构建操作可靠的数据流系统
文章目录
- 前言
- 数据流动遇到的困难
- 先从简单开始
- 可靠性
- 延迟
- 丢失
- 性能
- 性能损失
- 性能——分层重试
- 可扩展性
- 总结
前言
- 在流式架构中,任何对非功能性需求的漏洞都可能导致严重后果。如果数据工程师没有将可伸缩性、可靠性和可操作性等非功能性需求作为首要考虑因素来构建系统,他们将花费大量时间来处理问题和保持系统运行。如果你没有将这些“ility”作为系统的第一类公民来构建,你将支付高昂的运营成本。
- 要构建可靠的流式数据管道,可以将流式管道概念化为一系列事务性链路。这些链路通过 Kafka 主题连接,每个主题都提供事务性保证。一旦将这些链路组合起来,整个管道就会是事务性的。
- 对于任何流式数据管道来说,最重要的两个顶级指标是延迟和丢失。延迟表示系统中消息的延迟量。丢失则衡量了消息在系统中传输时的丢失程度。
- 大多数流式数据用例需要低延迟,但它们也需要低或零丢失。重要的是要理解,构建无丢失的管道时存在性能损失。为了实现零丢失,你需要牺牲一些速度。然而,有一些策略可以在一组消息中最小化延迟(例如通过并行处理增加吞吐量)。通过这样做,我们可能会有一个延迟下限,但我们仍然可以最大化吞吐量。
- 自动扩展是最大化吞吐量的关键。在选择自动扩展的指标时,确保选择一个随着流量增加而增加,随着规模扩展而减少的指标。平均 CPU 使用率通常就足够了。
在当今世界,机器学习和个性推荐驱动着引人入胜的在线体验。无论是搜索引擎的排名系统,推荐音乐或电影的推荐系统,还是在你选择的社交平台上重新排名的排名系统。不同的数据不断被连接起来,以驱动预测,提升用户浏览兴趣。随着数据增长使得将所有这些数据存储在单个DB中变得不切实际。十年前,我们使用单一的单机数据库来存储数据,但是今天,下图更能代表我们所看到的现代数据架构:
这是由许多个可移植的数据服务连接在一起从点到面的解决方案,但同时也增加了架构的复杂性。上图的关键就是数据流动,通常有两种形式:批处理和流处理。
数据流动遇到的困难
上面的图片涉及许多不同的组件,组件越多就意味着出错的可能性越大。在流式架构中,如果在非功能性需求方面存在任何差距,那么后果可能非常严重。如果数据工程师们不将“ilities”作为第一类公民来构建这些系统,他们将花费大量时间应对问题并保持系统的运行;这里的“ilities”指的是可扩展性( scalability)、可靠性(reliability)、可观察性(observability)、可操作性(operability)等非功能性需求。如果数据团队不讲上边的非功能需求作为数据架构设计的第一指标,那么将会为数据系统的不可用和中断等问题付出极大的运营成本。
先从简单开始
任何复杂的问题,都可以从一个简单的例子说起:
构建一个从数据源 S 到 数据源 D 发送消息的系统。
首先,让我们通过在 S 和 D 之间引入消息中间 Kafka 件来解耦它们。在这个系统中,我创建了一个称为 E 的单一主题,用来表示将通过该主题流动的事件。我通过这个事件主题解耦了 S 和 D。这意味着如果 D 失败,S 仍然可以继续向 E 发布消息。如果 S 失败,D 仍然可以继续从 E 消费消息。
