SpringBoot集成Solr全文检索
SrpingBoot 集成 Solr 实现全文检索
一、核心路线
- 使用 Docker 镜像部署 Solr 8.11.3 版本服务
- 使用 ik 分词器用于处理中文分词
- 使用 spring-boot-starter-data-solr 实现增删改查
- 配置用户名密码认证
- 使用 poi 和 pdfbox 组件进行文本内容读取
- 文章最上方有源码和 ik 分词器资源
二、Solr Docker 镜像制作
由于 Solr 官方镜像无法通过环境变量直接配置用户名密码认证,所以选用第三方的 bitnami/solr 镜像作为基础,将 ik 分词器插件封装后得到新的镜像。
-
拉取
bitnami/solr镜像docker pull bitnami/solr:8.11.3 -
下载 ik 分词器 jar 包
ik-analyzer-8.5.0.jar -
编写 Dockerfile 文件
FROM bitnami/solr:8.11.3COPY ./ik-analyzer-8.5.0.jar /opt/bitnami/solr/server/solr-webapp/webapp/WEB-INF/lib/CMD ["/opt/bitnami/scripts/solr/run.sh"] -
构建镜像
docker build -t bitnami/solr:8.11.3-ik .
三、部署 Solr 服务
方式一:普通 docker 命令行部署
-
创建数据目录,例如
/home/solr-data -
启动容器
docker run -d -p 8983:8983 --name solr \-v /home/solr-data:/bitnami \-e SOLR_ENABLE_AUTHENTICATION=yes \-e SOLR_CORES=my_core \-e SOLR_ADMIN_USERNAME=admin \-e SOLR_ADMIN_PASSWORD=SolrPass \bitnami/solr:8.11.3-ik
方式二:Rancher 云平台部署
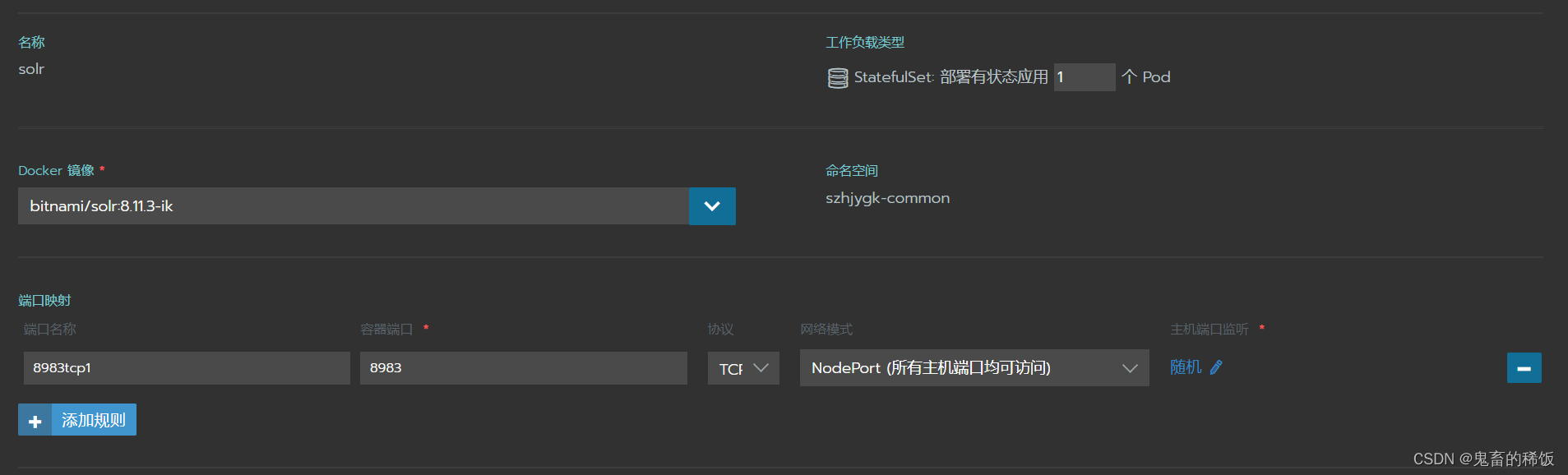



