MNN Session::resize 之流水线编码(五)

系列文章目录
MNN createFromBuffer(一)
MNN createRuntime(二)
MNN createSession 之 Schedule(三)
MNN createSession 之创建流水线后端(四)
MNN Session::resize 之流水线编码(五)
MNN Session 创建执行器(六)
文章目录
- 系列文章目录
- 1、createSession
- 1.1 createMultiPathSession
- 1.1.1 Session::resize
- 1.1.1.1 Pipeline::encode
- 1.1.1.1.1 GeometryComputerUtils::shapeComputeAndGeometryTransform
- 1.1.1.1.1.1 SizeComputer::computeOutputSize
- 1.1.1.1.1.1.1 SizeComputerSuite::search
- 1.1.1.1.1.1.2 ConvolutionSizeComputer::onComputeSize
- 1.1.1.1.1.2 GeometryComputer::search
- 1.1.1.1.1.2.1 GeometryComputerManager::search
- 1.1.1.1.1.3 GeometryConv2D::onRecompute
- 1.1.1.2 Command 命令
- 1.1.1.3 CommandBuffer
1、createSession

依据 ScheduleConfig 和 RuntimeInfo 创建会话。
// source/core/Interpreter.cpp
Session* Interpreter::createSession(const ScheduleConfig& config, const RuntimeInfo& runtime) {return createMultiPathSession({config}, runtime);
}
1.1 createMultiPathSession
// source/core/Interpreter.cpp
Session* Interpreter::createMultiPathSession(const std::vector<ScheduleConfig>& configs, const RuntimeInfo& runtime) {// ...auto result = newSession.get();auto validForResize = info.validForResize;if (validForResize && mNet->modes.inputMode == Session_Input_Inside && mNet->modes.resizeMode == Session_Resize_Direct) {result->resize();}if ((!mNet->cacheFile.empty()) && (!valid) && mNet->modes.backendMode == Session_Backend_Fix) {// Try to save extra cacheauto buffer = result->getCache();if (buffer.first != nullptr && buffer.second > 0) {MNN_PRINT("Write cache to %s, size = %zu\n", mNet->cacheFile.c_str(), buffer.second);writeCacheFile(mNet, buffer);mNet->lastCacheSize = buffer.second;// Write CachecacheMode = cacheMode | 2;}}// Reset cacheresult->loadCache(nullptr, 0);mNet->sessions.emplace_back(std::move(newSession));#ifdef MNN_INTERNAL_ENABLEDint precision = BackendConfig::Precision_Normal;if (nullptr != configs[0].backendConfig) {precision = configs[0].backendConfig->precision;}int mode = configs[0].mode;mNet->sessionInfo.insert(std::make_pair(result, std::make_tuple(precision, mode)));if (shouldLog(FREQ_HIGH)) {std::map<std::string, std::string> metrics = mNet->basicLogginData;metrics.emplace("UUID", mNet->uuid);metrics.emplace("Time", std::to_string((float)_timer.durationInUs() / 1024.0f));metrics.emplace("Backend", std::to_string(configs[0].type));metrics.emplace("Precision", std::to_string(precision));metrics.emplace("Mode", std::to_string(mode));metrics.emplace("Cache", std::to_string(cacheMode));metrics.emplace("CacheSize", std::to_string((float)(mNet->lastCacheSize / 1024.0f)));metrics.emplace("ModelSize", std::to_string ((float)mNet->buffer.size() / 1024.0f / 1024.0f));metrics.emplace("Usage", std::to_string((int) mNet->net->usage()));metrics.emplace("API", "Interpreter::createMultiPathSession");logAsync(metrics);}
#endif // MNN_INTERNAL_ENABLEDreturn result;
}
1.1.1 Session::resize
// source/core/Session.cpp
ErrorCode Session::resize() {
#ifdef LOG_VERBOSEfor (auto& iter : mInputs) {auto& inputTensor = iter.second;MNN_PRINT("before resize, input name:%s, ptr:%p, hostPtr:%p, shape:", iter.first.c_str(), inputTensor, inputTensor->host<void>());inputTensor->printShape();MNN_PRINT("\n");}
#endifbool permitCodegen = mCodegenMode == Interpreter::Session_Codegen_Enable;bool firstMalloc = false;if (mNeedResize) {bool debug = mCallBackMode == Interpreter::Session_Debug;// mPipelines 类型为 std::vector<std::shared_ptr<Pipeline>>for (auto& iter : mPipelines) {auto error = iter->encode(debug, permitCodegen);if (NO_ERROR != error) {return error;}}mNeedResize = false;mNeedMalloc = true;firstMalloc = true;}if (mNeedMalloc) {// Set needResize = true for easy for judge in runSession when errormNeedResize = true;// Turn Pipeline to Command Buffer and Malloc resource// TODO: Separate Schedule and Mallocbool forbidReplace = permitCodegen;if (mInfo.constReplaceBackend != nullptr) {forbidReplace = true;}for (auto& iter : mPipelines) {auto error = iter->allocMemory(firstMalloc, forbidReplace);if (NO_ERROR != error) {return error;}}if(mMemoryUsageMode == Interpreter::Session_Memory_Collect) {#ifdef LOG_VERBOSEfloat memory = 0.0f;#endiffor (auto& iter : mRuntime.first) {iter.second->onGabageCollect(0);#ifdef LOG_VERBOSEmemory += iter.second->onGetMemoryInMB();#endif}#ifdef LOG_VERBOSEFUNC_PRINT_ALL(memory, f);#endif}mNeedMalloc = false;mNeedResize = false;}#ifdef LOG_VERBOSEMNN_PRINT("session after resize\n");for (auto& iter : mOutputs) {auto& outputTensor = iter.second;MNN_PRINT("output name:%s, ptr:%p,shape:", iter.first.c_str(), outputTensor);outputTensor->printShape();MNN_PRINT("\n");}
#endifreturn NO_ERROR;
}
1.1.1.1 Pipeline::encode
BackendCache、OpCacheInfo
// source/core/Pipeline.cpp
// typedef std::pair<BackendCache, std::vector<OpCacheInfo>> PipelineInfo;
//
// struct BackendCache {
// Backend::Info info;
// BackendConfig config;
// std::pair<std::shared_ptr<Backend>, std::shared_ptr<Backend>> cache;
// bool needComputeShape = true;
// bool needComputeGeometry = true;
// bool reportError = true;
// std::map<Tensor*, TENSORCACHE> inputTensorCopyCache;
// };
//
// /** pipeline info */
// struct OpCacheInfo {
// /** op */
// const Op* op;
// /** input tensors */
// std::vector<Tensor*> inputs;
// /** output tensors */
// std::vector<Tensor*> outputs;
// /** schedule type*/
// Schedule::Type type = Schedule::Type::SEPARATE;
//
// /**Command buffer for cache*/
// CommandBuffer cacheBuffer;
//
// /**Command buffer for execute*/
// CommandBuffer executeBuffer;
//
// std::map<const Op*, std::shared_ptr<Execution>> executionCache;
