ElasticSearch - ElasticSearch基本概念及集群内部原理
文章目录
- 1. ElasticSearch的应用场景
- 01. Elasticsearch 是什么?
- 02. 为何使用 Elasticsearch?
- 03. Elasticsearch 的用途是什么?
- 04. Elasticsearch 的工作原理是什么?
- 05. Elasticsearch 索引是什么?
- 06. Logstash 的用途是什么?
- 07. Kibana 的用途是什么?
- 2. ElasticSearch的数据模型核心概念
- 01. Elasticsearch集群中的文档是什么?
- 02. Elasticsearch集群中索引是什么?
- 03. Elasticsearch集群中映射是什么?
- 04. Elasticsearch 中的节点是什么?
- 05. Elasticsearch 中的分片是什么?
- 06. ElasticSearch中的副本是什么?
- 07. ElasticSearch主分片数量可以在后期更改吗? 为什么?
- 08. ElasticSearch中更新 Mapping 的语法?
- 09. Elasticsearch 中删除索引的语法?
- 10. Elasticsearch 中列出集群的所有索引的语法?
- 3. ElasticSearch集群的内部原理
- 01. 空集群 (ElasticSearch的集群和节点)
- 02. 集群健康
- 03. 添加索引 (ElasticSearch的分片和副本)
- 04. 添加故障转移(添加节点)
- 05. 水平扩容(添加副本)
- 06. 应对故障(节点故障)
1. ElasticSearch的应用场景
01. Elasticsearch 是什么?
Elasticsearch 文档
Elasticsearch 是一个近实时的分布式搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。Elasticsearch 在 Apache Lucene 的基础上开发而成,以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件;
02. 为何使用 Elasticsearch?
Elasticsearch 很快。由于 Elasticsearch 是在 Lucene 基础上构建而成的,所以在全文本搜索方面表现十分出色。Elasticsearch 同时还是一个近实时的搜索平台,这意味着从文档索引操作到文档变为可搜索状态之间的延时很短,一般只有一秒。
Elasticsearch 具有分布式的本质特征。Elasticsearch 中存储的文档分布在不同的容器中,这些容器称为分片,可以进行复制以提供数据冗余副本,以防发生硬件故障。Elasticsearch 的分布式特性使得它可以扩展至数百台(甚至数千台)服务器,并处理 PB 量级的数据。
ES提供了REST风格的API接口。用户可以借助任何语言使用HTTP对ES执行请求来完成搜索任务;Elasticsearch 提供强大且全面的 REST API 集合,这些 API 可用来执行各种任务,例如检查集群的运行状况、针对索引执行 CRUD(创建、读取、更新、删除)和搜索操作,以及执行诸如筛选和聚合等高级搜索操作。
Elasticsearch 包含一系列广泛的功能。除了速度、可扩展性和弹性等优势以外,Elasticsearch 还有大量强大的内置功能(例如数据汇总和索引生命周期管理),可以方便用户更加高效地存储和搜索数据。
ES本身还提供了聚合功能。用户可以使用该功能对索引中的数据进行统计分析;
03. Elasticsearch 的用途是什么?
Elasticsearch 在速度和可扩展性方面都表现出色,而且还能够索引多种类型的内容,这意味着其可用于多种用例:
- 应用程序搜索
- 网站搜索
- 企业搜索
- 日志处理和分析
- 基础设施指标和容器监测
- 应用程序性能监测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
04. Elasticsearch 的工作原理是什么?
原始数据会从多个来源(包括日志、系统指标和网络应用程序)输入到 Elasticsearch 中。数据采集指在 Elasticsearch 中进行索引之前解析、标准化并充实这些原始数据的过程。这些数据在 Elasticsearch 中索引完成之后,用户便可针对他们的数据运行复杂的查询,并使用聚合来检索自身数据的复杂汇总。在 Kibana 中,用户可以基于自己的数据创建强大的可视化,分享仪表板,并对 Elastic Stack 进行管理。
05. Elasticsearch 索引是什么?
Elasticsearch 索引指相互关联的文档集合。Elasticsearch 会以 JSON 文档的形式存储数据。每个文档都会在一组键(字段或属性的名称)和它们对应的值(字符串、数字、布尔值、日期、数值组、地理位置或其他类型的数据)之间建立联系。
Elasticsearch 使用的是一种名为倒排索引的数据结构,这一结构的设计可以允许十分快速地进行全文本搜索。倒排索引会列出在所有文档中出现的每个特有词汇,并且可以找到包含每个词汇的全部文档。
在索引过程中,Elasticsearch 会存储文档并构建倒排索引,这样用户便可以近实时地对文档数据进行搜索。索引过程是在索引 API 中启动的,通过此 API 您既可向特定索引中添加 JSON 文档,也可更改特定索引中的 JSON 文档。
06. Logstash 的用途是什么?
Logstash 是 Elastic Stack 的核心产品之一,可用来对数据进行聚合和处理,并将数据发送到 Elasticsearch。Logstash 是一个开源的服务器端数据处理管道,允许您在将数据索引到 Elasticsearch 之前同时从多个来源采集数据,并对数据进行充实和转换。
07. Kibana 的用途是什么?
Kibana 是一款适用于 Elasticsearch 的数据可视化和管理工具,可以提供实时的直方图、线形图、饼状图和地图。Kibana 同时还包括诸如 Canvas 和 Elastic Maps 等高级应用程序;Canvas 允许用户基于自身数据创建定制的动态信息图表,而 Elastic Maps 则可用来对地理空间数据进行可视化。
2. ElasticSearch的数据模型核心概念
01. Elasticsearch集群中的文档是什么?
ElasticSearch是面向文档的,对文档进行索引、检索、排序和过滤—而不是对行列数据(关系型数据库是对行列数据),它使用 JSON文档来表示一个对象,如员工对象:
{"email": "john@smith.com","first_name": "John","last_name": "Smith","info": {"bio": "Eco-warrior and defender of the weak","age": 25,"interests": [ "dolphins", "whales" ]},"join_date": "2014/05/01"
}
JSON 文档 包含了这位员工的所有详细信息,他的名字叫 John Smith ,今年 25 岁,喜欢攀岩。
02. Elasticsearch集群中索引是什么?
索引一个员工对象,就是将代表员工信息的 JSON 文档添加到索引中:
索引(名词):一个索引类似于传统关系数据库中的一个数据库,是一个存储关系型文档的地方。
索引(动词):索引一个文档就是存储一个文档到一个索引中以便被检索和查询。类似于 SQL 中的 INSERT 关键词。
索引文档后,它会在1 秒内以近乎实时的方式编入索引并可搜索。Elasticsearch 使用一种称为倒排索引的数据结构,支持非常快速的全文搜索。倒排索引列出出现在任何文档中的每个唯一单词,并标识每个单词出现的所有文档。
索引可以被认为是文档的集合,每个文档都是字段的集合,字段是包含数据的键值对。默认情况下,Elasticsearch 索引每个字段中的所有数据,每个索引字段都有一个专用的、优化的数据结构。例如,文本字段存储在倒排索引中,数字和地理字段存储在 BKD 树中。使用每个字段的数据结构来组合和返回搜索结果的能力使 Elasticsearch 如此之快。
03. Elasticsearch集群中映射是什么?
建立索引时需要定义文档的数据结构,这种结构叫作映射。Elasticsearch 可以在不明确指定文档的字段类型的情况下对文档进行索引。ES还提供了自动映射功能,启用动态映射后,Elasticsearch 会自动检测字段类型并将其添加到索引,只需开始索引文档,Elasticsearch 就会检测布尔值、浮点和整数值、日期和字符串并将其映射到适当的 Elasticsearch 数据类型。
定义您自己的映射使您能够:
- 区分全文字符串字段和精确值字符串字段
- 执行特定于语言的文本分析
- 为部分匹配优化字段
- 使用自定义日期格式
- 使用无法自动检测的 数据类型,例如
geo_point和geo_shape
04. Elasticsearch 中的节点是什么?
单台 Elasticsearch 服务器提供服务,往往都有最大的负载能力,超过这个阈值,服务器性能就会大大降低甚至不可用,所以生产环境中,一般都是运行在指定服务器集群中。除了负载能力,单点服务器也存在其他问题:
单台机器存储容量有限
单服务器容易出现单点故障,无法实现高可用
单服务的并发处理能力有限
在分布式系统中,为了完成海量数据的存储、计算并提升系统的高可用性,需要多台计算机集成在一起协作,这种形式被称为集群。这些集群中的每台计算机叫作节点。ES集群的节点个数不受限制,用户可以根据需求增加计算机对搜索服务进行扩展。
05. Elasticsearch 中的分片是什么?
Elasticsearch 旨在始终可用并根据您的需求进行扩展。您可以将服务器(节点)添加到集群以增加容量,Elasticsearch 会自动将您的数据和查询负载分布到所有可用节点。Elasticsearch 知道如何平衡多节点集群以提供规模和高可用性,节点越多越好。
这是如何运作的?Elasticsearch 索引实际上只是一个或多个物理分片的逻辑分组,其中每个分片实际上是一个独立的索引。通过将索引中的文档分布在多个分片上,并将这些分片分布在多个节点上,Elasticsearch 可以确保冗余,这既可以防止硬件故障,又可以在节点添加到集群时增加查询容量。随着集群的增长(或收缩),Elasticsearch 会自动迁移分片以重新平衡集群。
06. ElasticSearch中的副本是什么?
有两种类型的分片:主分片和副本分片。索引中的每个文档都属于一个主分片。副本分片是主分片的副本。副本提供数据的冗余副本,以防止硬件故障并增加处理读取请求(如搜索或检索文档)的能力。索引中主分片的数量在创建索引时是固定的,但副本分片的数量可以随时更改,而不会中断索引或查询操作。
总结:在ES中,一个分片对应的就是一个Lucene索引,每个分片可以设置多个副分片,这样当主分片所在的计算机因为发生故障而离线时,副分片会充当主分片继续服务。
07. ElasticSearch主分片数量可以在后期更改吗? 为什么?
索引的主分片个数只能设置一次,之后不能更改。在默认情况下,ES的每个索引设置为5个分片。
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?
首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到 余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
08. ElasticSearch中更新 Mapping 的语法?
PUT /user/_mapping
{"properties": {"height": {"type": "long"}}
}
09. Elasticsearch 中删除索引的语法?
DELETE /customer
10. Elasticsearch 中列出集群的所有索引的语法?
GET _cat/indices
yellow open bank nVKCBX8_SC-V5r6NnL3H8Q 1 1 1000 0 414.3kb 414.3kb
green open .kibana_task_manager_1 DOCIE0WAS4ie2E6cKRrrKg 1 0 2 0 12.5kb 12.5kb
green open .apm-agent-configuration rxUfER_KQA-4LGhSXxXgsw 1 0 0 0 283b 283b
yellow open user w8vL9cNWTDScmtPyBcbp0A 1 1 3 1 5.8kb 5.8kb
green open .kibana_1 _LyEJbfYSVu-qitn5iUktA 1 0 8 0 32kb 32kb
yellow open account KVR4yMcGRX24l5gPgawbdg 1 1 0 0 283b 283b
yellow open customer J0af4Dn8Rca3z0r-miUGqA 1 1 4 0 4.3kb 4.3kb
yellow open knowledge Dq3eO_doQomUCzZ_sCfEdw 1 1 1 0 5.3kb 5.3kb
3. ElasticSearch集群的内部原理
01. 空集群 (ElasticSearch的集群和节点)
如果我们启动了一个单独的节点,里面不包含任何的数据和索引,那我们的集群看起来就是一个 Figure 1, “包含空内容节点的集群” 。

