MySQL调优 - SQL查询深度分页问题
一、问题引入
例如当前存在一张表test_user,然后往这个表里面插入3百万的数据:
CREATE TABLE `test_user` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',`user_id` varchar(36) NOT NULL COMMENT '用户id',`user_name` varchar(30) NOT NULL COMMENT '用户名称',`phone` varchar(20) NOT NULL COMMENT '手机号码',`lan_id` int(9) NOT NULL COMMENT '本地网',`region_id` int(9) NOT NULL COMMENT '区域',`create_time` datetime NOT NULL COMMENT '创建时间',PRIMARY KEY (`id`),KEY `idx_user_id` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT;在数据库开发过程中我们经常会使用分页,核心技术是使用用 limit start, count 分页语句进行数据的读取。
我们分别看下从0、10000、100000、500000、1000000、1800000开始分页的执行时长(每页取100条)。
SELECT * FROM test_user LIMIT 0,100; # 0.031
SELECT * FROM test_user LIMIT 10000,100; # 0.047
SELECT * FROM test_user LIMIT 100000,100; # 0.109
SELECT * FROM test_user LIMIT 500000,100; # 0.219
SELECT * FROM test_user LIMIT 1000000,100; # 0.547s
SELECT * FROM test_user LIMIT 1800000,100; # 1.625s我们已经看出随着起始记录的增加,时间也随着增大。这说明分页语句limit跟起始页码是有很大关系的,那么我们把起始记录改为290w看下:
SELECT * FROM test_user LIMIT 2900000,100; # 3.062s我们惊讶的发现MySQL在数据量大的情况下分页起点越大,查询速度越慢!
那么为什么会出现上述这种情况呢?
答案: 因为 limit 2900000,100 的语法实际上是mysql扫描到前2900100条数据,之后丢弃前面的3000000行,这个步骤其实是浪费掉的。
从中我们也能总结出以下两件事情:
limit语句的查询时间与起始记录的位置成正比。
mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
二、MySQL中的limit用法
limit子句可以被用于强制select语句返回指定的记录数,其语法格式如下:
SELECT * FROM 表名 limit m,n;
SELECT * FROM table LIMIT [offset,] rows;limit接受一个或两个数字参数,参数必须是一个整数常量,如果给定两个参数:
- 第一个参数指定第一个返回记录行的偏移量
- 第二个参数指定返回记录行的最大数目
2.1 m代表从m+1条记录行开始检索,n代表取出n条数据。(m可设为0)
SELECT * FROM 表名 limit 6,5;上述SQL表示从第7条记录行开始算,取出5条数据
2.2 值得注意的是,n可以被设置为-1,当n为-1时,表示从m+1行开始检索,直到取出最后一条数据
SELECT * FROM 表名 limit 6,-1;上述SQL表示取出第6条记录行以后的所有数据
2.3 若只给出m,则表示从第1条记录行开始算一共取出m条
SELECT * FROM 表名 limit 6;2.4 以年龄倒序后取出前3行
select * from student order by age desc limit 3;2.5 跳过前3行后再2取行
select * from student order by age desc limit 3,2;三、深度分页优化策略
方法一:用主键id或者唯一索引优化
即先找到上次分页的最大id,然后利用id上的索引来查询:
SELECT * FROM test_user WHERE id>1000000 LIMIT 100; # 0.047秒使用此优化SQL相比于前面的查询速度已经快了11倍。除了主键ID,也可以利用唯一索引快速定位部分数据,避免全表扫描。例如读取第1000到1019行数据(pk是唯一键),则相对应的优化SQL如下:
SELECT * FROM 表名称 WHERE pk>=1000 ORDER BY pk ASC LIMIT 0,20原因:索引扫描,速度会很快。
适用场景:如果数据查询出来是按照pk或者id进行排序,并且全部数据没有缺失的话则可以这样优化,否则分页操作会漏数据。
方法二:利用索引覆盖优化
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(也就是索引覆盖),那么这种情况会查询很快。
为什么索引覆盖查询会很快呢?
答案:因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。另外Mysql中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。
在我们的测试表test_user中,id字段是主键,自然就包含了默认的主键索引。现在让我们看看利用覆盖索引的查询效果如何。
这次我们查询第1000001到1000100行的数据(利用覆盖索引,只包含id列):
SELECT id FROM test_user LIMIT 1000000,100; # 0.843秒从这个结果中发现查询速度比全表扫描速度还要慢(当然在重复执行这条SQL,多次查询之后速度还是变快了很多,几乎省了一半时间,这是由于缓存的原因), 接着使用explain命令来查看该SQL的执行计划,发现该SQL执行采用的普通索引 idx_user_id:
EXPLAIN SELECT id FROM test_user LIMIT 1000000,100;
如果我们把普通索引给删除的话,就会发现执行上述SQL其采用的会是主键索引。那如果不删除普通索引的话,针对这种情况,我们要让上述SQL走主键索引的话,则可以使用order by语句:
SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100; # 0.250秒那么如果我们也要查询所有列,有两种方法,一种是id>=的形式,另一种就是利用join。
第一种写法:
SELECT * FROM test_user WHERE ID >= (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,1) LIMIT 100;
上述SQL查询时间为0.281秒
第二种写法:
SELECT * FROM (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100) a LEFT JOIN test_user b ON a.id = b.id;上述SQL查询时间为0.252秒
方法三:基于索引再排序
其中pageNum表示页码,其取值从0开始;pageSize表示指的是每页多少条数据。
SELECT * FROM 表名称 WHERE id_pk > (pageNum*pageSize) ORDER BY id_pk ASC LIMIT pageSize;适应场景:
- 适用于数据量多的情况
- 最好ORDER BY后的列对象是主键或唯一索引
- id数据没有缺失,可以作为序号使用
- 使用ORDER BY操作能利用索引被消除,但结果集是稳定的
原因:
- 索引扫描,速度会很快
- 但MySQL的排序操作,只有ASC没有DESC。MySQL中索引存储的排序方式是ASC的,没有DESC的索引。这就能够理解为啥order by 默认是按照ASC来排序的了吧
方法四:基于索引使用prepare
PREPARE预编译一个SQL语句,并为其分配一个名称 stmt_name,以便以后引用该语句,预编译好的语句用EXECUTE执行。
PREPARE stmt_name FROM 'SELECT * FROM test_user WHERE id > ? ORDER BY id ASC LIMIT ?';
SET @a = 1000000;
SET @b = 100;
EXECUTE stmt_name USING @a, @b;;
上述SQL查询时间为0.047秒。
对于定义好的PREPARE预编译语句,我们可以使用下述命令来释放该预编译语句:
DEALLOCATE PREPARE stmt_name;原因:
- 索引扫描,速度会很快.
- prepare语句又比一般的查询语句快一点。
方法五:利用"子查询+索引"快速定位数据
其中page表示页码,其取值从0开始;pagesize表示指的是每页多少条数据。
SELECT * FROM your_table WHERE id <= (SELECT id FROM your_table ORDER BY id DESC LIMIT ($page-1)*$pagesize ORDER BY id DESC LIMIT $pagesize);方法六:利用复合索引进行优化
假设数据表 collect ( id, title ,info ,vtype) 就这4个字段,其中id是主键自增,title用定长,info用text, vtype是tinyint,vtype是一个普通索引。
现在往里面填充数据,填充10万条记录,数据库表占用硬1.6G。
select id,title from collect limit 1000,10;执行上述SQL速度很快,基本上0.01秒就OK。
select id,title from collect limit 90000,10;然后再执行上述SQL,就发现非常慢,基本上平均8~9秒完成。
这个时候如果我们执行下述,我们会发现速度又变的很快,0.04秒就OK。
select id from collect order by id limit 90000,10;那么这个现象的原因是什么?
答案:因为用了id主键做索引, 这里实现了索引覆盖,当然快。
所以如果想一起查询其它列的话,可以按照索引覆盖进行优化,具体如下:
select id,title from collect where id >= (select id from collect order by id limit 90000,1) limit 10;再看下面的语句,带上where 条件:
select id from collect where vtype=1 order by id limit 90000,10; 可以发现这个速度上也是很慢的,用了8~9秒!
这里有一个疑惑:vtype 做了索引了啊?怎么会慢呢?
vtype做了索引是不错,如果直接对vtype进行过滤:
select id from collect where vtype=1 limit 1000,10;可以看到速度还是很快的,基本上0.05秒,如果从9万开始,那就是0.05*90=4.5秒的速度了。
其实加了 order by id 就不走索引,这样做还是全表扫描,解决的办法是:复合索引!
因此针对下述SQL深度分页优化时可以加一个search_index(vtype,id)复合索引:
select id from collect where vtype=1 order by id limit 90000,10; 综上:
- 在进行SQL查询深度分页优化时,如果对于有where条件,又想走索引用limit的,必须设计一个索引,将where放第一位,limit用到的主键放第二位,而且只能select 主键。
- 最后根据查询出的主键走一级索引找到对应的数据。
- 按这样的逻辑,百万级的limit 在0.0x秒就可以分完,完美解决了分页问题。
相关文章:
MySQL调优 - SQL查询深度分页问题
一、问题引入 例如当前存在一张表test_user,然后往这个表里面插入3百万的数据: CREATE TABLE test_user (id int(11) NOT NULL AUTO_INCREMENT COMMENT 主键id,user_id varchar(36) NOT NULL COMMENT 用户id,user_name varchar(30) NOT NULL COMMENT 用…...
0306spring--复习
一,spring是什么 Spring是一个轻量级的控制反转(IOC)和面向切面编程(AOP)的容器框架 理念:使现有的技术更加容易使用,本身是一个大杂烩,整合了现有的技术框架 优点࿱…...

