pytorch常用的模块函数汇总(2)
目录
torch.utils.data:数据加载和处理模块,包括 Dataset 和 DataLoader 等工具,用于加载和处理训练数据。
torchvision:计算机视觉模块,提供了图像数据集、转换函数、预训练模型等,用于计算机视觉任务。
torchtext:自然语言处理模块,包含了文本数据集、文本处理工具等,用于自然语言处理任务。
torch.nn.functional:函数式接口模块,包含了一些函数式的操作,如激活函数、池化函数、卷积函数等。
torch.nn.init:参数初始化模块,用于初始化神经网络的参数。
torch.optim.lr_scheduler:学习率调度器模块,用于动态调整学习率。
torch.utils:实用工具模块,包含了模型保存和加载、学习率调整等实用工具。
torch.distributed:分布式计算模块,提供了用于分布式计算的支持。
-
torch.utils.data:数据加载和处理模块,包括 Dataset 和 DataLoader 等工具,用于加载和处理训练数据。
-
torch.utils.data.Dataset是一个抽象类,代表数据集。为了自定义数据集,我们可以创建一个继承自Dataset的子类,并实现__len__和__getitem__方法,以便能够按索引获取数据集中的样本。 -
torch.utils.data.DataLoader是一个用于批量加载数据的工具。它接收一个Dataset对象作为输入,然后在训练过程中按照指定的批量大小和顺序加载数据,并可选择是否进行数据打乱等操作。 -
torch.utils.data.random_split(dataset, lengths)函数用于将一个数据集按照给定的长度随机分割成多个子数据集。这在划分训练集和验证集时很有用。 -
torch.utils.data.Subset类表示原始数据集的一个子集,可以通过传入索引列表来创建。 -
torch.utils.data.TensorDataset是一个将张量作为数据集的类,通常用于将特征张量和标签张量进行配对。 -
torch.utils.data.ConcatDataset类允许将多个数据集串联起来,以便联合使用多个数据集的样本。 -
torch.utils.data.Sampler类用于指定样本抽样的策略,如随机抽样、有放回抽样、无放回抽样等。 -
torchvision:计算机视觉模块,提供了图像数据集、转换函数、预训练模型等,用于计算机视觉任务。
-
transforms 模块:
transforms.Compose(transforms):将多个图像变换组合在一起。transforms.ToTensor():将 PIL 图像或 ndarray 转换为张量。transforms.Normalize(mean, std):对张量进行归一化。transforms.Resize(size):调整图像尺寸。transforms.CenterCrop(size):对图像进行中心裁剪。transforms.RandomHorizontalFlip():随机水平翻转图像。transforms.RandomRotation(degrees):随机旋转图像。
-
datasets 模块:
datasets.ImageFolder(root, transform):加载包含图像的文件夹数据集,可以自动根据文件夹名称进行分类。datasets.CIFAR10(root, train=True, transform=None, target_transform=None, download=False):加载 CIFAR-10 数据集。datasets.CIFAR100(root, train=True, transform=None, target_transform=None, download=False):加载 CIFAR-100 数据集。datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False):加载 MNIST 数据集。datasets.VOCDetection(root, year='2012', image_set='train', transform=None, target_transform=None, download=False):加载 VOC 数据集。
-
models 模块:
- 预训练的图像分类模型:
models.resnet18(pretrained=True)、models.resnet50(pretrained=True)等。 - 预训练的目标检测模型:
models.detection.fasterrcnn_resnet50_fpn(pretrained=True)、models.detection.maskrcnn_resnet50_fpn(pretrained=True)等。
- 预训练的图像分类模型:
-
utils 模块:
utils.make_grid(tensor, nrow=8, padding=2, normalize=False, range=None, scale_each=False, pad_value=0):将张量转换为图像网格显示。utils.save_image(tensor, filename, nrow=8, padding=2, normalize=False, range=None, scale_each=False, pad_value=0):保存张量为图像文件。- 这些函数和类使得我们能够方便地处理图像数据,加载常用的数据集,构建图像处理流水线,以及使用预训练的模型进行图像分类、目标检测等任务。
