阿里云CentOS7安装Hadoop3伪分布式
ECS准备
开通阿里云ECS
略
控制台设置密码
连接ECS
远程连接工具连接阿里云ECS实例,这里远程连接工具使用xshell

根据提示接受密钥

根据提示写用户名和密码
用户名:root
密码:在控制台设置的密码
修改主机名
将主机名从localhost改为需要的主机名,例如:node1
[root@iZwz9hpiui8zhoe2pkat8nZ ~]# hostnamectl set-hostname node1 [root@iZwz9hpiui8zhoe2pkat8nZ ~]# hostname node1
发现未重启时,命令行@后面显示的主机名未变
重启 [root@iZwz9hpiui8zhoe2pkat8nZ ~]# reboot 重新连接 [root@node1 ~]#
重启后,命令行中的主机名改变了
创建普通用户
因为root用户权限太高,误操作可能造成一些麻烦。一般情况下,我们不会用root用户来安装hadoop,所以我们需要创建普通用户来安装hadoop。
创建新用户方法如下:
创建新用户,例如用户名为:hadoop,并设置新用户密码,重复设置2次,看不到输入的密码,这是linux的安全机制,输入即可。
[root@node1 ~]# adduser hadoop [root@node1 ~]# passwd hadoop Changing password for user hadoop. New password: BAD PASSWORD: The password is shorter than 8 characters Retype new password: passwd: all authentication tokens updated successfully.
给普通用户添加sudo执行权限
[root@node1 ~]# chmod -v u+w /etc/sudoers mode of ‘/etc/sudoers’ changed from 0440 (r--r-----) to 0640 (rw-r-----) [root@node1 ~]# vim /etc/sudoers 在%wheel ALL=(ALL) ALL一行下面添加如下语句: hadoop ALL=(ALL) ALL [root@node1 ~]# chmod -v u-w /etc/sudoers mode of ‘/etc/sudoers’ changed from 0640 (rw-r-----) to 0440 (r--r-----)
这种情况下,执行sudo相关命令时,需要输入当前普通用户的密码。
如果不想输入密码,在%wheel ALL=(ALL) ALL一行下面添加的语句更改为如下:
hadoop ALL=(ALL) NOPASSWD:ALL
关闭root连接
普通用户登录
使用xshell新建一个连接,
用户名:hadoop
密码:创建hadoop用户时设置的密码
映射IP和主机
[hadoop@node1 ~]$ sudo vim /etc/hosts
文件末尾一行,将ECS内网IP与实际的主机名node1映射,修改如下内容:
192.168.0.100 node1