由于 solr 镜像默认使用 solr 用户启动容器,挂载的 pvc 没有写入权限,需要按照以下步骤进行:
-
以 UID=0 即 root 用户进行启动,并且入口 Entrypoint 使用 /bin/bash 覆盖默认启动命令,然后进入容器命令行
-
修改数据目录属主
chown -R solr:solr /bitnami/ -
去掉入口(Entrypoint)命令,用户 UID 设置为 1000 即 solr,重启工作负载即可
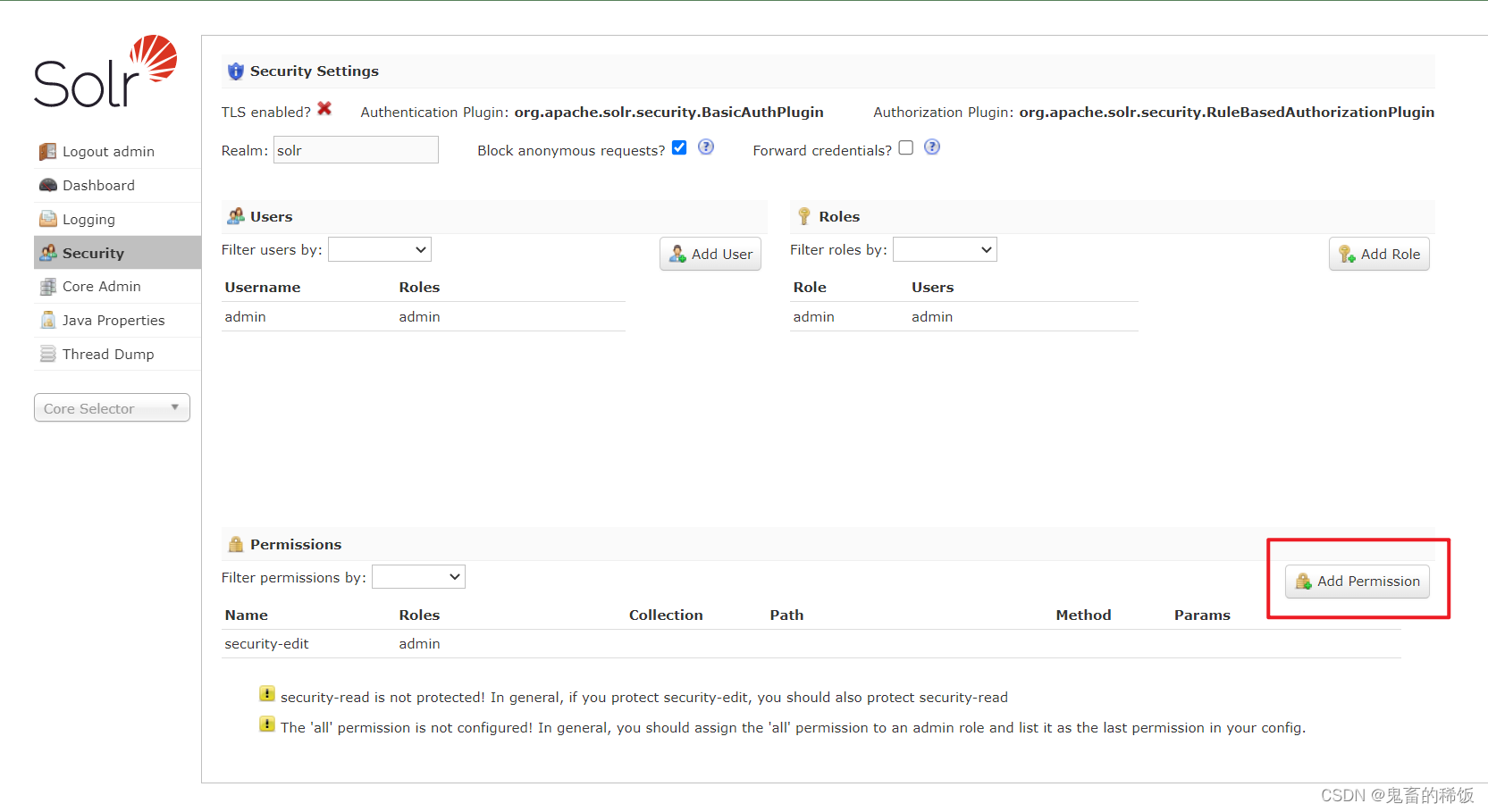
四、配置 Solr 用户权限
-
访问
http://localhost:8983即可打开 solr 控制台,输入账号密码admin/SolrPass登录认证 -
为了演示方便,直接给 admin 用户赋予全部权限
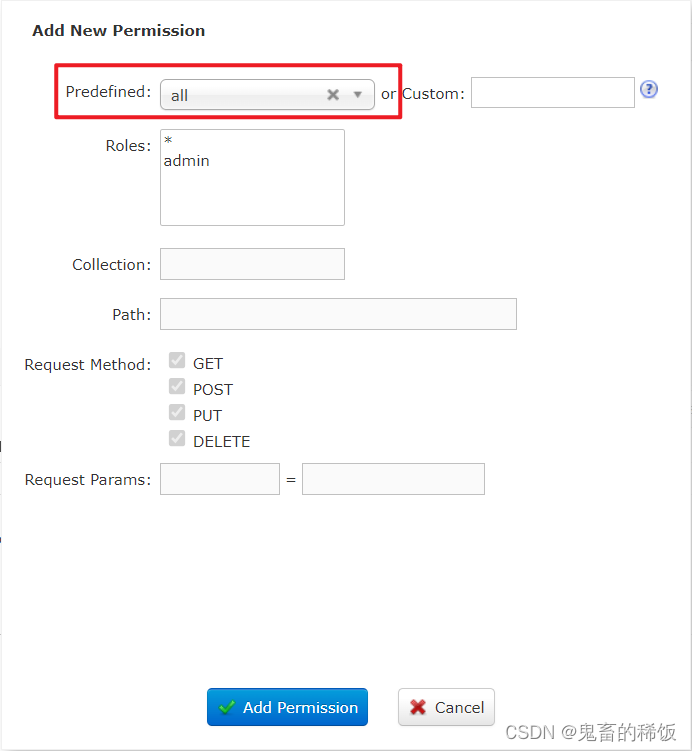
五、配置 my_core 的 ik 分词
编辑 /bitnami/solr/server/solr/my_core/conf/managed-schema 配置文件,追加以下配置内容:
<!--ik 分词插件配置--><fieldType name="text_ik" class="solr.TextField"><analyzer type="index"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="false"/><filter class="solr.LowerCaseFilterFactory"/></analyzer><analyzer type="query"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="true"/><filter class="solr.LowerCaseFilterFactory"/></analyzer></fieldType>
配置完成后重启 solr 容器。
六、创建 SpringBoot 工程
pom.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.4.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.example</groupId><artifactId>solr-example</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--Solr--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-solr</artifactId></dependency><!--Solr 认证--><dependency><groupId>commons-codec</groupId><artifactId>commons-codec</artifactId></dependency><!--读取 docx 文档内容--><dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>5.2.2</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.2.2</version></dependency><!--读取 doc 文档内容--><dependency><groupId>org.apache.poi</groupId><artifactId>poi-scratchpad</artifactId><version>5.2.2</version></dependency><!--读取 PDF 文档内容--><dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.26</version></dependency><!--Hutool 工具类--><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.2</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency></dependencies><build><finalName>${project.artifactId}</finalName><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>2.3.3.RELEASE</version><executions><execution><phase>package</phase><goals><goal>repackage</goal><!--可以把依赖的包都打包到生成的Jar包中--></goals></execution></executions></plugin></plugins></build></project>配置文件
server:port: 18888
spring:servlet:# 文件上传配置multipart:enabled: truemax-file-size: 100MBmax-request-size: 100MBdata:solr:host: http://localhost:8983/solr # solr 服务地址username: admin # solr 用户名password: SolrPass # solr 密码
工程启动类
package com.example.solr;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.data.solr.repository.config.EnableSolrRepositories;@EnableSolrRepositories // 启用 solr repository
@SpringBootApplication
public class SolrExampleApplication {public static void main(String[] args) {SpringApplication.run(SolrExampleApplication.class, args);}
}SolrConfig 配置类
该类用于配置 Solr 认证
import org.apache.http.HttpHost;
import org.apache.http.HttpRequest;
import org.apache.http.HttpRequestInterceptor;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.AuthState;
import org.apache.http.auth.Credentials;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.client.protocol.HttpClientContext;
import org.apache.http.impl.auth.BasicScheme;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.protocol.HttpContext;
import org.apache.http.protocol.HttpCoreContext;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.net.URI;@Configuration