// };
//
ErrorCode Pipeline::encode(bool supportDebug, bool permitCodegen) {// mInfo.first.cache 类型为 std::pair<std::shared_ptr<Backend>, std::shared_ptr<Backend>>// mBackend 创建的后端如(VulkanBackend)auto& mBackend = mInfo.first.cache.first;// mBackupBackend 创建的后备(默认)后端如(CPUBackend)auto& mBackupBackend = mInfo.first.cache.second;// Static Model just copy info to command buffer// mInfo.first 类型为 BackendCache if (!mInfo.first.needComputeGeometry) {for (int i=0; i<mInfo.second.size(); ++i) {auto& info = mInfo.second[i];SharedPtr<Command> cmd = new Command;cmd->op = info.op;if (cmd->op->type() == OpType_Raster) {// Compability for Origin Static Modelcmd->outputs = info.outputs;if (TensorUtils::getDescribe(info.outputs[0])->regions.empty() && info.inputs.size() > 0 && TensorUtils::getDescribe(info.inputs[0])->regions.size() > 0) {TensorUtils::getDescribe(info.outputs[0])->regions = std::move(TensorUtils::getDescribe(info.inputs[0])->regions);TensorUtils::setRasterInputs(cmd.get());} else {cmd->inputs = info.inputs;}} else {cmd->inputs = info.inputs;cmd->outputs = info.outputs;}info.executeBuffer.command = {cmd};}} else {
#ifndef MNN_BUILD_MINI// mContext 类型为 GeometryComputer::ContextmContext.clear();/** Size Compute and compute Const Begin */auto res = GeometryComputerUtils::shapeComputeAndGeometryTransform(mInfo.second, mContext, mInfo.first.cache.second, mUseGeometry, false, permitCodegen);if (res != NO_ERROR) {return res;}
#endif}// Propagate Scale and insert new commandif (mIsQuantModel && (mBackend->type() == MNN_FORWARD_CPU || mBackend->type() == MNN_FORWARD_CPU_EXTENSION || mBackend->type() == MNN_FORWARD_CUDA || mBackend->type() == MNN_FORWARD_NN || mBackend->type() == MNN_FORWARD_OPENCL)) {// get propagate mapusing PropagateMap = std::map<const MNN::Tensor*, std::set<const MNN::Tensor*>>;PropagateMap forwardMap, backwardMap;auto insertPropagateMap = [](PropagateMap& propagateMap, const Tensor* s, const Tensor* t) {if (propagateMap.find(s) == propagateMap.end()) {propagateMap[s] = std::set<const Tensor*>({t});} else {propagateMap[s].insert(t);}};std::set<OpType> propagateOpTypes = { OpType_Raster, OpType_ReLU, OpType_ReLU6, OpType_Pooling,OpType_Interp, OpType_CropAndResize, OpType_ROIPooling, OpType_Gather,OpType_GatherV2, OpType_GatherV2, OpType_ScatterNd};for (auto& info : mInfo.second) {auto& buffer = info.executeBuffer;for (const auto& cmdP : buffer.command) {auto& cmd = *cmdP;const auto type = cmd.op->type();const auto output = cmd.outputs[0];if (propagateOpTypes.find(type) != propagateOpTypes.end()) {for (auto t : cmd.inputs) {insertPropagateMap(forwardMap, t, output);insertPropagateMap(backwardMap, output, t);}}}}auto getStart = [&forwardMap, &backwardMap](bool forward) {auto& propagateMap = forward ? forwardMap : backwardMap;auto& antiMap = forward ? backwardMap : forwardMap;// delete N->1 Map of Opfor (const auto& iter : antiMap) {if (iter.second.size() > 1) {for (auto t : iter.second) {auto res = propagateMap.find(t);if (res != propagateMap.end()) {propagateMap.erase(res);}}}}std::set<const Tensor*> root, leaf, start;for (const auto& iter : propagateMap) {root.insert(iter.first);for (auto t : iter.second) {leaf.insert(t);}}std::set_difference(root.begin(), root.end(), leaf.begin(), leaf.end(), std::inserter(start, start.begin()));return start;};auto forwardStart = getStart(true);auto backwardStart = getStart(false);// propagate scaleauto propagateScale = [](PropagateMap& propagateMap, std::set<const Tensor*>& start) {std::function<bool(const Tensor*)> scalePropagate = [&propagateMap, &scalePropagate](const Tensor* t) {if (TensorUtils::getDescribe(t)->quantAttr.get() == nullptr) {return false;}if (propagateMap.find(t) == propagateMap.end()) {return false;}bool change = false;for (auto x : propagateMap[t]) {if (TensorUtils::getDescribe(x)->quantAttr != TensorUtils::getDescribe(t)->quantAttr) {TensorUtils::getDescribe(x)->quantAttr = TensorUtils::getDescribe(t)->quantAttr;change = true;}change |= scalePropagate(x);}return change;};bool change = false;for (auto t : start) {change |= scalePropagate(t);}return change;};for (int i = 0; i < 3 && (propagateScale(forwardMap, forwardStart) || propagateScale(backwardMap, backwardStart)); i++);// Insert caststd::map<const Tensor*, Tensor*> cachedCastTensor;for (auto& info : mInfo.second) {auto bufferCommand = std::move(info.executeBuffer.command);bool hasConvert = false;for (auto cmdP : bufferCommand) {auto& cmd = *cmdP;auto& outputs = cmd.outputs;auto& inputs = cmd.inputs;auto opType = cmd.op->type();// Check if need use quant opDataType runType = DataType_DT_FLOAT;bool useQuant = false;if (outputs.size() == 1) {// Quant: output and all input has quantAttr and op supportif (TensorUtils::getDescribe(outputs[0])->quantAttr != nullptr) {useQuant = _supportQuant(cmd.op, inputs, outputs, mBackend->type());}if (useQuant) {for (auto t : inputs) {if (TensorUtils::getDescribe(t)->quantAttr == nullptr) {useQuant = false;break;}}}}if (useQuant) {runType = DataType_DT_INT8;}for (auto o : outputs) {auto quan = TensorUtils::getDescribe(o)->quantAttr;if (nullptr != quan) {TensorUtils::getDescribe(o)->type = runType;}}auto makeCommand = [&cachedCastTensor, &info](CommandBuffer& cmdBuffer, Tensor* input, DataType runType) {if (cachedCastTensor.find(input) != cachedCastTensor.end()) {return cachedCastTensor[input];}std::shared_ptr<Tensor> wrapTensor(new Tensor);TensorUtils::copyShape(input, wrapTensor.get(), true);TensorUtils::setLinearLayout(wrapTensor.get());auto des = TensorUtils::getDescribe(wrapTensor.get());auto