深度学习J1周-ResNet50算法实战与解析_鸟类识别(CNN)
🍨 本文为[🔗365天深度学习训练营]内部限免文章(版权归 *K同学啊* 所有)
🍖 作者:[K同学啊]
本周任务:
●1.请根据本文 TensorFlow 代码(训练营内部阅读),编写出相应的 Pytorch 代码
●2.了解残差结构
●3.是否可以将残差模块融入到C3当中(自由探索)
思路:因为本章是识别四种鸟类,拿pytorch写,数据集(下文有下载链接)结构没有划分训练集和测试集。很类似week8的咖啡豆识别,因此本章思路代码参考深度学习Week8-咖啡豆识别(Pytorch)_牛大了2022的博客-CSDN博客
理论知识储备
深度残差网络ResNet(deep residual network)在2015年由何恺明等提出,因为它简单与实用并存,随后很多研究都是建立在ResNet-50或者ResNet-101基础上完成的。
ResNet主要解决深度卷积网络在深度加深时候的“退化”问题。在一般的卷积神经网络中,增大网络深度后带来的第一个问题就是梯度消失、爆炸,这个问Szegedy提出BN后被顺利解决。BN层能对各层的输出做归一化,这样梯度在反向层层传递后仍能保持大小稳定,不会出现过小或过大的情况。
但是作者发现加了BN后再加大深度仍然不容易收敛,其提到了第二个问题--准确率下降问题:层级大到一定程度时准确率就会饱和,然后迅速下降,这种下降即不是梯度消失引起的也不是过拟合造成的,而是由于网络过于复杂,以至于光靠不加约束的放养式的训练很难达到理想的错误率。准确率下降问题不是网络结构本身的问题,而是现有的训练方式不够理想造成的。当前广泛使用的训练方法,无论是SGD,还是RMSProp,或是Adam,都无法在网络深度变大后达到理论上最优的收敛结果。还可以证明只要有理想的训练方式,更深的网络肯定会比较浅的网络效果要好。证明过程也很简单:假设在一种网络A的后面添加几层形成新的网络B,如果增加的层级只是对A的输出做了个恒等映射(identity mapping),即A的输出经过新增的层级变成B的输出后没有发生变化,这样网絡A和网络B的错误率就是相等的,也就证明了加深后的网络不会比加深前的网络效果差。
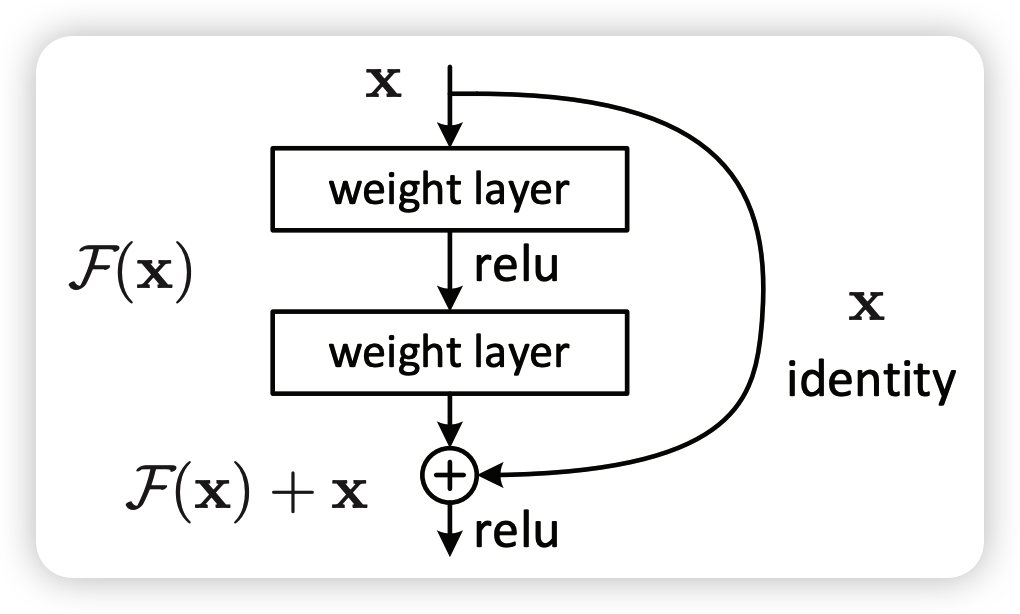
何恺明提出了一种残差结构来实现上述恒等映射(图1):整个模块除了正常的卷积层输出外,还有一个分支把输入直接连到输出上,该分支输出和卷积的输出做算术相加得到最终的输出,用公式表达就是H(x)=F(x)+x,x是输入,F(x)是卷积分支的输出,H(x)是整个结构的输出。可以证明F(x)分支中所有参数都是0。H(x)就是个恒等映射。残差结构人为制造了恒等映射,就能让整个结构朝着恒等映射的方向去收敛,确保最终的错误率不会因为深度的变大而越来越差。如果一个网络通过简单的手工设置参数值就能达到想要的结果,那这种结构就很容易通过训练来收敛到该结果,这是一条设计复杂的网络时通用的规则。
一、环境配置
1. 设置GPU
如果设备上支持GPU就使用GPU,否则使用CPU。尽量配置好GPU使用。
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warningswarnings.filterwarnings("ignore") #忽略警告信息device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
2. 导入数据
本地数据集位于./data/bird_photos/目录下。数据集下载:百度网盘 请输入提取码(提取码:0mhm)

data_dir = './data/bird_photos/'
data_dir = pathlib.Path(data_dir)data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[2] for path in data_paths]
print(classeNames)
['Bananaquit', 'Black Skimmer', 'Black Throated Bushtiti', 'Cockatoo']
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)图片总数为: 565
图形变换,输出一下:用到torchvision.transforms.Compose()类,有兴趣的朋友可以参考这篇博客:torchvision.transforms.Compose()详解【Pytorch手册】
train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸# transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])test_transform = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])total_data = datasets.ImageFolder("./data/bird_photos/", transform=train_transforms)