-
torchtext:自然语言处理模块,包含了文本数据集、文本处理工具等,用于自然语言处理任务
-
data 模块:
data.Field:定义文本字段的处理规则,如分词方法、是否转换为小写等。data.TabularDataset.splits:加载文本数据集并进行划分。data.Iterator:生成数据迭代器,用于模型训练。data.Example:表示一个样本,包含字段和对应的数值。
-
datasets 模块:
datasets.LanguageModelingDataset:用于语言建模任务的数据集。datasets.SequenceTaggingDataset:用于序列标注任务的数据集。datasets.TranslationDataset:用于机器翻译任务的数据集。
-
vocab 模块:
vocab.Vocab:构建词汇表对象,包含词汇表的词汇和索引映射关系。vocab.GloVe:加载预训练的 GloVe 词向量。
-
utils 模块:
utils.get_tokenizer:获取用于分词的 tokenizer。utils.ngrams_iterator:生成 n 元组(n-grams)的迭代器。
-
experimental 模块:
experimental.datasets.SNLI:加载斯坦福自然语言推断数据集。experimental.datasets.IMDB:加载 IMDB 电影评论情感分类数据集。
- 通过使用这些函数和类,我们可以方便地处理文本数据,并将其转换为模型可接受的格式,从而进行文本相关的任务,如文本分类、序列标注、机器翻译等。
torchtext的功能丰富且易于使用,能够加速文本数据处理流程。
-
torch.nn.functional:函数式接口模块,包含了一些函数式的操作,如激活函数、池化函数、卷积函数等
-
激活函数:
torch.nn.functional.relu(input, inplace=False):ReLU(修正线性单元)激活函数。torch.nn.functional.sigmoid(input):Sigmoid 激活函数。torch.nn.functional.tanh(input):双曲正切激活函数。torch.nn.functional.softmax(input, dim=None):Softmax 激活函数。
-
池化函数:
torch.nn.functional.max_pool2d(input, kernel_size, stride=None, padding=0, dilation=1, ceil_mode=False):二维最大池化。torch.nn.functional.avg_pool2d(input, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True):二维平均池化。
-
损失函数:
torch.nn.functional.cross_entropy(input, target):交叉熵损失函数。torch.nn.functional.mse_loss(input, target):均方误差损失函数。
-
卷积函数:
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1):二维卷积操作。torch.nn.functional.conv_transpose2d(input, weight, bias=None, stride=1, padding=0, output_padding=0, groups=1, dilation=1):二维转置卷积操作(反卷积)。反卷积主要作用如下:上采样:反卷积可以用来实现上采样操作,将输入特征图的尺寸放大,从而恢复到更高分辨率的特征图。这在一些任务中非常有用,比如图像分割、图像生成等。特征映射还原:在某些情况下,我们需要将经过卷积降维的特征图还原到原始输入的尺寸,反卷积可以帮助我们实现这一目的,从而保留更多的空间信息。重建输入:反卷积可以用于重建输入信号,尤其在一些自编码器、生成对抗网络(GAN)等模型中,可以通过反卷积层来重建生成的图像或信号。网络可视化:在神经网络可视化中,我们常常会使用反卷积来可视化卷积神经网络中各个层的特征激活图,帮助理解网络学到的特征。
-
归一化函数:
torch.nn.functional.batch_norm(input, running_mean, running_var, weight=None, bias=None, training=False, momentum=0.1, eps=1e-5):批量归一化操作。批量归一化的基本思想是对每个特征维度的数据进行归一化处理,使其均值接近0,方差接近1,然后再通过缩放和平移参数(γ 和 β)来恢复网络的表示能力。加速收敛; 控制过拟合; 提高泛化能力。torch.nn.functional.layer_norm(input, normalized_shape, weight=None, bias=None, eps=1e-5):层归一化操作。与批量归一化不同,层归一化是针对每个样本的所有特征进行归一化处理,而不是像批量归一化一样对每个特征维度在 mini-batch 上进行归一化。