originDes = TensorUtils::getDescribe(input);if (originDes->quantAttr != nullptr) {des->quantAttr.reset(new QuantAttr);*des->quantAttr = *originDes->quantAttr;des->type = runType;}cmdBuffer.extras.emplace_back(wrapTensor);SharedPtr<Command> command(new Command);command->inputs = {input};command->outputs = {wrapTensor.get()};info.cacheBuffer.hasWrap = true;flatbuffers::FlatBufferBuilder builder;OpBuilder opB(builder);if (runType == DataType_DT_INT8) {opB.add_type(OpType_FloatToInt8);} else {opB.add_type(OpType_Int8ToFloat);}builder.Finish(opB.Finish());command->buffer.reset(new BufferStorage);command->buffer->storage = builder.ReleaseRaw(command->buffer->allocated_size, command->buffer->offset);command->op = flatbuffers::GetRoot<Op>(command->buffer->buffer());info.executeBuffer.command.emplace_back(std::move(command));return wrapTensor.get();};// judge is it need CastWrapif (OpType_Raster == opType) {for (int v=0; v<cmd.inputs.size(); ++v) {auto input = cmd.inputs[v];bool needCast = CPUBackend::getDataType(input) != runType;if (needCast) {cmd.inputs[v] = makeCommand(info.executeBuffer, input, runType);}}} else {for (int i = 0; i < cmd.inputs.size(); i++) {if (OpCommonUtils::opNeedContent(cmd.op, i) && inputs[i]->getType() != halide_type_of<int>()) {bool needCast = CPUBackend::getDataType(inputs[i]) != runType;if (needCast) {cmd.inputs[i] = makeCommand(info.executeBuffer, inputs[i], runType);}}}}info.executeBuffer.command.emplace_back(cmdP);}}}/** Prepare DebugInfo*/if (supportDebug) {mFlops = 0.0f;int totalIndex = 0;for (auto& info : mInfo.second) {auto& buffer = info.executeBuffer;int index = 0;for (auto& cmdP : buffer.command) {auto& cmd = *cmdP;cmd.info.reset(new UnitInfo);static_cast<UnitInfo*>(cmd.info.get())->setUp(cmd, index++, info.op, totalIndex++);mFlops += cmd.info->flops();}}}
#ifndef MNN_BUILD_MINIelse {for (auto& info : mInfo.second) {auto& buffer = info.executeBuffer;for (auto& cmdP : buffer.command) {mFlops += SizeComputer::computeFlops(cmdP->op, cmdP->inputs, cmdP->outputs);}}}
#endifreturn NO_ERROR;
}
1.1.1.1.1 GeometryComputerUtils::shapeComputeAndGeometryTransform
OpCacheInfo
// source/geometry/GeometryComputerUtils.cpp
// /** pipeline info */
// struct OpCacheInfo {
// /** op */
// const Op* op;
// /** input tensors */
// std::vector<Tensor*> inputs;
// /** output tensors */
// std::vector<Tensor*> outputs;
// /** schedule type*/
// Schedule::Type type = Schedule::Type::SEPARATE;
//
// /**Command buffer for cache*/
// CommandBuffer cacheBuffer;
//
// /**Command buffer for execute*/
// CommandBuffer executeBuffer;
//
// std::map<const Op*, std::shared_ptr<Execution>> executionCache;
// };
//
ErrorCode GeometryComputerUtils::shapeComputeAndGeometryTransform(std::vector<Schedule::OpCacheInfo>& infos,GeometryComputer::Context& geoContext,std::shared_ptr<Backend> backupBackend,Runtime::CompilerType compileType, bool skipShapeCompute,bool permitCodegen) {/** Size Compute and compute Const Begin */GeometryComputer::Context ctx(backupBackend);// Size Compute and compute Const// infos 为算子缓存,大小为 171for (int i=0; i<infos.size(); ++i) {// info 类型为 OpCacheInfoauto& info = infos[i];auto& cmdBufferVir = info.executeBuffer;auto& tempBuffer = info.cacheBuffer;// TODO: OptimizecmdBufferVir.command.clear();cmdBufferVir.extras.clear();for (auto t : info.outputs) {if (!TensorUtils::getDescribe(t)->isMutable) {continue;}auto usage = TensorUtils::getDescribe(t)->usage;auto type = TensorUtils::getDescribe(t)->memoryType;MNN_ASSERT(type != Tensor::InsideDescribe::MEMORY_OUTSIDE);MNN_ASSERT(type != Tensor::InsideDescribe::MEMORY_HOST);if (TensorUtils::getDescribeOrigin(t)->mContent->count() > 1) {TensorUtils::getDescribeOrigin(t)->mContent = new Tensor::InsideDescribe::NativeInsideDescribe;t->buffer().dim = TensorUtils::getDescribe(t)->dims;TensorUtils::getDescribe(t)->usage = usage;} else {// 不是不变的和可训练的if (info.type != Schedule::CONSTANT && usage != Tensor::InsideDescribe::TRAINABLE) {TensorUtils::getDescribeOrigin(t)->mContent->setBackend(nullptr);// TODO: If output is static and length larger than new size, don't clear memTensorUtils::getDescribeOrigin(t)->mContent->mem.reset(nullptr);}}}if (!skipShapeCompute) {auto res = SizeComputer::computeOutputSize(info.op, info.inputs, info.outputs);if (!res) {if (info.op->name() != nullptr) {MNN_ERROR("Compute Shape Error for %s\n", info.op->name()->c_str());} else {MNN_ERROR("Compute Shape Error for %d\n", info.op->type());}return COMPUTE_SIZE_ERROR;}// FIXME: Find better way to may compability for old model/**For Convolution of 2D / 3D Tensor(Dense / 1D Convolution)Because of old code, we will acces dim[2] / dim[3] to get width and heightSet the lenght to 1 for compability*/for (auto t : info.outputs) {TensorUtils::adjustTensorForCompability(t);}}if (info.type == Schedule::CONSTANT) {if (_hasZeroShapeOutput(info)) {continue;}ctx.clear();auto geo = GeometryComputer::search(info.op->type(), Runtime::Compiler_Loop);{auto res = geo->onRecompute(info.op, info.inputs, info.outputs, geoContext, tempBuffer);if (!res) {tempBuffer.command.clear();tempBuffer.extras.clear();res = geo->onCompute(info.op, info.inputs, info.outputs, geoContext, tempBuffer);}if (!res) {MNN_ERROR("Const Folder Error in geometry for %s\n", info.op->name()->c_str());return NOT_SUPPORT;}}GeometryComputerUtils::makeRaster(tempBuffer, cmdBufferVir, ctx);for (auto t : info.outputs) {ctx.getRasterCacheCreateRecursive(t, cmdBufferVir);}for (auto& cp : cmdBufferVir.command) {auto& c = *cp;if (nullptr == c.execution) {c.execution.reset(backupBackend->onCreate(c.inputs, c.outputs, c.op));}auto