R语言使用dietaryindex包计算NHANES数据多种营养指数(2)
健康饮食指数 (HEI) 是评估一组食物是否符合美国人膳食指南 (DGA) 的指标。Dietindex包提供用户友好的简化方法,将饮食摄入数据标准化为基于指数的饮食模式,从而能够评估流行病学和临床研究中对这些模式的遵守情况,从而促进精准营养。
该软件包可以计算以下饮食模式指数:
• 2020 年健康饮食指数(HEI2020 和 HEI-Toddlers-2020)
• 2015 年健康饮食指数 (HEI2015)
• 另类健康饮食指数(AHEI)
• 控制高血压指数 (DASH) 的饮食方法
• DASH 试验中的 DASH 份量指数 (DASHI)
• 替代地中海饮食评分 (aMED)
• PREDIMED 试验中的 MED 份量指数 (MEDI)
• 膳食炎症指数 (DII)
• 美国癌症协会 2020 年饮食评分(ACS2020_V1 和 ACS2020_V2)
• EAT-Lancet 委员会 (PHDI) 的行星健康饮食指数
上一期咱们咱们初步介绍了dietaryindex包计算膳食指数,这期咱们继续介绍。
先导入需要的R包
library(ggplot2)
library(dplyr)
library(tidyr)
library(dietaryindex)
library(survey)
options(survey.lonely.psu = "adjust") ##解决了将调查数据分组到小组的孤独psu问题
导入R包自带的数据,其中DASH_trial和PREDIMED_trial是临床试验的数据,NHANES_20172018数据属于临床流行病学的研究。
假设咱们想研究临床试验数据的膳食指数和流行病学中的膳食指数由什么不同?
data("DASH_trial")
data("PREDIMED_trial")
data("NHANES_20172018")


先设置一下咱们的目录
setwd(“E:/公众号文章2024年/dietaryindex包计算营养指数”)
导入R包关于设置好的营养指数的数据,这个数据需要到作者的主页空间下载,如果需要我下载好的,公众号回复:代码
# Load the NHANES data from 2005 to 2018
## NHANES 2005-2006
load("NHANES_20052006.rda")## NHANES 2007-2008
load("NHANES_20072008.rda")## NHANES 2009-2010
load("NHANES_20092010.rda")## NHANES 2011-2012
load("NHANES_20112012.rda")## NHANES 2013-2014
load("NHANES_20132014.rda")## NHANES 2015-2016
load("NHANES_20152016.rda")
这里咱们以DASHI饮食指数和地中海 MEDI 膳食指数为例子, 利用DASH和MEDI饮食指数,对2017-2018年临床试验(即DASH和PREDIMED)的结果与流行病学研究(即NHANES)的结果进行对比分析。
计算DASHI饮食指数(基于营养素),即停止高血压的饮食方法,使用每1天摄入的营养素。
所有营养素将除以(总能量/2000 kcal)以调整能量摄入
DASHI_DASH = DASHI(SERV_DATA = DASH_trial, #原始数据文件,包括所有份量的食物和营养素RESPONDENTID = DASH_trial$Diet_Type, #每个参与者的唯一参与者IDTOTALKCAL_DASHI = DASH_trial$Kcal, #总能量摄入TOTAL_FAT_DASHI = DASH_trial$Totalfat_Percent, #总脂肪摄入量SAT_FAT_DASHI = DASH_trial$Satfat_Percent, #饱和脂肪摄入量PROTEIN_DASHI = DASH_trial$Protein_Percent, #蛋白质摄入量CHOLESTEROL_DASHI = DASH_trial$Cholesterol, #胆固醇摄入量FIBER_DASHI = DASH_trial$Fiber, #纤维摄入量POTASSIUM_DASHI = DASH_trial$Potassium, #钾摄入量MAGNESIUM_DASHI = DASH_trial$Magnesium, #镁摄入量CALCIUM_DASHI = DASH_trial$Calcium, #钙摄入量SODIUM_DASHI = DASH_trial$Sodium) #钠摄入量
#计算地中海 MEDI 膳食指数(基于食用量),使用给定的 1 天摄入的食物和营养素的食用量
MEDI_PREDIMED = MEDI(SERV_DATA = PREDIMED_trial, #数据文件RESPONDENTID = PREDIMED_trial$Diet_Type, #每位参与者的唯一 IDOLIVE_OIL_SERV_MEDI = PREDIMED_trial$Virgin_Oliveoil,#橄榄油的食用分量FRT_SERV_MEDI = PREDIMED_trial$Fruits, #所有全果的食用分量VEG_SERV_MEDI = PREDIMED_trial$Vegetables, #除马铃薯和豆类以外的所有蔬菜的食用量LEGUMES_SERV_MEDI = PREDIMED_trial$Legumes, #豆类蔬菜的食用分量 NUTS_SERV_MEDI = PREDIMED_trial$Total_nuts, #坚果和种子的食用量FISH_SEAFOOD_SERV_MEDI = PREDIMED_trial$Fish_Seafood, #鱼类海产品的食用分量ALCOHOL_SERV_MEDI = PREDIMED_trial$Alcohol, #酒精的食用量,包括葡萄酒、啤酒、"淡啤酒"、白酒SSB_SERV_MEDI = PREDIMED_trial$Soda_Drinks, #所有含糖饮料的食用量SWEETS_SERV_MEDI = PREDIMED_trial$Sweets, #所有甜食(包括糖果、巧克力、冰淇淋、饼干、蛋糕、派、糕点)DISCRET_FAT_SERV_MEDI = PREDIMED_trial$Refined_Oliveoil, #酌定脂肪食用分量,包括黄油、人造黄油、蛋黄酱、沙拉酱 REDPROC_MEAT_SERV_MEDI = PREDIMED_trial$Meat) #红肉和加工肉类