-
其他常用函数:
torch.nn.functional.dropout(input, p=0.5, training=True, inplace=False):随机丢弃操作。torch.nn.functional.embedding(input, weight, padding_idx=None, max_norm=None, norm_type=2.0):嵌入层操作。
-
torch.nn.init:参数初始化模块,用于初始化神经网络的参数
torch.nn.init.xavier_uniform_: 使用 Xavier 均匀分布初始化权重。
torch.nn.init.xavier_normal_: 使用 Xavier 正态分布初始化权重。
torch.nn.init.kaiming_uniform_: 使用 Kaiming 均匀分布初始化权重。
torch.nn.init.kaiming_normal_: 使用 Kaiming 正态分布初始化权重。
torch.nn.init.uniform_: 使用均匀分布初始化张量。
torch.nn.init.normal_: 使用正态分布初始化张量。
torch.nn.init.constant_: 使用常数初始化张量。
备注:
Xavier 初始化的核心思想是根据网络的输入与输出的尺度,合理地初始化权重,使得每一层的输出方差尽量保持不变。具体来说,对于一个全连接层或卷积层的权重矩阵 ( W ),Xavier 初始化将权重初始化为从均匀或正态分布中采样的值。
-
torch.optim.lr_scheduler:学习率调度器模块,用于动态调整学习率
StepLR: 根据给定的步长调整学习率。
MultiStepLR: 在指定的 epochs 处调整学习率。
ExponentialLR: 使用指数衰减调整学习率。
ReduceLROnPlateau: 当某个指标不再变化时,减小学习率。
CosineAnnealingLR: 使用余弦退火调整学习率。
-
torch.utils:实用工具模块,包含了模型保存和加载、学习率调整等实用工具
-
data: 数据处理相关的工具函数和数据集类。
-
data.dataloader: 数据加载器,用于批量加载数据并提供数据增强功能。
-
data.dataset: 数据集抽象类,用于自定义数据集。
-
model_zoo: 包含预训练模型的存储库,可以加载预训练的模型参数。
-
utils.clip_grad_norm_: 对模型梯度进行裁剪,防止梯度爆炸。
-
utils.data: 提供数据集、数据加载器等数据处理相关的函数。
-
utils.make_grid: 将多张图片拼接成一个网格形式的图片显示。
-
utils.parameters_to_vector, utils.vector_to_parameters: 将模型参数转换为向量、将向量转换回模型参数。
-
utils.save_checkpoint, utils.load_checkpoint: 保存和加载模型检查点。
-
torch.distributed:分布式计算模块,提供了用于分布式计算的支持
通过这些函数,可以方便地在多个设备或多台机器上进行模型训练,并实现数据并行、模型并行等分布式训练策略。
init_process_group: 初始化分布式环境,并设置通信后端。
is_initialized: 检查当前进程是否已经初始化了分布式环境。
get_rank: 获取当前进程的全局排名。
get_world_size: 获取参与训练的总进程数。
broadcast: 在所有进程之间广播张量数据。
reduce: 在所有进程中对张量数据进行归约操作。
all_reduce: 对所有进程中的张量数据进行全局归约操作。
gather: 收集所有进程中的张量数据到指定进程。
scatter: 将指定进程中的张量数据分发到所有进程。
相关文章:
)
pytorch常用的模块函数汇总(2)
目录 torch.utils.data:数据加载和处理模块,包括 Dataset 和 DataLoader 等工具,用于加载和处理训练数据。 torchvision:计算机视觉模块,提供了图像数据集、转换函数、预训练模型等,用于计算机视觉任务。 …...

OpenAI奥特曼豪赌1.42亿破解长生不老
生物初创公司 Retro Biosciences 由山姆奥特曼投资1.42亿英镑,公司目标是延长人类寿命。 山姆奥特曼投资背景: 38 岁的奥特曼一直是科技行业的重要参与者。尽管年纪轻轻,奥特曼凭借 ChatGPT 和 Sora 等产品席卷了科技领域。奥特曼对 Reddit…...

[晕事]今天做了件晕事29;iptables
今天办了一件晕事,主机之间做ping用tcpdump抓到了ping request,但是没有看到ping reply,查看主机的arp表,路由表都没有问题,忘记看iptables的规则。虽然在tcpdump看到包,只是代表包到了二层,并不…...

2018年亚马逊云科技推出基于Arm的定制芯片实例
2018年,亚马逊云技术推出了基于Arm的定制芯片。 据相关数据显示,基于Arm的性价比比基于x86的同类实例高出40%。 这打破了对 x86 的依赖,开创了架构的新时代,现在能够支持多种配置的密集计算任务。 这些举措为亚马逊云技术的其他创…...