注意:192.168.0.100为ECS内网IP,ECS内网IP可以在阿里云控制台查询,请根据实际情况设置。
配置免密登录
生成密钥对
ssh-keygen -t rsa
执行命令后,连续敲击三次回车键,运行过程如下:
[hadoop@node1 ~]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa. Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub. The key fingerprint is: SHA256:F7ztwW9iUTYORd3jGBD46lvznVHbxe0jZcAHeI7kVRk hadoop@node1 The key's randomart image is: +---[RSA 2048]----+ | .o+o+E+| | o o.=.oo| | * *oB..| | O Bo+.| | S + = .o=| | o . +o.=| | . o+.o+o| | ...ooo +| | .. . o | +----[SHA256]-----+
拷贝公钥
ssh-copy-id node1
安装jdk
创建安装包目录
创建一个目录,专门存放安装包(可选)
[hadoop@node1 ~]$ mkdir ~/installfile
下载jdk8安装包
官网下载jdk安装包:jdk-8u271-linux-x64.tar.gz,并将安装包上传到Linux的installfile目录。
解压安装包
解压安装包
[hadoop@node1 installfile]$ tar -zxvf jdk-8u271-linux-x64.tar.gz -C ~/soft
切换到soft目录,查看解压后的文件
[hadoop@node1 softinstall]$ cd ~/soft [hadoop@node1 soft]$ ls jdk1.8.0_271
配置环境变量
[hadoop@node1 soft]$ sudo nano /etc/profile.d/my_env.sh
内容如下
export JAVA_HOME=/home/hadoop/soft/jdk1.8.0_271 export PATH=$PATH:$JAVA_HOME/bin
让配置立即生效
[hadoop@node1 soft]$ source /etc/profile
验证版本号
[hadoop@node1 soft]$ java -version java version "1.8.0_271" Java(TM) SE Runtime Environment (build 1.8.0_271-b09) Java HotSpot(TM) 64-Bit Server VM (build 25.271-b09, mixed mode)
看到输出java version "1.8.0_271",说明jdk安装成功。
遇到的问题
验证java版本号时,遇到找不到libjli.so的问题
[hadoop@node1 ~]$ java -version java: error while loading shared libraries: libjli.so: cannot open shared object file: No such file or directory
排查问题,发现解压jdk包时出现了错误,造成该问题
jdk1.8.0_271/jre/lib/ jdk1.8.0_271/jre/lib/amd64/ jdk1.8.0_271/jre/lib/amd64/server/ jdk1.8.0_271/jre/lib/amd64/server/Xusage.txt jdk1.8.0_271/jre/lib/amd64/server/libjvm.so tar: Skipping to next header gzip: stdin: invalid compressed data--format violated tar: Child returned status 1 tar: Error is not recoverable: exiting now
重新上传jdk安装包,确保文件完整,然后再重新解压,解压正常,版本号验证正常。
安装hadoop伪分布式
下载hadoop
