矢量数据库:连接人工智能应用程序的数据复杂性与可用性的桥梁
关注我的公众号:Halo咯咯
简介
矢量数据库是一种专门设计的数据库,专注于高效地存储、管理和操作矢量数据。与传统数据库处理标量值(如数字、字符串、日期)不同,矢量数据库针对的是那些表现为多维数据点的向量,这些向量通常由机器学习模型从复杂的数据类型如图像、视频、文本和音频中提取而来。这种多维表示使得矢量数据库能够优化对这类复杂数据的处理,从而在人工智能和大数据分析等应用中发挥关键作用。
矢量数据库的重要性体现在它们能够高效处理和解析非结构化数据的复杂性和细微差异,这在当今数字化世界中变得越来越常见。通过将各类复杂数据类型转换到向量空间中,矢量数据库使得执行相似性搜索等高级操作成为可能。这类搜索能够识别向量空间中与特定查询点“最相似”的数据点。这一功能对于需要实现高精度和高效内容搜索与推荐的应用程序至关重要,例如图像和视频检索系统、个性化推荐引擎以及在大型数据集中执行的高级搜索功能。矢量数据库的这些能力,使得它们成为连接数据复杂性与应用程序可用性的关键工具。

此外,矢量数据库通过其可扩展且高效的数据存储与检索架构,为人工智能和机器学习模型的快速开发及部署提供了强有力的支持。这种能力对于希望借助人工智能技术提升用户体验、增强运营效率以及从复杂数据中挖掘新洞察的企业和开发者来说,具有不可估量的价值。矢量数据库不仅加速了机器学习应用的原型设计和测试过程,还确保了在生产环境中能够实时处理和分析大规模数据集,从而推动了创新和决策的智能化。
矢量数据库通过优化复杂数据类型的高效处理、快速搜索和精准管理,显著推动了创新,并增强了数据驱动领域的能力。在现代应用程序的开发和优化中,它们扮演着至关重要的角色,使得企业和开发者能够充分利用大数据的潜力,实现更智能的决策和更个性化的用户体验。

矢量数据库如何工作
矢量数据库的技术架构专注于高效处理高维数据矢量,这些矢量主要由机器学习模型生成。其核心操作包括为矢量数据量身打造的索引和查询机制,以及机器学习模型在构建这些矢量时发挥的关键作用。通过深入理解这些组成部分,我们可以清晰地看到矢量数据库在搜索和管理工作中涉及的复杂数据类型时所具有的显著优势。