将我们的服务S 和 D 运行起来,为了提升系统的可靠性,将 kafka 的副本数设置为 3。
可靠性
可靠性最直接的体现:0消息丢失
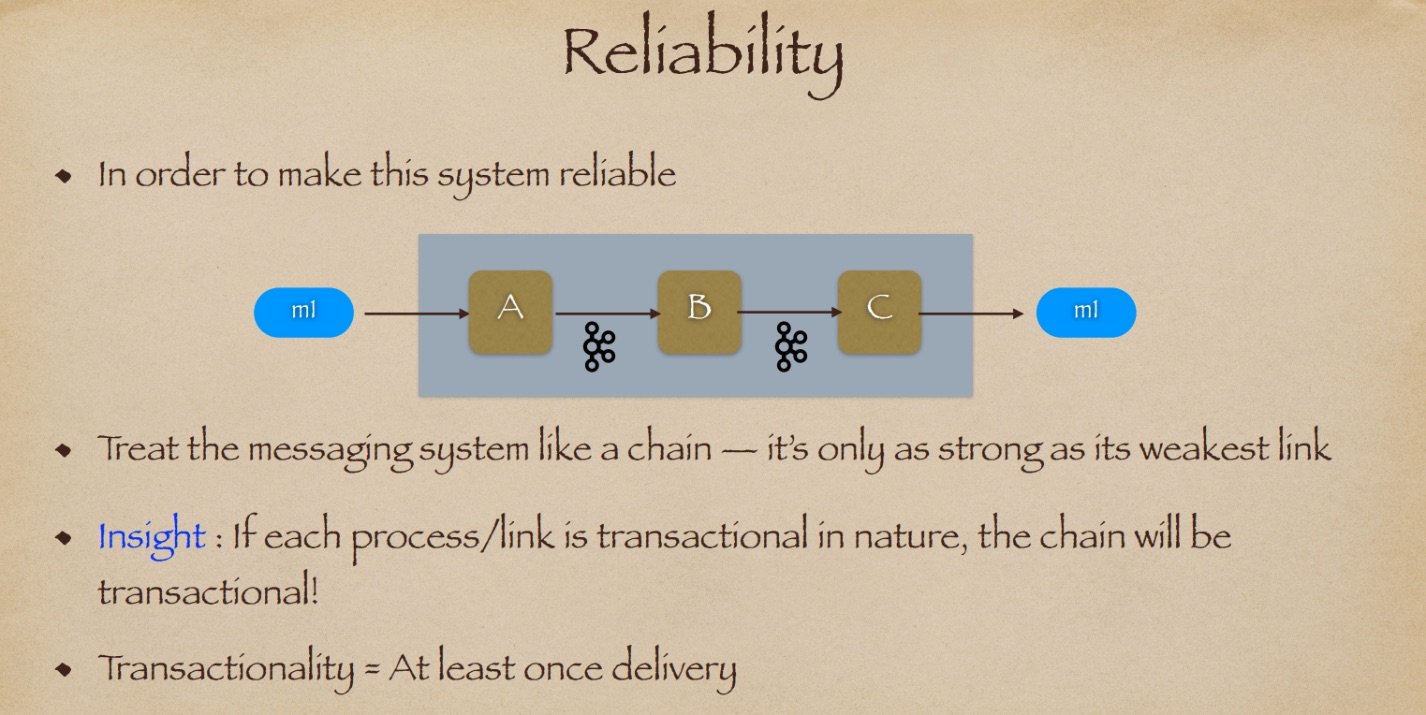
这个要求对我们的设计意味着什么?这意味着一旦进程 S 向远程发送方确认了一条消息,D 必须将该消息传递给远程接收方。我们如何在系统中构建可靠性?让我们首先概括一下我们的系统。不仅仅是 S 和 D,我们假设有三个进程,A、B 和 C,它们都通过 Kafka 主题连接在一起。为了使这个系统可靠,让我们将这个线性拓扑视为一个链条。就像任何链条一样,它的强度取决于它最弱的一环。如果每个进程或链路都具有事务性质,这个链条将是事务性的。我对“事务性”的定义是at least once delivery (至少一次交付),因为这是 Kafka 今天最常见的使用方式。我们如何使每个链路都具有事务性?让我们首先将这个链条分解成其组成处理链路。首先,我们有 A:A 是一个写入节点。然后我们有 B:B 是一个内部节点。它从 Kafka 中读取并写入 Kafka。最后,我们有 C:C 是一个写出节点,它从 Kafka 中读取并将消息发送到D。
我们如何让 A 可靠?A 将通过其 REST 端点接收请求,处理消息 m1,并可靠地将数据发送到 Kafka 作为 Kafka 事件。然后,A 将向其调用者发送 HTTP 响应。为了可靠地将数据发送到 Kafka,A 需要调用 kProducer.send 方法,传入两个参数:一个主题和一条消息。然后,A 需要立即调用 flush 方法,该方法将刷新内部 Kafka 缓冲区,并强制将 m1 发送到所有三个代理节点。由于我们设置了生产者配置 acks=all,A 将等待所有三个代理节点成功确认的响应,然后才能响应其调用者。
那么 C 呢?为了保证 C 的可靠性,它需要做些什么?C 需要读取数据,通常是从 Kafka 中读取一个批次,对其进行一些处理,然后可靠地将数据发送出去。在这种情况下,可靠地意味着它需要等待来自某个外部服务的 200 OK 响应代码。在收到响应后,C 进程将手动将其 Kafka 检查点向前移动。如果出现任何问题,C 进程将向 Kafka 发送负面确认(即 NACK),强制 B 重新读取相同的数据。最后,B 需要做什么?B 是 A 和 C 的结合体。B 需要像 A 一样作为可靠的 Kafka 生产者,并且还需要像 C 一样作为可靠的 Kafka 消费者。
现在我们可以说我们系统的可靠性如何了?如果一个进程崩溃会发生什么?如果 A 崩溃,我们将在写入过程中完全中断。这意味着我们的系统将不接受任何新消息。相反,如果 C 崩溃,该服务将停止向外部消费者传递消息;
但这意味着 A 将继续接收消息并将它们保存到 Kafka 中。B 将继续处理它们,但 C 不会将它们传递,直到 C 进程恢复。
延迟
在流式系统中,有两个主要的质量指标我们关心:延迟和丢失
