深入理解数据结构(3):栈和队列详解


- 文章主题:顺序表和链表详解🌱
- 所属专栏:深入理解数据结构📘
- 作者简介:更新有关深入理解数据结构知识的博主一枚,记录分享自己对数据结构的深入解读。😄
- 个人主页:[₽]的个人主页🔥🔥
栈和队列详解
- 前言
- 栈
- 栈的概念及结构
- 栈的实现
- 队列
- 队列的概念及结构
- 队列的实现
- 结语
前言
上文我们已经讲完了线性表中最基本的、最常用的顺序表和链表,这一次博主为大家带来基于顺序表和链表实现的线性表中也是十分常用的数据结构栈和队列的详解,希望能够让你对数据结构有一个更加深入的理解。
栈
栈的概念及结构
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈/弹栈。出数据也在栈顶。

栈的实现
栈的实现一般可以使用数组或者链表实现,相对而言数组的结构实现更优一些。因为数组在尾上插入数据的代价比较小,最简单。

静态数组栈
下面是定长的静态栈的结构,实际中一般不实用,所以我们主要实现下面的支持动态增长的栈
// 下面是定长的静态栈的结构,实际中一般不实用,所以我们主要实现下面的支持动态增长的栈
typedef int STDataType;
#define N 10
typedef struct Stack
{STDataType _a[N];int _top; // 栈顶
}Stack;
动态数组栈
Stack.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
// 支持动态增长的栈
typedef int STDataType;
typedef struct Stack
{STDataType* _a;int _top; // 栈顶int _capacity; // 容量
}Stack;
// 初始化栈
void StackInit(Stack* ps);
// 入栈
void StackPush(Stack* ps, STDataType data);
// 出栈
void StackPop(Stack* ps);
// 获取栈顶元素
STDataType StackTop(Stack* ps);
// 获取栈中有效元素个数
int StackSize(Stack* ps);
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
int StackEmpty(Stack* ps);
// 销毁栈
void StackDestroy(Stack* ps);
Stack.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "Stack.h"
void StackInit(Stack* ps)
{assert(ps);// 栈区数组未创建,赋成NULLps->_a = NULL;ps->_capacity = 0;// 表示top指向栈顶元素ps->_top = -1;// 表示top指向栈顶元素的下一个//ps->_top = 0
}
void StackPush(Stack* ps, STDataType data)
{assert(ps);// 栈区数据已满,扩容if (ps->_top + 1 == ps->_capacity){// 确定扩容后的新容量,如果是 0 就扩容为 4 ,如果已经扩过容了就将容量在增加一个原来这么多,即扩大为原来的两倍int newcapacity = ps->_capacity == 0 ? 4 : ps->_capacity * 2;// 扩容STDataType* tmp = (STDataType*)realloc(ps->_a, newcapacity * sizeof(STDataType));// 扩容失败打印失败原因后返回if (tmp == NULL){perror("realloc fail");return;}// 未失败将容量更新成新容量,数据指针更新成新指针ps->_capacity = newcapacity;ps->_a = tmp;}// 插入数据ps->_top++;ps->_a[ps->_top] = data;
}
void StackPop(Stack* ps)
{assert(ps);// 栈不为空时才能删除数据assert(ps->_top + 1 > 0);// 栈顶元素坐标下移,删除数据ps->_top--;
}
STDataType StackTop(Stack* ps)
{assert(ps);// 不为空,为空弹不出数据来进行访问,并且访问会导致数组越界assert(ps->_top + 1 > 0);// 返回栈顶元素值return ps->_a[ps->_top];
}
int StackSize(Stack* ps)
{assert(ps);// 返回栈中有效元素个数(栈顶元素 +1 即为栈中有效元素个数)return ps->_top + 1;
}
int StackEmpty(Stack* ps)
{assert(ps);// 为空则返回非 0 的真return ps->_top + 1 == 0;
}
void StackDestroy(Stack* ps)
{assert(ps);// 数据内存释放,再将记录数据的各值清空free(ps->_a);ps->_a = NULL;ps->_capacity = 0;ps->_top = -1;
}
Test.c
#include "Stack.h"
void StackTest1()
{// 初始化栈Stack S1;StackInit(&S1);// 数据入栈StackPush(&S1, 1);StackPush(&S1, 2);StackPush(&S1, 3);StackPush(&S1, 4);StackPush(&S1, 5);// 销毁栈StackDestroy(&S1);// 检测是否销毁成功if (S1._a == NULL && S1._capacity == 0 && S1._top == -1)printf("销毁成功!\n");elseprintf("销毁失败。\n");
}
void StackTest2()
{// 初始化栈Stack S1;StackInit(&S1);// 数据入栈StackPush(&S1, 1);StackPush(&S1, 2);StackPush(&S1, 3);StackPush(&S1, 4);StackPush(&S1, 5);// 从栈顶读取数据后弹出栈中数据while (!StackEmpty(&S1)){printf("%d ", StackTop(&S1));StackPop(&S1);}printf("\n");// 销毁栈StackDestroy(&S1);
}
void StackTest3()
{// 初始化栈Stack S1;StackInit(&S1);// 栈为空时也弹出数据StackPop(&S1);// 销毁栈StackDestroy(&S1);
}
int main()
{StackTest3();return 0;
}
队列
队列的概念及结构
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out) 入队列:进行插入操作的一端称为队尾 出队列:进行删除操作的一端称为队头
入队:队列的插入操作叫做入队,入数据在队尾。
出队:队列的删除操作叫做出队。出数据在队头。
(栈和对列都是将出数据的地方叫作顶/头)