接下来就是对NHANES进行计算
对2017-2018 年第 1 天和第 2 天 NHANES 数据设置调查设计,先去掉缺失值
##过滤掉权重变量 WTDR2D 的缺失值
NHANES_20172018_design_d1d2 = NHANES_20172018$FPED %>%filter(!is.na(WTDR2D))
计算各个指数
##NHANES 2017年至2018年
#DASHI第1天和第2天,NUTRIENT为第一天数据,NUTRIENT2为第二天数据
#在 1 个步骤内计算 NHANES_FPED 数据(2005 年以后)的 DASHI(基于营养素)
DASHI_NHANES = DASHI_NHANES_FPED(NUTRIENT_PATH=NHANES_20172018$NUTRIENT, NUTRIENT_PATH2=NHANES_20172018$NUTRIENT2)
MEDI for 第1天和第2天
MEDI_NHANES = MEDI_NHANES_FPED(FPED_IND_PATH=NHANES_20172018$FPED_IND, NUTRIENT_IND_PATH=NHANES_20172018$NUTRIENT_IND, FPED_IND_PATH2=NHANES_20172018$FPED_IND2, NUTRIENT_IND_PATH2=NHANES_20172018$NUTRIENT_IND2)
DASH for 第1天和第2天
DASH_NHANES = DASH_NHANES_FPED(NHANES_20172018$FPED_IND, NHANES_20172018$NUTRIENT_IND, NHANES_20172018$FPED_IND2, NHANES_20172018$NUTRIENT_IND2)
MED for 第1天和第2天
MED_NHANES = MED_NHANES_FPED(FPED_PATH=NHANES_20172018$FPED, NUTRIENT_PATH=NHANES_20172018$NUTRIENT, DEMO_PATH=NHANES_20172018$DEMO, FPED_PATH2=NHANES_20172018$FPED2, NUTRIENT_PATH2=NHANES_20172018$NUTRIENT2)
#AHEI for 第1天和第2天
AHEI_NHANES = AHEI_NHANES_FPED(NHANES_20172018$FPED_IND, NHANES_20172018$NUTRIENT_IND, NHANES_20172018$FPED_IND2, NHANES_20172018$NUTRIENT_IND2)
DII for 第1天和第2天
DII_NHANES = DII_NHANES_FPED(FPED_PATH=NHANES_20172018$FPED, NUTRIENT_PATH=NHANES_20172018$NUTRIENT, DEMO_PATH=NHANES_20172018$DEMO, FPED_PATH2=NHANES_20172018$FPED2, NUTRIENT_PATH2=NHANES_20172018$NUTRIENT2)
HEI2020 for 第1天和第2天
HEI2020_NHANES_1718 = HEI2020_NHANES_FPED(FPED_PATH=NHANES_20172018$FPED, NUTRIENT_PATH=NHANES_20172018$NUTRIENT, DEMO_PATH=NHANES_20172018$DEMO, FPED_PATH2=NHANES_20172018$FPED2, NUTRIENT_PATH2=NHANES_20172018$NUTRIENT2)
通过SEQN将所有先前的这些数据合并为一个数据,
NHANES_20172018_dietaryindex_d1d2 = inner_join(NHANES_20172018_design_d1d2, DASHI_NHANES, by = "SEQN") %>%inner_join(MEDI_NHANES, by = "SEQN") %>%inner_join(DASH_NHANES, by = "SEQN") %>%inner_join(MED_NHANES, by = "SEQN") %>%inner_join(AHEI_NHANES, by = "SEQN") %>%inner_join(DII_NHANES, by = "SEQN") %>%inner_join(HEI2020_NHANES_1718, by = "SEQN")
对这个合并数据生成调查设计
NHANES_design_1718_d1d2 <- svydesign(id = ~SDMVPSU, strata = ~SDMVSTRA, weight = ~WTDR2D, data = NHANES_20172018_dietaryindex_d1d2, #set up survey design on the full dataset #can restrict at time of analysis nest = TRUE)
从这个调查对象中提取出相关指标的平均值