消息在系统中传递的时间越长,延迟就越大。延迟增加会对业务产生更大的影响,尤其是那些依赖低延迟的业务。我们的目标是尽可能地减少延迟,以尽快提供业务见解。那么我们如何计算延迟呢?首先,让我们来谈谈一个概念,就是事件时间。事件时间是指消息或事件的创建时间。事件时间通常嵌入在消息体内,随着消息在系统中的传递而传递。我们可以使用下面的方程来计算系统中任意节点 N 上的任何消息 m1 的延迟: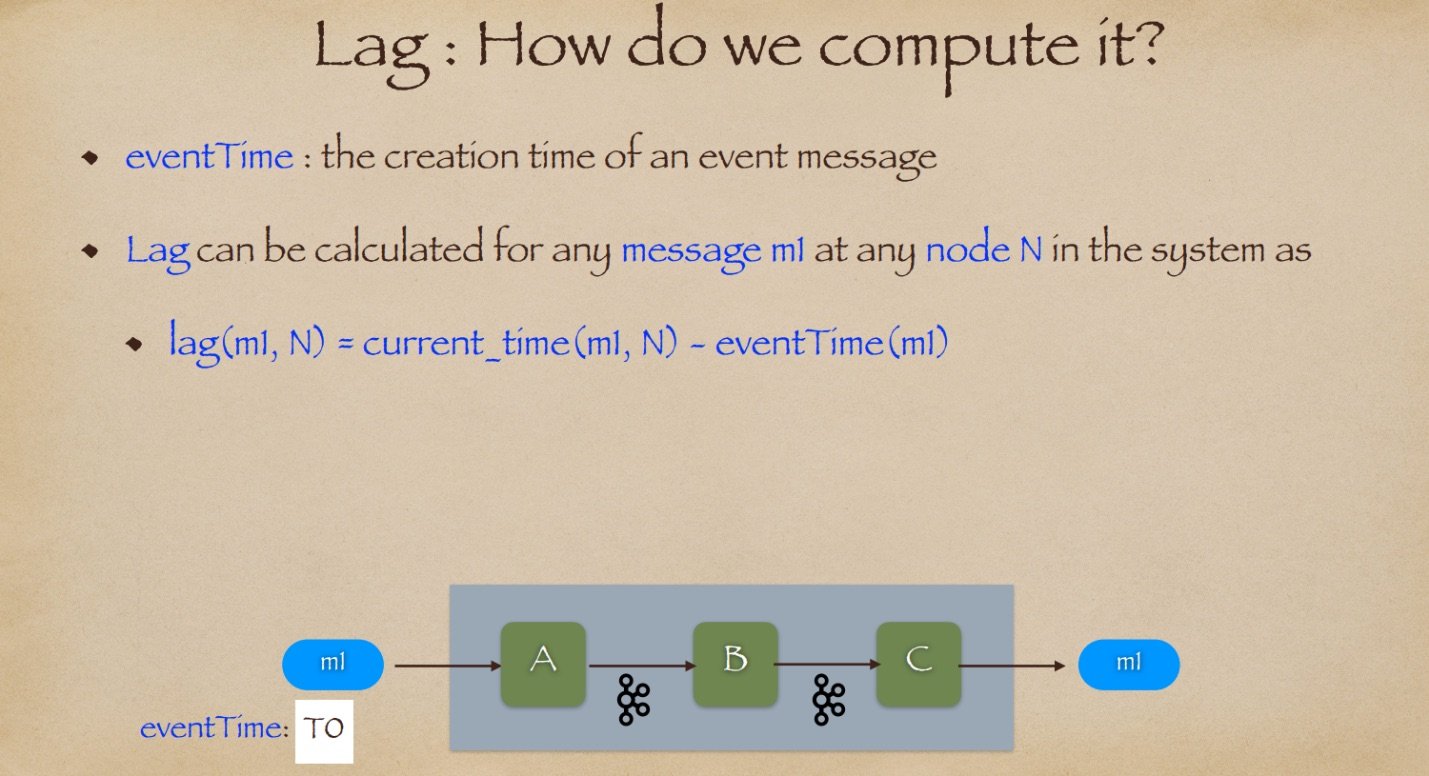
看一个真实的例子:
假设我们有一条消息是在中午(T0)创建的。这条消息在下午12:01(T1)到达我们的系统的节点 A。节点 A 处理消息并将其发送到节点 B。消息在下午12:04(T3)到达节点 B。B 处理消息并将其发送到节点 C,在下午12:10(T5)接收到消息。依此类推,C 处理消息并将其继续发送。使用前一页中的方程,我们可以计算出消息 m1 在节点 C 的延迟时间为 10 分钟,即 T5-T0。
实际上,在这些系统中,延迟时间并不是以分钟为单位,而是以毫秒为单位。
我们一直在谈论消息到达这些节点的情况;因此,这被称为到达时的延迟或进入后的滞后。另一个要观察的是,延迟是累积的。这意味着在节点C计算的延迟考虑了节点A和B上游的延迟。同样,节点B计算的延迟考虑了节点A上游的延迟。
除了到达延迟之外,还有另一种类型的延迟称为离开延迟。当消息离开节点时,会计算离开延迟。参考下面的图像,我们已经计算了所有节点A、B和C的离开延迟,分别为T2、T4和T6。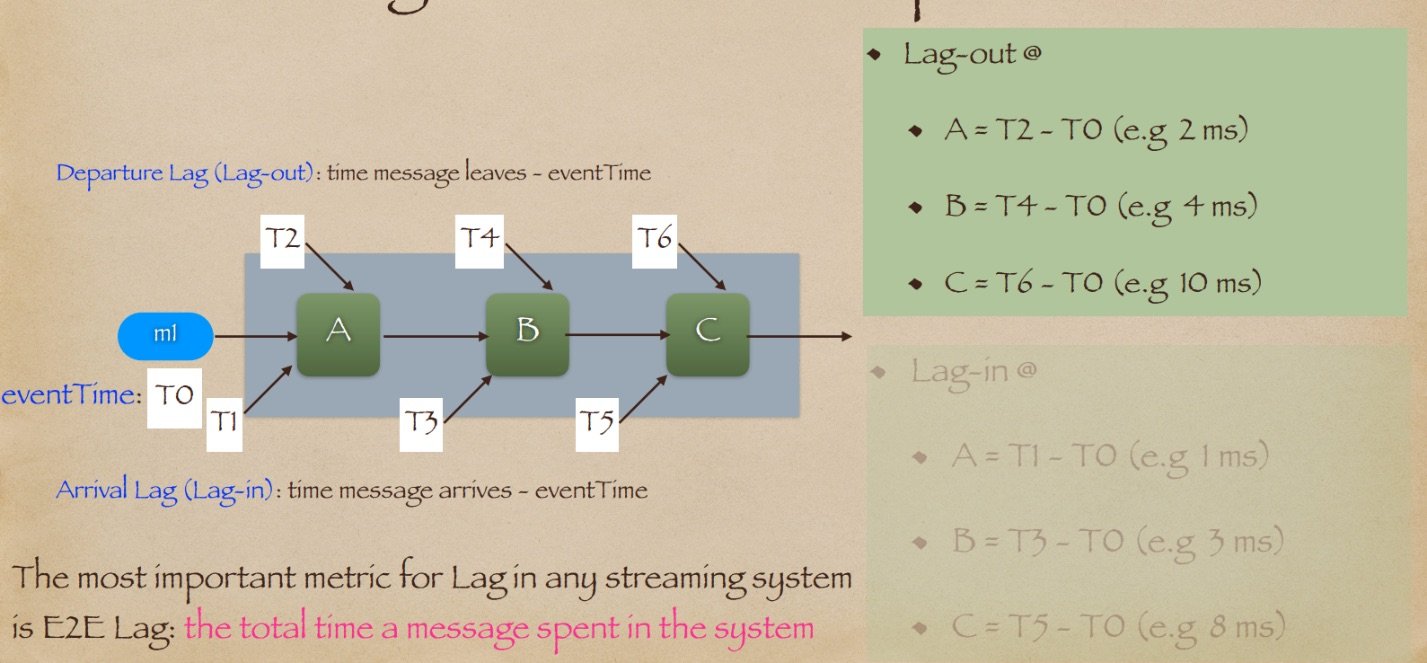
在任何流处理系统中,最重要的指标是称为端到端延迟(E2E Delay)的指标。端到端延迟是消息在系统中花费的总时间。端到端延迟很容易计算,因为它只是系统中最后一个节点的离开延迟。因此,它是节点C的离开延迟(即10毫秒)。
虽然了解特定消息(ml)的延迟是有趣的,但在处理数十亿或数万亿条消息时,它的用处不大。相反,我们利用统计学来捕获总体行为。我更喜欢使用第95(或第99)个百分位数(即P95)。许多人更喜欢最大值或P99。
让我们看看我们可以构建的一些统计数据。我们可以计算P95下的总体端到端延迟。我们还可以计算任何节点的延迟(即延迟内或延迟外)。我们可以计算所谓的具有延迟内和延迟外的处理持续时间:这是链中任何节点上花费的时间。这有什么用呢?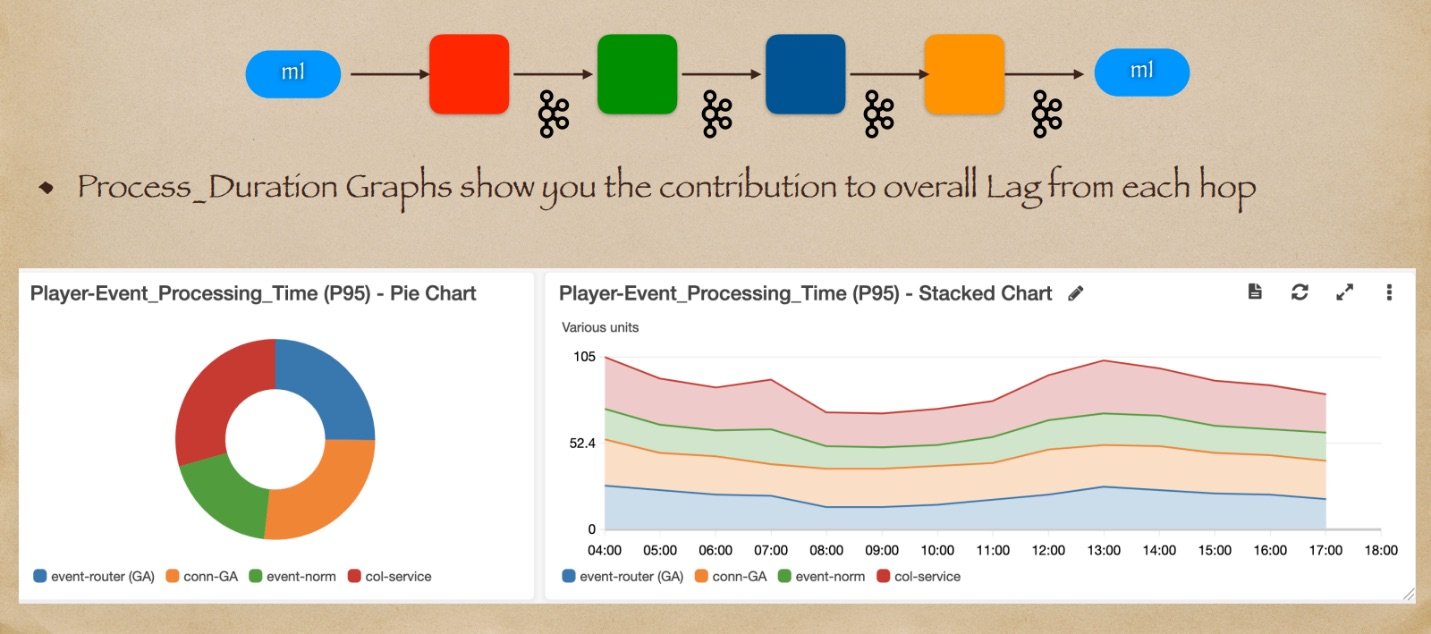
让我们看一个真实的例子。想象一下上面图中所示的线性拓扑结构;我们有一条消息进入了一个具有四个节点的系统,即红色节点、绿色节点、蓝色节点,最后是橙色节点。实际上,这是我们在生产环境中运行的系统。上面的图表是从我们生产服务的 CloudWatch 中获取的。正如你所看到的,我们获取了每个节点的处理持续时间,并将其放入了一个饼图中。这为我们提供了系统中每个节点的延迟贡献。每个节点的延迟贡献大致相等。没有单个节点突出。这是一个调校非常良好的系统。如果我们将这个饼图在时间上展开,我们会得到右边的图表,它向我们展示了系统的性能随时间的一致性。因此,我们有一个性能稳定、调校良好的系统。
丢失