矢量数据库的技术运作确实围绕着高维数据矢量的有效处理,这些矢量大多数是由机器学习模型生成的。为了理解矢量数据库如何在搜索和管理复杂数据类型方面提供显著优势,我们需要深入了解其核心组件和运作机制:
-
机器学习模型与矢量生成:机器学习模型,特别是深度学习模型,能够将非结构化数据(如图像、文本和音频)转换为高维矢量。这些矢量是数据的数值表示,它们捕捉了数据中的复杂模式和特征。
-
索引机制:矢量数据库使用特殊的索引技术来优化矢量数据的搜索效率。这些索引技术包括向量索引(如IVFADC、HNSW)、倒排索引和哈希索引等。它们允许数据库快速识别和检索与查询矢量相似的矢量,即使是在包含数百万或数十亿矢量的数据集中。
-
查询优化:矢量数据库提供查询优化工具和算法,以确保快速准确地检索数据。这些优化可能包括查询矢量的预处理、索引的选择和调整,以及查询执行计划的优化。
-
存储优化:为了高效地存储大量矢量数据,矢量数据库采用各种压缩技术,如Product Quantization (PQ) 和 Scalar Quantization (SQ),以减少存储空间的需求,同时保持检索性能。
-
并行处理和分布式架构:矢量数据库通常设计为支持并行处理和分布式计算,这使得它们能够处理大规模数据集和实时查询,同时保持高性能和可扩展性。
-
集成和兼容性:矢量数据库通常提供API和工具,以便与主流的数据处理和机器学习框架集成,如Python的Pandas、NumPy,以及深度学习框架TensorFlow和PyTorch。
通过这些技术运作,矢量数据库为机器学习应用提供了强大的支持,使得复杂数据类型的管理和搜索变得高效和可扩展。这不仅加速了开发过程,还提高了最终应用程序的性能和用户体验。
使用机器学习模型生成向量
该过程始于将非结构化数据,如图像、文本或音频,转换为高维向量。这一转换通过机器学习模型,尤其是深度学习网络来实现,这些网络能够分析数据并将其映射到一个多维向量空间中。在这个空间中,每个向量都是数据点特征的数值表示,向量间的数值距离反映了数据点之间的相似性。例如,在文本分析领域,诸如Word2Vec或BERT之类的词嵌入模型被用来将文本转换为向量,使得语义上相近的单词在向量空间中彼此接近。这种转换不仅保留了单词的语义信息,而且还允许计算机以数值方式处理和理解语言,从而为各种下游任务,如文本分类、情感分析和机器翻译,提供了强大的基础。
向量数据库中的索引
一旦数据被转换成向量,索引就成为组织这些向量并实现高效检索的关键环节。传统的索引方法可能并不适用于高维数据,因为它们可能无法有效地处理这种复杂性。相比之下,矢量数据库采用了专为高维空间设计的先进索引技术,包括:
- 基于树的索引:例如KD树或球树,这些结构通过将向量空间划分为多个区域来优化搜索过程。它们通过逐级细化搜索范围,快速定位到目标区域,从而加快了搜索速度。
- 基于散列的索引:如局部敏感散列(LSH),这种技术通过减少维度来简化搜索过程。它将相似的向量散列到相同的存储桶中,这样可以在保持高效性的同时,减少搜索所需的时间和资源。
- 基于图的索引:例如可导航小世界(NSW)或分层可导航小世界(HNSW)图,这些索引使用图结构来连接向量。通过图结构的导航,可以在高维空间中实现快速而精确的搜索。
这些索引技术使得矢量数据库在处理和检索高维数据时表现出色,为用户提供了快速、准确的搜索体验,极大地提高了数据处理的效率和效果。
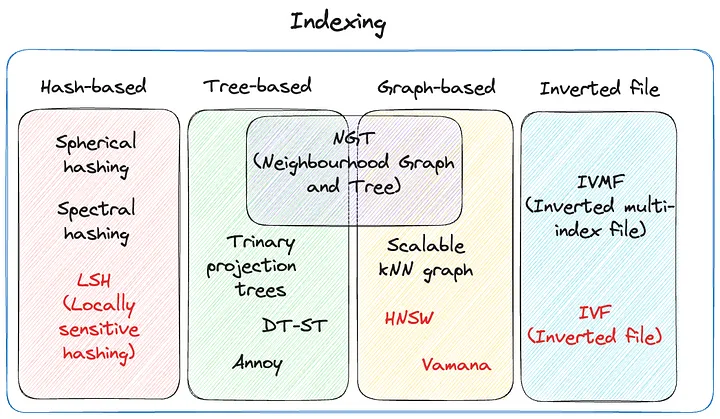
这些索引技术旨在优化搜索准确性和查询速度之间的平衡,通常允许可调参数以满足特定应用程序的需求。
在向量数据库中查询
在向量数据库中,查询操作的核心目标是识别与给定查询向量在特征上最为接近的向量。这一过程,称为相似性搜索或最近邻搜索,依赖于特定的距离度量方法,如欧几里得距离或余弦相似性,来评估查询向量与数据库中存储的向量之间的相似程度。
