【python开发】并发编程(上)
并发编程(上)
- 一、进程和线程
- (一)多线程
- (二)多进程
- (三)GIL锁
- 二、多线程开发
- (一)t.start()
- (二)t.join()
- (三)t.setDaemon(布尔值)
- (四)线程名称的设置和获取
- (五)run方法
- 三、线程安全
- 四、线程锁
- (一)Lock:同步锁
- (二)RLock,递归锁
- 五、死锁
- 六、线程池
- (一)示例一
- (二)示例二
- (三)示例三
- (四)示例四
- 七、单例模式(扩展)
一、进程和线程
类比:
- 一个工厂,至少需要一个车间,一个车间至少需要一个工人操作一台机器,最终是工人在工作。
- 一个程序,至少有一个进程,一个进程中至少有一个线程,最终是线程在工作。
线程是计算机中可以被cpu调度的最小单元;进程是计算机资源分配的最小单元(进程为线程提供资源)。一个进程中可以有多个线程,同一个进程中的线程可以共享次过程中的资源。一个进程中可以有多个线程,同一个进程中的线程可以共享此进程中的资源。
import time
import requestsurl_list = [('东北F4模仿秀.mp4', "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"),('卡特扣篮.mp4', "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34qlg"),('罗斯mvp.mp4', "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg")]start_time = time.time()
print(start_time)for file_name, url in url_list:res = requests.get(url)with open(file_name, mode='wb') as f:f.write(res.content)end_time = time.time()print(file_name, end_time-start_time)'''
1710295330.536654
东北F4模仿秀.mp4 0.9025721549987793
卡特扣篮.mp4 1.5163640975952148
罗斯mvp.mp4 2.1225790977478027
'''
从上述实验可以看出,在串行任务中下载三个视频耗费时间大致为2.12秒。
(一)多线程
基于多线程对上述串行示例进行优化:
- 一个工厂,创建一个车间,这个车间中安排3个工人,并行处理任务;
- 一个程序,创建一个进程,这个进程中创建3个线程,并行处理任务。
多线程threading,在引入threading模块后,引用Thread方法,Thread方法通常来说需要输入两个参数:target和args
import threadingdef thread_job():print('This is an added Thread, which is %s' % threading.current_thread())def main():# 添加一个线程added_thread = threading.Thread(target=thread_job) # target表示要该线程要执行的任务# 启动线程added_thread.start()if __name__ == '__main__':main()当我们用多线程方法下载三个抖音视频时:
import time
import requests
import threadingurl_list = [('东北F4模仿秀.mp4', "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"),('卡特扣篮.mp4', "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34qlg"),('罗斯mvp.mp4', "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg")]start_time = time.time()
print(start_time)def task(file_name, video_url):res = requests.get(video_url)with open(file_name, mode='wb') as f:f.write(res.content)end_time = time.time()print(file_name, end_time - start_time)for file_name, url in url_list:#创建线程,让每个线程都去执行task函数(参数不同)t = threading.Thread(target=task, args=(file_name, url))t.start()'''
1710296455.683249
罗斯mvp.mp4 0.8964550495147705
东北F4模仿秀.mp4 0.9174120426177979
卡特扣篮.mp4 0.9269850254058838
'''
在使用多线程的情况下,我们可以看出下载三个痘印视频最多需要0.9秒,比不使用多线程时少了将近一半时间。
(二)多进程
- 一个工厂,创建三个车间,每个车间一个工人(共三人),并行处理任务;
- 一个程序,创建三个进程,每个进程中创建一个线程(共三人),并行处理任务。
import time
import requests
import multiprocessingmultiprocessing.set_start_method('fork')#进程创建之,在进程中会创建一个线程
#t = multiprocessing.Process(target=函数名,args=(name, url))
#t.start()url_list = [('东北F4模仿秀.mp4', "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"),('卡特扣篮.mp4', "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34qlg"),('罗斯mvp.mp4', "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg")]def task(file_name, video_url):res = requests.get(video_url)with open(file_name, mode="wb") as f:f.write(res.content)end_time = time.time()print(end_time-start_time)if __name__ == '__main__':for name, url in url_list:start_time = time.time()t = multiprocessing.Process(target=task, args=(name, url))t.start()'''
0.6752231121063232
0.7185511589050293
0.7391998767852783
'''
根据以上实验可以看出:多进程耗费时间小于多线程。多线程最好是使用:if name == ‘main’:主方法,为什么不能跟多线程一样用for循环来实现(会报错),因为Linux系统只能支持fork,win系统可以只是spawn,mac支持fork和spwan(python3.8默认设置spawn)。
(三)GIL锁
GIL,全局解释锁(Global Interpreter Lock),是CPython解释器特有的,让一进程同一时刻只能由一个线程被CPU调用。

如果想利用计算机的多核优势,让CPU同时处理一些任务,适合用多进程开发(即使资源开销大)。如果不利用计算机的多核优势,则适合多线程开发。
- 计算密集型,用多进程,例如:大量的数量计算(累加计算示例);
- IO密集型,用多线程,例如:文件读写、网络数据传输(下载抖音视频示例)。
累加计算串型计算(计算密集型):
import timeresult = 0