现在我们已经讨论了延迟,那么损失又是什么呢?损失简单地衡量了在系统传输过程中丢失的消息数量。消息可能因为各种原因丢失,其中大多数我们都可以加以缓解——损失越大,数据质量越低。因此,我们的目标是最小化损失,以提供高质量的见解。你可能会问自己,“我们如何在流式系统中计算损失呢?”损失可以计算为系统中任意两个点之间消息的集合差。如果我们看一下之前的拓扑结构,你会发现这里的一个不同之处是我们有十条消息在系统中传输,而不是一条消息在系统中传输。
我们可以使用以下的损失表来计算损失。损失表中的每一行都是一条消息;每一列都是链中的一个节点。当一条消息通过系统时,我们会计算一个1。例如,消息1成功通过了整个系统,所以在每一列中都有一个1。消息2也成功通过了我们系统中的每个节点。然而,消息3虽然在红色节点成功处理了,但却没有到达绿色节点。因此,它也就没有到达蓝色节点或黄色节点。在底部,我们可以计算每个节点的损失。然后,正如你在右下角所见,我们可以计算系统中的端到端损失,本例中为50%。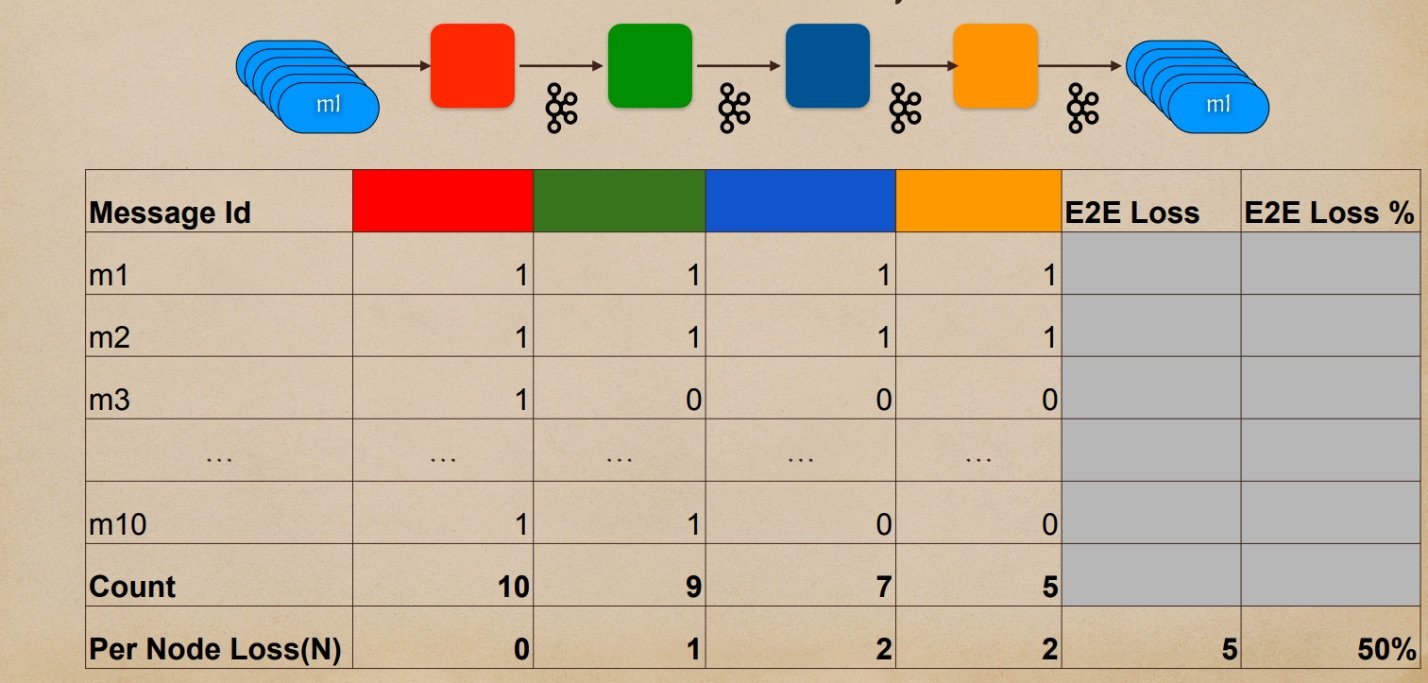
在流数据系统中,消息永远不会停止流动。我们如何知道何时计数呢?关键是使用消息事件时间将消息分配到1分钟宽的时间段中。例如,在一天的12:34分,我们可以计算一个损失表,其中包括所有事件时间落在12:34分的消息。同样地,我们可以在一天的其他时间做同样的事情。让我们想象一下,现在是中午12:40。我们知道,在这些系统中,消息可能会迟到。我们可以看到有四个表仍在更新其计数。然而,我们可能会注意到12:35的表不再改变;因此,所有将到达的消息都已经到达。在这一点上,我们可以计算损失。任何在此时间之前的表,我们都可以进行老化处理并丢弃。这样做可以通过删除我们不再需要进行计算的表来扩缩容损失计算。
总结一下,我们等待几分钟让消息进行传输,然后计算损失。然后,如果损失超过配置的阈值,例如1%,我们就会发出损失警报。通过解释滞后和损失,我们有了一种衡量系统可靠性和延迟的方法。
性能
我们是否已经调优了系统以提高性能?让我们重新审视一下我们的目标。我们想要构建一个能够以低延迟可靠地从 S 传递消息到 D 的系统。为了理解流式系统的性能,我们需要了解端到端滞后的组成部分。我想要提及的第一个组成部分称为写入时间。写入时间是从请求中的最后一个字节到响应中的第一个字节的时间。这段时间包括我们在可靠地将消息发送到 Kafka 中所产生的任何开销。在我们的管道末端,有一个被称为排出时间或输出时间的东西。这是在 D 处处理和输出一条消息所需的时间。在这两者之间的任何时间都被称为传输时间。所有这三种时间加起来就构成了端到端滞后。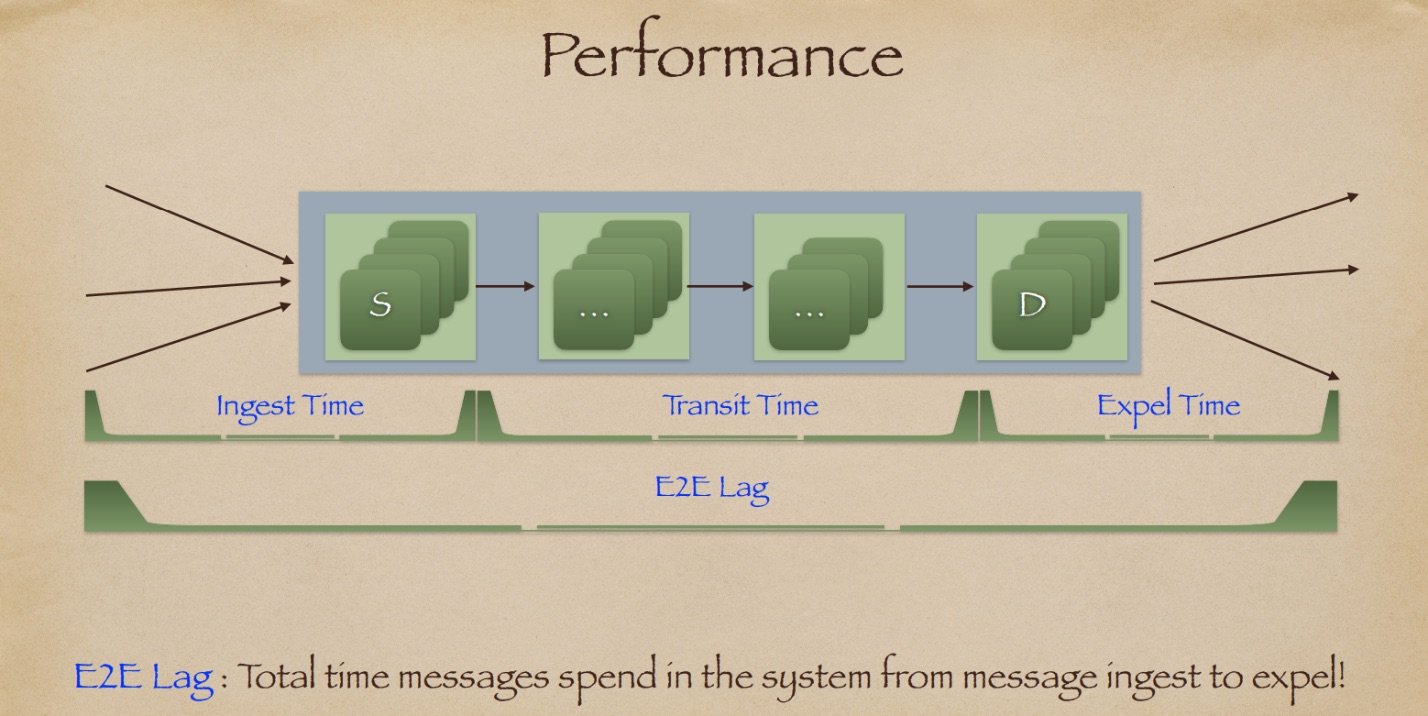
性能损失
在讨论性能时,我们必须承认,在构建无丢失系统时,我们必须承担某些性能成本。换句话说,我们需要在可靠性和延迟之间进行权衡。让我们看看其中的一些成本。
第一个成本是写入成本。出于可靠性考虑,S 需要在每个传入的 API 请求上调用 kProducer.flush。S 还需要在将 API 响应发送给客户端之前等待 Kafka 的三个确认。虽然我们无法消除这些写入性能成本,但我们可以通过批处理来分摊它们的成本。换句话说,我们可以通过支持和推广批处理 API,最大程度地提高每个 API 调用的吞吐量,从而在恒定的每个 API 调用延迟上获得多条消息。
