排序算法超详细代码和知识点整理(java版)
排序
1、冒泡排序
两层循环,相邻两个进行比较,大的推到后面去,一共比较“数组长度”轮,每一轮都是从第一个元素开始比较,每一轮比较都会将一个元素固定到数组最后的一个位置。【其实就是不停的把元素往后堆,数组剩余长度越来越少,直到堆到最后一个,数组都堆好排好序了】
if (arr == null || arr.length < 2) return;
for (int e = arr.length - 1; e > 0; e--) {for (int i = 0; i < e; i++) {if (arr[i] > arr[i + 1]) {swap(arr, i, i + 1); } } }
2、选择排序
也是比较**“数组长度-1”轮,但是每一轮中是将一个最值元素放在开头**,然后从这个更新过元素的位置往后继续开始此轮的选择最值过程【其实就是不停的从选择最小元素,然后往前堆,和冒泡正好相反,然后前面剩余空间越来越少,直到前面都堆好了排好序了】
if (arr == null || arr.length < 2) return;
for(int i=0; i<arr.length - 1; i++){int minIndex = i;for(int j=i+1; j<arr.length; j++){minIndex = arr[j] < arr[minIndex] ? j : minIndex;} swap(arr,i,minIndex);
}
3、插入排序
重点看当前索引指向的元素大小,去对比比当前索引小,也就是前面排好序的那一部分元素。找到合适的位置,然后插进去。这对比的次数明显变少,只用和【索引-1】前面的数进行比较。
if (arr == null || arr.length < 2) return;
for(int i = 1; i<arr.length; i++)for(int j = i-1; arr[j+1]<arr[j] && j >= 0; j--)swap(arr,j,j+1);
4、快速排序
本质是找个基准值,一般可以选取这段数组中的最后一个元素。然后将小于这个基准值的放在其左侧,大于的放在其右侧.
在遍历数组时,一般采用三指针法来实现。具体来说,我们使用一个左指针指向数组的左边界,用一个右指针指向数组的右边界。另外一个指针指向元素,用来遍历。
-
如果当前查找的索引值对应数据 arr [i] 小于基准值,那么这个值和左边界【左指针】的下一个进行交换,同时左指针右移;
-
如果大于基准值,就将其和右边界的前一个元素交换,同时左边界指针不动。索引 i 也不动,但是右指针左移
-
如果等于基准值,索引 i ++