# 生成 DASHI_ALL 的 svymean 对象
DASHI_1718_svymean = svymean(~DASHI_ALL, design = NHANES_design_1718_d1d2, na.rm = TRUE)
# 从 svymean 对象中提取平均值
DASHI_1718_svymean_mean = DASHI_1718_svymean[["DASHI_ALL"]]# 生成 MEDI_ALL 的 svymean 对象
MEDI_1718_svymean = svymean(~MEDI_ALL, design = NHANES_design_1718_d1d2, na.rm = TRUE)
# 从 svymean 对象中提取平均值
MEDI_1718_svymean_mean = MEDI_1718_svymean[["MEDI_ALL"]]#为DASH_ALL生成svymean对象
DASH_1718_svymean = svymean(~DASH_ALL, design = NHANES_design_1718_d1d2, na.rm = TRUE)
#从svymean对象中提取均值
DASH_1718_svymean_mean = DASH_1718_svymean[["DASH_ALL"]]#为MED_ALL生成svymean对象
MED_1718_svymean = svymean(~MED_ALL, design = NHANES_design_1718_d1d2, na.rm = TRUE)
#从svymean对象中提取均值
MED_1718_svymean_mean = MED_1718_svymean[["MED_ALL"]]# generate the svymean object for AHEI_ALL
AHEI_1718_svymean = svymean(~AHEI_ALL, design = NHANES_design_1718_d1d2, na.rm = TRUE)
# extract the mean from the svymean object
AHEI_1718_svymean_mean = AHEI_1718_svymean[["AHEI_ALL"]]# generate the svymean object for DII_ALL
DII_1718_svymean = svymean(~DII_ALL, design = NHANES_design_1718_d1d2, na.rm = TRUE)
# extract the mean from the svymean object
DII_1718_svymean_mean = DII_1718_svymean[["DII_ALL"]]# generate the svymean object for HEI2020_ALL
HEI2020_1718_svymean = svymean(~HEI2020_ALL, design = NHANES_design_1718_d1d2, na.rm = TRUE)
# extract the mean from the svymean object
HEI2020_1718_svymean_mean = HEI2020_1718_svymean[["HEI2020_ALL"]]
先设置X轴标签名
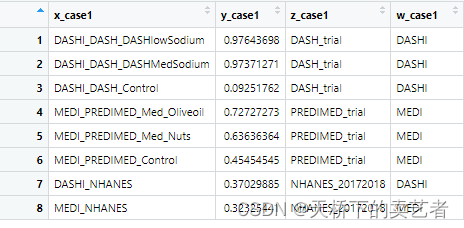
x_case1 = c("DASHI_DASH_DASHlowSodium", "DASHI_DASH_DASHMedSodium", "DASHI_DASH_Control", "MEDI_PREDIMED_Med_Oliveoil", "MEDI_PREDIMED_Med_Nuts", "MEDI_PREDIMED_Control", "DASHI_NHANES", "MEDI_NHANES")
提取DASHI_DASH数据中DASHI_ALL指标,MEDI_PREDIMED数据中的MEDI_ALL指标,MEDI_PREDIMED数据中的MEDI_ALL指标,还有从NHANES_design_1718_d1d2提取的平均值
y_case1 = c(DASHI_DASH$DASHI_ALL[2]/9, DASHI_DASH$DASHI_ALL[3]/9, DASHI_DASH$DASHI_ALL[5]/9, MEDI_PREDIMED$MEDI_ALL[1]/11, MEDI_PREDIMED$MEDI_ALL[2]/11, MEDI_PREDIMED$MEDI_ALL[3]/11, DASHI_1718_svymean_mean/9, MEDI_1718_svymean_mean/11)
生产一个Z的向量,等下绘图用于分组
z_case1 = c("DASH_trial", "DASH_trial", "DASH_trial", "PREDIMED_trial", "PREDIMED_trial", "PREDIMED_trial", "NHANES_20172018", "NHANES_20172018")
创建饮食索引类型的向量
w_case1 = c("DASHI", "DASHI", "DASHI", "MEDI", "MEDI", "MEDI", "DASHI", "MEDI")
将所有y值乘以100得到百分比
y_case1 = y_case1*100
将相关指标合并成一个数据
df_case1 = data.frame(x_case1, y_case1, z_case1, w_case1)
把分类变量转成因子
df_case1$z_case1 = factor(df_case1$z_case1, levels = c("NHANES_20172018", "DASH_trial", "PREDIMED_trial"))
