【NLP笔记】RNN总结
文章目录
- 经典RNN
- 单向RNN
- 双向RNN
- Deep RNN
- RNN特性总结
- 变体RNN
- LSTM
- GRU
参考及转载内容:
- 循环神经网络(RNN)
- 深度学习05-RNN循环神经网络
- 完全理解RNN(循环神经网络)
传统的CNN(Covolutional Neural Network,卷积神经网络)通常是给定输入预测对应的输出,是一对一的关系(输入层->隐藏层->输出层,隐藏层之间无关联,为顺序传播的关系),没有涉及输入信息间的关联关系。而在实际应用中,如自然语言处理、语音处理、时序数据处理等任务都依赖于上下文的输入才能够确定输出,因此CNN就无法很好地解决此类任务所需的关联关系提取。

RNN(Recurrent Neural Network,循环神经网络)就是针对这一类需要考虑上下文信息的数据分析与处理提出来的网络架构,循环神经网络的隐藏层会对之前的信息进行记忆存储,隐藏层之间的信息可以进行交互,当前隐藏层的输入可以包含上一个隐藏层的输出、上一个隐藏层存储的信息状态、输入层的输出。

经典RNN
单向RNN

假设 x t x_{t} xt表示第 t t t步的输入, s t s_{t} st表示第 t t t步的隐藏层的状态,该状态是根据上一个隐藏层状态 s t − 1 s_{t-1} st−1计算得出,假设 U U U表示输入层的链接矩阵, W W W表示上一个隐藏时刻到下一个隐藏时刻的权重矩阵, f ( x ) f(x) f(x)为非线性层的激活函数,一般为 t a n h tanh tanh或 R e L U ReLU ReLU,则时刻 t t t的隐藏层计算为: s t = f ( U x t + W s t − 1 ) s_{t}=f(Ux_{t}+Ws_{t-1}) st=f(Uxt+Wst−1)则时刻t的输出计算为: o t = g ( V ∗ s t ) o_{t}=g(V*s_{t}) ot=g(V∗st)其中 V V V表示输出层的权重矩阵, g ( x ) g(x) g(x)为激活函数。可以看到当前时刻的输出与多个历史时刻的数据相关,因为每个当前时刻的输出都受到上个时刻的影响。但是单向RNN仅考虑了历史信息,很多时候需要共同结合上下文信息才能够得到更好的预测结果。
# pytorch中的单向RNN
import torch
import torch.nn as nn# 定义输入数据
input_size = 10 # 输入特征的维度
sequence_length = 5 # 时间步个数
batch_size = 3 # 批次大小# 创建随机输入数据
#输入数据的维度为(sequence_length, batch_size, input_size),表示有sequence_length个时间步,
#每个时间步有batch_size个样本,每个样本的特征维度为input_size。
input_data = torch.randn(sequence_length, batch_size, input_size)
print("输入数据",input_data)
# 定义RNN模型
# 定义RNN模型时,我们指定了输入特征的维度input_size、隐藏层的维度hidden_size、隐藏层的层数num_layers等参数。
# batch_first=False表示输入数据的维度中批次大小是否在第一个维度,我们在第二个维度上。
rnn = nn.RNN(input_size, hidden_size=20, num_layers=1, batch_first=False)
"""
在前向传播过程中,我们将输入数据传递给RNN模型,并得到输出张量output和最后一个时间步的隐藏状态hidden。
输出张量的大小为(sequence_length, batch_size, hidden_size),表示每个时间步的隐藏层输出。
最后一个时间步的隐藏状态的大小为(num_layers, batch_size, hidden_size)。
"""
# 前向传播,第二个参数h0未传递,默认为0
output, hidden = rnn(input_data)
print("最后一个隐藏层",hidden.shape)
print("输出所有隐藏层",output.shape)# 打印每个隐藏层的权重和偏置项
# weight_ih表示输入到隐藏层的权重,weight_hh表示隐藏层到隐藏层的权重,注意这里使出是转置的结果。
# bias_ih表示输入到隐藏层的偏置,bias_hh表示隐藏层到隐藏层的偏置。
for name, param in rnn.named_parameters():if 'weight' in name or 'bias' in name:print(name, param.data)
单向RNN的参数是共享的,RNN参数共享指的是:在每一个时间步上,所对应的参数是共享的。参数共享的目的有两个:一、用这些参数来捕获序列上的特征;二、共享参数减少模型的复杂度。
对于RNN的参数共享,我们可以理解为对于一个句子或者文本,参数U可以看成是语法结构、参数W是一般规律,而下一个单词的预测必须是上一个单词和一般规律W与语法结构U共同作用的结果。我们知道,语法结构和一般规律在语言当中是共享的。所以,参数自然就是共享的!
我们需要记住的是,深度学习是怎么减少参数的,很大原因就是参数共享,而CNN是在空间上共享参数,RNN是在时间序列上共享参数。
双向RNN