public class SolrConfig {@Value("${spring.data.solr.username}")private String username;@Value("${spring.data.solr.password}")private String password;@Value("${spring.data.solr.host}")private String uri;/**** 配置 solr 账号密码*/@Beanpublic HttpSolrClient solrClient() {CredentialsProvider provider = new BasicCredentialsProvider();final URI uri = URI.create(this.uri);provider.setCredentials(new AuthScope(uri.getHost(), uri.getPort()),new UsernamePasswordCredentials(this.username, this.password));HttpClientBuilder builder = HttpClientBuilder.create();// 指定拦截器,用于设置认证信息builder.addInterceptorFirst(new SolrAuthInterceptor());builder.setDefaultCredentialsProvider(provider);CloseableHttpClient httpClient = builder.build();return new HttpSolrClient.Builder(this.uri).withHttpClient(httpClient).build();}public static class SolrAuthInterceptor implements HttpRequestInterceptor {@Overridepublic void process(final HttpRequest request, final HttpContext context) {AuthState authState = (AuthState) context.getAttribute(HttpClientContext.TARGET_AUTH_STATE);if (authState.getAuthScheme() == null) {CredentialsProvider provider =(CredentialsProvider) context.getAttribute(HttpClientContext.CREDS_PROVIDER);HttpHost httpHost = (HttpHost) context.getAttribute(HttpCoreContext.HTTP_TARGET_HOST);AuthScope scope = new AuthScope(httpHost.getHostName(), httpHost.getPort());Credentials credentials = provider.getCredentials(scope);authState.update(new BasicScheme(), credentials);}}}
}MyDocument 实体类
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.solr.client.solrj.beans.Field;
import org.springframework.data.annotation.Id;
import org.springframework.data.solr.core.mapping.Indexed;
import org.springframework.data.solr.core.mapping.SolrDocument;import java.io.Serializable;@Data
@NoArgsConstructor
@AllArgsConstructor
@SolrDocument(collection = "my_core") // 此处配置 core 信息
public class MyDocument implements Serializable {@Id@Fieldprivate String id;// 使用 string 类型即不进行分词@Indexed(name = "type", type = "string")private String type;// 使用 text_ik 类型即使用 ik 分词器进行分词索引和查询@Indexed(name = "title", type = "text_ik")private String title;// 使用 text_ik 类型即使用 ik 分词器进行分词索引和查询@Indexed(name = "content", type = "text_ik")private String content;
}
MyDocumentRepository 类
该类用于和 solr 服务进行通信,实现增删改查操作。
import com.example.solr.entity.MyDocument;
import org.springframework.data.domain.Pageable;
import org.springframework.data.solr.core.query.result.HighlightPage;
import org.springframework.data.solr.repository.Highlight;
import org.springframework.data.solr.repository.Query;
import org.springframework.data.solr.repository.SolrCrudRepository;import java.util.List;public interface MyDocumentRepository extends SolrCrudRepository<MyDocument, String> {/*** 按类型进行查询** @param type 类型* @return 查询结果*/@Query("type:?0")List<MyDocument> findAllByType(String type);/*** 按照标题或内容进行模糊查询,并且对关键词进行高亮标记* snipplets = 3 用于指定查询出符合条件的结果数,不指定则只能查出一条** @param title 标题关键词* @param content 内容关键词* @param pageable 分页对象* @return 带有高亮标记的查询结果*/@Highlight(snipplets = 3, fields = {"title", "content"}, prefix = "<span style='color:red'>", postfix = "</span>")HighlightPage<MyDocument> findAllByTitleOrContent(String title, String content, Pageable pageable);
}
MyDocumentService 类
import com.example.solr.entity.MyDocument;
import org.springframework.data.domain.Pageable;import java.util.List;
import java.util.Map;public interface MyDocumentService {MyDocument save(MyDocument document);void saveAll(List<MyDocument> documentList);void delete(String id);MyDocument findById(String id);List<MyDocument> findAllByType(String type);List<Map<String, Object>> findAllByTitleOrContent(String searchItem, Pageable pageable);
}
对应的实现类
import com.example.solr.entity.MyDocument;
import com.example.solr.repository.MyDocumentRepository;
import com.example.solr.service.MyDocumentService;
import org.springframework.data.domain.Pageable;
import org.springframework.data.solr.core.query.result.HighlightEntry;