[hadoop@node1 soft]$ cd ~/softinstall/ [hadoop@node1 soft]$ wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz [hadoop@node1 softinstall]$ ls hadoop-3.3.4.tar.gz jdk-8u271-linux-x64.tar.gz
解压hadoop
[hadoop@node1 softinstall]$ tar -zxvf hadoop-3.3.4.tar.gz -C ~/soft
配置环境变量
[hadoop@node1 softinstall]$ sudo nano /etc/profile.d/my_env.sh
在文件末尾添加如下配置
export HADOOP_HOME=/home/hadoop/soft/hadoop-3.3.4 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
让环境变量生效
[hadoop@node1 softinstall]$ source /etc/profile
验证版本号
执行hadoop version命令,能看到Hadoop 3.3.4版本号,说明环境变量配置成功。
[hadoop@node1 softinstall]$ hadoop version Hadoop 3.3.4 Source code repository https://github.com/apache/hadoop.git -r a585a73c3e02ac62350c136643a5e7f6095a3dbb Compiled by stevel on 2022-07-29T12:32Z Compiled with protoc 3.7.1 From source with checksum fb9dd8918a7b8a5b430d61af858f6ec This command was run using /home/hadoop/soft/hadoop-3.3.4/share/hadoop/common/hadoop-common-3.3.4.jar
配置hadoop
进入配置目录
[hadoop@node1 softinstall]$ cd $HADOOP_HOME/etc/hadoop
配置core-site.xml
[hadoop@node1 hadoop]$ vim core-site.xml
在<configuration> 和</configuration>之间添加如下内容:
<!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://node1:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/home/hadoop/soft/hadoop-3.3.4/data</value></property> <!-- 配置HDFS网页登录使用的静态用户为hadoop,value里的hadoop代表用户 --><property><name>hadoop.http.staticuser.user</name><value>hadoop</value></property> <!-- 配置该hadoop(superUser)(第二个hadoop代表用户)允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property><!-- 配置该hadoop(superUser)(第二个hadoop代表用户)允许通过代理用户所属组 --><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property><!-- 配置该hadoop(superUser)(第二个hadoop代表用户)允许通过代理的用户--><property><name>hadoop.proxyuser.hadoop.users</name><value>*</value></property>
配置hdfs-site.xml
[hadoop@node1 hadoop]$ nano hdfs-site.xml
在<configuration> 和</configuration>之间添加如下内容:
<!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>node1:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>node1:9868</value></property><!-- HDFS副本的数量1 --><property><name>dfs.replication</name><value>1</value></property>