- k-最近邻 (k-NN) 搜索:该方法旨在找出与查询向量距离最近的前k个向量。这些向量代表了数据库中与查询向量最为相似的数据点,基于距离度量,它们可以为用户呈现最相关的结果。
- 范围查询:此类型的查询专注于检索所有与查询向量距离小于或等于某个预定义阈值的向量。这种方法适用于用户希望获取与查询向量在特定相似度范围内的所有数据点的情况。
通过这些查询机制,向量数据库能够高效地处理复杂的数据检索任务,为用户提供精确且相关的信息。这些技术的应用范围广泛,从推荐系统到图像识别,再到数据挖掘和分析,都体现了向量数据库在现代数据驱动环境中的关键作用。
机器学习模型的作用
机器学习模型在矢量数据库中扮演着核心角色,主要体现在以下两个方面:
- 特征提取:机器学习模型负责从原始数据中提炼出有意义的特征,并将其转换成向量形式。这些向量的质量对于相似性搜索的效果至关重要,因为它们直接决定了搜索结果的相关性和准确性。
- 持续学习:在一些先进的系统中,矢量数据库能够与机器学习模型形成反馈循环。这意味着,随着新数据的加入和查询模式的变化,模型可以不断地进行自我优化和调整,以提高其性能和适应性。
矢量数据库的技术架构——从利用机器学习模型生成高质量的向量,到采用复杂的索引技术来组织这些向量,再到实施高效的查询机制——共同构成了其处理复杂、非结构化数据的能力。这些技术的综合应用使得矢量数据库在需要进行深入数据分析和精确检索的应用场景中显得尤为宝贵。
什么是Embeddings?
Embeddings技术是机器学习和人工智能领域的一个基础性概念,尤其适用于处理和理解高维数据,如文本、图像、声音以及复杂的结构化数据。Embeddings的核心在于将这些高维数据映射到一个固定维度(通常较低)的向量空间中,同时尽可能地保留原始数据中的上下文或含义。
这种从高维到低维的转换不仅有助于简化数据结构,还能够揭示数据点之间的空间关系。这样的表示方法使得原本复杂的数据变得更加易于分析和处理,因为向量之间的相似性和差异性可以通过简单的数学运算(如距离计算)来衡量和比较。
Embeddings技术的应用极大地提高了处理非结构化数据的效率,并为我们提供了深入数据内部结构的洞察力。通过这种方式,机器学习模型能够更好地理解和处理复杂的数据集,推动了人工智能在各个领域的应用和发展。
Embeddings技术通过将数据从高维空间映射到低维向量空间,实现了一种有效的数据表示方法。这种映射策略是精心设计的,目的是保持高维空间中相似数据点在低维向量空间中的邻近性。例如,在文本嵌入的应用中,语义上相近的单词会被映射到嵌入空间中彼此接近的向量位置。
这种映射的关键优势在于,它使得算法能够捕捉并理解数据中的语义关系。在传统的数字或分类数据表示中,这些关系往往难以捕捉和表达。嵌入空间中的向量能够揭示单词、短语或其他数据片段之间的微妙联系,从而为机器学习模型提供了更丰富的信息,使其能够更准确地执行分类、聚类、推荐等任务。
此外,Embeddings的使用还有助于提高计算效率,因为低维向量相比于原始高维数据更容易处理。这使得算法能够更快地进行学习和推理,同时保持对数据内在结构的高度敏感性。因此,Embeddings技术在自然语言处理、图像识别、推荐系统等多个人工智能领域中都发挥着至关重要的作用。
向量Embeddings: 深入探讨
向量Embeddings是一种将原始高维数据转换为低维向量空间的技术,这种转换不仅减少了数据的维度,而且通过复杂的编码过程捕获了数据的本质特征和上下文关系。这一过程对于矢量数据库的功能至关重要,因为它直接影响到数据库执行有效相似性搜索的能力。
向量Embeddings的生成是通过学习模型实现的,这些模型将数据点映射到向量上,使得这些向量之间的空间关系能够反映原始数据的语义或上下文关系。这一映射过程通常涉及对大型数据集的训练,模型在训练过程中调整参数,以确保相似的数据项在向量空间中的距离更近,而不相似的数据项则相隔较远。