df_case1$x_case1 = factor(df_case1$x_case1, levels = c("DASHI_NHANES", "DASHI_DASH_Control", "DASHI_DASH_DASHMedSodium", "DASHI_DASH_DASHlowSodium", "MEDI_NHANES", "MEDI_PREDIMED_Control", "MEDI_PREDIMED_Med_Nuts", "MEDI_PREDIMED_Med_Oliveoil"))
最后绘图
ggplot(df_case1, aes(x=z_case1, y=y_case1, fill=x_case1)) + geom_bar(stat = "identity", position = "dodge") +theme_bw() +# create a facet grid with the dietary index typefacet_wrap(. ~ w_case1, scales = "free_x") +labs(y = "Mean dietary index percentile", fill = "Dieary indexes for specific diets") +theme(# increase the plot title sizeplot.title = element_text(size=18),# remove the x axis titleaxis.title.x = element_blank(),# remove the x axis textaxis.text.x = element_blank(),# increase the y axis title and text sizeaxis.title.y = element_text(size=18),axis.text.y = element_text(size=14),# increase the legend title and text sizelegend.title = element_text(size=18),legend.text = element_text(size=16),# increase the facet label sizestrip.text = element_text(size = 16)) +# add numeric labels to the bars and increase their sizegeom_text(aes(label = round(y_case1, 2)), vjust = -0.5, size = 4.5, position = position_dodge(0.9)) +# add custom fill labelsscale_fill_discrete(labels = c("DASHI_DASH_DASHlowSodium" = "DASHI for DASH trial low sodium diet","DASHI_DASH_DASHMedSodium" = "DASHI for DASH trial medium sodium diet","DASHI_DASH_Control" = "DASHI for DASH trial control diet","MEDI_PREDIMED_Med_Oliveoil" = "MEDI for PREDIMED mediterranean olive oil diet","MEDI_PREDIMED_Med_Nuts" = "MEDI for PREDIMED mediterranean nuts diet","MEDI_PREDIMED_Control" = "MEDI for PREDIMED control diet","DASHI_NHANES" = "DASHI for NHANES 2017-18","MEDI_NHANES" = "MEDI for NHANES 2017-18"))
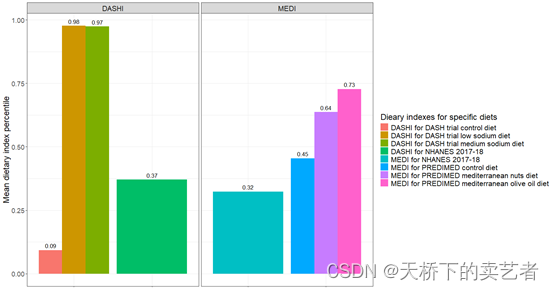
最后得到上图,y表示平均膳食指数百分位,不同颜色的柱子分别表示各个指数。
相关文章:
R语言使用dietaryindex包计算NHANES数据多种营养指数(2)
健康饮食指数 (HEI) 是评估一组食物是否符合美国人膳食指南 (DGA) 的指标。Dietindex包提供用户友好的简化方法,将饮食摄入数据标准化为基于指数的饮食模式,从而能够评估流行病学和临床研究中对这些模式的遵守情况,从而促进精准营养。 该软件…...
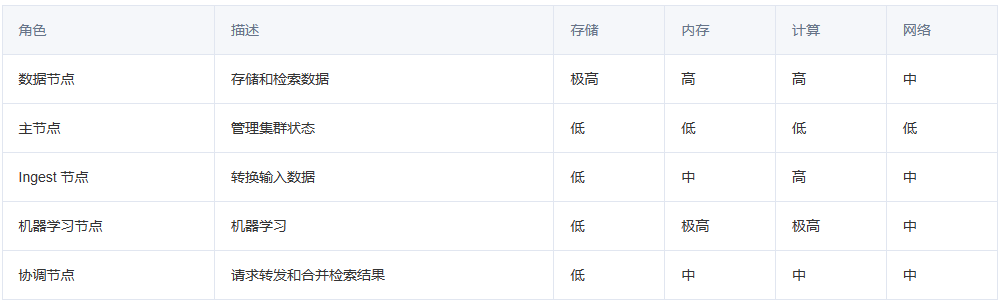
Elasticsearch 索引模板、生命周期策略、节点角色
简介 索引模板可以帮助简化创建和二次配置索引的过程,让我们更高效地管理索引的配置和映射。 索引生命周期策略是一项有意义的功能。它通常用于管理索引和分片的热(hot)、温(warm)和冷(cold)数…...
buy me a btc 使用数字货币进行打赏赞助
最近在调研使用加密货币打赏的平台,发现idatariver平台 https://idatariver.com 推出的buymeabtc功能刚好符合使用场景,下图为平台的演示项目, 演示项目入口 https://buymeabtc.com/idatariver 特点 不少人都听说过buymeacoffee,可以在上面发…...
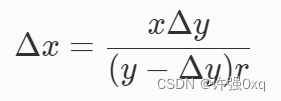
Solidity Uniswap V2 Router swapTokensForExactTokens
最初的router合约实现了许多不同的交换方式。我们不会实现所有的方式,但我想向大家展示如何实现倒置交换:用未知量的输入Token交换精确量的输出代币。这是一个有趣的用例,可能并不常用,但仍有可能实现。 GitHub - XuHugo/solidit…...

网络安全渗透测试工具
网络安全渗透测试常用的开发工具包括但不限于以下几种: Nmap:一款网络扫描工具,用于探测目标主机的开放端口和正在运行的服务,是网络发现和攻击界面测绘的首选工具。Wireshark:一个流量分析工具,用于监测网…...