public static void quickSort(int[] arr){if(arr == null || arr.length < 2)return;quickSort(arr,0,arr.length-1);
}public static void quickSort(int[] arr, int l, int r){if(l < r){int[] p = partition(arr,l,r); //作用就是将最后一个元素当作基准值,然后将大于基准值得放右边,小于的放左边//同时,返回一个基准信息,p[0]就是基准值中最左的一个【考虑到可能标志值会重复】,p[1]是最右侧quickSort(arr, l, p[0] - 1);quickSort(arr, p[1] + 1, r);}
}public static void partiton(int[] arr, int l, int r){ //l是左边界,int pivot = arr[r];int left = l -1;int right = r;while(l < right){ //arr[l],就用来记录逐步遍历数组中的元素if(arr[l] < pivot)swap(arr, ++left, l++); // 将小于等于pivot的元素交换到左边界的右侧else if(arr[l] > pivot){swap(arr, --right, l); // 将大小于等于pivot的元素交换到右边界的左侧}elsel++;}swap(arr, more, r); //最后将基准值转移到右指针位置return new int[] { less + 1, more };
}
5、归并排序
将数组按照中间的位置,划分成左右两部分,然后对这两部分进行扫描归并。准备两个指针,分别指向左部分的开头,以及有部分的开头。然后比较大小,按照比较结果,将结果放进一个临时开辟的数组中,最后将这个临时数组的元素再塞回去。
public static void mergeSort(int[] arr){if(arr == null || arr.length < 2)return;mergeSort(arr,0,arr.length-1);
}public static void mergeSort(int[] arr, int l, int r){if(l < r){int mid = l + ((r-l)>>1;mergeSort(arr, l, mid+1);mergeSort(arr, mid+1, r); merge(arr,l,mid,r);}
}public static void merge(int[] arr, int l, int mid, int r) {int[] help = new int[r - l + 1];int i = 0;int p1 = l;int p2 = mid + 1;while(p1 <= mid && p2 <= r){help[i++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];}while (p1 <= m) {help[i++] = arr[p1++];}while (p2 <= r) {help[i++] = arr[p2++];}for (i = 0; i < help.length; i++) {arr[l + i] = help[i];}
}
6、堆排序
主要涉及两步骤:
1、构建堆【heapInsert】,2、输出堆顶元素,然后调整堆结构,以便于下一轮继续输出堆顶元素【heapify】
构建堆的过程就是不停的往上,也就是和自己的父节点、祖父节点…一直比较下去,如果想要大根堆,那就是只要大于父节点,那就和父节点交换,我们对数组的每一个元素都去单独构建一边。
调整堆,就是不停的往下。将堆顶元素和数组最后元素交换,由于当前数组经过构建堆过程后,已经是堆结构了。所以我们的堆顶元素肯定就是一个最值,交换过后,再重新调整堆即可。就是找到堆顶的孩子节点中最大的值,进行比较交换,一直比较到树的最后一层
public static void heapSort(int[] arr) { //这个是主函数,参数中的arr数组中存放的就是待排元素if (arr == null || arr.length < 2) {return;}for (int i = 0; i < arr.length; i++) { //这个函数是用于创建大根堆,为了之后输出堆顶元素就是最大值heapInsert(arr, i);}int size = arr.length; swap(arr, 0, --size); //这一步是为了将堆顶元素和最后一个元素互换位置,注意最后要自减 也就是说最后应该数组中元素是从小到大排序的(如果一开始是一个大根堆)while (size > 0) {heapify(arr, 0, size);swap(arr, 0, --size); //同上面道理}
}
public static void heapInsert(int[] arr, int index) { //这个函数比较好理解,就是一个循环,只要在创建堆结构过程中,新加入堆中的子节点比父节点元素大,就交换,最后形成的是大根堆while (arr[index] > arr[(index - 1) / 2]) {swap(arr, index, (index - 1) /2);index = (index - 1)/2 ; //这一步别忘记了,一直是往下走的,index这个表示父节点位置的标记变量也要向下走}
}
public static void heapify(int[] arr, int index, int size) {//这次函数中参数中要借助 堆的大小size(对应上面主函数中的每次输出一次堆顶元素后,大小减1)int left = index * 2 + 1;while (left < size) {int largest = left + 1 < size && arr[left + 1] > arr[left] ? left + 1 : left;//上面这一步是为了找到左右子节点,哪个最大,然后记录最大的那个下标largest = arr[largest] > arr[index] ? largest : index;if (largest == index) {break;}swap(arr, largest, index);index = largest;left = index * 2 + 1;}
}
public static void swap(int[] arr, int i, int j) { //就是一个交换函数,C++中直接用swap函数即可int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp; }
7、优先级队列
默认是小根堆
//小根堆。默认
PriorityQueue<Integer> heap = new PriorityQueue<>();
-
在左神算法讲解时举了一个例子,就是;
堆排序扩展题目: 已知一个几乎有序的数组,几乎有序是指,如果把数组排好顺序的话,每个元素移动的距离可以不超过k,并且k相对于数组来说比较小。请选择一个合适的排序算法针对这个数据进行排序。这时候就需要借助 堆结构 一开始先将前k个数存放入此优先级队列,也就是堆结构,然后将堆顶元素返回,也就是用pop返回
这k个元素构成一个堆结构,找到这个堆中的小根堆的堆顶元素,就是当前最小的
因为每个元素移动的距离不超过k,所以可以理解为这前k个数中最小的一个属肯也是整体数据中最小的一个数字,把第k+1个数放进去,再次形成小根堆,那返回的堆顶元素就是第二小的元素
然后再重新从数组中取下一个元素,添加到堆中,自动就排好序形成相应的大根堆或者是小根堆
-
下面我用左神算法中的java 代码来展示,其中关键的地方都加了注释了:
public void sortedArrDistanceLessK(int[] arr, int k) {PriorityQueue<Integer> heap = new PriorityQueue<>(); //java中的优先级队列的定义方式int index = 0;for (; index < Math.min(arr.length, k); index++) {//万一k超出范围了,就选取数组长度当作边界值,min()的作用就是这个heap.add(arr[index]);}int i = 0;for (; index < arr.length; i++, index++) {heap.add(arr[index]); //上面那个for循环实际上没有取到第k个元素,所以先取arr[i] = heap.poll(); //然后再弹出堆顶元素}while (!heap.isEmpty()) {//数组最后一个元素也都加进堆结构后,剩下的就是将堆中的所有元素放依次弹出了arr[i++] = heap.poll();}
}
8、复杂度
- 冒泡:时间复杂度o(n^2) 空间复杂度O(1)(原地排序,不需要额外空间)
- 选择:时间复杂度o(n^2) 空间复杂度O(1)(原地排序,不需要额外空间)
- 插入:时间复杂度o(n^2) 空间复杂度O(1)(原地排序,不需要额外空间)
- 快速:时间复杂度o(nlogN) 空间复杂度平均情况下是O(log n),最坏情况下是O(n)。
- 归并:时间复杂度o(nlogN) 空间复杂度O(n)(需要额外的空间来合并子数组)
- 堆 :时间复杂度o(nlogN) 空间复杂度O(1)(原地排序)
相关文章:
排序算法超详细代码和知识点整理(java版)
排序 1、冒泡排序 两层循环,相邻两个进行比较,大的推到后面去,一共比较“数组长度”轮,每一轮都是从第一个元素开始比较,每一轮比较都会将一个元素固定到数组最后的一个位置。【其实就是不停的把元素往后堆&#…...

