【Python从入门到进阶】51、电影天堂网站多页面下载实战
接上篇《50、当当网Scrapy项目实战(三)》
上一篇我们讲解了使用Scrapy框架在当当网抓取多页书籍数据的效果,本篇我们来抓取电影天堂网站的数据,同样采用Scrapy框架多页面下载的模式来实现。
一、抓取需求
打开电影天堂网站(https://dy2018.com/),点击最新电影的更多页面(https://www.dy2018.com/html/gndy/dyzz/index.html),这里需要抓取最新电影的名字,以及详情页的图片:

要完成这个目标,我们需要造Scrapy框架中封装一个里外嵌套的item对象。下面我们来进行开发。
二、创建工程及爬虫文件
首先我们打开编辑器,打开控制台,进入爬虫文件夹,使用“scrapy startproject 项目名”指令,来创建我们的爬虫工程: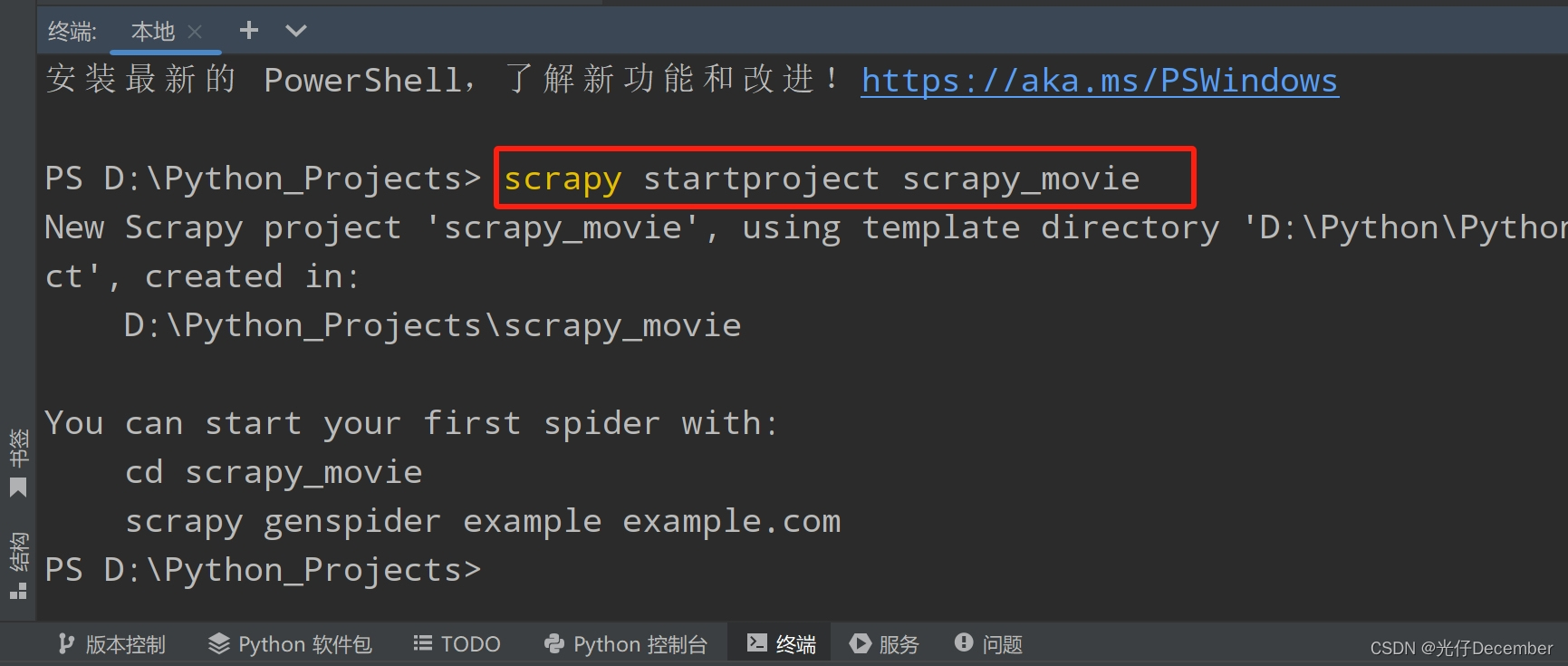