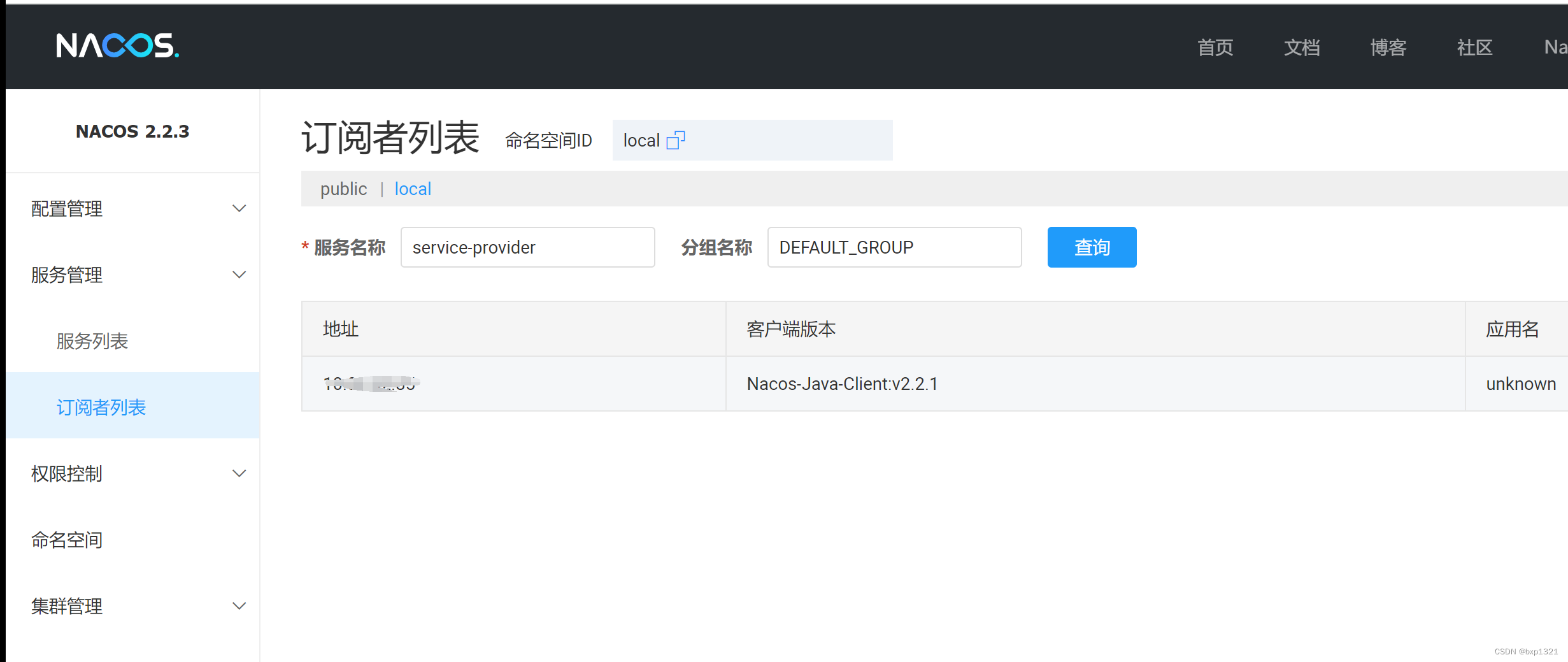
springcloud+nacos服务注册与发现
快速开始 | Spring Cloud Alibaba 参考官方快速开始教程写的,主要注意引用的包是否正确。 这里是用的2022.0.0.0-RC2版本的springCloud,所以需要安装jdk21,参考上一个文章自行安装。 nacos-config实现配置中心功能-CSDN博客 将nacos-conf…...

【C++程序员的自我修炼】基础语法篇(一)
心中若有桃花源 何处不是水云间 目录 命名空间 💞命名空间的定义 💞 命名空间的使用 输入输出流 缺省参数 函数的引用 引用的定义💞 引用的表示💞 引用的特性💞 常量引用💞 引用的使用场景 做参数 做返回值…...
小狐狸JSON-RPC:钱包连接,断开连接,监听地址改变
detect-metamask 创建连接,并监听钱包切换 一、连接钱包,切换地址(监听地址切换),断开连接 使用npm安装 metamask/detect-provider在您的项目目录中: npm i metamask/detect-providerimport detectEthereu…...

union在c语言中什么用途
在C语言中,union是一种特殊的数据类型,可以在同一块内存中存储不同类型的数据。它的主要用途有以下几个: 1. 节省内存:由于union只占用其成员中最大的数据类型所占用的内存空间,可以在不同的情况下使用同一块内存来存…...
)
2024年华为OD机试真题- 寻找最优的路测线路-Java-OD统一考试(C卷)
题目描述: 评估一个网络的信号质量,其中一个做法是将网络划分为栅格,然后对每个栅格的信号质量计算。路测的时候,希望选择一条信号最好的路线(彼此相连的栅格集合)进行演示。现给出R行C列的整数数组Cov,每个单元格的数值S即为该栅格的信号质量(已归一化,无单位,值越大…...

WPF 多路绑定、值转换器ValueConvert、数据校验
值转换器 valueconvert 使用ValueConverter需要实现IValueConverter接口,其内部有两个方法,Convert和ConvertBack。我们在使用Binding绑定数据的时候,当遇到源属性和目标控件需要的类型不一致的,就可以使用ValueConverter…...