类似地,我们有一种称为写出成本的惩罚。我们需要考虑的一个观察结果是,Kafka 非常快速。它的速度比公共互联网上典型的 HTTP 往返时间(RTT)快几个数量级。事实上,大部分的写出时间是由 HTTP 往返时间组成的。同样,我们将采用摊销方法。在每个 D 节点中,我们将添加批处理和并行性。我们将从 Kafka 中读取一批数据,然后将它们重新分批成较小的批次,并使用并行线程将它们发送到它们的目的地。这样,我们可以最大程度地提高吞吐量,并尽量减少每个消息的写出成本或惩罚。
最后但同样重要的是,我们有一种称为重试成本的惩罚。为了运行一个零丢失的流水线,我们需要在 D 节点重试消息,只要重试足够次数,就会成功。我们无法控制 D 调用的远程端点。这些端点可能会发生暂时性故障;它们也可能不时地限制 D 的吞吐量。可能还会发生我们无法控制的其他情况。我们必须确定是否可以通过重试成功。我们将这些类型的故障称为可恢复性故障。然而,还有一些类型的情况或错误是不可恢复的。例如,如果我们收到一个 4xx 的 HTTP 响应代码,除了 429(即一个常见的限流响应代码),我们不应该重试,因为即使重试也不会成功。总结一下,为了处理重试成本,我们必须在重试时付出一些延迟成本。我们需要明智地选择重试的内容,我们已经讨论过了。我们不会对任何不可恢复的故障进行重试。我们还必须明智地选择重试的方式。
性能——分层重试
我使用的一个想法叫做分层重试 - 请参考下面的架构图。在这种方法中,我们有两个层次:本地重试层和全局重试层。在本地层,我们尝试在 D 处发送一条消息,重试次数可配置,重试间隔短。这一层的目标是在远程目标发生短暂和暂时性中断时尝试传递消息。
如果我们耗尽了本地的重试次数,D 将消息传递给全局重试服务 (gr)。全局重试器然后在更长的时间范围内重试消息。这一层的目标是尝试在较长时间的中断中坚持下来,以期成功传递消息。通过将这一责任交给全局重试器,服务 D 可以专注于传递没有问题的消息。请注意,服务 D 可能会将消息发送到不同的远程服务或端点。因此,尽管其中一个远程目标可能遇到中断,但其他目标可能完全正常。由于这是一个流式系统,全局重试器和服务 D 通过 Kafka 主题 RI (Retry_In) 和 RO (Retry_Out) 分隔。
这种方法的美妙之处在于,在实践中,我们通常看到的全局重试远远少于 1%,通常远远少于 0.1%。因此,即使这些需要更长的时间,它们也不会影响我们的 P95 端到端延迟。
可扩展性
在这一点上,我们有一个在低规模下运作良好的系统。这个系统如何随着流量增加而扩展?首先,让我们打破一个神话。没有什么东西可以处理无限规模的系统。许多人认为,通过迁移到 AWS 或其他托管平台,你可以实现这种目标。现实是,每个账户都有一些限制,因此你的流量和吞吐量将受到限制。实质上,每个系统都有一个流量评级,无论它在哪里运行。流量评级是通过对系统进行负载测试来衡量的。我们只能通过迭代运行负载测试并消除瓶颈来实现更高的规模。在自动扩缩容时,特别是对于数据流,我们通常有两个目标。目标1是自动扩展以保持低延迟,例如,最小化端到端延迟。目标2是缩小规模以减少成本。现在,我将专注于目标1。在自动扩缩容时,有几件事需要考虑;首先,我们可以自动扩缩容什么?至少在过去的十年左右,在亚马逊上,我们已经能够自动扩缩容计算。我们所有的计算节点都是可以自动扩展的。那么 Kafka 呢?目前 Kafka 不支持自动扩缩容,但这是他们正在努力解决的问题。