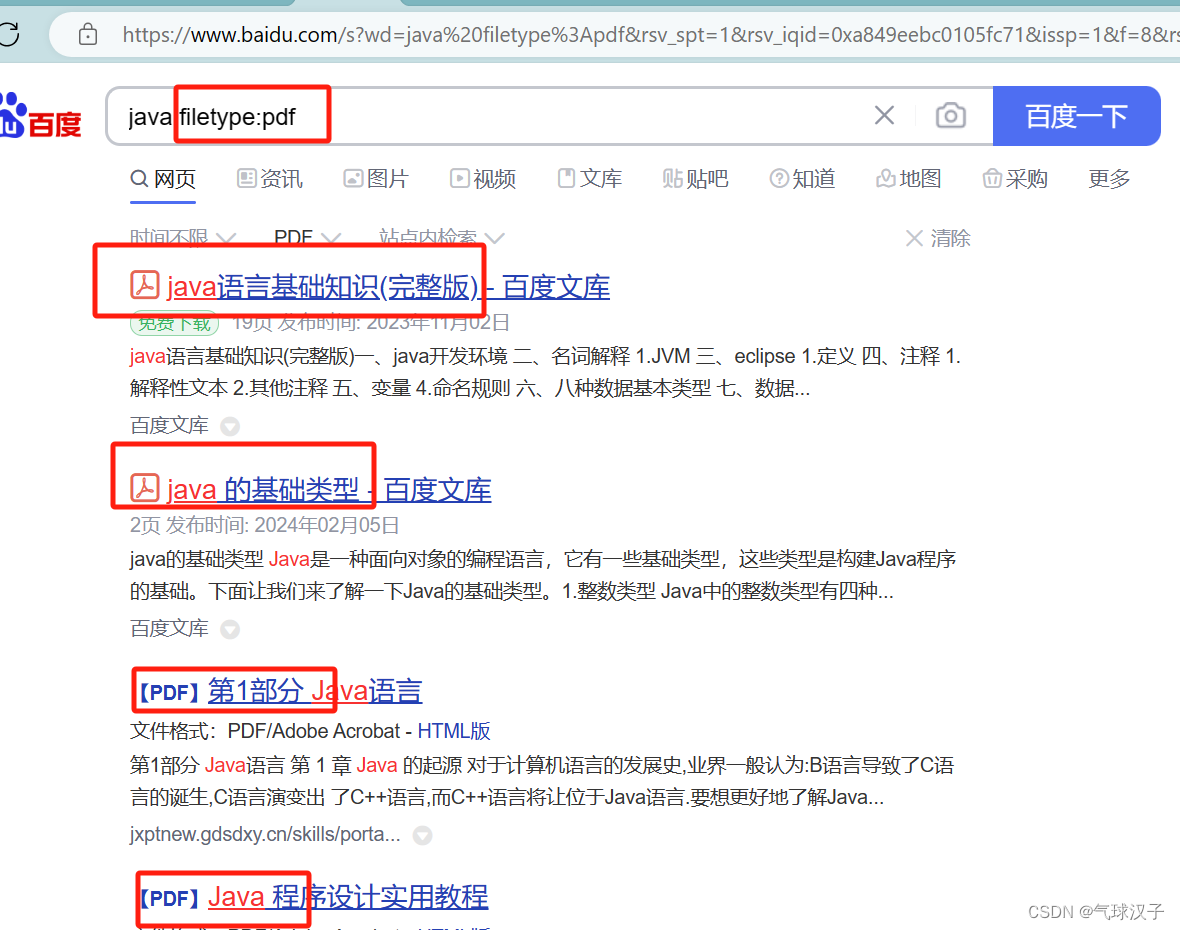
用搜索引擎收集信息-常用方式
1,site csdn.net (下图表示只在csdn网站里搜索java) 2,filetype:pdf (表示只检索某pdf文件类型) 表示在浏览器里面查找有关java的pdf文件 3,intitle:花花 (表示搜索网页标题里面有花…...

Adobe推出20多个,企业版生成式AI定制、微调服务
3月27日,全球多媒体领导者Adobe在拉斯维加斯召开“Summit 2024”大会,重磅推出了Firefly Services。 Firefly Services提供了20 多个生成式AI和创意API服务,支持企业自有数据对模型进行定制、微调,同时可以与PS、Illustrator、Ex…...