exe = c.execution;if (nullptr == exe.get()) {MNN_ERROR("Const Folder Error for %s\n", info.op->name()->c_str());return NO_EXECUTION;}for (auto t : c.outputs) {auto des = TensorUtils::getDescribe(t);TensorUtils::setLinearLayout(t);auto res = backupBackend->onAcquireBuffer(t, Backend::STATIC);if (!res) {return OUT_OF_MEMORY;}des->setBackend(backupBackend.get());}backupBackend->onResizeBegin();auto code = exe->onResize(c.inputs, c.outputs);if (NO_ERROR != code) {return NOT_SUPPORT;}code = backupBackend->onResizeEnd();if (NO_ERROR != code) {return NOT_SUPPORT;}code = exe->onExecute(c.inputs, c.outputs);if (NO_ERROR != code) {return NOT_SUPPORT;}}// Clear const commandctx.pushCache(cmdBufferVir);cmdBufferVir.command.clear();cmdBufferVir.extras.clear();}}/** Size Compute and compute Const End *//** Geometry Transform */for (int i=0; i<infos.size(); ++i) {auto& info = infos[i];auto& cmdBufferReal = info.executeBuffer;auto& tempBuffer = info.cacheBuffer;// TODO: Optimizeif (info.type == Schedule::CONSTANT) {continue;}if (_hasZeroShapeOutput(info)) {continue;}auto geo = GeometryComputer::search(info.op->type(), compileType);{bool res = false;if (!tempBuffer.hasWrap) {res = geo->onRecompute(info.op, info.inputs, info.outputs, geoContext, tempBuffer);}if (!res) {tempBuffer.command.clear();tempBuffer.extras.clear();res = geo->onCompute(info.op, info.inputs, info.outputs, geoContext, tempBuffer);}if (!res) {return NOT_SUPPORT;}tempBuffer.hasWrap = false;GeometryComputerUtils::makeRaster(tempBuffer, cmdBufferReal, geoContext);for (auto t : info.outputs) {auto des = TensorUtils::getDescribe(t);if (des->usage == Tensor::InsideDescribe::OUTPUT || des->usage == Tensor::InsideDescribe::TRAINABLE) {// For output and trainable value, must directly compute the tensorgeoContext.getRasterCacheCreateRecursive(t, cmdBufferReal);}}}}#ifdef MNN_BUILD_CODEGENif(permitCodegen) {#ifdef LOG_VERPOSEMNN_PRINT("infos : [\n");for (auto info : infos) {auto& cmds = info.executeBuffer.command;for (auto cmd : cmds) {MNN_PRINT("\t%s", EnumNameOpType(cmd->op->type()));if(cmd->op->type() == OpType_BinaryOp) {MNN_PRINT(" %d ", cmd->op->main_as_BinaryOp()->opType());}if(cmd->op->type() == OpType_UnaryOp) {MNN_PRINT(" %d ", cmd->op->main_as_UnaryOp()->opType());}MNN_PRINT("\n");}}MNN_PRINT("]\n");MNN_PRINT("==================== opFuse ====================\n");#endifopFuse(infos, geoContext.forwardType(), geoContext.precisionType());#ifdef LOG_VERPOSEMNN_PRINT("infos : [\n");for (auto info : infos) {auto& cmds = info.executeBuffer.command;for (auto cmd : cmds) {MNN_PRINT("\t%s\n", EnumNameOpType(cmd->op->type()));}}MNN_PRINT("]\n");#endif}
#endifreturn NO_ERROR;
}
1.1.1.1.1.1 SizeComputer::computeOutputSize
// source/shape/SizeComputer.cpp
bool SizeComputer::computeOutputSize(const MNN::Op* op, const std::vector<Tensor*>& inputs,const std::vector<Tensor*>& outputs) {auto computeFactory = SizeComputerSuite::get();// When op is nullptr, it means a copy opif (nullptr != op) {// For Loop Opif (op->type() == OpType_While && op->main_type() == OpParameter_LoopParam) {auto loop = op->main_as_LoopParam();if (loop->extraTensorInfos() == nullptr) {return false;}MNN_ASSERT(loop->extraTensorInfos()->size() == outputs.size());for (int i=0; i<outputs.size(); ++i) {auto des = loop->extraTensorInfos()->GetAs<TensorDescribe>(i);MNN_ASSERT(des->blob() != nullptr);auto blob = des->blob();TensorUtils::getDescribe(outputs[i])->dimensionFormat = blob->dataFormat();outputs[i]->setType(blob->dataType());if (blob->dims() != nullptr) {auto dims = blob->dims()->data();outputs[i]->buffer().dimensions = blob->dims()->size();for (int j=0; j<blob->dims()->size(); ++j) {outputs[i]->setLength(j, dims[j]);}} else {outputs[i]->buffer().dimensions = 0;}}return true;}// Don't support compute shape for control flow opif (op->type() == OpType_While || op->type() == OpType_If) {return false;}// Check -1 inputfor (auto& t : inputs) {for (int i=0; i < t->dimensions(); ++i) {if (t->length(i) < 0) {return false;}}}auto computer = computeFactory->search(op->type());if (nullptr != computer) {bool ret = computer->onComputeSize(op, inputs, outputs);
#ifdef MNN_DEBUG_TENSOR_SIZE_printShape(op, inputs, outputs);
#endifreturn ret;}}// Default Set to the sameif (inputs.size() >= 1 && (outputs.size() == 1 || outputs.size() == inputs.size())) {if (inputs[0] == outputs[0]) {return true;}for (int i=0; i<outputs.size(); ++i) {const auto& ib = inputs[i]->buffer();auto& ob = outputs[i]->buffer();memcpy(ob.dim, ib.dim, sizeof(halide_dimension_t) * ib.dimensions);ob.dimensions = ib.dimensions;ob.type = ib.type;TensorUtils::getDescribe(outputs[i])->dimensionFormat = TensorUtils::getDescribe(inputs[i])->dimensionFormat;}
#ifdef MNN_DEBUG_TENSOR_SIZE_printShape(op, inputs, outputs);
#endifreturn true;}// Not SupportMNN_PRINT("Can't compute size for %d, name=%s\n", op->type(), op->name() ? op->name()->c_str() : "");return false;
}
1.1.1.1.1.1.1 SizeComputerSuite::search
// source/shape/SizeComputer.cpp
SizeComputer* SizeComputerSuite::search(OpType name) {auto iter = mRegistry[name];if (iter == nullptr) {return nullptr;}return iter;
}
1.1.1.1.1.1.2 ConvolutionSizeComputer::onComputeSize
// source/shape/ShapeConvolution.cpp