这种可以结合上下文信息的RNN结构即双向RNN,双向RNN的隐藏层需要保存两个状态值,一个是正向计算,一个是反向计算,基于上述单向计算的过程,双向计算可表示如下: o t = g ( V ∗ s t + V ′ ∗ s t ′ ) o_{t}=g(V*s_{t}+V'*s'_{t}) ot=g(V∗st+V′∗st′)
正向计算: s t = f ( U x t + W s t − 1 ) s_{t}=f(Ux_{t}+Ws_{t-1}) st=f(Uxt+Wst−1)
反向计算: s t ′ = f ( U ′ x t + W s t + 1 ) s'_{t}=f(U'x_{t}+Ws_{t+1}) st′=f(U′xt+Wst+1)
在正向计算和反向计算过程中,权重不共享。其中网络参数的更新是通过前向传播和反向传播过程完成的,其中反向传播的过程采用的是BPTT(BackPropagation Through Time)算法进行的,其实基本原理也是基于常规的BP算法,只是BPTT需要考虑不同时刻的梯度计算结果之和,具体计算可参考:BPTT算法推导 。
# pytorch定义双向RNN
import torch
import torch.nn as nn# 定义输入数据
input_size = 10 # 输入特征的维度
sequence_length = 5 # 时间步个数
batch_size = 3 # 批次大小# 创建随机输入数据
input_data = torch.randn(sequence_length, batch_size, input_size)# 定义双向RNN模型
rnn = nn.RNN(input_size, hidden_size=20, num_layers=1, batch_first=False, bidirectional=True)# 前向传播
output, hidden = rnn(input_data)# 输出结果
print("输出张量大小:", output.size())
print("最后一个时间步的隐藏状态大小:", hidden.size())
Deep RNN

基本循环神经网络和双向循环神经网络只有单个隐藏层,有时不能很好的学习数据内部关系,可以通过叠加多个隐藏层,形成深度循环神经网络结构。单层的隐藏层RNN的参数是共享的,深层的RNN会有 L L L层的参数,其每一层都可以是一个双向RNN结构。
# pytorch实现双向RNN
import torch
import torch.nn as nn# 定义输入数据和参数
input_size = 5
hidden_size = 10
num_layers = 2
batch_size = 3
sequence_length = 4# 创建输入张量
input_tensor = torch.randn(sequence_length, batch_size, input_size)# 创建多层RNN模型
rnn = nn.RNN(input_size, hidden_size, num_layers)# 前向传播
output, hidden = rnn(input_tensor)# 打印输出张量和隐藏状态的大小
print("Output shape:", output.shape)
print("Hidden state shape:", hidden.shape)
RNN特性总结
-
单向单隐藏层传播参数共享;
-
参数更新采用BPTT的算法实现;

-
存在梯度消失和梯度爆炸的问题;
- 梯度消失:传统的RNN不能捕获长距离词之间的关系。从图中可以看到tanh函数在x趋近于无穷大和无穷小时梯度值都为0,当邻近神经元梯度接近0时,因为前面层的梯度是由后面层的梯度连乘得到的,多个梯度相乘会使梯度值以指数级速度下降,最终在反向传播几步后就完全消失,比较远的时刻的梯度值为0。
- 梯度爆炸:RNN的学习依赖于我们的激活函数和网络初始参数,如果Jacobian矩阵中的值太大,会产生梯度爆炸而不是梯度消失问题。梯度消失比梯度爆炸受到了更多的关注有两方面的原因。其一,梯度爆炸容易发现,梯度值会变成NaN,导致程序崩溃。其二,用预定义的阈值裁剪梯度可以简单有效的解决梯度爆炸问题。梯度消失问题就不容易发现并且也不好处理,这也是梯度消失比梯度爆炸受到学术界更多关注的原因。
-
RNN的几种架构:
-
单输入单输出(Single Input Single Output,SISO): 给定一段文本,预测下一个词语;