然后进入配置文件settings.py,设置ROBOTSTXT_OBEY参数为false,即不遵循robots协议。
然后进入工程文件的spiders文件夹下,使用“scrapy genspider 爬虫文件名 爬取路径”创建我们的爬虫文件,这里我命名爬虫文件为“movies”: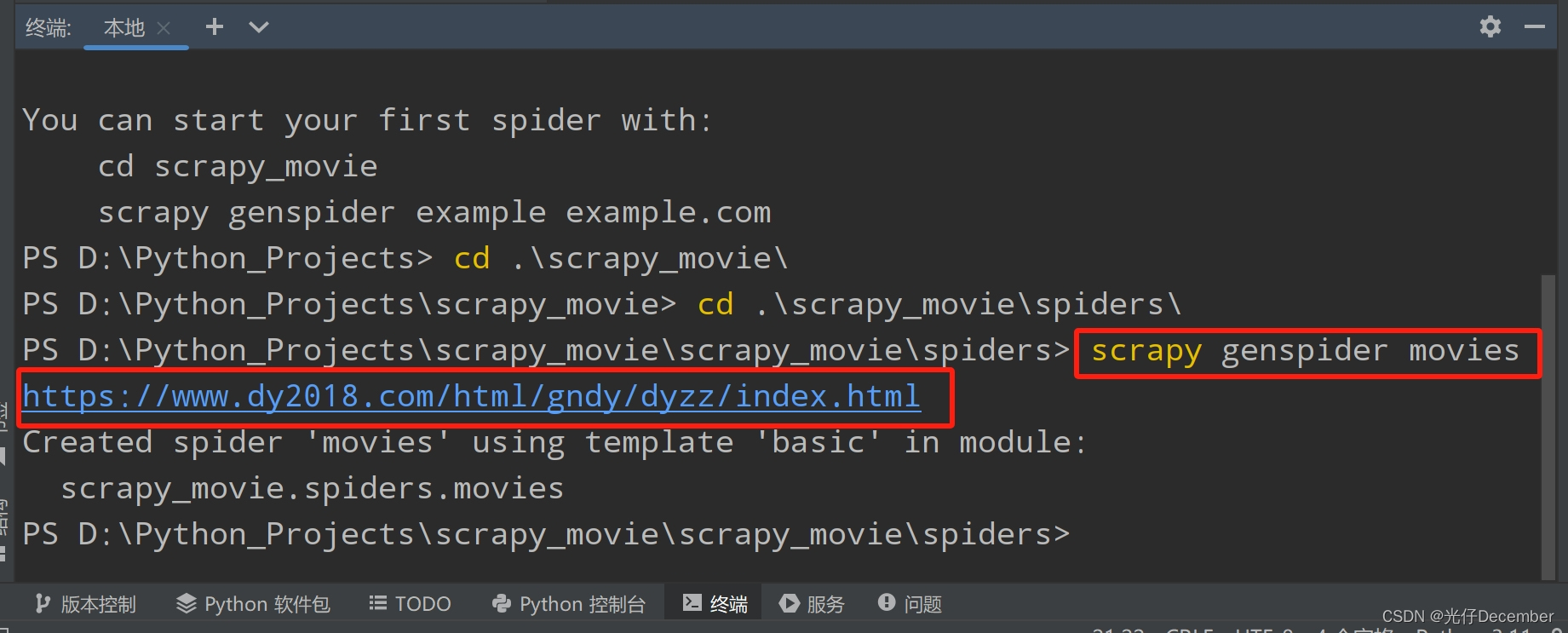