print(total_data.class_to_idx)
{'Bananaquit': 0, 'Black Skimmer': 1, 'Black Throated Bushtiti': 2, 'Cockatoo': 3}
3. 划分数据集
划分训练集和测试集.
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=0)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=0)
for X, y in test_dl:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)breakShape of X [N, C, H, W]: torch.Size([32, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
二、残差网络(ResNet)介绍
1. 残差网络解决了什么
残差网络是为了解决神经网络隐藏层过多时,而引起的网络退化问题。退化(degradation)问题是指:当网络隐藏层变多时,网络的准确度达到饱和然后急剧退化,而且这个退化不是由于过拟合引起的。
拓展: 深度神经网络的“两朵乌云”
●梯度弥散/爆炸
简单来讲就是网络太深了,会导致模型训练难以收敛。这个问题可以被标准初始化和中间层正规化的方法有效控制。(现阶段知道这么一回事就好了)
●网络退化
随着网络深度增加,网络的表现先是逐渐增加至饱和,然后迅速下降,这个退化不是由于过拟合引起的。
2. ResNet-50介绍
ResNet-50有两个基本的块,分别名为Conv Block和Identity Block

三、构建ResNet-50网络模型
这里可以参考深度学习Week9-YOLOv5-C3模块实现(Pytorch)_牛大了2022的博客-CSDN博客 的构建思路,虽然像week4week6也有CNN网络的构建,但略微粗糙。week9这篇分成四个类构建,同时用到卷积中的autopad这个函数自动补充pad,这个思路我们也可以用到。
def autopad(k, p=None): # kernel, padding# Pad to 'same'if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn p1.identity block
结合上图的结构,conv2d、BN、ReLu,conv2d、BN、ReLu,conv2d、BN三个模块组成,最后再加个relu层
class IdentityBlock(nn.Module):def __init__(self, in_channel, kernel_size, filters):super(IdentityBlock, self).__init__()filters1, filters2, filters3 = filtersself.conv1 = nn.Sequential(nn.Conv2d(in_channel, filters1, 1, stride=1, padding=0, bias=False),nn.BatchNorm2d(filters1),nn.ReLU(True))self.conv2 = nn.Sequential(nn.Conv2d(filters1, filters2, kernel_size, stride=1, padding=autopad(kernel_size), bias=False),nn.BatchNorm2d(filters2),nn.ReLU(True))self.conv3 = nn.Sequential(nn.Conv2d(filters2, filters3, 1, stride=1, padding=0, bias=False),nn.BatchNorm2d(filters3))self.relu = nn.ReLU(True)def forward(self, x):x1 = self.conv1(x)x1 = self.conv2(x1)x1 = self.conv3(x1)x = x1 + xself.relu(x)return x2.conv block
比前者多一个conv2d、BN层