队列的实现
队列也可以数组和链表的结构实现,使用链表(带头的单链表)的结构实现更优一些(时间复杂度O(1),比数组来说在队头删除数据更加简洁),因为如果使用数组的结构,出队列在数组头上出数据,效率会比较低(时间复杂度为O(N))。

队列
Queue.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>typedef int QDataType;
// 链式结构:表示队列
typedef struct QListNode
{struct QListNode* _next;QDataType _data;
}QNode;// 队列的结构
typedef struct Queue
{QNode* _front;QNode* _rear;int _size;
}Queue;// 初始化队列
void QueueInit(Queue* q);
// 销毁队列
void QueueDestroy(Queue* q);
// 队尾入队列
void QueuePush(Queue* q, QDataType data);
// 队头出队列
void QueuePop(Queue* q);
// 获取队列头部元素
QDataType QueueFront(Queue* q);
// 获取队列队尾元素
QDataType QueueBack(Queue* q);
// 获取队列中有效元素个数
int QueueSize(Queue* q);
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
int QueueEmpty(Queue* q);
Queue.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "Queue.h"
void QueueInit(Queue* q)
{assert(q);// 首尾指针都赋成NULL,元素个数赋0q->_front = q->_rear = NULL;q->_size = 0;
}
void QueueDestroy(Queue* q)
{assert(q);// 释放队列数据内存QNode* cur = q->_front;while (cur){QNode* tmp = cur;cur = cur->_next;free(tmp);}// 将队列中的首尾指针数据赋成NULL,队列元素个数也置为0q->_front = q->_rear = NULL;q->_size = 0;
}
void QueuePush(Queue* q, QDataType data)
{assert(q);// 创建新节点QNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("maloc fail");return;}newnode->_data = data;newnode->_next = NULL;// 无节点if (q->_front == NULL){q->_front = q->_rear = newnode;}// 有节点else{q->_rear->_next = newnode;q->_rear = newnode;}// 队尾入数据时总元素个数加一q->_size++;
}
void QueuePop(Queue* q)
{assert(q);// 无节点assert(q->_front);// 有节点QNode* tmp = q->_front;q->_front = q->_front->_next;free(tmp);// 一个节点时,尾指针因为释放节点变成野指针,需要置空if (q->_front == NULL)q->_rear = NULL;// 队头出数据时总元素个数减一q->_size--;
}
QDataType QueueFront(Queue* q)
{assert(q);// 无节点assert(q->_front);// 有节点return q->_front->_data;
}
QDataType QueueBack(Queue* q)
{assert(q);// 无节点assert(q->_front);// 有节点return q->_rear->_data;
}
int QueueSize(Queue* q)
{assert(q);// 直接将储存队列主要数据的结构体中的元素个数拿出来返回return q->_size;
}
int QueueEmpty(Queue* q)