三、编写爬虫逻辑
默认生成的spider爬虫代码如下:
import scrapyclass MoviesSpider(scrapy.Spider):name = "movies"allowed_domains = ["www.dy2018.com"]start_urls = ["https://www.dy2018.com/html/gndy/dyzz/index.html"]def parse(self, response):pass我们把其中的“pass”替换为“print("=============")”,使用“scrapy crawl 爬虫文件名”执行该爬虫:
可以看到正常输出了我们打印的等于号,可以证明网站并没有设置反爬虫。下面我们来编写实际内容,首先我们先定义我们最终要包装成的item对象:
import scrapyclass ScrapyMovieItem(scrapy.Item):name = scrapy.Field()src = scrapy.Field()这里我们主要定义了两个参数,一个是电影名字name,一个是电影封面地址src。
然后我们回到电影天堂列表界面,F12查看电影名字的Html代码:
可以看到是由td包裹的标签,其中a标签中的内容即为电影名字,其中的href参数为电影的详情页面地址。
然后邮件Html中的电影名所在标签,使用xpath工具,获取到电影名字的xpath路径:
xpath地址为:
/html/body/div/div/div[3]/div[6]/div[2]/div[2]/div[2]/ul/table[1]/tbody/tr[2]/td[2]/b/a这里full xpath获取的地址太长,我们再观察一下,发在它是在class为co_content8的div下面的: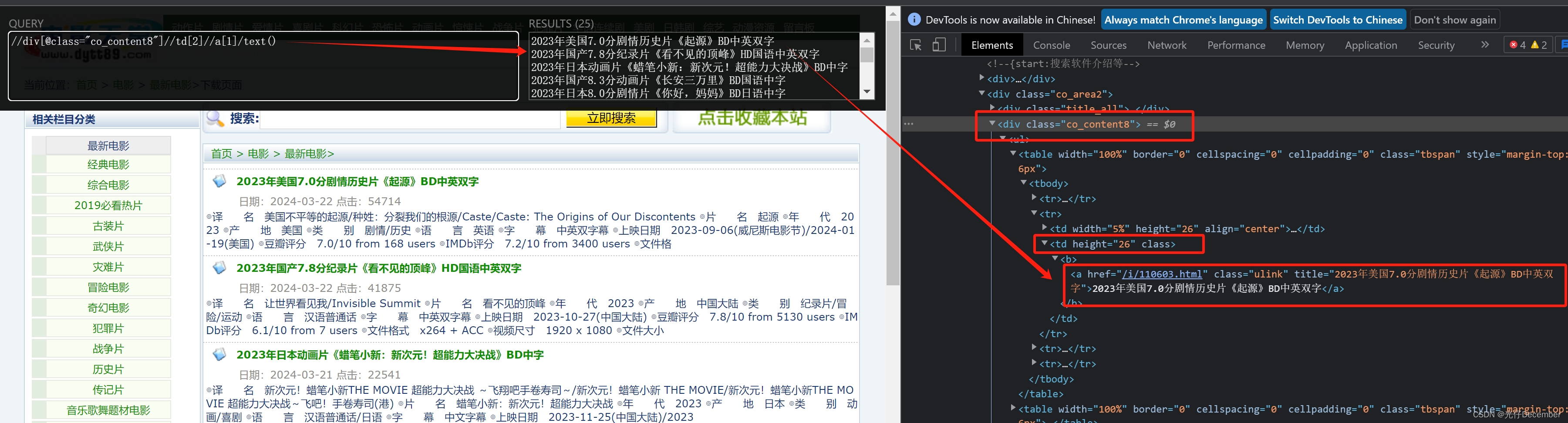
xpath地址可以缩减为:
(1)电影名称
//div[@class="co_content8"]//td[2]//a[1]/text()(2)详情地址
//div[@class="co_content8"]//td[2]//a[1]/@href所以爬虫代码可以编写为:
import scrapyclass MoviesSpider(scrapy.Spider):name = "movies"allowed_domains = ["www.dy2018.com"]start_urls = ["https://www.dy2018.com/html/gndy/dyzz/index.html"]def parse(self, response):# 抓取电影名称以及详情页的封面a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[1]')for a in a_list:# 获取第一页的name和要点击的详情链接地址name = a.xpath('./text()').extract_first()href = a.xpath('./@href').extract_first()print(name,href)执行一下爬虫,可以看到能拿到相应结果: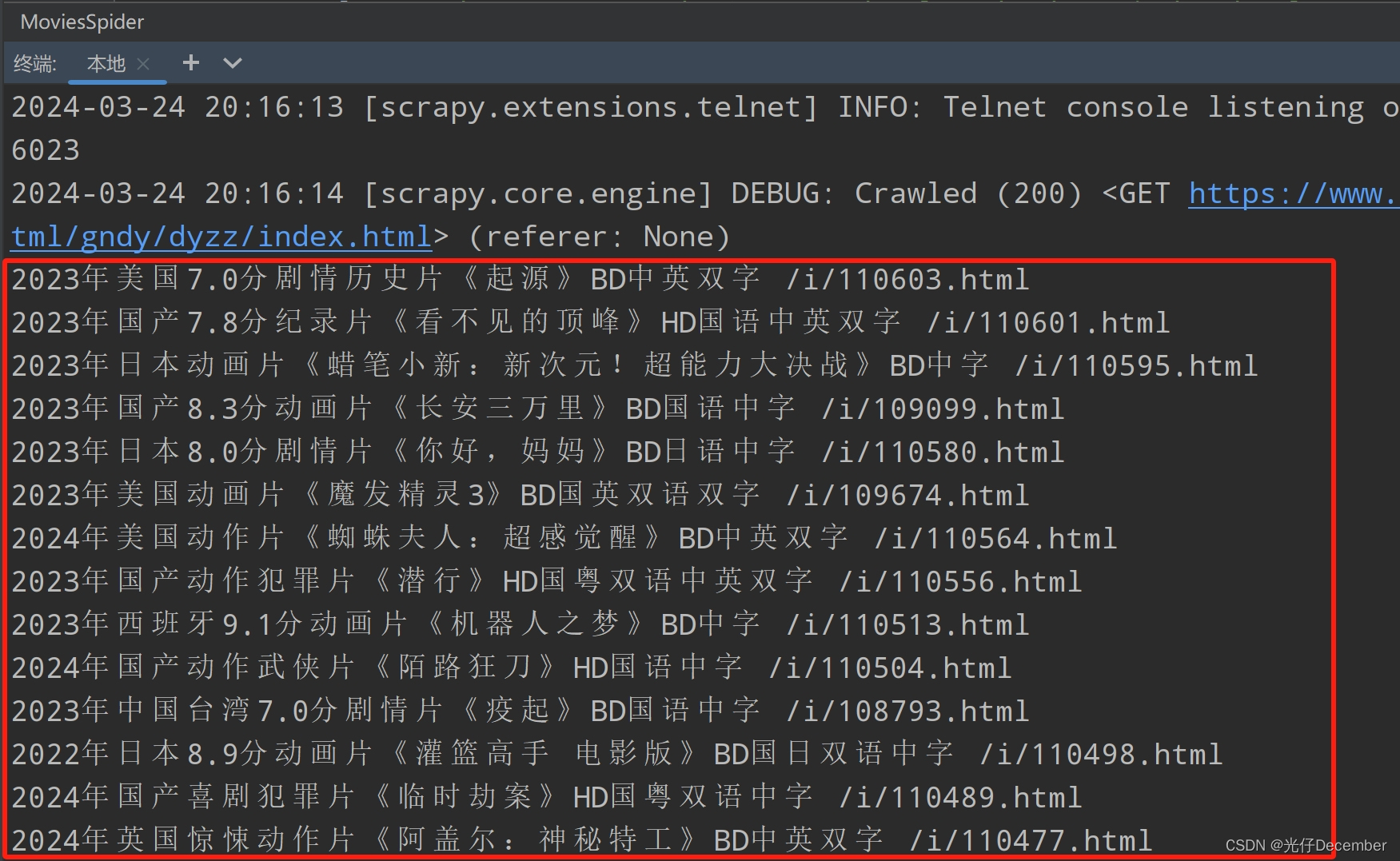
然后完善详情界面的地址,进入详情地址,然后获取详情页的图片:
import scrapyclass MoviesSpider(scrapy.Spider):name = "movies"allowed_domains = ["www.dy2018.com"]start_urls = ["https://www.dy2018.com/html/gndy/dyzz/index.html"]def parse(self, response):# 抓取电影名称以及详情页的封面a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[1]')for a in a_list:# 获取第一页的name和要点击的详情链接地址name = a.xpath('./text()').extract_first()href = a.xpath('./@href').extract_first()# 拼接得到详情页地址url = 'https://www.dy2018.com'+href# 对第二页的链接发起访问yield scrapy.Request(url=url, callback=self.parse_second, meta={'name': name})def parse_second(self, response):print("第二个解析方法")这里我们执行了第二个解析方法,并在下面定义了这个方法“parse_second”,并在上一个函数中,将name作为meta参数带入进去。
此时我们去电影天堂网站打开第一个电影的详情页,右键或F12查看电影封面:
可以大致推断出封面路径的xpath地址为:
//div[@id="Zoom"]//img[1]/@src所以解析详情图片的代码为(ScrapyMovieItem需要import一下):
def parse_second(self, response):src = response.xpath('//div[@id="Zoom"]//img[1]/@src').extract_first()# 获取上一步得到的meta参数中的namename = response.meta['name']movie = ScrapyMovieItem(name=name, src=src)yield movie最后将封装好的movie对象返回给管道。完整代码:
import scrapyfrom scrapy_movie.items import ScrapyMovieItemclass MoviesSpider(scrapy.Spider):name = "movies"allowed_domains = ["www.dy2018.com"]start_urls = ["https://www.dy2018.com/html/gndy/dyzz/index.html"]def parse(self, response):# 抓取电影名称以及详情页的封面a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[1]')for a in a_list:# 获取第一页的name和要点击的详情链接地址name = a.xpath('./text()').extract_first()href = a.xpath('./@href').extract_first()# 拼接得到详情页地址url = 'https://www.dy2018.com' + href# 对第二页的链接发起访问yield scrapy.Request(url=url, callback=self.parse_second, meta={'name': name})def parse_second(self, response):src = response.xpath('//div[@id="Zoom"]//img[1]/@src').extract_first()# 获取上一步得到的meta参数中的namename = response.meta['name']print(name, src)movie = ScrapyMovieItem(name=name, src=src)yield movie四、开启并定义管道