class ConvBlock(nn.Module):def __init__(self, in_channel, kernel_size, filters, stride=2):super(ConvBlock, self).__init__()filters1, filters2, filters3 = filtersself.conv1 = nn.Sequential(nn.Conv2d(in_channel, filters1, 1, stride=stride, padding=0, bias=False),nn.BatchNorm2d(filters1),nn.ReLU(True))self.conv2 = nn.Sequential(nn.Conv2d(filters1, filters2, kernel_size, stride=1, padding=autopad(kernel_size), bias=False),nn.BatchNorm2d(filters2),nn.ReLU(True))self.conv3 = nn.Sequential(nn.Conv2d(filters2, filters3, 1, stride=1, padding=0, bias=False),nn.BatchNorm2d(filters3))self.conv4 = nn.Sequential(nn.Conv2d(in_channel, filters3, 1, stride=stride, padding=0, bias=False),nn.BatchNorm2d(filters3))self.relu = nn.ReLU(True)def forward(self, x):x1 = self.conv1(x)x1 = self.conv2(x1)x1 = self.conv3(x1)x2 = self.conv4(x)x = x1 + x2self.relu(x)return x3.ResNet50
注意def forward上面一行的 4 是识别种类的数目
class ResNet50(nn.Module):def __init__(self, classes=1000):super(ResNet50, self).__init__()self.conv1 = nn.Sequential(nn.Conv2d(3, 64, 7, stride=2, padding=3, bias=False, padding_mode='zeros'),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=0))self.conv2 = nn.Sequential(ConvBlock(64, 3, [64, 64, 256], stride=1),IdentityBlock(256, 3, [64, 64, 256]),IdentityBlock(256, 3, [64, 64, 256]))self.conv3 = nn.Sequential(ConvBlock(256, 3, [128, 128, 512]),IdentityBlock(512, 3, [128, 128, 512]),IdentityBlock(512, 3, [128, 128, 512]),IdentityBlock(512, 3, [128, 128, 512]))self.conv4 = nn.Sequential(ConvBlock(512, 3, [256, 256, 1024]),IdentityBlock(1024, 3, [256, 256, 1024]),IdentityBlock(1024, 3, [256, 256, 1024]),IdentityBlock(1024, 3, [256, 256, 1024]),IdentityBlock(1024, 3, [256, 256, 1024]),IdentityBlock(1024, 3, [256, 256, 1024]))self.conv5 = nn.Sequential(ConvBlock(1024, 3, [512, 512, 2048]),IdentityBlock(2048, 3, [512, 512, 2048]),IdentityBlock(2048, 3, [512, 512, 2048]))self.pool = nn.AvgPool2d(kernel_size=7, stride=7, padding=0)self.fc = nn.Linear(2048, 4)#4是识别种类的数目def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = self.conv4(x)x = self.conv5(x)x = self.pool(x)x = torch.flatten(x, start_dim=1)x = self.fc(x)return x4. 查看模型详情
打印下模型
model = ResNet50().to(device)
print(model)ResNet50(
(conv1): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv2): Sequential(………………
统计模型参数量以及其他指标
import torchsummary as summary