{assert(q);return q->_size == 0;
}Test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "Queue.h"
void QueueTest1()
{// 队列初始化Queue Q1;QueueInit(&Q1);// 队尾入数据QueuePush(&Q1, 1);QueuePush(&Q1, 2);QueuePush(&Q1, 3);QueuePush(&Q1, 4);QueuePush(&Q1, 5);// 销毁队列QueueDestroy(&Q1);if (Q1._front == NULL && Q1._rear == NULL && Q1._size == 0)printf("销毁成功!\n");elseprintf("销毁失败。\n");
}void QueueTest2()
{// 队列初始化Queue Q1;QueueInit(&Q1);// 队尾入数据QueuePush(&Q1, 1);QueuePush(&Q1, 2);QueuePush(&Q1, 3);QueuePush(&Q1, 4);QueuePush(&Q1, 5);// 打印队列中的数据printf("Queue: \n");while (!QueueEmpty(&Q1)){printf("%d ", QueueFront(&Q1));QueuePop(&Q1);}printf("\n");// 销毁队列QueueDestroy(&Q1);
}void QueueTest3()
{// 队列初始化Queue Q1;QueueInit(&Q1);// 队尾入数据QueuePush(&Q1, 1);QueuePush(&Q1, 2);QueuePush(&Q1, 3);QueuePush(&Q1, 4);QueuePush(&Q1, 5);// 打印队列中的数据printf("Queue: \n");while (!QueueEmpty(&Q1)){printf("%d ", QueueFront(&Q1));QueuePop(&Q1);}printf("\n");// 无节点从队列中弹出数据QueuePop(&Q1);// 销毁队列QueueDestroy(&Q1);
}void QueueTest4()
{// 队列初始化Queue Q1;QueueInit(&Q1);// 队尾入数据QueuePush(&Q1, 1);QueuePush(&Q1, 2);QueuePush(&Q1, 3);QueuePush(&Q1, 4);QueuePush(&Q1, 5);// 打印队尾中的数据printf("BackNum: \n%d\n", QueueBack(&Q1));// 打印队列中的数据printf("Queue: \n");while (!QueueEmpty(&Q1)){printf("%d ", QueueFront(&Q1));QueuePop(&Q1);}printf("\n");// 销毁队列QueueDestroy(&Q1);
}void QueueTest5()
{// 队列初始化Queue Q1;QueueInit(&Q1);// 队尾入数据QueuePush(&Q1, 1);QueuePush(&Q1, 2);QueuePush(&Q1, 3);QueuePush(&Q1, 4);QueuePush(&Q1, 5);// 打印队列中的数据个数printf("QueueSize: \n%d\n", QueueSize(&Q1));// 打印队列中的数据printf("Queue: \n");while (!QueueEmpty(&Q1)){printf("%d ", QueueFront(&Q1));QueuePop(&Q1);}printf("\n");// 销毁队列QueueDestroy(&Q1);
}int main()
{QueueTest5();return 0;
}
环形队列
另外扩展了解一下,实际中我们有时还会使用一种队列叫循环队列。如操作系统中的生产者消费者模型中就会使用循环队列。环形队列可以使用数组实现,也可以使用循环链表实现(差别不是很大,并且环形队列的元素个数是固定的,但也可以不是在栈区的静态数组实现的,其可用在动态区用长度不变的数组来实现内存大小不变的效果,可理解成动态数组大小不变所实现的仿静态效果,并且虽逻辑结构上两种环形队列都相接,数组型的环形队列物理结构上首尾不相接,链表物理结构上相接)。