一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为 主 节点时, 它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节点都可以成为主节点。我们的示例集群就只有一个节点,所以它同时也成为了主节点。
作为用户,我们可以将请求发送到 集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
02. 集群健康
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是 集群健康 , 它在 status 字段中展示为 green 、 yellow 或者 red 。
GET /_cluster/health
在一个不包含任何索引的空集群中,它将会有一个类似于如下所示的返回内容:
{"cluster_name": "elasticsearch","status": "green", "timed_out": false,"number_of_nodes": 1,"number_of_data_nodes": 1,"active_primary_shards": 0,"active_shards": 0,"relocating_shards": 0,"initializing_shards": 0,"unassigned_shards": 0
}
status 字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
green:所有的主分片和副本分片都正常运行。
yellow :所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red :有主分片没能正常运行。
03. 添加索引 (ElasticSearch的分片和副本)
我们往 Elasticsearch 添加数据时需要用到 索引 —— 保存相关数据的地方。 索引实际上是指向一个或者多个物理 分片 的逻辑命名空间。
一个分片是一个底层的工作单元 ,它仅保存了全部数据中的一部分。一个分片是一个 Lucene 的实例,它本身就是一个完整的搜索引擎。 我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。 当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
一个分片可以是主分片或者副本分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。一个副本分片只是一个主分片的拷贝。副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。
让我们在包含一个空节点的集群内创建名为 blogs 的索引。 索引在默认情况下会被分配5个主分片, 但是为了演示目的,我们将分配3个主分片和一份副本(每个主分片拥有一个副本分片):
PUT /blogs
{"settings" : {"number_of_shards" : 3,"number_of_replicas" : 1}
}
我们的集群现在是 Figure 2, “拥有一个索引的单节点集群” 。所有3个主分片都被分配在 Node 1 。

