Java中解析XML文件
1 在Java中解析XML文件共有四种方式
- A、DOM方式解析XML数据
树结构,有助于更好地理解、掌握,代码易于编写,在解析过程中树结构是保存在内存中,方便修改
- B、SAX方式解析
采用事件驱动模式,对内存消耗比较小,适用于仅处理xml中的数据时使用
- C、JDOM方式解析
大量采用了 Collections 类
- D、DOM4J方式解析
JDOM的一种智能分支,合并了许多超出基本XML文档表示的功能;
性能优越,灵活性好,功能强大,极端易用。
2 要处理的XML文件
<?xml version="1.0" encoding="UTF-8"?> <books xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"><book id="1001"><name>JAVA 高级编程</name><author>张三</author><price>85.72</price></book><book id="1002"><name>C++和C#</name><author>李失失</author><price>125.73</price></book> </books>
3 DOM方式解析XML数据的步骤
a. 创建一个DocumentBuilderFactory对象
b. 创建一个DocumentBuilder对象
c. 通过DocumentBuilder的parse()方法,得到Document对象
d. 通过getElementsByTagName()方法,获取节点的列表
e. 使用for循环遍历节点
f. 得到所有节点的属性和属性值
g. 得到所有节点的节点名和节点值
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;public class TestDom4Xml {public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {//创建一个DocumentBuilderFactory对象DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();//创建一个DocumentBuilder对象DocumentBuilder db = dbf.newDocumentBuilder();//通过DocumentBuilder的parse()方法,得到Document对象Document doc = db.parse("book.xml");//通过getElementsByTagName()方法,获取节点的列表NodeList nodelist = doc.getElementsByTagName("book");System.out.println(nodelist.getLength());//使用for循环遍历节点for(int i=0;i<nodelist.getLength();i++){Node node = nodelist.item(i);//得到所有节点属性和属性值的对象NamedNodeMap nnm = node.getAttributes();for(int j=0;j<nnm.getLength();j++){Node sub_node = nnm.item(j);//得到所有节点的属性和属性值System.out.println(sub_node.getNodeName() + " : " + sub_node.getNodeValue());}//得到所有节点的子节点NodeList childlist = node.getChildNodes();for(int j=0;j<childlist.getLength();j++){Node sub_node = childlist.item(j);//获取节点类型short type = sub_node.getNodeType();//判断节点类型是否不为#text,因会将前一标签的末尾>与下一标签的开头<之间的字符,标记为#text//因此这里需要进行判断if(type == Node.ELEMENT_NODE){//得到所有节点的节点名和节点值System.out.println(sub_node.getNodeName() + " : " + sub_node.getTextContent());}}}}
}
输出结果如下
2
id : 1001
name : JAVA 高级编程
author : 张三
price : 85.72
id : 1002
name : C++和C#
author : 李失失
price : 125.73
4 SAX方式解析XML文件
4.1 创建DeaultHandler子类,用来解析XML文档
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;public class BookDefaultHandler extends DefaultHandler {/*** 解析xml文档时调用*/public void startDocument() throws SAXException {System.out.println("开始解析XML文档");super.startDocument();}/*** 解析xml文档结束时调用*/public void endDocument() throws SAXException {super.endDocument();System.out.println("完成解析XML文档");}/*** 解析XML文档节点开始时使用*/public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {super.startElement(uri, localName, qName, attributes);//判断如果是 book节点,获取节点属性和属性值if(qName.equals("book")){//获取当前属性的数量int len = attributes.getLength();//循环获取每个属性for(int i=0;i<len;i++){//属性名称String name = attributes.getQName(i);//属性值String value = attributes.getValue(i);System.out.println("属性名称: " + name + "\t属性值: " + value);}}else if(!"books".equals(qName) && !"book".equals(qName)){System.out.print("节点的名称:" + qName + "\t");}}/*** 解析XML文档节点结束时使用*/public void endElement(String uri, String localName, String qName) throws SAXException {super.endElement(uri, localName, qName);}/*** 解析节点文本内容*/public void characters(char[] ch, int start, int length) throws SAXException {super.characters(ch, start, length);//将节点文本转为字符串String value = new String(ch, start, length);//排除空数据,并输出节点文本if(!"".equals(value.trim())){System.out.println(value);}}