动手实现一遍Transformer
最近乘着ChatGpt的东风,关于NLP的研究又一次被推上了风口浪尖。在现阶段的NLP的里程碑中,无论如何无法绕过Transformer。《Attention is all you need》成了每个NLP入门者的必读论文。惭愧的是,我虽然使用过很多基于Transformer的模型&#x…...

【Flutter入门到进阶】Flutter基础篇---弹窗Dialog
1 AlertDialog 1.1 说明 最简单的方案是利用AlertDialog组件构建一个弹框 1.2 示例 void alertDialog(BuildContext context) async {var result await showDialog(barrierDismissible: false, //表示点击灰色背景的时候是否消失弹出框context: context,builder: (context)…...

【操作系统】进程和线程的区别
文章目录1. 概述2. 进程3. 线程4. 协程5. 进程与线程区别1. 概述 进程和线程这两个名词天天听,但是对于它们的含义和关系其实还有点懵的,其实除了进程和线程,还存在一个协程,它们的关系如下: 首先,我们需要…...
Linux开发环境配置--正点原子阿尔法开发板
Linux开发环境配置–正点原子阿尔法开发板 文章目录Linux开发环境配置--正点原子阿尔法开发板1.网络环境设置1.1添加网络适配器1.2虚拟网络编辑器设置1.3Ubuntu和Windows网络信息设置Ubuntu网络信息配置方式:1.系统设置->网络->选项2.配置网络文件2源码准备2.…...

Android ThreadPoolExecutor的基本使用
ThreadPoolExecutor是Java中的一个线程池类,Android中也可以使用该类来管理自己的线程池,它为我们管理线程提供了很多方便。 线程池是一种能够帮助我们管理和复用线程的机制,它可以有效地降低线程创建和销毁的开销。使用线程池可以避免不必要…...

基于区域生长和形态学处理的图像融合方法——Matlab图像处理
✅ 大三下时弄的 文章目录最终效果图摘要1 研究背景及意义2 基本原理描述3 实验数据来源3.1 原始图像的来源3.2 天空背景图像的来源4 实验步骤及相应处理结果4.1 原始图像的预处理4.2 区域生长法分割图像4.3 形态学处理填充孔洞4.4 边缘检测根据二值图像构造RGB图像4.5 图像拼接…...
三个案例场景带你掌握Cisco交换机VLAN互通
VLAN间路由的方式现在主流的组网主要是依靠三层交换机通过配置SVI接口【有的厂商叫VLANIF接口】,当然也有比较小型的网络,它就一个出口路由器可管理的二层交换机,还有一种更加差的,就是出口路由一个可管理的二层交换机,…...

小白入门之持久连接与非持久连接的差别
对比 HTTP 0.9 已过时 HTTP1.0:非持续连接,每个连接只处理一个请求响应事务,有些服务器端甚至还在用此,可以在一定时间内复用连接,具体复用时间的长短可以由服务器控制,一般在15s左右。 HTTP 1.1 默认使用持…...

TypeScript篇.01-简介,类,接口,基础类型
1.简介(1)安装及编译安装: npm install -g typescript创建 .ts 后缀名的文件编译: tsc 文件名.ts 编译后会生成同名 .js 的文件查看: 在html文件中script引入js文件,运行查看控制台即可(2)类型注解TypeScript里的类型注解是一种轻量级的为函数或变量添加约束的方式 变量或函数声…...

分享几种WordPress怎么实现相关文章功能
一淘模板(56admin.com)给大家介绍一下WordPress代码实现相关文章的几种方法,希望对大家有所帮助! WordPress很多插件可以实现相关文章的功能,插件的优点是配置简单,但是可能会对网站的速度造成一些小的影响…...