在文本数据中,Embeddings通常是通过Word2Vec、GloVe、BERT或GPT等模型生成的。这些模型通过分析大规模文本语料库,学习如何将具有相似含义的单词映射到向量空间中彼此接近的位置。这一过程涉及到理解单词的上下文用法,识别同义词、反义词的细微差别,以及不同上下文中的多样用法。
对于图像数据,卷积神经网络(CNN)常用于生成图像嵌入。通过多层卷积滤波器,模型学习识别图像中的各种模式和特征,如边缘、纹理或更复杂的对象,并将这些特征编码为紧凑的向量表示。
同样地,对于音频、视频以及结构化数据等其他类型的数据,也可以使用专门针对这些数据特征定制的深度学习架构来创建Embeddings。这些Embeddings技术使得矢量数据库能够高效地处理和分析各种复杂的、非结构化的数据,为用户提供强大的数据分析和搜索能力。
向量数据库中向量Embeddings的重要性
向量Embeddings在矢量数据库中的强大之处体现在它们能够促进在大型数据集上进行高效的相似性搜索。与传统的基于精确匹配或关键字的搜索方法相比,矢量Embeddings能够捕捉到非结构化数据的复杂性和多维性,从而提供更为精细的相似性概念。
- 语义搜索的实现:向量Embeddings使得搜索引擎能够基于查询和数据库项目的语义和上下文进行理解,而不仅仅是它们的表面特征。这种语义搜索在内容推荐系统中尤为重要,它能够根据用户的偏好或兴趣找到“相似”的项目。
- 可扩展性和效率:通过将高维数据转换为低维向量,同时保留其语义信息,向量Embeddings使得在庞大的数据集中执行相似性搜索变得可行。这种效率在需要快速响应的环境中尤为关键,如实时推荐系统或大规模信息检索系统。
- 跨领域的多功能性:向量Embeddings的适用性跨越了多个领域,包括自然语言处理(NLP)、计算机视觉以及异常检测等。这种多功能性突显了矢量Embeddings在支持需要理解复杂数据关系的人工智能应用中的核心作用。
向量Embeddings是数据表示和机器学习领域的交汇点,为向量数据库构建其核心功能提供了基础。通过实现高效的相似性搜索和深入的数据语义理解,嵌入技术支持了广泛的应用,并推动了人工智能的发展,提供了前所未有的见解。随着嵌入生成技术和架构的不断进步,向量数据库的潜力和应用范围也在不断扩展,体现了该领域的活力和变革性。
向量数据库的应用
矢量数据库以其处理和搜索高维矢量数据的能力,在多个领域中发挥着重要作用。它们的核心优势在于执行相似性搜索的能力,这使得它们对于需要深入理解和处理复杂数据类型的应用场景来说极其宝贵。以下是矢量数据库的一些关键应用:
- 推荐系统:矢量数据库通过高效检索与用户兴趣或行为最相似的项目,支持个性化推荐系统。用户配置文件和商品通过向量表示,使得系统能够快速匹配符合用户喜好的产品。
- 搜索引擎:在处理非结构化数据如图像和视频的搜索引擎中,矢量数据库通过内容进行搜索,提高了搜索结果的准确性和相关性。
- 欺诈识别:通过识别交易或用户活动中的异常模式,矢量数据库有助于检测欺诈行为,保护企业和用户免受损失。
- 自然语言处理:矢量数据库在自然语言处理领域中,通过词嵌入技术,使得文本数据可以基于语义相似性进行比较和检索,支持情感分析、主题建模等应用。
- 生物信息学:在生物信息学中,矢量数据库用于分析基因序列和蛋白质结构,帮助研究人员发现功能关系和进化模式。
- 计算机视觉:矢量数据库使得图像和视频内容的高效存储和检索成为可能,支持面部识别和对象检测等应用。
- 市场分析和消费者洞察:通过分析消费者反馈和社交媒体数据,矢量数据库帮助企业捕捉市场趋势和消费者偏好,优化产品和营销策略。
- 异常检测:在网络安全和系统监控中,矢量数据库通过识别与正常模式的偏差来检测潜在的安全威胁或系统故障。
这些应用展示了矢量数据库在处理复杂数据分析任务方面的多功能性和实用性。通过提供高效、精确的相似性搜索,矢量数据库极大地扩展了系统处理、分类和预测数据的能力,超越了传统数据库的限制。
向量数据库的选择