starttime = time.time()for i in range(10000000):result += 1#print(result)endtime = time.time()
print(endtime - starttime) #1.1689763069152832在程序中创建两个进程时,通过两个累加计算结果相加来减少时间耗费。
import time
import multiprocessingresult = 0
starttime = time.time()for i in range(10000000):result += 1#print(result)endtime = time.time()
print(endtime - starttime) #1.1689763069152832def task(start, end, queue):result = 0for i in range(start, end):result += 1queue.put(result)if __name__ == '__main__':queue = multiprocessing.Queue()starttime_ = time.time()p1 = multiprocessing.Process(target=task, args=(0, 5000000, queue))p1.start()p2 = multiprocessing.Process(target=task, args=(5000000, 10000000, queue))p2.start()v1 = queue.get(block=True)v2 = queue.get(block=True)print(v1 + v2)endtime_ = time.time()print("耗时:", endtime_ - starttime_)
#耗时: 0.40788888931274414
当然,在程序开发中多线程和多进程可以结合使用,例如创建两个进程(进程个数和CPU个数相同),每个进程中创建3个线程。
二、多线程开发
主线程和子线程的关系:最常见的情况,主线程中开启了一个子线程,开启之后,主线程与子线程互不影响各自的生命周期,即主线程结束,子线程还可以继续执行;子线程结束,主线程也能继续执行。
import threadingdef task(arg):pass#创建一个Thread对象(线程),并封装线程被CPU调度时应该执行的任务和相关参数。
t = threading.Thread(target=task, args=('xxx'))
#线程准备就绪(等待CPU调度),代码继续向下执行
t.start()print("继续执行。。。") #主线程执行完所有代码,不结束(等待子线程)
编程中常见的方法:
(一)t.start()
当前线程准备就绪(等待CPU调度,具体时间由CPU来决定)
import threadingloop = 1000000
number = 0def _add(count):global numberfor i in range(count):number += 1t = threading.Thread(target=_add, args=(loop,))
t.start()print(number)
#第一次运行结果:45067
#第二次运行结果:46539
#第三次运行结果:60418
在上述例子中,正式因为start方法什么时候调度由cpu来决定,主线程和子线程个字进行,所以当主线程运行结束的时候,这个子线程运行到什么程度未可知,所以每次运行都会出现不同的数字。
(二)t.join()
等待当前线程的任务执行完毕后再向下继续执行
import threadingloop = 1000000
number = 0def _add(count):global numberfor i in range(count):number += 1t = threading.Thread(target=_add, args=(loop,))
t.start()t.join() #主线程等待中print(number)
#第一次运行结果:1000000
#第二次运行结果:1000000
#第三次运行结果:1000000
在上述的例子中可以知道,join方法中,主线程会等待子线程运行结束后才会执行,所以每次运行的结果都相同,数值均等于loop。
import threadingloop = 1000000
number = 0def _add(count):global numberfor i in range(count):number += 1def _sub(count):global numberfor i in range(count):number -= 1t1 = threading.Thread(target=_add, args=(loop,))
t2 = threading.Thread(target=_sub, args=(loop,))t1.start() #t1子线程准备就绪,等待CPU调度
t1.join() #主线程等待中,t1子线程运行完毕才继续运行
t2.start()
t2.join()#主线程序等待,t2子线程运行完毕之后继续运行
print(number)
#0如果调换start和join方法的顺序,结果将会不同。
import threadingloop = 1000000
number = 0def _add(count):global numberfor i in range(count):number += 1def _sub(count):global numberfor i in range(count):number -= 1t1 = threading.Thread(target=_add, args=(loop,))
t2 = threading.Thread(target=_sub, args=(loop,))t1.start() #t1子线程准备就绪,等待CPU调度
t2.start()t1.join() #t1子线程运行完毕才继续运行
t2.join()#t2子线程运行完毕之后继续运行
print(number)
#第一次执行结果为:333015
#第二次执行结果为:-284747
#第三次执行结果为:186463
cpu会分区运行add和sub函数,而start()方法确定了cpu什么时候开始调度这两个函数无法确定,所以虽然在子线程t1结束之后再运行t2子线程,但是每次执行完主线程之后的数值也无法确定。
(三)t.setDaemon(布尔值)
守护线程(必须在start之前设置)
- t.setDaemon(True),设置为守护线程,主线程执行完毕之后,子线程也自动关闭
- t.setDaemon(False),设置为非守护线程,主程序等待子线程,子线程执行完毕后,主线程才结束。(默认)
def task(arg):time.sleep(5)print("任务")t = threading.Thread(target=task, args=(11,))
t.setDaemon(True)
t.start()print("End")#End上述示例,设定了守护线程后,主线程结束之后,子线程也关闭了,所以只有主线程的结果输出。
import threading
import timedef task(arg):time.sleep(5)print("任务")t = threading.Thread(target=task, args=(11,))
t.setDaemon(False)
t.start()print("End")'''
End
任务
'''
(四)线程名称的设置和获取
import threadingdef task(arg):#获取当前执行此代码的线程name = threading.current_thread().getName()print(name)for i in range(10):t = threading.Thread(target=task, args=(11,))t.setName('happyeveryday{}'.format(i))t.start()'''
happyeveryday0
happyeveryday1
happyeveryday2
happyeveryday3
happyeveryday4
happyeveryday5
happyeveryday6