通常为区分队头和队尾,会在数组中多加一个元素来既防止数组越界,又能够解决因空和满索引条件相同而造成无法判断的假溢出问题(此时环形队列容量为数组总元素个数减一):
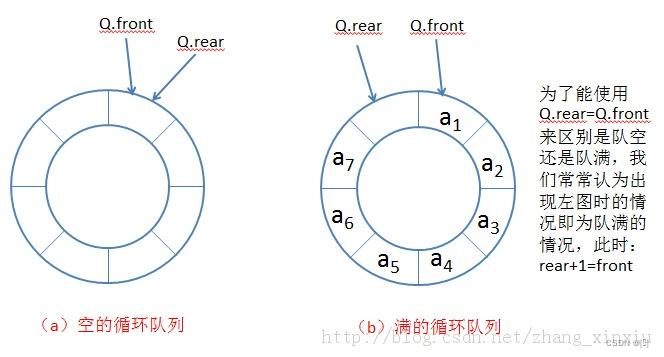
结语
以上就是博主对栈和队列的详解,😄希望对你的数据结构的学习有所帮助!看都看到这了,点个小小的赞或者关注一下吧(当然三连也可以~),你的支持就是博主更新最大的动力!让我们一起成长,共同进步!
相关文章:
深入理解数据结构(3):栈和队列详解
文章主题:顺序表和链表详解🌱所属专栏:深入理解数据结构📘作者简介:更新有关深入理解数据结构知识的博主一枚,记录分享自己对数据结构的深入解读。😄个人主页:[₽]的个人主页&#x…...
单例设计模式(3)
单例模式(3) 实现集群环境下的分布式单例类 如何理解单例模式中的唯一性? 单例模式创建的对象是进程唯一的。以springboot应用程序为例,他是一个进程,可能包含多个线程,单例代表在这个进程的某个类是唯一…...
将jupyter notebook文件导出为pdf(简单有效)
1.打开jupyter notebook笔记: 2.点击file->print Preview 3.在新打开的页面右键打印 4.另存为PDF 5.保存即可 6.pdf效果 (可能有少部分图片显示不了) 网上也有其他方法,比如将其转换为.tex再转为PDF等,但个人觉…...

使用INSERT INTO ... ON DUPLICATE KEY UPDATE批量插入更新导入excel数据的实践场景应用
INSERT INTO ... ON DUPLICATE KEY UPDATE 是 MySQL 中的一个非常有用的语法,它允许你在插入新记录时,如果记录的唯一键(如主键或唯一索引)已存在,则执行更新操作而不是插入。这可以帮助你避免在插入数据时产生的重复键…...
AJAX-项目优化(目录、基地址、token、请求拦截器)
目录管理 基地址存储 在utils/request.js配置axios请求基地址 作用:提取公共前缀地址,配置后axios请求时都会baseURLurl 填写API的公共前缀后,将js文件导入到html文件中 <script src"../../utils/request.js"></script&…...

SQLite中的动态内存分配(五)
返回:SQLite—系列文章目录 上一篇:SQLite中的原子提交(四) 下一篇:自己编译SQLite或将SQLite移植到新的操作系统(六) 概述 SQLite使用动态内存分配来获得 用于存储各种对象的内存 (例如…...

快速上手Spring Cloud 十一:微服务架构下的安全与权限管理
快速上手Spring Cloud 一:Spring Cloud 简介 快速上手Spring Cloud 二:核心组件解析 快速上手Spring Cloud 三:API网关深入探索与实战应用 快速上手Spring Cloud 四:微服务治理与安全 快速上手Spring Cloud 五:Spring …...

如何简化多个 if 的判断结构
多少算太多? 有些人认为数字就是一,你应该总是用至少一个三元运算符来代替任何单个 if 语句。我并不这样认为,但我想强调一些摆脱常见的 if/else 意大利面条代码的方法。 我相信很多开发人员很容易陷入 if/else 陷阱,不是因为其…...