如果我们现在查看集群健康,我们将看到如下内容:
GET /_cluster/health
{"cluster_name": "elasticsearch","status": "yellow", "timed_out": false,"number_of_nodes": 1,"number_of_data_nodes": 1,"active_primary_shards": 3,"active_shards": 3,"relocating_shards": 0,"initializing_shards": 0,"unassigned_shards": 3, "delayed_unassigned_shards": 0,"number_of_pending_tasks": 0,"number_of_in_flight_fetch": 0,"task_max_waiting_in_queue_millis": 0,"active_shards_percent_as_number": 50
}
集群的健康状况为 yellow 则表示全部 主 分片都正常运行(集群可以正常服务所有请求),但是 副本 分片没有全部处在正常状态。 实际上,所有3个副本分片都是 unassigned —— 它们都没有被分配到任何节点。 在同一个节点上既保存原始数据又保存副本是没有意义的,因为一旦失去了那个节点,我们也将丢失该节点上的所有副本数据。
当前我们的集群是正常运行的,但是在硬件故障时有丢失数据的风险。
04. 添加故障转移(添加节点)
当集群中只有一个节点在运行时,意味着会有一个单点故障问题——没有冗余。 幸运的是,我们只需再启动一个节点即可防止数据丢失。
当你在同一台机器上启动了第二个节点时,只要它和第一个节点有同样的 cluster.name 配置,它就会自动发现集群并加入到其中。 但是在不同机器上启动节点的时候,为了加入到同一集群,你需要配置一个可连接到的单播主机列表。
如果启动了第二个节点,我们的集群将会如 Figure 3, “拥有两个节点的集群——所有主分片和副本分片都已被分配” 所示。