注意:node1为ECS的主机名称,注意根据实际情况修改,之后的配置文件node1也需要注意修改。
配置yarn-site.xml
[hadoop@node1 hadoop]$ nano yarn-site.xml
在<configuration> 和</configuration>之间添加如下内容:
<!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>node1</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!--yarn单个容器允许分配的最大最小内存 --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value></property><!-- yarn容器允许管理的物理内存大小 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><!-- 关闭yarn对物理内存和虚拟内存的限制检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>true</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
配置mapred-site.xml
[hadoop@node1 hadoop]$ nano mapred-site.xml
在<configuration> 和</configuration>之间添加如下内容:
<!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
配置workers
[hadoop@node1 hadoop]$ nano workers
删除原有内容,配置workers的主机名称,内容如下
node1
配置历史服务器
[hadoop@node1 hadoop]$ nano mapred-site.xml
添加如下配置
<!-- 历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value></property> <!-- 历史服务器web端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value></property>
配置日志聚集
开启日志聚集功能,应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
[hadoop@node1 hadoop]$ nano yarn-site.xml
添加如下功能
<!-- 开启日志聚集功能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property> <!-- 设置日志聚集服务器地址 --><property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs</value></property> <!-- 设置日志保留时间为7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
格式化
格式化hdfs文件系统
[hadoop@node1 hadoop]$ hdfs namenode -format
部分输出如下
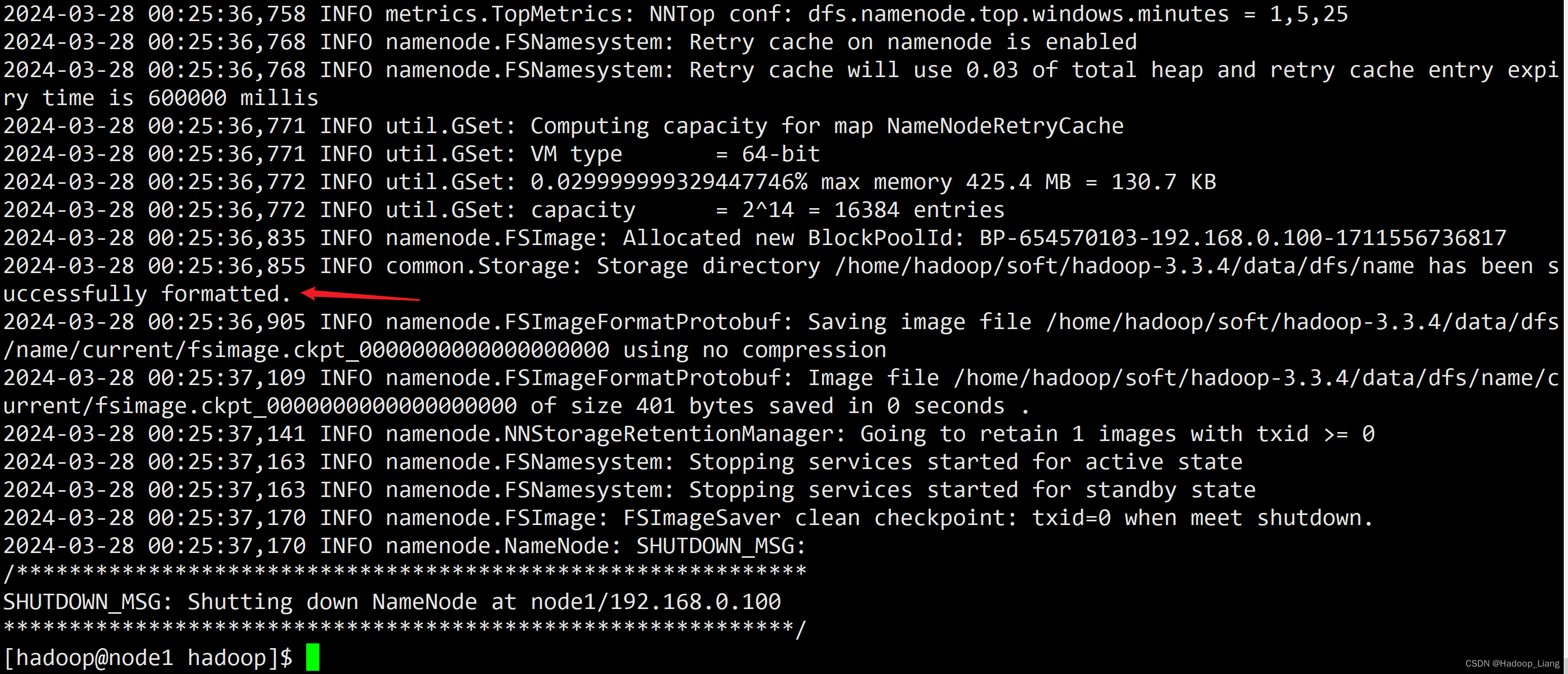
看到successfully formatted.说明格式化成功。
注意:格式化只能进行一次。
启动集群
[hadoop@node1 hadoop]$ start-dfs.sh [hadoop@node1 hadoop]$ start-yarn.sh
查看进程
[hadoop@node1 hadoop]$ jps 16944 DataNode 18818 Jps 17413 ResourceManager 17144 SecondaryNameNode 17513 NodeManager 16844 NameNode
看到如上进程,说明正常。
如果缺少进程:
1.检查配置是否正确;
2.查看对应$HADOOP_HOME/logs目录对应进程log文件的报错信息来解决。
放开Web UI端口
登录阿里云控制台,在安全组放开9870、8088、9868端口