PANGO的IOB的电平能力那些事
LVCMOS33 如果要使用33电平,VCCIO则必须供电3V3. 在此制式下,VILMAX为0.8V,VIHMIN为2.0V,即,电平处于0.8V到2.0V之间时,处于浮游态。 VOLMAX是0.4V,VOHMIN是VCCIO-0.4V,折算下来&am…...

scrpy学习-02
新浪微博[Scrapy 教程] 3. 利用 scrapy 爬取网站中的详细信息 - YouTubedef parse(self,response):soup BeautifulSoup(response.body,html.parser)tags soup.find_all(a,hrefre.compile(r"sina.*\d{4}-\d{2}-\d{2}.*shtmls"))#匹配日期for tag in tags:url tag.get(…...

MySQL运维篇之Mycat分片规则
3.5.3、Mycat分片规则 3.5.3.1、范围分片 根据指定的字段及其配置的范围与数据节点的对应情况,来决定该数据属于哪一个分片。 示例: 可以通过修改autopartition-long.txt自定义分片范围。 注意: 范围分片针对于数字类型的字段,…...

vue router elementui template CDN模式实现多个页面跳转
文章目录前言一、elementui Tabs标签页和NavMenu 导航菜单是什么?二、使用方式1.代码如下2.页面效果总结前言 写上一篇bloghttps://blog.csdn.net/jianyuwuyi/article/details/128959803的时候因为整个前端都写在一个index.html页面里,为了写更少的代码…...
ElasticSearch - ElasticSearch基本概念及集群内部原理
文章目录1. ElasticSearch的应用场景01. Elasticsearch 是什么?02. 为何使用 Elasticsearch?03. Elasticsearch 的用途是什么?04. Elasticsearch 的工作原理是什么?05. Elasticsearch 索引是什么?06. Logstash 的用途是…...

【反射中,Class.forName和ClassLoader区别】
在Java中,可以使用反射机制来获取类的信息并动态地创建对象。其中,Class是Java反射机制中的重要类,表示一个类的信息。 Class.forName()和ClassLoader都可以用于获取类的Class对象,但它们之间存在一些差别: 1、是否会…...

2023了为什么还有人在问:女生适合做跨境电商吗?
女生适合做跨境电商吗?这是东哥最近咨询里面问最多的,今天东哥就给大家解答一下你们内心的疑惑,虽然代表的是东哥我自己的观点,但我觉得还是很值得深思的。 女生适合做跨境电商吗? 性别并不是决定一个人是否适合从事跨…...
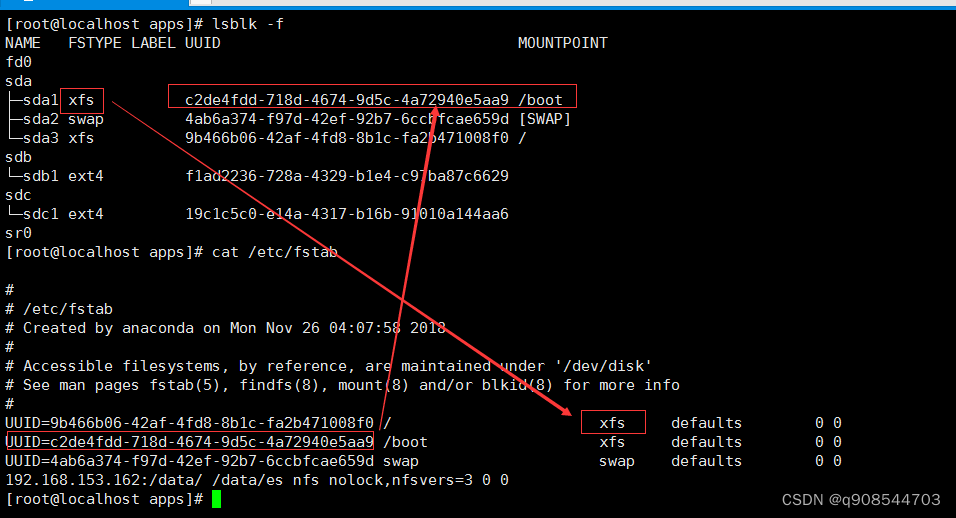
磁盘分区和挂载
磁盘分区和挂载一、linux分区1.原理介绍2.分区和文件关系示意图:3.硬盘说明二、linux分区1.查看所有设备挂载情况三、挂载案例1.使用lsblk命令查看2. 虚拟机硬盘分区3.虚拟机硬盘分区格式化4.mount挂载 重启挂载失效4.1挂载名词解释4.2注意事项4.3挂载4.4挂载非空目…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么? 近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的…...