import org.springframework.data.solr.core.query.result.HighlightPage;
import org.springframework.stereotype.Service;import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;@Service
public class MyDocumentServiceImpl implements MyDocumentService {@Resourceprivate MyDocumentRepository repository;@Overridepublic MyDocument save(MyDocument document) {return repository.save(document);}@Overridepublic void saveAll(List<MyDocument> documentList) {repository.saveAll(documentList);}@Overridepublic void delete(String id) {repository.delete(findById(id));}@Overridepublic MyDocument findById(String id) {return repository.findById(id).orElse(null);}@Overridepublic List<MyDocument> findAllByType(String type) {return repository.findAllByType(type);}@Overridepublic List<Map<String, Object>> findAllByTitleOrContent(String searchItem, Pageable pageable) {// 查询分页结果HighlightPage<MyDocument> page = repository.findAllByTitleOrContent(searchItem, searchItem, pageable);List<Map<String, Object>> result = new ArrayList<>();// 处理查询结果高亮片段for (HighlightEntry<MyDocument> highlight : page.getHighlighted()) {// 每个 map 对应一个文档Map<String, Object> map = new HashMap<>();MyDocument doc = highlight.getEntity();map.put("id", doc.getId());map.put("type", doc.getType());map.put("title", doc.getTitle());for (HighlightEntry.Highlight hl : highlight.getHighlights()) {map.put(hl.getField().getName(), hl.getSnipplets());}result.add(map);}return result;}
}
FileUtil 文件内容处理类
import cn.hutool.core.util.StrUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.apache.poi.hwpf.HWPFDocument;
import org.apache.poi.hwpf.extractor.WordExtractor;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.poi.xwpf.usermodel.XWPFRun;
import org.springframework.web.multipart.MultipartFile;import java.io.IOException;
import java.io.InputStream;@Slf4j
public class FileUtil {/*** 读取文档内容* 目前仅支持 txt, doc, docx, pdf 格式** @param file 文件对象* @return 文档内容*/public static String readFileContent(MultipartFile file) {String filename = file.getOriginalFilename();assert filename != null;String fileType = filename.substring(filename.lastIndexOf(".") + 1).toUpperCase();switch (fileType) {case "TXT":return readTxtContent(file);case "DOC":case "DOCX":return readWordContent(file);case "PDF":return readPDFContent(file);default:return "";}}/*** 读取 txt 文档内容*/private static String readTxtContent(MultipartFile file) {try {return StrUtil.utf8Str(file.getBytes());} catch (IOException e) {e.printStackTrace();log.error("读取 txt 文件内容时发生 IO 异常");return "";}}/*** 读取 doc 和 docx 文档内容*/private static String readWordContent(MultipartFile file) {String filename = file.getOriginalFilename();assert filename != null;String fileType = filename.substring(filename.lastIndexOf(".") + 1);return "doc".equals(fileType) ? readDocContent(file) : readDocxContent(file);}/*** 读取 .doc 格式的 word 文档** @param file 文件对象* @return 文本内容*/private static String readDocContent(MultipartFile file) {StringBuilder content = new StringBuilder();try (InputStream inputStream = file.getInputStream();HWPFDocument document = new HWPFDocument(inputStream)) {WordExtractor extractor = new WordExtractor(document);String[] paragraphs = extractor.getParagraphText();for (String paragraph : paragraphs) {content.append(paragraph);}} catch (IOException e) {e.printStackTrace();log.error("读取文件内容时发生 IO 异常");}return content.toString();}/*** 读取 .docx 格式的 word 文档** @param file 文件对象* @return 文本内容*/private static String readDocxContent(MultipartFile file) {StringBuilder content = new StringBuilder();try (InputStream inputStream = file.getInputStream();XWPFDocument document = new XWPFDocument(inputStream)) {for (XWPFParagraph paragraph : document.getParagraphs()) {for (XWPFRun run : paragraph.getRuns()) {String runText = run.getText(0);if (runText != null) {content.append(runText);}}}} catch (IOException e) {e.printStackTrace();log.error("读取文件内容时发生 IO 异常");}return content.toString();}/*** 读取 pdf 文档内容*/private static String readPDFContent(MultipartFile file) {StringBuilder content = new StringBuilder();try (InputStream inputStream = file.getInputStream();PDDocument document = PDDocument.load(inputStream)) {// 检查是否是由文档转换出的 pdf 文件if (!document.isEncrypted() && document.getNumberOfPages() > 0) {PDFTextStripper textStripper = new PDFTextStripper();content.append(textStripper.getText(document));} else {log.warn("PDF 已加密或不是由文档转换的 PDF 格式,无法读取内容!");}} catch (IOException e) {e.printStackTrace();log.error("读取文件内容时发生 IO 异常");}return content.toString();}
}MyDocumentController 控制器类
package com.example.solr.controller;import com.example.solr.entity.MyDocument;
import com.example.solr.service.MyDocumentService;
import com.example.solr.util.FileUtil;
import org.springframework.data.domain.PageRequest;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;import javax.annotation.Resource;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.UUID;@RestController
@RequestMapping("/solr")
public class MyDocumentController {@Resourceprivate MyDocumentService documentService;/*** 上传文档文件,读取文档内容并写入 solr** @param file 上传的文档文件,仅支持读取以下格式的文件内容 txt, doc, docx, pdf(由文档转换生成的)* @param type 文件分类* @return 处理结果*/@PostMapping("/upload")public Map<String, Object> upload(@RequestPart("multipartFile") MultipartFile file, @RequestParam String type) {MyDocument doc = new MyDocument();doc.setId(UUID.randomUUID().toString());doc.setType(type);doc.setTitle(file.getOriginalFilename());doc.setContent(FileUtil.readFileContent(file));documentService.save(doc);Map<String, Object> result = new HashMap<>();result.put("result", true);result.put("data", doc);return result;}/*** 直接向 solr 添加内容** @param type 类型* @param title 标题* @param content 内容* @return 处理结果*/@PostMapping("/save")public Map<String, Object> save(@RequestParam String type, @RequestParam String title, @RequestParam String content) {MyDocument doc = new MyDocument();doc.setId(UUID.randomUUID().toString());doc.setType(type);doc.setTitle(title);doc.setContent(content);documentService.save(doc);Map<String, Object> result = new HashMap<>();result.put("result", true);result.put("data", doc);return result;}/*** 删除 solr 内容** @param id 主键* @return 处理结果*/@DeleteMapping("/delete")public Map<String, Object> delete(@RequestParam String id) {documentService.delete(id);Map<String, Object> result = new HashMap<>();result.put("result", true);result.put("data", null);return result;}/*** 根据标题或内容模糊搜索,并且高亮关键词** @param searchItem 搜索关键词* @param page 页码* @param size 每页数量* @return 查询结果*/@GetMapping("/searchTitleOrContent")public Map<String, Object> searchTitleOrContent(@RequestParam String searchItem, @RequestParam Integer page,@RequestParam Integer size) {List<Map<String, Object>> data = documentService.findAllByTitleOrContent(searchItem, PageRequest.of(page, size));Map<String, Object> result = new HashMap<>();result.put("result", true);result.put("data", data);return result;}/*** 根据类型搜索** @param type 类型* @return 查询结果*/@GetMapping("/searchType")public Map<String, Object> searchType(@RequestParam String type) {List<MyDocument> data = documentService.findAllByType(type);Map<String, Object> result = new HashMap<>();result.put("result", true);result.put("data", data);return result;}
}七、验证
启动服务,使用 postman 等工具进行接口请求。
1. 直接写入 solr 内容