在为项目选择合适的矢量数据库时,需要综合考虑多个因素,以确保所选的数据库能够满足项目的数据管理和检索需求。以下是在选择过程中应考虑的主要因素:
1. 可扩展性:
- 水平与垂直扩展:评估数据库是否支持通过增加更多节点或增强现有节点来扩展能力。水平扩展通过增加计算节点来实现,而垂直扩展则涉及增强单个节点的性能。
- 数据量增长:确保所选数据库能够适应预期的数据增长,同时保持或仅轻微影响性能。
2. 性能:
- 查询延迟:考虑数据库返回查询结果所需的平均时间,尤其是对于需要实时数据检索的应用。
- 吞吐量:评估数据库能够处理的查询数量,特别是对于高并发查询的场景。
- 索引效率:数据库的索引机制应高效,特别是在处理高维向量空间时。
3. 易用性:
- API和查询语言:选择提供易于使用的API和直观查询语言的数据库,以便快速开发和集成。
- 与现有工具的集成:检查数据库是否容易与项目中使用的其他工具和框架集成。
- 管理和维护:考虑数据库的设置、部署、监控和维护的复杂性。
4. 机器学习模型支持:
- 与ML模型集成:由于矢量数据库通常与机器学习模型配合使用,评估数据库对ML框架的集成支持程度。
- 持续学习:对于需要不断优化的项目,选择支持持续学习的数据库。
5. 安全与合规性:
- 数据安全功能:确保数据库提供足够的安全措施,如加密和访问控制。
- 监管合规性:对于受法规约束的项目,确保数据库符合相关的数据保护和隐私要求。
6. 社区和供应商支持:
- 社区支持:一个活跃的社区可以提供帮助和资源,有利于项目的长期成功。
- 供应商支持:对于商业数据库,考虑供应商提供的支持水平和服务质量。
在选择矢量数据库时,仔细权衡这些因素将帮助您找到最适合您项目需求的解决方案,并确保数据库能够随着项目的发展而扩展。
!pip -q install chromadb openai langchain tiktokenimport osos.environ['OPENAI_API_KEY'] = ""from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.document_loaders import DirectoryLoader
from langchain.document_loaders import TextLoader!pip install tensorflow datasets
!pip install tensorflow-datasetsimport tensorflow_datasets as tfds# Load the dataset
dataset, info = tfds.load('imdb_reviews', with_info=True, as_supervised=True)# Select a subset for demonstration, for instance, the training set
train_data = dataset['train'].take(1000) # Adjust the number as needed# Example preprocessing function
def preprocess_text(text):# Assuming `text` is a TensorFlow tensor, convert it to a stringtext = text.numpy().decode('utf-8')# Apply any specific preprocessing steps herereturn text# Initialize a list to store preprocessed texts
texts = []for text_tensor, _ in train_data:text = preprocess_text(text_tensor)texts.append(text)# Now `texts` contains preprocessed reviewsprint(texts)
combined_reviews = "\n".join(texts)
# Calculate the length to slice (50%)
slice_length = len(combined_reviews) // 2# Slice the string
half_combined_reviews = combined_reviews[:slice_length]# Print the sliced part
print(half_combined_reviews)# Define the path and name of the file where you want to save the text
file_path = "/content/combined_reviews.txt"# Write the combined_reviews string to a file
with open(file_path, "w") as text_file:text_file.write(half_combined_reviews)print(f"Text has been written to {file_path}")loader = DirectoryLoader("/content/", glob = "./*.txt", loader_cls= TextLoader)
document = loader.load()
documentfrom langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1000, chunk_overlap = 200)
text = text_splitter.split_documents(document)
textfrom langchain import embeddings
persist_directory = 'db'embedding = OpenAIEmbeddings()vectordb = Chroma.from_documents(documents=text,embedding=embedding,persist_directory=persist_directory)vectordb.persist()
vectordb = Noneretriever = vectordb.as_retriever()docs = retriever.get_relevant_documents("I also thought Rachel was terrifically fresh and funny in these scenes.")len(docs)docs这段代码展示了一个完整的流程,从加载文本数据集开始,经过预处理、生成文本嵌入,最终使用这些嵌入来支持矢量数据库,并基于语义相似性进行文档检索。下面是对代码各个部分的详细解释:
1. 设置和数据加载:
- 安装所需库:脚本首先安装了必要的Python库,如`chromadb`、`openai`、`langchain`、`tiktoken`等,这些库用于访问矢量数据库、生成嵌入和处理文本数据。同时,安装了TensorFlow和TensorFlow Datasets用于加载数据集。
- OpenAI API 密钥:设置了环境变量以存储OpenAI API密钥,这是使用OpenAI服务(如生成嵌入)所必需的。
- 加载 IMDb 评论数据集:使用TensorFlow Datasets加载IMDb评论数据集,并从中选择了前1000个示例进行处理。
2. 文本预处理:
- 预处理文本数据:定义了一个函数来对文本张量进行解码和预处理,以便后续处理。
- 组合和切片评论:将预处理后的文本评论合并为一个长字符串,然后切片只保留前半部分内容,并将其保存到文本文件中,模拟处理大型文档的过程。
3. 从目录加载文档:
- 目录加载器初始化:尽管代码中提到了从目录加载文档,但实际上前面的步骤并没有涉及将评论保存为单独的文件,这可能是一个概念上的错误。
4. 文件分割:
- 将文本拆分为块:使用`langchain`中的`RecursiveCharacterTextSplitter`将大文本拆分为更小的块,以适应语言模型的输入长度限制。
5. 生成嵌入和矢量数据库创建:
- 嵌入生成:初始化`OpenAIEmbeddings`来生成文本输入的嵌入。
- 使用 Chroma 创建矢量数据库:通过`Chroma`类创建矢量数据库,将每个文档块嵌入并保存在指定目录中。
6. 文件检索:
- 相关文档的检索:将`vectordb`转换为检索器,根据嵌入的语义相似性查找与查询字符串相关的文档。
- 查询和检索:使用示例文本作为查询,通过检索器找到语义相关的文档。
这个流程展示了如何使用现代工具和技术来处理和检索文本数据,特别是在需要理解文档语义相似性的场景中。通过这种方式,可以有效地管理和查询大量的非结构化文本数据。
如果觉得文章对你有帮助,欢迎点赞+关注~
相关文章:
矢量数据库:连接人工智能应用程序的数据复杂性与可用性的桥梁
关注我的公众号:Halo咯咯 简介 矢量数据库是一种专门设计的数据库,专注于高效地存储、管理和操作矢量数据。与传统数据库处理标量值(如数字、字符串、日期)不同,矢量数据库针对的是那些表现为多维数据点的向量…...