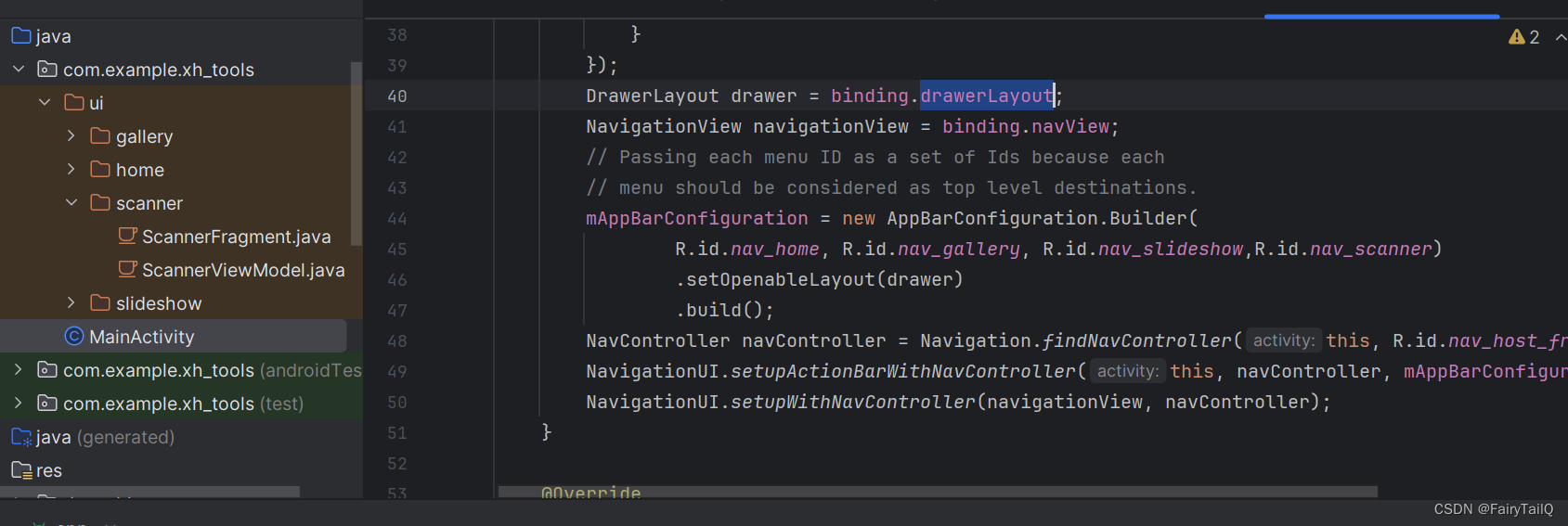
叁[3],NavigationDrawerViewsActivity新增Fragment
1,环境 AndriodStudio JDK21 2,新建项目NavigationDrawerViewsActivity 3,新建包文件夹,ui右键菜单/New/Package 4,新建Fragment,app右键菜单/New/Fragment/Fragment(with ViewModel) 5,资源string增加键…...