机器学习的数学基础:线性模型
线性模型 线性模型的基本形式为: f ( x ) ω T x b f\left(\boldsymbol{x}\right)\boldsymbol{\omega}^\text{T}\boldsymbol{x}b f(x)ωTxb 回归问题 利用最小二乘法,得到 ω \boldsymbol{\omega} ω和 b b b的参数估计$ \boldsymbol{\hat{\omega}}…...
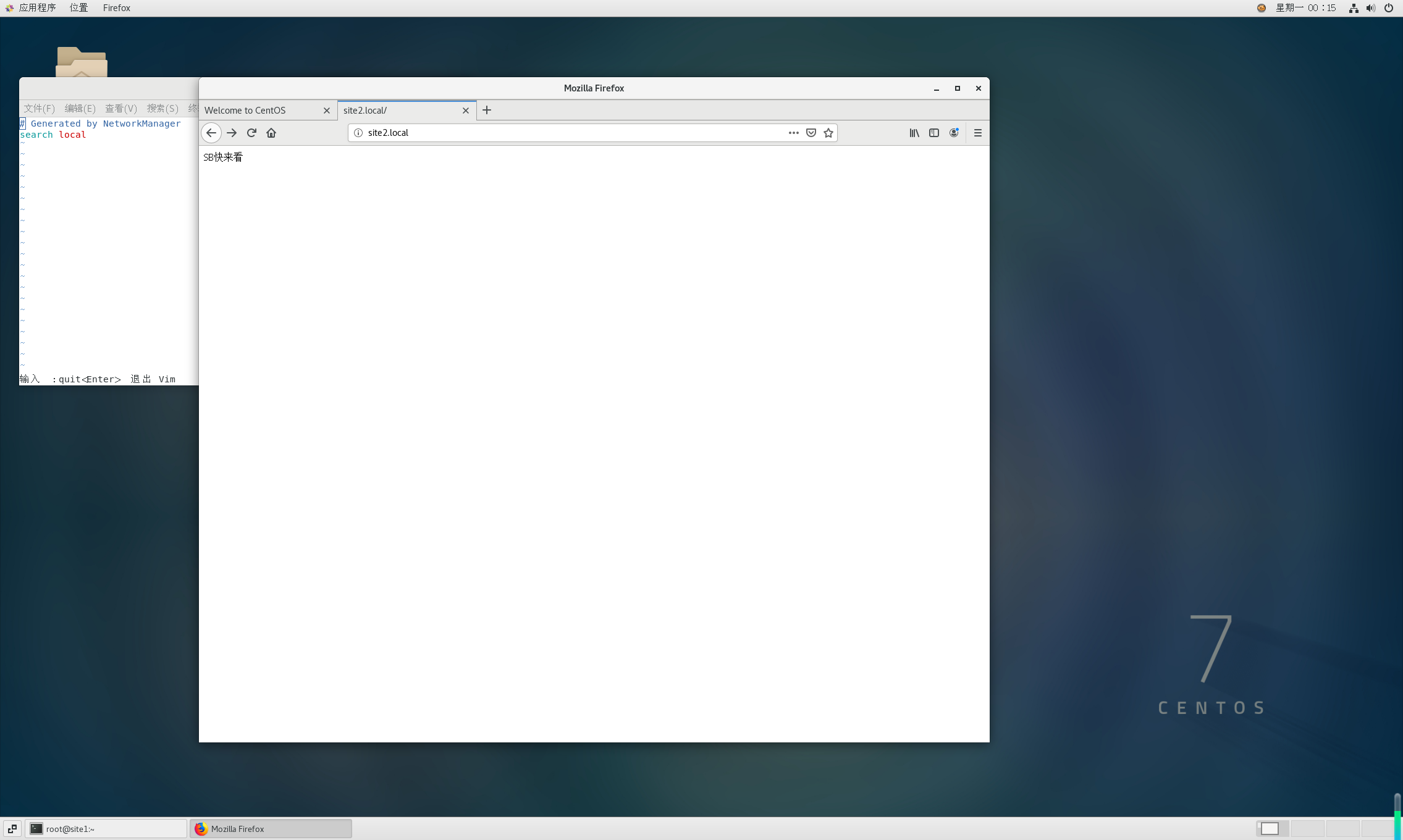
Centos 7 服务器部署多网站
一、准备工作 安装 Apache bash sudo yum install httpd -y sudo systemctl start httpd sudo systemctl enable httpd创建网站目录 假设部署 2 个网站,目录结构如下: bash sudo mkdir -p /var/www/site1/html sudo mkdir -p /var/www/site2/html添加测试…...
)
Vue3学习(接口,泛型,自定义类型,v-for,props)
一,前言 继续学习 二,TS接口泛型自定义类型 1.接口 TypeScript 接口(Interface)是一种定义对象形状的强大工具,它可以描述对象必须包含的属性、方法和它们的类型。接口不会被编译成 JavaScript 代码,仅…...