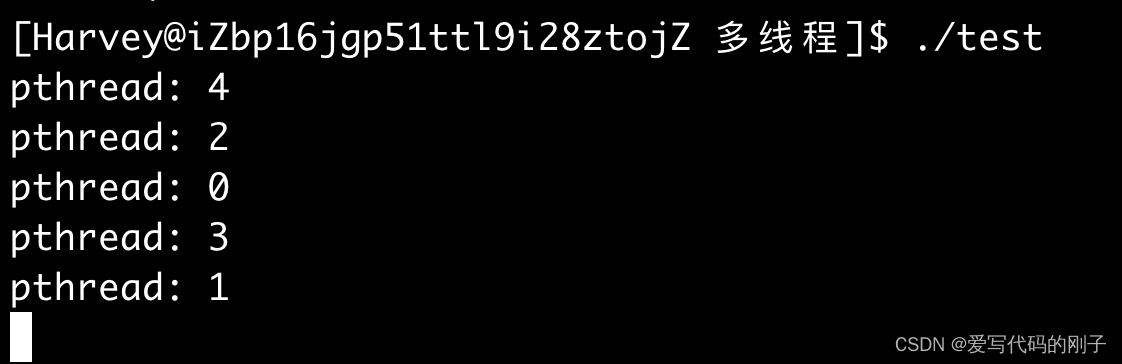
【Linux多线程】线程的同步与互斥
【Linux多线程】线程的同步与互斥 目录 【Linux多线程】线程的同步与互斥分离线程Linux线程互斥进程线程间的互斥相关背景概念问题产生的原因: 互斥量mutex互斥量的接口互斥量实现原理探究对锁进行封装(C11lockguard锁) 可重入VS线程安全概念常见的线程不安全的情况…...

Linux网卡bond的七种模式详解
像Samba、Nfs这种共享文件系统,网络的吞吐量非常大,就造成网卡的压力很大,网卡bond是通过把多个物理网卡绑定为一个逻辑网卡,实现本地网卡的冗余,带宽扩容和负载均衡,具体的功能取决于采用的哪种模式。 Lin…...
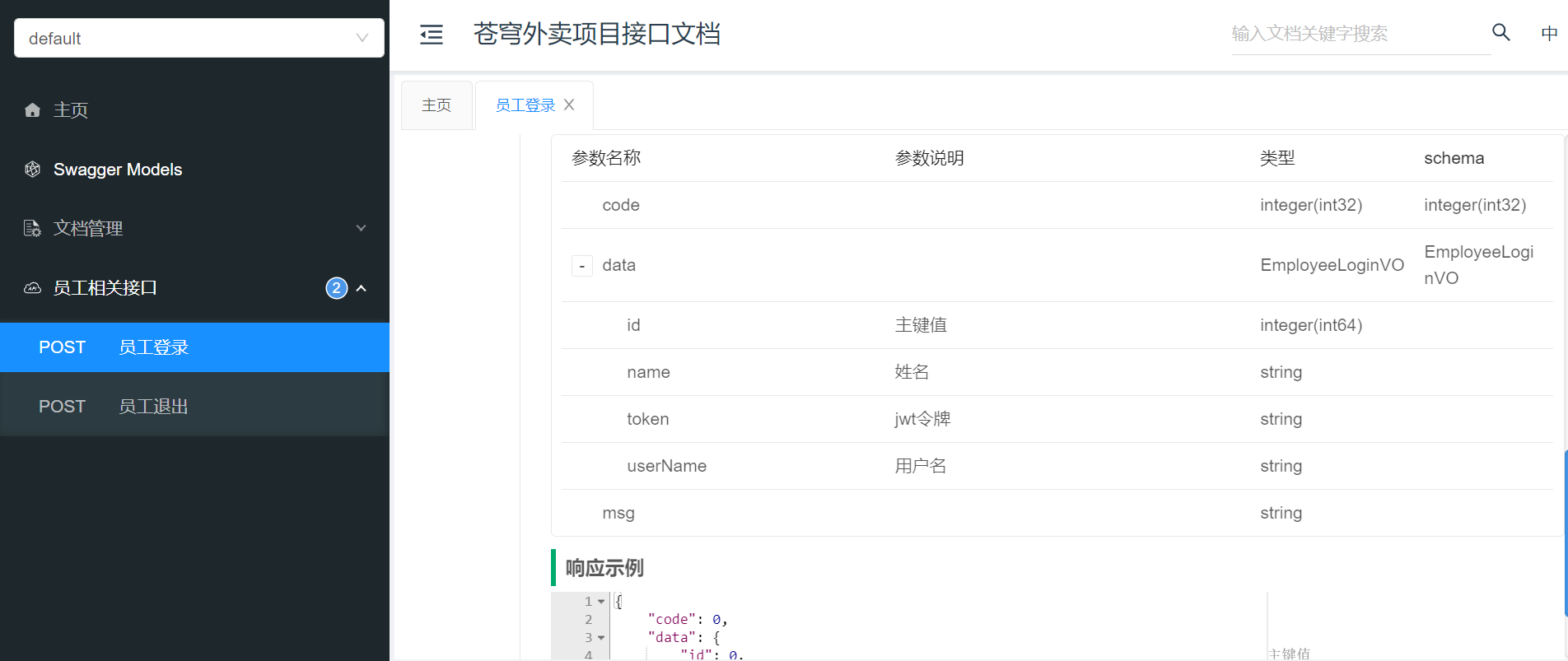
【学习笔记】java项目—苍穹外卖day01
文章目录 苍穹外卖-day01课程内容1. 软件开发整体介绍1.1 软件开发流程1.2 角色分工1.3 软件环境 2. 苍穹外卖项目介绍2.1 项目介绍2.2 产品原型2.3 技术选型 3. 开发环境搭建3.1 前端环境搭建3.2 后端环境搭建3.2.1 熟悉项目结构3.2.2 Git版本控制3.2.3 数据库环境搭建3.2.4 前…...