此时我们前往settings.py开启管道(将ITEM_PIPELINES注释取消即可):
ITEM_PIPELINES = {"scrapy_movie.pipelines.ScrapyMoviePipeline": 300,
}然后打开pipelines.py,编写一段逻辑,将获取的电影名字和封面地址写入一个json文件中:
# 如果需要使用管道,要在setting.py中打开ITEM_PIPELINES参数
class ScrapyMoviePipeline:# 1、在爬虫文件开始执行前执行的方法def open_spider(self, spider):print('++++++++爬虫开始++++++++')# 这里写入文件需要用'a'追加模式,而不是'w'写入模式,因为写入模式会覆盖之前写的self.fp = open('movies.json', 'a', encoding='utf-8') # 打开文件写入# 2、爬虫文件执行时,返回数据时执行的方法# process_item函数中的item,就是爬虫文件yield的movie对象def process_item(self, item, spider):# write方法必须写一个字符串,而不能是其他的对象self.fp.write(str(item)) # 将爬取信息写入文件return item# 在爬虫文件开始执行后执行的方法def close_spider(self, spider):print('++++++++爬虫结束++++++++')self.fp.close() # 关闭文件写入五、执行测试
编写完item、spider、pipeline之后,我们运行爬虫,查看输出的json文件: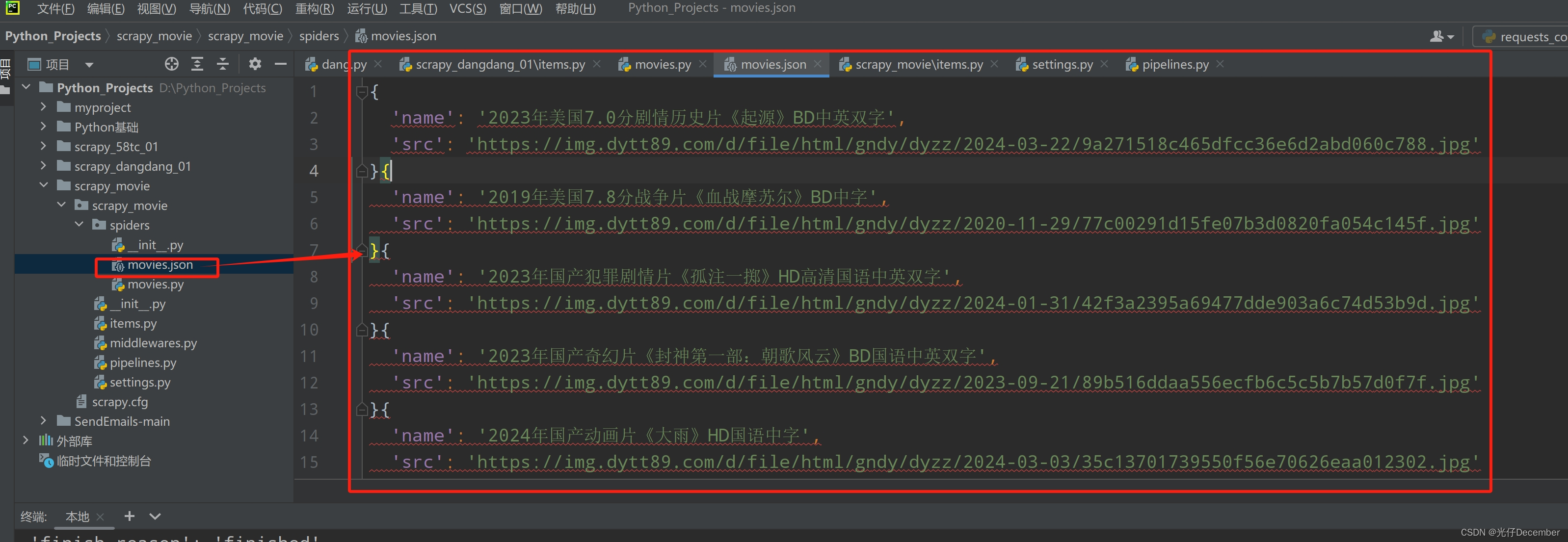
可以看到完整获取电影的名称以及封面图片的下载地址。
以上就是电影天堂网站多页面下载的实战内容。下一篇我们来讲解scrapy中链接提取器的使用。
参考:尚硅谷Python爬虫教程小白零基础速通
转载请注明出处:https://guangzai.blog.csdn.net/article/details/136994919
相关文章:
【Python从入门到进阶】51、电影天堂网站多页面下载实战
接上篇《50、当当网Scrapy项目实战(三)》 上一篇我们讲解了使用Scrapy框架在当当网抓取多页书籍数据的效果,本篇我们来抓取电影天堂网站的数据,同样采用Scrapy框架多页面下载的模式来实现。 一、抓取需求 打开电影天堂网站&…...
苹果CMS影视APP源码,二开版本带视频教程
编译app教程 工具下载:Android Studio 官网地址:https://developer.android.google.cn/studio/ 环境设置: 设置中文:https://blog.csdn.net/qq_37131111/article/details/131492844 汉化包找最新的下载就行了,随便下载…...