happyeveryday7
happyeveryday8
happyeveryday9
'''(五)run方法
自定义线程类,直接将线程需要做的事写到run()方法中。
import threadingclass MyThread(threading.Thread): #继承了threading.Thread方法,def run(self):print('执行此线程', self._args)t = MyThread(args=(100, ))
t.start()
#执行此线程 (100,)
改写抖音下载的都线程代码
import time
import requests
import threadingclass DouYinThread(threading.Thread):def run(self):file_name, video_url = self._argsres = requests.get(video_url)with open(file_name, mode="wb") as f:f.write(res.content)url_list = [('东北F4模仿秀.mp4', "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"),('卡特扣篮.mp4', "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34qlg"),('罗斯mvp.mp4', "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg")]for itme in url_list:t = DouYinThread(args=(itme[0], itme[1]))t.start()
三、线程安全
一个进程中可以有多个线程,且线程共享进程中的所有资源。多个线程同时去操作,可能会存在数据混乱的情况,例如:
import threadingloop = 1000000
number = 0def _add(count):global numberfor i in range(count):number += 1def _sub(count):global numberfor i in range(count):number -= 1t1 = threading.Thread(target=_add, args=(loop,))
t2 = threading.Thread(target=_sub, args=(loop,))t1.start() #t1子线程准备就绪,等待CPU调度
t2.start()t1.join() #t1子线程运行完毕才继续运行
t2.join()#t2子线程运行完毕之后继续运行
print(number)
#第一次执行结果为:333015
#第二次执行结果为:-284747
#第三次执行结果为:186463
那么对于这种情况应该如何解决呢?用锁锁定程序:
import threading lock_object = threading.RLock() #建锁
loop = 1000000
number = 0 def _add(count): lock_object.acquire() #申请锁 global number for i in range(count): number += 1 lock_object.release() #释放锁 def _sub(count): lock_object.acquire() #申请锁(等待) global number for i in range(count): number -= 1 lock_object.release() #释放锁 t1 = threading.Thread(target=_add, args=(loop,))
t2 = threading.Thread(target=_sub, args=(loop,)) t1.start() #t1子线程准备就绪,等待CPU调度
t2.start() t1.join() #t1子线程运行完毕才继续运行
t2.join()#t2子线程运行完毕之后继续运行
print(number)
#第一次执行结果为:0
#第二次执行结果为:0
#第三次执行结果为:0 如果想要彻底解决数据混乱的问题,需要为两个线程构建同一个把锁,分别在线程内部编写申请锁和释放锁的代码。虽然cpu还是会分块执行两个线程,但是每次执行每个线程的结果将被锁死,以便于下次执行线程使用。
示例:
import threading num = 0
lock_object = threading.RLock() def task(): print("开始") lock_object.acquire() #第一个抵达的线程进入并上锁,其他线程就需要再次等待 global num for i in range(1000000): num += 1 lock_object.release() print(num) for i in range(2): #构造了循环函数,循环创建了两个线程,正常来说,两个线程都执行完,num=2000000 t = threading.Thread(target=task) t.start() '''
开始
开始
1000000
2000000
'''
在开发的过程中要注意有些操作是默认 “线程安全”的(内部结成了锁的机制),我们在使用的时候无需再通过锁处理,例如:append(x)、extend(x)、pop(x)、赋值=、update()。在操作不是默认线程安全的情况下可以需要加锁来避免数据混乱的情况。需要多注意看一些开发文档中是否标明线程安全。
四、线程锁
在程序中如果想自己手动加锁,可以加两种锁:Lock和Rlock。Lock和Rlock用法大致相同。
(一)Lock:同步锁
import threadingnum = 0
lock_object = threading.Lock()def task():print("开始")lock_object.acquire() #第一个抵达的线程进入并上锁,其他线程就需要再次等待global numfor i in range(1000000):num += 1lock_object.release()print(num)for i in range(2): #构造了循环函数,循环创建了两个线程,正常来说,两个线程都执行完,num=2000000t = threading.Thread(target=task)t.start()
同步锁不支持在多次申请锁,否则会造成死锁的情况发生。下述例子是同步锁可以使用的:
def task():print("开始")lock_object.acquire() #第一个抵达的线程进入并上锁,其他线程就需要再次等待global numfor i in range(1000000):num += 1lock_object.release()lock_object.acquire() #第一个抵达的线程进入并上锁,其他线程就需要再次等待global numfor i in range(1000000):num += 1lock_object.release()print(num)以下情况是不能使用两个锁的:
def task():print("开始")lock_object.acquire() #第一个抵达的线程进入并上锁,其他线程就需要再次等待lock_object.acquire() #会导致死锁,Lock是不能这么使用的,但Rlock可以global numfor i in range(1000000):num += 1lock_object.release()lock_object.release()print(num)
(二)RLock,递归锁
import threading num = 0
lock_object = threading.RLock() def task(): print("开始") lock_object.acquire() #第一个抵达的线程进入并上锁,其他线程就需要再次等待 global num for i in range(1000000): num += 1 lock_object.release() print(num) for i in range(2): #构造了循环函数,循环创建了两个线程,正常来说,两个线程都执行完,num=2000000 t = threading.Thread(target=task) t.start() '''