之vector超详用法整理)
C++之STL整理(2)之vector超详用法整理
C之STL整理(2)之vector用法(创建、赋值、方法)整理 注:整理一些突然学到的C知识,随时mark一下 例如:忘记的关键字用法,新关键字,新数据结构 C 的vector用法整理 C之STL整…...
机器学习作业二之KNN算法
KNN(K- Nearest Neighbor)法即K最邻近法,最初由 Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路非常简单直观:如果一个样本在特征空间中的K个最相似&…...

笔记81:在服务器中运行 Carla 报错 “Disabling core dumps.”
背景:使用实验室提供的服务器配 Carla-ROS2 联合仿真的实验环境,在安装好 Carla 后运行 ./CarlaUE4.sh 但是出现 Disabling core dumps. 报错,而且不会出现 Carla 的窗口; 解决:运行以下命令 ./CarlaUE4.sh -carl…...
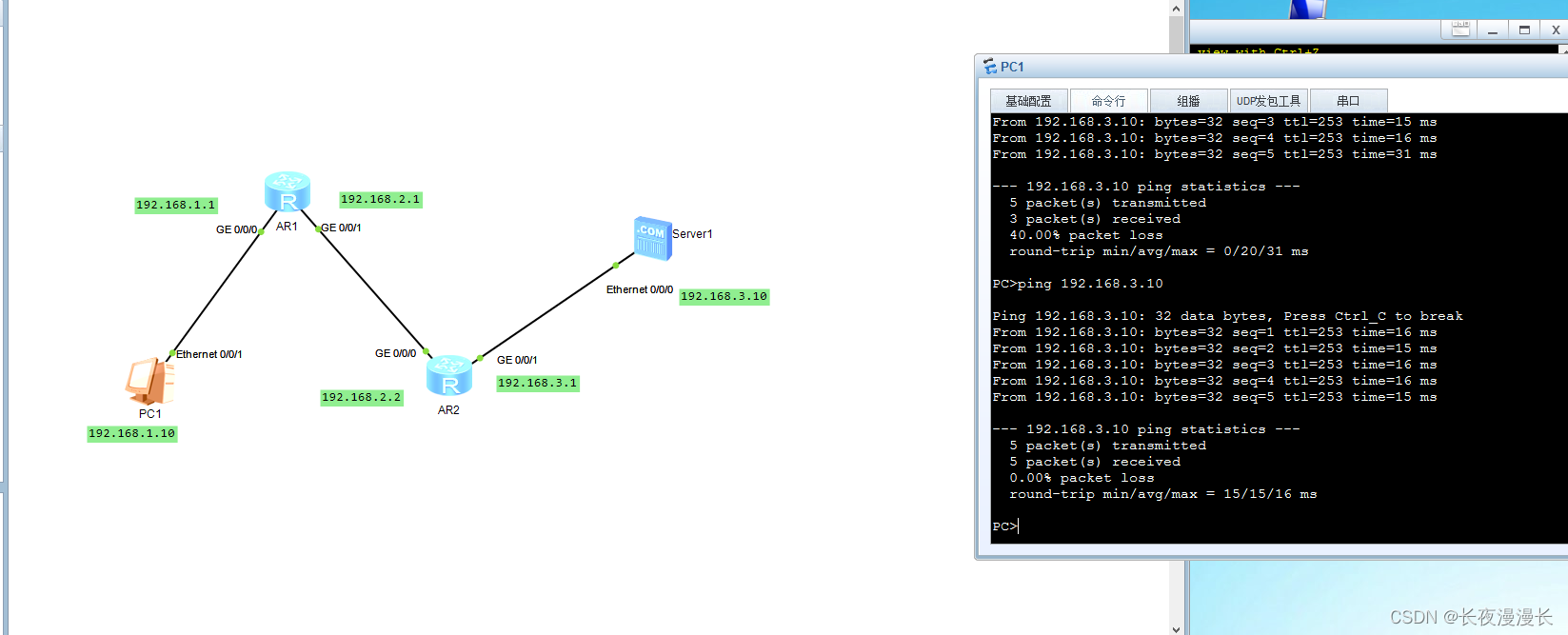
ensp中pc机访问不同网络的服务器
拓扑图如下,资源已上传 说明:pc通过2个路由访问server服务器 三条线路分别是192.168.1.0网段,192.168.2.0网段和192.168.3.0网段,在未配置的情况下,pc设备是访问不到server的 具体操作流程 第一;pc设备…...