Zigbee技术在智能农业领域的应用研究
Zigbee技术在智能农业领域的应用研究 **摘要:**随着现代信息技术的飞速发展,智能农业已成为当今农业发展的新趋势。Zigbee技术作为一种低功耗、低成本的无线通信技术,在智能农业领域具有广泛的应用前景。本文深入分析了Zigbee技术的原理和特…...

Spring Cloud Gateway 中GET请求能正常访问,POST请求出现Unable to handle DataBuffer
报错信息如下: java.lang.IllegalArgumentException: Unable to handle DataBuffer of type class org.springframework.http.server.reactive.UndertowServerHttpRequest$UndertowDataBufferat org.springframework.cloud.gateway.filter.NettyRoutingFilter.getB…...

什么是git? 初步认识git 如何使用git
Git是什么? Git 是分布式版本控制系统,可以有效,高速地处理从很小到非常大地项目版本管理,分布式相比于集中式的最大区别在于开发者可以提交到本地,每个开发者可以通过克隆,在本地机器上拷贝一个完整的Git …...
Douyin视频详情数据API接口(视频详情,评论)
抖音官方并没有直接提供公开的视频详情数据采集API接口给普通用户或第三方开发者。抖音的数据采集通常受到严格的限制,以保护用户隐私和平台安全。 请求示例,API接口接入Anzexi58 如果您需要获取抖音视频详情数据,包括评论、点赞等ÿ…...
MySQL 索引:索引为什么使用 B+树?
Hash 索引不支持顺序和范围查询; 二叉查找树(BST):解决了排序的问题,极端情况下可能会退化成线性链表,查询效率急剧下降; 平衡二叉树(AVL) :通过旋转解决了平衡的问题,但是旋转操作效率太低&am…...

2024年第四届天府杯全国大学生数学建模竞赛B题思路
B题:新质生产力引领下的企业生产与发展策略优化 问题背景 随着技术的飞速发展,新质生产力如人工智能、大数据分析、物联网等技术被广泛应用于生产和服务过程中,极大地提高了生产效率和产品质量,改变了传统的生产与经营模式。一家…...

c++部分题
const关键字与宏定义的区别是什么? const关键字和宏定义在功能上有相似之处,但在实现和使用上有很大的区别。 作用域和类型安全性: const关键字定义的常量具有作用域和类型安全性。它们的作用域仅限于声明它们的块,并且在编译时会…...