2. 上传 word 文档读取内容写入 solr

3. 根据类型精确查询

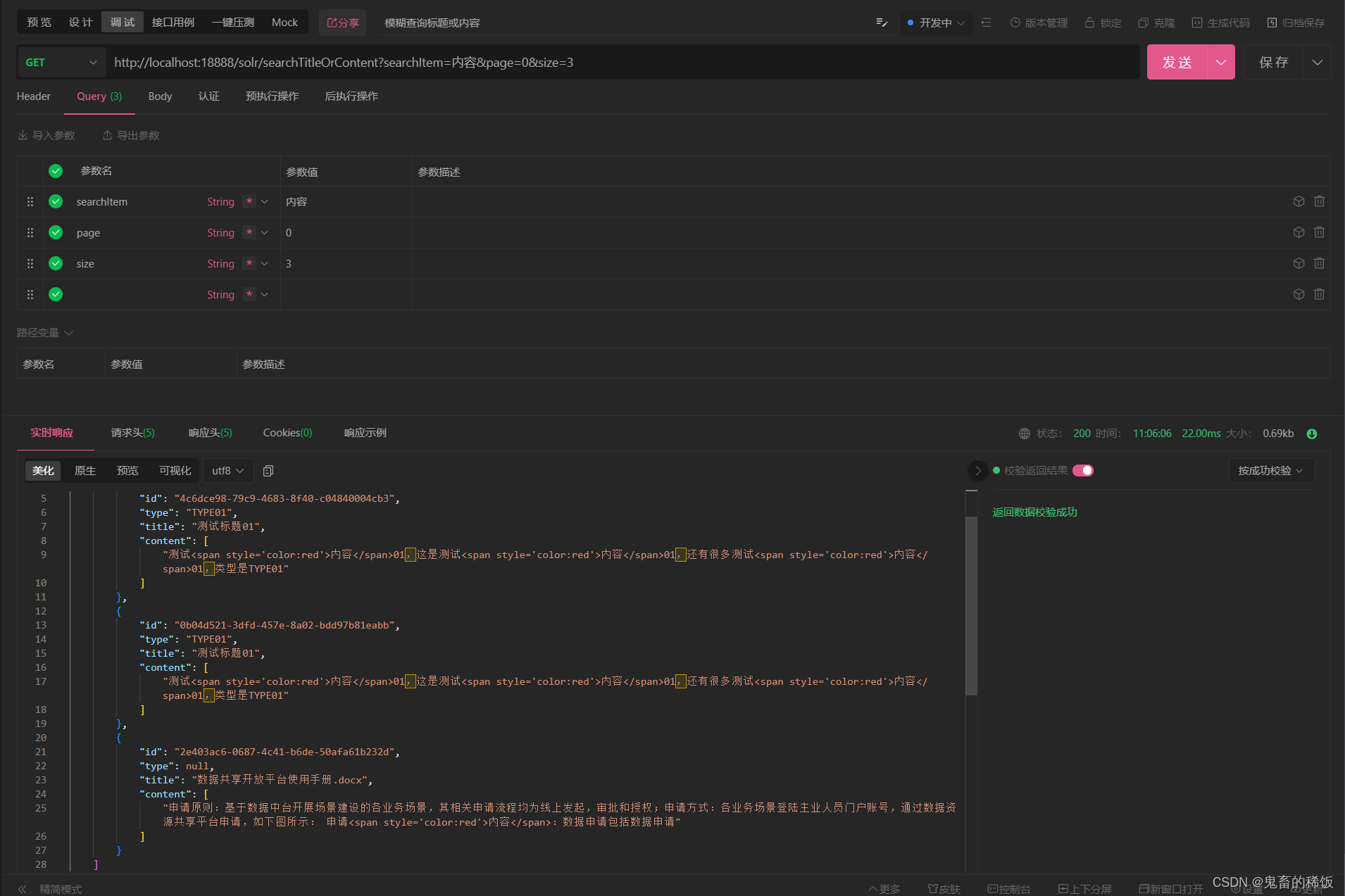
4. 根据标题或内容模糊查询
相关文章:
SpringBoot集成Solr全文检索
SrpingBoot 集成 Solr 实现全文检索 一、核心路线 使用 Docker 镜像部署 Solr 8.11.3 版本服务使用 ik 分词器用于处理中文分词使用 spring-boot-starter-data-solr 实现增删改查配置用户名密码认证使用 poi 和 pdfbox 组件进行文本内容读取文章最上方有源码和 ik 分词器资源…...

厨余垃圾处理设备工业监控PLC连接APP小程序智能软硬件开发之功能原理篇
接着上一篇《厨余垃圾处理设备工业监控PLC连接APP小程序智能软硬件开发之功能结构篇》继续总结一下厨余垃圾处理设备智能软硬件统的原理。所有的软硬件系统全是自己一人独自开发,看法和角度难免有局限性。希望抛砖引玉,将该智能软硬件系统分享给更多有类…...
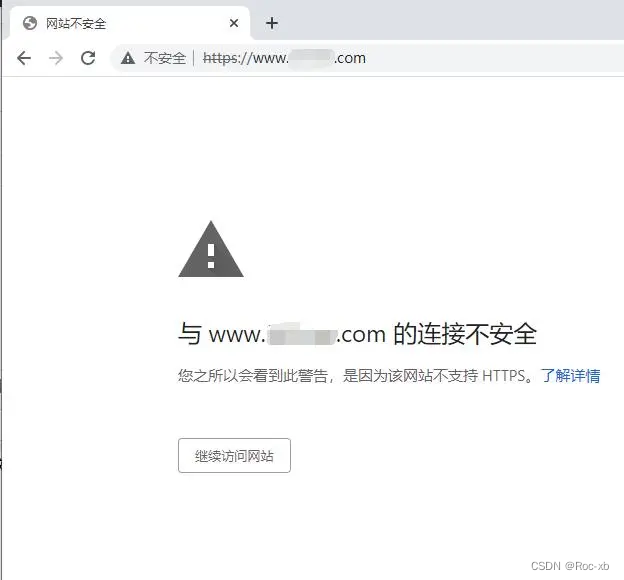
google浏览器网站不安全与网站的连接不安全怎么办?
使用google谷歌浏览器访问某些网站打开时google谷歌浏览器提示网站不安全,与网站的连接不安全,您之所以会看到此警告,是因为该网站不支持https造成的怎么办? 目录 1、打开谷歌google浏览器点击右上角【┇】找到设置...