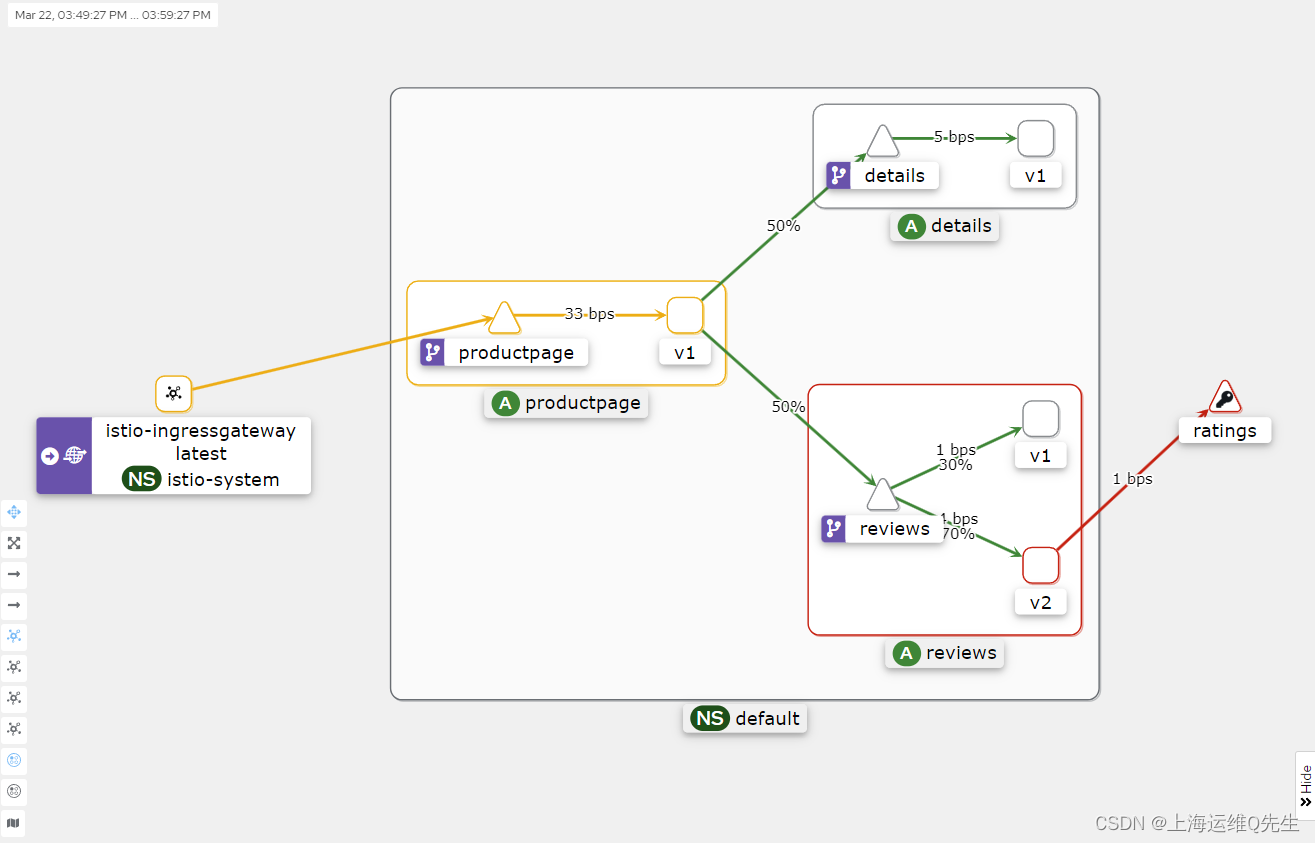
备考ICA----Istio实验7---故障注入 Fault Injection 实验
备考ICA----Istio实验7—故障注入 Fault Injection 实验 Istio 的故障注入用于模拟应用程序中的故障现象,以测试应用程序的故障恢复能力。故障注入有两种: 1.delay延迟注入 2.abort中止注入 1. 环境准备 kubectl apply -f istio/samples/bookinfo/platform/kube/…...

[flask]异常抛出和捕获异常
Python学习之Flask全局异常处理流程_flask 异常处理-CSDN博客 读取文件错误 OSError: [Errno 22] Invalid argument:_[errno 22] invalid argument: ..\\data\\snli_1.0\\-CSDN博客 异常触发 assert触发异常: 在Python中,使用assert语句可以检查某个条…...

js逆向之实例某宝热卖(MD5)爬虫
目录 正常写 反爬 逆向分析 关键字搜索 打断点&分析代码 得出 sign 的由来 确定加密方式 写加密函数了 补全代码 免责声明:本文仅供技术交流学习,请勿用于其它违法行为. 正常写 还是老规矩,正常写代码,该带的都带上,我这种方法发现数据格式不完整. 应该后面也是大…...

7、jenkins项目构建细节-常用的构建触发器
文章目录 一、常用的构建细节1、触发远程构建2、其他工程构建后触发3、定时构建4、轮询SCM(Poll SCM)二、Git hook自动触发构建(☆☆☆)1、安装插件2、Jenkins设置自动构建3、Gitlab配置webhook三、Jenkins的参数化构建1、项目创建分支,并推送到gitlab上2、在Jenkins添加字…...

【前端学习——css篇】4.px和rem的区别
https://github.com/febobo/web-interview 4.px和rem的区别 ①px px,表示像素,所谓像素就是呈现在我们显示器上的一个个小点,每个像素点都是大小等同的,所以像素为计量单位被分在了绝对长度单位中 有些人会把px认为是相对长度&…...