Java复习第十二天学习笔记(JDBC),附有道云笔记链接
【有道云笔记】十二 3.28 JDBC https://note.youdao.com/s/HsgmqRMw 一、JDBC简介 面向接口编程 在JDBC里面Java这个公司只是提供了一套接口Connection、Statement、ResultSet,每个数据库厂商实现了这套接口,例如MySql公司实现了:MySql驱动…...

Python从零到一构建GPT模型
只用Python和 torch框架,从零到一构建GPT模型,对大语言模型入门,了解GPT的内部网络结构,是一个很好示例。 Build_GPT_from_Scratch.ipynb...

V R虚拟现实元宇宙的前景|虚拟现实体验店加 盟合作|V R设备在线购买
VR(虚拟现实)技术作为一种新兴的技术,正在逐渐改变人们的生活和工作方式。随着技术的不断进步,人们对于元宇宙的概念也越来越感兴趣。元宇宙是一个虚拟世界,通过VR技术可以实现人们在其中进行各种活动和交互。 元宇宙的…...

大话设计模式之策略模式
策略模式是一种行为设计模式,它允许在运行时选择算法的行为。这种模式定义了一族算法,将每个算法都封装起来,并且使它们之间可以互相替换。 在策略模式中,一个类的行为或其算法可以在运行时改变。这种模式包含以下角色࿱…...

蓝桥杯23年第十四届省赛真题-三国游戏|贪心,sort函数排序
题目链接: 1.三国游戏 - 蓝桥云课 (lanqiao.cn) 蓝桥杯2023年第十四届省赛真题-三国游戏 - C语言网 (dotcpp.com) 虽然这道题不难,很容易想到,但是这个视频的思路理得很清楚: [蓝桥杯]真题讲解:三国游戏࿰…...

P15:PATH环境变量
为什么要配置环境变量 当我们打开DOS窗口,输入:javac,出现下面问题。 原因:windows操作系统在当前目录中无法找到javac命令文件。Windows操作系统是如何搜索硬盘上某一个命令? 首先从当前目录中搜索该命令如果当前目录…...
)
math模块篇(七)
文章目录 math.dist(p, q)math.hypot(*coordinates)math.sin(x)math.tan(x)math.degrees(x)math.radians(x)math.acosh(x)math.asinh(x)math.atanh(x) math.dist(p, q) 在Python的math模块中,并没有一个名为math.dist(p, q)的函数。可能你是想要计算两点p和q之间的…...

wordpress插件,免费的wordpress插件
WordPress作为世界上最受欢迎的内容管理系统之一,拥有庞大的插件生态系统,为用户提供了丰富的功能扩展。在内容创作和SEO优化方面,有一类特殊的插件是自动生成原创文章并自动发布到WordPress站点的工具。这些插件能够帮助用户节省时间和精力&…...

Remote Desktop Manager for Mac:远程桌面管理软件
Remote Desktop Manager for Mac,是远程桌面管理的理想之选。它集成了多种远程连接技术,无论是SSH、RDP还是VNC,都能轻松应对,让您随时随地安全访问远程服务器和工作站。 软件下载:Remote Desktop Manager for Mac下载…...