自动扩缩容最关键的部分是选择正确的指标来触发自动扩缩容操作。为了做到这一点,我们必须选择一个指标,它在流量增加时保持低延迟,并在微服务扩展时下降。根据我的经验,平均 CPU 是最好的衡量标准。然而,还有一些需要注意的事项。如果你的代码有锁、代码同步或IO等待,就会有问题。你可能无法饱和你的计算机的 CPU。随着流量的增加,你的 CPU 将达到一个平稳期。当这种情况发生时,自动扩缩容将停止,你的延迟将增加。如果你在系统中看到了这种情况,简单的解决方法就是将阈值降低到 CPU 平稳期以下。这样就可以解决这个问题。
总结
此时,我们拥有了一个符合我们期望的非功能性需求的系统。虽然我们已经涵盖了许多关键要素,但还有许多要考虑的因素:隔离性、具有容器的多级自动扩缩容、流操作符和缓存架构。
相关文章:
构建操作可靠的数据流系统
文章目录 前言数据流动遇到的困难先从简单开始可靠性延迟丢失 性能性能损失性能——分层重试 可扩展性总结 前言 在流式架构中,任何对非功能性需求的漏洞都可能导致严重后果。如果数据工程师没有将可伸缩性、可靠性和可操作性等非功能性需求作为首要考虑因素来构建…...

awesome-cheatsheets:超级速查表 - 编程语言、框架和开发工具的速查表
awesome-cheatsheets:超级速查表 - 编程语言、框架和开发工具的速查表,单个文件包含一切你需要知道的东西 官网:GitHub - skywind3000/awesome-cheatsheets: 超级速查表 - 编程语言、框架和开发工具的速查表,单个文件包含一切你需…...

GFW不起作用
闲着折腾,刷openwrt到一个小米3G路由器后,GFW不起作用。后面发现是自己电脑设置了DNS,解析完IP后,在经过代代,IP不在GFW的清单里,所以转发控制就没有起作用。 结论 在经过代代前的所有节点,都…...
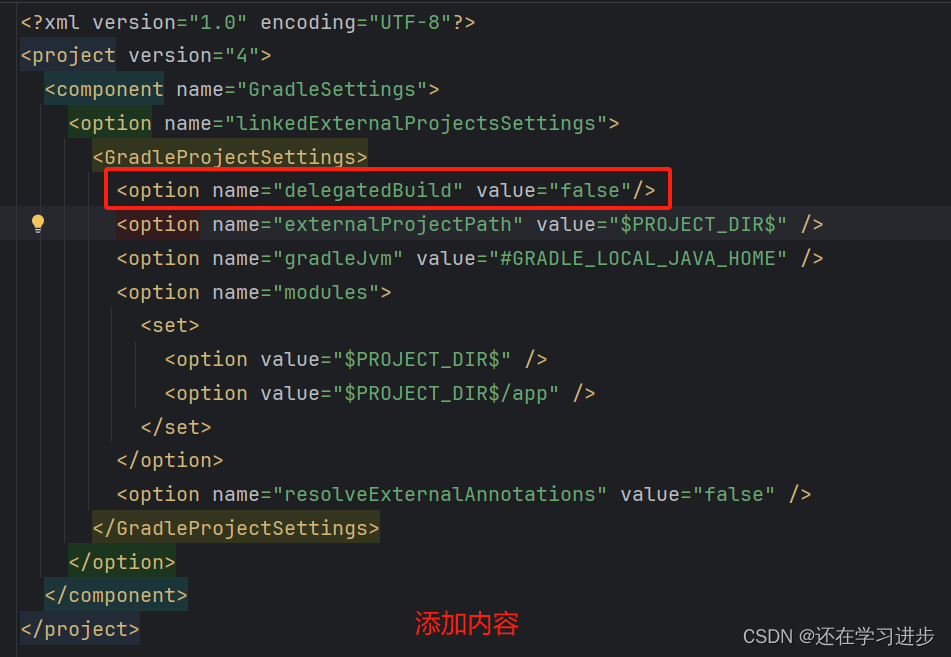
AndroidStudio出现类似 Could not create task ‘:app:ToolOperatorDemo.main()‘. 错误
先看我们的报错 翻译过来大概意思是:无法创建任务:app:ToolOperatorDemo.main()。 没有找到名称为“main”的源集。 解决方法: 在.idea文件夹下的gradle.xml文件中 <GradleProjectSettings>标签下添加<option name"delegatedBuild" value"f…...

一些常见的ClickHouse问题和答案
什么是ClickHouse?它与其他数据库系统有什么区别? ClickHouse是一个开源的列式数据库管理系统(DBMS),专门用于高性能、大规模数据分析。与传统的行式数据库相比,ClickHouse具有更高的查询性能、更高的数据…...