}
4.2 SAX方式解析XML数据的步骤
a. 创建SAXParserFactory对象
b. 创建SAXParser对象(作为解析器)
c. 创建DefaultHandler子类对象
d. 调用parse方法
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.SAXException;public class TestSax4Xml {public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {//a. 创建SAXParserFactory对象SAXParserFactory spf = SAXParserFactory.newInstance();//b. 创建SAXParser对象(作为解析器)SAXParser sp = spf.newSAXParser();//c. 创建DefaultHandler子类对象BookDefaultHandler bdh = new BookDefaultHandler();//d. 调用SAXParser对象的parse方法sp.parse("book.xml", bdh);}
}
4.3 输出结果
开始解析XML文档
属性名称: id 属性值: 1001
节点的名称:name JAVA 高级编程
节点的名称:author 张三
节点的名称:price 85.72
属性名称: id 属性值: 1002
节点的名称:name C++和C#
节点的名称:author 李失失
节点的名称:price 125.73
完成解析XML文档
5 JDOM方式解析XML数据
5.1 步骤
a. 创建SAXBuilder对象
b. 调用build方法,通过IO流得到Document对象
c. 获取根节点
d. 获取根节点下直接子节点的集合
e. 遍历集合
import java.io.FileInputStream;
import java.io.IOException;
import java.util.List;import org.jdom2.Attribute;
import org.jdom2.Document;
import org.jdom2.Element;
import org.jdom2.JDOMException;
import org.jdom2.input.SAXBuilder;public class TestJdom4Xml {public static void main(String[] args) throws JDOMException, IOException {//a. 创建SAXBuilder对象SAXBuilder sb = new SAXBuilder();//b. 调用build方法,通过OI流得到Document对象Document doc = sb.build(new FileInputStream("src/book.xml"));//c. 获取根节点Element root = doc.getRootElement();//d. 获取根节点下直接子节点的集合List<Element> books = root.getChildren();//e. 遍历集合,获取每一个子节点for(int i=0;i<books.size();i++){//获取集合中的元素Element book = books.get(i);//获取当前节点下的属性集合List<Attribute> atts = book.getAttributes();for(int j=0;j<atts.size();j++){//输出属性名称:属性值System.out.println(atts.get(j).getName() + "\t" + atts.get(j).getValue());}//获取当前节点下子节点List<Element> subEles = book.getChildren();//遍历子节点,获取名称和文本值for(Element e : subEles){System.out.println(e.getName() + "\t" + e.getValue());}}}
}
5.2 输出结果
id 1001
name JAVA 高级编程
author 张三
price 85.72
id 1002
name C++和C#
author 李失失
price 125.73
6 DOM4J解析XML
6.1 DOM4J解析XML步骤
a. 创建SAXReader对象
b. 调用read方法
c. 获取根节点
d. 通过迭代器遍历直接节点
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.util.Iterator;import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;public class TestDom4jXml {public static void main(String[] args) throws FileNotFoundException, DocumentException {//a. 创建SAXReader对象SAXReader sr = new SAXReader();//b. 调用read方法Document doc = sr.read(new FileInputStream("src/book.xml"));//c. 获取根节点Element root = doc.getRootElement();//d. 通过迭代器遍历直接节点for(Iterator<Element> iter=root.elementIterator();iter.hasNext();){Element book = iter.next();//获取节点下所有属性Iterator<Attribute> arrts = book.attributeIterator();//遍历属性信息while(arrts.hasNext()){Attribute at = arrts.next();String name = at.getName();String value = at.getValue();System.out.println("节点属性:" + name + "\t" + value);}//遍历节点下子节点Iterator<Element> subele = book.elementIterator();//获取子节点下所有节点名称和文本值while(subele.hasNext()){Element node = subele.next();System.out.println(node.getName() + "\t" + node.getText());}}}
}
6.2 输出结果
节点属性:id 1001
name JAVA 高级编程
author 张三
price 85.72
节点属性:id 1002
name C++和C#
author 李失失
price 125.73
相关文章:

Java中解析XML文件
1 在Java中解析XML文件共有四种方式 A、DOM方式解析XML数据 树结构,有助于更好地理解、掌握,代码易于编写,在解析过程中树结构是保存在内存中,方便修改 B、SAX方式解析 采用事件驱动模式,对内存消耗比较小࿰…...
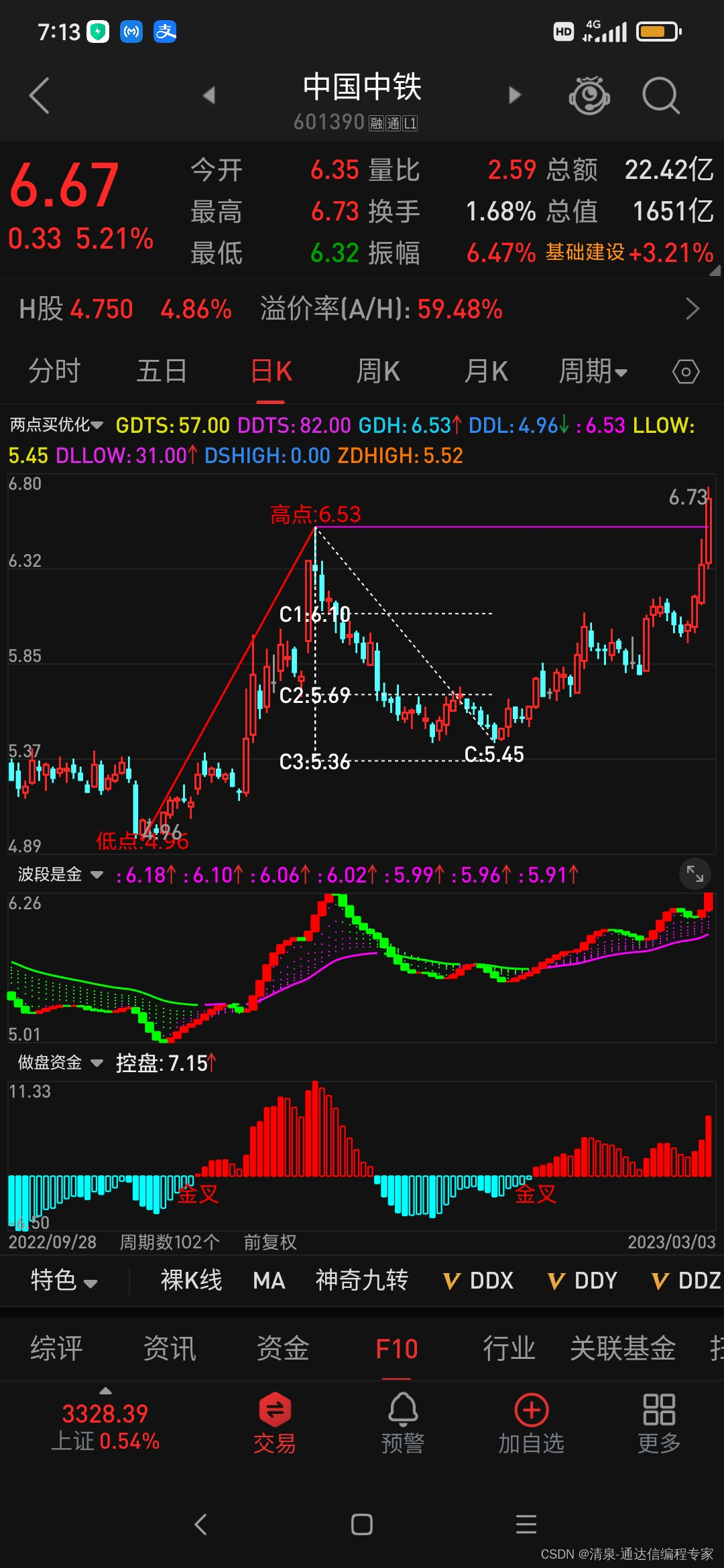
二点回调测买 源码
如图所示,两点回调测买点的效果图,这是我们常见的一种预测买点计算方法。 现将源码公布如下: DRAWKLINE(H,O,L,C); N:13; A1:REF(HIGH,N)HHV(HIGH,2*N1); B1:FILTER(A1,N); C1:BACKSET(B1,N1); D1:FILTER(C1,N); A2:REF(LOW,N)LLV(LOW,2*N1…...
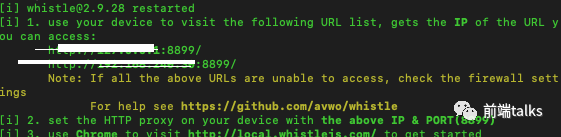
钉钉端H5开发调试怎么搞
H5开发本地调试教程 作为一名前端开发,大家平时工作中或多或少都有接触或需要开发H5页面的场景,在开发过程中,如何像PC端页面一样有有丝滑的体验呢? 不同的情况需要在不同的端调试更方便有效: 1. 在画UI的时候,更适合在PC端调试,更改代码或者直接在浏览器调试,都是实…...
Mysql Server原理简介
Mysql客户端包括JDBC、 Navicat、sqlyog,只是为了和mysql server建立连接,向mysql server提交sql语句。mysql server组件第一部分叫连接器主要承担的功能叫管理连接和验证权限,每次在进行数据库访问的时候,必然要输入用户名和密码…...

