Python爬虫之异步爬虫
异步爬虫
一、协程的基本原理
1、案例
案例网站:https://www.httpbin.org/delay/5、这个服务器强制等待了5秒时间才返回响应
测试:用requests写一个遍历程序,遍历100次案例网站:
import requests
import logging
import timelogging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s:%(message)s')
TOTAL_NUMBER = 100
URL = 'https://www.httpbin.org/delay/5'start_time = time.time()
for _ in range(1,TOTAL_NUMBER + 1):logging.info('scraping %s',URL)response = requests.get(URL)
end_time = time.time()
logging.info('total time %s seconds',end_time - start_time)# 爬取总时间约为11分钟
2、基本知识
2.1、阻塞
阻塞状态指程序未得到所需计算资源时被挂起的状态。程序在等待某个操作完成期间,自身无法继续干别的事情,则称该程序在该操作上市阻塞的 。
常见的阻塞形式有:网络I/O阻塞、磁盘I/O阻塞、用户输入阻塞等。阻塞是无处不在的,包括在CPU切换上下文时,所有进程都无法真正干事情,它们也会被阻塞。在多核CPU的情况下,正在执行上下文切换操作的核不可被利用。
2.2、非阻塞
程序在等待某操作的过程中,自身不被阻塞,可以继续干别的事情,则称该程序在该操作上是非阻塞的。
非阻塞并不是在任何程序级别、任何情况下都存在的。仅当程序封装的级别可以囊括独立的子程序单元时,程序才可能存在非阻塞状态。
非阻塞因阻塞的存在而存在,正因为阻塞导致程序运行时的耗时增加与效率低下,我们才要把它变成非阻塞的。
2.3、同步
不同单元为了共同完成某个任务,在执行过程中需要靠某种通信方式保持协调一致,此时这些程序单元是同步执行的。
同步意味着有序。
2.4、异步
为了完成某个任务,有时不同程序单元之间戊戌通信协调也能完成任务,此时不相关的程序单元之间可以是异步的。
异步意味着无序。
2.5、多进程
多进程就是利用CPU的多核优势,在同一时间并行执行多个任务,可以大大提高执行效率。
2.6、协程
协程,英文叫做coroutine,又称微线程、纤程,是一种运行在用户太的轻量级线程。
协程拥有自己的寄存器上下文和栈。协程在调度切换时,将寄存器上下文和栈保存到其他地方,等切回来的时候,再恢复先前保存的寄存器上下文和栈。因此,协程能保留上一次调用的状态,即所有局部状态的一个特定组合,每次过程重入,就相当于上一次调用的状态。
协程本质是单进程,相对于多进程来说,它没有线程上下文切换的开销,没有原子操作锁定及同步的开销,编程模型也非常简单。
3、协程的用法
Python3.4开始,Python中加入了协程的概念,但这个版本的协程还是以生成器对象为基础。Python3.5中增加了asyncio、await,使得协程的实现更为方便。
Python中使用协程最常用的莫过于asyncio库。
- event_loop:事件循环,相当于一个无限循环,我们可以把一些函数注册到这个事件循环上、当满足发生条件的时候,就调用对应的处理方法。
- coroutine:中文翻译叫协程,在Python中长指代协程对象类型,我们可以将协程对象注册到事件循环中,它会被事件循环调用。我们可以使用async关键字来定义一个方法,这个方法在调用时不会立即被执行,而是会返回一个协程对象。
- task:任务,这是对协程对象的进一步封装,包含协程对象的各个状态。
- future:代表将来执行或者没有执行的任务的结果,实际上和task没有本质。
4、准备工作
确保安装的Python版本为3.5以上。
5、定义协程
import asyncio # 引入asyncio包,这样才能使用async和await关键字。async def execute(x): # 使用async定义了一个execute方法,该方法接受一个数字参数x,执行之后会打印这个数字。print('Number:',x)
coroutine = execute(1) # 调用这execute方法,然而没有被执行,而是返回了一个coroutine协程对象。
print('Coroutine:',coroutine)
print('After calling execute')loop = asyncio.get_event_loop() # 使用get_event_loop方法创建了一个事件循环loop
loop.run_until_complete(coroutine) # 调用loop对象的run_until_complete方法将协程对象注册到了事件循环中,接着启动。才看见了这个数字。
print('After calling loop')
- 可见,async定义的方法会变成一个无法执行的协程对象,必须将此对象注册到事件循环中才可以执行。
- 前面提到的task,是对协程对象的进一步封装,比协程对象多了个运行状态,例如runing、finished等,我们可以利用这些状态获取协程对象的执行情况。
- 在上述例子中,我们把协程对象coroutine传递给run_untill_complete方法的时候,实际上它进行了一个操作,就是将coroutine封装成task对象。对此,我们也可以显式的进行声明:
import asyncioasync def execute(x):print('Number:',x)return xcoroutine = execute(1)
print('Coroutine:',coroutine)
print('After calling execute')loop = asyncio.get_event_loop()
task = loop.create_task(coroutine) # 调用loop对象的create_task方法,将协程对象转为task对象,随后打印输出一下,发现它处于pending状态
print('Task:',task) # pending
loop.run_until_complete(task) # 将task对象加入到事件循环中执行后,发现状态变为finished
print('Task:',task) # finished
print('After calling loop')
定义task对象还有另外一种方式,就是直接调用asyncio包的ensure_future方法,返回结果也是task对象,这样的话就可以不借助loop对象。即使还没有声明loop,也可以提取定义好task对象:
async def execute(x):print('Number:',x)return xcoroutine = execute(1)
print('Coroutine:',coroutine)
print('After calling execute')task = asyncio.ensure_future(coroutine)
print('Task:',task)
loop = asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:',task)
print('After calling loop')
6、绑定回调
我们也可以为某个task对象绑定一个回调方法:
import asyncio