验证回文串
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。 字母和数字都属于字母数字字符。 给定一个字符串 s,如果它是 回文串 ,返回 true ;否则&#…...
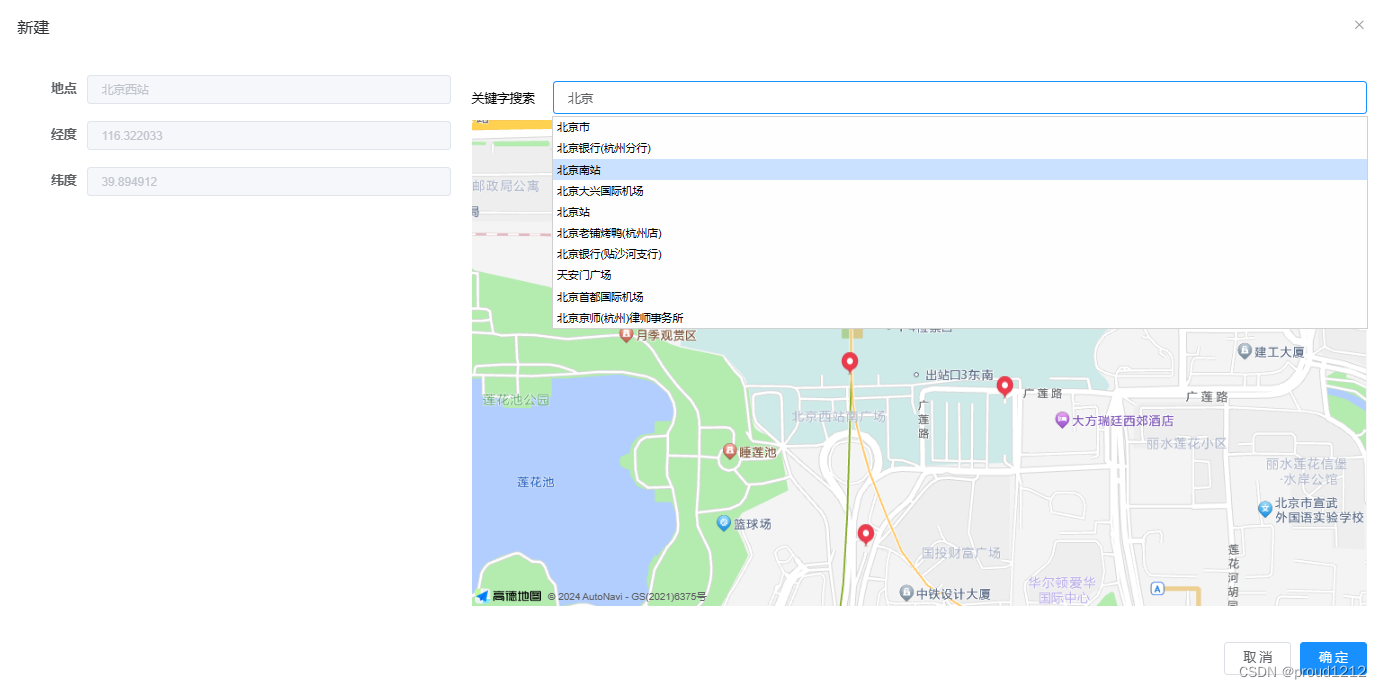
vue2高德地图选点
<template><el-dialog :title"!dataForm.id ? 新建 : isDetail ? 详情 : 编辑" :close-on-click-modal"false" :visible.sync"show" class"rv-dialog rv-dialog_center" lock-scroll width"74%" :before-close&q…...

Gitflow:一种依据 Git 构建的分支管理工作流程模式
文章目录 前言Gitflow 背景Gitflow 中的分支模型Gitflow 的版本号管理简单模拟 Gitflow 工作流 前言 Gitflow 工作流是一种版本控制流程,主要适用于较大规模的团队。这个流程在团队中进行合作时可以避免冲突,并能快速地完成项目,因此在很多软…...

利用云手机技术,开拓海外社交市场
近年来,随着科技的不断进步,云手机技术逐渐在海外社交营销领域崭露头角。其灵活性、成本效益和全球性特征使其成为海外社交营销的利器。那么,究竟云手机在海外社交营销中扮演了怎样的角色呢? 首先,云手机技术能够消除地…...
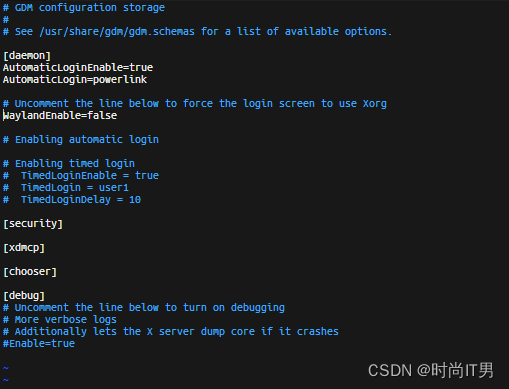
脚本实现Ubuntu设置屏幕无人操作,自动黑屏
使用 xrandr 命令可以实现对屏幕的控制,包括调整分辨率、旋转屏幕以及关闭屏幕等。要实现 Ubuntu 设置屏幕在无人操作一段时间后自动黑屏,非待机,并黑屏后点击触摸屏可以唤醒屏幕,可以借助 xrandr 命令来实现。 首先,…...