summary.summary(model, (3, 224, 224))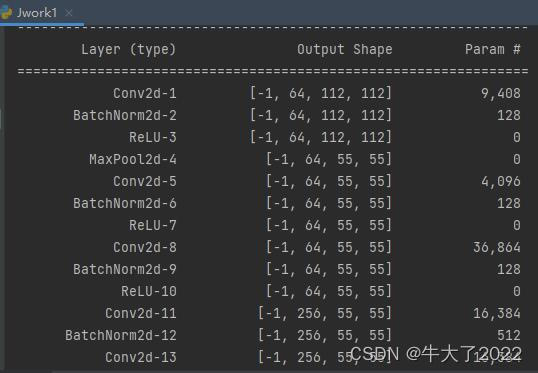
四、训练与运行
1. 编写训练和测试函数
两个基本上不怎么变。训练部分代码和之前cnn网络一样
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss训练函数和测试函数差别不大,但是由于不进行梯度下降对网络权重进行更新,所以不用优化器
(所以测试函数代码部分和之前几周一样)
def test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小num_batches = len(dataloader) # 批次数目test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss2.训练器的选择和训练
结合之前的实验经验,使用Adam模型。按照实验要求,10轮训练。记得加上4可视化后再运行。
学习率试了1e-7效果并不好,所以用了1e-5,设置动态学习率也许会好一点点。
import copyoptimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss() # 创建损失函数epochs = 10train_loss = []
train_acc = []
test_loss = []
test_acc = []best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标for epoch in range(epochs):# 更新学习率(使用自定义学习率时使用)# adjust_learning_rate(optimizer, epoch, learn_rate)model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)# scheduler.step() # 更新学习率(调用官方动态学习率接口时使用)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)# 保存最佳模型到 best_modelif epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = optimizer.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss,epoch_test_acc * 100, epoch_test_loss, lr))# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)print('Done')
3.结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()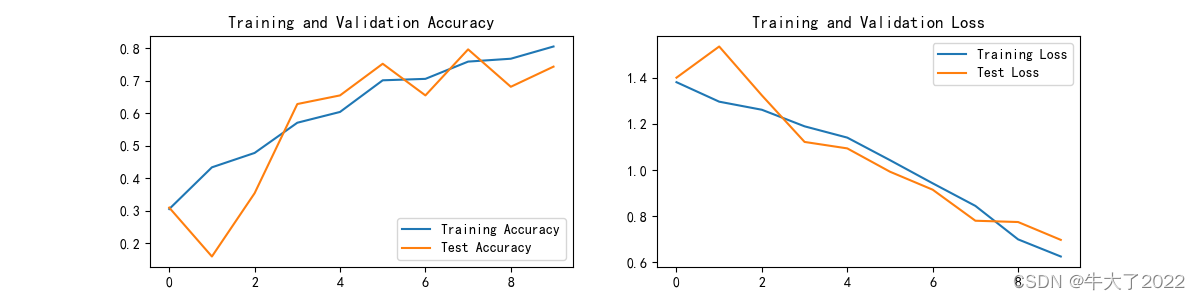
五、模型预测
预测时候可以把上面训练大部分注释掉。
from PIL import Imageclasses = list(total_data.class_to_idx)def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_,pred = torch.max(output,1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')# 预测训练集中的某张照片predict_one_image(image_path='./data/bird_photos/Bananaquit/007.jpg',model=model,transform=train_transforms,classes=classes)
模型评估
以往都是看看最后几轮得到准确率,但是跳动比较大就不太好找准确率最高的一回,所以我们用函数返回进行比较。
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
print(epoch_test_acc, epoch_test_loss)
print(epoch_test_acc)相关文章:
深度学习J1周-ResNet50算法实战与解析_鸟类识别(CNN)
🍨 本文为[🔗365天深度学习训练营]内部限免文章(版权归 *K同学啊* 所有) 🍖 作者:[K同学啊] 本周任务: ●1.请根据本文 TensorFlow 代码(训练营内部阅读),编写…...
SpringBoot中一行代码解决字符串向枚举类型转换的问题
1. 场景 在WEB开发,客户端和服务端传输的数据中经常包含一些这样的字段:字段的值只包括几个固定的字符串。 这样的字段意味着我们需要在数据传输对象(Data Transfer Object, DTO)中对该字段进行校验以避免客户端传输的非法数据持…...