import requestsasync def request(): # 定义request方法,请求百度,返回状态码。url = 'https://www.baidu.com'status = requests.get(url)return statusdef callback(task): # 定义callback方法,接受一个task对象参数,打印task对象的结果。print('Status:',task.result())coroutine = request()
task = asyncio.ensure_future(coroutine)
task.add_done_callback(callback) # 将callback方法传递给封装好的task对象,这样当task执行完毕后,就可以调用callback方法了。同时task对象还会作为参数传递给callback方法,调用task对象的result方法就可以获取返回结果。
print('Task:',task)loop = asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:',task)
实际上,即使不适用回调方法,在task运行完毕后,也可以直接调用result方法获取结果:
import asyncio
import requestsasync def request():url = 'https://www.baidu.com'status = requests.get(url)return statuscoroutine = request()
task = asyncio.ensure_future(coroutine)
print('Task:',task)loop = asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:',task)
print('Result:',task.result())
7、多任务协程
如果想执行多次请求,可以定义一个task列表,然后使用asyncio包中的wait方法执行:
import asyncio
import requestsasync def request():url = 'https://www.baidu.com'status = requests.get(url)return statustasks = [asyncio.ensure_future(request()) for _ in range(5)] # 列表推导式
print('Tasks:',tasks)loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))for task in tasks:print('Tasl result:',task.result())
使用一个for循环创建了5个task,它们组成一个列表(列表推导式),然后把这个列表首先传递给asyncio包的wait方法,再将其注册到事件循环中,就可以发起5个任务了。
8、协程实现
await不能和requests返回的Response对象一起使用。await后面的对象必须是以下:
- 一个原生协程对象
- 一个由types.coroutine修饰的生成器,这个生成器可以返回协程对象
- 由一个包含_await_方法的对象返回一个迭代器
import asyncio
import requests
import timestart = time.time()
async def get(url):return requests.get(url)async def request():url = 'https://www.httpbin.org/delay/5'print('Waiting for',url)response = await get(url)print('Get response from',url,'response',response)tasks = [asyncio.ensure_future(request()) for _ in range(10)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))end = time.time()
print('Cost time:',end - start)
报错,说明仅仅将涉及I/O操作的代码封装到async修饰的方法是不可行的。只有使用支持异步操作的请求方式才可以实现真正的异步。aiohttp就派上用场了
9、使用aiohttp
aiohttp是一个支持异步请求的库,它和asyncio配合使用,可以使我们方便的实现异步请求操作。
pip3 install aiohttp
import asyncio
import requests
import aiohttp
import timestart = time.time()async def get(url):session = aiohttp.ClientSession()response = await session.get(url)await response.text()await session.close()return requestsasync def request():url = 'https://www.httpbin.org/delay/5'print('Waiting for',url)response = await get(url)print('Get response from',url,'response',response)tasks = [asyncio.ensure_future(request()) for _ in range(10)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))end = time.time()
print('Cost time:',end - start) # 6秒
二、aiohttp的使用
1、基本介绍
aiohttp是一个基于asyncio的异步HTTP网络模块,它既提供了服务端,又提供了客户端。
- 其中,我们用服务端可以搭建一个支持异步处理的服务器,这个服务器就是用来处理请求并返回响应的,类似Djaongo、Flask等。
- 而客户端可以用来发起请求,类似于使用requests发起一个HTTP请求然后获得响应,但requests发起的是同步的网络请求,aiohttp是异步的。
2、基本实例
import aiohttp
import asyncioasync def fetch(session,url):async with session.get(url) as response:return await response.text(),response.statusasync def main():async with aiohttp.ClientSession() as session:html,status = await fetch(session,'https://cuiqingcai.com')print(f'html:{html[:100]}...')print(f'status:{status}')if __name__ == '__main__':loop = asyncio.get_event_loop()loop.run_until_complete(main())
# asyncio.run(main())
aiohttp的请求方法与之前的差别:
- 必须引入aiohttp库和asyncio库。因为实现异步爬取,需要启动协程,而协程需要借助asyncio里面的事件循环才能执行。除了事件循环,aasyncio里面也提供了许多基础的异步操作。