virtual bool onComputeSize(const MNN::Op* op, const std::vector<Tensor*>& inputs,const std::vector<Tensor*>& outputs) const override {MNN_ASSERT(inputs.size() >= 1);MNN_ASSERT(1 == outputs.size());const Convolution2DCommon* layer = loadCommon(op);int kX = layer->kernelX();int kY = layer->kernelY();auto outputCount = layer->outputCount();if (inputs.size() > 1 && outputCount == 0) {// From TF's multi input convolutionoutputCount = inputs[1]->length(0);kX = inputs[1]->length(3);kY = inputs[1]->length(2);}int kernel_width = layer->dilateX() * (kX - 1) + 1;int kernel_height = layer->dilateY() * (kY - 1) + 1;int output_width = 1;int output_height = 1;auto input = inputs[0];if (input->dimensions() <= 1) {// Convolution is not valid for dimension <= 1return false;}auto inputCount = layer->inputCount();bool depthwiseMatch =inputCount == layer->outputCount() &&inputCount == layer->group() &&inputCount == input->channel();int commonChannelMatch =inputCount == inputs[0]->channel() || // real relationship in express(inputCount * layer->group() == input->channel()); // standard definition of group convolutionbool valid = inputCount == 0 || depthwiseMatch || commonChannelMatch;// For Tensorflow Group Convolution, the inputCount is the size of filter's input countif (inputs.size() == 1 && !valid && OpType_Convolution == op->type()) {input->printShape();MNN_ERROR("Error for compute convolution shape, inputCount:%d, outputCount:%d, KH:%d, KW:%d, group:%d\ninputChannel: %d, batch:%d, width:%d, height:%d. ""Input data channel may be mismatch with filter channel count\n",layer->inputCount(), outputCount, kY, kX, layer->group(),input->channel(), input->batch(), input->width(), input->height());return false;}if (layer->padMode() == PadMode_SAME) {// Tensorflow padding mode SAMEoutput_width = ceil((float)input->width() / (float)layer->strideX());output_height = ceil((float)input->height() / (float)layer->strideY());} else if (layer->padMode() == PadMode_VALID) {// Tensorflow padding mode VALIDoutput_width = ceil((float)(input->width() - kernel_width + 1) / (float)layer->strideX());output_height = ceil((float)(input->height() - kernel_height + 1) / (float)layer->strideY());} else {// Pad_Caffe means User setted paddingif (nullptr != layer->pads()) {MNN_ASSERT(layer->pads()->size() >= 4);int input_width = input->width() + layer->pads()->data()[1] + layer->pads()->data()[3];int input_height = input->height() + layer->pads()->data()[0] + layer->pads()->data()[2];output_width = input_width < kernel_width ? 0 : (input_width - kernel_width) / layer->strideX() + 1;output_height = input_height < kernel_height ? 0 : (input_height - kernel_height) / layer->strideY() + 1;} else {int input_width = input->width() + layer->padX() * 2;int input_height = input->height() + layer->padY() * 2;output_width = (input_width - kernel_width) / layer->strideX() + 1;output_height = (input_height - kernel_height) / layer->strideY() + 1;}}auto& outputBuffer = outputs[0]->buffer();outputBuffer.dimensions = input->buffer().dimensions;auto format = TensorUtils::getDescribe(input)->dimensionFormat;outputBuffer.type = input->getType();if (op->main_as_Convolution2D() && op->main_as_Convolution2D()->symmetricQuan() && op->main_as_Convolution2D()->symmetricQuan()->outputDataType() != DataType_DT_INT8) {auto type = op->main_as_Convolution2D()->symmetricQuan()->outputDataType();outputs[0]->setType(type);}outputBuffer.dim[0].extent = input->buffer().dim[0].extent;if (MNN_DATA_FORMAT_NHWC == format) {outputBuffer.dim[3].extent = outputCount;outputBuffer.dim[1].extent = output_height;outputBuffer.dim[2].extent = output_width;} else {outputBuffer.dim[1].extent = outputCount;outputBuffer.dim[2].extent = output_height;outputBuffer.dim[3].extent = output_width;}// MNN_PRINT("outputs: %d, %d, %d, %d\n", outputs[0]->length(0), outputs[0]->length(1), outputs[0]->length(2), outputs[0]->length(3));TensorUtils::getDescribe(outputs[0])->dimensionFormat = TensorUtils::getDescribe(inputs[0])->dimensionFormat;return true;}
1.1.1.1.1.2 GeometryComputer::search
// source/geometry/GeometryComputer.cpp
const GeometryComputer* GeometryComputer::search(int type, Runtime::CompilerType compType) {return GeometryComputerManager::get()->search(type, compType);
}
1.1.1.1.1.2.1 GeometryComputerManager::search
// source/geometry/GeometryComputer.cppGeometryComputer* search(int type, Runtime::CompilerType compType) {if (Runtime::Compiler_Origin == compType) {return &mDefault;}if (Runtime::Compiler_Loop == compType) {auto iter = mLoopTable[type].get();if (iter != nullptr) {return iter;}}// Geometryauto iter = mTable[type].get();if (iter != nullptr) {// FUNC_PRINT(type);return iter;}return &mDefault;}
1.1.1.1.1.3 GeometryConv2D::onRecompute
virtual bool onRecompute(const Op* op, const std::vector<Tensor*>& inputs, const std::vector<Tensor*>& outputs,Context& context, CommandBuffer& res) const override {return false;}
1.1.1.2 Command 命令
// source/core/Command.hpp
struct Command : public RefCount {const Op* op;std::vector<Tensor*> workInputs;std::vector<Tensor*> workOutputs;std::vector<Tensor*> inputs;std::vector<Tensor*> outputs;std::shared_ptr<BufferStorage> buffer;std::shared_ptr<Execution> execution;std::shared_ptr<OperatorInfo> info;#ifdef MNN_BUILD_CODEGENbool canVectorize = false;#endif
};
1.1.1.3 CommandBuffer
// source/core/Command.hpp
struct CommandBuffer {std::vector<SharedPtr<Command>> command;std::vector<std::shared_ptr<Tensor>> extras;bool hasWrap = false;
};
☆
相关文章:
MNN Session::resize 之流水线编码(五)
系列文章目录 MNN createFromBuffer(一) MNN createRuntime(二) MNN createSession 之 Schedule(三) MNN createSession 之创建流水线后端(四) MNN Session::resize 之流水线编码&am…...
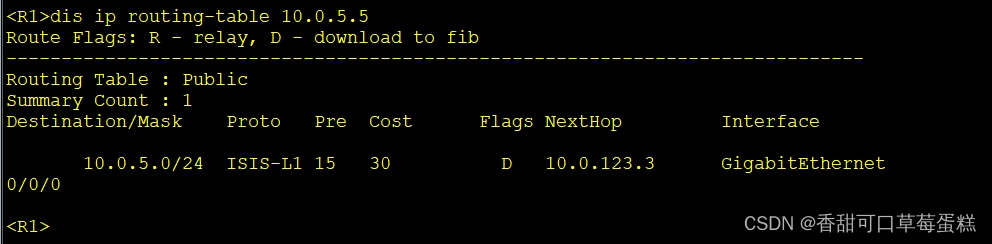
2. IS-IS 基础实验
2.1 IS-IS 配置实验 2.1.1 实验介绍 2.1.1.1 学习目标 1. 实现 IS-IS 协议基本配置 2. 实现 IS-IS 协议 DIS 优先级修改 3. 实现 IS-IS 协议网络类型修改 4. 实现 IS-IS 协议外部路由引入 5. 实现 IS-IS 接口 cost 修改 6. 实现 IS-IS 路由渗透配置 2.1.1.2 实验组网介…...