-
单输入多输出(Single Input Multiple Output,SIMO):如上图有两种实现形式。这种1 to N的结构可以处理的问题有很多,比如图像标注,输入的X是图像的特征,而输出的y序列是一段句子。
-
多输入单输出(Multiple Input Single Output,MISO):输入是一个序列,输出是一个单独的值而不是序列。这种结构通常用来处理序列分类问题。如输入一段文字判别它所属的类别,输入一个句子判断其情感倾向,输入一段文档并判断它的类别等等。
-
多输入多输出(Multiple Input Multiple Output,MIMO):一种是NtoN,输入和输出序列是等长的。这种可以作为简单的Char RNN可以用来生成文章,诗歌,甚至是代码,非常有意思。另一种是这种结构又叫Encoder-Decoder模型,也称之为Seq2Seq模型。在现实问题中,我们遇到的大部分序列都是不等长的。如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。而Encoder-Decoder结构先将输入数据编码成一个上下文向量c,之后在通过这个上下文向量输出预测序列。
-
变体RNN
参考链接:【译】理解LSTM(通俗易懂版)
LSTM
RNN的结构的隐藏层只有一个状态,对邻近的输入会非常敏感,如果我们再增加一个门(gate)来控制特征的流通和损失,即c,让它来保存长期的状态,这就是长短时记忆网络(Long Short Term Memory,LSTM)。

新增加的状态c,称为单元状态。我们把LSTM按照时间维度展开:
其中图像上的标识 σ \sigma σ标识使用sigmod激活到[0-1],tanh激活到[-1,1],⨀ 是一个数学符号,表示逐元素乘积(element-wise product)或哈达玛积(Hadamard product)。当两个相同维度的矩阵、向量或张量进行逐元素相乘时,可以使用 ⨀ 符号来表示。

LSTM的输入有三个:当前时刻网络的输出值 x t x_{t} xt、上一时刻LSTM的输出值 h t − 1 h_{t-1} ht−1 、以及上一时刻的记忆单元向量 c t − 1 c_{t−1} ct−1;
LSTM的输出有两个:当前时刻LSTM输出值 h t h_{t} ht、当前时刻的隐藏状态向量 h t h_{t} ht、和当前时刻的记忆单元状态向量 c t c_{t} ct。
注意:记忆单元c在LSTM 层内部结束工作,不向其他层输出。LSTM的输出仅有隐藏状态向量h。
LSTM 的关键是单元状态,即贯穿图表顶部的水平线,有点像传送带。这一部分一般叫做单元状态(cell state)它自始至终存在于LSTM的整个链式系统中。

f t f_{t} ft叫做遗忘门,表示 C t − 1 C_{t−1} Ct−1 的哪些特征被用于计算 C t C_{t} Ct, f t f_{t} ft是一个向量,向量的每个元素均位于(0~1)范围内。通常我们使用 sigmoid 作为激活函数,sigmoid 的输出是一个介于于(0~1)区间内的值,但是当你观察一个训练好的LSTM时,你会发现门的值绝大多数都非常接近0或者1,其余的值少之又少。

C t C_{t} Ct表示单元状态更新值,由输入数据 x t x_{t} xt和隐节点 h t − 1 h_{t-1} ht−1经由一个神经网络层得到,单元状态更新值的激活函数通常使用tanh。 i t i_{t} it叫做输入门,同 f t f_{t} ft一样也是一个元素介于(0~1)区间内的向量,同样由 x t x_{t} xt和 h t − 1 h_{t-1} ht−1经由sigmoid激活函数计算而成。


最后,为了计算预测值 y t y^{t} yt和生成下个时间片完整的输入,我们需要计算隐节点的输出 h t h_{t} ht

GRU
Gated Recurrent Unit – GRU 是 LSTM 的一个变体。他保留了 LSTM 划重点,遗忘不重要信息的特点,在long-term 传播的时候也不会被丢失。
LSTM 的参数太多,计算需要很长时间。因此,最近业界又提出了 GRU(Gated RecurrentUnit,门控循环单元)。GRU 保留了 LSTM使用门的理念,但是减少了参数,缩短了计算时间。
相对于 LSTM 使用隐藏状态和记忆单元两条线,GRU只使用隐藏状态。异同点如下:

GRU的计算过程如下:
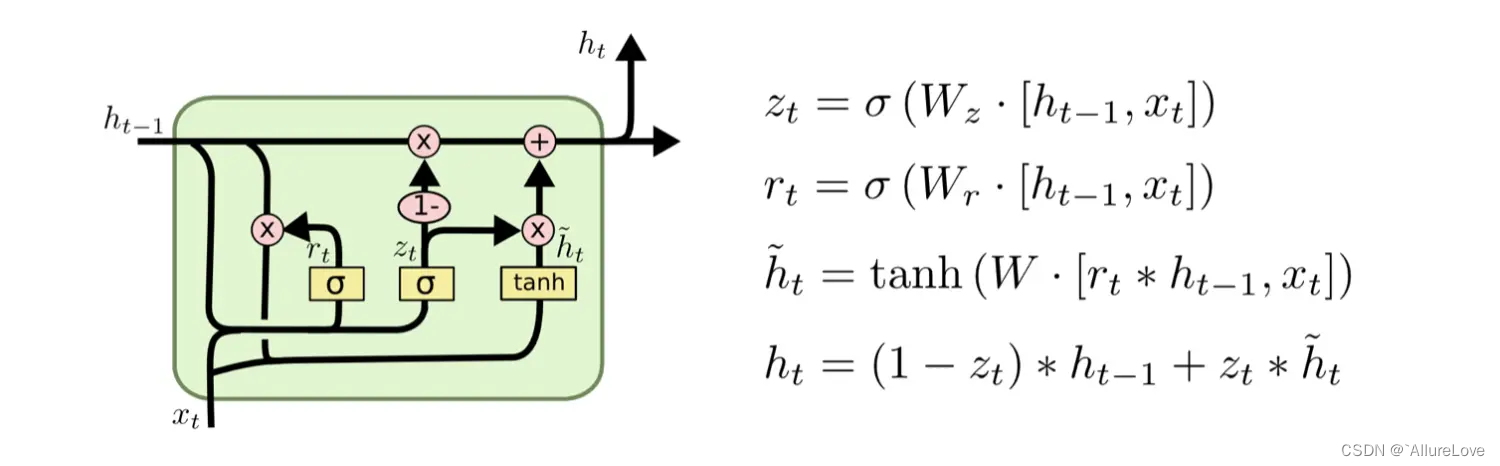
如图所示,GRU 没有记忆单元,只有一个隐藏状态h在时间方向上传播。这里使用r和z共两个门(LSTM 使用 3 个门),r称为 reset 门,z称为 update 门。r(reset门)决定在多大程度上“忽略”过去的隐藏状态,定义了前面记忆保存到当前时间步的量。
相关文章:
【NLP笔记】RNN总结
文章目录 经典RNN单向RNN双向RNNDeep RNNRNN特性总结 变体RNNLSTMGRU 参考及转载内容: 循环神经网络(RNN)深度学习05-RNN循环神经网络完全理解RNN(循环神经网络) 传统的CNN(Covolutional Neural Network&am…...

[c++]内存管理
1. C/C内存分布 我们先来看下面的一段代码和相关问题 int globalVar 1; static int staticGlobalVar 1; void Test() { static int staticVar 1; int localVar 1; int num1[10] { 1, 2, 3, 4 }; char char2[] "abcd"; const char* pChar3 "abcd"; …...

k8s通过编排文件,实现服务的滚动更新
k8s通过编排文件,实现服务的滚动更新 apiVersion: apps/v1 kind: pod metadata:name: ‘servicename’labels:app: ‘servicename’ spec:replicas: 4 ##pod启动数量最少为2,不然滚动更新无意义strategy:type: RollingUpdate ##设置类型为滚动更新以及…...

安卓面试题多线程 96-100
96. 简述notify()和notifyAll()有什么区别 ?notify可能会导致死锁,而notifyAll则不会任何时候只有一个线程可以获得锁,也就是说只有一个线程可以运行synchronized 中的代码 使用notifyall,可以唤醒 所有处于wait状态的线程,使其重新进入锁的争夺队列中,而notify只能唤醒一…...