23种设计模式-外观模式
外观模式是一种结构型设计模式,它提供了一个统一的接口,用来访问子系统中的一群接口。外观模式定义了一个高层接口,使得客户端可以更加方便地访问子系统的功能。在这篇博客中,我们将讨论如何使用Java实现外观模式,并通…...

使用 Vulkan VkImage 作为 CUDA cuArray
使用 Vulkan VkImage 作为 CUDA cuArray【问题标题】:Use Vulkan VkImage as a CUDA cuArray使用 Vulkan VkImage 作为 CUDA cuArray【发布时间】:2019-08-20 20:01:10【问题描述】:将 Vulkan VkImage 用作 CUDA cuArray 的正确方法是什么&am…...

电商API接口-电商OMS不可或缺的一块 调用代码展示
电商后台管理系统关键的一环就是实现电商平台数据的抓取,以及上下架商品、订单修改等功能的调用。这里就需要调用电商API接口。接入电商API接口后再根据自我的需求进行功能再开发,实现业务上的数字化管理。其中订单管理模板上需要用到如下API:seller_ord…...

Solaris ZFS文件系统rpool扩容
ZFS文件系统简介 Solaris10默认的文件系统是ufs(Unix Filesystem),当然也可以选装zfs;Solaris11默认的文件系统是zfs(Zettabyte Filesystem)。 ZFS文件系统的英文名称为Zettabyte File System,也叫动态文件…...
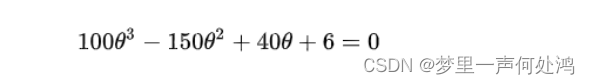
模式识别 —— 第二章 参数估计
模式识别 —— 第二章 参数估计 文章目录模式识别 —— 第二章 参数估计最大似然估计(MLE)最大后验概率估计(MAP)贝叶斯估计最大似然估计(MLE) 在语言上: 似然(likelihood…...
)
判断4位回文数-课后程序(Python程序开发案例教程-黑马程序员编著-第3章-课后作业)
实例1:判断4位回文数 所谓回文数,就是各位数字从高位到低位正序排列和从低位到高位逆序排列都是同一数值的数,例如,数字1221按正序和逆序排列都为1221,因此1221就是一个回文数;而1234的各位按倒序排列是43…...
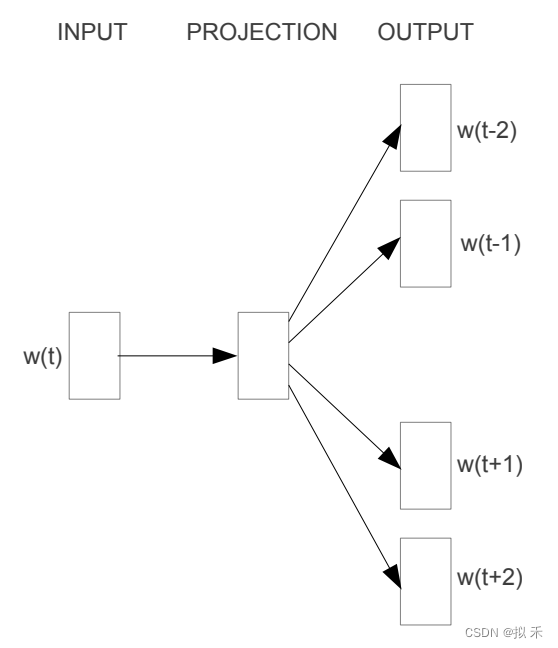
【NLP】Word2Vec 介绍
Word2Vec 是一种非常流行的自然语言处理技术,它将每个单词表示为高维向量,并且通过向量之间的相似度来表示单词之间的语义关系。 1 One-Hot 编码🍂 在自然语言处理任务中,我们需要将文本转换为计算机可以理解的形式,即…...