发掘服务器硬件优势:怎样有效管理、维护、更新
1. 概述 服务器是许多信息技术的核心,通过提供计算和存储资源,以用于企业和机构的数据处理和存储。服务器硬件也是服务器的核心组成部分,在服务器架构和配置中扮演着重要角色。 服务器硬件的优势: - 提供更高的性能和处理能力。…...
SD卡备份和烧录ubuntu20.04镜像
设备及系统:nuc幻影峡谷工控机,ubuntu20.04,树莓派4B,SD卡读卡器 一、确定SD卡设备号的两种方法 方法1: 将有ubuntu镜像的SD卡插入读卡器,再将读卡器插入电脑主机,在 工具 中打开 磁盘&#…...
短视频账号矩阵系统/开发 -- -- -- 蒙太奇算法上线
短视频账号矩阵系统,短视频矩阵系统开发3年技术之路,目前已经在技术竞品出沉淀出来,近期技术迭代的新的功能同步喽: php7.4版本,自研框架,有开发文档,类laravel框架 近期剪辑迭代的技术算法&am…...

Docker Stack(堆栈) 部署多服务集群,多服务编排
1、Docker Stack简介 Docker Stack(堆栈) 是在 Swarm 上管理服务堆栈的工具。而在以前文章docker swarm集群搭建 介绍的 Docker Swarm 只能实现对单个服务的简单部署,于是就引出了Docker Stack。 上面我们介绍到 docker-compose:可以在一台机器上使用…...

全国青少年软件编程(Scratch)等级考试二级考试真题2023年12月——持续更新.....
青少年软件编程(图形化)等级考试试卷(二级) 分数:100 题数:37 一、单选题(共25题,共50分) 1.在制作推箱子游戏时,地图是用数字形式储存在电脑里的,下图是一个推箱子地图,地图表示如下: 第一行(111111) 第二行(132231) 第三行(126621) 第四行( ) 第五行(152…...

python基础——异常捕获【try-except、else、finally】
📝前言: 这篇文章主要介绍一下python基础中的异常处理: 1,异常 2,异常的捕获 3,finally语句 🎬个人简介:努力学习ing 📋个人专栏:C语言入门基础以及python入门…...

JAVA面试大全之JVM和调优篇
目录 1、类加载机制 1.1、类加载的生命周期? 1.2、类加载器的层次? 1.3、Class.forName()和ClassLoader.loadClass()区别?...
数据可视化-ECharts Html项目实战(8)
在之前的文章中,我们学习了如何设置散点图涟漪效果与仪表盘动态指针效果。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢 今天的文章,会…...

JavaSE:继承和多态(下篇)
目录 一、前言 二、多态 (一)多态的概念 (二)多态实现条件 (三)多态的优缺点 三、重写 (一)重写的概念 (二)重写的规则 (三)重…...

springboot+mybatis项目集成p6spy输出格式化sql日志
本文背景:公司项目框架是基于springboot+mybatis的web项目,由于鄙人在使用过程中发现打印的mybatis日志每次都要粘贴出来,然后再用在线工具的格式化填充参数,很不方便,最近发现那个在线的工具打不开了,更不方便了,因此想有没有直接可以输出的填充好参数的sql语句,当然i…...

yarn安装和使用及与npm的区别
一、yarn安装和使用 要安装和使用yarn,您可以按照以下步骤进行操作: 安装Node.js:首先,您需要在您的计算机上安装Node.js。您可以从Node.js的官方网站(https://nodejs.org/en/download/)下载并安装适用于您…...
【3D-GS】Gaussian Splatting SLAM——基于3D Gaussian Splatting的全网最详细的解析
【3D-GS】Gaussian Splatting SLAM——基于3D Gaussian Splatting的定SLAM 3D-GS 与 Nerf 和 Gaussian Splatting1. 开山之作 Nerf2. 扛鼎之作 3D Gaussian Splatting2.1 什么是3D高斯?高斯由1D推广到3D的数学推导2.2 什么是光栅化?2.3 什么是Splatting?2.4 什么是交叉优化?…...