docker:can’t create unix socket /var/run/docker.sock: is a directory
docker:can’t create unix socket /var/run/docker.sock: is a directory 原因:docker.sock不能创建 解决方式: rm -rf /var/run/docker.sock 然后重新启动docker Docker是一种相对使用较简单的容器,我们可以通过以下几种方式获取信息&…...

Qt 图形视图 /图形视图框架坐标系统的设计理念和使用方法
文章目录 概述Qt 坐标系统图形视图的渲染过程Item图形项坐标系Scene场景坐标系View视图坐标系map坐标映射场景坐标转项坐标视图坐标转图形项坐标图形项之间的坐标转换 其他 概述 The Graphics View Coordinate System 图形视图坐标系统是Qt图形视图框架的重要组成部分…...

视频号小店类目资质如何申请?新手看一遍就懂了!
我是电商珠珠 大家在视频号小店后台新增商品的时候,需要先完成类目资质的申请,通过后才可以上架相关商品。 而类目资质分为普通类目和特殊类目,如果你所上架的商品属于开放类目,那么就去按照普通类目资质去申请。 如果是定向准…...
整合SpringSecurity+JWT实现登录认证
一、关于 SpringSecurity 在 Spring Boot 出现之前,SpringSecurity 的使用场景是被另外一个安全管理框架 Shiro 牢牢霸占的,因为相对于 SpringSecurity 来说,SSM 中整合 Shiro 更加轻量级。Spring Boot 出现后,使这一情况情况大有…...
C# Onnx Yolov9 Detect 物体检测
目录 介绍 效果 项目 模型信息 代码 下载 C# Onnx Yolov9 Detect 物体检测 介绍 yolov9 github地址:https://github.com/WongKinYiu/yolov9 Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information…...

Flink SQL 基于Update流出现空值无法过滤问题
问题背景 问题描述 基于Flink-CDC ,Flink SQL的实时计算作业在运行一段时间后,突然发现插入数据库的计算结果发生部分主键属性发生失败,导致后续计算结果无法插入, 超过失败次数失败的情况问题报错 Caused by: java.sql.BatchUp…...

git-怎样把连续的多个commit合并成一个?
Git怎样把连续的多个commit合并成一个? Git怎样把连续的多个commit合并成一个? 参考URL: https://www.jianshu.com/p/5b4054b5b29e 查看git日志 git log --graph比如下图的commit 历史,想要把bai “Second change” 和 “Third change” 这…...

2024年2月游戏手柄线上电商(京东天猫淘宝)综合热销排行榜
鲸参谋监测的线上电商(京东天猫淘宝)游戏手柄品牌销售数据已出炉!2月游戏手柄销售数据呈现出强劲的增长势头。 根据鲸参谋数据显示,今年2月游戏手柄月销售量累计约43万件,同比去年上涨了78%;销售额累计达1…...

Sass5分钟速通基础语法
前言 近来在项目中使用sass,想着学习一下,但官方写的教程太冗杂,所以就有了本文速通Sass的基础语法 Sass 是 CSS 的一种预编译语言。它提供了 变量(variables)、嵌套规则(nested rules)、 混合(mixins) 等…...

百度蜘蛛池平台在线发外链-原理以及搭建教程
蜘蛛池平台是一款非常实用的SEO优化工具,它可以帮助网站管理员提高网站的排名和流量。百度蜘蛛池原理是基于百度搜索引擎的搜索算法,通过对网页的内容、结构、链接等方面进行分析和评估,从而判断网页的质量和重要性,从而对网页进行…...