3月6日,30秒知全网,精选7个热点
///石家庄地铁:在指定店铺购物金额不限 就可免费乘地铁 乘客只要在指定商铺或地铁站内36524便利店购物,便能得到一张当日乘车券,可免费乘坐地铁一次,不限里程 ///神州泰岳:公司语音机器人等产品能够进行多轮问答 公司…...

Python笔记 -- 字典
文章目录1、概述2、增删改查3、遍历3.1、遍历所有键值对3.2、分别遍历键和值4、嵌套4.1、字典列表4.2、在字典中储存列表4.3、在字典中储存字典1、概述 字典是一系列键值对,可将任何Python对象作为字典中的值 字典和列表容易混淆,列表也可用{} 字典是一…...
)
【独家】华为OD机试 - 滑动窗口(C 语言解题)
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 最近更新的博客使用说明本期…...

MySQL调优 - SQL查询深度分页问题
一、问题引入 例如当前存在一张表test_user,然后往这个表里面插入3百万的数据: CREATE TABLE test_user (id int(11) NOT NULL AUTO_INCREMENT COMMENT 主键id,user_id varchar(36) NOT NULL COMMENT 用户id,user_name varchar(30) NOT NULL COMMENT 用…...
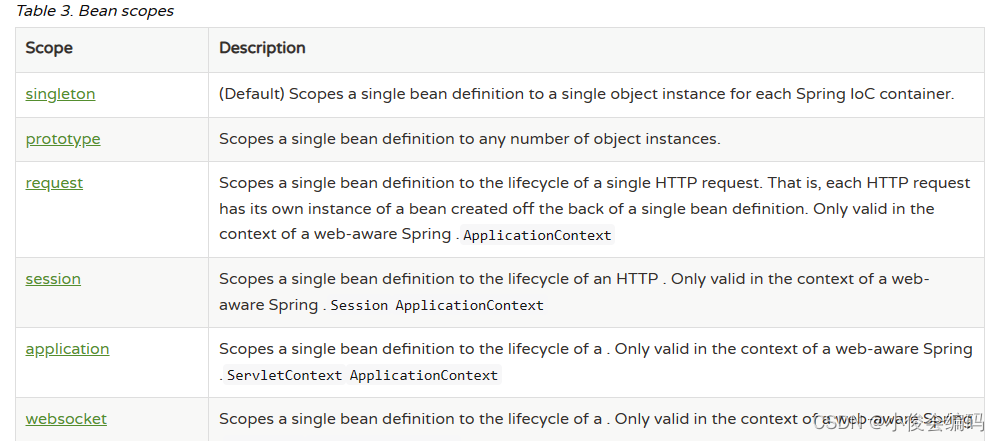
0306spring--复习
一,spring是什么 Spring是一个轻量级的控制反转(IOC)和面向切面编程(AOP)的容器框架 理念:使现有的技术更加容易使用,本身是一个大杂烩,整合了现有的技术框架 优点࿱…...

动手实现一遍Transformer
最近乘着ChatGpt的东风,关于NLP的研究又一次被推上了风口浪尖。在现阶段的NLP的里程碑中,无论如何无法绕过Transformer。《Attention is all you need》成了每个NLP入门者的必读论文。惭愧的是,我虽然使用过很多基于Transformer的模型&#x…...

【Flutter入门到进阶】Flutter基础篇---弹窗Dialog
1 AlertDialog 1.1 说明 最简单的方案是利用AlertDialog组件构建一个弹框 1.2 示例 void alertDialog(BuildContext context) async {var result await showDialog(barrierDismissible: false, //表示点击灰色背景的时候是否消失弹出框context: context,builder: (context)…...

【操作系统】进程和线程的区别
文章目录1. 概述2. 进程3. 线程4. 协程5. 进程与线程区别1. 概述 进程和线程这两个名词天天听,但是对于它们的含义和关系其实还有点懵的,其实除了进程和线程,还存在一个协程,它们的关系如下: 首先,我们需要…...
Linux开发环境配置--正点原子阿尔法开发板
Linux开发环境配置–正点原子阿尔法开发板 文章目录Linux开发环境配置--正点原子阿尔法开发板1.网络环境设置1.1添加网络适配器1.2虚拟网络编辑器设置1.3Ubuntu和Windows网络信息设置Ubuntu网络信息配置方式:1.系统设置->网络->选项2.配置网络文件2源码准备2.…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...