第二十六章 配置 Web Gateway 的默认参数
文章目录 第二十六章 配置 Web Gateway 的默认参数网络网关实例主机名最大连接数最大缓存大小网络服务器 ID Cookie 第二十六章 配置 Web Gateway 的默认参数 本页介绍如何通过 Web Gateway 管理页面配置 IRIS Web Gateway 的默认参数。其他文章介绍了如何配置服务器和应用程序…...
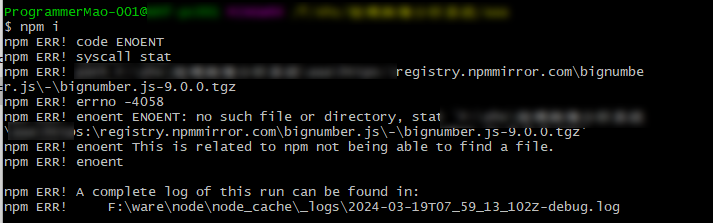
npm i安装依赖报错,但是cnpm i 却安装成功
问题描述:在a项目中npm i 安装依赖时发生以上报错,但是cnpm i 却成功,而且在其他项目中npm i 安装其他项目依赖也能成功.... 解决办法:删除项目中package-lock.json文件后再npm i 即可...
C语言经典算法-9
文章目录 其他经典例题跳转链接46.稀疏矩阵47.多维矩阵转一维矩阵48.上三角、下三角、对称矩阵49.奇数魔方阵50.4N 魔方阵51.2(2N1) 魔方阵 其他经典例题跳转链接 C语言经典算法-1 1.汉若塔 2. 费式数列 3. 巴斯卡三角形 4. 三色棋 5. 老鼠走迷官(一)6.…...

React 19的变化
并发模式(非实验): React 的并发模式终于从实验阶段毕业了。这一改变游戏规则的功能允许 React 应用程序同时准备多个版本的 UI。有着更平滑的过渡和更灵敏的用户体验,因为 React 现在可以处理高优先级更新,同时保持应用程序的交互…...
的区别是什么?)
Kafka整理-Kafka与传统消息队列系统(如RabbitMQ, ActiveMQ)的区别是什么?
Apache Kafka与传统消息队列系统(如RabbitMQ, ActiveMQ)虽然都是处理消息和数据流的中间件,但它们在设计理念、架构、功能和使用场景方面有显著的区别。下面是Kafka与传统消息队列系统的主要区别: 1. 设计目的和使用场景 Kafka: 设计初衷是为处理大量的实时数据流。强调高…...
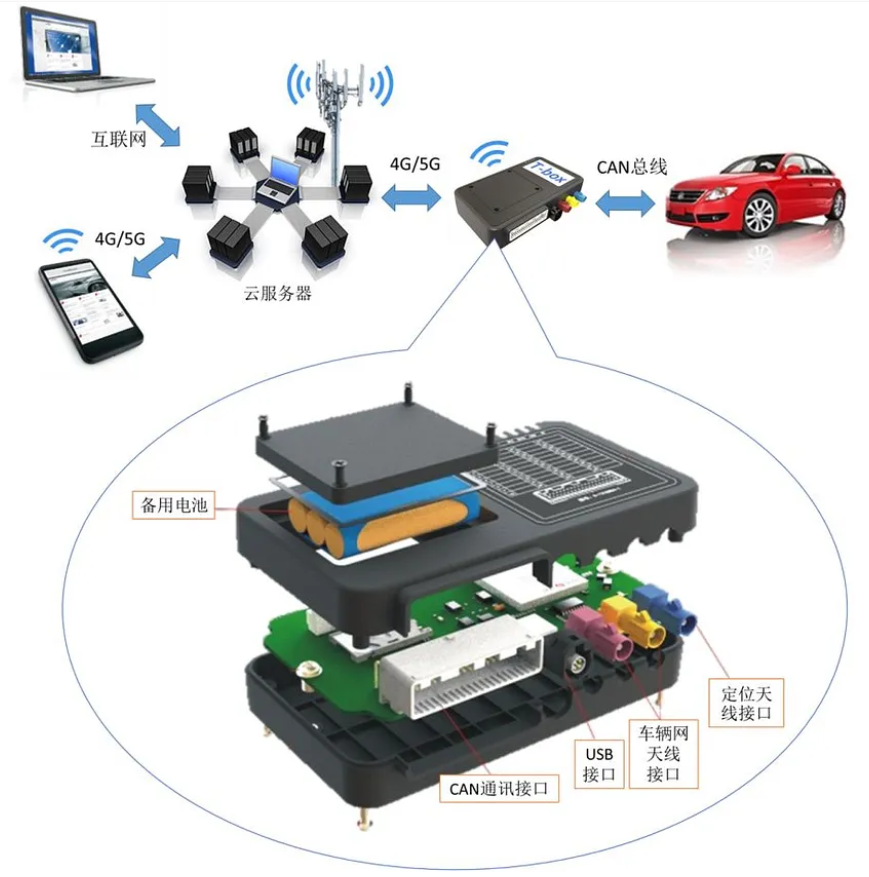
汽车电子零部件(8):T_Box
前言: 网联汽车(Connected Vehicles ,CV)是一个广泛的概念,四个主要的CV线程已发展起来:互联、自主、共享和电动。这些应用于包括CV在内的垂直领域:汽车、通信、互联网和共享手机服务。中国汽车工程师学会(SAEC)提倡将车载ADAS(高级驾驶员辅助系统)与通信技术相结合…...