开始
开始
1000000
2000000
'''
Rlock支持多次申请和释放锁(lock不支持),例如:
import threadingnum = 0
lock_object = threading.RLock()def task():print("开始")lock_object.acquire() #第一个抵达的线程进入并上锁,其他线程就需要再次等待lock_object.acquire() #会导致死锁,Lock是不能这么使用的,但Rlock可以print(1234)lock_object.release()lock_object.release()for i in range(3): #构造了循环函数,循环创建了两个线程,正常来说,两个线程都执行完,num=2000000t = threading.Thread(target=task)t.start()'''
开始
1234
开始
1234
开始
1234
'''
在什么情况下需要使用安全锁呢?程序员A和B都需要需要安全锁来保证自己开发的代码是数据安全的(都使用了安全锁),而且程序员B需要引用程序员A开发的代码,那么此时为了避免死锁问题,建议使用RLock。
五、死锁
死锁是由于资源竞争或者彼此通信而造成的阻塞现象。
死锁案例一:
import threadingnum = 0
lock_object = threading.Lock()def task():print("开始")lock_object.acquire() #第一个抵达的线程进入并上锁,其他线程就需要再次等待lock_object.acquire() #会导致死锁,进程会卡在这里,不会往下执行global numfor i in range(1000000):num += 1lock_object.release()lock_object.release()print(num)for i in range(2): #构造了循环函数,循环创建了两个线程,正常来说,两个线程都执行完,num=2000000t = threading.Thread(target=task)t.start()死锁案例二:
import threading
import timelock_1 = threading.Lock()
lock_2 = threading.Lock()def task1():lock_1.acquire()time.sleep(1)lock_2.acquire()print(11)lock_2.release()print(111)lock_1.release()print(1111)def task2():lock_2.acquire()time.sleep(1)lock_1.acquire()print(22)lock_1.release()print(222)lock_2.release()print(2222)t1 = threading.Thread(target=task1)
t1.start()t2 = threading.Thread(target=task2)
t2.start()六、线程池
线程不是越多越好,开得多可能会导致系统的性能更低,例如:如下的代码不推荐在项目开发中编写,不建议无限制得创建线程。
import threadingdef task(video_url):passurl_list = ["www.xxxxx-{}.com".format(i) for i in range(30000)]for url in url_list:t = threading.Thread(target=task, args=(url, ))t.start()
既然无限制得开线程会导致效率低下,因此可以使用线程池来解决这一问题。
(一)示例一
import time
from concurrent.futures import ThreadPoolExecutor#pool = ThreadPoolExecutor(100) 创建了100个线程def task(video_url, num):print("开始执行任务", video_url)time.sleep(5)#创建线程,最多维护10个线程pool = ThreadPoolExecutor(10)url_list = ["www.xxxxx-{}.com".format(i) for i in range(300)]for url in url_list:#在线程池中提交一个任务,线程池中如果有空闲线程,则分配一个线程去执行,执行完毕后再将线程交还给线程池;如果没有空闲线程则等待pool.submit(task, url, 2)print("end")(二)示例二
等待线程池的任务执行完毕,主线程再继续执行,类似于线程里的join()方法。
import time
from concurrent.futures import ThreadPoolExecutor#pool = ThreadPoolExecutor(100) 创建了100个线程def task(video_url):print("开始执行任务", video_url)time.sleep(1)#创建线程,最多维护10个线程pool = ThreadPoolExecutor(10)url_list = ["www.xxxxx-{}.com".format(i) for i in range(200)]for url in url_list:#在线程池中提交一个任务,线程池中如果有空闲线程,则分配一个线程去执行,执行完毕后再将线程交还给线程池;如果没有空闲线程则等待pool.submit(task, url)print("执行中。。。。")
pool.shutdown(True) #等待线程池中的任务执行完毕后,再继续执行
print("end")
(三)示例三
任务执行完,再干点别的事情:add_done_callback
可以分工,通过task下载,用done专门将下载的数据写入本地文件。
import time
import random
from concurrent.futures import ThreadPoolExecutor,Future#pool = ThreadPoolExecutor(100) 创建了100个线程def task(video_url):print("开始执行任务", video_url)time.sleep(2)return random.randint(0, 10)def done(responce):print("任务执行后的返回值", responce.result)#创建线程,最多维护10个线程pool = ThreadPoolExecutor(10)url_list = ["www.xxxxx-{}.com".format(i) for i in range(200)]for url in url_list:#在线程池中提交一个任务,线程池中如果有空闲线程,则分配一个线程去执行,执行完毕后再将线程交还给线程池;如果没有空闲线程则等待future = pool.submit(task, url)future.add_done_callback(done) #是子主线程执行'''
开始执行任务 www.xxxxx-2.com
开始执行任务 www.xxxxx-3.com
开始执行任务 www.xxxxx-4.com开始执行任务 www.xxxxx-5.com
开始执行任务 www.xxxxx-6.com开始执行任务 www.xxxxx-7.com
开始执行任务 www.xxxxx-8.com
开始执行任务 www.xxxxx-9.com
任务执行后的返回值 <bound method Future.result of <Future at 0x7fa69912f340 state=finished returned int>>
任务执行后的返回值 <bound method Future.result of <Future at 0x7fa69912f700 state=finished returned int>>
任务执行后的返回值 <bound method Future.result of <Future at 0x7fa69912faf0 state=finished returned int>>