CSGO赛事管理系统的设计与实现|Springboot+ Mysql+Java+ B/S结构(可运行源码+数据库+设计文档)
本项目包含可运行源码数据库LW,文末可获取本项目的所有资料。 推荐阅读100套最新项目持续更新中..... 2024年计算机毕业论文(设计)学生选题参考合集推荐收藏(包含Springboot、jsp、ssmvue等技术项目合集) 目录 1. 系…...
win10微软拼音输入法 - bug - 在PATH变量为空的情况下,无法输入中文
文章目录 win10微软拼音输入法 - bug - 在PATH变量为空的情况下,无法输入中文概述笔记实验前提条件100%可以重现 - 无法使用win10拼音输入法输入中文替代的输入法软件备注备注END win10微软拼音输入法 - bug - 在PATH变量为空的情况下,无法输入中文 概述…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

【 java 虚拟机知识 第一篇 】
目录 1.内存模型 1.1.JVM内存模型的介绍 1.2.堆和栈的区别 1.3.栈的存储细节 1.4.堆的部分 1.5.程序计数器的作用 1.6.方法区的内容 1.7.字符串池 1.8.引用类型 1.9.内存泄漏与内存溢出 1.10.会出现内存溢出的结构 1.内存模型 1.1.JVM内存模型的介绍 内存模型主要分…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...
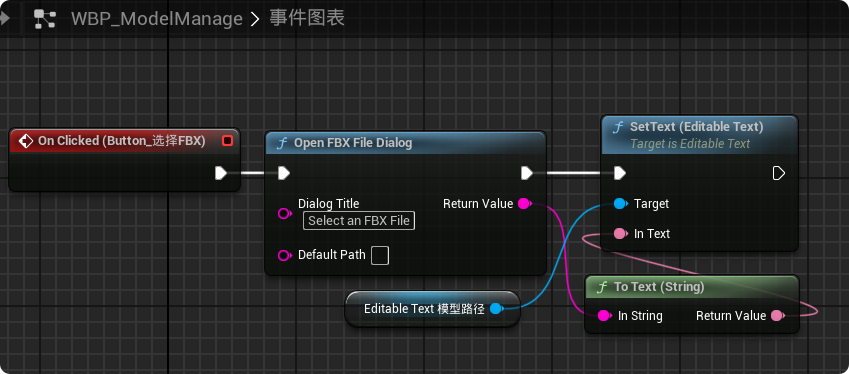
【UE5 C++】通过文件对话框获取选择文件的路径
目录 效果 步骤 源码 效果 步骤 1. 在“xxx.Build.cs”中添加需要使用的模块 ,这里主要使用“DesktopPlatform”模块 2. 添加后闭UE编辑器,右键点击 .uproject 文件,选择 "Generate Visual Studio project files",重…...
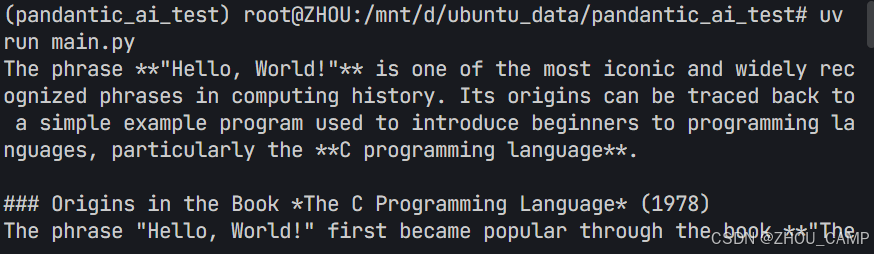
PydanticAI快速入门示例
参考链接:https://ai.pydantic.dev/#why-use-pydanticai 示例代码 from pydantic_ai import Agent from pydantic_ai.models.openai import OpenAIModel from pydantic_ai.providers.openai import OpenAIProvider# 配置使用阿里云通义千问模型 model OpenAIMode…...

拟合问题处理
在机器学习中,核心任务通常围绕模型训练和性能提升展开,但你提到的 “优化训练数据解决过拟合” 和 “提升泛化性能解决欠拟合” 需要结合更准确的概念进行梳理。以下是对机器学习核心任务的系统复习和修正: 一、机器学习的核心任务框架 机…...
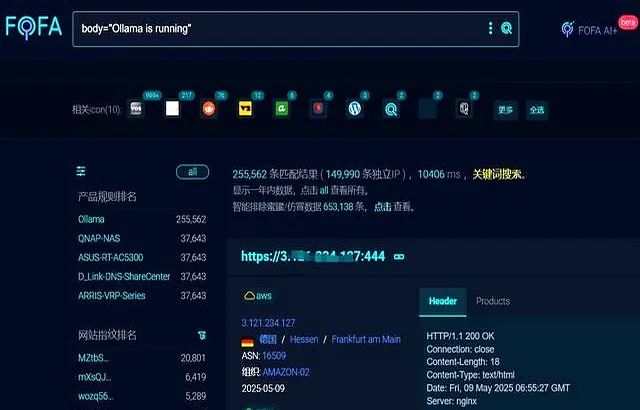
未授权访问事件频发,我们应当如何应对?
在当下,数据已成为企业和组织的核心资产,是推动业务发展、决策制定以及创新的关键驱动力。然而,未授权访问这一隐匿的安全威胁,正如同高悬的达摩克利斯之剑,时刻威胁着数据的安全,一旦触发,便可…...