- 异步爬取方法的定义不同,每个异步方法的前面都要统一加async来修饰。
- with as 语句前面同样需要加async来修饰。在Python中,with as 语句用来声明一个上下文管理器,能够帮我们自动分配和释放资源。而在异步方法中,with as前面加上async代表声明一个支持异步的上下文管理器。
- 对于一些返回协程对象的操作,前面需要加await来修饰。
- 定义完爬取方法之后,实际上是main方法调用了fetch方法。要运行的话,必须启用事件循环。
在Python3.7及以后的版本,我们可以使用asyncio.run(main())代替最后的启动操作,不需要显示声明事件循环,run()方法内部会自动启用一个事件循环。
3、URL参数设置
对于URL参数的设置,我们可以借助params参数,传入一个字典即可:
import aiohttp
import asyncioasync def main():params = {'name':'germey','age':25}async with aiohttp.ClientSession() as session:async with session.get('https://www.httpbin.org/get',params=params) as response:print(await response.text())if __name__ == '__main__':asyncio.get_event_loop().run_until_complete(main())
实际请求的URL为https://www.httpbin.org/get?name=germey&age=25、其中的参数对应params的内容
4、其他请求类型
aiohttp还支持其他请求类型:
async with session.get('http://www.httpbin.org/get',data=b'data')
async with session.put('http://www.httpbin.org/get',data=b'data')
async with session.delete('http://www.httpbin.org/get',)
async with session.head('http://www.httpbin.org/get',)
async with session.options('http://www.httpbin.org/get',)
async with session.patch('http://www.httpbin.org/get',data=b'data')
5、POST请求
对于POST表单提交,其对应的请求头中的Content-Type为application/x-www-form-urlencoded,实现:
import asyncio
import aiohttpasync def main():data = {'name':'germey','age':25}async with aiohttp.ClientSession() as session:async with session.post('https://www.httpbin.org/post',data=data) as response:print(await response.text())if __name__ == '__main__':asyncio.get_event_loop().run_until_complete(main())
对于POST JSON数据提交,其对应的请求头中的Content-Type为application/json,将post方法里的data参数改成json即可:
async def main():data = {'name':'germey','age':25}async with aiohttp.ClientSession() as session:async with session.post('https://www.httpbin.org/post',json=data) as response:print(await response.text())
6、响应
对于响应来说,我们可以用如下方法分别获取其中的状态码、响应头、响应体,响应体二进制内容、响应体JSON结果:
import aiohttp
import asyncioasync def main():data = {'name':'germey','age':25}async with aiohttp.ClientSession() as session:async with session.post('https://www.httpbin.org/post',data=data) as response:print('status:',response.status)print('headers:',response.headers)print('body:',await response.text())print('bytes:',await response.read())print('json:',await response.json())if __name__ == '__main__':asyncio.get_event_loop().run_until_complete(main())
有些字段需要加await的原因是,如果返回的是一个协程对象(如async修饰的方法),那么前面就要加await。
7、超时设置
可以借助ClientTimeout对象设置超时,例如要设置1秒的超时时间:
import aiohttp
import asyncioasync def main():timeout = aiohttp.ClientTimeout(total=1)async with aiohttp.ClientSession(timeout=timeout) as session:async with session.get('https://www.httpbin.org/get') as response:print('status:',response.status)if __name__ == '__main__':asyncio.get_event_loop().run_until_complete(main())
如果超时则抛出TimeoutRrror异常。
8、并发限制
由于aiohttp可以支持非常高的并发量,面对高的并发量,目标网站可能无法在短时间内响应,而且有瞬间将目标网站爬挂掉。因此需要借助asyncio的Semaphore控制一下爬取的并发量:
import asyncio
import aiohttpCONCURRENCY = 5
URL = 'https://www.baidu.com'semaphore = asyncio.Semaphore(CONCURRENCY)
session = Noneasync def scrap_api():async with semaphore:print('scraping',URL)async with session.get(URL) as response:await asyncio.sleep(1)return await response.text()