基于Axios封装请求---防止接口重复请求解决方案
一、引言 前端接口防止重复请求的实现方案主要基于以下几个原因: 用户体验:重复发送请求可能导致页面长时间无响应或加载缓慢,从而影响用户的体验。特别是在网络不稳定或请求处理时间较长的情况下,这个问题尤为突出。 服务器压力…...
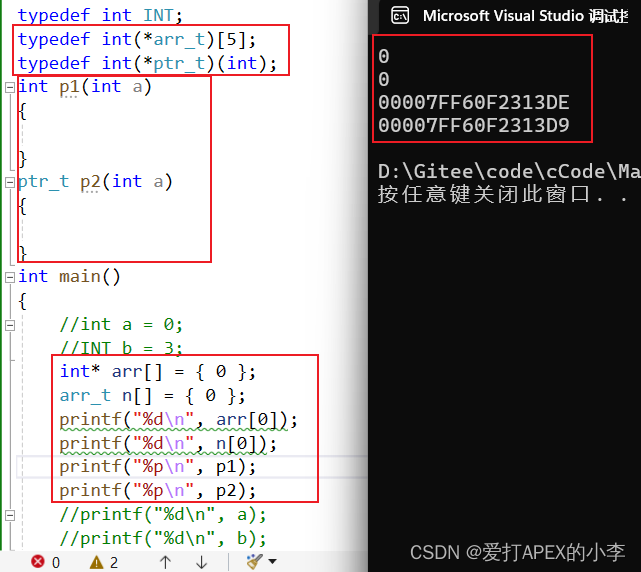
深入理解指针(7)函数指针变量及函数数组(文章最后放置本文所有原码)
一、函数指针变量 什么是函数指针变量呢? 既然是指针变量,那么它指向的一定是地址,而且我们可以通过地址来调用函数的。 函数是否有地址呢?地址是什么? 经过上面的测试可以看到函数也是有地址的,而且其地…...
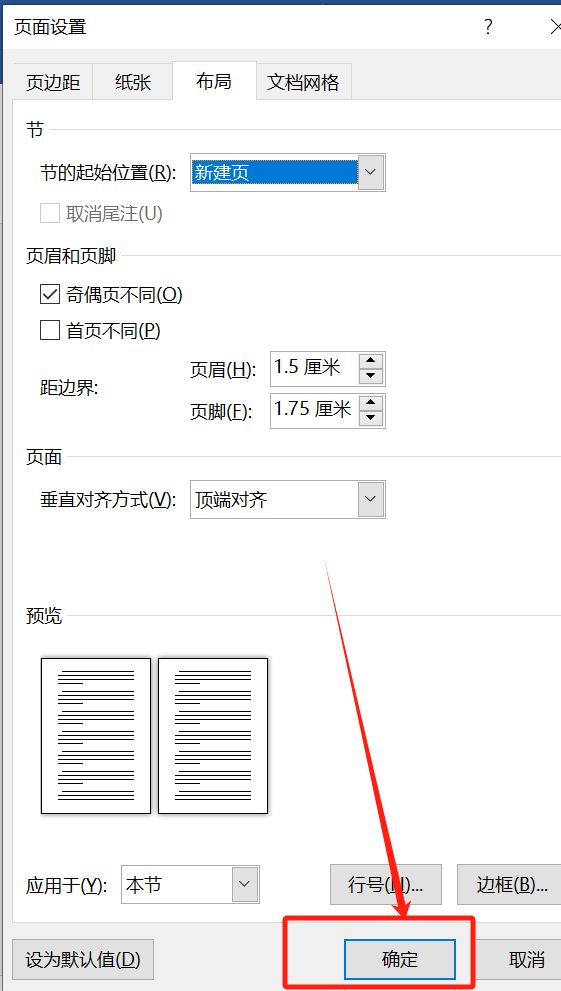
office办公技能|word中的常见使用问题解决方案2.0
一、设置多级列表将表注从0开始,设置为从1开始 问题描述:word中插入题注,出来的是表0-1,不是1-1,怎么办? 写论文时,虽然我设置了“第一章”为一级标题,但是这三个字并不是自动插入的…...

华为2023年年度报告启示:大学生如何把握未来科技趋势,规划个人发展路径
华为2023年年度报告展现了公司在技术创新、生态构建、社会责任等方面的卓越成就与前瞻布局。对于身处数字化时代的大学生而言,这份报告不仅是洞察科技行业发展趋势的窗口,更是规划个人学业与职业道路的重要参考。本文将从报告中提炼关键信息,…...