及其等价改写方法)
深入解析Oracle数据库中的标量子查询(Scalar Subquery)及其等价改写方法
在Oracle数据库中,标量子查询(Scalar Subquery)是一种特殊的子查询,它返回单个值作为结果,而不是一组记录。标量子查询通常嵌套在另一个查询的SELECT列表、WHERE子句、HAVING子句或表达式中,它就像一个可以…...

Pytorch多机多卡分布式训练
多机多卡分布式: 多机基本上和单机多卡差不多: 第一台机器(主设备): torchrun --master_port 6666 --nproc_per_node8 --nnodes${nnodes} --node_rank0 --master_addr${master_addr} train_with_multi_machine_an…...

win11 环境配置 之 Jmeter
一、安装 JDK 1. 安装 jdk 截至当前最新时间: 2024.3.27 jdk最新的版本 是 官网下载地址: https://www.oracle.com/java/technologies/downloads/ 建议下载 jdk17 另存为到该电脑的 D 盘下,新建jdk文件夹 开始安装到 jdk 文件夹下 2. 配…...
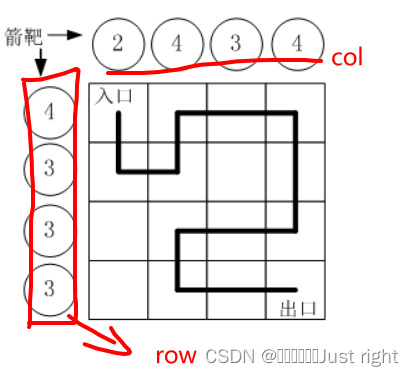
蓝桥杯刷题之路径之谜
题目来源 路径之谜 不愧是国赛的题目 题意 题目中会给你两个数组,我这里是分别用row和col来表示 每走一步,往左边和上边射一箭,走到终点的时候row数组和col数组中的值必须全部等于0这个注意哈,看题目看了半天,因为…...

【深度学习】图片预处理,分辨出模糊图片
ref:https://pyimagesearch.com/2015/09/07/blur-detection-with-opencv/ 论文 ref:https://www.cse.cuhk.edu.hk/leojia/all_final_papers/blur_detect_cvpr08.pdf 遇到模糊的图片,还要处理一下,把它挑出来,要么修复,要么弃用。否…...

基础NLP知识了解
基础NLP知识… 线性变换 通过一个线性变换将隐藏状态映射到另一个维度空间,以获得预期维度的向量 $ outputs hidden_layer * W b$ 这里的W是权重矩阵,b是偏置项,它们是线性变换的参数,通过训练数据学习得到。输出向量的维度…...
Android 性能优化(六):启动优化的详细流程
书接上文,Android 性能优化(一):闪退、卡顿、耗电、APK 从用户体验角度有四个性能优化方向: 追求稳定,防止崩溃追求流畅,防止卡顿追求续航,防止耗损追求精简,防止臃肿 …...
QT程序打包
将exe文件单独拿出来放入一个单独的文件夹 保存qt安装路径下有如下这个文件 windeployqt.exe 在TCPFile.exe文件夹中使用以下cmd命令运行 即可打包 windeployqt 文件名.exe 成功打包!...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...
安装docker)
Linux离线(zip方式)安装docker
目录 基础信息操作系统信息docker信息 安装实例安装步骤示例 遇到的问题问题1:修改默认工作路径启动失败问题2 找不到对应组 基础信息 操作系统信息 OS版本:CentOS 7 64位 内核版本:3.10.0 相关命令: uname -rcat /etc/os-rele…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...
基于Springboot+Vue的办公管理系统
角色: 管理员、员工 技术: 后端: SpringBoot, Vue2, MySQL, Mybatis-Plus 前端: Vue2, Element-UI, Axios, Echarts, Vue-Router 核心功能: 该办公管理系统是一个综合性的企业内部管理平台,旨在提升企业运营效率和员工管理水…...
Linux-进程间的通信
1、IPC: Inter Process Communication(进程间通信): 由于每个进程在操作系统中有独立的地址空间,它们不能像线程那样直接访问彼此的内存,所以必须通过某种方式进行通信。 常见的 IPC 方式包括&#…...