如何撰写研究论文
SEVENTYFOUR/SHUTTERSTOCK 即使对于有经验的作家来说,将数月或数年的研究浓缩到几页纸中也是一项艰巨的任务。作者需要在令人信服地解决他们的科学问题和详细地呈现他们的结果之间找到最佳平衡点,以至于丢失了关键信息。他们必须简明扼要地描述他们的方…...
数据结构
一、栈 先进后出 二、队列 先进先出 三、数组 查询快,增加修改慢 四、链表 查询慢,增加修改慢 五、二叉树 节点: 查找二叉树 二叉查找树的特点 二叉查找树,又称二叉排序树或者二叉搜索树 每一个节点上最多有两个子节点 左子树上所…...
动态规划相关题目
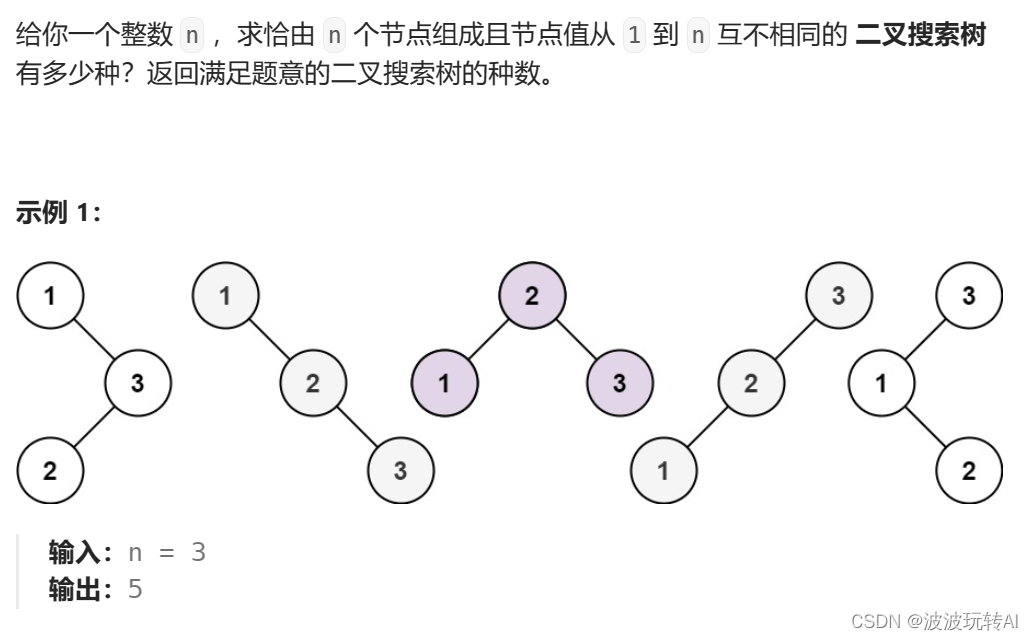
文章目录 1.动态规划理论基础2.斐波那契数3.爬楼梯4.使用最小花费爬楼梯5.不同路径6.不同路径 II7. 整数拆分8. 不同的二叉搜索树 1.动态规划理论基础 1.1 什么是动态规划? 动态规划,英文:Dynamic Programming,简称DP,如果某一…...

iOS - Runtime - Class-方法缓存(cache_t)
文章目录 iOS - Runtime - Class-方法缓存(cache_t)1. 散列表的存取值 iOS - Runtime - Class-方法缓存(cache_t) Class内部结构中有个方法缓存(cache_t),用散列表(哈希表)来缓存曾经调用过的方法,可以提高…...

2014年认证杯SPSSPRO杯数学建模B题(第一阶段)位图的处理算法全过程文档及程序
2014年认证杯SPSSPRO杯数学建模 B题 位图的处理算法 原题再现: 图形(或图像)在计算机里主要有两种存储和表示方法。矢量图是使用点、直线或多边形等基于数学方程的几何对象来描述图形,位图则使用像素来描述图像。一般来说&#…...

【物联网项目】基于ESP8266的家庭灯光与火情智能监测系统——文末完整工程资料源码
目录 系统介绍 硬件配置 硬件连接图 系统分析与总体设计 系统硬件设计 ESP8266 WIFI开发板 人体红外传感器模块 光敏电阻传感器模块 火焰传感器模块 可燃气体传感器模块 温湿度传感器模块 OLED显示屏模块 系统软件设计 温湿度检测模块 报警模块 OLED显示模块 …...

Unity中控制帧率的思考
如何控制帧率: 在Unity中,你可以通过设置Application.targetFrameRate来限制帧率。 例如,如果你想将帧率限制为16帧, 你可以在你的代码中添加以下行: Application.targetFrameRate 16; 通常,这行代码会放在…...

阿里云子域名配置,且不带端口访问
进入阿里云控制台,创建一个SSL证书 # 域名名称child.domain.com创建完成后,将返回主机记录以及记录值,保存好,用于下一步使用 创建DNS解析 创建DNS的TXT类型解析 选择记录类型:TXT 填写主机记录:_dnsa…...