开始执行任务 任务执行后的返回值 任务执行后的返回值 任务执行后的返回值 <bound method Future.result of <Future at 0x7fa699122fa0 state=finished returned int>>
开始执行任务 开始执行任务 任务执行后的返回值 <bound method Future.result of <Future at 0x7fa6991117c0 state=finished returned int>>www.xxxxx-10.com
'''
(四)示例四
引入Future方法,直接输出结果。
import time
import random
from concurrent.futures import ThreadPoolExecutor,Futuredef task(video_url):print("开始执行任务",video_url)time.sleep(2)return random.randint(0, 10)pool = ThreadPoolExecutor(10)url_list = ["www.xxxxx-{}.com".format(i) for i in range(200)]future_list = []
for url in url_list:#在线程池中提交一个任务,线程池中如果有空闲线程,则分配一个线程去执行,执行完毕后再将线程交还给线程池;如果没有空闲线程则等待future = pool.submit(task, url)future_list.append(future)pool.shutdown(True)
for fu in future_list:print(fu.result())'''
开始执行任务开始执行任务 www.xxxxx-195.com
开始执行任务 www.xxxxx-196.com
开始执行任务 www.xxxxx-197.com 开始执行任务 www.xxxxx-198.com开始执行任务 www.xxxxx-199.com
www.xxxxx-194.com
7
7
5
2
3
3
0
8
8
8
8
8
2
'''
七、单例模式(扩展)
单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。
主要有四种实现方式:
- 模块实现方式:
python 的模块就是天然的单例模式,因为模块在第一次导入时,会生成 .pyc 文件,当第二次导入时,就会直接加载 .pyc 文件,而不会再次执行模块代码。因此,我们只需把相关的函数和数据定义在一个模块中,就可以获得一个单例对象了。
- 装饰器实现方式。
- 类方法实现。
- 基于__new__ 方法实现:、
我们知道,当我们实例化一个对象时,是先执行了类的__new__方法(我们没写时,默认调用object.new),实例化对象;然后再执行类的__init__方法,对这个对象进行初始化,所以我们可以基于这个,实现单例模式。
class Singleton:instance = Nonedef __init__(self, name):self.name = namedef __new__(cls, *args, **kwargs):#返回空对象if cls.instance:print("已经有了")return cls.instanceelse:print("还没有")cls.instance = object.__new__(cls)return cls.instanceobj1 = Singleton("alex")
obj2 = Singleton("nihao")print(obj1, obj2)
'''
还没有
已经有了
<__main__.Singleton object at 0x7fa5ce9417f0> <__main__.Singleton object at 0x7fa5ce9417f0>'''
从上述实验可以看出,通过__new__方法实现单例模后,实例化的对象调用了同一个内存。但是该方法不适用多线程,应为再多线程条件下,由于cpu分区执行,可能占据不同的内存保存对象。
class Singleton:instance = Nonedef __init__(self, name):self.name = namedef __new__(cls, *args, **kwargs):#返回空对象if cls.instance:#print("已经有了")return cls.instancetime.sleep(0.1)#print("还没有")cls.instance = object.__new__(cls)return cls.instancedef task():obj = Singleton('x')print(obj)for i in range(10):t = threading.Thread(target=task)t.start()'''
<__main__.Singleton object at 0x7fa11ba419d0><__main__.Singleton object at 0x7fa11d118fd0>
<__main__.Singleton object at 0x7fa11d0fefd0>
<__main__.Singleton object at 0x7fa11d1184c0><__main__.Singleton object at 0x7fa11b86caf0>
<__main__.Singleton object at 0x7fa11b86c850>
<__main__.Singleton object at 0x7fa11b86c730>
<__main__.Singleton object at 0x7fa11b86caf0>
<__main__.Singleton object at 0x7fa11b86c850>
<__main__.Singleton object at 0x7fa11b8868e0>
'''
针对这一个问题,同样可以用RLock来解决:
class Singleton:instance = Nonelock = threading.RLock()def __init__(self, name):self.name = namedef __new__(cls, *args, **kwargs):#返回空对象if cls.instance:return cls.instancecls.instance = object.__new__(cls)with cls.lock:if cls.instance:return cls.instancetime.sleep(1)cls.instance = object.__new__(cls)return cls.instancedef task():obj = Singleton('x')print(obj)for i in range(10):t = threading.Thread(target=task)t.start()'''
<__main__.Singleton object at 0x7fb7166d5910>
<__main__.Singleton object at 0x7fb7166d5910>
<__main__.Singleton object at 0x7fb7166d5910>
<__main__.Singleton object at 0x7fb7166d5910>
<__main__.Singleton object at 0x7fb7166d5910>
<__main__.Singleton object at 0x7fb7166d5910>
<__main__.Singleton object at 0x7fb7166d5910>
<__main__.Singleton object at 0x7fb7166d5910>
<__main__.Singleton object at 0x7fb7166d5910>
<__main__.Singleton object at 0x7fb7166d5910>
'''相关文章:
【python开发】并发编程(上)
并发编程(上) 一、进程和线程(一)多线程(二)多进程(三)GIL锁 二、多线程开发(一)t.start()(二)t.join()(三)t.…...