当第二个节点加入到集群后,3个副本分片将会分配到这个节点上——每个主分片对应一个副本分片。 这意味着当集群内任何一个节点出现问题时,我们的数据都完好无损。
所有新近被索引的文档都将会保存在主分片上,然后被并行的复制到对应的副本分片上。这就保证了我们既可以从主分片又可以从副本分片上获得文档。
GET /_cluster/health
{"cluster_name": "elasticsearch","status": "green", "timed_out": false,"number_of_nodes": 2,"number_of_data_nodes": 2,"active_primary_shards": 3,"active_shards": 6,"relocating_shards": 0,"initializing_shards": 0,"unassigned_shards": 0,"delayed_unassigned_shards": 0,"number_of_pending_tasks": 0,"number_of_in_flight_fetch": 0,"task_max_waiting_in_queue_millis": 0,"active_shards_percent_as_number": 100
}
cluster-health 现在展示的状态为 green ,这表示所有6个分片(包括3个主分片和3个副本分片)都在正常运行。
05. 水平扩容(添加副本)
怎样为我们的正在增长中的应用程序按需扩容呢? 当启动了第三个节点,我们的集群将会看起来如 Figure 4, “拥有三个节点的集群——为了分散负载而对分片进行重新分配” 所示。

Node 1 和 Node 2 上各有一个分片被迁移到了新的 Node 3 节点,现在每个节点上都拥有2个分片,而不是之前的3个。 这表示每个节点的硬件资源(CPU, RAM, I/O)将被更少的分片所共享,每个分片的性能将会得到提升。
分片是一个功能完整的搜索引擎,它拥有使用一个节点上的所有资源的能力。 我们这个拥有6个分片(3个主分片和3个副本分片)的索引可以最大扩容到6个节点,每个节点上存在一个分片,并且每个分片拥有所在节点的全部资源。
但是如果我们想要扩容超过6个节点怎么办呢?
主分片的数目在索引创建时就已经确定了下来。实际上,这个数目定义了这个索引能够存储的最大数据量。(实际大小取决于你的数据、硬件和使用场景。) 但是,读操作——搜索和返回数据——可以同时被主分片 或 副本分片所处理,所以当你拥有越多的副本分片时,也将拥有越高的吞吐量。
在运行中的集群上是可以动态调整副本分片数目的,我们可以按需伸缩集群。让我们把副本数从默认的 1 增加到 2 :
PUT /blogs/_settings
{"number_of_replicas" : 2
}
如 Figure 5, “将参数 number_of_replicas 调大到 2” 所示, blogs 索引现在拥有9个分片:3个主分片和6个副本分片。
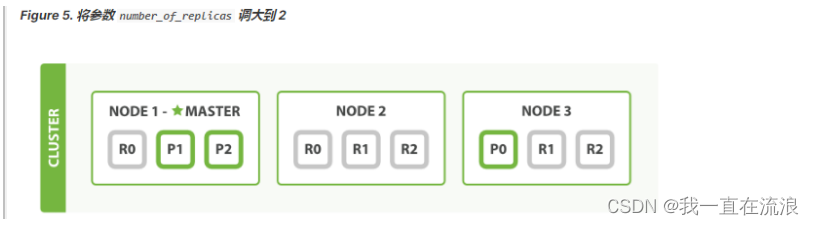
这意味着我们可以将集群扩容到9个节点,每个节点上一个分片。相比原来3个节点时,集群搜索性能可以提升 3 倍。当然,如果只是在相同节点数目的集群上增加更多的副本分片并不能提高性能,因为每个分片从节点上获得的资源会变少。 你需要增加更多的硬件资源来提升吞吐量。但是更多的副本分片数提高了数据冗余量:按照上面的节点配置,我们可以在失去2个节点的情况下不丢失任何数据。
06. 应对故障(节点故障)
我们之前说过 Elasticsearch 可以应对节点故障,接下来让我们尝试下这个功能。 如果我们关闭第一个节点,这时集群的状态为Figure 6, “关闭了一个节点后的集群”
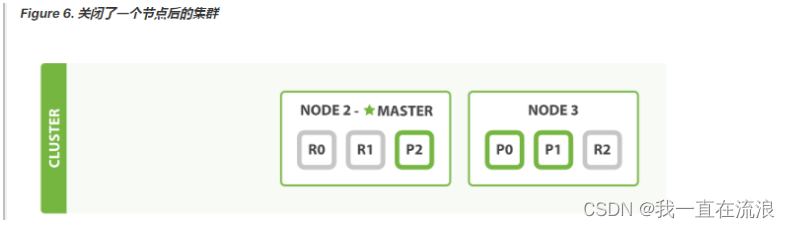
我们关闭的节点是一个主节点。而集群必须拥有一个主节点来保证正常工作,所以发生的第一件事情就是选举一个新的主节点: Node 2 。
在我们关闭 Node 1 的同时也失去了主分片 1 和 2 ,并且在缺失主分片的时候索引也不能正常工作。 如果此时来检查集群的状况,我们看到的状态将会为 red :不是所有主分片都在正常工作。
幸运的是,在其它节点上存在着这两个主分片的完整副本, 所以新的主节点立即将这些分片在 Node 2 和 Node 3 上对应的副本分片提升为主分片, 此时集群的状态将会为 yellow 。 这个提升主分片的过程是瞬间发生的,如同按下一个开关一般。
参考文档:ES权威指南
相关文章:
ElasticSearch - ElasticSearch基本概念及集群内部原理
文章目录1. ElasticSearch的应用场景01. Elasticsearch 是什么?02. 为何使用 Elasticsearch?03. Elasticsearch 的用途是什么?04. Elasticsearch 的工作原理是什么?05. Elasticsearch 索引是什么?06. Logstash 的用途是…...