刚刚,璞华科技、璞华易研PLM产品荣获智能制造领域两大奖项!
刚刚,在e-works数字化企业网于北京举办的“第十三届中国智能制造高峰论坛暨第二十一届中国智能制造岁末盘点颁奖典礼”上,璞华科技凭借在智能制造领域的雄厚实力和产品口碑,荣获两大奖项。 璞华科技被评为e-works【2023年度智能制造优秀供应…...

乐维更改IP地址
1.1 系统IP调整 vim /etc/sysconfig/network-scripts/ifcfg-ens1921.2 Web相关服务IP变更 1.2.1 编辑/itops/nginx/html/lwjkapp/.env文件,更改ZABBIXSERVER、ZABBIXRPCURL、DB_HOST中的IP 1.2.2 进入/itops/nginx/html/lwjk_app/目录下,执行php bin/manager process-conso…...

大话设计模式之简单工厂模式
简单工厂模式(Simple Factory Pattern)是一种创建型设计模式,属于工厂模式的一种。在简单工厂模式中,有一个工厂类负责根据输入参数的不同来创建不同类的实例。 简单工厂模式包含以下几个要素: 1. **工厂类࿰…...
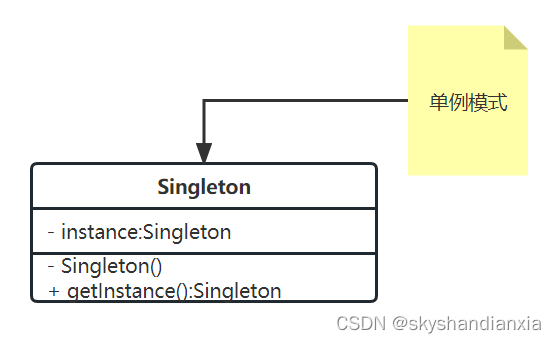
设计模式之单例模式精讲
UML图: 静态私有变量(即常量)保存单例对象,防止使用过程中重新赋值,破坏单例。私有化构造方法,防止外部创建新的对象,破坏单例。静态公共getInstance方法,作为唯一获取单例对象的入口…...

论文复现3:Stable Diffusion v1
abstract: 通过将图像形成过程分解为去噪自动编码器的顺序应用,扩散模型 (DM) 在图像数据及其他方面实现了最先进的合成结果。此外,他们的公式允许一种指导机制来控制图像生成过程,而无需重新训练。然而,由于这些模型通常直接在像素空间中运行,因此强大的 DM 的优化通常会…...

Halcon与VisionMaster对比
作为一个经验丰富的机器视觉算法工程师,我对于机器视觉软件的评价会基于多年的实践经验和对不同软件功能的深入了解。在评价VisionMaster和Halcon软件时,我会从使用场景、工作效率、使用便捷性等方面进行全面分析,并结合软件的优缺点进行讨论…...
多线程的学习1
多线程 线程是操作系统能够进入运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。 进程:是程序的基本执行实体。 并发:在同一个时刻,有多个指令在单个CPU上交替执行。 并行:在同一时刻,…...

警务数据仓库的实现
目录 一、SQL Server 2008 R2(一)SQL Server 的服务功能(二)SQL Server Management Studio(三)Microsoft Visual Studio 二、创建集成服务项目三、配置“旅馆_ETL”数据流任务四、配置“人员_ETL”数据流任…...

Excel·VBA数组分组问题
看到一个帖子《excel吧-数据分组问题》,对一组数据分成4组,使每组的和值相近 目录 代码思路1,分组形式、可分组数代码1代码2代码2举例 2,数组所有分组形式举例 这个问题可以转化为2步:第1步,获取一组数据…...

【笔记】Hbase基础笔记
启动hbase:进入hbase安装目录 输入bin/start-hbase.sh 打开shell命令行模式:进入hbase安装目录 输入bin/hbase shell 退出shell命令行模式:exit 停止hbase:进入hbase安装目录 输入bin/stop-hbase.sh 启动关闭Hadoop和HBase的顺序一…...

创建vue3项目并集成cesium插件运行
创建vue3项目并集成cesium插件 一、vue项目创建 1、前期准备 node.js&npm或yarn 本地开发环境已经安装好。 参考安装 2、安装vue-cli,要求3以上版本 #先查看是否已经安装 vue -V#安装 npm install -g vue/cli4.5.17 示例:Idea工具 页面 Termin…...
Mac 装 虚拟机 vmware、centos7等
vmware: https://www.vmware.com/products/fusion.html centos7 清华镜像: 暂时没有官方的 m1 arm架构镜像 centos7 链接: https://pan.baidu.com/s/1oZw1cLyl6Uo3lAD2_FqfEw?pwdzjt4 提取码: zjt4 复制这段内容后打开百度网盘手机App,操…...
工厂能耗管控物联网解决方案
工厂能耗管控物联网解决方案 工厂能耗管控物联网解决方案是一种创新的、基于先进技术手段的能源管理系统,它深度融合了物联网(IoT)、云计算、大数据分析以及人工智能等前沿科技,以实现对工业生产过程中能源消耗的实时监测、精确计…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...