Android_ android使用原生蓝牙协议_连接设备以后,给设备发送指令触发数据传输---Android原生开发工作笔记167
之前通过蓝牙连接设备的时候,直接就是连接上蓝牙以后,设备会自动发送数据,有数据的时候,会自动发送,但是,有一个设备就不会,奇怪了很久,设备启动了也连接上了,但是就是没有数据过来. 是因为,这个设备有几种模式是握力球,在设备连接到蓝牙以后,需要,给设备通过蓝牙发送一个指令…...
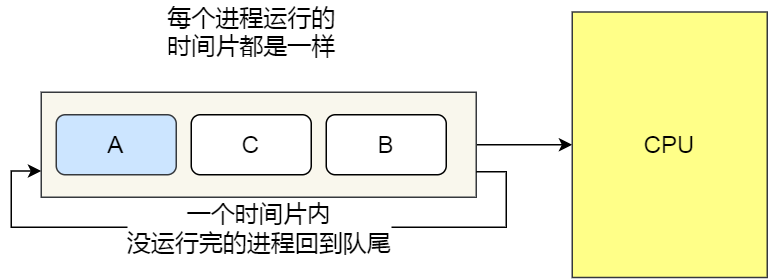
【Java面试题】操作系统
文章目录 1.进程/线程/协程1.1辨别进程和线程的异同1.2优缺点1.2.1进程1.2.2线程 1.3进程/线程之间通信的方法1.3.1进程之间通信的方法1.3.2线程之间通信的方法 1.4什么是线程上下文切换1.5协程1.5.1协程的定义?1.5.2使用协程的原因?1.5.3协程的优缺点&a…...

SQLite数据库成为内存中数据库(三)
返回:SQLite—系列文章目录 上一篇:SQLite使用的临时文件(二) 下一篇:SQLite中的原子提交(四) SQLite数据库通常存储在单个普通磁盘中文件。但是,在某些情况下,数据库可能…...

多张图片怎么合成一张gif?快来试试这个方法
将多张图片合成一张gif动图是现在常见的图像处理的方式,适合制作一些简单的动态图片。通过使用在线图片合成网站制作的gif动图不仅体积小画面丰富,画质还很清晰。不需要下载任何软件小白也能轻松上手,支持上传jpg、png以及gif格式图片&#x…...

爬取b站音频和视频数据,未合成一个视频
一、首先找到含有音频和视频的url地址 打开一个视频,刷新后,找到这个包,里面有我们所需要的数据 访问这个数据包后,获取字符串数据,用正则提取,再转为json字符串方便提取。 二、获得标题和音频数据后&…...