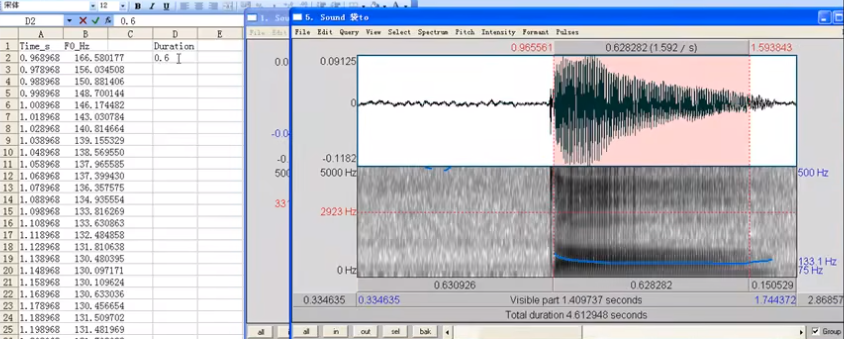
Praat之基频分析
Praat之基频分析 测量基频F0的方法 自相关 Autocorrelation(易出现pitch-halving\pitch-double)窄带谱图 Narrowband spectrogram(第一谐波就是基频)倒谱分析 Cepstral analysis测量声门波 glottal pluse(通过波形&a…...
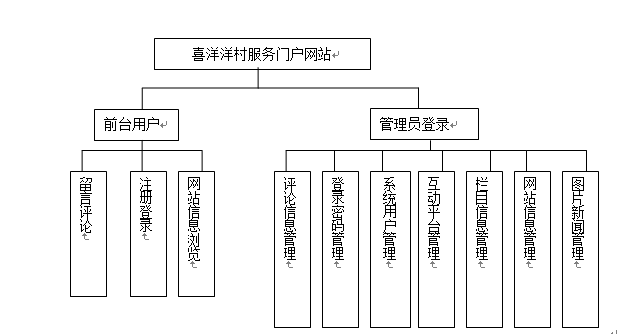
乡村企业门户网站
技术:Java、JSP等摘要:随着时代的发展,电脑与Internet已经进入我们的生活。信息时代的来临,知识经济的扩张,网站已越来越靠近我们的生活。据CNNIC报告显示,中国上网用户有6800万。通过Internet来经营运作一…...

Deploy Workshop|DIY部署环境,让OceanBase跑起来
2023 年 3 月 25 日,我们将在北京开启首次 OceanBase 开发者大会,与开发者共同探讨单机分布式、云原生、HTAP 等数据库前沿趋势,分享全新的产品 Roadmap,交流场景探索和最佳实践,此外,OceanBase 开源技术全…...

【CPP】定义一个类
一:当实现一个类的时候,编译器都做了什么 前言:当我们实现一个类的时候,编译器为我们做了什么;在对类进行操作的时候,有哪些特殊的成员函数可以帮助我们更好的操纵类; class A {A();//默认构造…...
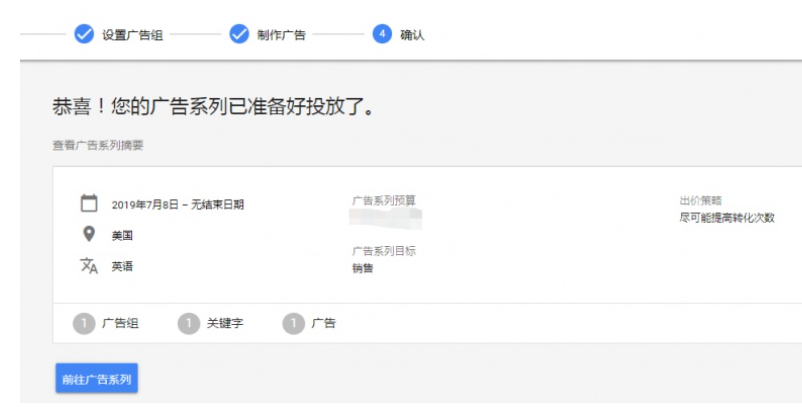
谷歌广告投放步骤流程是什么?一文带你全方位了解实操细节
谷歌,大家都不陌生吧,一个人们很常用的搜索引擎。而谷歌还可以打广告,即谷歌广告,那这跟跨境电商有什么关心呢?东哥告诉大家,关系大了去了,毕竟如果用户搜索与我们相关的关键词,就有…...

TypeScript 怎么去查找类型定义的?