注意:0.0.0.0/0代表所有ip均能访问,不安全。可以只授权给特定ip,例如自己当前电脑的公网ip地址,一般情况下,当前电脑的公网ip会变化,变化后就需要重新查询当前电脑的公网ip,再重新设置授权对象。
访问Web UI
浏览器访问
公网IP:9870

公网IP:8088

公网IP:9868

如果不想输入公网ip,可以在windows的hosts文件做映射:
公网IP node1 alinode
含义:公网IP映射的主机为node1,alinode为node1机器的别名。
使用node1或者alinode代替公网IP,访问相关端口,也能正常访问如下:

完成!enjoy it!
相关文章:
阿里云CentOS7安装Hadoop3伪分布式
ECS准备 开通阿里云ECS 略 控制台设置密码 连接ECS 远程连接工具连接阿里云ECS实例,这里远程连接工具使用xshell 根据提示接受密钥 根据提示写用户名和密码 用户名:root 密码:在控制台设置的密码 修改主机名 将主机名从localhost改为需要…...

78.子集90.子集2
78.子集 思路 又回到了组合的模板中来,这道题相比于前面的题省去了递归终止条件。大差不差。 代码 class Solution {List<List<Integer>> result new ArrayList<>();LinkedList<Integer> listnew LinkedList<>();public List<…...

基于Ubuntu的Linux系统安装jsoncpp开发包过程
执行以下命令: sudo apt update sudo apt install libjsoncpp-dev有可能出现的问题: 1.如果在执行sudo apt update时出现以下信息 Hit:1 http://mirrors.aliyun.com/ubuntu bionic InRelease Hit:2 http://mirrors.aliyun.com/ubuntu bionic-security…...

葵花卫星影像应用场景及数据获取
一、卫星参数 葵花卫星是由中国航天科技集团公司研制的一颗光学遥感卫星,代号CAS-03。该卫星于2016年11月9日成功发射,位于地球同步轨道,轨道高度约为35786公里,倾角为0。卫星设计寿命为5年,搭载了高分辨率光学相机和多…...
Jenkins升级中的小问题
文章目录 使用固定版本安装根据jenkins页面下载war包升级jenkins重启jenkins报错问题解决 K8s部署过程中的一些小问题 ##### Jenkins版本小插曲 在Jenkins环境进行插件安装时全部清一色飘红,发现是因为Jenkins版本过低导致,报错的位置可以找到更新je…...