async def main():global sessionsession = aiohttp.ClientSession()scrape_index_tasks = [asyncio.ensure_future(scrap_api()) for _ in range(10000)]await asyncio.gather(*scrape_index_tasks)if __name__ == '__main__':asyncio.get_event_loop().run_until_complete(main())
这里声明CONCURRENCY(代表爬取的最大并发量)为5,同时声明爬取的目标为百度…
三、aiohttp异步爬取实战
1、案例介绍
网站:https://spa5.scrape.center/
2、准备工作
- 安装好了Python
- 了解Ajax爬取的一些基本原理和模拟方法
- 了解异步爬虫的基本原理和asyncio库的基本用法
- 了解asiohttp库的基本用法
3、页面分析
- 列表页的Ajax请求接口格式为https://spa5.scrape.center/api/book/?limit=18&offset={offset}
- 在列表页的Ajax接口返回的数据里,results字段包含当前页里18本图书的信息,其中每本书的数据里都含有一个id字段,这个id就是图书本身的ID
- 详情页的Ajax请求格式为https://spa5.scrape.center/api/book{id}
4、实现思路
- 第一阶段:异步爬取所有列表页,将所有列表页的爬取任务集合在一起,并将其声明为由task组成的列表,进行异步爬取。
- 第二阶段:拿到上一步列表页的所有内容解析,将所有图书的ID信息组合为所有详情页的爬取任务集合,并将其声明为task组成的列表。进行异步爬取,结果也以异步新式存储到数据库。
5、基本配置
import asyncio
import aiohttp
import logginglogging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s:%(message)s')
INDEX_URL = 'https://spa5.scrape.center/api/book/?limit=18&offset={offset}'
DETAIL_URL = 'https://spa5.scrape.center/api/book/{id}'
PAGE_SIZE =18
PAGE_NUMBER = 100
CONCURRENCY = 5
6、爬取列表页
爬取列表页,先定义一个通用的爬取方法:
semaphore = asyncio.Semaphore(CONCURRENCY) # 声明信号量,控制最大并发数量
session = Noneasync def scrape_api(url): # 定义scrape_api方法,接受一个参数apiasync with semaphore: # 用async with语句引入信号量作为上下文try:logging.info('scraping %s',url)async with session.get(url) as response: # 调用session的get方法请求url,return await response.json() # 返回响应的JSON格式except aiohttp.ClientError: # 进行异常处理logging.error('error occurred while scraping %s',url,exc_info=True)
爬取列表页:
async def scrape_index(page): # 爬取列表页方法,接受一个参数page,url = INDEX_URL.format(offset=PAGE_SIZE * (page - 1)) # 构造一个列表页的URLreturn await scrape_api(url) # scripe_api调用之后本身会返回一个协程对象,所以加await
定义main()方法,将上面的方法串联起来调用:
async def main():global session # 声明最初声明的全局变量sessionsession = aiohttp.ClientSession() scrape_index_tasks = [asyncio.ensure_future(scrape_index(page)) for page in range(1,PAGE_NUMBER + 1)] # 用于爬取列表页所有的task组成的列表results = await asyncio.gather(*scrape_index_tasks) # 调用gather方法,将task列表传入其参数,将结果赋值为results,它是由所有task返回结果组成的列表。logging.info('results %s',json.dumps(results,ensure_ascii=False,indent=2))if __name__ == '__main__': # 调用main方法,开启事件循环。asyncio.get_event_loop().run_until_complete(main())
7、爬取详情页
在main方法里增加results的解析代码:
ids = []
for index_data in results:if not index_data: continuefor item in index_data.get('results'):ids.append(item.get('id'))
在定义两个方法用于爬取详情页和保存数据:
async def save_data(data):logging.info('saving data %s',data)... # (以后再补)async def scrape_detail(id):url = DETAIL_URL.format(id=id)data = await scrape_api(url)await save_data(data)
接着在main方法里面增加对scrape_detail方法的调用即可爬取详情页:
scrape_detail_tasks = [asyncio.ensure_future(scrape_detail(id)) for id in ids]await asyncio.wait(scrape_detail_tasks)await session.close()
相关文章:

Python爬虫之异步爬虫
异步爬虫 一、协程的基本原理 1、案例 案例网站:https://www.httpbin.org/delay/5、这个服务器强制等待了5秒时间才返回响应 测试:用requests写一个遍历程序,遍历100次案例网站: import requests import logging import time…...
【Web】NSSCTF Round#20 Basic 个人wp
目录 前言 真亦假,假亦真 CSDN_To_PDF V1.2 前言 感谢17👴没让我爆零 真亦假,假亦真 直接getshell不行,那就一波信息搜集呗,先开dirsearch扫一下 扫的过程中先试试常规的robots.txt,www.zip,shell.phps,.git,.sv…...

【Java笔记】实现延时队列1:JDK DelayQueue
文章目录 需求创建订单类创建延时队列优缺点 Reference JDK DelayQueue是一个无阻塞队列,底层是 PriorityQueue 需求 经典的订单超时取消 创建订单类 放入DelayQueue的对象需要实现Delayed接口 public interface Delayed extends Comparable<Delayed> {…...