Rust 并行库 crossbeam 的 Channel 示例
示例1 一个不完整的示例: let (tx, rx) channel::unbounded::<Task>(); let mut handlers vec![];for _ in 0..number {let rx rx.clone();let handle thread::spawn(move || {while let Some(task) rx.recv() {task.call_box();}});handlers.push(han…...

缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级的理解
一:缓存雪崩 我们可以简单的理解为:由于原有缓存失效,新缓存未到期间 (例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了ÿ…...

springcloud gateway
一、 predicate : 就是你定义一些规则,如果满足了这些规则,就去找到对应的路由。 对于strip 二、自定义过略器和全局过滤器 约定大于配置,后缀不变,只改前缀 sentinel持久化 三、sentinel quick-start | Sentinel 信号量虽然简…...

JAVA八股day1
遇到的问题 相比于包装类型(对象类型), 基本数据类型占用的空间往往非常小为什么说是几乎所有对象实例都存在于堆中呢?静态变量和成员变量、成员变量和局部变量的区别为什么浮点数运算的时候会有精度丢失的风险?如何解…...

探索拓展坞的奥秘:提升电脑接口的无限可能
在数字化时代的浪潮中,电脑已成为我们日常生活和工作中不可或缺的一部分。然而,随着外接设备的日益增多,电脑接口的数量和类型往往无法满足我们的需求。这时,拓展坞便应运而生,以其强大的扩展能力和便捷的使用方式&…...
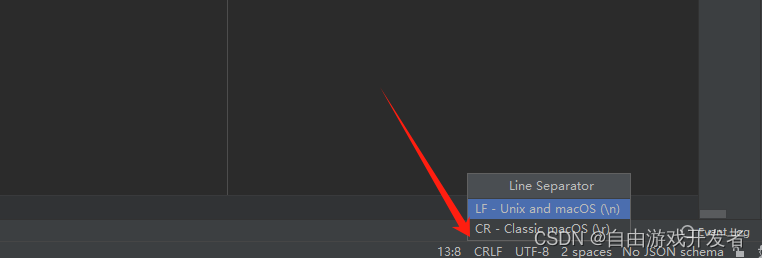
Linux中执行脚本报错(脚本乱码问题)
主要原因是在windows中编译文件格式导致 linux下解决: 方案一: Linux下打开shell文件,用vi/vim命令打开脚本文件,输入“:set fileformatunix”,回车,保存退出。 方案二: yum install -y dos2uni…...

el-table按钮获取当前行元素
el-table按钮获取当前行元素 vue2 <el-table-column label"操作" width"240px"><template slot-scope"scope"><el-button size"mini" click"toItem(scope.row)">用户详情</el-button><el-butto…...
MySQL数据导入的方式介绍
MySQL数据库中的数据导入是一个常见操作,它涉及将数据从外部源转移到MySQL数据库表中。在本教程中,我们将探讨几种常见的数据导入方式,包括它们的特点、使用场景以及简单的示例。 1. 命令行导入 使用MySQL命令行工具mysql是导入数据的…...

构建部署_Docker常用命令
构建部署_Docker常见命令 启动命令镜像命令容器命令 启动命令 启动docker:systemctl start docker 停止docker:systemctl stop docker 重启docker:systemctl restart docker 查看docker状态:systemctl status docker 开机启动&…...

Spring Boot Actuator介绍
大家在yaml中经常见到的这个配置 management: endpoints: web: exposure: #该配置线上需要去掉,会有未授权访问漏洞 include: "*" 他就是Actuator! 一、什么是 Actuator Spring Boot Actuator 模块提供了生产级别…...

数据库中DQL、DML、DDL、DCL的概念与区别
目录 DQL (Data Query Language) DML (Data Manipulation Language) DDL (Data Definition Language) DCL (Data Control Language) 数据库语言可以根据其功能被分为几个不同的类别:DQL(数据查询语言)、DML(数据操纵语言&…...