【反射中,Class.forName和ClassLoader区别】
在Java中,可以使用反射机制来获取类的信息并动态地创建对象。其中,Class是Java反射机制中的重要类,表示一个类的信息。 Class.forName()和ClassLoader都可以用于获取类的Class对象,但它们之间存在一些差别: 1、是否会…...

2023了为什么还有人在问:女生适合做跨境电商吗?
女生适合做跨境电商吗?这是东哥最近咨询里面问最多的,今天东哥就给大家解答一下你们内心的疑惑,虽然代表的是东哥我自己的观点,但我觉得还是很值得深思的。 女生适合做跨境电商吗? 性别并不是决定一个人是否适合从事跨…...
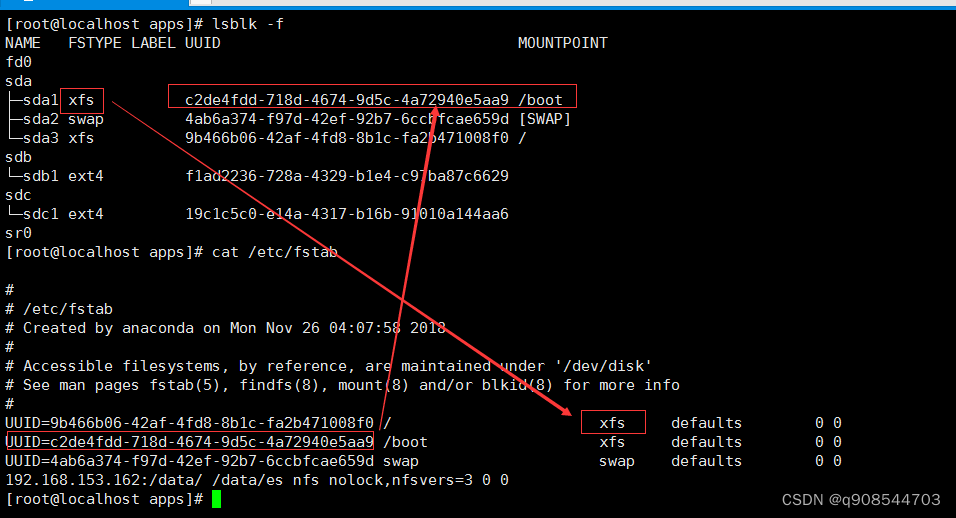
磁盘分区和挂载
磁盘分区和挂载一、linux分区1.原理介绍2.分区和文件关系示意图:3.硬盘说明二、linux分区1.查看所有设备挂载情况三、挂载案例1.使用lsblk命令查看2. 虚拟机硬盘分区3.虚拟机硬盘分区格式化4.mount挂载 重启挂载失效4.1挂载名词解释4.2注意事项4.3挂载4.4挂载非空目…...
电子技术——晶体管尺寸
电子技术——晶体管尺寸 在本节我们介绍关于IC设计的一个重要的参数晶体管尺寸(例如长度和长宽比)。我们首先考虑MOS反相器。 反相器尺寸 为了说明 (W/L)(W/L)(W/L) 的尺寸大小以及 (W/L)p(W/L)_p(W/L)p 和 (W/L)n(W/L)_n(W/L)n 的比例问题对于MO…...