npm淘宝镜像源切换
查询 npm config get registry注意因为淘宝的镜像域名更换,https://registry.npm.taobao.org域名HTTPS证书到期更换为https://registry.npmmirror.com/ 切换 npm config set registry https://registry.npmmirror.com/...
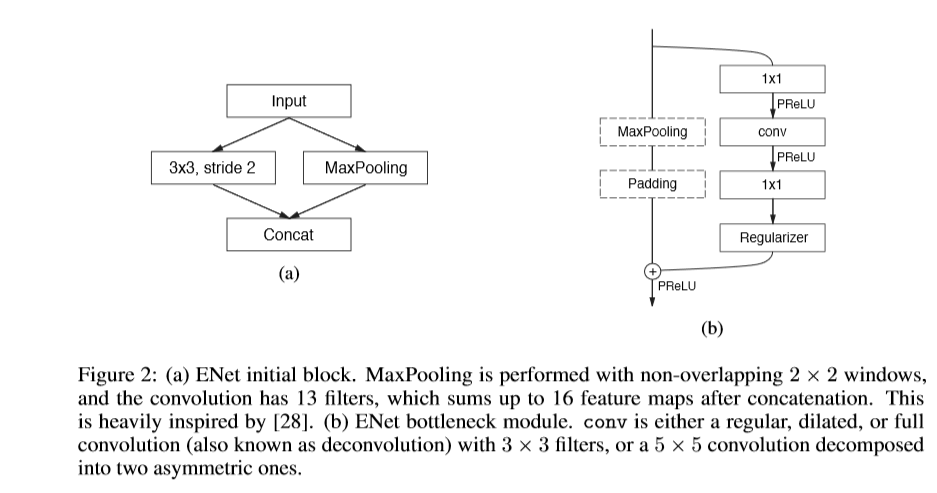
ENet——实时语义分割的深度神经网络架构与代码实现
概述 在移动设备上执行实时像素级分割任务具有重要意义。现有的基于分割的深度神经网络需要大量的浮点运算,并且通常需要较长时间才能投入使用。本文提出的ENet架构旨在减少潜在的计算负担。ENet在保持或提高分割精度的同时,相比现有的分割网络…...
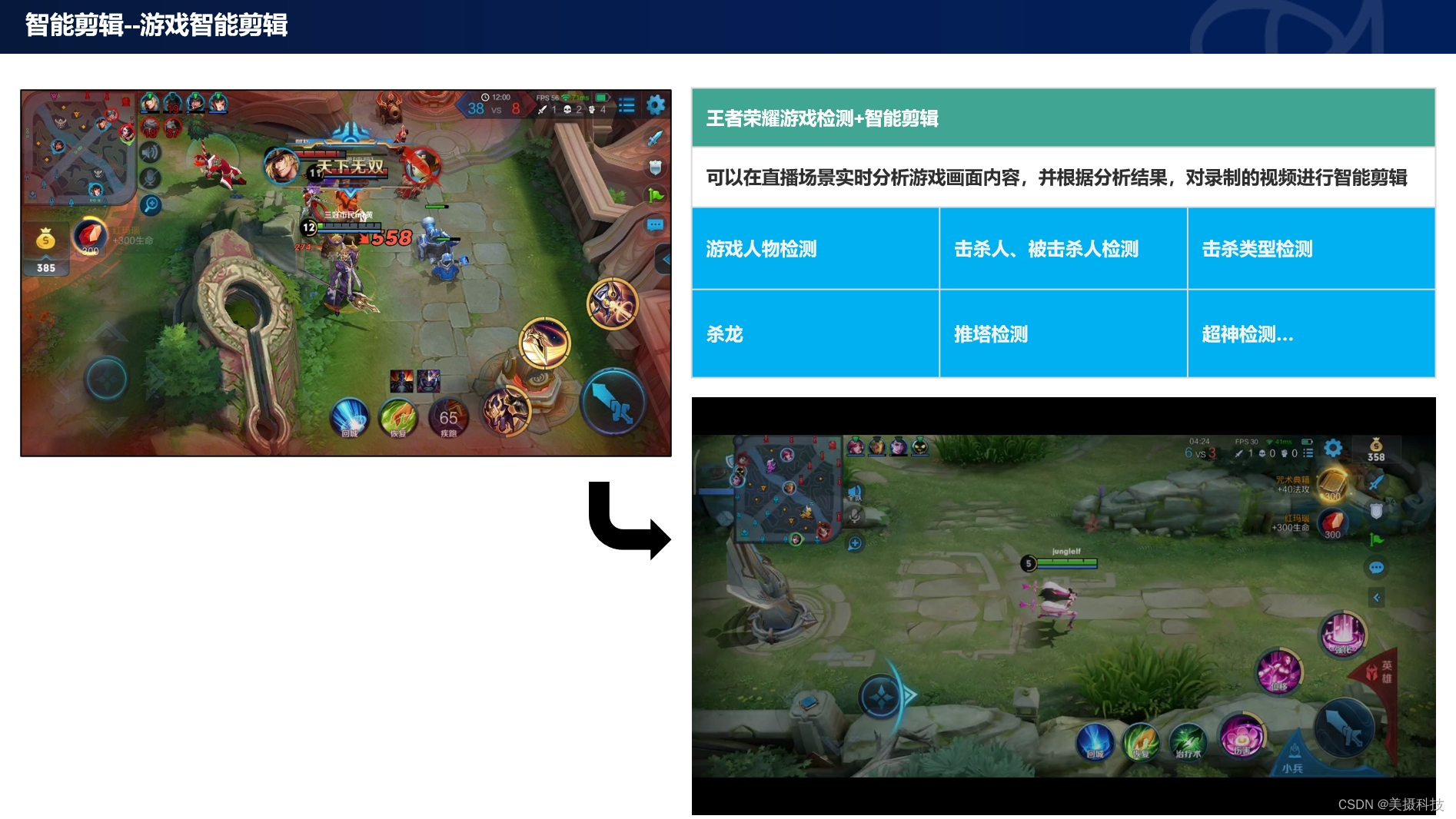
游戏领域AI智能视频剪辑解决方案
游戏行业作为文化创意产业的重要组成部分,其发展和创新速度令人瞩目。然而,随着游戏内容的日益丰富和直播文化的兴起,传统的视频剪辑方式已难以满足玩家和观众日益增长的需求。美摄科技,凭借其在AI智能视频剪辑领域的深厚积累和创…...

腾讯云轻量2核2G3M云服务器优惠价格61元一年,限制200GB月流量
腾讯云轻量2核2G3M云服务器优惠价格61元一年,配置为轻量2核2G、3M带宽、200GB月流量、40GB SSD盘,腾讯云优惠活动 yunfuwuqiba.com/go/txy 活动链接打开如下图: 腾讯云轻量2核2G云服务器优惠价格 腾讯云:轻量应用服务器100%CPU性能…...
leecode 331 |验证二叉树的前序序列化 | gdb 调试找bug
计算的本质是数据的计算 数据的计算需要采用格式化的存储, 规则的数据结果,可以快速的按照指定要求存储数据 这里就不得不说二叉树了,二叉树应用场景真的很多 本题讲的是,验证二叉树的前序序列化 换言之,不采用建立树的…...

服务器安全事件应急响应排查方法
针对服务器操作系统的安全事件也非常多的。攻击方式主要是弱口令攻击、远程溢出攻击及其他应用漏洞攻击等。分析安全事件,找到入侵源,修复漏洞,总结经验,避免再次出现安全事件,以下是参考网络上文章,总结的…...

数码视讯Q7盒子刷armbian或emuelec的一些坑