用c语言实现扫雷游戏
文章目录 概要整体架构流程代码的实现小结 概要 学习了c语言后,我们可以通过c语言写一些小程序,然后我们这篇文章主要是,扫雷游戏的一步一步游戏。 整体架构流程 扫雷网页版 根据上面网页版的基础扫雷可以看出是一个99的格子,…...

LeetCode 2882.删去重复的行
DataFrame customers ------------------- | Column Name | Type | ------------------- | customer_id | int | | name | object | | email | object | ------------------- 在 DataFrame 中基于 email 列存在一些重复行。 编写一个解决方案,删除这些重复行&#…...
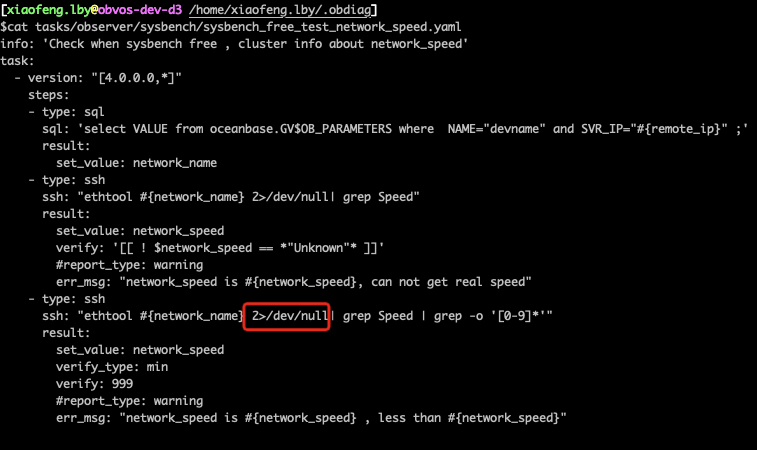
对OceanBase进行 sysbench 压测前,如何用 obdiag巡检
有一些用户想对 OceanBase 进行 sysbench 压测,并向我询问是否需要对数据库的各种参数进行调整。我想起有一个工具 obdiag ,具备对集群进行巡检的功能。因此,我正好借此机会试用一下这个工具。 obdiag 功能的比较丰富,详细情况可参…...

每天学习几道面试题|Kafka架构设计类
文章目录 1. Kafka 是如何保证高可用性和容错性的?2. Kafka 的存储机制是怎样的?它是如何处理大量数据的?3. Kafka 如何处理消费者的消费速率低于生产者的生产速率?4. Kafka 集群中的 Controller 是什么?它的作用是什么…...
.rmallox勒索病毒解密方法|勒索病毒解决|勒索病毒恢复|数据库修复
导言: 近年来,勒索病毒的威胁日益增加,其中一种名为.rmallox的勒索病毒备受关注。这种病毒通过加密文件并勒索赎金来威胁受害者。本文将介绍.rmallox勒索病毒的特点,以及如何恢复被其加密的数据文件,并提供预防措施&a…...

安卓性能优化面试题 11-15
11. 简述APK安装包瘦身方案 ?(1):剔 除掉冗余的代码与不必要的jar包;具体来讲的话,我们可以使用SDK集成的ProGuard混淆工具,它可以在编译时检查并删除未使用的类、字段、方法 和属性,它会遍历所有代码找到无用处的代码,所有那些不可达的代码都会在生成最终apk文件之前被…...

Python错题集-9PermissionError:[Errno 13] (权限错误)
1问题描述 Traceback (most recent call last): File "D:\pycharm\projects\5-《Python数学建模算法与应用》程序和数据\02第2章 Python使用入门\ex2_38_1.py", line 9, in <module> fpd.ExcelWriter(data2_38_3.xlsx) #创建文件对象 File "D:…...

QT TCP通信介绍
QT是一个跨平台的C应用程序开发框架,它提供了一套完整的工具和库,用于开发各种类型的应用程序,包括图形用户界面(GUI)应用程序、命令行工具、网络应用程序等。QT提供了丰富的功能和类来简化网络通信的开发,其中包括TCP通信。 TCP…...
保姆级教学!微信小程序设计全攻略!
微信小程序开启了互联网软件的新使用模式。在各种微信小程序争相抢占流量的同时,如何设计微信小程序?让用户感到舒适是设计师在产品设计初期应该考虑的问题。那么如何做好微信小程序的设计呢?即时设计总结了以下设计指南,希望对准…...

日期差值的计算
1、枚举所有数值进行日期判断 时间复杂度是o(n)的,比较慢,单实例能凑合用,多实例的话时间复杂度有点高。 核心代码就是判断某个八位数能否表示一个日期。 static int[] month {0,31,28,31,30,31,30,31,31,30,31,30,31};static String a, b…...