Apache Hive的基本使用语法(二)
Hive SQL操作 7、修改表 表重命名 alter table score4 rename to score5;修改表属性值 # 修改内外表属性 ALTER TABLE table_name SET TBLPROPERTIES("EXTERNAL""TRUE"); # 修改表注释 ALTER TABLE table_name SET TBLPROPERTIES (comment new_commen…...

基于单片机16位智能抢答器设计
**单片机设计介绍,基于单片机16位智能抢答器设计 文章目录 一 概要二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 基于单片机16位智能抢答器设计是一个结合了单片机技术、显示技术、按键输入技术以及声音提示技术的综合性项目。其设计…...

idea默认代码生成脚本修改
修改了下idea自带的代码生成脚本,增加了脚本代码的注释,生成了controller,service,impl,mapper,里面都是空的,具体可以根据自己的代码习惯增加 代码生成脚本的使用可以看下使用 idea 生成实体类…...
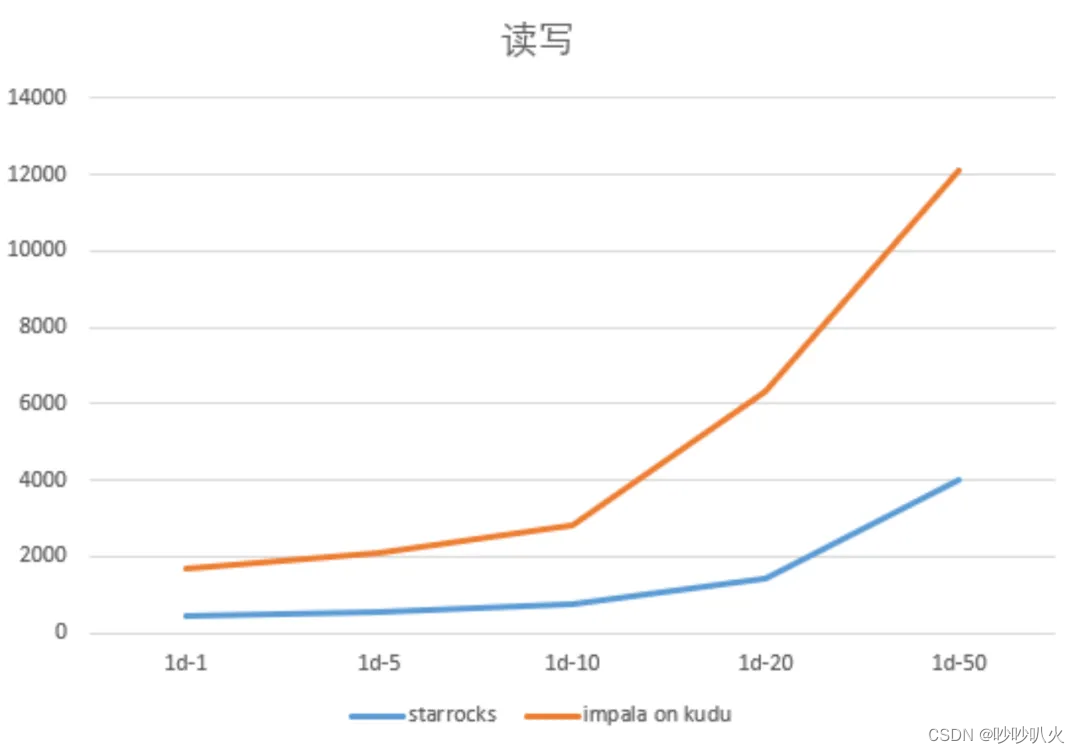
StarRocks实战——多点大数据数仓构建
目录 前言 一、背景介绍 二、原有架构的痛点 2.1 技术成本 2.2 开发成本 2.2.1 离线 T1 更新的分析场景 2.2.2 实时更新分析场景 2.2.3 固定维度分析场景 2.2.4 运维成本 三、选择StarRocks的原因 3.1 引擎收敛 3.2 “大宽表”模型替换 3.3 简化Lambda架构 3.4 模…...
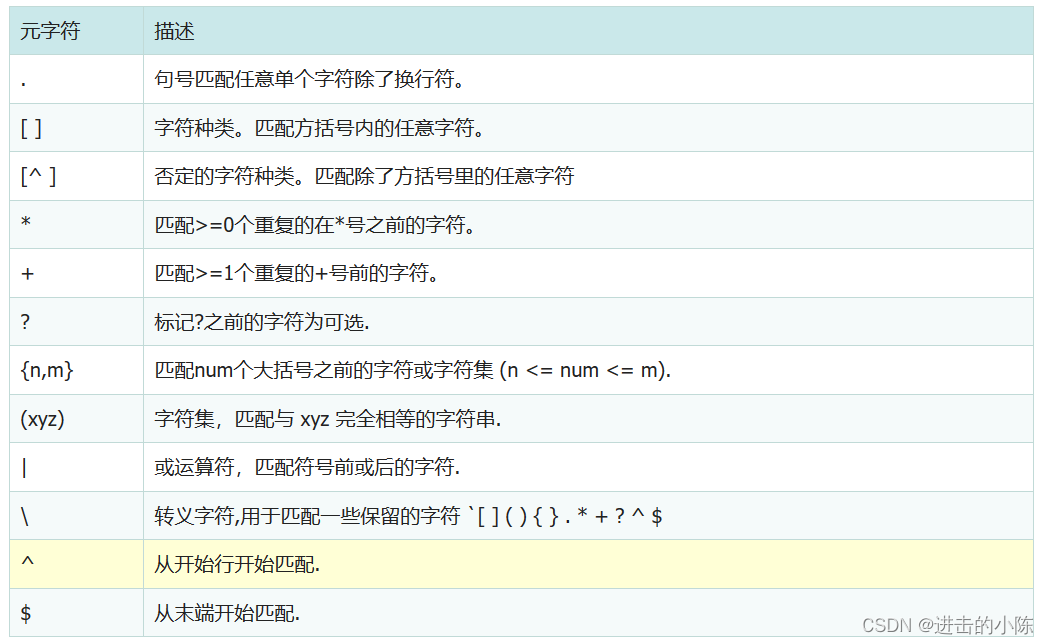
jmeter总结之:Regular Expression Extractor元件
Regular Expression Extractor是一个后处理器元件,使用正则从服务器的响应中提取数据,并将这些数据保存到JMeter变量中,以便在后续的请求或断言中使用。在处理动态数据或验证响应中的特定信息时很有用。 添加Regular Expression Extractor元…...