mysql进阶知识总结
1.存储引擎 1.1MySQL体系结构 1).连接层 最上层是一些客户端和链接服务,包含本地sock通信和大多数基于客户端/服务端工具实现的类似于TCP/IP的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证…...
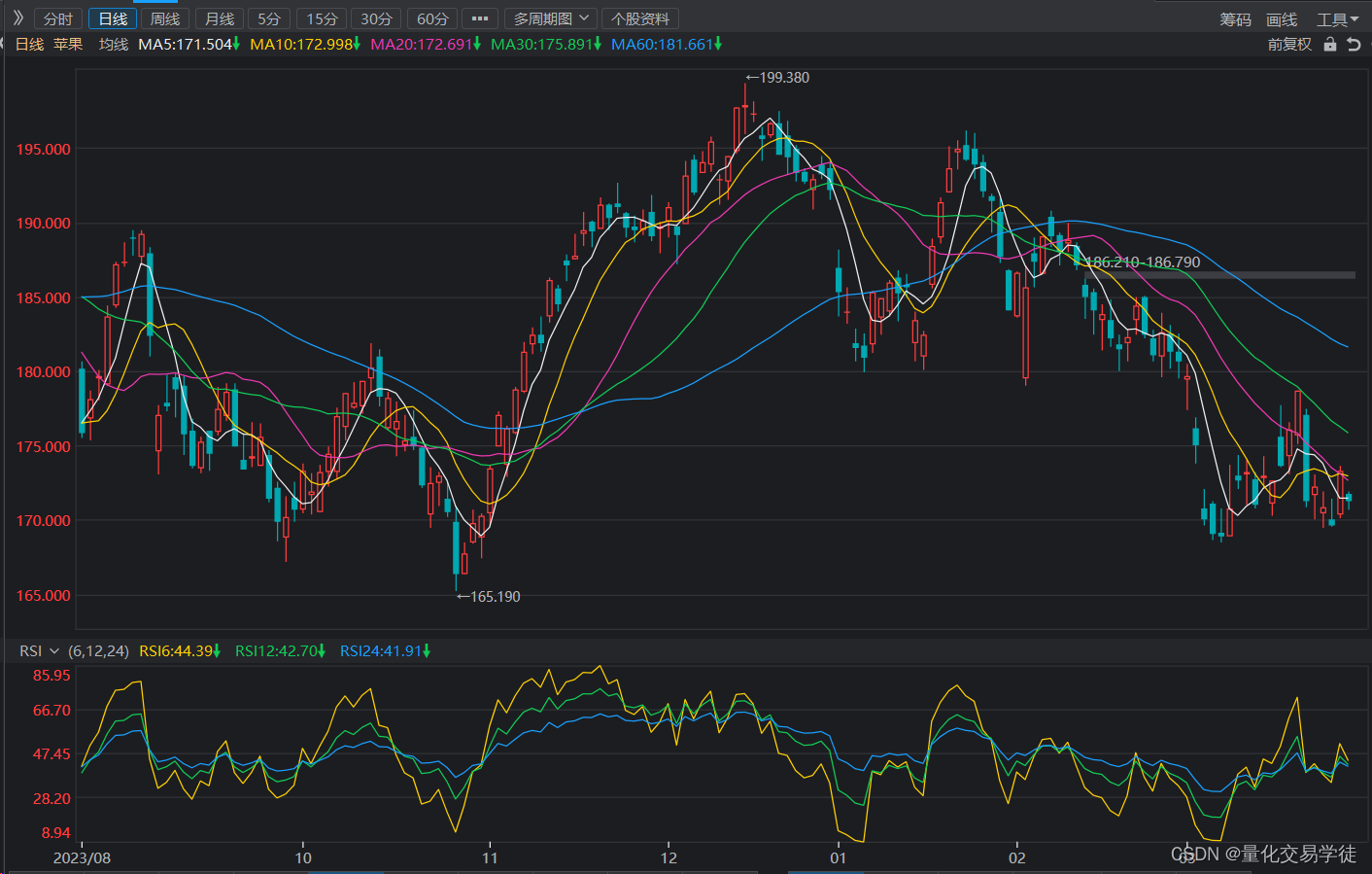
量化交易入门(二十五)什么是RSI,原理和炒股实操
前面我们了解了KDJ,MACD,MTM三个技术指标,也进行了回测,结果有好有坏,今天我们来学习第四个指标RSI。RSI指标全称是相对强弱指标(Relative Strength Index),是通过比较一段时期内的平均收盘涨数和平均收盘跌数来分析市…...

快速上手Spring Cloud 九:服务间通信与消息队列
快速上手Spring Cloud 一:Spring Cloud 简介 快速上手Spring Cloud 二:核心组件解析 快速上手Spring Cloud 三:API网关深入探索与实战应用 快速上手Spring Cloud 四:微服务治理与安全 快速上手Spring Cloud 五:Spring …...

python——遍历网卡并禁用/启用
一、遍历网卡 注意:只能遍历到启用状态的网卡,如果网卡是禁止状态,则遍历不到!!! import os import time import psutil import loggingdef get_multi_physical_network_card():physical_nic_list []try:…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

数学建模-滑翔伞伞翼面积的设计,运动状态计算和优化 !
我们考虑滑翔伞的伞翼面积设计问题以及运动状态描述。滑翔伞的性能主要取决于伞翼面积、气动特性以及飞行员的重量。我们的目标是建立数学模型来描述滑翔伞的运动状态,并优化伞翼面积的设计。 一、问题分析 滑翔伞在飞行过程中受到重力、升力和阻力的作用。升力和阻力与伞翼面…...

CppCon 2015 学习:Reactive Stream Processing in Industrial IoT using DDS and Rx
“Reactive Stream Processing in Industrial IoT using DDS and Rx” 是指在工业物联网(IIoT)场景中,结合 DDS(Data Distribution Service) 和 Rx(Reactive Extensions) 技术,实现 …...

算法刷题-回溯
今天给大家分享的还是一道关于dfs回溯的问题,对于这类问题大家还是要多刷和总结,总体难度还是偏大。 对于回溯问题有几个关键点: 1.首先对于这类回溯可以节点可以随机选择的问题,要做mian函数中循环调用dfs(i&#x…...