MacOS---设置Java环境变量
介绍 在MacOS系统配置Java环境变量。 操作步骤 第一步:打开.bash_profile文件 vim ~/.bash_profile第二步:添加或修改配置 如果是第一次配置需要添加配置如果是已经配置过想更换其他版本需要修改配置 在文件末尾添加或修改下面的配置 export JAVA…...
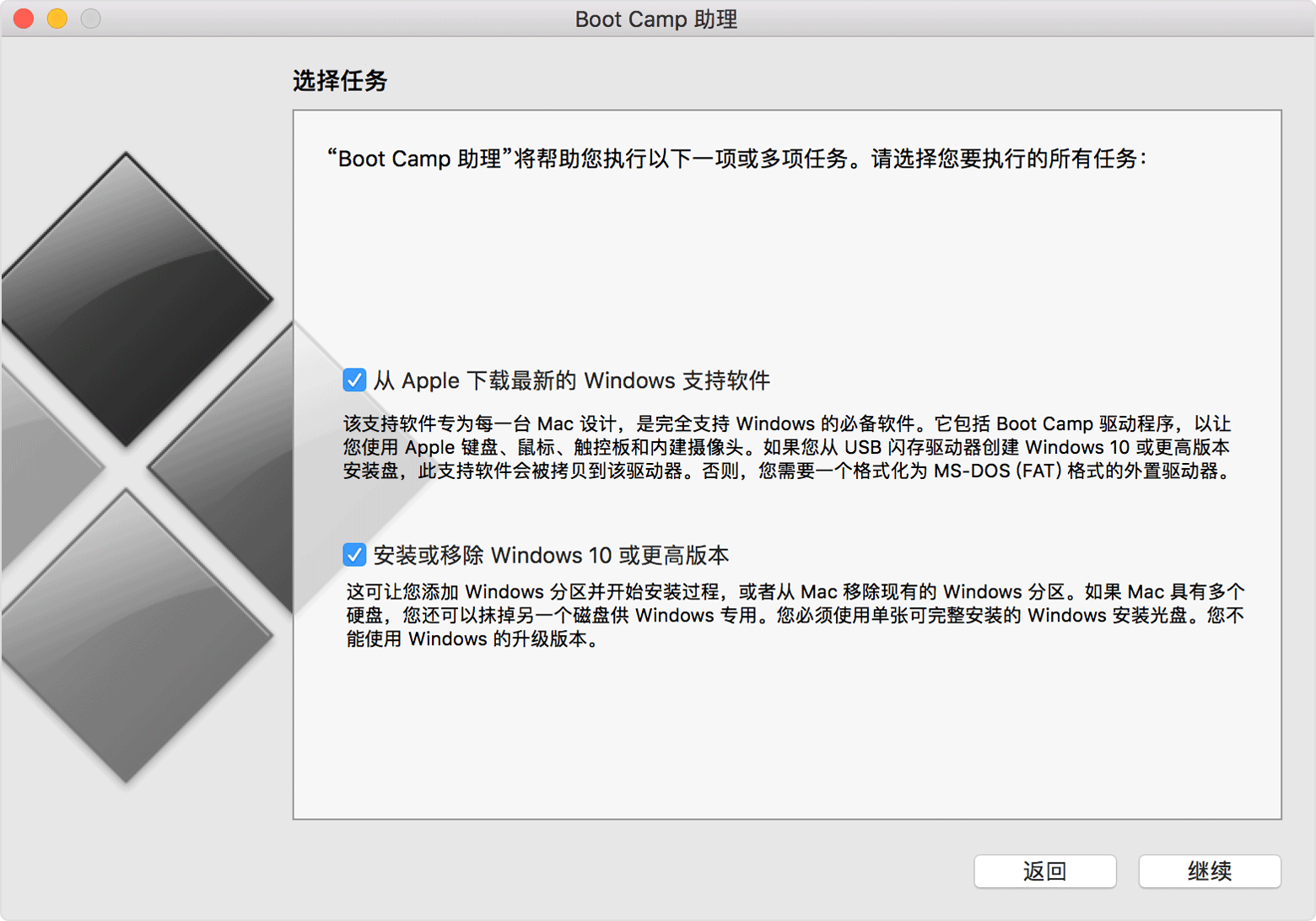
使用 Boot Camp 助理查明您的 Mac 需不需要 Windows 安装介质
使用 Boot Camp 助理查明您的 Mac 需不需要 Windows 安装介质 当前的 Mac 机型无需介质即可安装 Windows,也就是说,您不需要用到外置驱动器。较早的 Mac 机型需要用到 USB 驱动器或光盘驱动器。使用 Boot Camp 助理可查明您需要用到什么。 Boot Camp 助…...
)
KY105 整除问题(用Java实现)
描述 给定n,a求最大的k,使n!可以被a^k整除但不能被a^(k1)整除。 输入描述: 两个整数n(2<n<1000),a(2<a<1000) 输出描述: 一个整数. 示例1 输入: 6 10输出: 1代…...