首先,我手头的盒子是nand存储的,如果是emmc的,会省事很多…… 以下很多结论是我的推测,不一定准确。 1,原装安卓系统不支持SD卡或U盘启动,所以只能进uboot修改启动参数 2,原装安卓系统应该是…...

2_2.Linux中的远程登录服务
# 一.Openssh的功能 # 1.sshd服务的用途# #作用:可以实现通过网络在远程主机中开启安全shell的操作 Secure SHell >ssh ##客户端 Secure SHell daemon >sshd ##服务端 2.安装包# openssh-server 3.主配置文件# /etc/ssh/sshd_conf 4.…...
Spring Boot集成JPA快速入门demo
1.JPA介绍 JPA (Java Persistence API) 是 Sun 官方提出的 Java 持久化规范。它为 Java 开发人员提供了一种对象/关联映射工具来管理 Java 应用中的关系数据。他的出现主要是为了简化现有的持久化开发工作和整合 ORM 技术,结束现在 Hibernate,TopLink&am…...
深度学习理解及学习推荐(持续更新)
主推YouTuBe和Bilibili 深度学习博主推荐: Umar Jamil - YouTubehttps://www.youtube.com/umarjamilai StatQuest with Josh Starmer - YouTubehttps://www.youtube.com/statquest RNN Illustrated Guide to Recurrent Neural Networks: Understanding the Int…...

【C语言】贪吃蛇【附源码】
欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 一、游戏说明: 一个基于C语言链表开发的贪吃蛇游戏: 1. 按方向键上下左右,可以实现蛇移动方向的改变。 2. 短时间长按方向键上下左右其中之一,可实现蛇向该方向的短时间…...
【技巧】压缩文件如何设置“自动加密”?
很多人会在压缩文件的时候,同时设置密码,以此保护私密文件。如果经常需要压缩文件并设置密码,不妨使用解压缩软件的“自动加密”功能,更省时省力。 下面介绍WinRAR解压缩软件的两种“自动加密”的方法,一起来看看吧&a…...