湘潭品牌设计公司权威推荐榜单
在当今竞争激烈的市场环境中,品牌已成为企业最核心的资产之一。一个专业、系统、富有战略性的品牌设计,不仅能提升企业的市场辨识度,更能成为驱动业务增长的强大引擎。对于湘潭及周边地区的企业而言,选择一家专业、可靠的品牌设计…...

Frontend-Cheat-Sheets终极指南:从CSS2到CSS3的完整样式参考
Frontend-Cheat-Sheets终极指南:从CSS2到CSS3的完整样式参考 【免费下载链接】Frontend-Cheat-Sheets Collection of cheat sheets(HTML, CSS, JS, Git, Gulp, etc.,) for your frontend development needs & reference 项目地址: https://gitcode.com/gh_mir…...

如何高效使用ASP.NET Core视图包:动态数据容器完全指南
如何高效使用ASP.NET Core视图包:动态数据容器完全指南 【免费下载链接】aspnetcore dotnet/aspnetcore: 是一个 ASP.NET Core 应用程序开发框架的官方 GitHub 仓库,它包含了 ASP.NET Core 的核心源代码和技术文档。适合用于 ASP.NET Core 应用程序开发&…...

终极指南:如何使用 Matisse 打造 Android 图片选择器
终极指南:如何使用 Matisse 打造 Android 图片选择器 【免费下载链接】Matisse :fireworks: A well-designed local image and video selector for Android 项目地址: https://gitcode.com/gh_mirrors/mati/Matisse Matisse 是一款设计精美的 Android 本地图…...

着色器multi_compile笔记
概述一句multi_compile后面写若干个关键字XXX,在代码里用#if XXX条件编译一段代码。开启、关闭关键字关键字的开启关闭在材质debug界面。在Valid Keywords填的关键字如果在某句multi_compile里会自动进入Valid Keywords,否则进入Invalid。代码开启关键字…...

环境变量解密:从基础概念到云原生实践
1. 环境变量基础:从图书馆到代码世界 第一次听说环境变量时,我正坐在大学图书馆里啃着C语言教材。管理员突然广播:"考试周期间,每人限借3本书,借期缩短为15天。"看着同学们手忙脚乱地归还超额书籍࿰…...
比currentTimeMillis()更适合高精度计时?)
Java性能调优实战:为什么System.nanoTime()比currentTimeMillis()更适合高精度计时?
Java高精度计时实战:为何nanoTime()是性能调优的首选? 在游戏开发、算法性能测试等对时间精度要求极高的场景中,Java开发者常常面临一个关键选择:System.currentTimeMillis()还是System.nanoTime()?这个看似简单的选择…...

用树莓派Pico和MicroPython玩转OLED显示:从I2C连接到动态内容展示
树莓派Pico与MicroPython实战:OLED屏幕的I2C驱动与动态内容开发指南 1. 硬件准备与环境搭建 要让树莓派Pico驱动OLED屏幕,首先需要准备以下硬件组件: 树莓派Pico开发板(RP2040芯片)SSD1306驱动的0.96寸OLED屏幕&…...

ChatGPT内容生成指令与范例大全:从零构建高效提示词工程
ChatGPT内容生成指令与范例大全:从零构建高效提示词工程 刚开始接触ChatGPT这类大语言模型时,你是不是也遇到过这样的烦恼?明明想让AI写一篇产品介绍,结果它给你生成了一篇抒情散文;想让它总结技术文档,它…...

百考通AI:实践报告智能生成,让实习总结更高效专业
每一段实习实践的收尾,都绕不开一份详实规范的实践报告。从梳理实习经历到提炼成长收获,从搭建报告框架到打磨文字表达,繁琐的撰写流程常常让学子们倍感疲惫。百考通AI(https://www.baikaotongai.com)凭借智能化的实践…...