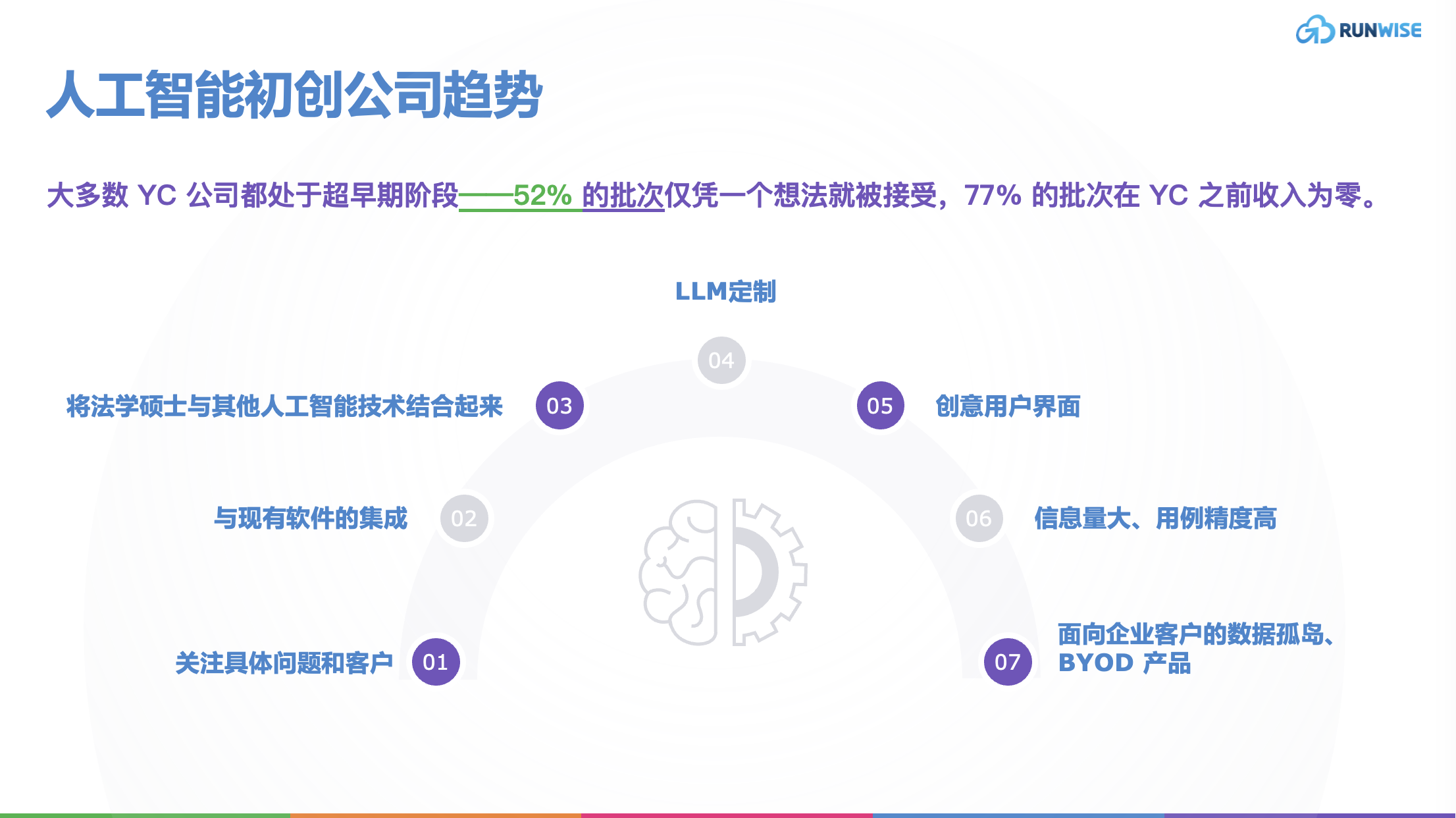
AI 初创公司趋势:Y Combinator 最新批次的见解
总部位于硅谷的著名创业加速器 Y Combinator (YC) 最近宣布了其 2023 年冬季队列,不出所料,约 31% 的初创公司(269 家中有 80 家)拥有自我报告的 AI 标签。在这篇文章中,我分析了这批 20-25 家初创公司,以了…...

tts语音合成原理
TTS(Text-to-Speech,文本到语音)语音合成技术是一种将文本数据转换为可听见的语音输出的技术。它允许计算机和其他电子设备读出文字信息,使得用户可以通过听的方式接收信息。TTS技术在无障碍服务、智能助手、语音导航、有声读物等…...