第九届蓝桥杯大赛个人赛省赛(软件类)真题C 语言 A 组-分数
solution1 直观上的分数处理 #include <iostream> using namespace std; int main() {printf("1048575/524288");return 0; }#include<stdio.h> #include<math.h> typedef long long ll; struct fraction{ll up, down; }; ll gcd(ll a, ll b){if…...

并发编程——4.线程池
这篇文章我们来讲一下线程池的相关内容 目录 1.什么是线程池 1.1为什么要用线程池 1.2线程池的优势 2.线程池的使用 3.线程池的关闭 4.线程池中的execute和submit方法的一些区别 5.线程池的参数和原理 6.自定义线程池 7.总结 1.什么是线程池 1.1为什么要用线程池 首…...
阿里云魔搭发起“ModelScope-Sora开源计划”,将为中国类Sora模型开发提供一站式工具链
在2024年3月23日的全球开发者先锋大会上,阿里云的魔搭社区宣布了一个新计划:“ModelScope-Sora开源计划”。这个计划旨在通过开源方式,帮助中国在Sora模型类型上做出更多创新。这个计划提供了一整套工具,包括处理数据的工具、多模…...

大模型与数据分析:探索Text-to-SQL
当今大模型如此火热,作为一名数据同学,持续在关注LLM是如何应用在数据分析中的,也关注到很多公司推出了AI数智助手的产品,比如火山引擎数智平台VeDI—AI助手、 Kyligence Copilot AI数智助理、ThoughtSpot等,通过接入人…...

Unity VisionOS开发流程
Unity开发环境 Unity Pro, Unity Enterprise and Unity Industry 国际版 Mac Unity Editor(Apple silicon) visionOS Build Support (experimental) 实验版 Unity 2022.3.11f1 NOTE: 国际版与国服版Pro账通用,需要激活Pro的许可证。官方模板v0.6.2,非Pro版本会打…...

聊聊k8s服务发现的优缺点
序 本文主要研究一下使用k8s服务发现的优缺点 spring cloud vs kubernetes 这里有张spring cloud与kubernetes的对比,如果将微服务部署到kubernetes上面,二者有不少功能是重复的,可否精简。 这里主要是讲述一下如果不使用独立的服务发现&am…...

Tomcat是如何处理并发请求的?
Tomcat处理请求流程: Tomcat是采用了扩展JDK线程池的方案 :先启动若干数量的线程,并让这些线程都处于睡眠状态,当客户端有一个新请求时,就会唤醒线程池中的某一个睡眠线程,让它来处理客户端的这个请求,当处…...
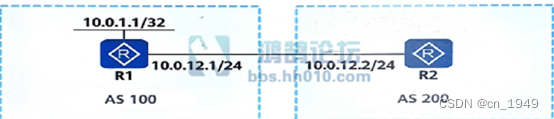
H12-831_561
单选题561、如图所示,R1使用Loopback0接口(IP地址为10.0.1.1/32)与R2的物理接口(IP地址为10.0.12.2/24)建立EBGP邻居关系,以下描述中正确的是哪一项? A.无需在R1和R2的BGP进程下指定ebgp-max-hop B.在R2的BGP进程下配置peer 10.0.1.1 ebgp-max-hop 2,且…...
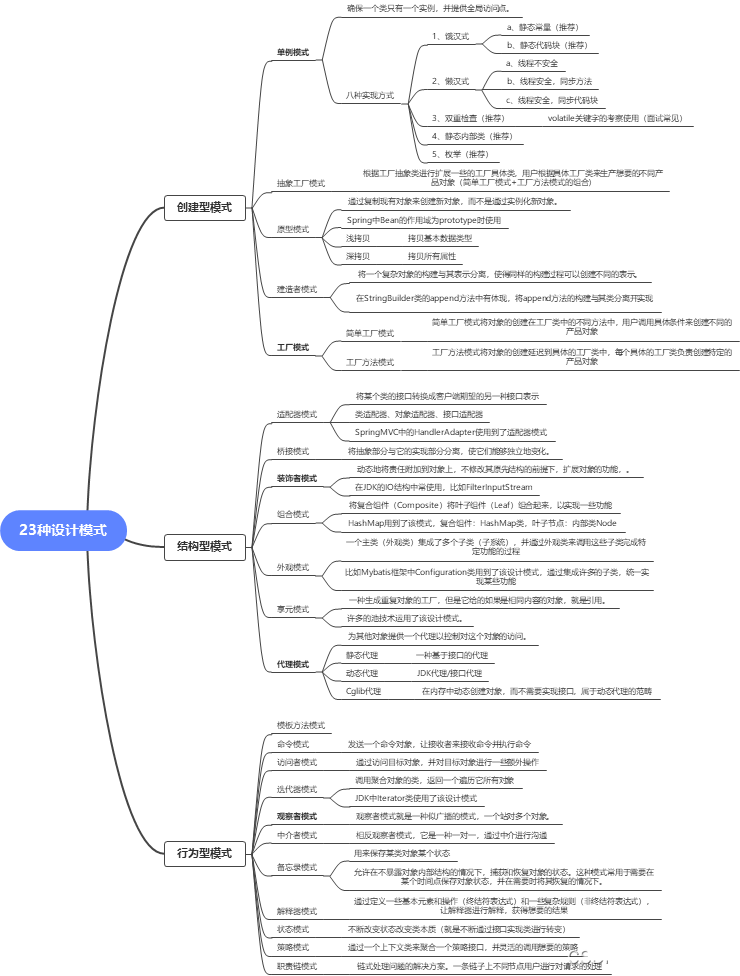
Java23种常见设计模式汇总
七大原则网站地址:设计模式7大原则+类图关系-CSDN博客 创建型设计模式:创建型设计模式合集-CSDN博客 七大结构型设计模式:7大结构型设计模式-CSDN博客 11种行为型设计模式: 11种行为型模式(上࿰…...
神经网络与深度学习(一)
线性回归 定义 利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法 要素 训练集(训练数据)输出数据拟合函数数据条目数 场景 预测价格(房屋、股票等)、预测住院时间&#…...
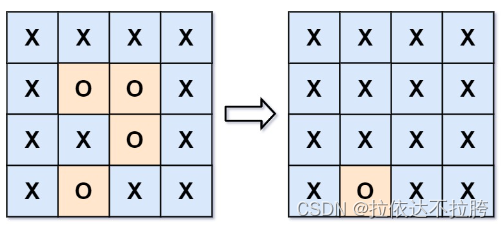
算法学习——LeetCode力扣图论篇2
算法学习——LeetCode力扣图论篇2 1020. 飞地的数量 1020. 飞地的数量 - 力扣(LeetCode) 描述 给你一个大小为 m x n 的二进制矩阵 grid ,其中 0 表示一个海洋单元格、1 表示一个陆地单元格。 一次 移动 是指从一个陆地单元格走到另一个相…...