快速上手Spring Cloud 七:事件驱动架构与Spring Cloud
快速上手Spring Cloud 一:Spring Cloud 简介 快速上手Spring Cloud 二:核心组件解析 快速上手Spring Cloud 三:API网关深入探索与实战应用 快速上手Spring Cloud 四:微服务治理与安全 快速上手Spring Cloud 五:Spring …...

leetcode 1997.访问完所有房间的第一天
思路:动态规划前缀和 这道题还是很难的,因为你如果需要推出状态方程是很难想的。 在题中我们其实可以发现,这里在访问nextVisit数组的过程中,其实就是对于当前访问的房子之前的房子进行了回访。 怎么说呢?比如你现在…...
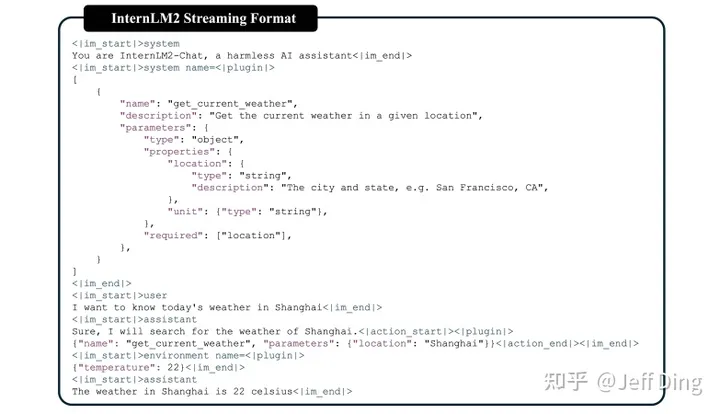
【InternLM 实战营第二期笔记】书生·浦语大模型全链路开源体系及InternLM2技术报告笔记
大模型 大模型成为发展通用人工智能的重要途径 专用模型:针对特定任务,一个模型解决一个问题 通用大模型:一个模型应对多种任务、多种模态 书生浦语大模型开源历程 2023.6.7:InternLM千亿参数语言大模型发布 2023.7.6&#…...
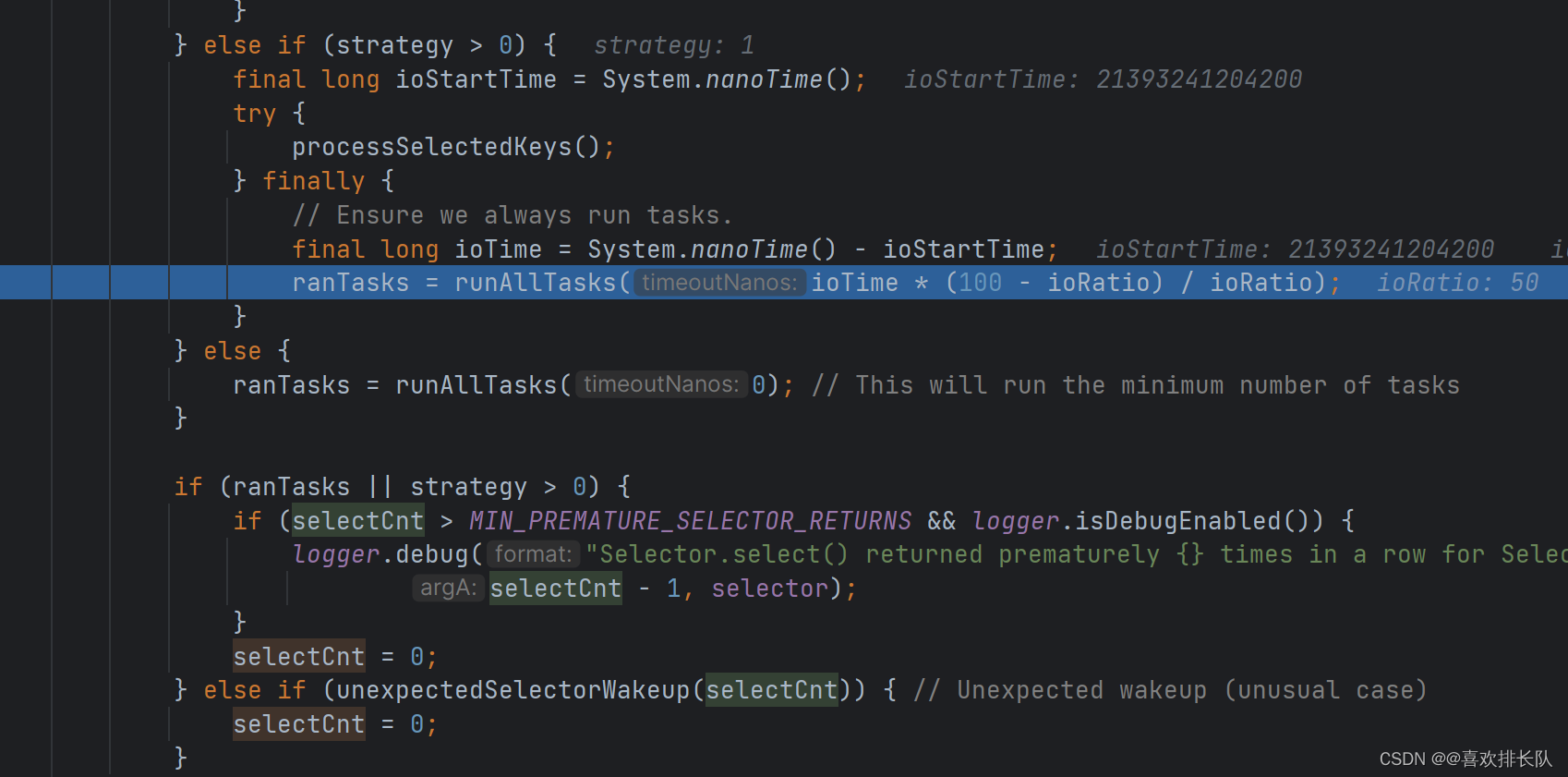
Netty对Channel事件的处理以及空轮询Bug的解决
继续上一篇Netty文章,这篇文章主要分析Netty对Channel事件的处理以及空轮询Bug的解决 当Netty中采用循环处理事件和提交的任务时 由于此时我在客户端建立连接,此时服务端没有提交任何任务 此时select方法让Selector进入无休止的阻塞等待 此时selectCnt进…...