TypeScript 怎么去查找类型定义的?类型文件分类第三方库的类型自定义类型结论类型文件分类 我们项目中的类型文件分为两种:一类是第三方库的类型,一类是在项目中的自定义类型。 第三方库的类型 (1)Jquery࿱…...
NPM包管理器
文章目录一、NPM包管理器1、简介2、安装NPM3、使用npm管理项目3.1项目初始化3.2修改npm镜像3.3 npm install命令的使用3.4其它命令一、NPM包管理器 1、简介 什么是NPM NPM全称Node Package Manager,是Node.js包管理工具,是全球最大的模块生态系统&…...

IT英语记录
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言1、Classification2、Logistic Regression3、网络相关3.1 WAN(Wide Area Network)、LAN(Local Area Network)网络…...
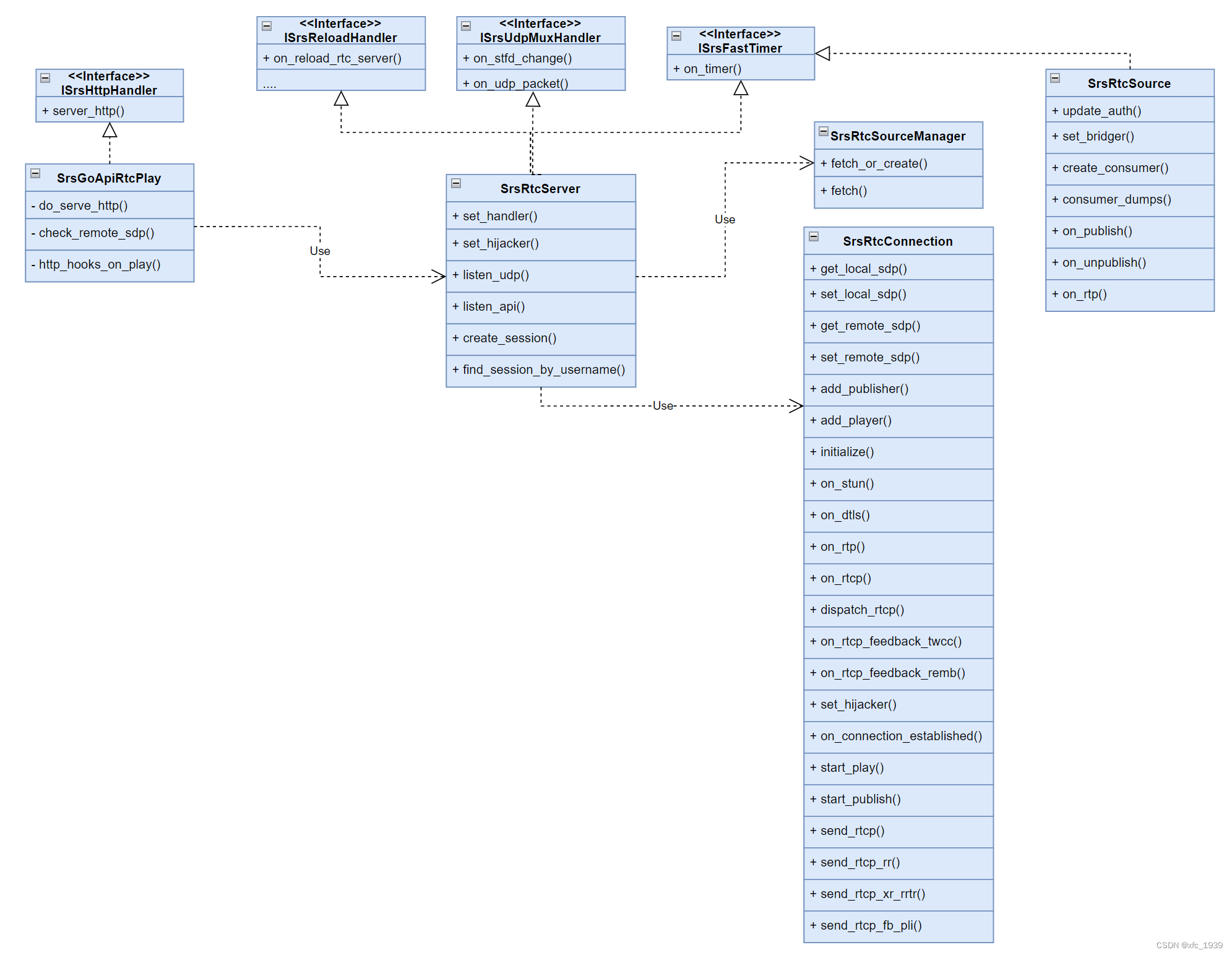
SRS4.0 源码分析- RTC模块相关类
前言 本文介绍SRS4.0涉及RTC模块的C类,主要包括RTC Server和Session相关的。 SrsGoApiRtcPlay 处理webrtc client的播放请求,解析client的offer,并且生成server的answer,并且为这次请求创建一个session。SrsRtcServer 监听udp端…...