Tuxera NTFS2023MacOS读写软件功能介绍使用
当我们遇到磁盘不能正常使用的情况时本能的会以为是磁盘损坏了,但某些情况下却并非如此。对于mac操作系统来说,软件无法使用设备无法正常读写似乎是很常见的事,毕竟现在的mac电脑对PC机上的产品无法完全适应使用,经常会存在兼容方…...

2022年数维杯国际大学生数学建模挑战赛A题自动地震地平线跟踪解题全过程论文及程序
2022年数维杯国际大学生数学建模挑战赛 A题 自动地震地平线跟踪 原题再现: 随着我国经济社会发展,地质工作的重要性也日益提高。地震资料解释是地震勘探工程的一个重要阶段,可以明确油气勘探的地下构造特征,为油气勘探提供良好和…...

推荐系统[八]:推荐系统常遇到问题和解决方案[物品冷启动问题、多目标平衡问题、数据实时性问题等]
相关文章推荐: 推荐系统[一]:超详细知识介绍,一份完整的入门指南,解答推荐系统相关算法流程、衡量指标和应用,以及如何使用jieba分词库进行相似推荐,业界广告推荐技术最新进展 推荐系统[二]:召回算法超详细讲解[召回模型演化过程、召回模型主流常见算法(DeepMF/TDM/Ai…...

shutil.copyfile PermissionError: [Errno 13] Permission denied
File "G:/od15/调试/翻译文件更换/更新翻译po文件.py", line 42, in <module> shutil.copyfile(gxpath,dir_file_path) File "E:\odsoft\python\lib\shutil.py", line 120, in copyfile with open(src, rb) as fsrc: PermissionError: [Er…...
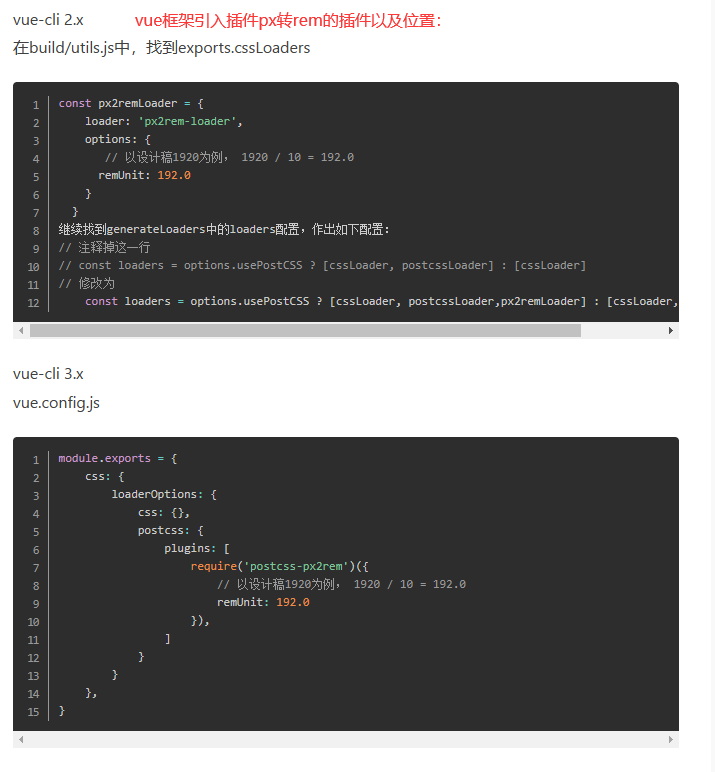
07react+echart,大屏代码开发
react框架引入第三方插件原链接gitHub:GitHub - hustcc/echarts-for-react: ⛳ Apache ECharts components for React wrapper. 一个简单的 Apache echarts 的 React 封装。import ReactECharts from echarts-for-react;import * as echarts from echarts;一、软件简介echarts-…...
)
【数据库原理复习】ch2 SQL语句(主要基于sql server)
这里写目录标题基本知识常用基本数据类型字符型数据类型二进制数据类型日期类型数字类型约束条件表SQL语句创建语句修改基本表 & 删除基本表数据查询基本知识 常用基本数据类型 字符型数据类型 名称大小说明char(n)占n个字节只能显示英文字符nchar(n)2n字节2字节额外开销…...