【PostgreSQL】- 1.1 在 Debian 12 上安装 PostgreSQL 15
官方说明参考 (原文 PostgreSQL:Linux 下载 (Debian)) 默认情况下,PostgreSQL 在所有 Debian 版本中都可用。但是, Debians 的稳定版本“快照”了特定版本的 PostgreSQL 然后在该 Debian 版本的…...

第4章.精通标准提示,引领ChatGPT精准输出
标准提示 标准提示,是引导ChatGPT输出的一个简单方法,它提供了一个具体的任务让模型完成。 如果你要生成一篇新闻摘要。你只要发送指示词:汇总这篇新闻 : …… 提示公式:生成[任务] 生成新闻文章的摘要: 任务&#x…...
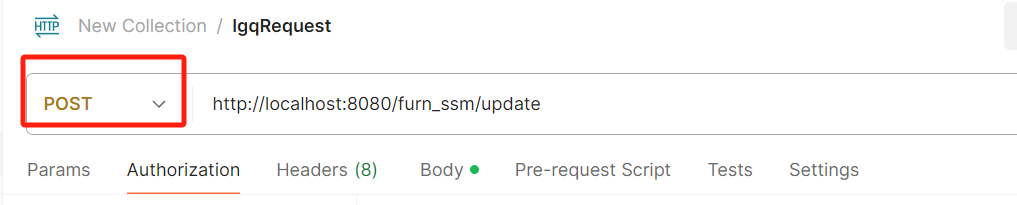
HTTP状态 405 - 方法不允许
方法有问题。 用Post发的请求,然后用Put接收的。 大家也可以看看是不是有这种问题 <body><h1>HTTP状态 405 - 方法不允许</h1><hr class"line" /><p><b>类型</b> 状态报告</p><p><b>消息…...

题目 2898: 二维数组回形遍历
题目描述: 给定一个row行col列的整数数组array,要求从array[0][0]元素开始,按回形从外向内顺时针顺序遍历整个数组。如图所示: 代码: package lanqiao;import java.math.BigInteger; import java.util.*;public class Main {public static …...
Git命令上传本地项目至github
记录如何创建个人仓库并上传已有代码至github in MacOS环境 0. 首先下载git 方法很多 这里就不介绍了 1. Github Create a new repository 先在github上创建一个空仓库,用于一会儿链接项目文件,按照自己的需求设置name和是否private 2.push an exis…...

机器学习之决策树现成的模型使用
目录 须知 DecisionTreeClassifier sklearn.tree.plot_tree cost_complexity_pruning_path(X_train, y_train) CART分类树算法 基尼指数 分类树的构建思想 对于离散的数据 对于连续值 剪枝策略 剪枝是什么 剪枝的分类 预剪枝 后剪枝 后剪枝策略体现之威斯康辛州乳…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...