轮转数组题解
链接:189. 轮转数组 - 力扣(LeetCode) 这个题目很简单,因为说到了 k 是一个非负数,那么我们就可以 求模的时候就不用考虑的下标还会越界了,往右边 移动 其实就是当前下标 ik ,为了保证它能头尾相接并且不越…...
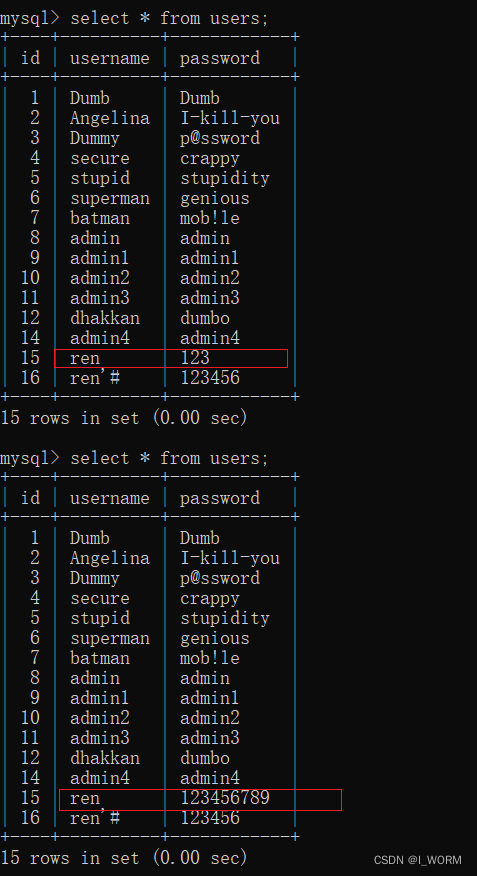
sqllab第二十四关通关笔记
知识点: 二次注入 先埋一个炸弹,然后通过其他路径引爆它 查看界面发现是一个登录框,尝试进行登录框的注入发现这里不存在注入点 那么就注册一个新的账户吧 通过点击注册,进入注册面板,注册一个新的账户 用户名为 re…...

web前端之多行文本擦除效果、文本逐个显示或展示、创建元素标签、querySelector、createElement、appendChild、requestAnimationFrame
MENU 版本一(requestAnimationFrame)版本二(setTimeout)版本三(css) 版本一(requestAnimationFrame) 前言 window.requestAnimationFrame()告诉浏览器——你希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画。该方法需要传入一个回调函数…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...

【电力电子】基于STM32F103C8T6单片机双极性SPWM逆变(硬件篇)
本项目是基于 STM32F103C8T6 微控制器的 SPWM(正弦脉宽调制)电源模块,能够生成可调频率和幅值的正弦波交流电源输出。该项目适用于逆变器、UPS电源、变频器等应用场景。 供电电源 输入电压采集 上图为本设计的电源电路,图中 D1 为二极管, 其目的是防止正负极电源反接, …...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...

Visual Studio Code 扩展
Visual Studio Code 扩展 change-case 大小写转换EmmyLua for VSCode 调试插件Bookmarks 书签 change-case 大小写转换 https://marketplace.visualstudio.com/items?itemNamewmaurer.change-case 选中单词后,命令 changeCase.commands 可预览转换效果 EmmyLua…...

实战设计模式之模板方法模式
概述 模板方法模式定义了一个操作中的算法骨架,并将某些步骤延迟到子类中实现。模板方法使得子类可以在不改变算法结构的前提下,重新定义算法中的某些步骤。简单来说,就是在一个方法中定义了要执行的步骤顺序或算法框架,但允许子类…...