Cadence Allegro 导出Component Pin Report详解
⏪《上一篇》 🏡《上级目录》 ⏩《下一篇》 目录 1,概述2,Component Pin Report作用3,Component Pin Report示例4,Component Pin Report导出方法4.1,方法14.2,方法2B站关注“硬小二”浏览更多演示视频 1,概述...

PAT甲级 1110 Complete Binary Tree
题目链接 PAT甲级 1110 Complete Binary Tree 思路 第一次的写法不是很好。 对于这种完全二叉树的层序遍历,比较烦人的就是空孩子使得处理很麻烦。 思来想去还是把空位置也入队比较好。 这样的话,访问到空指针的时机被推迟了一个level 而完全二叉树的…...
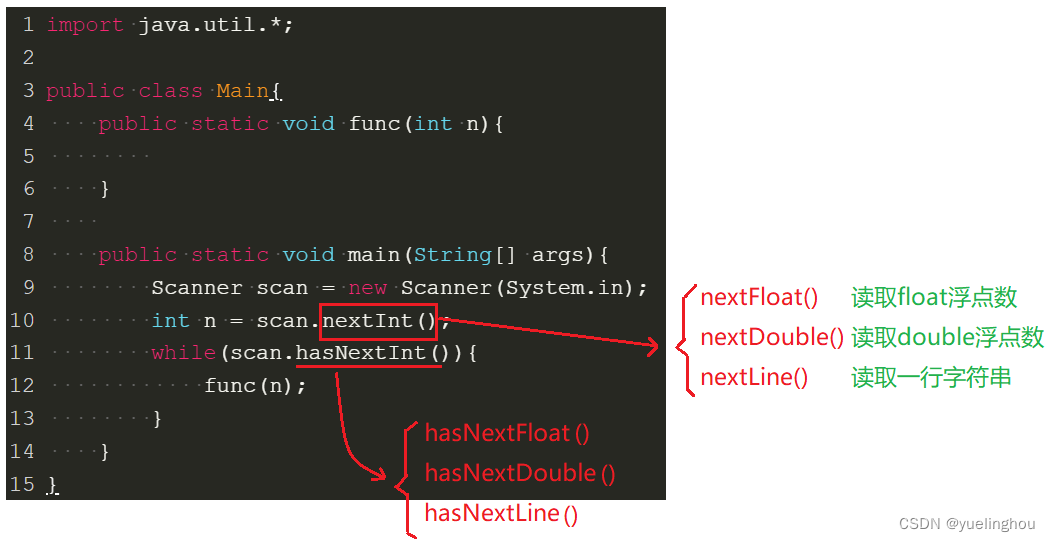
【JavaSE】逻辑控制语句
文章目录一. 顺序结构二. 分支结构1. if 语句2. switch 语句3、循环结构3.1 while 循环3.2 do while 循环3.3 for 循环3.4 break 和 continue三. 输入输出1. 输出到控制台2. 从键盘输入一. 顺序结构 顺序结构比较简单,即程序按照代码书写的顺序一行一行执行下去。 …...