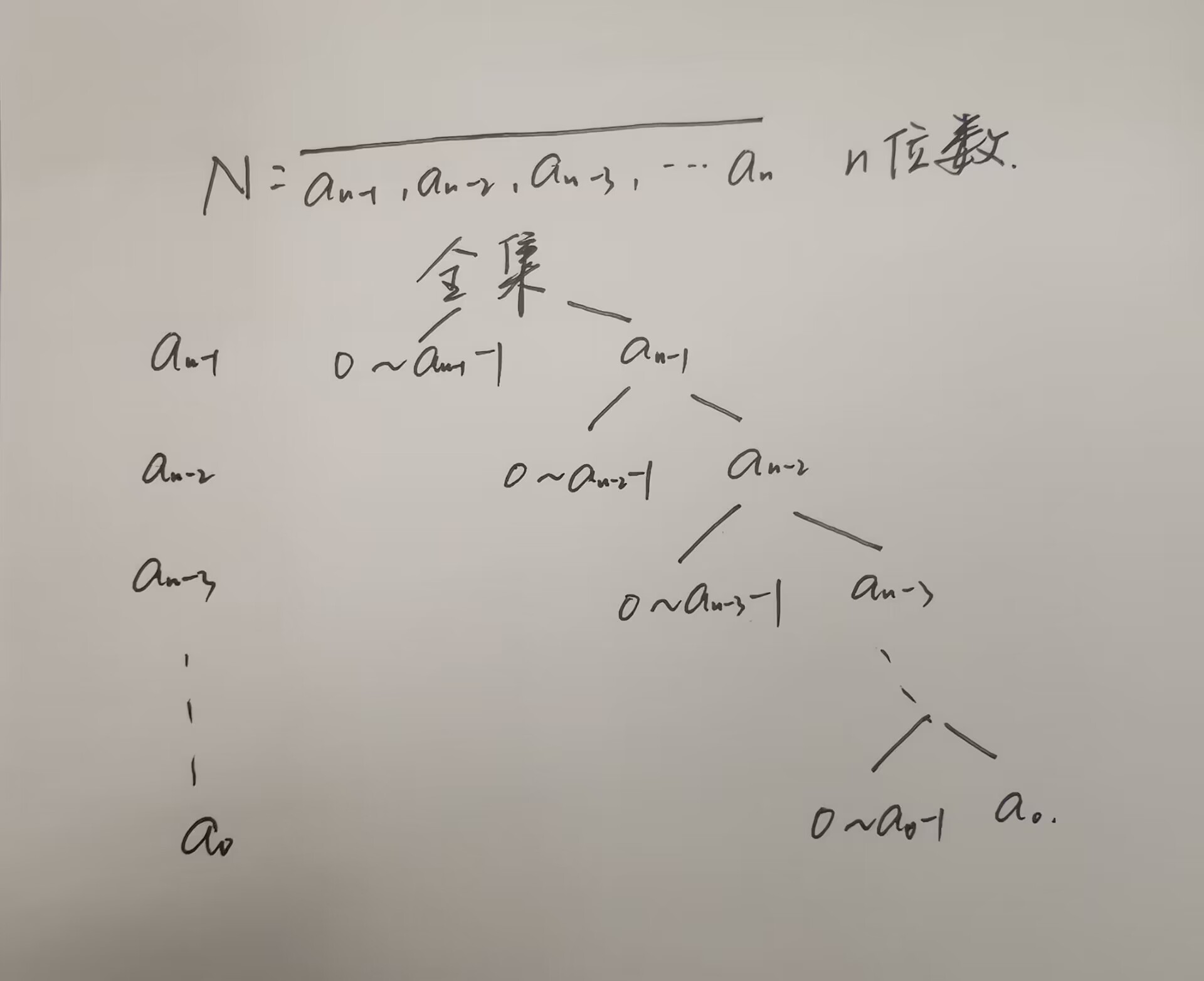
数位DP
数位dp的题目一般会问,某个区间内,满足某种性质的数的个数。 利用前缀和,比如求区间[l,r]中的个数,转化成求[0,r]的个数 [0,l-1]的个数。利用树的结构来考虑(按位分类讨论) 1081. 度的数量 #include<…...