内网穿透时报错【Bad Request This combination of host and port requires TLS.】的原因
目录 前言:介绍一下内网穿透 1.内网直接https访问(可以正常访问) 程序配置的证书 2.内网穿透后,通过外网访问 3.原因 4.内网非https的Web应用,使用https后,也变成了https访问 5.题外话 感觉自己的web应用配置了…...
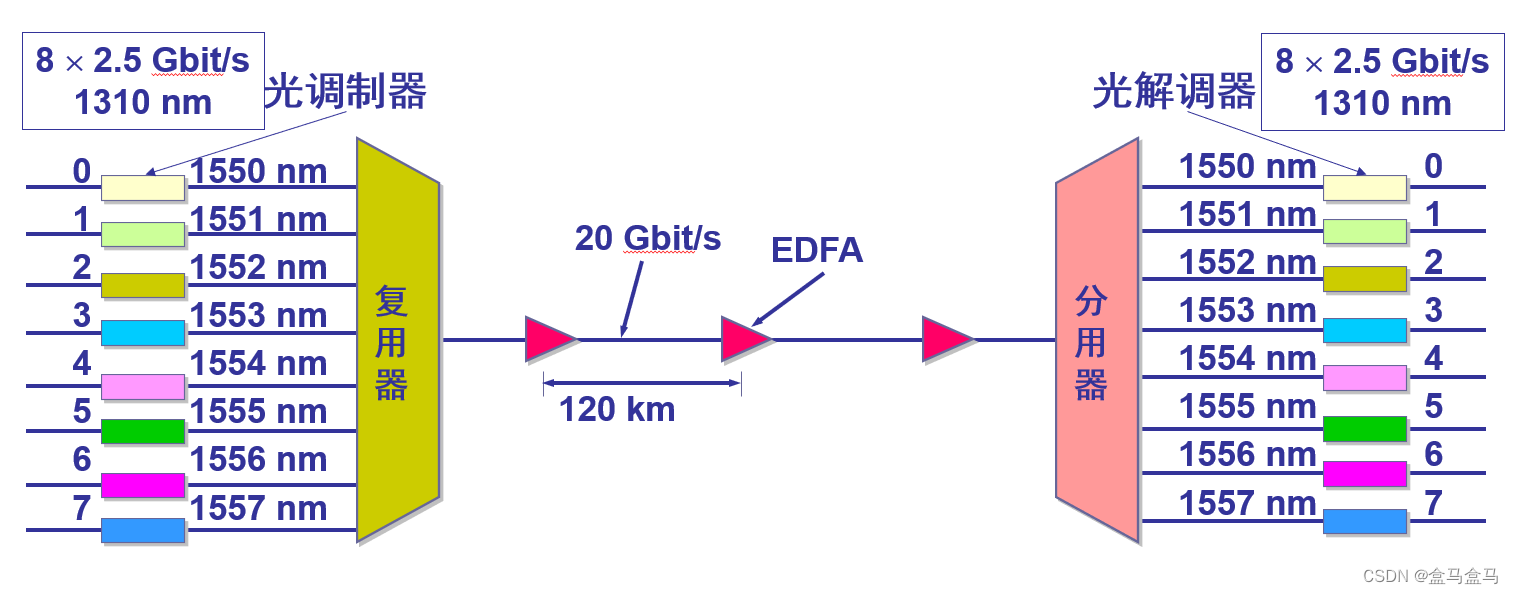
计算机网络:物理层 - 信道复用
计算机网络:物理层 - 信道复用 频分复用时分复用统计时分复用波分复用码分复用 计算机网络中,用户之间通过信道进行通信,但是信道是有限的,想要提高网络的效率,就需要提高信道的利用效率。因此计算机网络中普遍采用信道…...

【算法集训】基础算法:滑动窗口
定义一个快慢指针,用于截取数组中某一段信息。同时可以改变快慢指针的值来获取结果,这个过程比较像滑动。 1493. 删掉一个元素以后全为 1 的最长子数组 定义快慢指针快指针先走,如果到了第二个0上的时候。前面1的个数就是fast - slow - 1&a…...
QT 二维坐标系显示坐标点及点与点的连线-通过定时器自动添加随机数据点
QT 二维坐标系显示坐标点及点与点的连线-通过定时器自动添加随机数据点 功能介绍头文件C文件运行过程 功能介绍 上面的代码实现了一个简单的 Qt 应用程序,其功能包括: 创建一个 MainWindow 类,继承自 QMainWindow,作为应用程序的…...