Motionbuilder系统文件说明
安装路径 Motionbuilder 默认的安装路径在 C:\Program Files\Autodesk\MotionBuilder\ 用户数据(user data) 位于安装路径下的 bin\config 非管理员用户的配置文件路径 Motionbuilder会将配置文件备份到 \Users[user]\AppData\Local\Autodesk[MotionBuilder] 当用户第一次打开…...
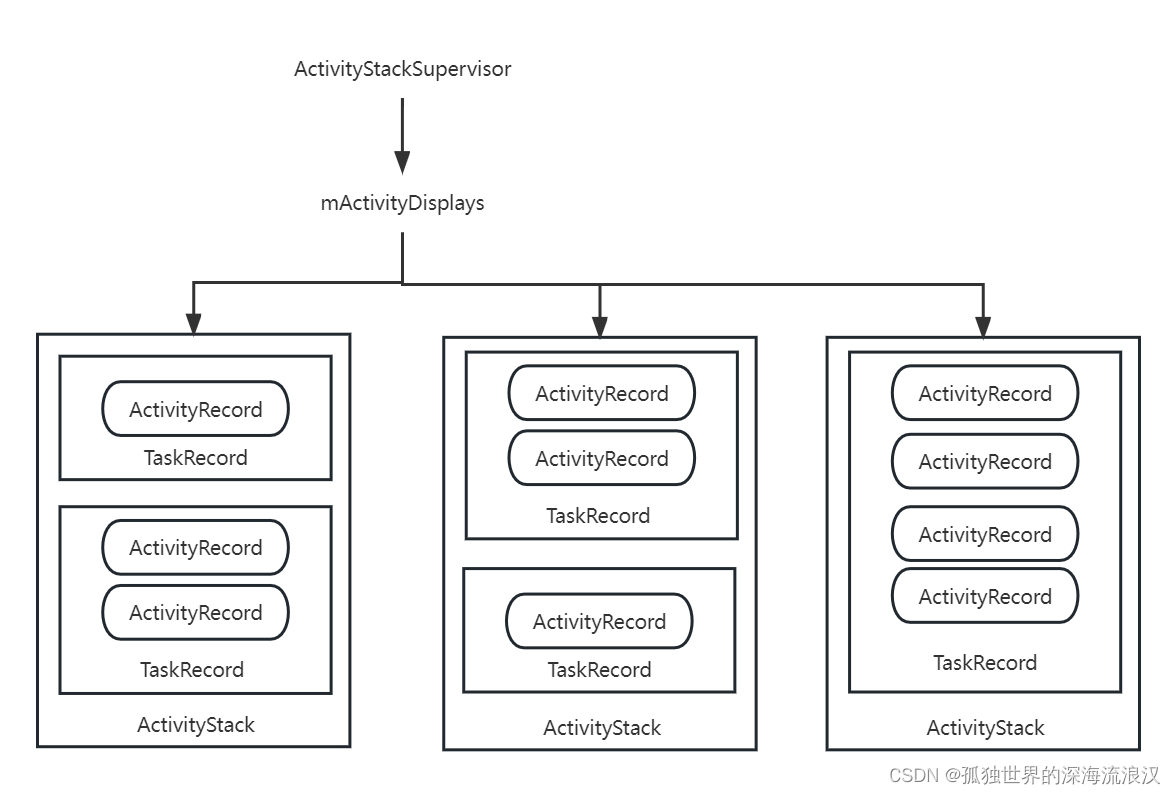
【我的Android开发】AMS中Activity栈管理
概述 Activity栈管理是AMS的另一个重要功能,栈管理又和Activity的启动模式和startActivity时所设置的Flag息息相关,Activity栈管理的主要处理逻辑是在ActivityStarter#startActivityUnchecked方法中,本文也会围绕着这个方法进进出出…...

C++源程序的构成————学习笔记
以下内容为,在学校上课时的课堂总结,偶尔我也会扩展一些内容内容仅供参考,欢迎大佬的指正简单的C程序#include <iostream> using namespace std;int main() {int x0;int y 0;cout << "请输入x,y的值"<<endl;cin…...

Spark Catalyst
Spark Catalyst逻辑计划逻辑计划解析逻辑计划优化Catalyst 规则优化过程物理计划Spark PlanJoinSelection生成 Physical PlanEnsureRequirementsSpark SQL 端到端的优化流程: Catalyst 优化器 : 包含逻辑优化/物理优化Tungsten : Spark SQL的优化过程 : 逻辑计划 …...

element 远程搜索下拉加载
created() { this.getList(); this.getGroupList(); }, directives: { /** 下拉框懒加载 */ “el-select-loadmore”: { bind(el, binding) { const SELECTWRAP_DOM el.querySelector( “.el-select-dropdown .el-select-dropdown__wrap” ); SELECTWRAP_DOM.addEventListener…...

空间复杂度与顺序表的具体实现操作(1)
最近更新的少,主要是因为参加了ACM竞赛空间复杂度空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度 。空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...
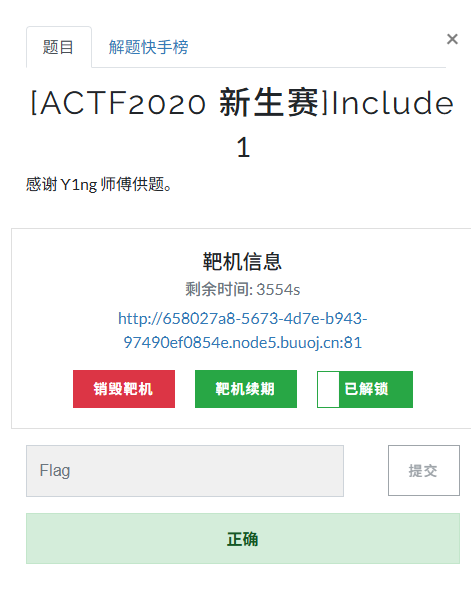
[ACTF2020 新生赛]Include 1(php://filter伪协议)
题目 做法 启动靶机,点进去 点进去 查看URL,有 ?fileflag.php说明存在文件包含,原理是php://filter 协议 当它与包含函数结合时,php://filter流会被当作php文件执行。 用php://filter加编码,能让PHP把文件内容…...