-链表)
剑指offer(一)-链表
(一)找出链表的环的入口结点 JZ23 链表中环的入口结点 中等 通过率:36.78% 时间限制:1秒 空间限制:64M 知识点链表哈希双指针 描述 给一个长度为n链表,若其中包含环,请找出该链表的环的入口结点…...
CDH大数据平台入门篇之搭建与部署
一、CDH介绍 1.CDH 是一个强大的商业版数据中心管理工具 提供了各种能够快速稳定运行的数据计算框架,如Spark; 使用Apache Impala做为对HDFS、HBase的高性能SQL查询引擎; 使用Hive数据仓库工具帮助用户分析数据; 提供CM安装HBas…...

Spark Join
Spark Join关联形式内关联外关联左外关联右外关联全外关联左半/逆关联关联机制NLJSMJHJ分发模式Join 选择等值 Join不等值 JoinJoin 按照关联形式(Join Types)划分 : 内关联、外关联、左关联、右关联 Join 按实现机制划分 : NLJ (Nested Loop Join) 、S…...

数字的转化规则?
数字的转化规则?js将字符串转换为数字的方式有哪些?1. 使用 parseInt()2. 使用 Number()3. 使用一元运算符 ()4.使用parseFloat()5. 使用 Math.floor()和Math.ceil()6.乘以数字7. 双波浪号 (~~) 运算符其它值到数字的转化规则1.Undefined 类型2.Null 类型…...

MySQL面试题-锁相关
目录 1.MySQL 锁的类型有哪些呢? 2.如何使用全局锁 3.如果要全库只读,为什么不使用set global readonlytrue的方式? 4.表级锁和行级锁有什么区别? 5.行级锁的使用有什么注意事项? 6.InnoDB 有哪几类行锁ÿ…...

Windows 终端编译 C代码
E:\My_SoftWare\Window gcc\windowbianji\mingw64\bin 此电脑--》属性--》系统--》高级系统设置--》环境变量--》Path--》新建--》粘贴路径 E:\My_SoftWare\Window gcc\windowbianji\mingw64\bin 打开命令终端 E: 回车 dir 显示所有文件 cd E:\My_SoftWare\Window gcc\C_co…...
SpringCloud:Feign的使用及配置
目录 Feign的使用及配置 1、Feign替代RestTemplate 2、使用Fegin步骤 3、自定义配置 4、Feign使用优化 5、Feign的最佳实践方式 Feign的使用及配置 1、Feign替代RestTemplate RestTemplate方式远程调用的问题 问题: 1、代码可读性差,编程体验不同…...

Parquet学习与使用之BloomFilter的应用
写在前面 最近在自己做自定义的OLAP系统,文件格式上用的是Parquet,但是发现Parquet各个API的示例代码很少。所以就打算把这个系列的文章写一下。 1. Parquet的Filter Parquet的过滤支持两大类,一类是基于Footer中的元数据进行RowGroup级别…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...

Python竞赛环境搭建全攻略
Python环境搭建竞赛技术文章大纲 竞赛背景与意义 竞赛的目的与价值Python在竞赛中的应用场景环境搭建对竞赛效率的影响 竞赛环境需求分析 常见竞赛类型(算法、数据分析、机器学习等)不同竞赛对Python版本及库的要求硬件与操作系统的兼容性问题 Pyth…...