16.JRE和JDK
程序员在编写代码的时候其实是需要一些环境,例如我们之前写的HelloWorld。我们需要的东西有JVM、核心类库、开发工具。 1、JVM(Java Virtual Machine):Java虚拟机,真正运行Java程序的地方。没有虚拟机,代码…...

C++从入门到精通——命名空间
命名空间 前言一、命名空间引例什么是命名空间 二、命名空间定义正常的命名空间定义嵌套的命名空间多个相同名称的命名空间 三、命名空间使用加命名空间名称及作用域限定符使用using将命名空间中某个成员引入使用using namespace 命名空间名称引用引用命名空间和引用头文件有什…...

JAVA面试大全之JAVA新特性篇
目录 1、Java 8特性 1.1、什么是函数式编程?Lambda表达式? 1.2、Stream中常用方法? 1.3、什么是FunctionalInterface? 1.4、如何自定义函数接口?...
)
【ZZULIOJ】1008: 美元和人民币(Java)
目录 题目描述 输入 输出 样例输入 Copy 样例输出 Copy code 题目描述 美元越来越贬值了,手上留有太多的美元似乎不是件好事。赶紧算算你的那些美元还值多少人民币吧。假设美元与人民币的汇率是1美元兑换6.5573元人民币,编写程序输入美元的金额&a…...
)
LeetCode刷题笔记之动态规划(三)
一、子序列/子数组问题 子序列:按原数组的顺序排列,不一定是原数组中的相邻元素组成的。即子序列可以是不连续的。 子数组:原数组中连续的几个元素组成的数组。 1. 300【最长递增子序列】 题目: 给你一个整数数组 nums ÿ…...
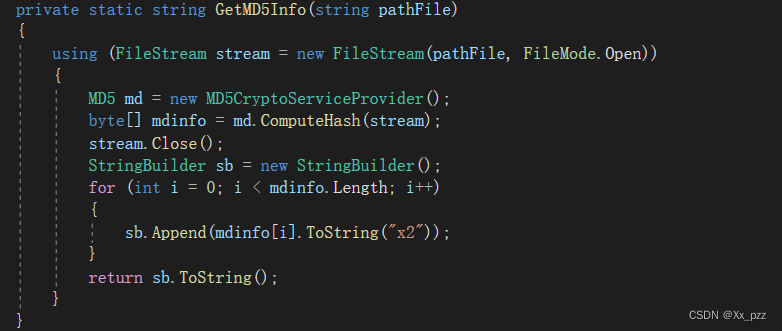
Unity编辑器功能将AB资源文件生成MD5码
将路径Application.dataPath/ArtRes/AB/PC文件夹下所有的Ab包文件生成MD5吗,通过文件名 文件长度MD5‘|’的格式拼接成字符串写入到资源对比文件abCompareInfo.txt中。 将路径pathFile扥文件生成MD5码...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...

SQL Server 触发器调用存储过程实现发送 HTTP 请求
文章目录 需求分析解决第 1 步:前置条件,启用 OLE 自动化方式 1:使用 SQL 实现启用 OLE 自动化方式 2:Sql Server 2005启动OLE自动化方式 3:Sql Server 2008启动OLE自动化第 2 步:创建存储过程第 3 步:创建触发器扩展 - 如何调试?第 1 步:登录 SQL Server 2008第 2 步…...
0609)
书籍“之“字形打印矩阵(8)0609
题目 给定一个矩阵matrix,按照"之"字形的方式打印这个矩阵,例如: 1 2 3 4 5 6 7 8 9 10 11 12 ”之“字形打印的结果为:1,…...

【题解-洛谷】P10480 可达性统计
题目:P10480 可达性统计 题目描述 给定一张 N N N 个点 M M M 条边的有向无环图,分别统计从每个点出发能够到达的点的数量。 输入格式 第一行两个整数 N , M N,M N,M,接下来 M M M 行每行两个整数 x , y x,y x,y,表示从 …...