C#-ConcurrentDictionary用于多线程并发字典
ConcurrentDictionary 是 .NET Framework 中用于多线程并发操作的一种线程安全的字典集合类。它提供了一种在多个线程同时访问和修改字典时保持数据一致性的机制。 以下是 ConcurrentDictionary 类的一些重要特性和用法: 线程安全性:ConcurrentDictiona…...

深入探讨多线程编程:从0-1为您解释多线程(下)
文章目录 6. 死锁6.1 死锁原因 6.2 避免死锁的方法加锁顺序一致性。超时机制。死锁检测和解除机制。 6. 死锁 6.1 死锁 原因 系统资源的竞争:(产生环路)当系统中供多个进程共享的资源数量不足以满足进程的需要时,会引起进程对2…...

从旅游Vlog到新闻视频:QVHIGHLIGHTS数据集在跨领域应用中的实战指南
QVHIGHLIGHTS数据集:跨领域视频内容智能解析的工程实践 当你在旅行Vlog中搜索"日落时分的海滩漫步",或在新闻视频中寻找"抗议活动现场冲突画面",传统视频平台只能返回整段视频——这就像给你一整本书而不是精确的页码。Q…...
AgentCPM-Report研报系统实操:Pixel Epic贤者响应延迟优化教程
AgentCPM-Report研报系统实操:Pixel Epic贤者响应延迟优化教程 1. 认识Pixel Epic智识终端 Pixel Epic是一款基于AgentCPM-Report大模型构建的创新研究报告辅助系统。与传统AI工具不同,它将枯燥的科研过程转化为一场像素风格的RPG冒险。在这个系统中&a…...

LangFlow+Ollama快速部署:3步搭建本地AI应用开发环境
LangFlowOllama快速部署:3步搭建本地AI应用开发环境 想快速搭建一个属于自己的AI应用开发环境,但又不想折腾复杂的命令行和配置?今天,我来分享一个极其简单的方法:用LangFlow和Ollama,只需3步,…...
)
10分钟搞定 Nginx 安装:Linux/Windows 双平台实测(附避坑指南)
一、前言上一篇我们初识了Nginx——知道了它是高性能的HTTP和反向代理服务器,懂了它为什么被99%的互联网公司青睐,也明确了我们后续的学习路线。本篇文章将手把手教你在Linux和Windows系统上,完成Nginx的安装、部署、启动、停止 ,…...

5个维度深度评估:哪款内容解锁工具真正值得投入时间?
5个维度深度评估:哪款内容解锁工具真正值得投入时间? 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在数字信息时代,付费墙已成为内容获取的主要障…...

告别手动!用Python+GDAL批量处理GlobeLand30影像:下载、去黑边、镶嵌裁剪全自动
用PythonGDAL打造GlobeLand30全自动处理流水线 遥感影像处理一直是地理信息科学领域的核心工作之一。对于需要处理大范围GlobeLand30数据的科研人员和开发者来说,传统的手动操作不仅效率低下,还容易引入人为错误。想象一下,当你需要处理覆盖整…...

Magisk完整实践指南:从Root权限获取到系统级定制
Magisk完整实践指南:从Root权限获取到系统级定制 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk Magisk作为Android系统Root权限管理的主流解决方案,提供了系统级定制能力而无需修…...

【限时开源】FastAPI 2.0 AI流式SDK v1.0:内置token计数、流控限速、断点续传、前端SSE自动重连——仅开放首批200个GitHub Star领取资格
第一章:FastAPI 2.0 异步 AI 流式响应的核心演进与架构定位FastAPI 2.0 将原生异步流式响应能力从实验性支持升级为一级公民,彻底重构了 AI 应用服务端的实时交互范式。其核心演进体现在对 StreamingResponse 的深度重写、对 ASGI 3.0 协议的精准适配&am…...

STM32环境监测系统在烟花爆竹仓库的应用
1. 项目概述与背景烟花爆竹作为一种特殊商品,其存储环境的安全管理一直是行业痛点。传统的人工巡检方式存在明显的滞后性——我曾亲眼见过一家小型烟花仓库因为夜间温湿度骤变而引发自燃,等值班人员发现时火势已难以控制。这个基于STM32的环境监测系统正…...

解锁Nvidia Tesla A100完整性能:从驱动安装到Fabric Manager服务配置
1. 为什么你的Tesla A100性能被锁住了? 很多朋友第一次拿到Tesla A100显卡时,都会遇到一个奇怪的现象:明明按照常规方法安装了驱动,nvidia-smi也能正常显示显卡信息,但实际跑深度学习训练或者高性能计算任务时…...