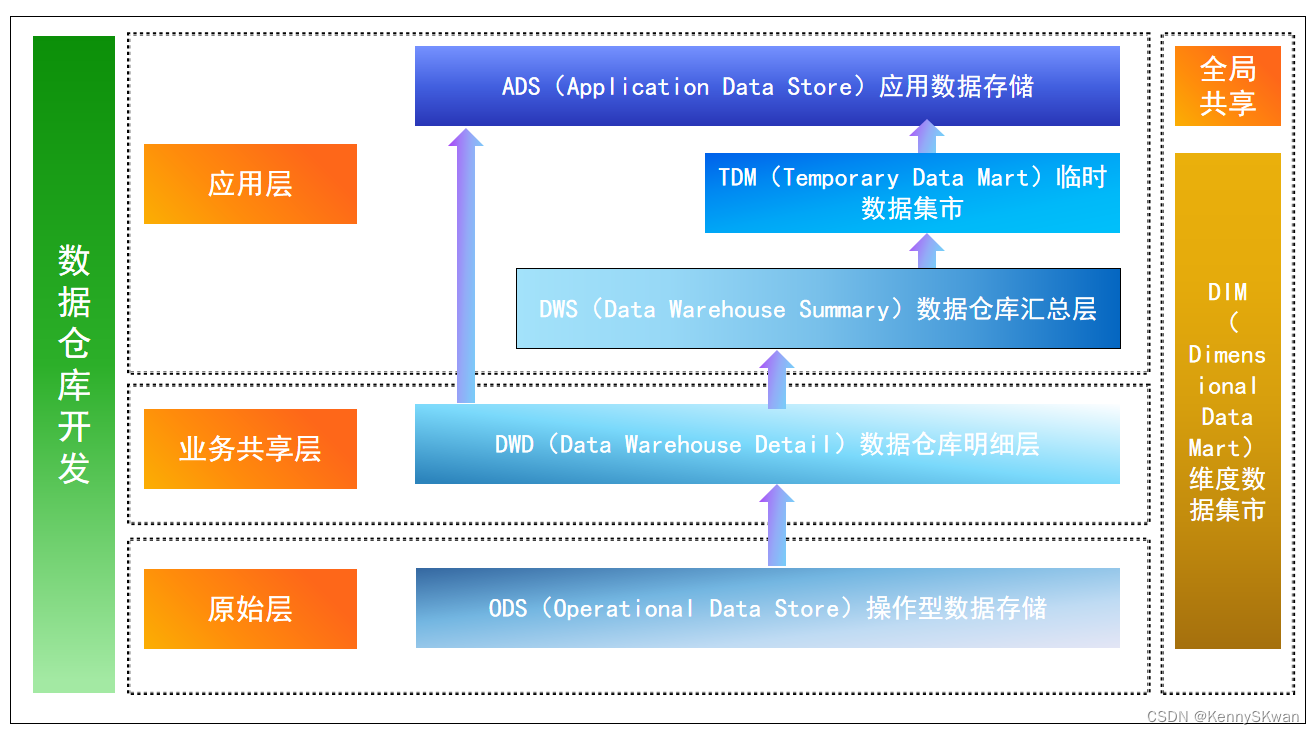
大数据设计为何要分层,行业常规设计会有几层数据
大数据设计通常采用分层结构的原因是为了提高数据管理的效率、降低系统复杂度、增强数据质量和可维护性。这种分层结构能够将数据按照不同的处理和应用需求进行分类和管理,从而更好地满足不同层次的数据处理和分析需求。行业常规设计中,数据通常按照以下…...

css3之2D转换transform
2D转换transform 一.移动(translate)(中间用,隔开)二.旋转(rotate)(有单位deg)1.概念2.注意点3.转换中心点(transform-origin)(中间用空格)4.一些例子(css三角和旋转) 三…...

pytest中文使用文档----6临时目录和文件
1. 相关的fixture 1.1. tmp_path1.2. tmp_path_factory1.3. tmpdir1.4. tmpdir_factory1.5. 区别 2. 默认的基本临时目录 1. 相关的fixture 1.1. tmp_path tmp_path是一个用例级别的fixture,其作用是返回一个唯一的临时目录对象(pathlib.Path…...
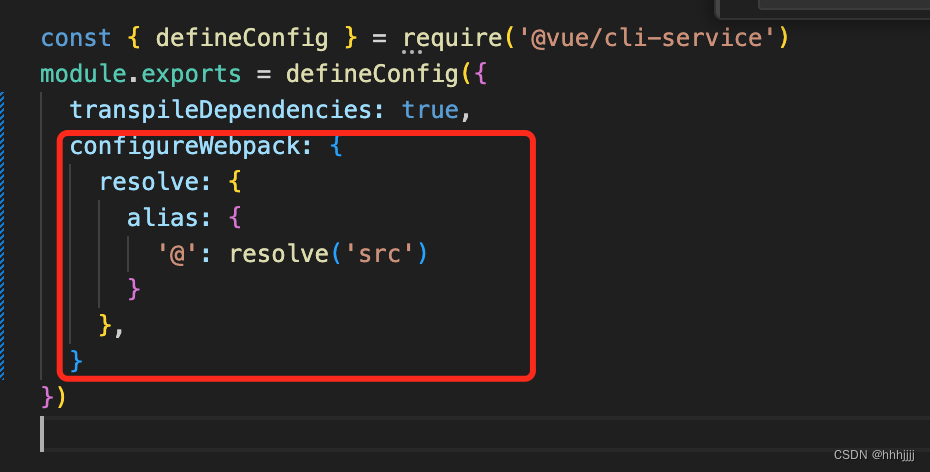
从0开始搭建基于VUE的前端项目
准备与版本 安装nodejs(v20.11.1)安装vue脚手架(vue/cli 5.0.8) ,参考(https://cli.vuejs.org/zh/)vue版本(2.7.16),vue2的最后一个版本 初始化项目 创建一个git项目(可以去gitee/github上创建ÿ…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

Proxmox Mail Gateway安装指南:从零开始配置高效邮件过滤系统
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...

pycharm 设置环境出错
pycharm 设置环境出错 pycharm 新建项目,设置虚拟环境,出错 pycharm 出错 Cannot open Local Failed to start [powershell.exe, -NoExit, -ExecutionPolicy, Bypass, -File, C:\Program Files\JetBrains\PyCharm 2024.1.3\plugins\terminal\shell-int…...

【把数组变成一棵树】有序数组秒变平衡BST,原来可以这么优雅!
【把数组变成一棵树】有序数组秒变平衡BST,原来可以这么优雅! 🌱 前言:一棵树的浪漫,从数组开始说起 程序员的世界里,数组是最常见的基本结构之一,几乎每种语言、每种算法都少不了它。可你有没有想过,一组看似“线性排列”的有序数组,竟然可以**“长”成一棵平衡的二…...