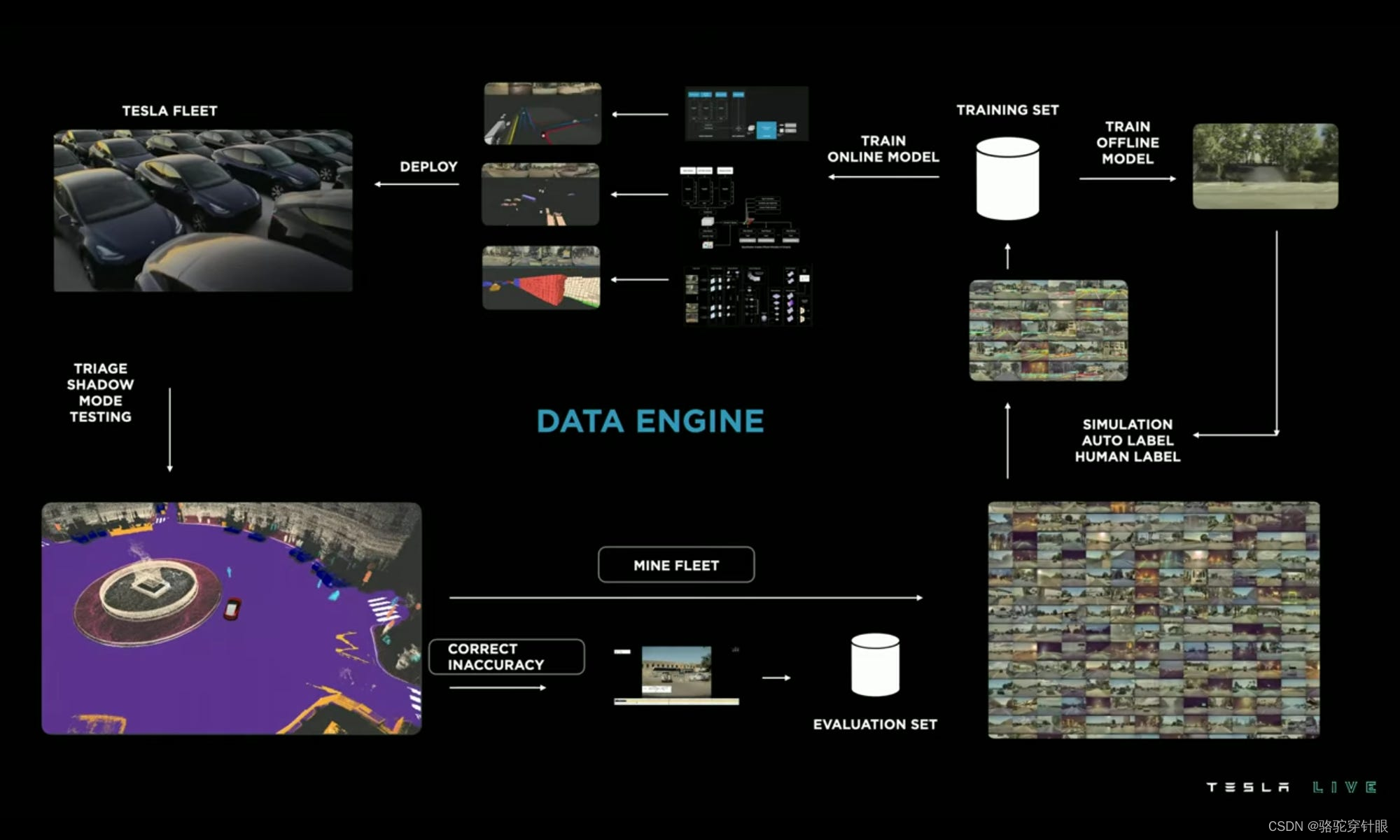
为什么需要Occupancy?
1.能够得到3D的占用信息 在基于BEV (鸟瞰图) 的2D预测模型中,我们通常仅具有二维平面(x和y坐标)上的信息。这种方法对于很多应用场景来说已经足够,但它并不考虑物体在垂直方向(z轴)上的分布。这限制了模型的…...