数库据设计最佳实践
中老年程序员,从业生涯设计过很多数据库,有用上的也有没用上的,有精心设计花无数心思更改了无数次的也有敷衍了事能用就行的,有最糟糕的设计也有感觉还不错的。在设计和修改过程中有很多疑问和感悟,在此记录一下以方便…...

ESSBAE 数据挖掘
essbase数据挖掘框架 1.算法:用来分析数据的方法 2.模型:系列的算法集合 3.任务:数据挖掘的步骤 4.任务模板,可以重复执行的任务 数据挖掘任务: 明确任务 建立及训练模型 测试模型 执行任务 为模型打分 ess…...
上的文件可双向复制粘贴)
在Linux/Ubuntu/Debian中使用iFuse访问iOS 设备(例如 iPhone 或 iPad)上的文件可双向复制粘贴
iFuse 是一款工具,可让你在 Linux 系统上安装 iOS 设备(例如 iPhone 或 iPad),使你能够访问其文件系统并与设备传输文件。 以下是有关如何使用 iFuse 的基本指南: 安装依赖项:在安装 iFuse 之前,…...

驱动开发中的DMA是什么
DMA是一种无须CPU的参与就可以让外设与系统内存之间进行双向数据传输的硬件机制。 使用DMA可以使系统CPU从实际的I/O数据传输过程中摆脱出来, 从而大大提高系统的吞吐率。 DMA通常与硬件体系结构, 特别是外设的总线技术密切相关。 DMA方式的数据传输由DM…...

websocket 升级协议时的协议切换点
websocket 的 rfc6455 标准中提到了协议升级,从http协议升级到websocket协议,用的办法是在http的request header中包含Connection: upgrade 和 Upgrade: websocket 以及其他验证相关的头。服务器验证通过后发送 respond,并升级到websocket。但…...

在Linux中开发C++
在Linux中开发C 本文档为本人在学习慕课网课程——[重学C ,重构你的C知识体系]时的一些记录与思考,侵删。学习课程请支持正版! 1. 搭建C/C编译环境 1.1 gcc 和 g 的区别 本质上没有太大区别,gcc 默认使用 c 编译器…...

【linux】Debian访问Debian上的共享目录
要在Debian系统上访问共享目录,通常意味着要访问通过网络共享的文件夹,比如通过SMB/CIFS(Server Message Block/Common Internet File System)协议共享的Windows共享文件夹。以下是访问共享目录的步骤: 1. 安装必要的…...
Postman Newman API 自动化测试快速入门
什么是 Newman? Newman 是一款专为 Postman 打造的命令行工具,旨在通过自动运行 Postman 集合和环境,实现 API 测试的自动化。它使得开发者无需打开 Postman 图形界面,即可直接在命令行中执行测试用例。 Newman 的优势 使用 Ne…...

Python之Web开发中级教程----ubuntu安装MySQL
Python之Web开发中级教程----ubuntu安装MySQL 进入/opt目录 cd /opt 更新软件源 sudo apt-get upgrade sudo apt-get update 3、安装Mysql server sudo apt-get install mysql-server 4、启动Mysql service mysql start 5、确认Mysql的状态 service mysql status 6、安全设…...
Flutter开发入门——路由
什么是路由? 移动端应用开发中,路由技术是一个非常重要的组成部分。路由技术负责管理应用中各个页面之间的跳转、导航以及参数传递等关键功能。在移动端应用中,一个高效、易于维护的路由系统对于提高开发效率和用户体验具有重要意义。 Flut…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...

MySQL 主从同步异常处理
阅读原文:https://www.xiaozaoshu.top/articles/mysql-m-s-update-pk MySQL 做双主,遇到的这个错误: Could not execute Update_rows event on table ... Error_code: 1032是 MySQL 主从复制时的经典错误之一,通常表示ÿ…...