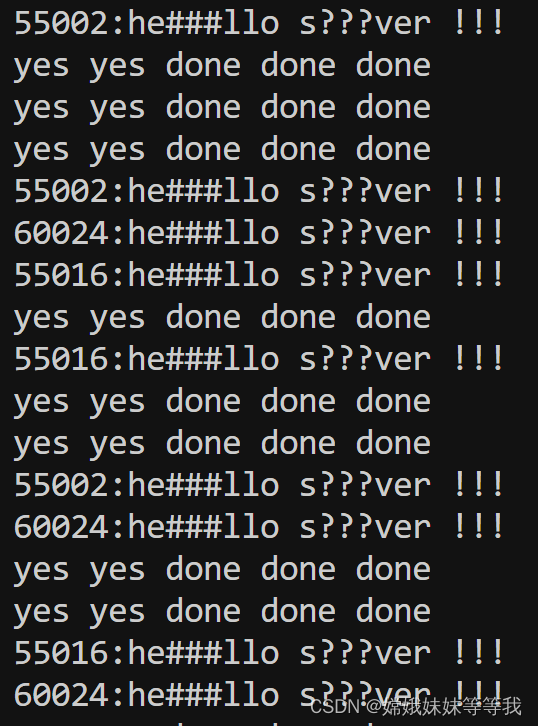
C语言TCP服务器模型 : select + 多线程与双循环单线程阻塞服务器的比较
观察到的实验现象: 启动三个客户端: 使用双循环阻塞服务器:只能accept后等待收发,同时只能与一个客户端建立连接,必须等已连接的客户端多次收发 明确断开后才能与下个客户端连接 使用IO多路复用select:可以同时接收所有的连接请求,并且连接状态一直是存活的,直到客户端关闭连…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

Webpack性能优化:构建速度与体积优化策略
一、构建速度优化 1、升级Webpack和Node.js 优化效果:Webpack 4比Webpack 3构建时间降低60%-98%。原因: V8引擎优化(for of替代forEach、Map/Set替代Object)。默认使用更快的md4哈希算法。AST直接从Loa…...

Kubernetes 网络模型深度解析:Pod IP 与 Service 的负载均衡机制,Service到底是什么?
Pod IP 的本质与特性 Pod IP 的定位 纯端点地址:Pod IP 是分配给 Pod 网络命名空间的真实 IP 地址(如 10.244.1.2)无特殊名称:在 Kubernetes 中,它通常被称为 “Pod IP” 或 “容器 IP”生命周期:与 Pod …...
)
Leetcode33( 搜索旋转排序数组)
题目表述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], …, nums[n-1], nums[0], nu…...
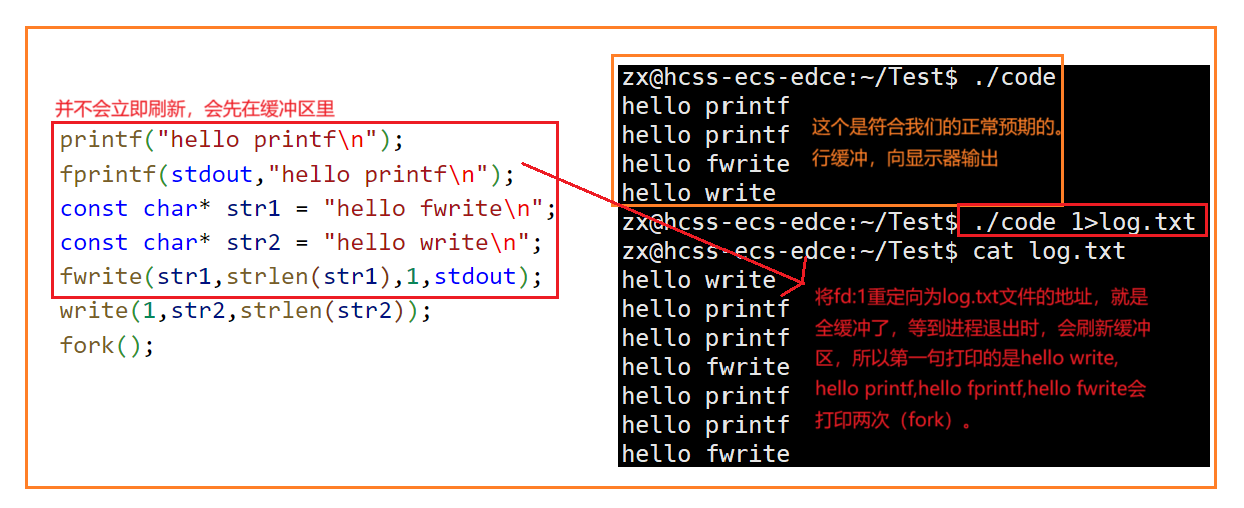
Linux中《基础IO》详细介绍
目录 理解"文件"狭义理解广义理解文件操作的归类认知系统角度文件类别 回顾C文件接口打开文件写文件读文件稍作修改,实现简单cat命令 输出信息到显示器,你有哪些方法stdin & stdout & stderr打开文件的方式 系统⽂件I/O⼀种传递标志位…...