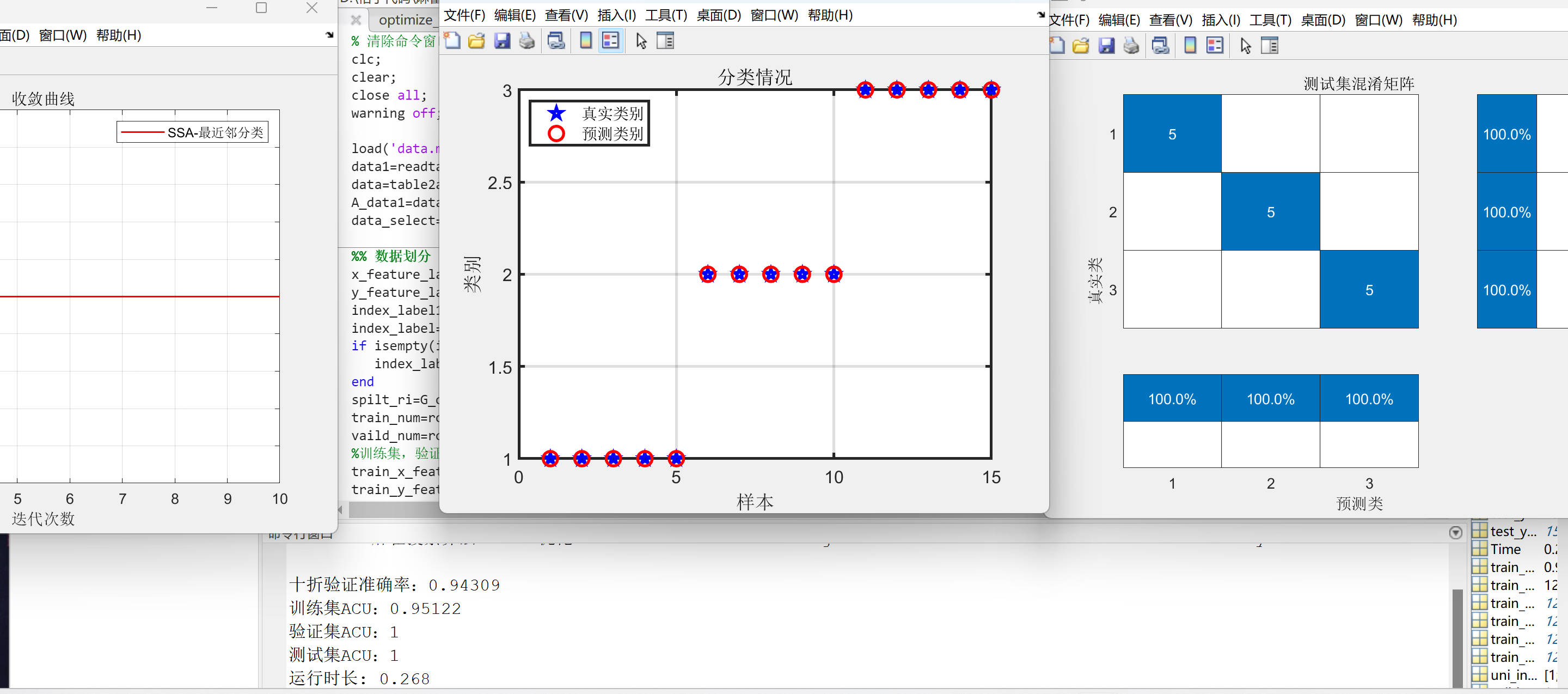
SSA优化最近邻分类预测(matlab代码)
SSA-最近邻分类预测matlab代码 麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种新型的群智能优化算法,在2020年提出,主要是受麻雀的觅食行为和反捕食行为的启发。 数据为Excel分类数据集数据。 数据集划分为训练集、验证集、测试集,比例为8&#…...

nginx相关内容的安装
nginx的安装 安装依赖 yum install gcc gcc-c automake autoconf libtool make gd gd-devel libxslt-devel -y 安装lua与lua依赖 lua安装步骤如下: mkdir /www mkdir /www/server #选择你自己的目录即可,不需要跟我一致 cd /www/server tar -zxvf lua-5.4.3.tar.gz cd lua-5.4…...
基于SpringBoot和Echarts的全国地震可视化分析实战
目录 前言 一、后台数据服务设计 1、数据库查询 2、模型层对象设计 3、业务层和控制层设计 二、Echarts前端配置 1、地图的展示 2、次数排名统计 三、最终结果展示 1、地图展示 2、图表展示 总结 前言 在之前的博客中基于SpringBoot和PotsGIS的各省地震震发可视化分…...

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的农作物害虫检测系统(深度学习模型+UI界面+训练数据集)
摘要:开发农作物害虫检测系统对于提高农业生产效率和作物产量具有关键作用。本篇博客详细介绍了如何运用深度学习构建一个农作物害虫检测系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5࿰…...

21 # 高级类型:条件类型
条件类型(Conditional Types)是一种高级的类型工具,它允许我们基于一个类型关系来选择另一个类型。条件类型通常使用条件表达式 T extends U ? X : Y 的形式,其中根据泛型类型 T 是否可以赋值给类型 U 来确定最终的类型是 X 还是…...
.sorted(Comparator.comparing())排序异常解决方案)
Java之List.steam().sorted(Comparator.comparing())排序异常解决方案
使用steam().sorted(Comparator.comparing())对List<T>集合里的String类型字段进行倒序排序,发现倒序失效。记录解决方案。 异常代码如下: customerVOList customerVOList.stream().sorted(Comparator.comparing(CustomerVOVO::getCustomerRate).reversed()…...
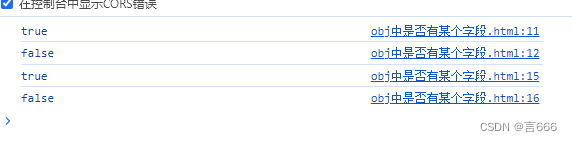
js判断对象是否有某个属性
前端判断后端接口是否返回某个字段的时候 <script>var obj { name: "John", age: 30 };console.log(obj.hasOwnProperty("name")); // 输出 trueconsole.log(obj.hasOwnProperty("email")); // 输出 falselet obj11 { name: "Joh…...

CleanMyMac X2024永久免费的强大的Mac清理工具
作为产品功能介绍专员,很高兴向您详细介绍CleanMyMac X这款强大的Mac清理工具。CleanMyMac X具有广泛的清理能力,支持多种文件类型的清理,让您的Mac始终保持最佳状态。 系统垃圾 CleanMyMac X能够深入系统内部,智能识别并清理各种…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...