C++ 接口的实现,及作用通俗理解方式
接口 C中的接口,一般就是指抽象类,是一种用来描述类对外提供的操作、方法或功能的集合——注意,一般只是描述(声明),而不对这些方法或功能进行定义实现,通常在类的继承或多态中作为基类使用&am…...
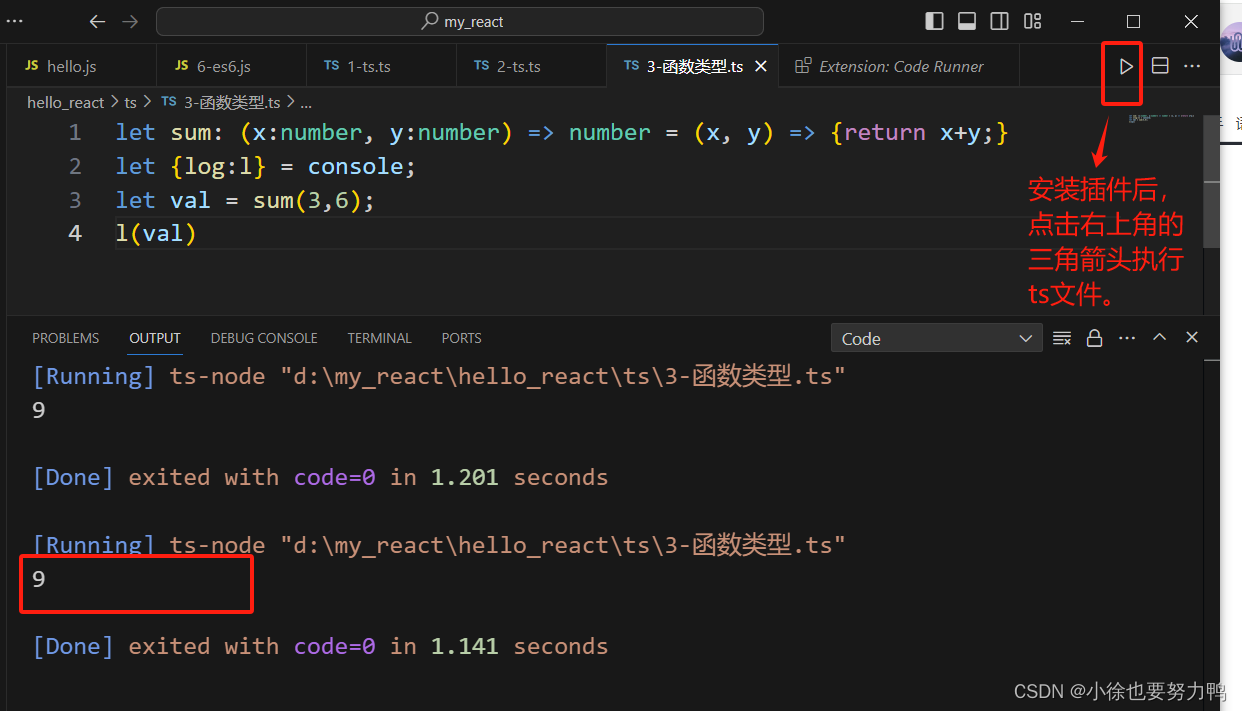
TypeScript:typescript的安装与运行
TypeScript:typescript的安装与运行 1 安装方式 -g全局安装TypeScript: npm install -g typescript2 运行方式 (1)ts编译成js,使用node命令运行js文件 打开vscode,进入ts文件所在目录下并打开终端term…...

【代码随想录Day27】
Day 27 回溯算法03 今日任务 组合总和 40.组合总和II131.分割回文串 代码实现 组合总和,直接套模板可解 public List<List<Integer>> combinationSum(int[] candidates, int target) {backtracking(candidates, target, 0);return result;}void back…...
【一】【单片机】有关LED的实验
点亮一个LED灯 根据LED模块原理图,我们可以知道,通过控制P20、P21...P27这八个位置的高低电平,可以实现D1~D8八个LED灯的亮灭。VCC接的是高电平,如果P20接的是低电平,那么D1就可以亮。如果P20接的是高电平,…...

Andi活码,最简单好用!
上链接: https://app.andi.cn/qr/ 试用过这么多群聊二维码的活码工具。 真正好用的是我推荐的这款Andi活码。 免登录、打开即用。单屏管理,超简单好用。 优威科技有限公司出品。 承诺永久免费长期支持。 稳定可靠好用! 不信我来用一下…...
Vision Transformers在密集预测任务中的创新应用与性能优化
1. Vision Transformers如何革新密集预测任务 第一次接触Vision Transformers(ViT)时,我完全被它的设计哲学震撼到了。传统的CNN在处理图像时,就像用固定大小的网格去观察世界,而ViT则像是一个拥有"全局视野"…...

快速体验Qwen3-ASR-0.6B:上传音频秒出文字,支持52种语言
快速体验Qwen3-ASR-0.6B:上传音频秒出文字,支持52种语言 1. 模型简介 Qwen3-ASR-0.6B是阿里云通义千问团队推出的开源语音识别模型,专为高效准确的语音转文字任务设计。这个0.6B参数的轻量级模型在精度和效率之间取得了出色平衡,…...

怎样快速管理Windows预览版:离线注册工具完整使用手册
怎样快速管理Windows预览版:离线注册工具完整使用手册 【免费下载链接】offlineinsiderenroll 项目地址: https://gitcode.com/gh_mirrors/of/offlineinsiderenroll 想要体验Windows最新功能但又不想绑定微软账户?OfflineInsiderEnroll为你提供了…...
)
告别臃肿OS!手把手教你将Zephyr蓝牙协议栈移植到资源受限MCU(基于Polling轮询架构)
从零构建极简蓝牙协议栈:Zephyr Polling架构在资源受限MCU的实战指南 当智能手环的PCB面积被压缩到硬币大小,当电子价签需要依靠纽扣电池运行三年,传统蓝牙协议栈的"豪华配置"突然成了奢侈品。在深圳华强北的某个研发实验室里&…...

3步构建工业级语音数据集:从混乱录音到AI训练素材的蜕变之路
3步构建工业级语音数据集:从混乱录音到AI训练素材的蜕变之路 你是否还在为语音识别模型效果不佳而烦恼?是否采集了大量语音却不知如何转化为训练数据?本文将带你通过FunASR框架提供的标准化工具链,3步完成工业级语音数据集的构建…...
)
告别改板焦虑!手把手教你用Ansys SIwave 2022R2搞定PCB信号完整性仿真(附S参数导出Pspice全流程)
告别改板焦虑!Ansys SIwave 2022R2信号完整性仿真实战指南 在高速PCB设计领域,信号完整性问题如同悬在硬件工程师头顶的达摩克利斯之剑。当信号速率突破10Gbps,板间距离压缩至毫米级时,传统"设计-打样-测试"的迭代模式已…...

PP-DocLayoutV3快速调用:10行Python代码实现文档解析
PP-DocLayoutV3快速调用:10行Python代码实现文档解析 你是不是经常遇到一堆扫描的PDF或者图片文档,想快速提取里面的文字、表格和图片,却不知道从何下手?手动整理不仅费时费力,还容易出错。今天,我就来分享…...

langchain AI开发大模型翻译助手
我直接给你运行后的真实输出结果,并把为什么会这样输出讲得明明白白! 一、你的代码 最终输出结果 prompt: [SystemMessage(content你是一个翻译专家,擅长将 英文 语言翻译成 中文语言.), HumanMessage(contentI love Large Language Model.)] result: 我…...

立知-lychee-rerank-mm效果展示:文本+图像联合匹配惊艳案例集
立知-lychee-rerank-mm效果展示:文本图像联合匹配惊艳案例集 1. 多模态重排序新体验 想象一下这样的场景:你在电商平台搜索"白色猫咪玩毛线球",系统返回了20个结果,有纯文字描述、有商品图片、还有图文混合的内容。传…...